对于调度器,一个很重要的是调度时机问题,在什么情况下,什么时候发生调度?也就是说在什么情况下,什么时候,把现在占用CPU的进程替换下来,根据进程生命周期的图示
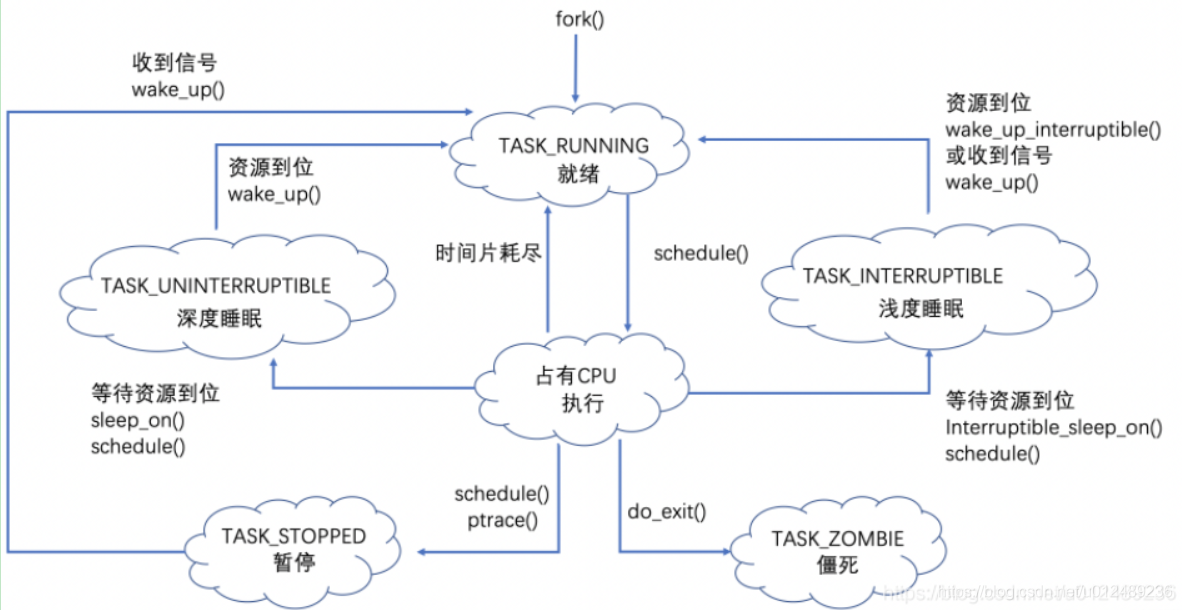
本章主要关注的是上图中schedule的调度时机,主要有两部分组成,一种是直接,比如上图中的进程等待资源的到位需要睡眠,或者处于其他的原因主动放弃CPU资源;另外一种是时间片耗尽而放弃调度,本章主要是结合源码,学习内容包括
- schedule()函数什么时候被调用
- 主调度器和周期性调度器如何工作
- 内核对于调度的各个场景是如何工作的
1. 核心调度器
进程调度分为资源和强制调度两种
- 自愿调度: 是指由于等待某种资源,将进程的状态改成非RUNNING状态后,如TASK_INTERRUPTIBLE等,就调用schedule()主动让出CPU资源
- 抢占调度: 任务状态仍为RUNNING状态,当时却失去了CPU使用权,如我们比较常见的任务时间片用完,有更高优先级的任务等需要让出CPU资源
1.1 schedule
schedule是linux调度器中最重要的一个函数,就像fork函数,它没有参数,没有返回值,却是实现内核中非常重要的功能,当需要执行调度时,直接调用schedule(),当前进程就停止了,而另外一个新进程占据了CPU,我们来学习下该接口函数做了些什么?其定义在kernel/sched/core.c中
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current; //获取当前进程
//若当前准备被切换出去的进程是io或worker线程的话,做一些特殊准备工作
sched_submit_work(tsk); //为了避免进程睡眠时发生死锁。
do {
preempt_disable(); //关闭内核抢占
__schedule(false); //完成调度的核心函数
sched_preempt_enable_no_resched(); //开启内核抢占
} while (need_resched()); //如果该进程被其他进程设置了TIF_NEED_RESCHED标志,则函数重新执行进行调度,再来一次
}
EXPORT_SYMBOL(schedule);
通过schedule()实现我们可以看出来,调用__schedule()前是需要关闭抢占的,实际上在__ schedule中会去检查当前进程的抢占计数(位于schedule_debug函数),确保此次调度是在关闭抢占的情况下进行的,且不能是在中断或原子上下文发生的调用。内核的抢占本身也是为了执行调度,现在本身就已经在调度了,如果不关抢占,递归地执行进程调度怎么看都是一件没必要的事。在调度过程完成之后,也就是 __schedule 返回之后,这个过程中可能会被设置抢占标志,这时候还是需要重新执行调度的
schedule() 函数只是个外层的封装,实际调用的还是 __ schedule() 函数, __ schedule() 接受一个参数,该参数为 bool 型,false 表示非抢占,自愿调度,而 true 则相反.其实最终是通过__schedule完成正在的调度工作,其定义在kernel/sched/core.c中,实现如下:
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next; //prev表示調度前的task,next表示調度後的task
unsigned long *switch_count;
struct pin_cookie cookie;
struct rq *rq;
int cpu;
cpu = smp_processor_id(); //找到当前运行的CPU
rq = cpu_rq(cpu); //通过CPU找到当前CPU的就绪队列rq
prev = rq->curr; //将当前正在运行的进程curr保存到prev中
//一些调度前的debug feature,当前有栈越界检查,原子上下文调度检查
schedule_debug(prev);
//如果使用了Hrtick,就先清除hrtick,hrtick应该是高精度定时器的进程tick
if (sched_feat(HRTICK))
hrtick_clear(rq);
//关闭本地中断
local_irq_disable();
rcu_note_context_switch(); //更新全局状态,标识当前CPU发生上下文切换
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*/
smp_mb__before_spinlock(); //自旋锁定rq,rf应该是死锁检测功能的一部分
raw_spin_lock(&rq->lock); //锁住该队列
cookie = lockdep_pin_lock(&rq->lock);
rq->clock_skip_update <<= 1; /* promote REQ to ACT */
switch_count = &prev->nivcsw; //切换次数记录, 默认认为非主动调度计数(抢占)
//如果该进程没有被内核态抢占同时该进程处于停止状态,就执行下面的条件
if (!preempt && prev->state) {
//当进程有待处理的信号,并且进程可以被信号唤醒或者存在KILL信号
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING; //当进程有待处理的信号,并且进程可以被信号唤醒或者存在KILL信号
} else {
//将当前进程从runqueue(运行队列)中删除
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0; //将当前进程从runqueue(运行队列)中删除
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
//如果当前进程的flags集配置了PF_WQ_WORKER则需要处理
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
//如果工作者线程已经休眠了,通知并且询问工作者队列是否需要唤醒进程来维持并发性
to_wakeup = wq_worker_sleeping(prev);
if (to_wakeup)//将to_wakeup进程放入到运行队列中,开始被调度
try_to_wake_up_local(to_wakeup, cookie);
}
}
switch_count = &prev->nvcsw; //如果不是被抢占的,就累加主动切换次数
}
//如果进程在rq中,则update rq的clock相关信息
if (task_on_rq_queued(prev))
update_rq_clock(rq);
//根据prev信息,rq信息,pick一个进程即next,挑选一个优先级最高的任务将其排进队列
next = pick_next_task(rq, prev, cookie);
//清除pre的TIF_NEED_RESCHED标志
clear_tsk_need_resched(prev);
//清内核抢占标识
clear_preempt_need_resched();
rq->clock_skip_update = 0;
// 如果prev和next非同一个进程
if (likely(prev != next)) {
rq->nr_switches++; // 队列切换次数更新
rq->curr = next; // 将next标记为队列的curr进程
++*switch_count; // 进程切换次数更新
trace_sched_switch(preempt, prev, next);
// 进程之间上下文切换
rq = context_switch(rq, prev, next, cookie); /* unlocks the rq */
} else { //如果prev和next为同一进程,则不进行进程切换
lockdep_unpin_lock(&rq->lock, cookie);
raw_spin_unlock_irq(&rq->lock);//清除标记位,重开中断
}
//队列自平衡:红黑树平衡操作
balance_callback(rq);
}
对于__schedule,进行current相关的处理,比如有待决信号,则继续标记状态为TASK_RUNNING,或者如果需要睡眠则调用deactivate_task将从运行队列移除后加入对应的等待队列,通过pick_next_task选择下一个需要执行的进程,进行context_switch进入新进程运行。
内核源码中主调度器函数也给出了调度时机的注释,下面我们就以此为依据来看下:
/*
* __schedule() is the main scheduler function.
*
* The main means of driving the scheduler and thus entering this function are:
*
* 1. Explicit blocking: mutex, semaphore, waitqueue, etc.
*
* 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return
* paths. For example, see arch/x86/entry_64.S.
*
* To drive preemption between tasks, the scheduler sets the flag in timer
* interrupt handler scheduler_tick().
*
* 3. Wakeups don't really cause entry into schedule(). They add a
* task to the run-queue and that's it.
*
* Now, if the new task added to the run-queue preempts the current
* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets
* called on the nearest possible occasion:
*
* - If the kernel is preemptible (CONFIG_PREEMPT=y):
*
* - in syscall or exception context, at the next outmost
* preempt_enable(). (this might be as soon as the wake_up()'s
* spin_unlock()!)
*
* - in IRQ context, return from interrupt-handler to
* preemptible context
*
* - If the kernel is not preemptible (CONFIG_PREEMPT is not set)
* then at the next:
*
* - cond_resched() call
* - explicit schedule() call
* - return from syscall or exception to user-space
* - return from interrupt-handler to user-space
*
* WARNING: must be called with preemption disabled!
*/
-
显式阻塞场景 : 包括互斥体、信号量、等待队列等。这个场景主要是为了等待某些资源而主动放弃处理器,来调用主调度器,如发现互斥体被其他内核路径所持有,则睡眠等待互斥体被释放的时候来唤醒我。
-
在中断和用户空间返回路径上检查TIF_NEED_RESCHED标志 : 例如,arch/x86/entry_64.S。为了在任务之间驱动抢占,调度程序在计时器中断处理程序scheduler_tick()中设置标志。也就是重新调度标志(TIF_NEED_RESCHED)的设置和检查的情形
- 重新调度标志设置情形: 如scheduler_tick周期性调度器按照特定条件设置、唤醒的路径上按照特定条件设置等。当前这样的场景并不会直接调用主调度器,而会在最近的调度点到来时调用主调度器。
- 重新调度标志检查情形 :是真正的调用主调度器,下面的场景都会涉及到
-
唤醒并不会真正导致schedule()的进入,他们添加一个任务到运行队列,仅此而已,通过添加到运行队列中的新任务抢占了当前任务,那么唤醒设置TIF_NEED_RESCHED, schedule()在最近的可能情况下被调用:
如果内核是可抢占的(CONFIG_PREEMPTION=y)
- 在系统调用或异常上下文中,调用
preempt_enable()时(多次调用preempt_enable()时,系统只会在最后一次调用时会调度) - 在IRQ上下文中,从中断处理程序返回到抢占上下文
如果内核是不可抢占的(CONFIG_PREEMPTION=y)
- cond_resched()调用:为了在不可抢占内核的一些耗时的内核处理路径中增加主动抢占点(抢占计数器是否为0且当前任务被设置了重新调度标志),则调用主调度器进行抢占式调度,所进行低延时处理。
- 显式的schedule()调用:这是主动放弃处理器的场景,如一些睡眠场景,像用户任务调用sleep
- 从系统调用或异常返回到用户空间:系统调用或异常返回到用户空间使会判断当前进程是否设置重新调度标志(TIF_NEED_RESCHED),如果设置则调用主调度器,放弃处理器。
- 从中断处理器返回到用户空间:中断处理器返回到用户空间会判断当前进程是否设置重新调度标志(TIF_NEED_RESCHED),如果设置则调用主调度器,放弃处理器。
schedule就是主调度器的工作函数, 在内核中的许多地方, 如果要将CPU分配给与当前活动进程不同的另一个进程, 都会直接调用主调度器函数schedule或者其子函数__schedule.其主要的流程如下:- 完成一些必要的检查, 并设置进程状态, 处理进程所在的就绪队列
- 调度全局的pick_next_task选择抢占的进程
- 如果当前cpu上所有的进程都是cfs调度的普通非实时进程, 则直接用cfs调度, 如果无程序可调度则调度idle进程
- 否则从优先级最高的调度器类
sched_class_highest(目前是stop_sched_class)开始依次遍历所有调度器类的pick_next_task函数, 选择最优的那个进程执行 context_switch完成进程上下文切换- 调用
switch_mm(), 把虚拟内存从一个进程映射切换到新进程中 - 调用
switch_to(),从上一个进程的处理器状态切换到新进程的处理器状态。这包括保存、恢复栈信息和寄存器信息
- 在系统调用或异常上下文中,调用
2 周期性调度器
对于目前市面上的大多数的操作系统,都存在一个时间片轮转的调度方式,而使用时间片的初衷在于,系统通过时间片可以很方便度量一个进程应该运行多久和一个进程已经运行了多久,以此作为唯一或者辅助的依据来执行任务调度。
在内核中,有一个周期性TIme,内核定义了一个宏变量HZ,周期性调度器是用中断实现的,系统定时产生一个中断,然后在中断执行中执行scheduler_tick()函数,执行完毕后,将CPU使用权还给用户进程,下一个时间点到了,系统再次产生中断,然后执行scheduler_tick,linux每个时钟中断(又称tick中断)处理中都会更新进程时间,即update_process_times。所以本文把update_process_times函数作为入口点进行分析
/*
* Called from the timer interrupt handler to charge one tick to the current
* process. user_tick is 1 if the tick is user time, 0 for system.
*/
void update_process_times(int user_tick)
{
struct task_struct *p = current;//获取当前进程的task_struct
// user_tick根据cpu模式判断是用户态还是内核态。linux统计时间的方式
// 基于整个cpu的统计,user_tick表示cpu在用户态,内核态还是中断状态。此处把一个tick的时间累加到kstat_cpu(i).cpustat.
// /proc/stat中的统计值是在此处统计的,表示cpu在用户态,内核态,中断中各占用多少时间,对应 stat.c(fs/proc):static int __init proc_stat_init(void);
//基于进程的统计。linux还有一种统计时间的方法更细化,统计的是调度实体上的时间sum_exec_runtime,它在sched_clock_cpu函数中基于timer计算
// /proc/pid/stat,/proc/pid/task/tid/stat中的时间是在此处统计的,它统计了一个进程/线程占用cpu的时间,对应do_task_stat实现
account_process_tick(p, user_tick);
//标记一个软中断去处理所有到期的定时器
run_local_timers();
rcu_check_callbacks(user_tick);
#ifdef CONFIG_IRQ_WORK
if (in_irq())
irq_work_tick();
#endif
//与进程和调度用过的时间参数
scheduler_tick();
run_posix_cpu_timers(p);
}
- 首先调用account_process_tick(),它根据当前进程运行了多久时间和当前进程类别,选择调用account_user_time()、account_system_time(),还是account_idle_time()。
- 调用run_local_timers(),从而间接调用raise_softirq(),用来激活本地CPU上的TIMER_SOFTIRQ任务队列。
- 启动周期性定时器(scheduler_tick)完成该cpu上任务的周期性调度工作
/*
* This function gets called by the timer code, with HZ frequency.
* We call it with interrupts disabled.
*/
void scheduler_tick(void)
{
// 1. 获取当前cpu上的全局就绪队列rq和当前运行的进程curr
int cpu = smp_processor_id(); //获取当前CPU ID
struct rq *rq = cpu_rq(cpu); //根据CPU ID 获取当前CPU运行队列rq
struct task_struct *curr = rq->curr; //获取当前CPU上运行队列正在运行进程
//以纳秒为单位将当前时间放入sched_clock_data中,更新sched_clock_data结构体
sched_clock_tick();
//2. 上锁,更新rq上的统计信息, 并执行进程对应调度类的周期性的调度
raw_spin_lock(&rq->lock);
update_rq_clock(rq); //更新当前调度队列rq的clock.即使rq->clock变为当前时间
//执行当前运行进程curr的调度类的task_tick函数
curr->sched_class->task_tick(rq, curr, 0);
cpu_load_update_active(rq); // 更新rq的负载信息,即就绪队列的cpu_load[]数据
calc_global_load_tick(rq); //更新cpu的active count活动计数,主要是更新全局cpu就绪队列的calc_load_update
raw_spin_unlock(&rq->lock);
perf_event_task_tick(); //与perf计数事件相关
#ifdef CONFIG_SMP
//判断当前CPU是否空闲
rq->idle_balance = idle_cpu(cpu);
//如果需要定期进行负载平衡,则触发sched_softirq,必要时进行负载均衡
trigger_load_balance(rq);
#endif
rq_last_tick_reset(rq);
}
- 调用sched_clock_tick()以纳秒为单位将当前时间放入sched_clock_data中
- 调用update_rq_clock()就绪队列时钟的更新, 实际上更新struct rq当前实例的时钟时间戳
- 调用curr->sched_class->task_tick()内核先找到了就绪队列上当前运行的进程curr, 然后调用curr所属调度类sched_class的周期性调度方法task_tick。在Linux-2.6.32中有task_tick_rt(),task_tick_fair(), task_tick_idle()
- 调用update_cpu_load()更新CPU上负载,为下一步执行调度类挑选进程做准备
- 如果系统支持SMP则调用trigger_load_balance()定期进行堵负载均衡
2.1 更新时间
scheduler_tick 中和更新时间相关的接口主要是两个,sched_clock_tick() 和 update_rq_clock(rq),前者用来更新和调度 timer 相关的计时统计,后者用来更新 percpu 的 runqueue 的时间.以下是源代码:
void sched_clock_tick(void)
{
struct sched_clock_data *scd;
u64 now, now_gtod;
if (sched_clock_stable())
return;
if (unlikely(!sched_clock_running))
return;
WARN_ON_ONCE(!irqs_disabled());
scd = this_scd();
now_gtod = ktime_to_ns(ktime_get());//获取monotonic clock的时间值,转换为64位纳秒计数器
now = sched_clock();//获取当前硬件 timer 的时间
scd->tick_raw = now;
scd->tick_gtod = now_gtod;
sched_clock_local(scd);
}
- scd 是一个 struct sched_clock_data 的结构,从名字可以看出,这是和硬件 timer 本身相关的一个计时数据结构,该结构是 percpu 的,也就是每一个 cpu 核都拥有各自的实体。其中记录了 tick_raw和 clock 值,tick_raw是硬件原始值,也就是 timer 的时间戳,而 clock 是经过过滤处理的
- sched_clock 是获取时间的底层接口,获取时间的上层函数会在多处被调用,都是基于 sched_clock 的封装,这个接口直接负责调用系统timer 的 read 回调函数,读取该定时器对应的时间戳,该时间以 ns 为单位.而 read 回调函数正是 schedule timer 在注册时提供的回调函数,用来直接读取 timer 的时间戳.
- 更新scd,主要是将硬件的time时间用来更新tick_raw,sched_clock_local 中对 scd->clock 进行更新
除了维护 scd 类型的时间之外,更重要的是维护 CPU runqueue 的时间,这是和调度直接相关的参数, runqueue 时间的更新由 update_rq_clock(rq) 执行:
void update_rq_clock(struct rq *rq)
{
s64 delta;
lockdep_assert_held(&rq->lock);
if (rq->clock_skip_update & RQCF_ACT_SKIP)
return;
delta = sched_clock_cpu(cpu_of(rq)) - rq->clock;
if (delta < 0)
return;
rq->clock += delta;
update_rq_clock_task(rq, delta);
}
struct rq 中有两个成员用来记录当前 CPU runqueue 的时间,
- 一个是 clock ,clock 是一个递增的时间,表示 CPU runqueue 从初始化到现在的总时间
- 一个是 clock_task ,记录的是纯粹的所有进程运行的总时间,一个 CPU 上并不只是进程在运行,同时还有中断以及部分中断下半部.这部分的统计取决于内核配
2.2 cfs调度类
完成更新统计信息后,内核将真正的调度工作委托给特定的调度类方法,内核先找到就绪队列上当前运行的curr,然后调用curr所属调度类sched_class的周期性调度方法task_tick
curr->sched_class->task_tick(rq, curr, 0);
task_tick函数的具体实现取决于调度器类,目前我们的内核中的3个调度器类struct sched_entity, struct sched_rt_entity, 和struct sched_dl_entity dl, 我们针对当前内核中实现的调度器类分别列出其周期性调度函数task_tick。
我们以CFS完全公平调度器类,该类是通过task_tick_fair函数完成周期性调度的工作
/*
* scheduler tick hitting a task of our scheduling class:
*/
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se; //获取当前进程curr所在的调度实体
//在不支持组调度的条件下只循环一次,在组调度的条件下调度实体存在层次关系,更新子调度实体时必须更新父调度实体
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se); //获取当当前运行的进程所在的CFS就绪队列
entity_tick(cfs_rq, se, queued); //完成周期性调度
}
if (static_branch_unlikely(&sched_numa_balancing))
task_tick_numa(rq, curr);
}
根据源码可以看到,系统实际上主要是调用entity_tick函数完成调度,而这个函数主要是调用check_preempt_tick函数来进行切换进程的决策
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq); //更新统计信息
/*
* Ensure that runnable average is periodically updated.
*/
update_load_avg(curr, 1); 更新load
update_cfs_shares(cfs_rq);
#ifdef CONFIG_SCHED_HRTICK
/*
* queued ticks are scheduled to match the slice, so don't bother
* validating it and just reschedule.
*/
if (queued) {
resched_curr(rq_of(cfs_rq));
return;
}
/*
* don't let the period tick interfere with the hrtick preemption
*/
if (!sched_feat(DOUBLE_TICK) &&
hrtimer_active(&rq_of(cfs_rq)->hrtick_timer))
return;
#endif
//如果进程的数目不少于两个,则由check_preempt_tick作出决策
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr);
}
- 使用update_curr来更新统计量,同时更新load
- hrtimer的更新, 这些由内核通过参数CONFIG_SCHED_HRTICK开启
- 如果cfs就绪队列中进程数目nr_running少于两个(< 2)则实际上无事可做. 因为如果某个进程应该被抢占, 那么至少需要有另一个进程能够抢占它(即cfs_rq->nr_running > 1),如果进程的数目不少于两个, 则由check_preempt_tick作出决策
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
//计算curr的理论上应该运行的时间
ideal_runtime = sched_slice(cfs_rq, curr);
//计算curr的实际运行时间,sum_exec_runtime: 进程执行的总时间
//prev_sum_exec_runtime:进程在切换进CPU时的sum_exec_runtime值
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime) { //如果实际运行时间比理论上应该运行的时间长
resched_curr(rq_of(cfs_rq));//说明curr进程已经运行了足够长的时间, 应该调度新的进程抢占CPU了
/*
* The current task ran long enough, ensure it doesn't get
* re-elected due to buddy favours.
*/
clear_buddies(cfs_rq, curr);
return;
}
/*
* Ensure that a task that missed wakeup preemption by a
* narrow margin doesn't have to wait for a full slice.
* This also mitigates buddy induced latencies under load.
*/
//若运行时间小于最小运行时间粒度,则不需要重新调度
if (delta_exec < sysctl_sched_min_granularity)
return;
// 在 cfs_rq 中选择 vruntime 值最小的进程,也就是 leftmost 进程.
se = __pick_first_entity(cfs_rq);
//计算两个进程 vruntime 之间的差值 delta
delta = curr->vruntime - se->vruntime;
//若当前进程的vruntime小于cfs_rq上的最左边的vruntime则不需要重新调度
if (delta < 0)
return;
//当差值大于进程应该运行的时间,那么当前进程就应该被调度.
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}
周期性调度器不显式的进行调度,而是采用延迟调度的策,如果发现需要抢占,周期性调度器就设置进程的重调度标识TIF_NEED_RESCHED,最终还是由主调度器完成调度工作。
- TIF_NEED_RESCHED标识表明进程需要被调度,TIF前缀表明这是一个存储在进程thread_info中flag字段的一个标识信息.在内核的关键位置,会检查当前进程是否设置了重调度标志TIF_NEED_RESCHE
- 在内核中会检查当前进程是否设置了重调度标志TLF_NEDD_RESCHED, 如果该进程被其他进程设置了TIF_NEED_RESCHED标志, 则函数重新执行进行调度
前面我们在check_preempt_tick中如果发现curr进程已经运行了足够长的时间, 其他进程已经开始饥饿, 那么我们就需要通过resched_curr来设置重调度标识TIF_NEED_RESCHED
static __always_inline bool need_resched(void)
{
return unlikely(tif_need_resched());
}
#define tif_need_resched() test_thread_flag(TIF_NEED_RESCHED)
其实就是通过set_tsk_need_resched(curr)函数设置重调度标识
2.3 实时调度类
在 Linux 系统中,实时进程是具有很强的调度需要的进程,它们的响应时间需要尽可能地短。这一类进程的优先级处于中等位置,低于 最早截止时间优先调度器(EDF) 而高于 CFS。因此,采用 RR(Round-Robin)和 FIFO 来进行调度。 这个调度类定义在 kernel/sched/rt.c 下。其进程切换函数 task_tick_rt 如下
static void task_tick_rt(struct rq *rq, struct task_struct *p, int queued)
{
struct sched_rt_entity *rt_se = &p->rt;
update_curr_rt(rq);
watchdog(rq, p);
/*
* RR tasks need a special form of timeslice management.
* FIFO tasks have no timeslices.
*/
if (p->policy != SCHED_RR) //检查释放时RR,如果不是,则为FIFO,无需调度
return;
if (--p->rt.time_slice) //检查是否到了切换时间片,否则不切换
return;
p->rt.time_slice = sched_rr_timeslice; //重置时间片
/*
* Requeue to the end of queue if we (and all of our ancestors) are not
* the only element on the queue
*/
//把当前进程插入就绪队列,并把就绪队列的队首提出来
for_each_sched_rt_entity(rt_se) {
if (rt_se->run_list.prev != rt_se->run_list.next) {
requeue_task_rt(rq, p, 0);
resched_curr(rq);
return;
}
}
}
由于FIFO是先来先服务,因此在每一个时间片到达时,并不需要进行进程调度,而RR则是在每一个时间片都要进行一次调度。
2.4 EDF调度类
这个调度类是为了实现最早截止时间优先算法而特意增设的调度类。 这种调度类下只有一种调度策略: EDF。 Linux 较高版本中新增的调度策略。这种调度方法具有很高的实时性,主要用于对时间要求很高的任务。 这个调度类定义在 kernel/sched/deadline.c 下。
static void task_tick_dl(struct rq *rq, struct task_struct *p, int queued)
{
update_curr_dl(rq); //更新当前进程的截止时间
/*
* Even when we have runtime, update_curr_dl() might have resulted in us
* not being the leftmost task anymore. In that case NEED_RESCHED will
* be set and schedule() will start a new hrtick for the next task.
*/
if (hrtick_enabled(rq) && queued && p->dl.runtime > 0 &&
is_leftmost(p, &rq->dl))
start_hrtick_dl(rq, p); //从队列中挑选截止时间最近的进程切换
}
3 总结
linux系统有两种方式来激活进程调度
- 主调度器: 进程直接请求调度,通过直接调用schedule,检查死锁,关闭内核抢占,然后调用_schedule() ,如果进程被设置了重新调度位,则在进行一次schedule,而对于_ _schedule则判断当前进程是否需要切换,然后从就绪队列中挑选进程,完成上下文切换操作。
- 周期性调度器: 系统周期性地检查是否需要调度,所以周期性调度是指Linux定时周期性地检查当前任务是否耗尽当前进程的时间片,并检查是否应该抢占当前进程。一般会在定时器的中断函数中,通过一层层函数调用最终到scheduler_tick()函数,该接口会调用调度类的,完成对于调度标志位TIF_NEED_RESCHED置位,在搭配主调度器来完成实际的调度工作。
4 参考文档
https://zhuanlan.zhihu.com/p/395606426
linux调度子系统6 - 周期调度 timer setup
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
