FixedLengthFrameDecoder
这个比较简单,固定长度解码,只要到了这个长度,就切片这个长度的缓冲区当做一个消息。
public class FixedLengthFrameDecoder extends ByteToMessageDecoder {
private final int frameLength;//固定一帧的长度
public FixedLengthFrameDecoder(int frameLength) {
checkPositive(frameLength, "frameLength");
this.frameLength = frameLength;
}
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
Object decoded = decode(ctx, in);
if (decoded != null) {
out.add(decoded);
}
}
protected Object decode(
@SuppressWarnings("UnusedParameters") ChannelHandlerContext ctx, ByteBuf in) throws Exception {
if (in.readableBytes() < frameLength) {//如果可读字节的小于固定长度,什么都不做
return null;
} else {
return in.readRetainedSlice(frameLength);//返回的是切片,会增加in引用计数,防止被回收了
}
}
}
LineBasedFrameDecoder
这个是换行符"\r\n"或者"\n"的分割,比前面那个稍微复杂点,因为还涉及到是否要分隔符,没读到分隔符要丢弃已读的数据,就算后面读到了分隔符,但是是属于前面丢弃的后半部分,所以也不要了。光说比较难懂,后面会画图解释的,先看一些属性,了解下可能会用的到。
属性
都有注释了,下面会结合方法说的。
private final boolean failFast;//超过长度是否马上抛出异常,无论是不是把数据全读完了,true超过就抛,false读完整个数据后抛
private final boolean stripDelimiter;//解码后的数据是否要去除分割符
private boolean discarding;//是否正在丢弃输入数据
private int discardedBytes;//丢弃的数据长度
/** Last scan position. */
private int offset;//最后一次扫描的索引位置
构造方法
一般就是传一个最大长度,其他默认就好。
public LineBasedFrameDecoder(final int maxLength) {
this(maxLength, true, false);
}
public LineBasedFrameDecoder(final int maxLength, final boolean stripDelimiter, final boolean failFast) {
this.maxLength = maxLength;
this.failFast = failFast;
this.stripDelimiter = stripDelimiter;
}
解码方法
//跟固定长度的那个一样
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
Object decoded = decode(ctx, in);
if (decoded != null) {
out.add(decoded);
}
}
decode内部方法
这个就有点复杂了,其实也还好啦就是4中情况。
- 上一次没有丢弃可读数据过的。如果找到分割符了,如果长度没超出,就根据是否要略过分隔符返回相应长度的切片,如果超出了就设置读索到分隔符之后并抛出异常。
- 上一次没有丢弃可读数据过的。如果没找到分隔符,长度又超过了最大长度就丢弃,设置丢弃数量,设置读索引到最后。根据需求抛出异常。
- 上一次有丢弃可读数据过的。如果找到分割符了,不处理,直接设置读索引到分隔符之后,因为这个是上一次丢弃的那部分所属的同一个消息的,都不要了。
- 上一次有丢弃可读数据过的。如果没有找到分割符了,继续丢弃,直接略过可读的数据。
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception {
final int eol = findEndOfLine(buffer);
if (!discarding) {//没有丢弃过可读的
if (eol >= 0) {//找到分割符了
final ByteBuf frame;
final int length = eol - buffer.readerIndex();//
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;//如果是'\r',分割符是2个字节'\r\n',否则是一个'\n'
if (length > maxLength) {//可读数据超过最大长度了,直接不要了
buffer.readerIndex(eol + delimLength);//设置读索引为分隔符索引之后
fail(ctx, length);//直接抛异常
return null;
}
if (stripDelimiter) {//如果略过分隔符的
frame = buffer.readRetainedSlice(length);//获取长度为length的切片
buffer.skipBytes(delimLength);//buffer略过分隔符
} else {
frame = buffer.readRetainedSlice(length + delimLength);//包括分隔符在内的切片
}
return frame;
} else {//没找到分割符,不会读取,不改变读索引
final int length = buffer.readableBytes();
if (length > maxLength) {//超过最大长度,也没找到分隔符
discardedBytes = length;//丢弃可读的
buffer.readerIndex(buffer.writerIndex());//直接略过可读的,设置为不可读
discarding = true;//有丢弃了
offset = 0;
if (failFast) {
fail(ctx, "over " + discardedBytes);
}
}
return null;
}
} else {
if (eol >= 0) {//前面有丢弃的话,后面跟着的也不要了
final int length = discardedBytes + eol - buffer.readerIndex();
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
buffer.readerIndex(eol + delimLength);//直接略过前面的一部分了
discardedBytes = 0;
discarding = false;
if (!failFast) {
fail(ctx, length);
}
} else {//还是没找到分隔符
discardedBytes += buffer.readableBytes();//增加丢弃数量
buffer.readerIndex(buffer.writerIndex());//直接略过可读的,设置为不可读
// We skip everything in the buffer, we need to set the offset to 0 again.
offset = 0;
}
return null;
}
}
findEndOfLine寻找换行分隔符的位置
可能是换行符"\r\n"或者"\n",所以位置会相差1,如果找到了索引offset 就从0开始,否则就从上一次长度的最后开始。
private int findEndOfLine(final ByteBuf buffer) {
int totalLength = buffer.readableBytes();
int i = buffer.forEachByte(buffer.readerIndex() + offset, totalLength - offset, ByteProcessor.FIND_LF);
if (i >= 0) {//找到了换行符
offset = 0;
if (i > 0 && buffer.getByte(i - 1) == '\r') {//如果索引不是0,且前一个是'\r',就返回前一个的索引
i--;
}
} else {
offset = totalLength;
}
return i;
}
fail抛出异常
private void fail(final ChannelHandlerContext ctx, int length) {
fail(ctx, String.valueOf(length));
}
//超出长度报异常
private void fail(final ChannelHandlerContext ctx, String length) {
ctx.fireExceptionCaught(
new TooLongFrameException(
"frame length (" + length + ") exceeds the allowed maximum (" + maxLength + ')'));
}
图示举例
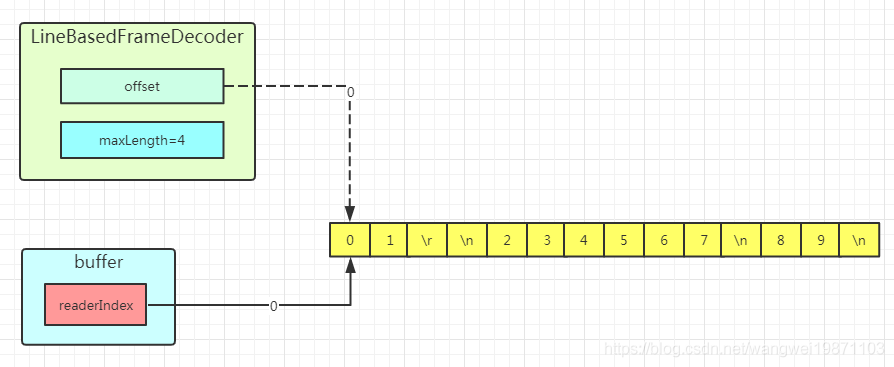
我还是来画图示意一下情况吧,黄色是我们要读取的数据,绿色的是被解码出的消息数据,我们设置编码器可以解码的最大长度是4,其他参数默认。
初始状态:
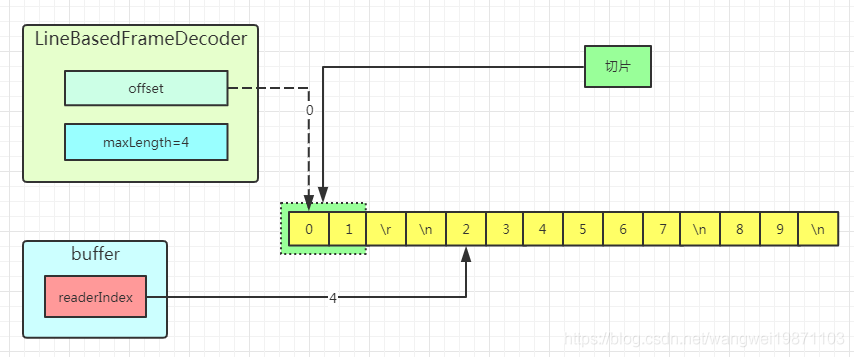
第一次读取,返回绿色的切片:
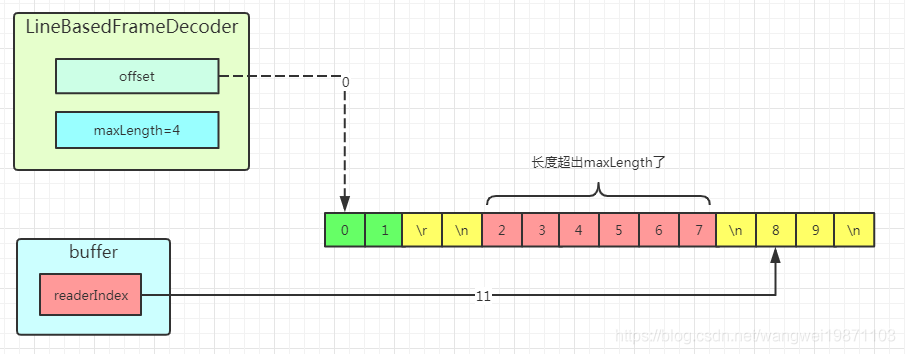
第二次读取的数据长度超出最大长度4了:
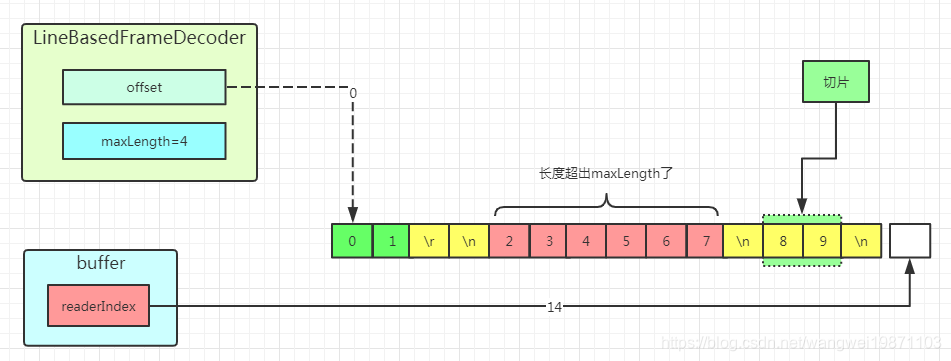
第三次读取最后两个,返回绿色切片:
分几个包的的情况
首先第一次接收"01",因为没遇到换行符,所以offset=2,返回null:
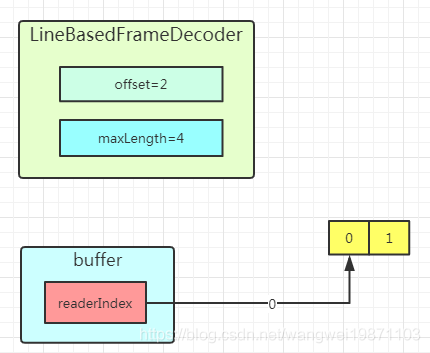
第二次接收"23\n2",返回绿色的切片:

分包丢弃的情况
第一次是这样,因为个数超过最大长度,所以会被丢弃,缓冲区也会被释放。
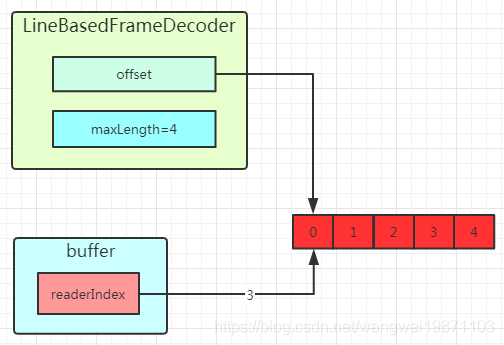
第二次收到后,发现是前面丢弃的另一部分,所以一起丢弃。
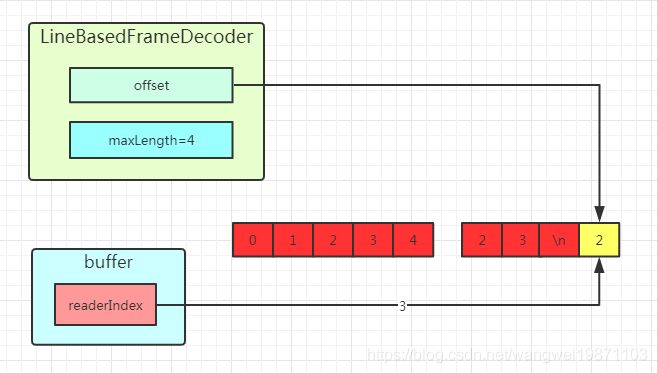
图可能也画的不是很好,还是结合代码分析吧。简单的就是说,如果第一次没找到换行符,而且可读长度超过最大长度了,后面无论多少数据,直到遇到换行符后,所有的数据都丢弃。只有在最大长度范围内,且有找到换行符的,才能拼起来返回切片。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
