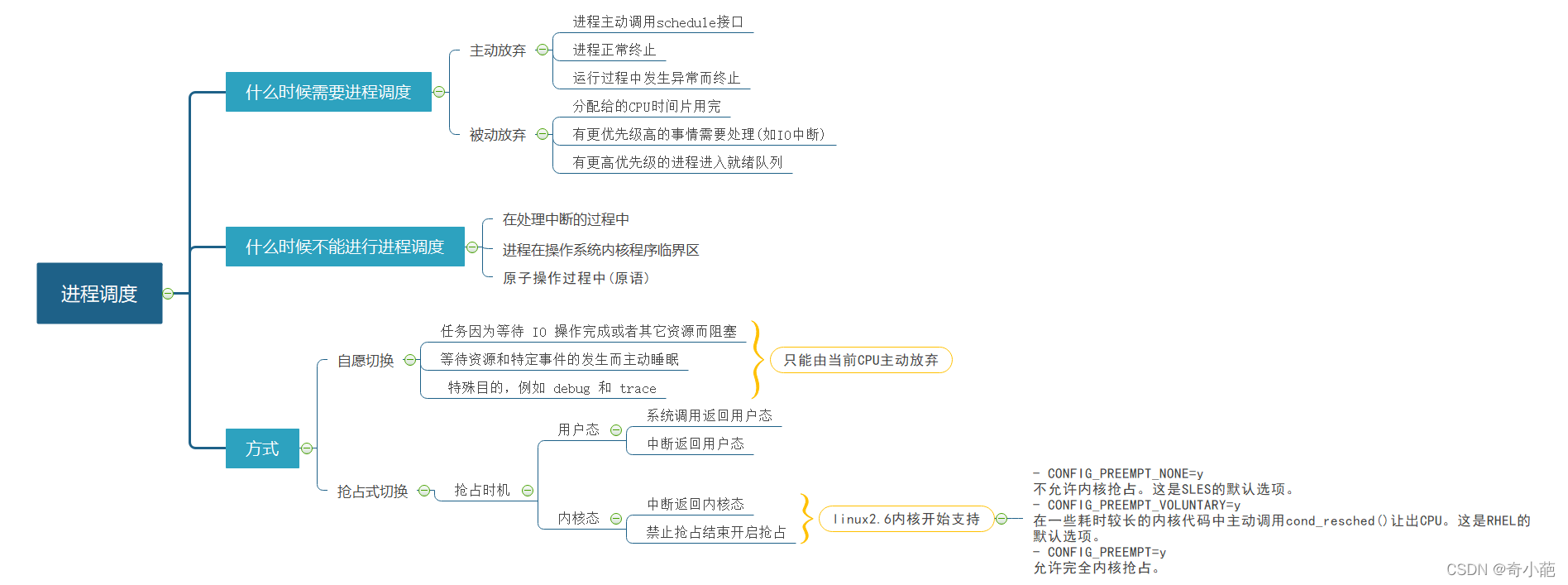
上一章学习了调度的方式,分为主调度器和周期性调度器,明白了进程切换分为自愿(voluntary)和强制(involuntary)两种。
-
自愿切换: 是指任务由于等待某种资源,将state改为非running状态后,主动调用schedule让出CPU
-
任务因为等待 IO 操作完成或者其它资源而阻塞。
任务显式地调用 schedule 前,把任务运行态设置成
TASK_UNINTERRUPTIBLE。保证任务阻塞后不能因信号到来而引起睡眠过程的中断,从而被唤醒。 Linux 内核各种同步互斥原语,如 Mutex,Semaphore,wait_queue,R/W Semaphore,及其他各种引起阻塞的内核函数。 -
等待资源和特定事件的发生而主动睡眠。
任务显式地调用 schedule 前,把任务运行态被设为
TASK_INTERRUPTIBLE。保证即使等待条件不满足也可以被任务接收到的信号所唤醒,重新进入运行态。 Linux 内核各种同步互斥原语,如 Mutex,Semaphore,wait_queue,及其它各种引起睡眠的内核函数。 -
特殊目的,例如 debug 和 trace。
任务在显式地用 schedule 函数前,利用 set_current_state 将任务设置成 非 TASK_RUNNING 状态 。 例如,设置成 TASK_STOPPED 状态,然后调用 schedule 函数。
-
-
强制切换: 任务装仍为running状态,但是失去CPU使用权,此时由于任务时间片用完、有更高优先级的任务、任务中调用了cond_resched()或者yield让出了CPU使用权
本章的主要学习的内容如下:
- 内核自愿切换的主要场景有哪些,具体的流程如何
- 内核强制切换的主要场景有哪些,具体的流程如何
1 主动调度时机
通常情况下,我们的进程运行在用户空间,无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,例如内核在等待资源的时候,将当前进程移到等待队列,并主动调用schedule()放弃CPU。
主动调度时机是指显式调用schedule()函数释放CPU,引起新一轮调度.一般发生在当前进程状态改变,如:进程终止、进程睡眠、进程对某些信号处理过程中等.
1.1 用户空间调用调度接口
通常情况下,我们的进程运行在用户空间,通过系统调用进入到内核空间,从而做一些更**高级**的事情。yield 系统调用主要是调用yield_task的接口,然后调度schedule让当前进程放弃 cpu,其接口 (kernel/sched/core.c)如下
SYSCALL_DEFINE0(sched_yield)
{
struct rq *rq = this_rq_lock();
schedstat_inc(rq->yld_count);
current->sched_class->yield_task(rq);
/*
* Since we are going to call schedule() anyway, there's
* no need to preempt or enable interrupts:
*/
__release(rq->lock);
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
do_raw_spin_unlock(&rq->lock);
sched_preempt_enable_no_resched();
schedule();
return 0;
}
pause 系统调用首先将当前进程设置为 TASK_INTERRUPTIBLE 状态,其实就是给 task_struct 结构中的 state 字段赋值,附上 TASK_INTERRUPTIBLE 之后,在后续进程调度中就可以过滤掉这个进程,选择其他的进程进行调度。接着,同样是一个简单的 schedule 函数,进入到调度,其接口(kernel/signal.c)如下:
SYSCALL_DEFINE0(pause)
{
while (!signal_pending(current)) {
__set_current_state(TASK_INTERRUPTIBLE);
schedule();
}
return -ERESTARTNOHAND;
}
futex (fast userspace mutex),用来给上层应用构建更高级别的同步机制,是实现信号量和锁的基础。我们简化一下场景:一个进程在等待某个信号的时候,最终会通过系统调用进入到 futex。其kernel/futex.c接口如下
SYSCALL_DEFINE6(futex, u32 __user *, uaddr, int, op, u32, val,
struct timespec __user *, utime, u32 __user *, uaddr2,
u32, val3)
{
...
return do_futex(uaddr, op, val, tp, uaddr2, val2, val3);
}
这个系统调用有 6 个参数,参数类型和名称并列展开,上层应用在等待一个信号量的时候,给 op 这个参数的传递的是 FUTEX_WAIT_BITSET ,我们通过调用链往下追
long do_futex(u32 __user *uaddr, int op, u32 val, ktime_t *timeout,
u32 __user *uaddr2, u32 val2, u32 val3)
{
...
switch (cmd) {
case FUTEX_WAIT:
val3 = FUTEX_BITSET_MATCH_ANY;
case FUTEX_WAIT_BITSET:
return futex_wait(uaddr, flags, val, timeout, val3);
...
}
...
}
改接口最终会调用 futex_wait_queue_me 可能会将自己设置为睡眠状态并且进行一次进程调度。
1.2 exit 进程退出
在一个进程退出的时候会触发进程调度,我们通过内核源码来证明这一点。应用层的进程在退出时,最终会通过 exit 系统调用进入到内核,调用如下(kernel/exit.c):
SYSCALL_DEFINE1(exit, int, error_code)
{
do_exit((error_code&0xff)<<8);
}
其最终会调用do_task_dead,最终将进程的state置位TASK_DEAD,然后调用__schedule,其实现如下
void __noreturn do_task_dead(void)
{
/*
* The setting of TASK_RUNNING by try_to_wake_up() may be delayed
* when the following two conditions become true.
* - There is race condition of mmap_sem (It is acquired by
* exit_mm()), and
* - SMI occurs before setting TASK_RUNINNG.
* (or hypervisor of virtual machine switches to other guest)
* As a result, we may become TASK_RUNNING after becoming TASK_DEAD
*
* To avoid it, we have to wait for releasing tsk->pi_lock which
* is held by try_to_wake_up()
*/
smp_mb();
raw_spin_unlock_wait(¤t->pi_lock);
/* causes final put_task_struct in finish_task_switch(). */
__set_current_state(TASK_DEAD);
current->flags |= PF_NOFREEZE; /* tell freezer to ignore us */
__schedule(false);
BUG();
/* Avoid "noreturn function does return". */
for (;;)
cpu_relax(); /* For when BUG is null */
}
1.3 内核主动阻塞
进程陷入内核后的自愿放弃行为是不可见的,它隐藏在其他可能受阻的系统调用,比如open、read、write等。进程因这些系统调用而陷入内核,如果这些调用被阻塞,总不能让CPU阻塞在这里啥都不干吧,于是内核就替进程做主,自愿放弃CPU启动一次调度。
2 抢占调度时机
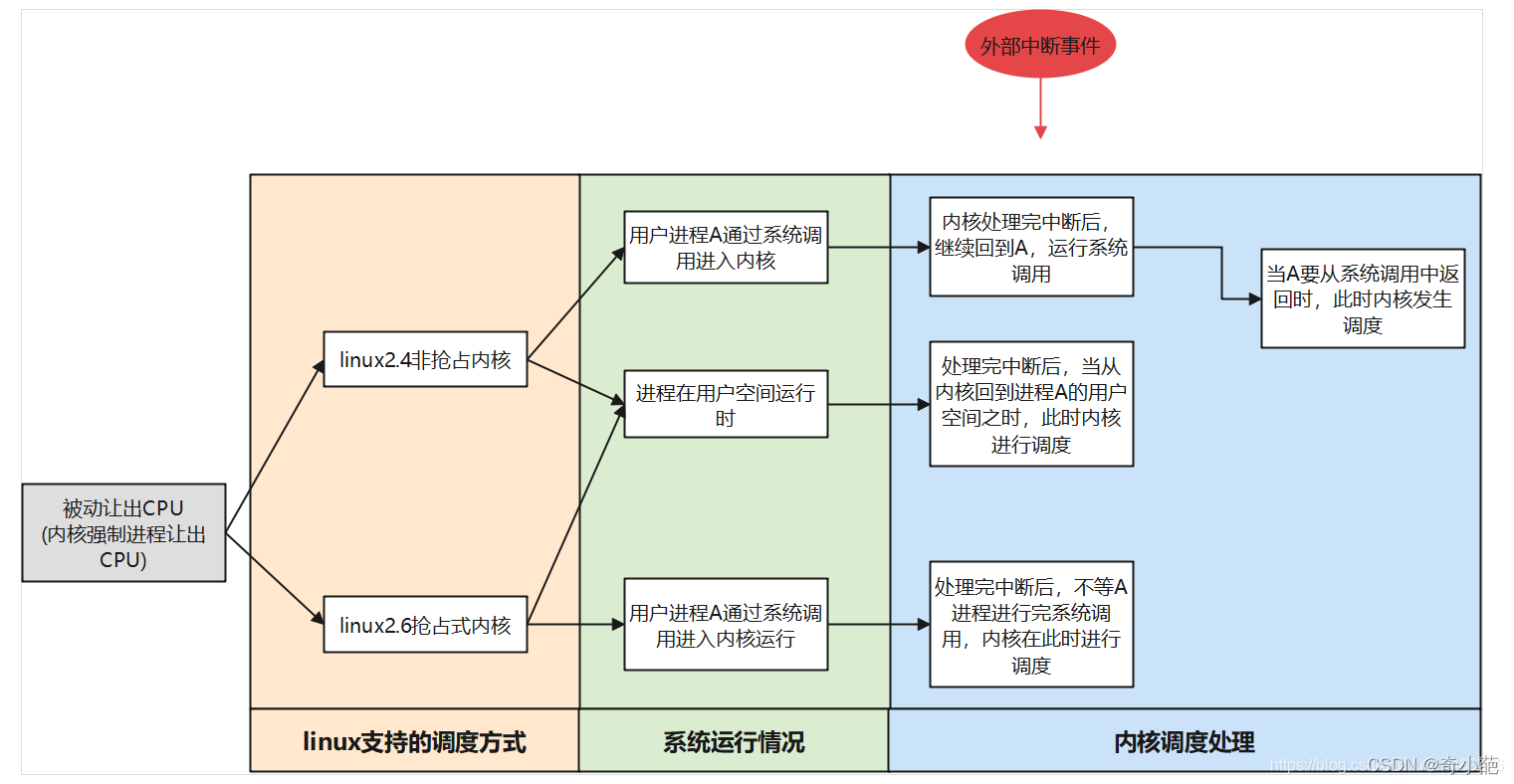
被动调度时间指不显示调用schedule()函数,只是PCB中的 need_resched 进程调度标志,该域置位为1将引起新的进程调度,而每当中断处理和系统调用返回时,核心调度程序都会主动查need_resched的状态(若置位,则主动调用 schedule ()函数。一般发生在新的进程产生时、某个进程优先级改变时、某个进程等待的资源可用被唤醒时、当前进程时间片用完等。
2.1 中断异常返回时调度
介绍中断之前,先描述一下什么是异常:进程的指令按照程序正常流程一直在 CPU 上跑,系统突然发生了一个带有异常号的异常,强迫 CPU 停止执行当前的指令,CPU 随后会在执行完当前指令之后,保存现场,根据异常号跳转到异常处理程序,处理完之后,回到被异常终止的下一条机器指令继续执行。
系统调用是常见一种类型的异常,也是应用代码从用户空间主动进入内核空间的唯一方式。另外一种常见的异常就是硬件中断,比如我们点下鼠标、按下键盘、网卡接收到数据、磁盘数据读写完毕等,都会触发一次硬件中断,运行在用户空间的进程会被动陷入到内核空间,进行中断处理程序的处理。armv8中断、系统调用的入口在arch/arm64/kernel/entry.S,实现的函数有el1_sync,el1_irq,el0_sync,el0_irq。其余都是invalid。
- el1_sync:当前处于内核态时,发生了指令执行异常、缺页中断(跳转地址或者取地址)。
- el1_irq:当前处于内核态时,发生硬件中断。
- el0_sync:当前处于用户态时,发生了指令执行异常、缺页中断(跳转地址或者取地址)、系统调用。
- el0_iqr:当前处于用户态时,发生了硬件中断。
2.1.1 中断异常内核空间抢占调度
当中断发生在内核态,中断el1_irq退出前,即irq handler之后,kernel_exit恢复现场之间。会去检查current进程的preempt_count和need_resched以判断是否需要进行一次抢占。
el1_irq:
kernel_entry 1
enable_dbg
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_off
#endif
irq_handler
#ifdef CONFIG_PREEMPT
ldr w24, [tsk, #TI_PREEMPT] // get preempt count
cbnz w24, 1f // preempt count != 0
ldr x0, [tsk, #TI_FLAGS] // get flags
tbz x0, #TIF_NEED_RESCHED, 1f // needs rescheduling?
bl el1_preempt
1:
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_on
#endif
kernel_exit 1
ENDPROC(el1_irq)
如果内核开启了CONFIG_PREEMPT,抢占前的检查:preempt_count和need_resched,设置need_resched的地方,同时也会设置TIF_NEED_RESCHED,所以这里检查need_resched即可,如果设置了,就跳转到el1_preempt尝试抢占
#ifdef CONFIG_PREEMPT
el1_preempt:
mov x24, lr
1: bl preempt_schedule_irq // irq en/disable is done inside
ldr x0, [tsk, #TI_FLAGS] // get new tasks TI_FLAGS
tbnz x0, #TIF_NEED_RESCHED, 1b // needs rescheduling?
ret x24
#endif
preempt_schedule_irq中断抢占的核心函数。注意:执行到此中断仍是关闭的,所以跳转回来时中断也要是关闭的
//封装了__schedule函数,且它会保证返回时local中断仍关闭
asmlinkage __visible void __sched preempt_schedule_irq(void)
{
enum ctx_state prev_state;
/* Catch callers which need to be fixed */
//检测异常:若抢占计数不为零,或者中断没有关闭 则dump_stack并产生oops
BUG_ON(preempt_count() || !irqs_disabled());
//保存当前cpu的异常状态下的上下文到prev_state
prev_state = exception_enter();
do {
preempt_disable(); //关抢占,__schedule的过程不允许被抢占
local_irq_enable(); //使能中断
__schedule(true); //调度器核心函数。true表示此次切换为抢占
local_irq_disable(); //关闭中断
sched_preempt_enable_no_resched(); //开抢占
} while (need_resched());//如果调度出去后的进程操作了被中断进程的thread_info.flags,使它仍为TIF_NEED_SCHED,那就继续进行调度
//恢复抢占前的保存在prev_state中的异常上下文。
exception_exit(prev_state);
}
当中断发生在进程的用户态,中断程序处理完之后,势必也要返回到用户空间,在返回用户空间之前,也会做一件事情,判断是否要进行调度,如果需要,则顺便做一次进程调度。我们以arm64处理器为例,中断处理程序的入口是el0_irq,流程如下:
el0_irq:
kernel_entry 0 #将进程的寄存器值保存到内核栈中
el0_irq_naked:
enable_dbg
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_off
#endif
ct_user_exit
#ifdef CONFIG_HARDEN_BRANCH_PREDICTOR
tbz x22, #55, 1f
bl do_el0_irq_bp_hardening
1:
#endif
irq_handler #中断处理
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_on
#endif
b ret_to_user #使用内核栈保存的寄存器值恢复进程的寄存器并返回用户模式
ENDPROC(el0_irq)
该接口在中断处理irq_handler后,通过ret_to_user返回用户空间的时候会发生一次调度
ret_to_user:
disable_irq // disable interrupts
ldr x1, [tsk, #TI_FLAGS]
and x2, x1, #_TIF_WORK_MASK
cbnz x2, work_pending
finish_ret_to_user:
enable_step_tsk x1, x2
kernel_exit 0
ENDPROC(ret_to_user)
- 关中断
获取thread_info中的flags变量的值,就是task_struct结构中的thread_info结构中的flags字段的偏移量- 取出
task_struct->thread_info->flags字段,然后通过与_TIF_WORK_MASK进行 and 操作,如果二进制位的值不为 0,就跳转(cbnz)到work_pending方法。
#define_TIF_WORK_MASK (_TIF_NEED_RESCHED |_TIF_SIGPENDING | \
_TIF_NOTIFY_RESUME |_TIF_FOREIGN_FPSTATE)
进入最重要的接口do_notify_resume
/*
* Ok, we need to do extra processing, enter the slow path.
*/
work_pending:
mov x0, sp // 'regs'
bl do_notify_resume
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_on // enabled while in userspace
#endif
ldr x1, [tsk, #TI_FLAGS] // re-check for single-step
b finish_ret_to_user
参数中 thread_flags 的值就是上面保存在 x1 寄存器中的值,也就是 `task_struct->thread_info->flags,如果该flags置位_TIF_NEED_RESCHED,就进行调度
asmlinkage void do_notify_resume(struct pt_regs *regs,
unsigned int thread_flags)
{
/*
* The assembly code enters us with IRQs off, but it hasn't
* informed the tracing code of that for efficiency reasons.
* Update the trace code with the current status.
*/
trace_hardirqs_off();
do {
if (thread_flags & _TIF_NEED_RESCHED) {
schedule();
} else {
local_irq_enable();
if (thread_flags & _TIF_SIGPENDING)
do_signal(regs);
if (thread_flags & _TIF_NOTIFY_RESUME) {
clear_thread_flag(TIF_NOTIFY_RESUME);
tracehook_notify_resume(regs);
}
if (thread_flags & _TIF_FOREIGN_FPSTATE)
fpsimd_restore_current_state();
}
local_irq_disable();
thread_flags = READ_ONCE(current_thread_info()->flags);
} while (thread_flags & _TIF_WORK_MASK);
}
到此,中断返回到用户空间的调度就比较清楚了,当中断处理程序返回用户空间的时候,如果被中断的进程被设置了需要进程调度标志,那么就进行一次进程调度。
-
那么,什么时候当前进程会被设置这个标志位呢?
只有进入到内核空间才能设置当前进程需要调度标志,而系统调用是我们主动从用户空间进入到内核空间的唯一方式,那些系统调用会设置当前进程需要调度标志。
- 创建新进程
- futex 唤醒进程
- 周期调度
Linux 内核里,中断和异常因其打断的上下文不同,在返回时可能会触发以下类型的任务调度,
-
User Preemption
中断和异常打断了用户态运行的任务,在返回时检查
TIF_NEED_RESCHED标志,决定是否调用schedule。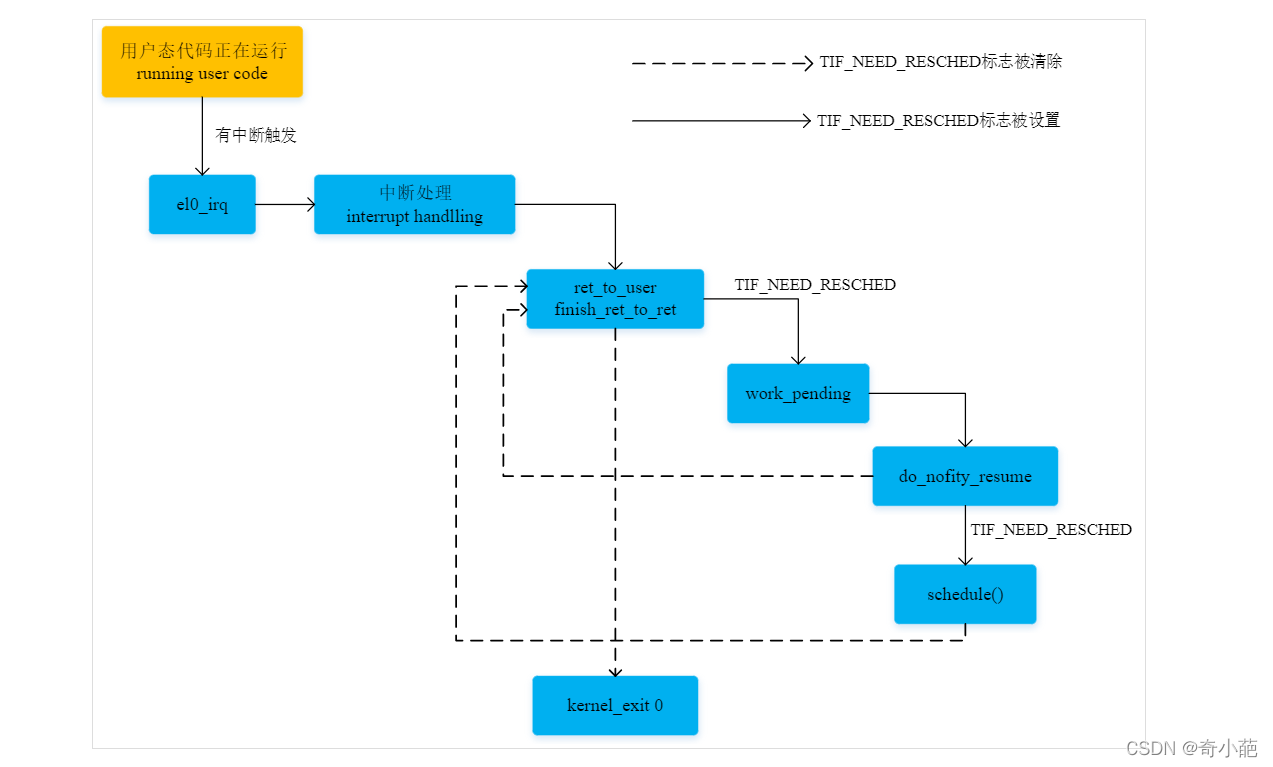
-
Kernel Preemption
中断和异常打断了内核态运行的任务,在返回时调用
preempt_schedule_irq。其代码会检查TIF_NEED_RESCHED标志,决定是否调用schedule。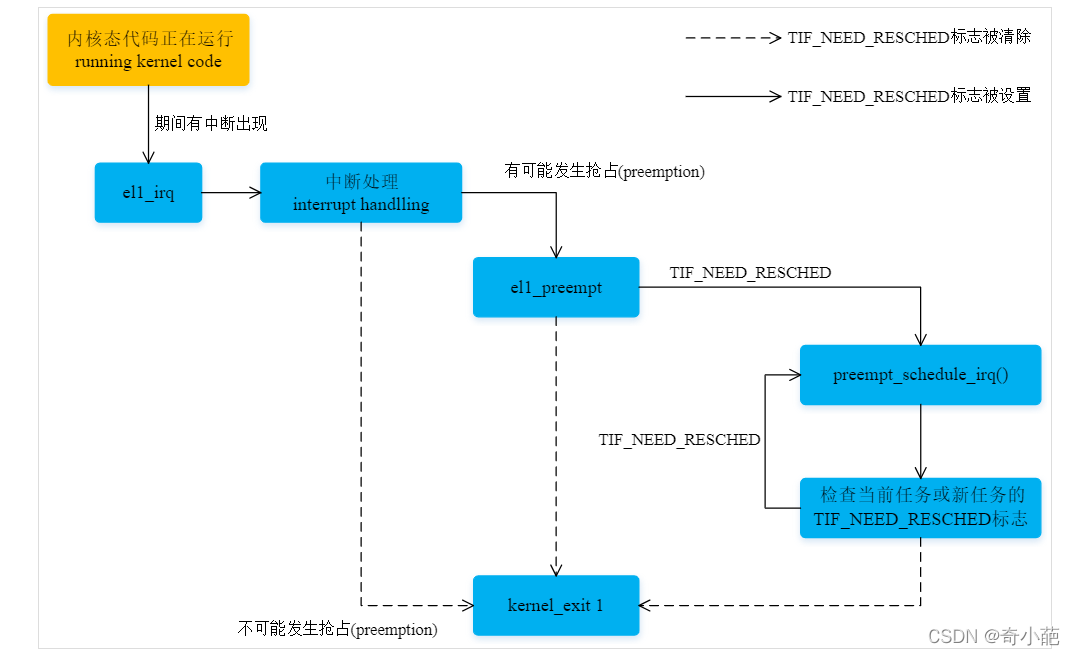
2.2 系统调用调度
当发生系统调用时,进程用户态转变成核心态,此时可能由于调度的资源需要等待资源,就会主动的调用进程切换,此时当系统调用完后,只能返回到用户态。我们来进一步查看SVC mode的处理。当系统调用时CPU会切换到SVC mode,并跳转到对应的地址去运行。kernel中会配置两个SVC Handler,分别对应这SVC_32/SVC_64两种mode,32bit程序和64bit程序执行系统调用会跳转到两个不同的handler去执行,arch/arm64/kernel/entry.S汇编代码中设置了SVC异常entry
el0_svc:
adrp stbl, sys_call_table // load syscall table pointer
uxtw scno, w8 // syscall number in w8
mov sc_nr, #__NR_syscalls
el0_svc_naked: // compat entry point
stp x0, scno, [sp, #S_ORIG_X0] // save the original x0 and syscall number
enable_dbg_and_irq
ct_user_exit 1
ldr x16, [tsk, #TI_FLAGS] // check for syscall hooks
tst x16, #_TIF_SYSCALL_WORK
b.ne __sys_trace
cmp scno, sc_nr // check upper syscall limit
b.hs ni_sys
mask_nospec64 scno, sc_nr, x19 // enforce bounds for syscall number
ldr x16, [stbl, scno, lsl #3] // address in the syscall table
blr x16 // call sys_* routine
b ret_fast_syscall
ni_sys:
mov x0, sp
bl do_ni_syscall
b ret_fast_syscall
ENDPROC(el0_svc)
这个数组在创建时首先会把所有的数组成员设置为sys_ni_syscall,而后根据**arch/arm64/include/asm/unistd32.h**中定义了所有的系统调用接口
void * const sys_call_table[__NR_syscalls] __aligned(4096) = {
[0 ... __NR_syscalls - 1] = sys_ni_syscall,
#include <asm/unistd.h>
};
我们重点关注ret_fast_syscall,其处理流程跟中断基本类似,判断条件,然后跳转到**[work_pending](https://elixir.bootlin.com/linux/v4.9.295/C/ident/work_pending)处理**
ret_fast_syscall:
disable_irq // disable interrupts
str x0, [sp, #S_X0] // returned x0
ldr x1, [tsk, #TI_FLAGS] // re-check for syscall tracing
and x2, x1, #_TIF_SYSCALL_WORK
cbnz x2, ret_fast_syscall_trace
and x2, x1, #_TIF_WORK_MASK
cbnz x2, work_pending
enable_step_tsk x1, x2
kernel_exit 0
与中断处理类似,具体系统调用函数退出后,公共系统调用代码返回用户空间时,可能会触发 User Preemption,即检查 TIF_NEED_RESCHED 标志,决定是否调用 schedule。 系统调用不会触发 Kernel Preemption,因为系统调用返回时,总是返回到用户空间,这一点与中断和异常有很大的不同。
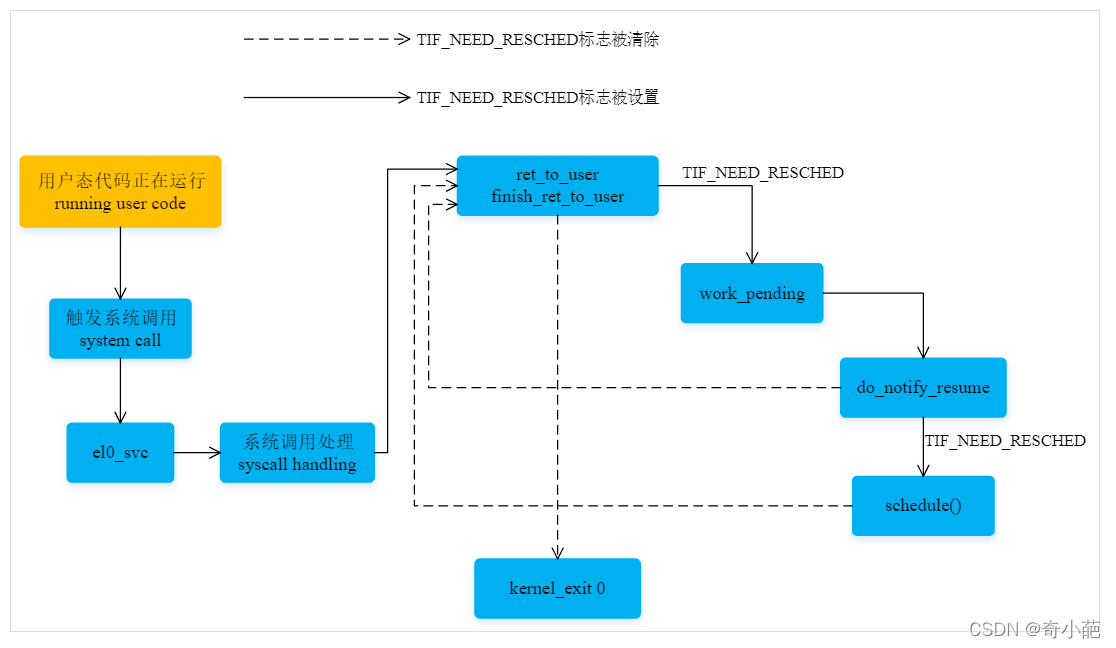
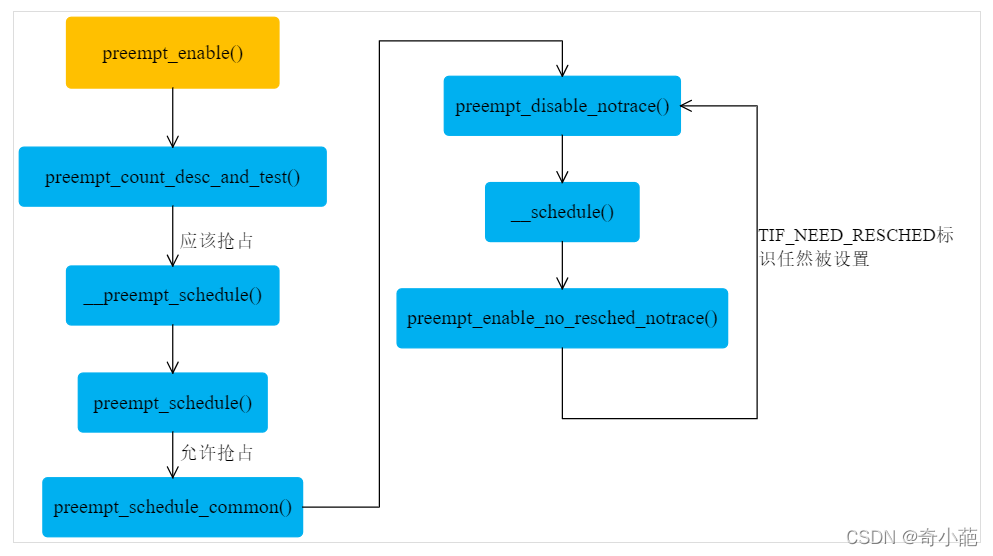
2.3 禁止内核抢占结束时
当linux2.6的内核,作为支持内核抢占,Linux 只允许在当前内核上下文需要禁止抢占的时候才使用 preempt_disable 禁止抢占,内核代码在禁止抢占后,应该尽早调用 preempt_enable 使能抢占,避免引入高调度延迟。 为尽快处理在禁止抢占期间 pending 的重新调度申请,内核在 preempt_enable 里会调用 preempt_schedule 检查 TIF_NEED_RESCHED 标志,触发任务切换
2.4 内核中调用cond_resch
内核代码中显式调用cond_resched()触发抢占,它的核心函数是preempt_schedule_common,该接口重要是在不支持内核抢占的情况下,会主动调用**[__schedule](https://elixir.bootlin.com/linux/v4.9.295/C/ident/__schedule)**
#define cond_resched() ({ \
___might_sleep(__FILE__, __LINE__, 0); \
_cond_resched(); \
})
#ifndef CONFIG_PREEMPT
int __sched _cond_resched(void)
{
if (should_resched(0)) {
preempt_schedule_common();
return 1;
}
return 0;
}
EXPORT_SYMBOL(_cond_resched);
#endif
3 触发抢占时机
抢占如果发生在进程处于用户态的时候,称为User Preemption(用户态抢占);如果发生在进程处于内核态的时候,则称为Kernel Preemption(内核态抢占)。在2.6内核的之前,只支持用户抢占,Linux在2.6版本之后就支持内核抢占了,但是请注意,具体取决于内核编译时的选项:
- CONFIG_PREEMPT_NONE=y
不允许内核抢占。这是SLES的默认选项。
- CONFIG_PREEMPT_VOLUNTARY=y
在一些耗时较长的内核代码中主动调用cond_resched()让出CPU。这是RHEL的默认选项。
- CONFIG_PREEMPT=y
允许完全内核抢占。
如果在内核态发生中断,在中断处理完后,内核会检查TIF_NEED_RESCHED标志并调用schedule()执行抢占。所以每个进程都包含一个TIF_NEED_RESCHED标志,内核根据这个标志判断该进程是否应该被抢占,设置TIF_NEED_RESCHED标志就意味着触发抢占。本小节主要关注TIF_NEED_RESCHED标志什么时候被设置呢?
3.1 周期性中断
时钟中断处理函数会调用scheduler_tick(),这是调度器核心层(scheduler core)的函数,它通过调度类(scheduling class)的task_tick方法 检查进程的时间片是否耗尽,如果耗尽则触发抢占,详细 进程管理(二十)----进程调度器
void scheduler_tick(void)
{
...
curr->sched_class->task_tick(rq, curr, 0);
...
}
在周期性的时钟中断里,内核调度器检查当前正在运行任务的持续运行时间是否超出具体调度算法支持的时间上限,从而决定是否剥夺当前任务的运行。 一旦决定剥夺在 CPU 上任务的运行,则会给正在 CPU 上运行的当前任务设置一个 请求重新调度的标志 :TIF_NEED_RESCHED。TIF_NEED_RESCHED 标志置位后,并没有立即调用 schedule 函数发生上下文切换。真正的上下文切换动作是 User Preemption 或 Kernel Preemption 的代码完成的。
User Preemption 或 Kernel Preemption 在很多代码路径上放置了检查当前任务的 TIF_NEED_RESCHED 标志,并显式调用 schedule 的逻辑。 接下来很快就会有机会调用 schedule 来触发任务切换,这时抢占就真正的完成了。上下文切换发生时,下一个被调度的任务将由具体调度器算法来决定从运行队列里挑选。
- 例如,如果时钟中断刚好打断正在用户空间运行的进程,那么当周期性中断会将
TIF_NEED_RESCHED标志位置位,随后时钟中断处理完成,并返回用户空间。此时中断返回会检查TIF_NEED_RESCHED标志位,如果置位就会调用schedule来完成上下文的切换
3.2 唤醒进程时候
当进程被唤醒的时候,如果优先级高于CPU上的当前进程,就会触发抢占。相应的内核代码中,当进程被唤醒的时候,如果优先级高于CPU上的当前进程,就会触发抢占。相应的内核代码中,当在try_to_wake_up/wake_up_process和wake_up_new_task中唤醒进程时, 内核使用全局check_preempt_curr看看是否进程可以抢占当前进程可以抢占当前运行的进程
//被唤醒进程的描述符指针(p),
//可以被唤醒的进程状态掩码(state),
// 一个标志wake_flags,用来禁止被唤醒的进程抢占本地CPU上正在运行的进程.
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
...
ttwu_queue(p, cpu, wake_flags);
stat:
ttwu_stat(p, cpu, wake_flags);
out:
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
return success;
}
ttwu_queue进程状态设置为TASK_RUNNING,并把该进程插入本地CPU运行队列rq来达到唤醒睡眠和停止的进程的目的
static inline void ttwu_activate(struct rq *rq, struct task_struct *p, int en_flags)
{
activate_task(rq, p, en_flags);
p->on_rq = TASK_ON_RQ_QUEUED;
/* if a worker is waking up, notify workqueue */
if (p->flags & PF_WQ_WORKER)
wq_worker_waking_up(p, cpu_of(rq));
}
[ttwu_do_wakeup](https://elixir.bootlin.com/linux/v4.9.295/C/ident/ttwu_do_wakeup) 然后调用 check_preempt_curr,检查当前进程是否需要被抢占,如果需要,就会设置 TIF_NEED_RESCHED 标志check_preempt_curr 的定义如下
void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags)
{
const struct sched_class *class;
if (p->sched_class == rq->curr->sched_class) {
rq->curr->sched_class->check_preempt_curr(rq, p, flags);
} else {
for_each_class(class) {
if (class == rq->curr->sched_class)
break;
if (class == p->sched_class) {
resched_curr(rq);
break;
}
}
}
/*
* A queue event has occurred, and we're going to schedule. In
* this case, we can save a useless back to back clock update.
*/
if (task_on_rq_queued(rq->curr) && test_tsk_need_resched(rq->curr))
rq_clock_skip_update(rq, true);
}
- 唤醒的进程和当前的进程同属于一个调度类,直接调用调度类的check_preempt_curr方法检查抢占条件。毕竟调度器自己管理的进程,自己最清楚是否适合抢占当前进程。
- 如果唤醒的进程和当前进程不属于一个调度类,就需要比较调度类的优先级。例如,当期进程是CFS调度类,唤醒的进程是RT调度类,自然实时进程是需要抢占当前进程的,因为优先级更高。就会调用 resched_curr 函数,它最终会设置 TIF_NEED_RESCHED 标志

3.3 新进程创建的时候
接下来,我们来分析 fork 系统调用是如何来设置进程需要调度的标识的,fork详细的过程见 进程管理(八)–创建进程fork ,创建完新进程之后,调用 wake_up_new_task 唤醒新进程,我们来看内核是如何唤醒新进程的,check_preempt_curr同样也会设置标志位,起流程如下:
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
//将当前进程设置为 RUNNING 状态,后续即可调度
raw_spin_lock_irqsave(&p->pi_lock, rf.flags);
p->state = TASK_RUNNING;
...
activate_task(rq, p, 0);
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p);
//判断是否要抢占当前进程
check_preempt_curr(rq, p, WF_FORK);
...
task_rq_unlock(rq, p, &rf);
}
3.4 进程修改nice值的时候
如果进程修改nice值导致优先级高于CPU上的当前进程,也会触发抢占resched_curr。内核代码参见 set_user_nice()
void set_user_nice(struct task_struct *p, long nice)
{
....
if (queued) {
enqueue_task(rq, p, ENQUEUE_RESTORE);
/*
* If the task increased its priority or is running and
* lowered its priority, then reschedule its CPU:
*/
if (delta < 0 || (delta > 0 && task_running(rq, p)))
resched_curr(rq);
}
if (running)
set_curr_task(rq, p);
out_unlock:
task_rq_unlock(rq, p, &rf);
}
3.5 futex 唤醒进程
除了 fork 系统调用,在 futex 系统调用的时候,也会设置需要调度的标志。,futex 的 wake 操作,最后同样会落到和 fork 一样的方法 check_preempt_curr,这个方法我们上面刚分析过,做的事情就是给当前线程设置一个需要调度的标志,在下一次中断返回时进行一次调度。
3.6 进行负载均衡的时候
在多CPU的系统上,进程调度器尽量使各个CPU之间的负载保持均衡,而负载均衡操作可能会需要触发抢占。
不同的调度类有不同的负载均衡算法,涉及的核心代码也不一样,比如CFS类在load_balance()中触发抢占:
4 总结
在不支持内核抢占的系统中,进程/线程一旦运行于内核空间,就可以一直运行,直到他主动放弃或者耗尽时间片为止,这样就会导致非常紧急的进程或线程长时间得不到运行。
为了提高Linux的实时性。在linux2.6中引入了“Kernel preemption”(内核抢占调度模式)。并很好的解决了这个问题。一句话就是抢占式内核可以在进程处于内核态时,进行抢占。
而根据进程抢占发生的时机, 抢占可以分为 内核抢占 和 用户抢占 , 内核抢占就是指一个在内核态运行的进程, 可能在执行内核函数期间被另一个进程取
用户抢占发生在以下几种情况
- 从系统调用返回用户空间;
- 从中断(异常)处理程序返回用户空间
内核抢占发生的时机,一般发生在:
- 当从中断处理程序正在执行,且返回内核空间之前。当一个中断处理例程退出,在返回到内核态时(kernel-space)。这是隐式的调用schedule()函数,当前任务没有主动放弃CPU使用权,而是被剥夺了CPU使用权。
- 当内核代码再一次具有可抢占性的时候,如解锁(spin_unlock_bh)及使能软中断(local_bh_enable)等, 此时当kernel code从不可抢占状态变为可抢占状态时(preemptible again)。也就是preempt_count从正整数变为0时。这也是隐式的调用schedule()函数
- 如果内核中的任务显式的调用schedule(), 任务主动放弃CPU使用权
- 如果内核中的任务阻塞(这同样也会导致调用schedule()), 导致需要调用schedule()函数。任务主动放弃CPU使用权
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
