索引配置、模板和重建
在Elasticsearch中索引有很多的配置参数,有些配置是可以在建好索引后重新进行设置和管理的,比如索引的副本数量、索引的分词等。
1、获取索引配置
索引中包含很多配置参数,可以通过下面命令获取索引的参数配置:
GET http://127.0.0.1:9200/secisland/_settings
获取索引配置参数的请求格式如下:
host:port/(index)/_settings
{index}为索引名称,可以接收多种参数格式,*|all|namel,name2…
过滤配置参数的返回结果:
GET http://127.0.0.1:9200/secisland/_settings/name=index.number_*
name-index.number*设置将只返回number_of_replicas,number_of_shards两个参数详情。
2、更新索引配置
在REST风格的URL设置中设置/settings(所有索引)或者{index}/_settings,可以设置一个或者多个索引,例如:
请求:
PUT http:/127.0.0.l:9200/secisland/_settings
参数:
{
"indexx":{"number_of_replicas":4}
}

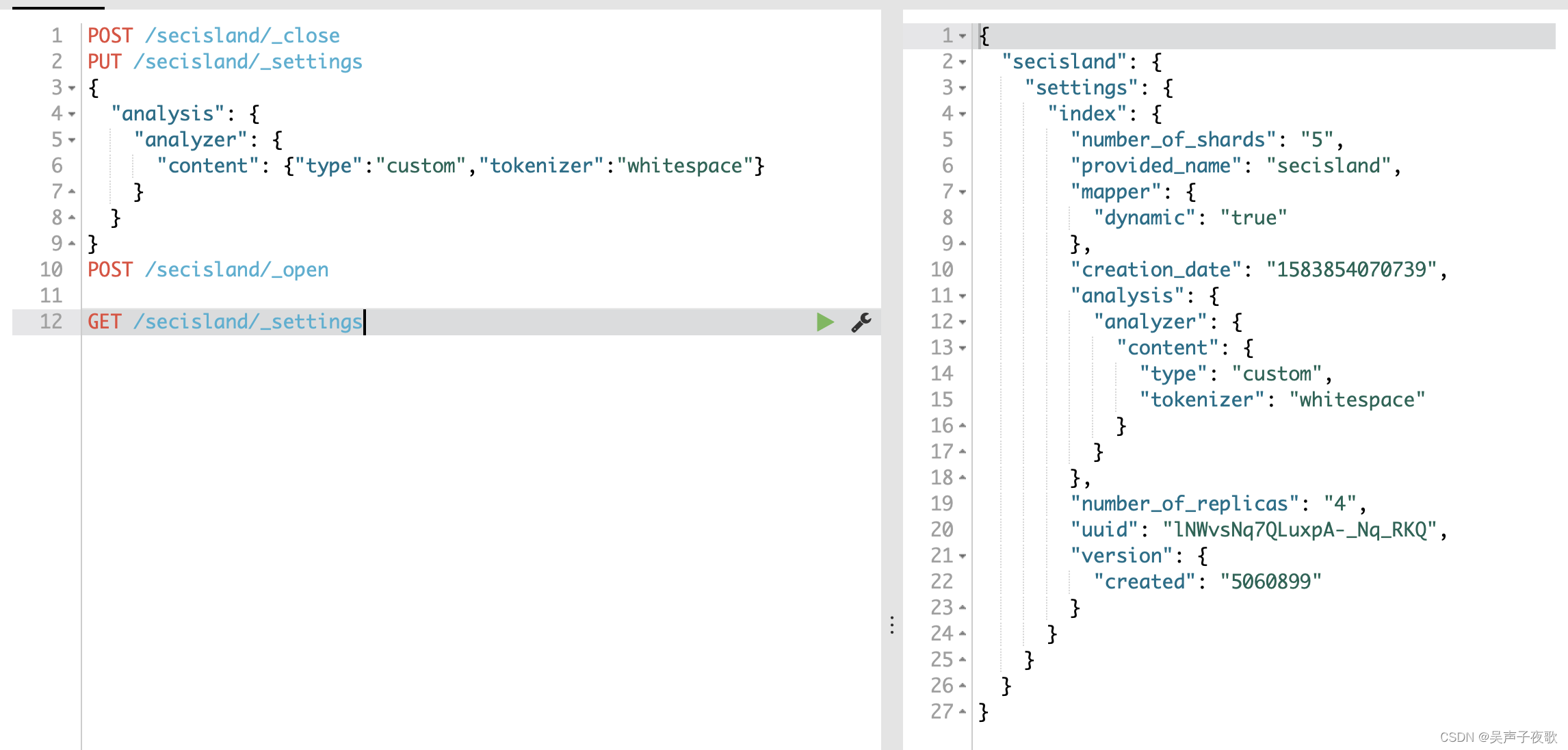
更新分词器。创建索引后可以添加新的分析器。添加分析器之前必须先关闭索引,添加之后再打开索引。
POST http://127.0.0.1:9200/secisland/_close
PUT http://127.0.0.1:9200/secisland/_settings
{
"analysis": {
"analyzer": {
"content": {"type":"custom","tokenizer":"whitespace"}
}
}
}
POST http://127.0.0.1:9200/secisland/_open
3、索引分析
索引分析(analysis)是这样一个过程:首先,把一个文本块分析成一个个单独的词(term),为了后面的倒排索引做准备。然后标准化这些词为标准形式,提高它们的“可搜索
性”。这些工作是分析器(analyzers)完成的。一个分析器(analyzers)是一个组合,用于将三个功能放到一起:
- 字符过滤器 :字符串经过字符过滤器(character filter)处理,它们的工作是在标记化之前处理字符串。字符过滤器能够去除HTML标记,或者转换“&”为“and”。
- 分词器 :分词器(tokenizer)被标记化成独立的词。一个简单的分词器(tokenizer)可以根据空格或逗号将单词分开。
- 标记过滤器 :每个词都通过所有标记过滤(token filters)处理,它可以修改词(例如将"Quick"转为小写),去掉词(例如连接词像“a”、“and”、“the”等),或者增加
词(例如同义词像“jump”和“leap”)。
Elasticsearch提供很多内置的字符过滤器,分词器和标记过滤器。这些可以组合起来创建自定义的分析器以应对不同的需求。
3.1、测试分析器
POST http://127.0.0.1:9200/_analyze
{
"analyzer":"standard",
"text":"this is a test"
}
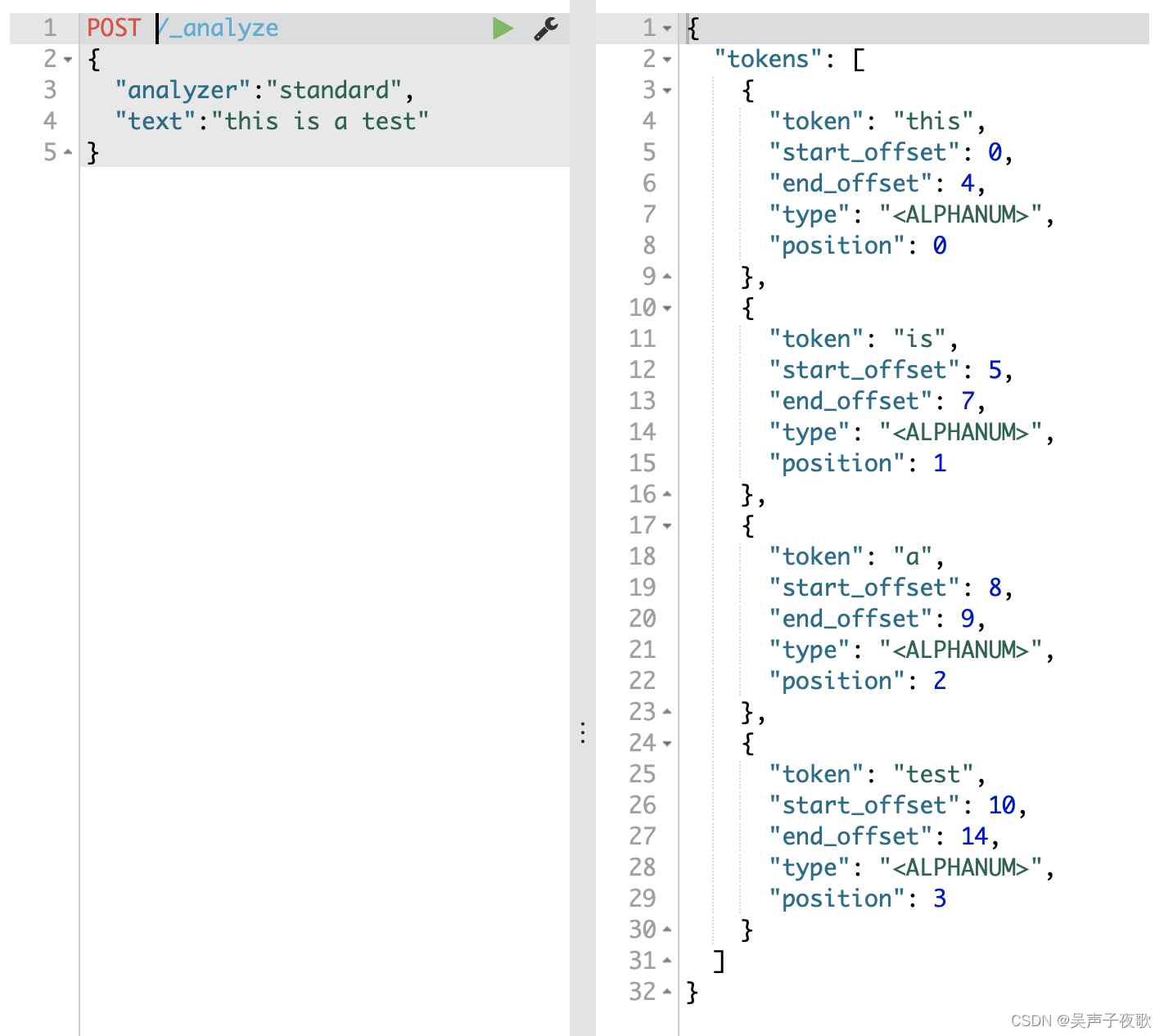
在该分析器下,将会分析成this,is,a,test四个词。
3.2、自定义分析器:
POST http://127.0.0.1:9200/_analyze
{
"tokenizer":"keyword",
"token_filters":["lowercase"],
"char_filters":["html_strip"],
"text":"this is a <b>test</b>"
}
使用keyword分词器、lowercase分词过滤、字符过滤器是html strip,这3部分构成一个分词器。
上面示例返回分词结果是this is a test,其中html_strip过滤掉了html字符。
也可以指定索引进行分词。URL格式如下:
http://127.0.0.1:9200/secisland/_analyze
3.3、索引分析详情
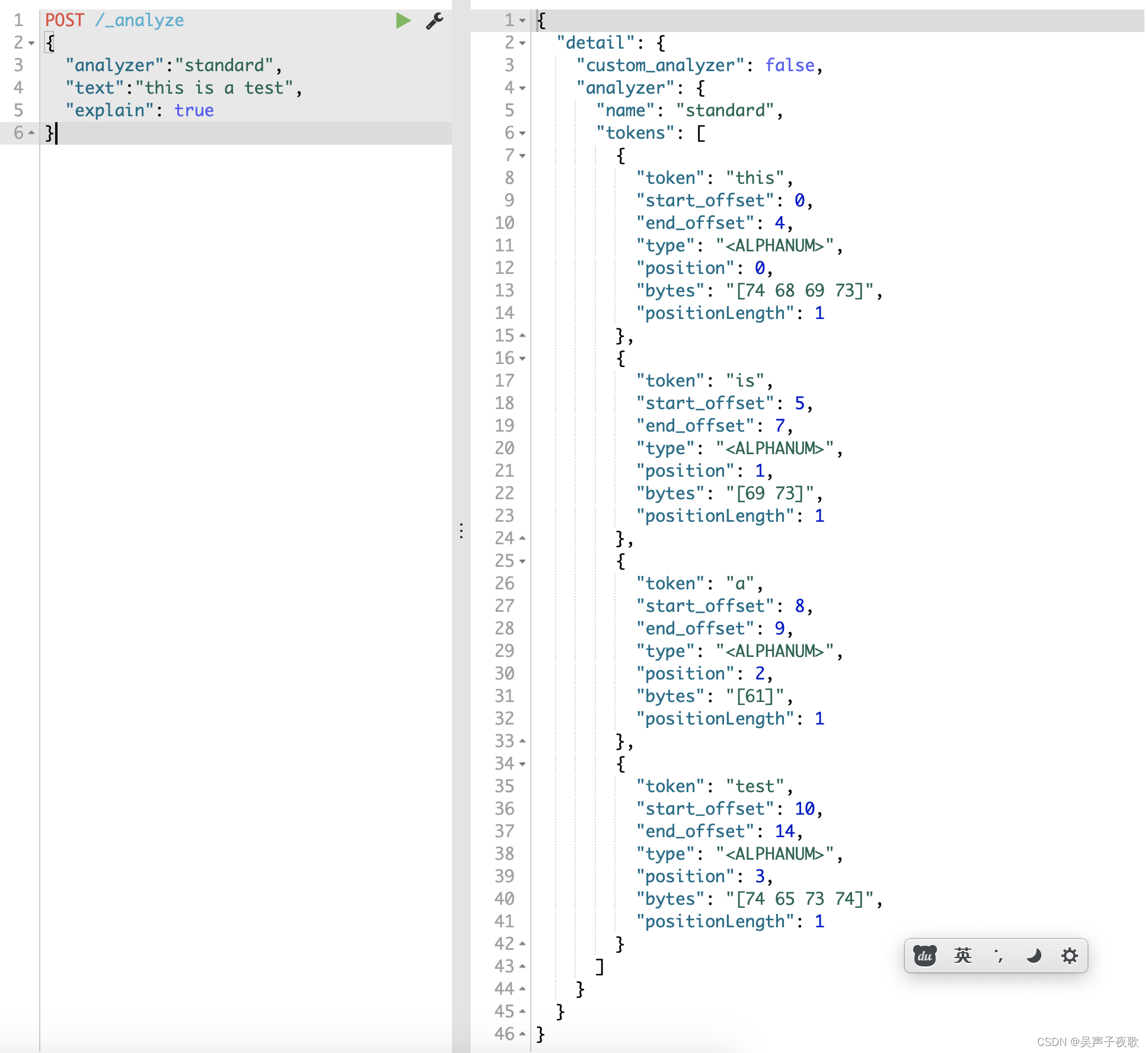
如果想获取分析器分析的更多细节,设置explain属性为true(默认为false),将输出分词详情。
4、索引模板
4.1、创建索引模板
PUT http://127.0.0.1:9200/_template/template_1
{
"template": "te*",
"settings": {"number_of_shards": 1},
"mappings": {
"type1": {
"_source": {
"enabled": false
}
}
}
}
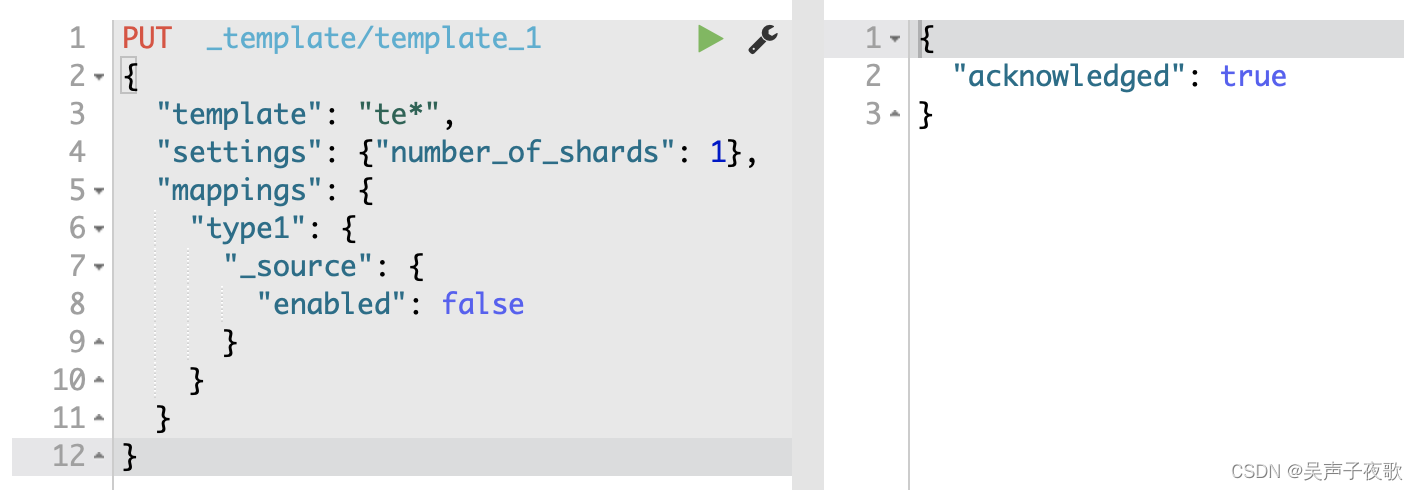
定义好模板可使用te*来适配,分片数量为1,默认文档类型为type1,_source的enabled为false。
4.2、删除索引模板
DELETE http://127.0.0.1:9200/_template/template_1
4.3、获取索引模板
GET http://127.0.0.1:9200/_template/template_1
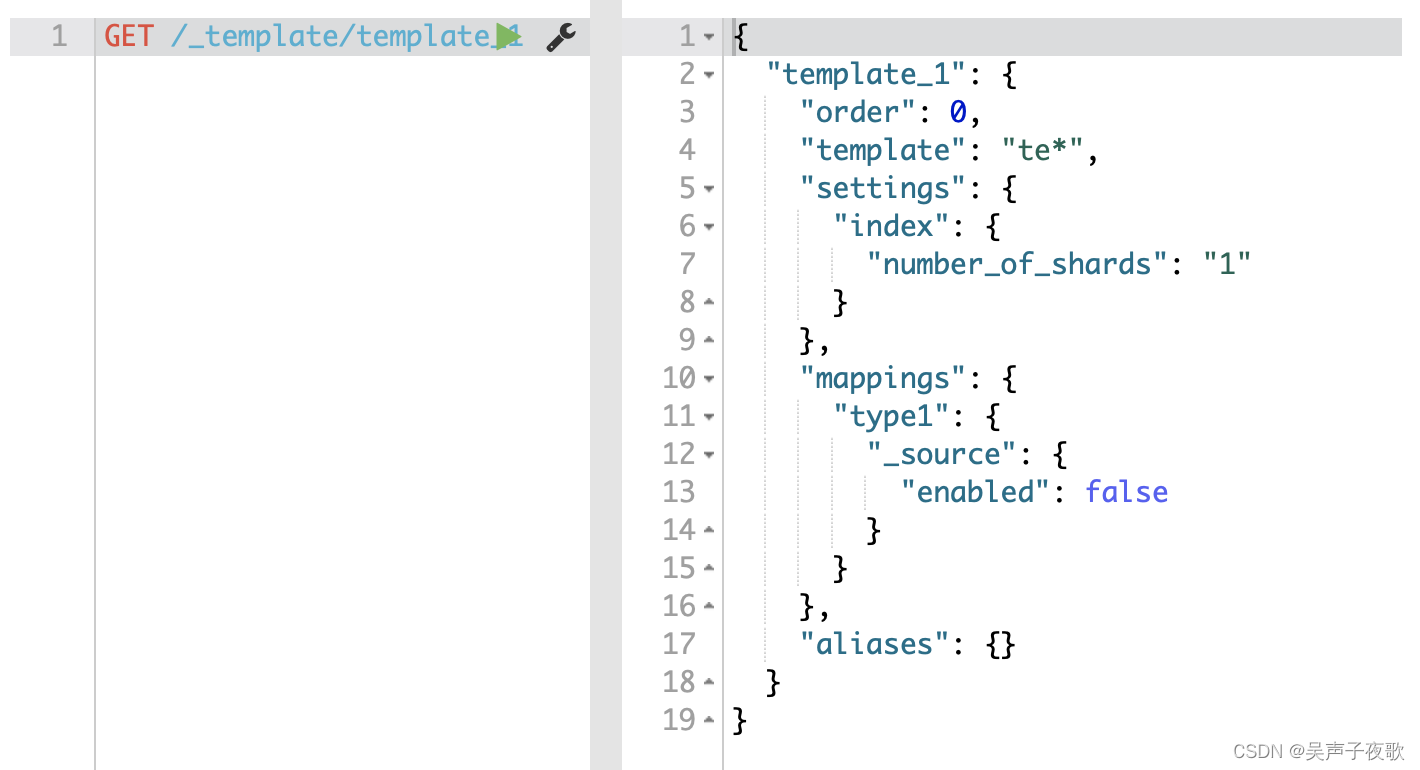
使用通配符或逗号分隔符:
GET http://127.0.0.1:9200/_template/temp*
GET http://127.0.0.1:9200/_template/template_1,template_2
获取所有索引模板:
GET http://127.0.0.1:9200/_template/
判断索引模板是否存在:
HEAD http://127.0.0.1:9200/_template/template_1

4.4、多个模板匹配
有这样一种情况:template_1、template2两个模板,使用te*会匹配2个模板,最后合并两个模板的配置。如果配置重复,这时应该设置order属性,order是从0开始的数字,先匹配ordr数字小的,再匹配数字大的,如果有相同的属性配置,后匹配的会覆盖之前的配置。
5、重建索引
5.1、基本功能
重建索引的最基本功能是拷贝文件从一个索引到另一个索引,例如:
POST /_reindex
{
"source": {"index": "secisland"},
"dest": {"index": "new_secisland"}
}
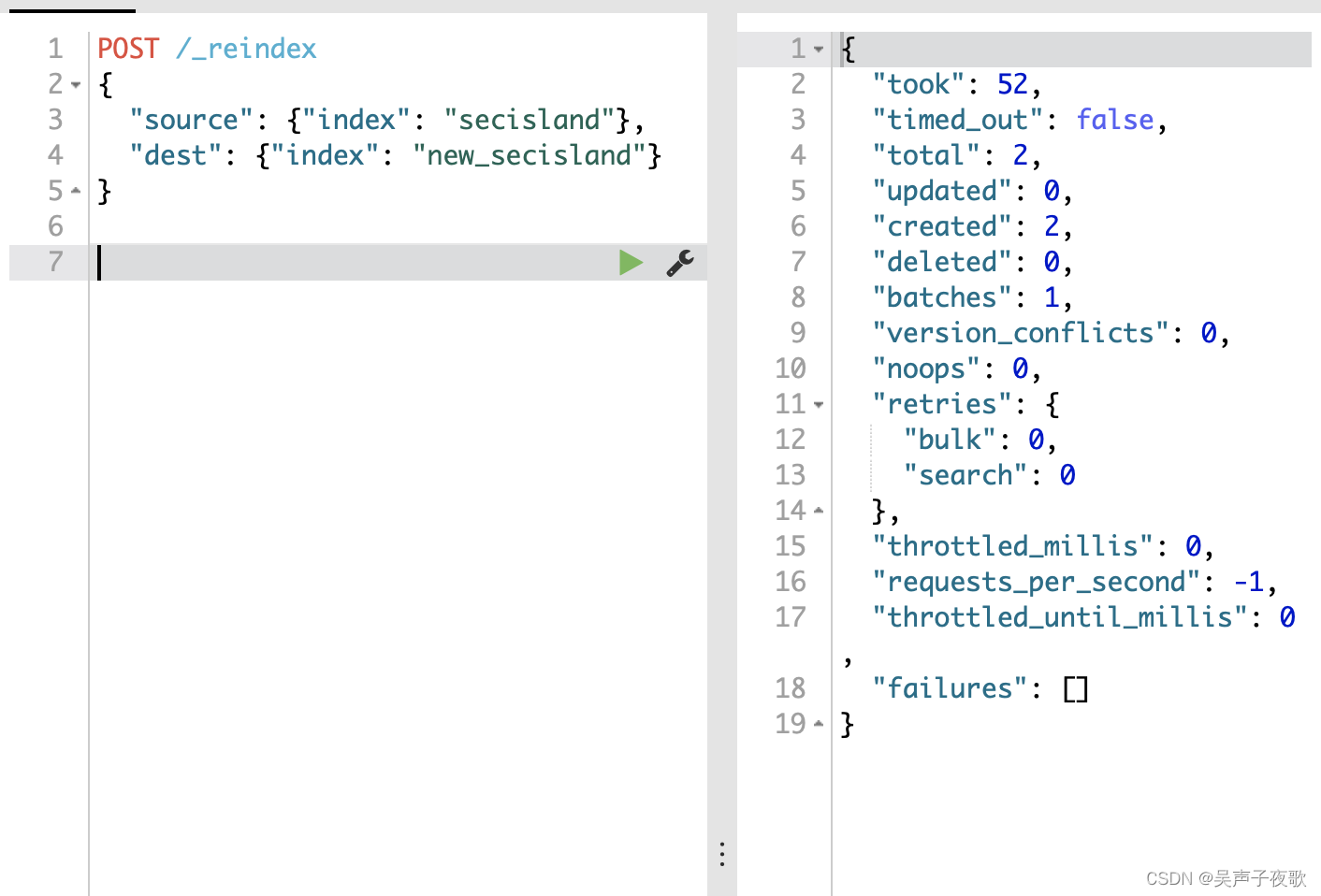
参数说明:
- took :从开始到结束的整个操作的毫秒数。
- updated :已成功更新的文档数。
- created :成功创建的文档数。
- batches :从重建索引拉回的滚动响应的数量。
- version_conflicts :重建索引中版本冲突数的数量。
- failures :所有索引失败的数组。如果这是非空的,则请求将被中止。
5.2、冲突控制
由于_reindex是获取源索引的快照,而且目标索引是不同的索引,所以基本上不太可能产生冲突。在接口参数中可以增加dest来进行乐观并发控制。如果version_type设置为
internal会导致Elasticsearch盲目转储文件到目标索引,任何具有相同类型和ID的文档将被重写。例如:
POST /_reindex
{
"source": {"index": "secisland"},
"dest": {
"index": "new_secisland",
"version_type": "internal"
}
}
如果设置version_type为external将会导致Elasticsearch保护源索引的版本,如果在目标索引中有一个比源索引旧的版本,则会更新文档。对于源文件中丢失的文档在目标中也会被创建。
POST /_reindex
{
"source": {"index": "secisland"},
"dest": {
"index": "new_secisland",
"version_type": "external"
}
}
设置op_type为create将导致_reindex在目标索引中仅创建丢失的文件。所有现有的文件将导致版本冲突。
POST /_reindex
{
"source": {"index": "secisland"},
"dest": {
"index": "new_secisland",
"op_type": "create"
}
}
正常情况下当发生冲突的时候reindex过程将被终止,可以在请求体中设置"conflicts’":“proceed”,可以只进行计算:
POST /_reindex
{
"source": {"index": "secisland"},
"dest": {"index": "new_secisland"},
"conflicts":"proceed"
}
5.3、查询限制
可以通过向源添加一个类型或者增加一个查询来限制文档的数量,比如只复制类型为secilog,且collect_type字段为syslog的文档:
POST /_reindex
{
"source": {
"index": "secisland",
"type":"secilog",
"query":{
"term": {
"collect_type": {
"value": "syslog"
}
}
}
},
"dest": {"index": "new_secisland"}
}
5.4、复制多个源
在请求接口中可以列出源索引和类型,可以在一个接口中复制多个源。例如下面的例子将在secisland和blog索引中的secilog和post类型中拷贝数据,这包括secisland索引中的“secilog”和“post”类型,也包括blog索引中的“secilog”和“post”类型。如果需要更具体的文档可以使用查询。当id产生冲突的时候是没有办法处理的,因为执行的顺序是随机的,所以目标索引将无法确认应该保存哪些文档:
POST /_reindex
{
"source": {
"index": ["secisland", "blog"],
"type": ["secilog", "post"]
},
"dest": {"index": "all_together"}
}
5.5、限制数量
也可以通过设置大小来限制处理文档的数量。这只会复制一个文件到new_secisland索引中:
POST /_reindex
{
"source": {"index": "secisland"},
"dest": {"index": "new_secisland"},
"size": 1
}
5.6、排序
如果你想要复制特定的文档,可以使用排序。排序会降低效率,但在某些情况下,它是有意义的。如果可能的话,可以选择性地查询来确定复制的大小和排序。下面将从secisland索引中复制l0000文档到new_secisland中:
POST /_reindex
{
"source": {"index": "secisland", "sort":{"date": "desc"}},
"dest": {"index": "new_secisland"},
"size": 10000
}
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
