有序集合类型键实现
1. 有序集合命令
Redis有序集合命令如下表所示:Redis 有序集合命令详解
| 序号 | 命令及描述 |
|---|---|
| 1 | ZADDkeyscore1member1[score2member2]:向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | ZCARDkey:获取有序集合的成员数 |
| 3 | ZCOUNTkeyminmax:计算在有序集合中指定区间分数的成员数 |
| 4 | ZINCRBYkeyincrementmember:有序集合中对指定成员的分数加上增量increment |
| 5 | ZINTERSTOREdestinationnumkeyskey[key…]:计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合key中 |
| 6 | ZLEXCOUNTkeyminmax:在有序集合中计算指定字典区间内成员数量 |
| 7 | ZRANGEkeystartstop[WITHSCORES]:通过索引区间返回有序集合成指定区间内的成员 |
| 8 | ZRANGEBYLEXkeyminmax[LIMIToffsetcount]:通过字典区间返回有序集合的成员 |
| 9 | ZRANGEBYSCOREkeyminmax[WITHSCORES][LIMIT]:通过分数返回有序集合指定区间内的成员 |
| 10 | ZRANKkeymember:返回有序集合中指定成员的索引 |
| 11 | ZREMkeymember[member…]:移除有序集合中的一个或多个成员 |
| 12 | ZREMRANGEBYLEXkeyminmax:移除有序集合中给定的字典区间的所有成员 |
| 13 | ZREMRANGEBYRANKkeystartstop:移除有序集合中给定的排名区间的所有成员 |
| 14 | ZREMRANGEBYSCOREkeyminmax:移除有序集合中给定的分数区间的所有成员 |
| 15 | ZREVRANGEkeystartstop[WITHSCORES]:返回有序集中指定区间内的成员,通过索引,分数从高到底 |
| 16 | ZREVRANGEBYSCOREkeymaxmin[WITHSCORES]:返回有序集中指定分数区间内的成员,分数从高到低排序 |
| 17 | ZREVRANKkeymember:返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| 18 | ZSCOREkeymember:返回有序集中,成员的分数值 |
| 19 | ZUNIONSTOREdestinationnumkeyskey[key…]:计算给定的一个或多个有序集的并集,并存储在新的key中 |
| 20 | ZSCANkeycursor[MATCHpattern][COUNTcount]:迭代有序集合中的元素(包括元素成员和元素分值) |
2. 有序集合类型实现
有序集合对象的底层实现类型如下表:
| 编码—encoding | 对象—ptr |
|---|---|
| OBJ_ENCODING_SKIPLIST | 跳跃表和字典 实现的有序集合对象 |
| OBJ_ENCODING_ZIPLIST | 压缩列表 实现的有序集合对象 |
关于底层的数据结构剖析和实现,请看如下博文
一个有序集合对象的结构如下:
typedef struct redisObject {
//对象的数据类型:OBJ_ZSET
unsigned type:4;
//对象的编码类型:OBJ_ENCODING_SKIPLIST 或 OBJ_ENCODING_ZIPLIST
unsigned encoding:4;
//least recently used
//实用LRU算法计算相对server.lruclock的LRU时间
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
//引用计数
int refcount;
//指向底层数据实现的指针,指向zset结构或ziplist结构
void *ptr;
} robj;
之前提到,编码为 OBJ_ENCODING_SKIPLIST 的底层的数据结构是 跳跃表和字典。因此就抽象了一个zset结构用来保存这两种结构。
typedef struct zset {
dict *dict; //字典
zskiplist *zsl; //跳跃表
} zset; //有序集合跳跃表类型
Redis采用跳跃表和哈希表代替平衡树的原因:具体分析可看 Redis 跳跃表源码剖析
- 跳跃表和平衡树的元素都是有序排列,而哈希表不是有序的。因此在哈希表上的查找只能是单个key的查找,不适合做范围查找。
- 跳跃表和平衡树做范围查找时,跳跃表算法简单,实现方便,而平衡树逻辑复杂。
- 查找单个key,跳跃表和平衡树的平均时间复杂度都为O(logN),而哈希表的时间复杂度为O(N)。
- 跳跃表平均每个节点包含1.33个指针,而平衡树每个节点包含2个指针,更加节约内存。
因此,在 redis中实现有序集合 的办法是: 跳跃表+哈希表
- 跳跃表元素有序,而且可以范围查找,且实现起来比平衡树简单。
- 哈希表查找单个key时间复杂度性能高。
我们创建一个视频播放量的有序集合,有体育sport、卡通carton、电视剧telepaly这三个成员
127.0.0.1:6379> ZADD video:view 1234 sport 888 carton 2345 teleplay
(integer) 3
127.0.0.1:6379> ZRANGE video:view 0 -1 WITHSCORES
1) "carton"
2) "88888"
3) "sport"
4) "123456"
5) "teleplay"
6) "234567"
127.0.0.1:6379> OBJECT ENCODING video:view
"ziplist"
我们可以查看到编码类型是压缩列表,这个 video:view 对象的空间结构如下图所示:

当有序集合类型达到配置文件中的阈值条件时,就会发生编码类型的转换,转换为OBJ_ENCODING_SKIPLIST类型,而且转换是双向的,可以相互转换,默认的条件如下
#define OBJ_ZSET_MAX_ZIPLIST_ENTRIES 128 // ziplist中最多存放的节点数
#define OBJ_ZSET_MAX_ZIPLIST_VALUE 64 // ziplist中最大存放的数据长度
为了简单,我们就用上面的video:view 对象,使用OBJ_ENCODING_SKIPLIST编码方式展示可能的空间结构:
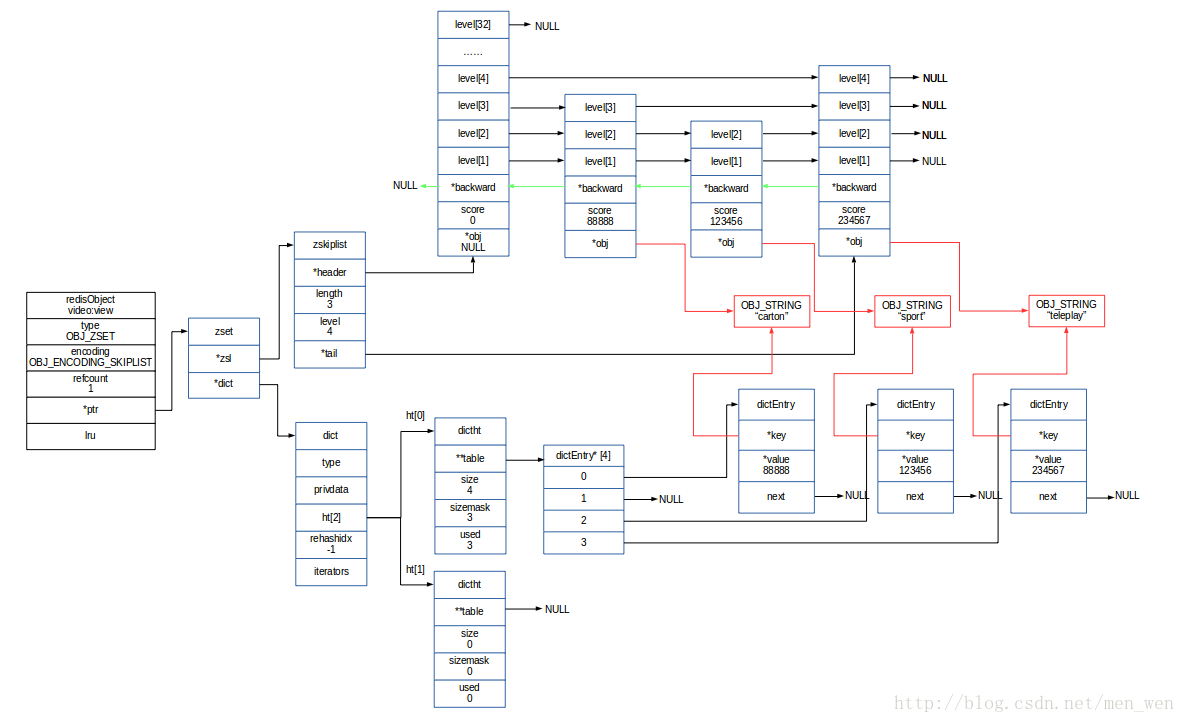
- 红色的是成员,我特地用红色表明,是想说明: OBJ_ENCODING_SKIPLIST 编码方式的有序集合,他的成员在两种数据结构中是共享的,只是简单的增加了引用计数,实际上内存只有一份成员数据。
有序集合基于ziplist的接口封装了一套对于OBJ_ENCODING_SKIPLIST类型的有序集合的API,这些函数大都是zzl开头:Redis有序集合键源码注释
// 从sptr指向的entry中取出有序集合的分值
double zzlGetScore(unsigned char *sptr);
// 返回一个sptr指向entry所构建的字符串类型的对象地址
robj *ziplistGetObject(unsigned char *sptr);
// 比较eptr和cstr指向的元素,返回0表示相等,正整数表示eptr比cstr大
int zzlCompareElements(unsigned char *eptr, unsigned char *cstr, unsigned int clen);
// 返回有序集合的元素个数
unsigned int zzlLength(unsigned char *zl);
// 将当前的元素指针eptr和当前元素分值的指针sptr都指向下一个元素和元素的分值
void zzlNext(unsigned char *zl, unsigned char **eptr, unsigned char **sptr);
// 将当前的元素指针eptr和当前元素分值的指针sptr都指向上一个元素和元素的分值
void zzlPrev(unsigned char *zl, unsigned char **eptr, unsigned char **sptr);
// 判断ziplist中是否有entry节点在range范围之内,有一个则返回1,否则返回0
int zzlIsInRange(unsigned char *zl, zrangespec *range);
// 返回第一个满足range范围的entry节点的地址
unsigned char *zzlFirstInRange(unsigned char *zl, zrangespec *range);
// 返回最后一个满足range范围的entry节点的地址
unsigned char *zzlLastInRange(unsigned char *zl, zrangespec *range);
// 比较p指向的entry的值和规定范围spec,返回1表示大于spec的最大值
static int zzlLexValueGteMin(unsigned char *p, zlexrangespec *spec);
// 比较p指向的entry的值和规定范围spec,返回1表示小于spec的最小值
static int zzlLexValueLteMax(unsigned char *p, zlexrangespec *spec);
// 判断ziplist中是否有entry节点在range范围之内,有一个则返回1,否则返回0
int zzlIsInLexRange(unsigned char *zl, zlexrangespec *range);
// 返回第一个满足range范围的元素的地址
unsigned char *zzlFirstInLexRange(unsigned char *zl, zlexrangespec *range);
// 返回最后一个满足range范围的元素的地址
unsigned char *zzlLastInLexRange(unsigned char *zl, zlexrangespec *range);
// 从ziplist中查找ele,将分值保存在score中
unsigned char *zzlFind(unsigned char *zl, robj *ele, double *score);
// 删除eptr制定的元素和分值从ziplist中
unsigned char *zzlDelete(unsigned char *zl, unsigned char *eptr);
//将ele元素和分值score插入到eptr指向节点的前面
unsigned char *zzlInsertAt(unsigned char *zl, unsigned char *eptr, robj *ele, double score);
//将ele元素和分值score插入在ziplist中,从小到大排序
unsigned char *zzlInsert(unsigned char *zl, robj *ele, double score);
// 删除ziplist中分值在制定范围内的元素,并保存删除的数量在deleted中
unsigned char *zzlDeleteRangeByScore(unsigned char *zl, zrangespec *range, unsigned long *deleted)
// 删除ziplist中分值在制定字典序范围内的元素,并保存删除的数量在deleted中
unsigned char *zzlDeleteRangeByLex(unsigned char *zl, zlexrangespec *range, unsigned long *deleted);
// 删除给定下标范围内的所有元素
unsigned char *zzlDeleteRangeByRank(unsigned char *zl, unsigned int start, unsigned int end, unsigned long *deleted);
这些API都是基于ziplist的结构封装,没有直接使用ziplist的接口原因是: 因为元素和分值都是成对保存在ziplist的节点中,基于ziplist接口封装,是为了更简答的操作有序集合类型的数据。
而OBJ_ENCODING_SKIPLIST类型的有序集合,Redis则是直接使用跳跃表和字典所提供的接口。
因此,有序集合类型的API如下:Redis有序集合键源码注释
// 返回有序集合的元素个数
unsigned int zsetLength(robj *zobj)
// 将有序集合对象的编码转换为encoding制定的编码类型
void zsetConvert(robj *zobj, int encoding)
// 按需转换编码成OBJ_ENCODING_ZIPLIST
void zsetConvertToZiplistIfNeeded(robj *zobj, size_t maxelelen)
// 将有序集合的member成员的分值保存到score中
int zsetScore(robj *zobj, robj *member, double *score)
3. 有序集合的迭代器
有序集合在t_zset.c中定义了迭代器,迭代器适用于有序集合和集合。
// 集合类型的迭代器
typedef struct {
robj *subject; //所属的对象
int type; /* Set, sorted set */ //对象的类型,可以是集合或有序集合
int encoding; //编码
double weight; //权重
union {
/* Set iterators. */ //集合迭代器
union _iterset {
struct { //intset迭代器
intset *is; //所属的intset
int ii; //intset节点下标
} is;
struct { //字典迭代器
dict *dict; //所属的字典
dictIterator *di; //字典的迭代器
dictEntry *de; //当前指向的字典节点
} ht;
} set;
/* Sorted set iterators. */ //有序集合迭代器
union _iterzset { //ziplist迭代器
struct {
unsigned char *zl; //所属的ziplist
unsigned char *eptr, *sptr; //当前指向的元素和分值
} zl;
struct { //zset迭代器
zset *zs; //所属的zset
zskiplistNode *node; //当前指向的跳跃节点
} sl;
} zset;
} iter;
} zsetopsrc;
// 集合迭代器和有序集合迭代器是一个共用体union,因此,不会浪费空间。
在实现迭代的过程中,由于迭代器指向的节点可能数据类型各不相同,有对象、有字符串、有整数,因此Redis又定义了一个保存这些类型的统一结构:
/* Store value retrieved from the iterator. */
// 从集合类型迭代器中恢复存储的值
typedef struct {
int flags;
unsigned char _buf[32]; /* Private buffer. */
// 保存元素的各种类型
robj *ele; //对象
unsigned char *estr; //ziplist
unsigned int elen;
long long ell;
// 保存分值
double score;
} zsetopval;
定义了zsetopval结构,还可以实现内部各种类型的数据进行转换,例如:根据estr的值,转换成ele对象类型。
当然,还为迭代器定义了一些接口,使用起来方便,函数名字都是以zui开头:Redis有序集合键源码注释
// 初始化迭代器
void zuiInitIterator(zsetopsrc *op)
// 释放迭代器空间
void zuiClearIterator(zsetopsrc *op)
// 返回正在被迭代的元素的长度
int zuiLength(zsetopsrc *op)
// 将当前迭代器指向的元素保存到val中,并更新指向,指向下一个元素
int zuiNext(zsetopsrc *op, zsetopval *val)
// 根据val设置longlong值
int zuiLongLongFromValue(zsetopval *val)
// 根据val中的值,创建对象
robj *zuiObjectFromValue(zsetopval *val)
// 从val中取出字符串
int zuiBufferFromValue(zsetopval *val)
// 在迭代器制定的对象中查找给定的元素,找到返回1,没找到返回0
int zuiFind(zsetopsrc *op, zsetopval *val, double *score)
// 对比两个被迭代对象的元素的个数,返回差值
int zuiCompareByCardinality(const void *s1, const void *s2)
4. 有序集合的范围限定方式
Redis有序集合有三种范围限定
- 根据字典区间
- 根据排位区间
- 根据分值区间
以上三种主要依赖两种排序方式
- 分值序
- 字典序
以上两种排序所表示的范围,依赖于两个结构,一个规定分值序的范围和边界,一个规定字典序的范围和边界。
/* Struct to hold a inclusive/exclusive range spec by score comparison. */
// 分值序的范围和边界
typedef struct {
double min, max; //最小值和最大值
//minex表示最小值是否包含在这个范围,1表示不包含,0表示包含
//同理maxex表示最大值
int minex, maxex; /* are min or max exclusive? */
} zrangespec;
/* Struct to hold an inclusive/exclusive range spec by lexicographic comparison. */
// 字典序的范围和边界
typedef struct {
robj *min, *max; /* May be set to shared.(minstring|maxstring) *///最小值和最大值
//minex表示最小值是否包含在这个范围,1表示不包含,0表示包含
//同理maxex表示最大值
int minex, maxex; /* are min or max exclusive? */
} zlexrangespec;
这两种区别就是:zrangespec不需要释放,而zlexrangespec需要释放空间,因为字典序的最大值和最小值对象可能是共享的。
因为上面的两种区别,因此在有序集合命令实现时,也是非常麻烦,例如ZRANGEBYLEX和ZRANGEBYSCORE命令,由于排序范围和边界,都抽象成一个结构体,所以代码逻辑几乎一致,但是字典序的多了释放空间这一步,否则就可以用一个函数实现这两种不同排序。
5. 有序集合类型命令的实现
有序集合命令实现具体请看:Redis有序集合键源码注释 这里只剖析个别命令:Redis 有序集合命令详解
- ZUNIONSTORE ZINTERSTORE 命令的底层实现:
有序集合计算交集的一般算法 :先将所有集合按元素个数从小到大排序,然后以元素个数最少的集合,也就是第一个集合为基数,遍历该集合的所有元素,如果元素在之后的所有集合都存在,则加入结果集中。
有序集合计算并集的一般算法 :先将所有集合按元素个数从小到大排序,遍历所有的集合的所有元素,将元素添加到结果集中,如果元素已不存在,则添加,否则操作下一个元素。
#define REDIS_AGGR_SUM 1 //和
#define REDIS_AGGR_MIN 2 //最小数
#define REDIS_AGGR_MAX 3 //最大数
//默认使用的参数 SUM ,可以将所有集合中某个成员的 score 值之 和 作为结果集中该成员的 score 值;
//使用参数 MIN ,可以将所有集合中某个成员的 最小 score 值作为结果集中该成员的 score 值;
//而参数 MAX 则是将所有集合中某个成员的 最大 score 值作为结果集中该成员的 score 值。
// ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]
// ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]
// ZUNIONSTORE ZINTERSTORE命令的底层实现
void zunionInterGenericCommand(client *c, robj *dstkey, int op) {
int i, j;
long setnum;
int aggregate = REDIS_AGGR_SUM; //默认是求和
zsetopsrc *src;
zsetopval zval;
robj *tmp;
unsigned int maxelelen = 0; //判断是否需要编码转换的条件之一
robj *dstobj;
zset *dstzset;
zskiplistNode *znode;
int touched = 0;
/* expect setnum input keys to be given */
// 取出numkeys参数值,保存在setnum中
if ((getLongFromObjectOrReply(c, c->argv[2], &setnum, NULL) != C_OK))
return;
// 至少指定一个key
if (setnum < 1) {
addReplyError(c,
"at least 1 input key is needed for ZUNIONSTORE/ZINTERSTORE");
return;
}
/* test if the expected number of keys would overflow */
// setnum与key数量不匹配,发送语法错误信息
if (setnum > c->argc-3) {
addReply(c,shared.syntaxerr);
return;
}
/* read keys to be used for input */
// 为每一个key分配一个迭代器空间
src = zcalloc(sizeof(zsetopsrc) * setnum);
// 遍历
for (i = 0, j = 3; i < setnum; i++, j++) {
// 以写方式读取出有序集合
robj *obj = lookupKeyWrite(c->db,c->argv[j]);
if (obj != NULL) { //检查读取出的集合类型,否则发送信息
if (obj->type != OBJ_ZSET && obj->type != OBJ_SET) {
zfree(src);
addReply(c,shared.wrongtypeerr);
return;
}
// 初始化每个集合对象的迭代器
src[i].subject = obj;
src[i].type = obj->type;
src[i].encoding = obj->encoding;
} else {
src[i].subject = NULL; //集合对象不存在则设置为NULL
}
/* Default all weights to 1. */
src[i].weight = 1.0; //默认权重为1.0
}
/* parse optional extra arguments */
// 解析其他的参数
if (j < c->argc) {
int remaining = c->argc - j; //其他参数的数量
while (remaining) {
// 设置了权重WEIGHTS参数
if (remaining >= (setnum + 1) && !strcasecmp(c->argv[j]->ptr,"weights")) {
j++; remaining--;
// 遍历设置的weight,保存到每个集合对象的迭代器中
for (i = 0; i < setnum; i++, j++, remaining--) {
if (getDoubleFromObjectOrReply(c,c->argv[j],&src[i].weight,
"weight value is not a float") != C_OK)
{
zfree(src);
return;
}
}
// 设置了集合方式AGGREGATE参数
} else if (remaining >= 2 && !strcasecmp(c->argv[j]->ptr,"aggregate")) {
j++; remaining--;
// 根据不同的参数,设置默认的方式
if (!strcasecmp(c->argv[j]->ptr,"sum")) {
aggregate = REDIS_AGGR_SUM;
} else if (!strcasecmp(c->argv[j]->ptr,"min")) {
aggregate = REDIS_AGGR_MIN;
} else if (!strcasecmp(c->argv[j]->ptr,"max")) {
aggregate = REDIS_AGGR_MAX;
} else {
zfree(src);
addReply(c,shared.syntaxerr); //不是以上三种集合方式,发送语法错误信息
return;
}
j++; remaining--;
} else {
zfree(src);
addReply(c,shared.syntaxerr); //不是以上两种参数,发送语法错误信息
return;
}
}
}
/* sort sets from the smallest to largest, this will improve our
* algorithm's performance */
// 对所有集合元素的多少,从小到大排序,提高算法性能
qsort(src,setnum,sizeof(zsetopsrc),zuiCompareByCardinality);
dstobj = createZsetObject(); //创建结果集对象
dstzset = dstobj->ptr;
memset(&zval, 0, sizeof(zval)); //初始化保存有序集合元素和分值的结构
// ZINTERSTORE命令
if (op == SET_OP_INTER) {
/* Skip everything if the smallest input is empty. */
// 如果当前集合没有元素,则不处理
if (zuiLength(&src[0]) > 0) {
/* Precondition: as src[0] is non-empty and the inputs are ordered
* by size, all src[i > 0] are non-empty too. */
// 初始化元素最少的有序集合
zuiInitIterator(&src[0]);
// 遍历元素最少的有序集合的每一个元素,将元素的分值和数值保存到zval中
while (zuiNext(&src[0],&zval)) {
double score, value;
// 计算加权分值
score = src[0].weight * zval.score;
if (isnan(score)) score = 0;
// 遍历其后的每一个有序集合,分别跟元素最少的有序集合做运算
for (j = 1; j < setnum; j++) {
/* It is not safe to access the zset we are
* iterating, so explicitly check for equal object. */
// 如果输入的key一样
if (src[j].subject == src[0].subject) {
// 计算新的加权分值
value = zval.score*src[j].weight;
// 根据集合方式sum、min、max保存结果值到score
zunionInterAggregate(&score,value,aggregate);
// 输入的key与第一个key不一样,在当前key查找当前的元素,并将找到元素的分值保存在value中
} else if (zuiFind(&src[j],&zval,&value)) {
// 计算加权后的分值
value *= src[j].weight;
// 根据集合方式sum、min、max保存结果值到score
zunionInterAggregate(&score,value,aggregate);
// 如果当前元素在所有有序集合中没有找到,则跳过for循环,处理下一个元素
} else {
break;
}
}
/* Only continue when present in every input. */
// 如果没有跳出for循环,那么该元素一定是每个key集合中都存在,因此进行ZINTER的STORE操作
if (j == setnum) {
tmp = zuiObjectFromValue(&zval); //创建当前元素的对象
znode = zslInsert(dstzset->zsl,score,tmp); //插入到有序集合中
incrRefCount(tmp); /* added to skiplist */
dictAdd(dstzset->dict,tmp,&znode->score); //加入到字典中
incrRefCount(tmp); /* added to dictionary */
if (sdsEncodedObject(tmp)) { //如果是字符串编码的对象
if (sdslen(tmp->ptr) > maxelelen) //更新最大长度
maxelelen = sdslen(tmp->ptr);
}
}
}
zuiClearIterator(&src[0]); //释放集合类型的迭代器
}
// ZUNIONSTORE命令
} else if (op == SET_OP_UNION) {
dict *accumulator = dictCreate(&setDictType,NULL); //创建一个临时字典作为结果集字典
dictIterator *di;
dictEntry *de;
double score;
// 计算出最大有序集合元素个数,并集至少和最大的集合一样大,因此按需扩展结果集字典
if (setnum) {
/* Our union is at least as large as the largest set.
* Resize the dictionary ASAP to avoid useless rehashing. */
dictExpand(accumulator,zuiLength(&src[setnum-1]));
}
/* Step 1: Create a dictionary of elements -> aggregated-scores
* by iterating one sorted set after the other. */
// 1.遍历所有的集合
for (i = 0; i < setnum; i++) {
if (zuiLength(&src[i]) == 0) continue; //跳过空集合
zuiInitIterator(&src[i]); //初始化集合迭代器
// 遍历当前集合的所有元素,迭代器当前指向的元素保存在zval中
while (zuiNext(&src[i],&zval)) {
/* Initialize value */
score = src[i].weight * zval.score; //初始化分值
if (isnan(score)) score = 0;
/* Search for this element in the accumulating dictionary. */
// 从结果集字典中找当前元素
de = dictFind(accumulator,zuiObjectFromValue(&zval));
/* If we don't have it, we need to create a new entry. */
// 如果在结果集中找不到,则加入到结果集中
if (de == NULL) {
tmp = zuiObjectFromValue(&zval); //创建元素对象
/* Remember the longest single element encountered,
* to understand if it's possible to convert to ziplist
* at the end. */
if (sdsEncodedObject(tmp)) { //字符串类型的话要更新maxelelen
if (sdslen(tmp->ptr) > maxelelen)
maxelelen = sdslen(tmp->ptr);
}
/* Add the element with its initial score. */
de = dictAddRaw(accumulator,tmp); //加入到结果集字典中
incrRefCount(tmp);
dictSetDoubleVal(de,score); //设置元素的分值
// 如果在结果集中可以找到
} else {
/* Update the score with the score of the new instance
* of the element found in the current sorted set.
*
* Here we access directly the dictEntry double
* value inside the union as it is a big speedup
* compared to using the getDouble/setDouble API. */
zunionInterAggregate(&de->v.d,score,aggregate); //更新加权分值
}
}
zuiClearIterator(&src[i]); //清理当前集合的迭代器
}
/* Step 2: convert the dictionary into the final sorted set. */
// 2. 创建字典的迭代器,遍历结果集字典
di = dictGetIterator(accumulator);
/* We now are aware of the final size of the resulting sorted set,
* let's resize the dictionary embedded inside the sorted set to the
* right size, in order to save rehashing time. */
// 按需扩展结果集合中的字典成员
dictExpand(dstzset->dict,dictSize(accumulator));
// 遍历结果集字典,
while((de = dictNext(di)) != NULL) {
// 获得元素对象和分值
robj *ele = dictGetKey(de);
score = dictGetDoubleVal(de);
// 插入到结果集合的跳跃表中
znode = zslInsert(dstzset->zsl,score,ele);
incrRefCount(ele); /* added to skiplist */
// 添加到结果集合的字典中
dictAdd(dstzset->dict,ele,&znode->score);
incrRefCount(ele); /* added to dictionary */
}
dictReleaseIterator(di); //释放字典的迭代器
/* We can free the accumulator dictionary now. */
dictRelease(accumulator); //释放临时保存结果的字典
} else {
serverPanic("Unknown operator");
}
// 删除已经存在的dstkey,并做标记
if (dbDelete(c->db,dstkey))
touched = 1;
// 如果结果集元素不为0
if (dstzset->zsl->length) {
zsetConvertToZiplistIfNeeded(dstobj,maxelelen); //按需进行编码转换
dbAdd(c->db,dstkey,dstobj); //将数据库中的dstkey和dstobj关联成对
addReplyLongLong(c,zsetLength(dstobj)); //发送结果集合的元素数量给client
signalModifiedKey(c->db,dstkey); //发送键被修改的信号
notifyKeyspaceEvent(NOTIFY_ZSET, //发送对应的事件通知
(op == SET_OP_UNION) ? "zunionstore" : "zinterstore",
dstkey,c->db->id);
server.dirty++; //更新脏键
// 结果集没有元素,释放对象,发送0给client
} else {
decrRefCount(dstobj);
addReply(c,shared.czero);
if (touched) {
signalModifiedKey(c->db,dstkey);
notifyKeyspaceEvent(NOTIFY_GENERIC,"del",dstkey,c->db->id);
server.dirty++;
}
}
zfree(src); //释放集合迭代器数组空间
}
- ZRANGEBYSCORE ZREVRANGEBYSCORE命令的底层实现
/* This command implements ZRANGEBYSCORE, ZREVRANGEBYSCORE. */
// ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
// ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
// ZRANGEBYSCORE ZREVRANGEBYSCORE命令的底层实现
void genericZrangebyscoreCommand(client *c, int reverse) {
zrangespec range;
robj *key = c->argv[1];
robj *zobj;
long offset = 0, limit = -1;
int withscores = 0;
unsigned long rangelen = 0;
void *replylen = NULL;
int minidx, maxidx;
/* Parse the range arguments. */
// 解析min和max范围的参数的下标
if (reverse) {
/* Range is given as [max,min] */
maxidx = 2; minidx = 3;
} else {
/* Range is given as [min,max] */
minidx = 2; maxidx = 3;
}
// 解析min和max范围参数,保存到zrangespec中,默认是包含[]临界值
if (zslParseRange(c->argv[minidx],c->argv[maxidx],&range) != C_OK) {
addReplyError(c,"min or max is not a float");
return;
}
/* Parse optional extra arguments. Note that ZCOUNT will exactly have
* 4 arguments, so we'll never enter the following code path. */
// 解析其他的参数
if (c->argc > 4) {
int remaining = c->argc - 4; //其他参数个数
int pos = 4;
while (remaining) {
// 如果有WITHSCORES,设置标志
if (remaining >= 1 && !strcasecmp(c->argv[pos]->ptr,"withscores")) {
pos++; remaining--;
withscores = 1;
// 如果有LIMIT,取出offset和count值 保存在offset和limit中
} else if (remaining >= 3 && !strcasecmp(c->argv[pos]->ptr,"limit")) {
if ((getLongFromObjectOrReply(c, c->argv[pos+1], &offset, NULL) != C_OK) ||
(getLongFromObjectOrReply(c, c->argv[pos+2], &limit, NULL) != C_OK)) return;
pos += 3; remaining -= 3;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
}
/* Ok, lookup the key and get the range */
// 以读操作取出有序集合对象
if ((zobj = lookupKeyReadOrReply(c,key,shared.emptymultibulk)) == NULL ||
checkType(c,zobj,OBJ_ZSET)) return;
// ziplist
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl = zobj->ptr;
unsigned char *eptr, *sptr;
unsigned char *vstr;
unsigned int vlen;
long long vlong;
double score;
/* If reversed, get the last node in range as starting point. */
// 获得range范围内的起始元素节点地址
if (reverse) {
eptr = zzlLastInRange(zl,&range);
} else {
eptr = zzlFirstInRange(zl,&range);
}
/* No "first" element in the specified interval. */
// 没有元素在range里,发送空回复
if (eptr == NULL) {
addReply(c, shared.emptymultibulk);
return;
}
/* Get score pointer for the first element. */
serverAssertWithInfo(c,zobj,eptr != NULL);
// 分值节点地址
sptr = ziplistNext(zl,eptr);
/* We don't know in advance how many matching elements there are in the
* list, so we push this object that will represent the multi-bulk
* length in the output buffer, and will "fix" it later */
// 回复长度
replylen = addDeferredMultiBulkLength(c);
/* If there is an offset, just traverse the number of elements without
* checking the score because that is done in the next loop. */
// 跳过offset设定的长度
while (eptr && offset--) {
if (reverse) {
zzlPrev(zl,&eptr,&sptr);
} else {
zzlNext(zl,&eptr,&sptr);
}
}
// 遍历所有符合范围的节点
while (eptr && limit--) {
score = zzlGetScore(sptr); //获取分值
/* Abort when the node is no longer in range. */
// 检查分值是否符合范围内的分值
if (reverse) {
if (!zslValueGteMin(score,&range)) break;
} else {
if (!zslValueLteMax(score,&range)) break;
}
/* We know the element exists, so ziplistGet should always succeed */
serverAssertWithInfo(c,zobj,ziplistGet(eptr,&vstr,&vlen,&vlong)); //保存当前元素的值到参数中
rangelen++;
// 不同元素类型,发送不同的类型的值给client
if (vstr == NULL) {
addReplyBulkLongLong(c,vlong);
} else {
addReplyBulkCBuffer(c,vstr,vlen);
}
if (withscores) {
addReplyDouble(c,score); //发送分值
}
/* Move to next node */
// 指向下一个元素和分值节点
if (reverse) {
zzlPrev(zl,&eptr,&sptr);
} else {
zzlNext(zl,&eptr,&sptr);
}
}
// 跳跃表
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplist *zsl = zs->zsl;
zskiplistNode *ln;
/* If reversed, get the last node in range as starting point. */
// 获得range范围内的起始节点地址
if (reverse) {
ln = zslLastInRange(zsl,&range);
} else {
ln = zslFirstInRange(zsl,&range);
}
/* No "first" element in the specified interval. */
// 没有元素存在在制定的范围内
if (ln == NULL) {
addReply(c, shared.emptymultibulk);
return;
}
/* We don't know in advance how many matching elements there are in the
* list, so we push this object that will represent the multi-bulk
* length in the output buffer, and will "fix" it later */
// 回复长度
replylen = addDeferredMultiBulkLength(c);
/* If there is an offset, just traverse the number of elements without
* checking the score because that is done in the next loop. */
// 跳过offset个节点
while (ln && offset--) {
if (reverse) {
ln = ln->backward;
} else {
ln = ln->level[0].forward;
}
}
// 遍历所有符合范围的节点
while (ln && limit--) {
/* Abort when the node is no longer in range. */
// 检查分值是否符合
if (reverse) {
if (!zslValueGteMin(ln->score,&range)) break;
} else {
if (!zslValueLteMax(ln->score,&range)) break;
}
rangelen++;
addReplyBulk(c,ln->obj); //发送元素
if (withscores) {
addReplyDouble(c,ln->score); //发送分值
}
/* Move to next node */
// 指向下一个节点
if (reverse) {
ln = ln->backward;
} else {
ln = ln->level[0].forward;
}
}
} else {
serverPanic("Unknown sorted set encoding");
}
if (withscores) { //更新回复长度
rangelen *= 2;
}
setDeferredMultiBulkLength(c, replylen, rangelen); //发送范围的长度
}
- ZRANK ZREVRANK命令底层实现
// ZRANK key member
// ZREVRANK key member
// ZRANK ZREVRANK命令底层实现
void zrankGenericCommand(client *c, int reverse) {
robj *key = c->argv[1];
robj *ele = c->argv[2];
robj *zobj;
unsigned long llen;
unsigned long rank;
// 以读操作取出有序集合对象
if ((zobj = lookupKeyReadOrReply(c,key,shared.nullbulk)) == NULL ||
checkType(c,zobj,OBJ_ZSET)) return;
llen = zsetLength(zobj); //获得集合元素数量
serverAssertWithInfo(c,ele,sdsEncodedObject(ele)); //member参数必须是字符串类型对象
// ziplist
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl = zobj->ptr;
unsigned char *eptr, *sptr;
eptr = ziplistIndex(zl,0); //元素节点地址
serverAssertWithInfo(c,zobj,eptr != NULL);
sptr = ziplistNext(zl,eptr);//分值节点地址
serverAssertWithInfo(c,zobj,sptr != NULL);
rank = 1;//排位
while(eptr != NULL) {
// 比较当前元素和member参数的大小
if (ziplistCompare(eptr,ele->ptr,sdslen(ele->ptr)))
break;
rank++; //如果大于,排位加1
zzlNext(zl,&eptr,&sptr); //指向下个元素和分值
}
// 发送排位值
if (eptr != NULL) {
if (reverse)
addReplyLongLong(c,llen-rank);
else
addReplyLongLong(c,rank-1);
} else {
addReply(c,shared.nullbulk);
}
// skiplist
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplist *zsl = zs->zsl;
dictEntry *de;
double score;
ele = c->argv[2]; //member参数
de = dictFind(zs->dict,ele); //查找保存member的节点地址
if (de != NULL) {
score = *(double*)dictGetVal(de); //获得分值
rank = zslGetRank(zsl,score,ele); //计算排位
serverAssertWithInfo(c,ele,rank); /* Existing elements always have a rank. */
// 发送排位
if (reverse)
addReplyLongLong(c,llen-rank);
else
addReplyLongLong(c,rank-1);
} else {
addReply(c,shared.nullbulk);
}
} else {
serverPanic("Unknown sorted set encoding");
}
}
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
