我们知道当调用schedule函数进行主动调度时, 首先 会调用通过调度类找到下一个要被调度的进程,然后将当前进程切换状态放入对应调度类的调度队列里面,等待再次被唤醒。而对于被调度的这个队列我们就要对其进行 上下文切换 ,上一章节我们学习了上下文切换的时候的基本原理后,本章主要是学习在最新的内核上基于ARM架构学习完整的进程上下文切换的过程,本文的内核版本号为linux4.9.88。
1 context_switch代码分析
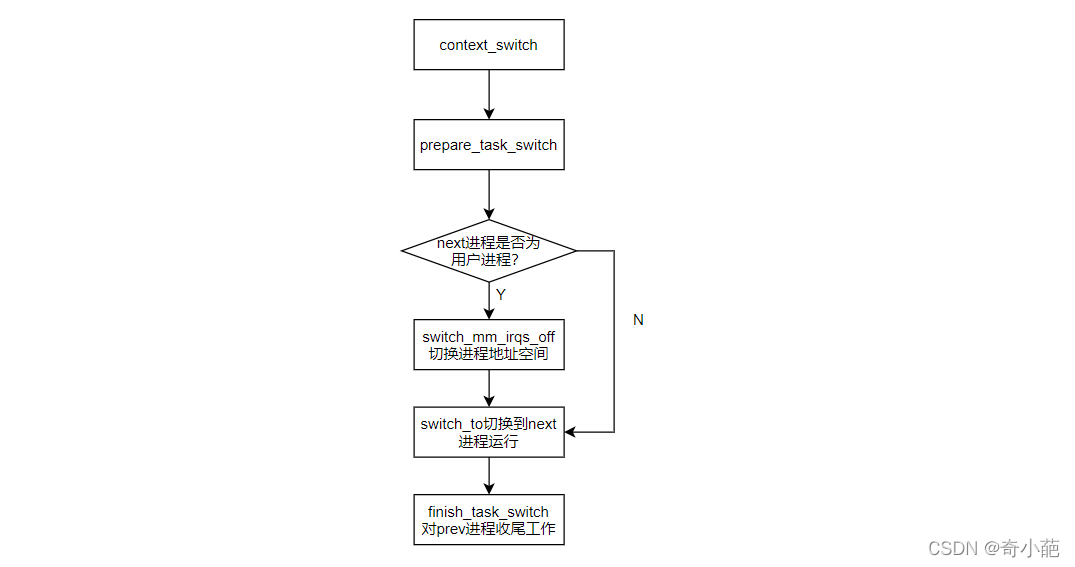
在操作系统中把当前正在运行的进程挂起并恢复以前挂起的某个进程的执行,这个过程叫进程切换或者进程上下文,linux内核实现进程切换的核心代码在kernel/sched/core.c中有一个context_switch函数,该函数用来完成具体的进程切换,代码如下

-
该函数是由调度器确定了pre进程和next进程,就调用到该接口执行进程的切换工作,所以其参数情况为
- rq:在多核系统中,进程切换总是发生在各个cpu core上,参数rq指向本次切换发生的那个cpu对应的run queue
- prev:将要被剥夺执行权利的那个进程
- next:被选择在该cpu上执行的那个进程
-
对于用户进程,其任务描述符(task_struct)的mm和active_mm相同,都是指向其进程地址空间的进程描述符mm_struct。对于内核线程而言,其task_struct的mm成员为NULL(内核线程没有进程地址空间),但是,内核线程被调度执行的时候,总是需要一个进程地址空间,而active_mm就是指向它借用的那个进程地址空间,所以mm为空的话,说明B进程是内核线程,这时候,只能借用A进程当前正在使用的那个地址空间(prev->active_mm)。注意:这里不能借用A进程的地址空间(prev->mm),因为A进程也可能是一个内核线程,不拥有自己的地址空间描述符。
-
如果要切入的B进程是内核线程,那么由于是借用当前正在使用的地址空间,因此没有必要调用switch_mm_irqs_off进行地址空间切换,只有要切入的B进程是一个普通进程的情况下(有自己的地址空间)才会调用switch_mm_irqs_off,真正执行地址空间切换。
-
switch_to完成了具体prev到next进程的切换,当switch_to返回的时候,说明A进程再次被调度执行了
虽然每个进程都可以拥有属于自己的进程空间,但是所有进程必须共享CPU寄存器等资源,所以在进程切换的时候必须把next进程在上一次挂起时保持的寄存器重新装载到CPU里,进程恢复执行前必须装入CPU寄存器的数据为硬件上下文,其主要包括以下两部分
- 由于对于每个进程拥有系统全部的虚拟地址空间,但是其并没有占用所有的物理地址,物理地址的访问需要页表转换完成,所以切换进程的页表到硬件页表中,此时才能切换进程地址空间,该过程是由switch_mm_irqs_off实现
- 切换到next进程的内核态栈和硬件上下文,是由switch_to函数实现的,硬件上下文提供了内核执行next进程所需要的所有硬件信息
2 切换前的准备工作
在进程切换之前, 首先执行调用每个体系结构都必须定义的prepare_task_switch挂钩, 这使得内核执行特定于体系结构的代码, 为切换做事先准备. 大多数支持的体系结构都不需要该选项,该接口基本没有做什么事情,暂时不介绍。

对于内核线程,没有空间切换,直接使用上一个进程的内核空间即可。但是如果是用户进程则调用switch_mm_irqs_off完成用户地址空间切换,switch_mm_irqs_off(或switch_mm)与体系结构相关。
对于ARM64的cpu,每个cpu core都有两个寄存器来指示当前运行在该CPU core上的进程实体的地址空间,这两个寄存器分别是ttbr0_el1(用户地址空间)和ttbr1_el1(内核地址空间)。由于所有的进程共享内核地址空间,因此所谓地址空间切换也就是切换ttbr0_el1而已。
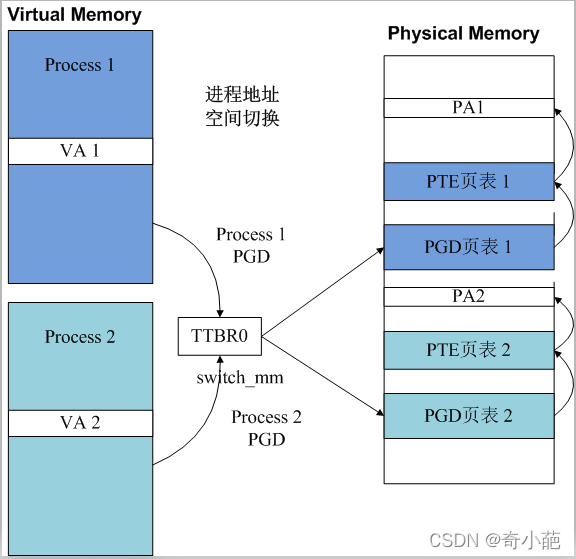
TTBR0指示了进程PGD页表基址,PGD指示了PTE页表基址,PTE指示了物理地址PA。每个进程的PGD不同,因而不同进程虚拟内存对于的物理地址就隔离开了。进程切换switch_mm实质上就是完成TTBR0寄存器的改写。Linux4.99内核调用switch_mm_irqs_off切换用户进程空间,对于没有定义该函数的架构,则调用的是switch_mm。X86体系架构定义了switch_mm_irqs_off函数,ARM体系架构没有定义。


对于swapper的进程,其使用cpu_set_reserved_ttbr0接口如下

那么check_and_switch_context完成了进程地址空间的切换,这包括两部分内容:
- ASID(Address Space ID)和TLB(Translation Lookaside Buffer)的处理;
- TTBR处理。
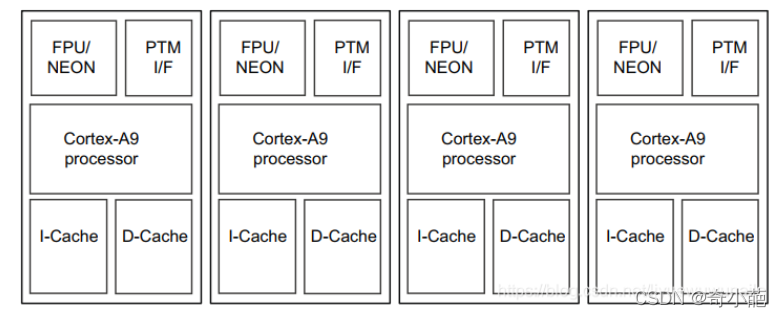
如果next进程发生迁移,在一个新的CPU上执行,则需要flush I-Cache(Instructions Cache)。如下图所示,对于ARM SMP架构来说每个core都有独立的I-Cache和D-Cache(哈佛结构L1 Cache),因而新进程第一次运行到某Core时需要将I-Cache内容全部刷新。
在看代码之前,我们要学习基础的知识,ASID指示了每个TLB entry所属的进程,这样可以保证不同进程之间的TLB entry不会互相干扰,因而避免了切换进程时将TLB刷新的问题。所以ASID作用避免了进程切换时TLB的频繁刷新。
实际上,ARM TLB包含了Global和process-specific表项,即全集类型的TLB和进程独有类型的TLB
-
Global类型TLB entry :用于内核空间地址转换,内核空间为所以进程所共有,因而进程切换时,内核映射关系无需变化,所以其TLB entry也不用变。内核的页表基址寄存器是TTBR1,进程切换时页表不变的。
-
process-specific类型TLB entry :用户进程独立地址空间映射关系。即ASID用于隔离不同进程的TLB entry。
区分Global和process-specific表项则是根据PTE entry的bit11(nG位)。nG位为1时,则表示TLB entry属于进程。

为了支持进程独有类型的TLB,ARM架构出现了一个硬件解决方案,叫进程地址空间ID(address space ID,ASID),TLB可以识别哪些TLB属于某个进程,其方案如下:
- 让每个TLB表项包含一个ASID,ASID用于表示每个进程的地址空间
- TLB命中查询的标准是在原来的虚拟地址判断智商,加上ASID条件,因此有了ASID硬件机制的支持,进程切换不需要刷新整个TLB,即使next进程访问了相同的虚拟地址,prev进程缓存的TLB项页不会影响到next进程
- 当系统中所有CPU的硬件ASID加起来超过硬件最大值时,就会发生溢出,就需要刷新全部的TLB,然后重新分配硬件ASID,并存储在asid_bits变量中
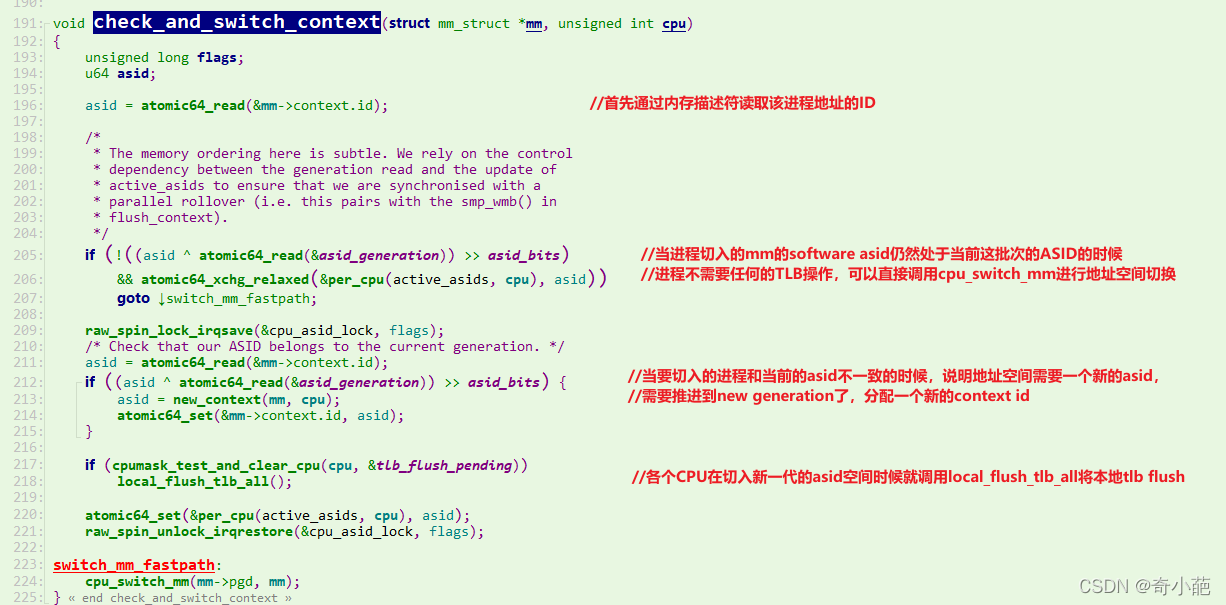
check_and_switch_context函数前面部分主要实现了ASID相关的内容,详细的内容参考进程切换分析(2):TLB处理
- 从mm->context.id原子的获取ASID;
- asid_generation记录ASID溢出,mm->context.id低8位记录ASID,高24位记录了ASID溢出次数,如果没有发生ASID溢出则直接调用cpu_switch_mm切换TTBR0。
- 如果发生ASID溢出则需要为进程重新分配ASID,并记录到mm->context.id中,并刷新TLB。
地址空间切换过程中,会清空tlb,防止当前进程虚拟地址转化过程中命中上一个进程的tlb表项,一般会将所有的tlb无效,但是这会导致很大的性能损失,因为新进程被切换进来的时候面对的是全新的空的tlb,造成很大概率的tlb miss,需要重新遍历多级页表,所以arm64在tlb表项中增加了非全局(nG)位区分内核和进程的页表项,使用ASID区分不同进程的页表项,来保证可以在切换地址空间的时候可以不刷tlb。
cpu_switch_mm调用cpu_do_switch_mm完成进程地址空间切换,该实现在汇编arch/arm64/mm/proc.S中完成

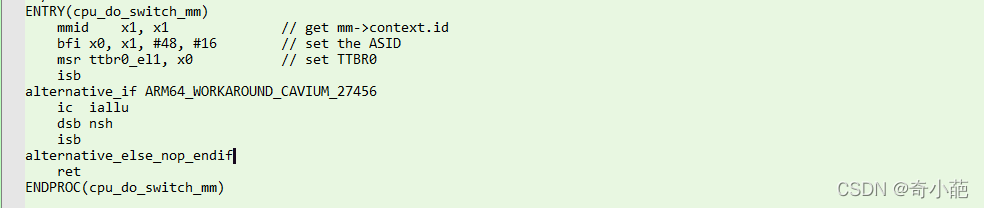
最终将进程的pgd虚拟地址转化为物理地址存放在ttbr0_el1中,这是用户空间的页表基址寄存器,当访问用户空间地址的时候mmu会通过这个寄存器来做遍历页表获得物理地址。完成了这一步,也就完成了进程的地址空间切换,确切的说是进程的虚拟地址空间切换。
3 switch_to函数
处理完TLB和页表基地址后,还需要进行栈空间切换,这样next进程才能开始运行,这个正是switch_to的目的。
extern struct task_struct *__switch_to(struct task_struct *,
struct task_struct *);
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \
} while (0)
函数一共有3个参数,prev表示将要被调度出去的进程prev,next表示将要被调度进来的进程,这里有一个几个困惑
- 为什么switch_to要有3个参数呢?prev和next就能实现进程的切换,为什么还需要last?
- switch_to函数后面的代码该由哪个进程来执行呢?什么时候执行?
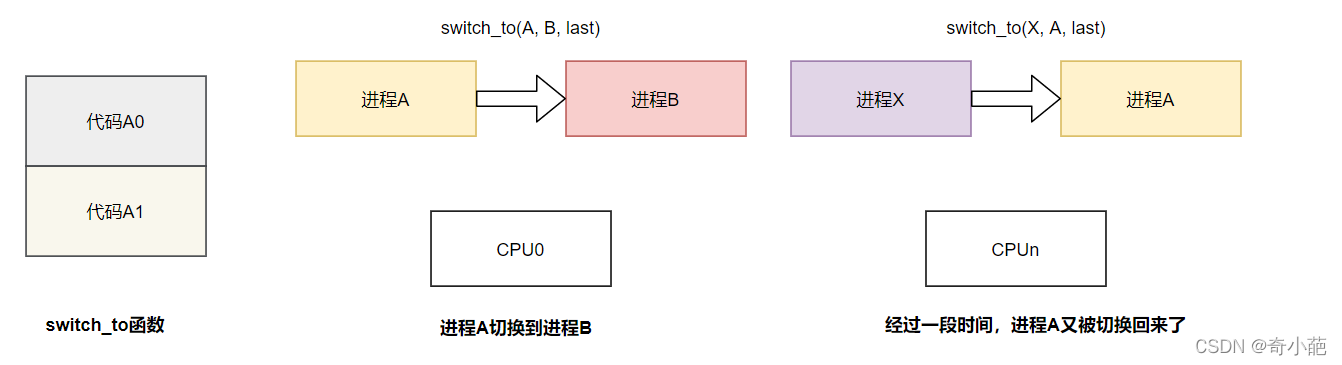
- 假设现在进程A在CPU0上执行了switch_to(A, B, last)函数,以主动的方式切换进程B来执行,那么CPU0切换到进程B的硬件上下文,让进程B运行。当switch_to运行之前,prev参数指向进程A,可是当switch_to函数运行完毕之后,CPU已经运行进程B,此时prev参数就变成了进程B的prev参数,而不是进程A
- 当进程B执行完毕后,又会切换到哪个进程暂时不关注,但是当经历千山万水后,某个CPU上某个进程X执行了调度,A进程又被重新调度的时候,进程A被加载到CPUn上,它会从上次睡眠点开始运行,也就是A1代码片段处。
所以当切换回A进程的时候,该cpu上(也不一定是A调用switch_to切换到B进程的那个CPU)执行的上一个task是谁?这就是第三个参数的含义,实际上这个参数的名字就是last,也就是如何恢复到上一次被调度的片段处。

具体的切换发生在arch/arm64/kernel/entry.S文件中的cpu_switch_to,代码如下:
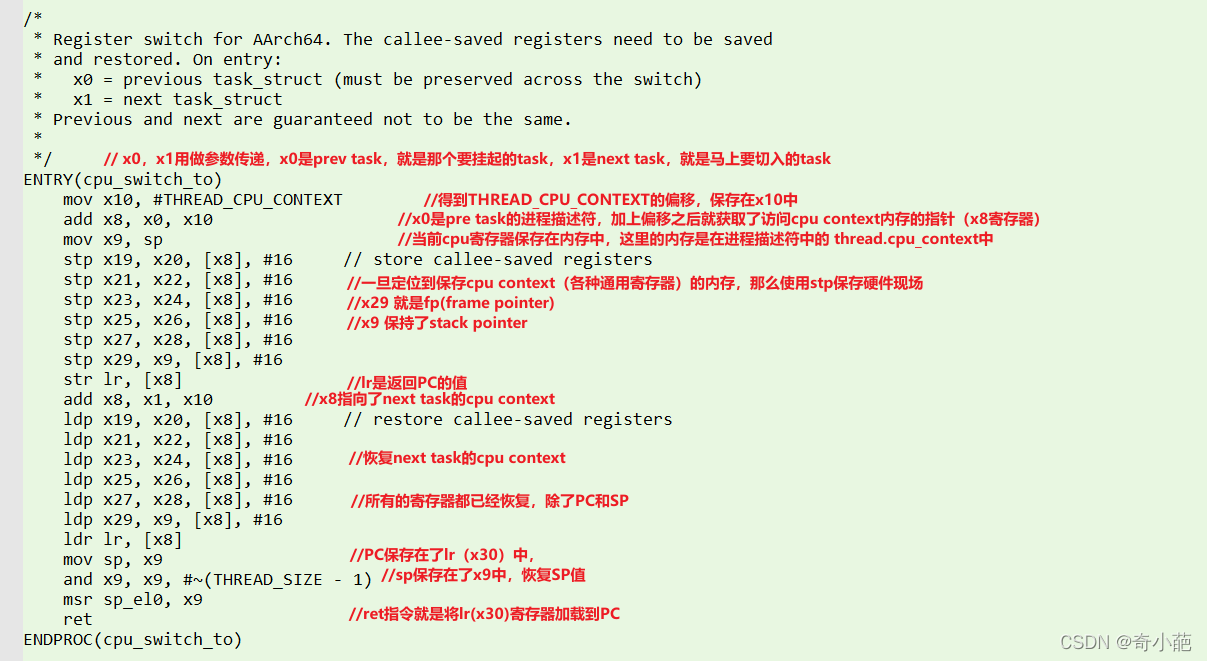
cpu_switch_to要如何保存现场呢?要保存那些通用寄存器,那么就需要符合ARM64标准的过程调用,对于该过程用到了task_struct数据结构里的一个thread_struct的数据结构,用于存放和具体架构相关的信息,对于ARM64定义在arch/arm64/include/asm/processor.h中

这个结构体主要保存CPU的部分状态(寄存器),用来存储内核态切换时的硬件上下文。
- 对于ARM64处理器来说,在进程切换的时,我们需要把prev进程的X19~X28寄存器,FP,SP以及PC寄存器保持到这个cpu_context数据结构中
- 然后把next进程上一次保持的cpu_context的值恢复到实际硬件的寄存器中,这样就完成了进程的上下文切换。
为什么cpu_context数据结构只包含X19X28寄存器,而没有X0X18寄存器?这是跟ARM64架构函数调用的标准和规范有关
- X19~X28寄存器在函数调用过程中需要保存在栈里,因为它们是函数调用者和被调用者公用的数据
- X0~X7寄存器用于传递函数参数,剩余的通用寄存器大多用于临时寄存器,在进程切换中不需要保存
cpu_context数据结构定义如下:
struct cpu_context {
unsigned long x19;
unsigned long x20;
unsigned long x21;
unsigned long x22;
unsigned long x23;
unsigned long x24;
unsigned long x25;
unsigned long x26;
unsigned long x27;
unsigned long x28;
unsigned long fp;
unsigned long sp;
unsigned long pc;
};
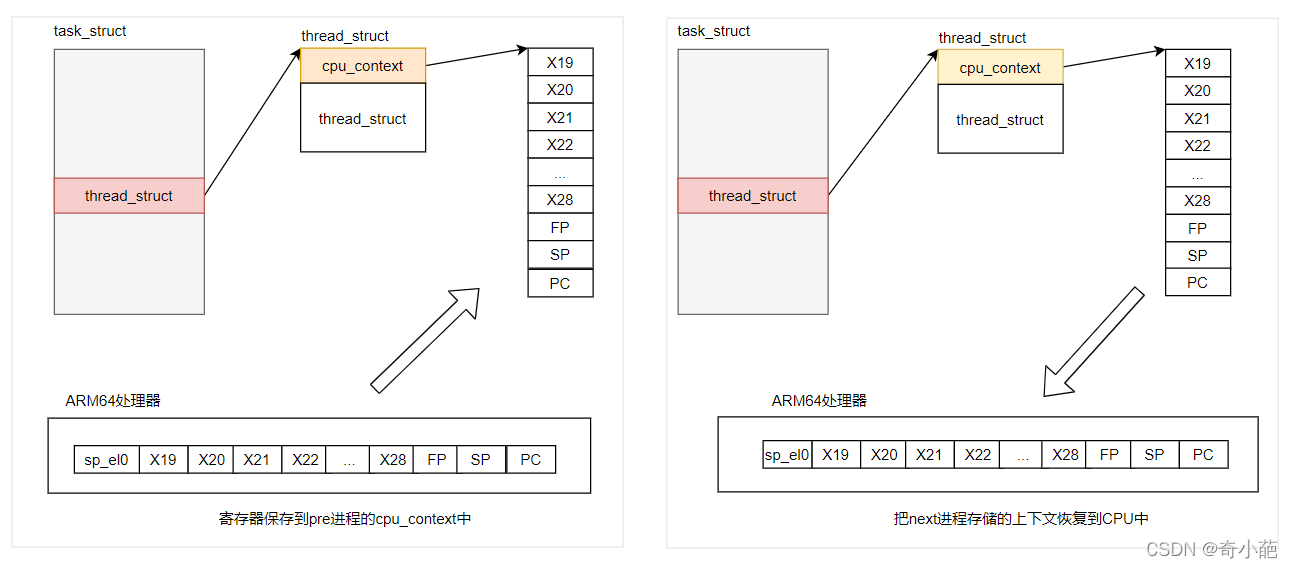
进程上下文切换的过程如下图所示,在切换的过程中,将进程硬件上下文的重要的寄存器保存到prev进程的cpu_context数据结构中,进程上下文的包括X19~X28寄存器,FP寄存器,SP寄存器,PC寄存器,然后将next进程描述符的cpu_contex的x19-x28,fp,sp,pc恢复到相应寄存器中,而且将next进程的进程描述符task_struct地址存放在sp_el0中,用于通过current找到当前进程,这样就完成了处理器的状态切换。
那么内核是如何恢复到用户空间去执行呢?我们知道用户空间通过异常/中断进入到内核空间的时候都需要保存现场,也就是保存发生异常/中断的所有的通用寄存器,内核会将现场保存到每个进程特有的进程内核栈中,当异常/中断处理完毕后会返回到用户空间,返回到之前保存的现场,用户程序继续执行。
当进程重新被调度的时候,从原来的调度的现场恢复执行,如以切换的next进程刚好是fork进程,那么它的lr是什么呢?这个在fork的时候设置的
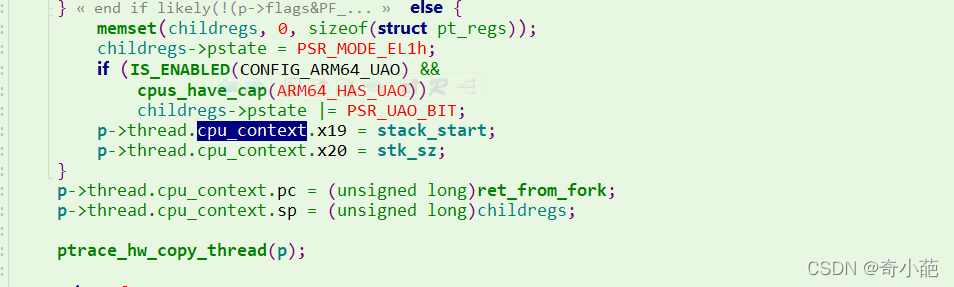
设置为了ret_from_fork的地址,当然这里也设置了sp等调度上下文(这里将进程切换保存的寄存器称之为调度上下文)。

刚fork的进程,从cpu_switch_to的ret指令执行后返回,lr加载到pc。于是执行到ret_from_fork:这里首先调用schedule_tail对前一个进程做清理工作,然后判断是否为内核线程如果是执行内核线程的执行函数,如果是用户任务通过ret_to_user返回到用户态。
4 finish_task_switch
A保存内核栈和寄存器,切换至B,此时prev = A, next = B,该状态会保存在栈里,等下次调用A的时候再恢复。然后调用B的finish_task_switch()继续执行下去,返回B的队列rq,该函数主要是完成任务切换后的清理工作,其注释已经解释的比较明白了
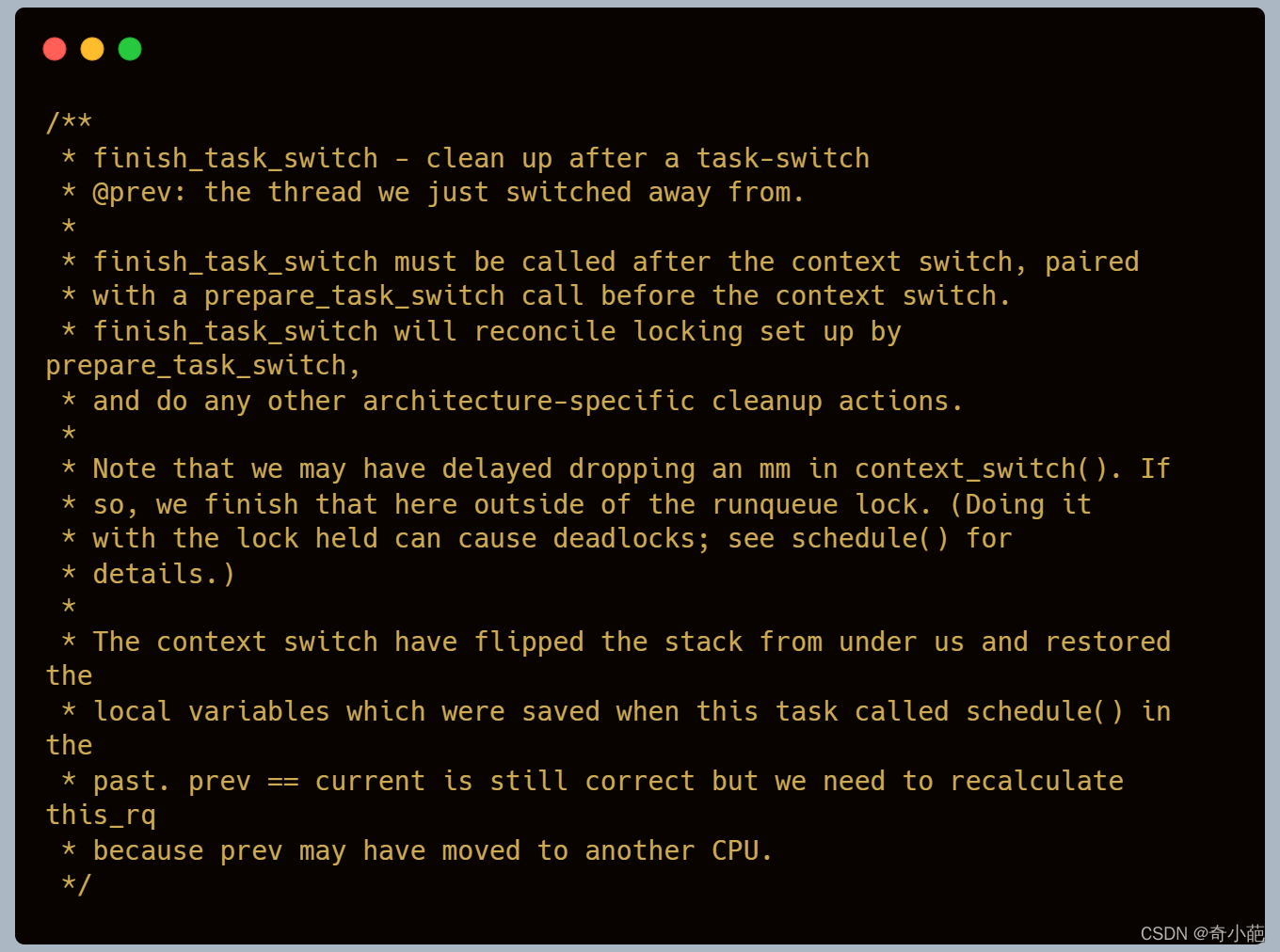
可以看到进程被重新调度时首先需要做的主要是:
- 在上下文切换前调用prepare_task_switch,在切换后调用finish_task_switch,释放之前的锁,并执行任何其他特定于体系结构的清理操作
- 重新使能本地中断 ,进程被重新调度时,本地cpu中断是被重新打开的!!!
- 如果有借用mm的情况,现在归还 如果前一个是内核线程,在进程地址空间切换时“借用了”某个进程的mm_struct,现在切换到了下一个进程,理应归还,归还做的是递减借用的mm_struct的引用计数,引用计数为0就会释放mm_struct占用的内存。
- 对于上一个死亡的进程现在回收最后的资源, 注意这里是递减引用计数,当引用计数为0时才会真正释放。
返回来,我们看当进程 A 在内核里面执行 switch_to 的时候,内核态的指令指针也是指向这一行的。但是在 switch_to 里面,将寄存器和栈都切换到成了进程 B 的,唯一没有变的就是指令指针寄存器。当 switch_to 返回的时候,指令指针寄存器指向了下一条语句 finish_task_switch。
但这个时候的 finish_task_switch 已经不是进程 A 的 finish_task_switch 了,而是进程 B 的 finish_task_switch 了。这样合理吗?我们如何知道进程B当时切换走到时候,执行到哪呢?恢复到B进程一定执行到这里吗?
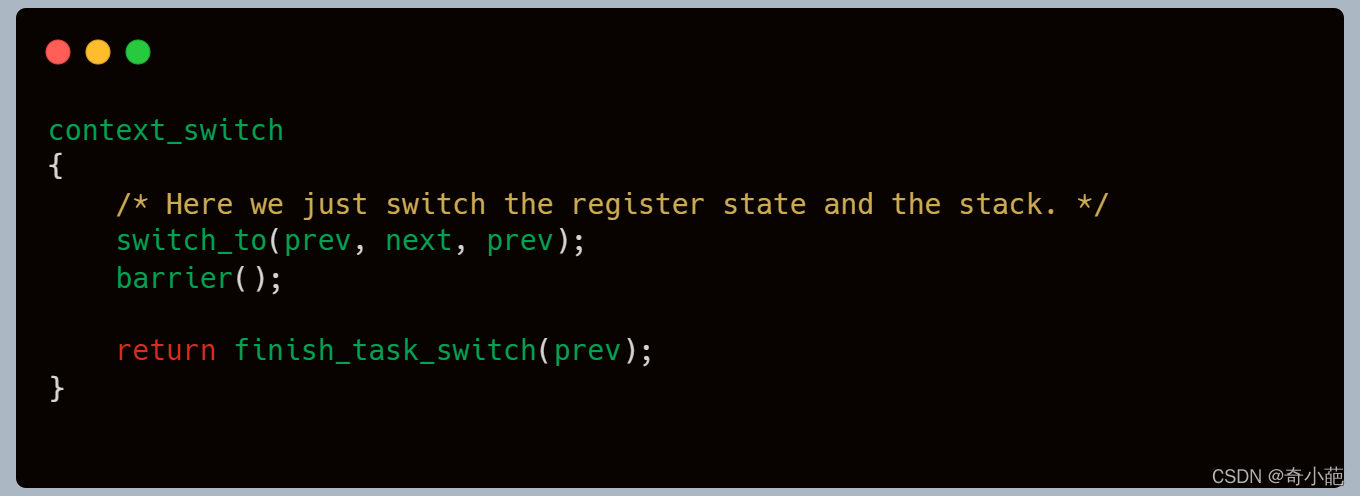
当年 B 进程被别人切换走的时候,也是调用 __schedule,也是调用到 switch_to,被切换成为 C 进程的,所以,B 进程当年的下一个指令也是 finish_task_switch,这就说明指令指针指到这里是没有错的。
5 总结
进程管理中最重要的一步要进行进程上下文切换,其中主要有两大步骤:
- 一是切换进程空间,也即虚拟内存:保证了进程回到用户空间之后能够访问到自己的指令和数据(其中包括减小tlb清空的ASID机制)
- 二是切换寄存器和 CPU 上下文,地址空间切换和处理器状态切换(硬件上下文切换),保证了进程内核栈和执行流的切换,会将当前进程的硬件上下文保存在进程所管理的一块内存,然后将即将执行的进程的硬件上下文从内存中恢复到寄存器
有了这两步的切换过程保证了进程运行的有条不紊,当然切换的过程是在内核空间完成,这对于进程来说是透明的。我们以一个系统调用为例
-
对于用户空间,从进程A切换到进程B,用户栈要不要切换呢?当然要,其实早就已经实现了切换,对于每个进程的用户空间都有独立的用户栈,保存在进程的用户地址空间中
-
对于系统调用,假设进程A在用户空间要写一个文件,因为写文件的操作没办法完成,就需要通过系统调用到达内核态,在这个切换的过程中,用户态的指令指针寄存器保持在pt_regs里面,到了内核态,就开始沿着写文件逻辑一步步的执行,发现需要等待,就会调用schedule函数调度出去
-
因为此时内存里面存储的都是A进程的上下文信息,B是不能马上运行的,需要A进程调用switch_to函数进行上下文的切换工作,在 switch_to 里面,将寄存器和栈都切换到成了进程 B 的,唯一没有变的就是指令指针寄存器。当 switch_to 返回的时候,指令指针寄存器指向了下一条语句 finish_task_switch,B进程就从上次切换的地方重新开始运行
-
假设B进程之前是调用tap_do_read 读网卡的进程。它当年调用 __schedule 的时候,是从 tap_do_read 这个函数调用进去的,当调度返回的时候,页需要接着tap_do_read运行,然后在内核运行完毕,返回用户态
-
这个时候,B 进程内核栈的 pt_regs 也保存了用户态的指令指针寄存器,就接着在用户态的下一条指令开始运行就可以了。
下面是进程由中断原因的导致的进程切换的示意图
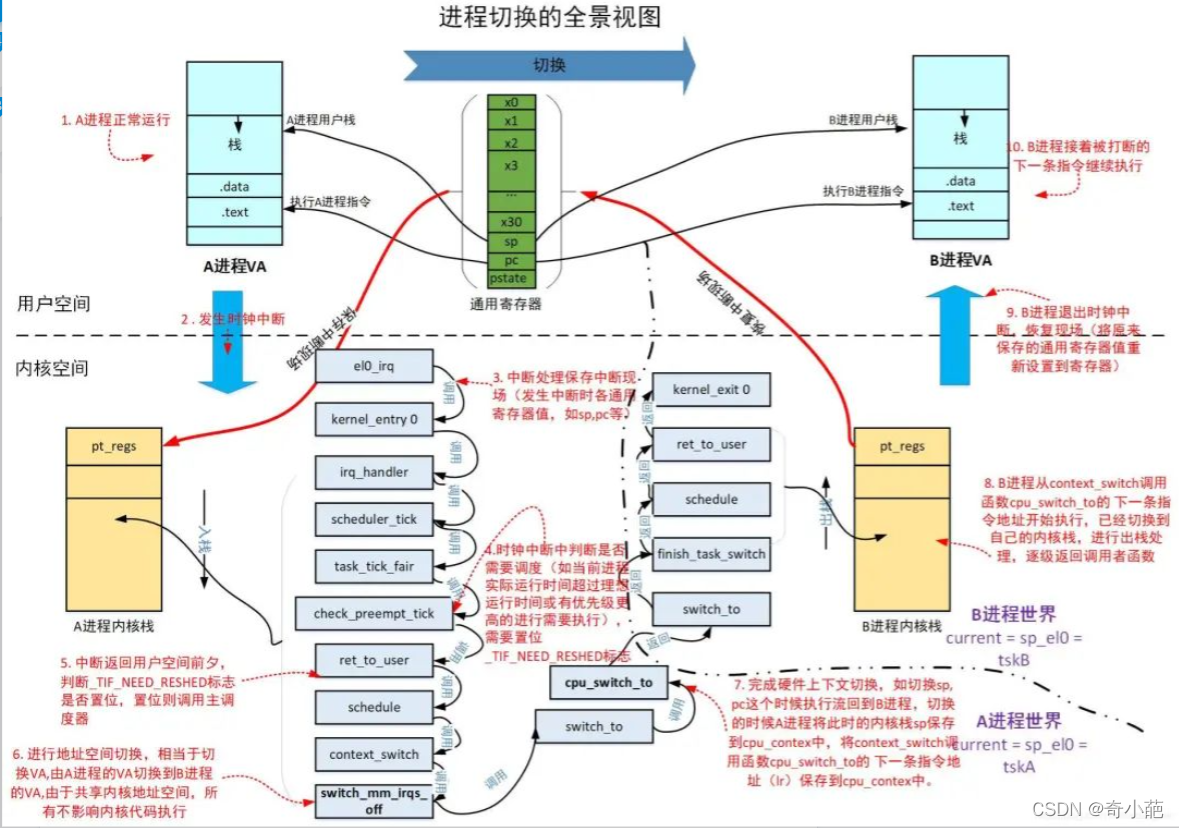
-
1.发生中断时的保存现场,将发生中断时的所有通用寄存器保存到进程的内核栈,使用struct pt_regs结构。
-
2.地址空间切换将进程自己的页全局目录的基地址pgd保存在ttbr0_le1中,用于mmu的页表遍历的起始点。
-
3.硬件上下文切换的时候,将此时的调用保存寄存器和pc, sp保存到struct cpu_context结构中。做好了这几个保存工作,当进程再次被调度回来的时候,通过cpu_context中保存的pc回到了cpu_switch_to的下一条指令继续执行,而由于cpu_context中保存的sp导致当前进程回到自己的内核栈,
-
4. 经过一系列的内核栈的出栈处理,最后将原来保存在pt_regs中的通用寄存器的值恢复到了通用寄存器,这样进程回到用户空间就可以继续沿着被中断打断的下一条指令开始执行,用户栈也回到了被打断之前的位置,而进程访问的指令数据做地址转化(VA到PA)也都是从自己的pgd开始进行,一切对用户来说就好像没有发生一样,简直天衣无缝。
6 参考文档
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
