Redis源码剖析—链表结构
1. redis中的链表
在redis中链表的应用非常广泛,例如 列表键的底层实现之一就是链表 。而且,在redis中的链表结构被实现成为 双向链表 ,因此,在头部和尾部进行的操作就会非常快。
通过列表键的命令感受一下双向链表:列表键命令详解
127.0.0.1:6379> LPUSH list a b c //依次在链表头部插入a、b、c
(integer) 3
127.0.0.1:6379> RPUSH list d e f //依次在链表尾部插入d、e、f
(integer) 6
127.0.0.1:6379> LRANGE list 0 -1 //查看list的值
1) "c"
2) "b"
3) "a"
4) "d"
5) "e"
6) "f"
2. 链表的实现
2.1 链表节点的实现
每个链表节点由adlist.h/listNode来表示
typedef struct listNode {
struct listNode *prev; //前驱节点,如果是list的头结点,则prev指向NULL
struct listNode *next;//后继节点,如果是list尾部结点,则next指向NULL
void *value; //万能指针,能够存放任何信息
} listNode;
listNode结构通过 prev和next指针就组成了双向链表 。刚才通过 列表键生成的双向链表如下图 :
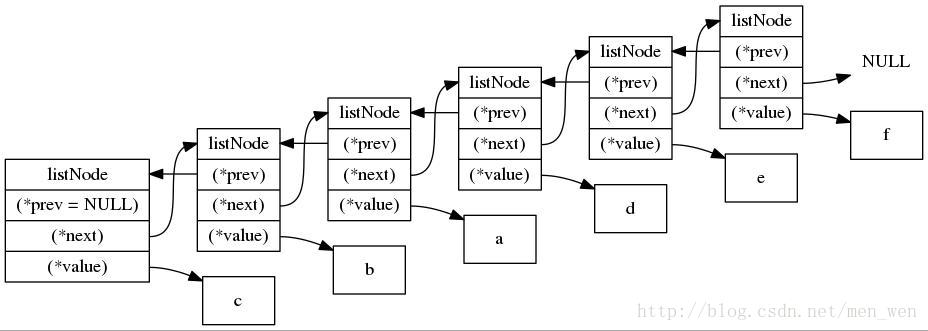
使用双向链表的好处:
- prev和next指针:获取某个节点的前驱节点和后继节点复杂度为O(1)。
2.2 表头的实现
redis还提供了一个表头,用于 存放上面双向链表的信息 ,它由adlist.h/list结构表示:
typedef struct list {
listNode *head; //链表头结点指针
listNode *tail; //链表尾结点指针
//下面的三个函数指针就像类中的成员函数一样
void *(*dup)(void *ptr); //复制链表节点保存的值
void (*free)(void *ptr); //释放链表节点保存的值
int (*match)(void *ptr, void *key); //比较链表节点所保存的节点值和另一个输入的值是否相等
unsigned long len; //链表长度计数器
} list;
将表头和双向链表连接起来,如图:

利用list表头管理链表信息的好处:
- head和tail指针: 对于链表的头结点和尾结点操作的复杂度为O(1)。
- len 链表长度计数器: 获取链表中节点数量的复杂度为O(1)。
- dup、free和match指针: 实现多态 ,链表节点listNode使用 万能指针void * 保存节点的值,而表头list使用dup、free和match指针来 针对链表中存放的不同对象从而实现不同的方法。
3. 链表结构源码剖析
3.1 adlist.h文件
针对 list结构和listNode结构的赋值和查询操作使用宏进行封装 ,而且一下操作的 复杂度均为O(1) 。
#define listLength(l) ((l)->len) //返回链表l节点数量
#define listFirst(l) ((l)->head) //返回链表l的头结点地址
#define listLast(l) ((l)->tail) //返回链表l的尾结点地址
#define listPrevNode(n) ((n)->prev) //返回节点n的前驱节点地址
#define listNextNode(n) ((n)->next) //返回节点n的后继节点地址
#define listNodeValue(n) ((n)->value) //返回节点n的节点值
#define listSetDupMethod(l,m) ((l)->dup = (m)) //设置链表l的复制函数为m方法
#define listSetFreeMethod(l,m) ((l)->free = (m)) //设置链表l的释放函数为m方法
#define listSetMatchMethod(l,m) ((l)->match = (m)) //设置链表l的比较函数为m方法
#define listGetDupMethod(l) ((l)->dup) //返回链表l的赋值函数
#define listGetFree(l) ((l)->free) //返回链表l的释放函数
#define listGetMatchMethod(l) ((l)->match) //返回链表l的比较函数
链表操作的函数原型(Prototypes):
list *listCreate(void); //创建一个表头
void listRelease(list *list); //释放list表头和链表
list *listAddNodeHead(list *list, void *value); //将value添加到list链表的头部
list *listAddNodeTail(list *list, void *value); //将value添加到list链表的尾部
list *listInsertNode(list *list, listNode *old_node, void *value, int after);//在list中,根据after在old_node节点前后插入值为value的节点。
void listDelNode(list *list, listNode *node); //从list删除node节点
listIter *listGetIterator(list *list, int direction); //为list创建一个迭代器iterator
listNode *listNext(listIter *iter); //返回迭代器iter指向的当前节点并更新iter
void listReleaseIterator(listIter *iter); //释放iter迭代器
list *listDup(list *orig); //拷贝表头为orig的链表并返回
listNode *listSearchKey(list *list, void *key); //在list中查找value为key的节点并返回
listNode *listIndex(list *list, long index); //返回下标为index的节点地址
void listRewind(list *list, listIter *li); //将迭代器li重置为list的头结点并且设置为正向迭代
void listRewindTail(list *list, listIter *li); //将迭代器li重置为list的尾结点并且设置为反向迭代
void listRotate(list *list); //将尾节点插到头结点
3.2 链表迭代器
在adlist.h文件中,使用C语言实现了迭代器,源码如下:
typedef struct listIter {
listNode *next; //迭代器当前指向的节点(名字叫next有点迷惑)
int direction; //迭代方向,可以取以下两个值:AL_START_HEAD和AL_START_TAIL
} listIter
#define AL_START_HEAD 0 //正向迭代:从表头向表尾进行迭代
#define AL_START_TAIL 1 //反向迭代:从表尾到表头进行迭代
在listDup函数中就使用了迭代器,listDup函数的定义如下:
//listDup的功能是拷贝一份链表
list *listDup(list *orig)
{
list *copy;
listIter *iter;
listNode *node;
if ((copy = listCreate()) == NULL) //创建一个表头
return NULL;
//设置新建表头的处理函数
copy->dup = orig->dup;
copy->free = orig->free;
copy->match = orig->match;
//迭代整个orig的链表,重点关注此部分。
iter = listGetIterator(orig, AL_START_HEAD);//为orig定义一个迭代器并设置迭代方向,在c++中例如是 vector<int>::interator it;
while((node = listNext(iter)) != NULL) { //迭代器根据迭代方向不停迭代,相当于++it
void *value;
//复制节点值到新节点
if (copy->dup) { //如果定义了list结构中的dup指针,则使用该方法拷贝节点值。
value = copy->dup(node->value);
if (value == NULL) {
listRelease(copy);
listReleaseIterator(iter);
return NULL;
}
} else
value = node->value; //获得当前node的value值
if (listAddNodeTail(copy, value) == NULL) { //将node节点尾插到copy表头的链表中
listRelease(copy);
listReleaseIterator(iter);
return NULL;
}
}
listReleaseIterator(iter); //自行释放迭代器
return copy; //返回拷贝副本
}
迭代器的好处:
- 提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示。
- 将指针操作进行了统一封装,代码可读性增强。
3.3 adlist.c文件
刚才所有函数的定义如下:
list *listCreate(void) //创建一个表头
{
struct list *list;
//为表头分配内存
if ((list = zmalloc(sizeof(*list))) == NULL)
return NULL;
//初始化表头
list->head = list->tail = NULL;
list->len = 0;
list->dup = NULL;
list->free = NULL;
list->match = NULL;
return list; //返回表头
}
/* Free the whole list.
*
* This function can't fail. */
void listRelease(list *list) //释放list表头和链表
{
unsigned long len;
listNode *current, *next;
current = list->head; //备份头节点地址
len = list->len; //备份链表元素个数,使用备份操作防止更改原有信息
while(len--) { //遍历链表
next = current->next;
if (list->free) list->free(current->value); //如果设置了list结构的释放函数,则调用该函数释放节点值
zfree(current);
current = next;
}
zfree(list); //最后释放表头
}
/* Add a new node to the list, to head, containing the specified 'value'
* pointer as value.
*
* On error, NULL is returned and no operation is performed (i.e. the
* list remains unaltered).
* On success the 'list' pointer you pass to the function is returned. */
list *listAddNodeHead(list *list, void *value) //将value添加到list链表的头部
{
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL) //为新节点分配空间
return NULL;
node->value = value; //设置node的value值
if (list->len == 0) { //将node头插到空链表
list->head = list->tail = node;
node->prev = node->next = NULL;
} else { //将node头插到非空链表
node->prev = NULL;
node->next = list->head;
list->head->prev = node;
list->head = node;
}
list->len++; //链表元素计数器加1
return list;
}
/* Add a new node to the list, to tail, containing the specified 'value'
* pointer as value.
*
* On error, NULL is returned and no operation is performed (i.e. the
* list remains unaltered).
* On success the 'list' pointer you pass to the function is returned. */
list *listAddNodeTail(list *list, void *value) //将value添加到list链表的尾部
{
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL) //为新节点分配空间
return NULL;
node->value = value; //设置node的value值
if (list->len == 0) { //将node尾插到空链表
list->head = list->tail = node;
node->prev = node->next = NULL;
} else { //将node头插到非空链表
node->prev = list->tail;
node->next = NULL;
list->tail->next = node;
list->tail = node;
}
list->len++; //更新链表节点计数器
return list;
}
list *listInsertNode(list *list, listNode *old_node, void *value, int after) //在list中,根据after在old_node节点前后插入值为value的节点。
{
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL) //为新节点分配空间
return NULL;
node->value = value; //设置node的value值
if (after) { //after 非零,则将节点插入到old_node的后面
node->prev = old_node;
node->next = old_node->next;
if (list->tail == old_node) { //目标节点如果是链表的尾节点,更新list的tail指针
list->tail = node;
}
} else { //after 为零,则将节点插入到old_node的前面
node->next = old_node;
node->prev = old_node->prev;
if (list->head == old_node) { //如果节点如果是链表的头节点,更新list的head指针
list->head = node;
}
}
if (node->prev != NULL) { //如果有,则更新node的前驱节点的指针
node->prev->next = node;
}
if (node->next != NULL) { //如果有,则更新node的后继节点的指针
node->next->prev = node;
}
list->len++; //更新链表节点计数器
return list;
}
/* Remove the specified node from the specified list.
* It's up to the caller to free the private value of the node.
*
* This function can't fail. */
void listDelNode(list *list, listNode *node) //从list删除node节点
{
if (node->prev) //更新node的前驱节点的指针
node->prev->next = node->next;
else
list->head = node->next;
if (node->next) //更新node的后继节点的指针
node->next->prev = node->prev;
else
list->tail = node->prev;
if (list->free) list->free(node->value); //如果设置了list结构的释放函数,则调用该函数释放节点值
zfree(node); //释放节点
list->len--; //更新链表节点计数器
}
/* Returns a list iterator 'iter'. After the initialization every
* call to listNext() will return the next element of the list.
*
* This function can't fail. */
listIter *listGetIterator(list *list, int direction) //为list创建一个迭代器iterator
{
listIter *iter;
if ((iter = zmalloc(sizeof(*iter))) == NULL) return NULL; //为迭代器申请空间
if (direction == AL_START_HEAD) //设置迭代指针的起始位置
iter->next = list->head;
else
iter->next = list->tail;
iter->direction = direction; //设置迭代方向
return iter;
}
/* Release the iterator memory */
void listReleaseIterator(listIter *iter) { //释放iter迭代器
zfree(iter);
}
/* Create an iterator in the list private iterator structure */
void listRewind(list *list, listIter *li) { //将迭代器li重置为list的头结点并且设置为正向迭代
li->next = list->head; //设置迭代指针的起始位置
li->direction = AL_START_HEAD; //设置迭代方向从头到尾
}
void listRewindTail(list *list, listIter *li) { //将迭代器li重置为list的尾结点并且设置为反向迭代
li->next = list->tail; //设置迭代指针的起始位置
li->direction = AL_START_TAIL; //设置迭代方向从尾到头
}
/* Return the next element of an iterator.
* It's valid to remove the currently returned element using
* listDelNode(), but not to remove other elements.
*
* The function returns a pointer to the next element of the list,
* or NULL if there are no more elements, so the classical usage patter
* is:
*
* iter = listGetIterator(list,<direction>);
* while ((node = listNext(iter)) != NULL) {
* doSomethingWith(listNodeValue(node));
* }
*
* */
listNode *listNext(listIter *iter) //返回迭代器iter指向的当前节点并更新iter
{
listNode *current = iter->next; //备份当前迭代器指向的节点
if (current != NULL) {
if (iter->direction == AL_START_HEAD) //根据迭代方向更新迭代指针
iter->next = current->next;
else
iter->next = current->prev;
}
return current; //返回备份的当前节点地址
}
/* Duplicate the whole list. On out of memory NULL is returned.
* On success a copy of the original list is returned.
*
* The 'Dup' method set with listSetDupMethod() function is used
* to copy the node value. Otherwise the same pointer value of
* the original node is used as value of the copied node.
*
* The original list both on success or error is never modified. */
list *listDup(list *orig) //拷贝表头为orig的链表并返回
{
list *copy;
listIter *iter;
listNode *node;
if ((copy = listCreate()) == NULL) //创建一个表头
return NULL;
//设置新建表头的处理函数
copy->dup = orig->dup;
copy->free = orig->free;
copy->match = orig->match;
//迭代整个orig的链表
iter = listGetIterator(orig, AL_START_HEAD); //为orig定义一个迭代器并设置迭代方向
while((node = listNext(iter)) != NULL) { //迭代器根据迭代方向不停迭代
void *value;
//复制节点值到新节点
if (copy->dup) {
value = copy->dup(node->value); //如果定义了list结构中的dup指针,则使用该方法拷贝节点值。
if (value == NULL) {
listRelease(copy);
listReleaseIterator(iter);
return NULL;
}
} else
value = node->value; //获得当前node的value值
if (listAddNodeTail(copy, value) == NULL) { //将node节点尾插到copy表头的链表中
listRelease(copy);
listReleaseIterator(iter);
return NULL;
}
}
listReleaseIterator(iter); //自行释放迭代器
return copy; //返回拷贝副本
}
/* Search the list for a node matching a given key.
* The match is performed using the 'match' method
* set with listSetMatchMethod(). If no 'match' method
* is set, the 'value' pointer of every node is directly
* compared with the 'key' pointer.
*
* On success the first matching node pointer is returned
* (search starts from head). If no matching node exists
* NULL is returned. */
listNode *listSearchKey(list *list, void *key) //在list中查找value为key的节点并返回
{
listIter *iter;
listNode *node;
iter = listGetIterator(list, AL_START_HEAD); //创建迭代器
while((node = listNext(iter)) != NULL) { //迭代整个链表
if (list->match) { //如果设置list结构中的match方法,则用该方法比较
if (list->match(node->value, key)) {
listReleaseIterator(iter); //如果找到,释放迭代器返回node地址
return node;
}
} else {
if (key == node->value) {
listReleaseIterator(iter);
return node;
}
}
}
listReleaseIterator(iter); //释放迭代器
return NULL;
}
/* Return the element at the specified zero-based index
* where 0 is the head, 1 is the element next to head
* and so on. Negative integers are used in order to count
* from the tail, -1 is the last element, -2 the penultimate
* and so on. If the index is out of range NULL is returned. */
listNode *listIndex(list *list, long index) { //返回下标为index的节点地址
listNode *n;
if (index < 0) {
index = (-index)-1; //如果下标为负数,从链表尾部开始
n = list->tail;
while(index-- && n) n = n->prev;
} else {
n = list->head; //如果下标为正数,从链表头部开始
while(index-- && n) n = n->next;
}
return n;
}
/* Rotate the list removing the tail node and inserting it to the head. */
void listRotate(list *list) { //将尾节点插到头结点
listNode *tail = list->tail;
if (listLength(list) <= 1) return; //只有一个节点或空链表直接返回
/* Detach current tail */
list->tail = tail->prev; //取出尾节点,更新list的tail指针
list->tail->next = NULL;
/* Move it as head */
list->head->prev = tail; //将节点插到表头,更新list的head指针
tail->prev = NULL;
tail->next = list->head;
list->head = tail;
}
参考书籍:《Redis设计与实现》——黄健宏
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
