学习了操作系统的基本原理和调度的相关知识,开始学习进程的上下文切换,本章主要要了解一下内容:
- 用户级和内核级上下文切换的原理
- 前面章节学习了进程由哪些部分组成,那么进程自身的上下文切换有哪些部分组成了
- 何时发生进程的上下文切换
- 进程间切换的线程和断点保存在哪里,结合linux0.11讲解进程切换的五部曲
1 用户级线程上下文切换
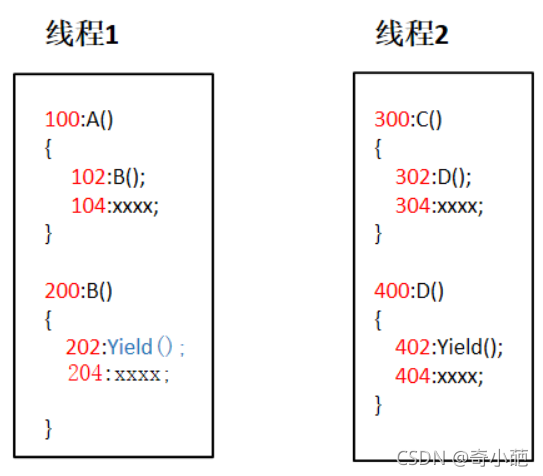
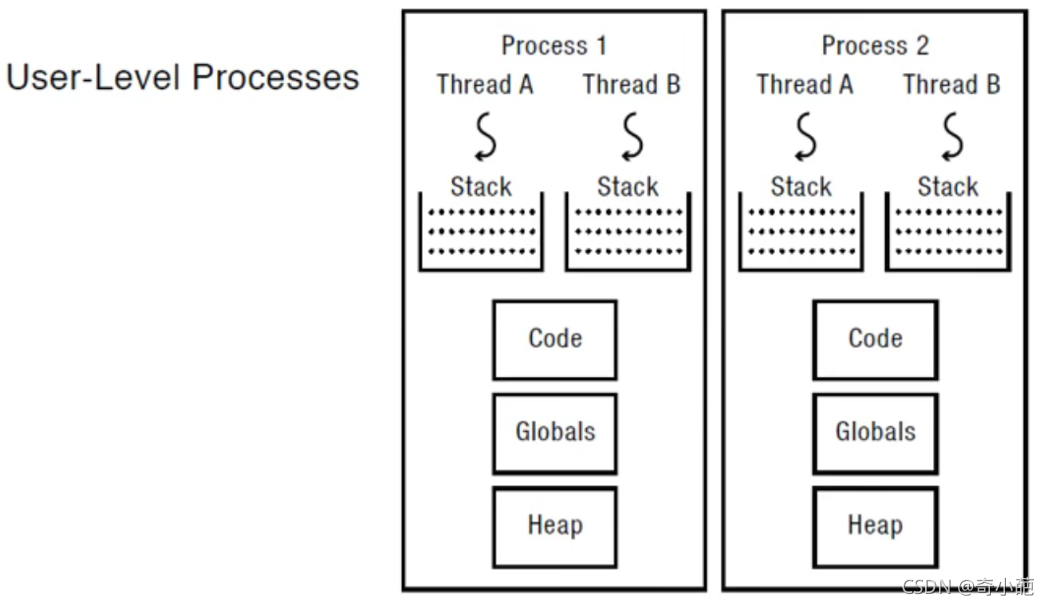
上文([进程管理(二)----线程的基本概念]((9条消息) 进程管理(二)----线程的基本概念_奇小葩-CSDN博客))中,我们讨论了何为多线程,而线程又分用户级线程和内核级线程,这节我们先来讨论一下何为 用户级线程 以及 用户级线程的底层原理 。用户级线程的切换是由我们用户来主动控制的,现在我们假设有线程1和线程2两个线程(图中红色的数字为内存的地址)
-
线程1中有A()和B()两个函数,执行流程为A()函数调用B()函数,B()函数执行完毕后返回到地址为104的语句继续往下执行
-
线程2中有C()和D()两个函数,执行流程为C()函数调用D()函数,D()函数执行完毕后返回到地址为304的语句继续往下执行
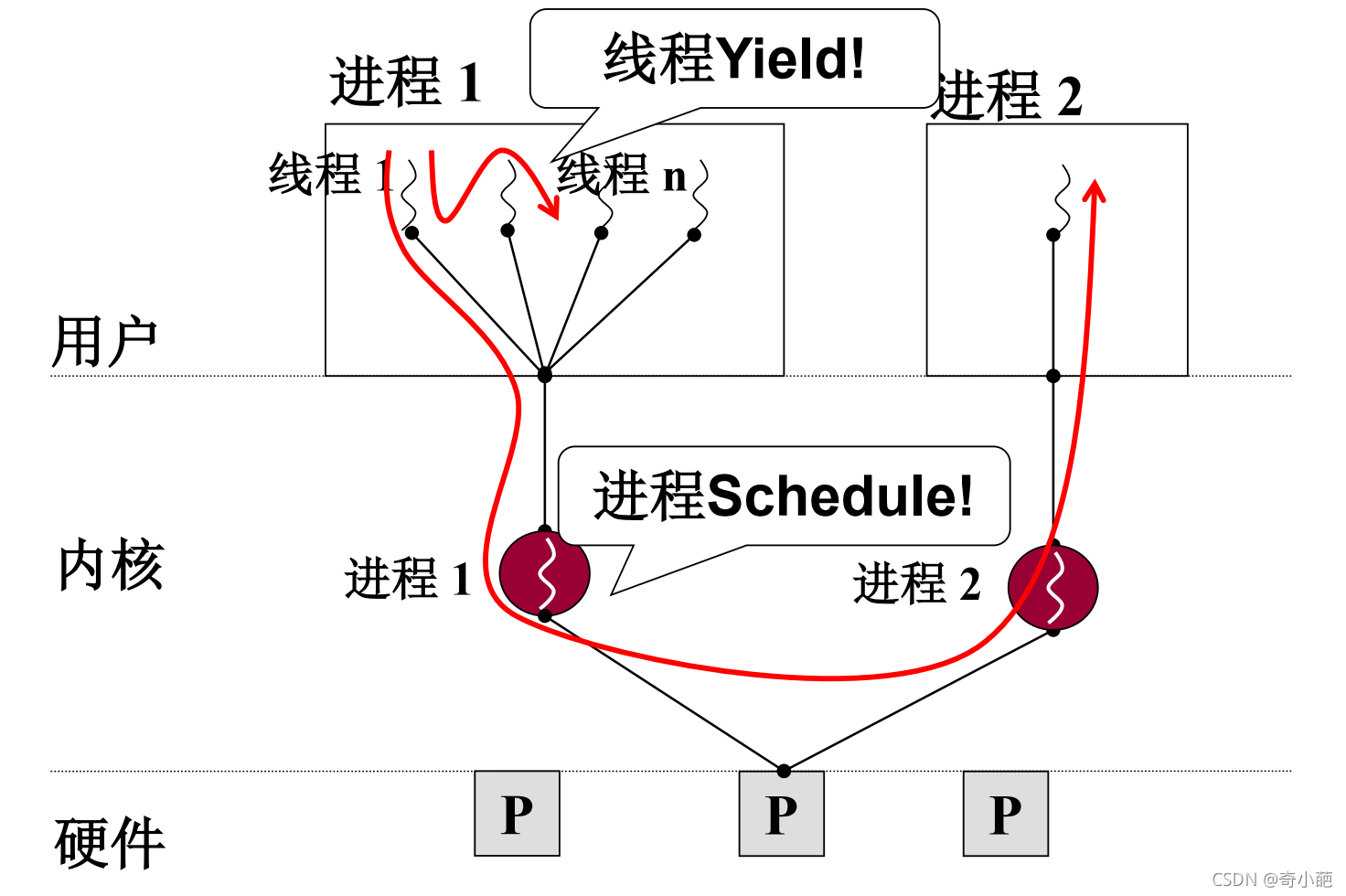
那么图中还有一个Yield()函数到底是什么东西呢,简单来说它就是我们用户主动来控制线程切换的一个函数,在线程1中调用Yield()函数,此时会切换到线程2,在线程2中调用了Yield()函数,此时又会回到线程1继续执行。因此,执行流程为下图所示。
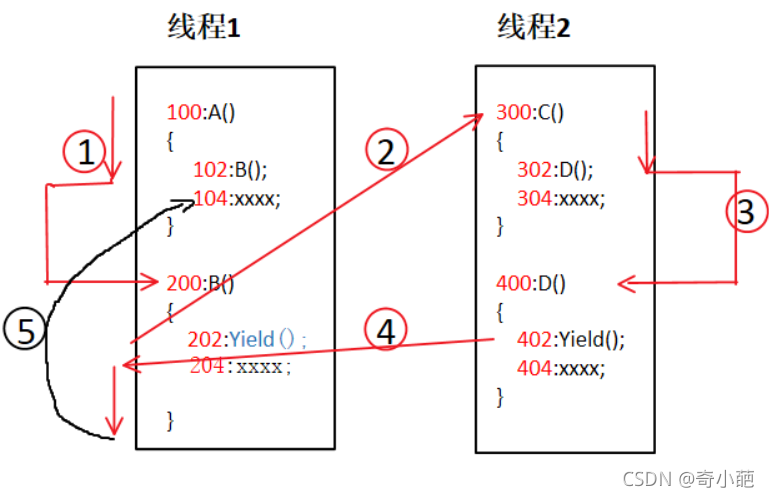
现在我们更加深入地去剖析整个切换过程到底发生了什么有趣的事 ,按照我们传统的方式
- 线程1运行,B为函数调用,此时函数调用的吓一跳指令地址入栈,即104入栈,此时要记录函数调用结束后返回继续执行地址
- 此时进入B函数内部执行,发生线程切换(Yield),则204入栈,就执行Yield,切换到线程2执行,跳转到300地址
- 类似的执行C,调用D,304入栈,即将执行Yield,404入栈
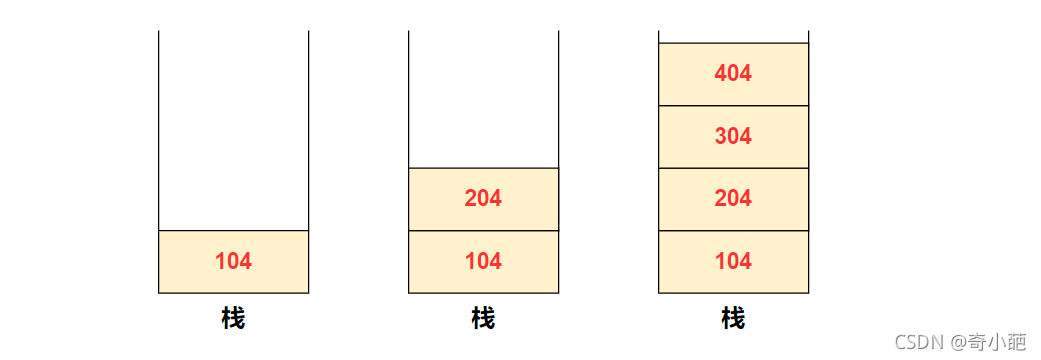
此时根据调用关系,那么当从D退出的时候,应该是从404返回,而不能回到104地方执行,出错的原因是因为两个线程共用了一个栈,导致线程间切换和内部运行出现了问题,因此可以用两个解决该问题,即为每个线程分配一个独立的栈。还是上面的例子,线程1和线程2分别有自己独有的栈,各种的栈地址放在各自线程的TCB中,其流程如下
- 线程1运行,B为函数调用,此时将函数调用的下一条入栈,即104入栈,然后B函数中执行调用Yield函数,204入线程1的栈,然后切换到线程2中执行
- 线程2执行,调用C函数中的D,此时304入线程2的栈,然后D函数中执行Yield函数,404入线程2的栈,然后再切换到线程1中执行
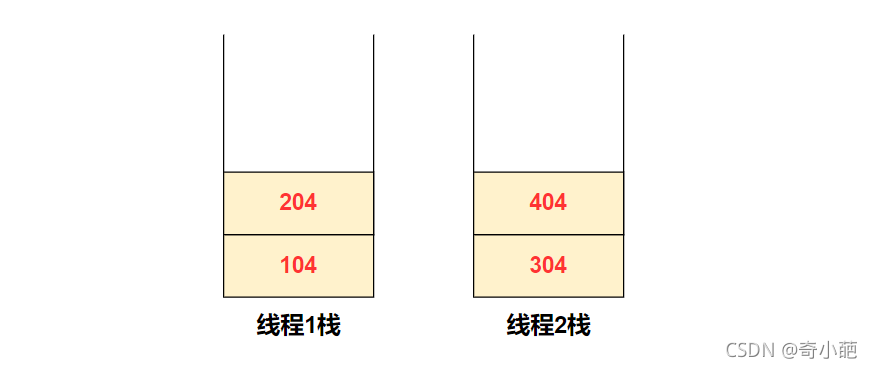
当线程2执行Yield函数后,全局的栈指示变量会执行线程1的栈,此时执行出栈的操作,出的时线程1的栈,弹出204,转向204的地方执行,接着B调用完毕后,继续执行线程1的栈,此时就完美的额解决了一个栈导致的混乱问题。由此可见,用户级线程是基于在用户态分别创建一套维护的用户栈来实现进程间的切换,其特点如下:
- 基于library函数实现,系统不可见
- 线程的创建,撤销,状态转换在用户态完成
- TCB在用户空间,每一个进程一个系统栈
- 优点是,不依赖于操作系统,调度灵活,同一进程多个线程切换速度快,不需要进入内核,不会发生上下文的切换
但是其缺点也很明显,对于多核的CPU,同一进程中的多个线程并不能真正的并发和并行,如果进程中的某个线程进入内核并阻塞,进程中的其它的线程将无法得到执行,例如若内核进程需要等待网卡IO,需要较长时间而导致进程阻塞, 用户态的多线程将没有任何作用。
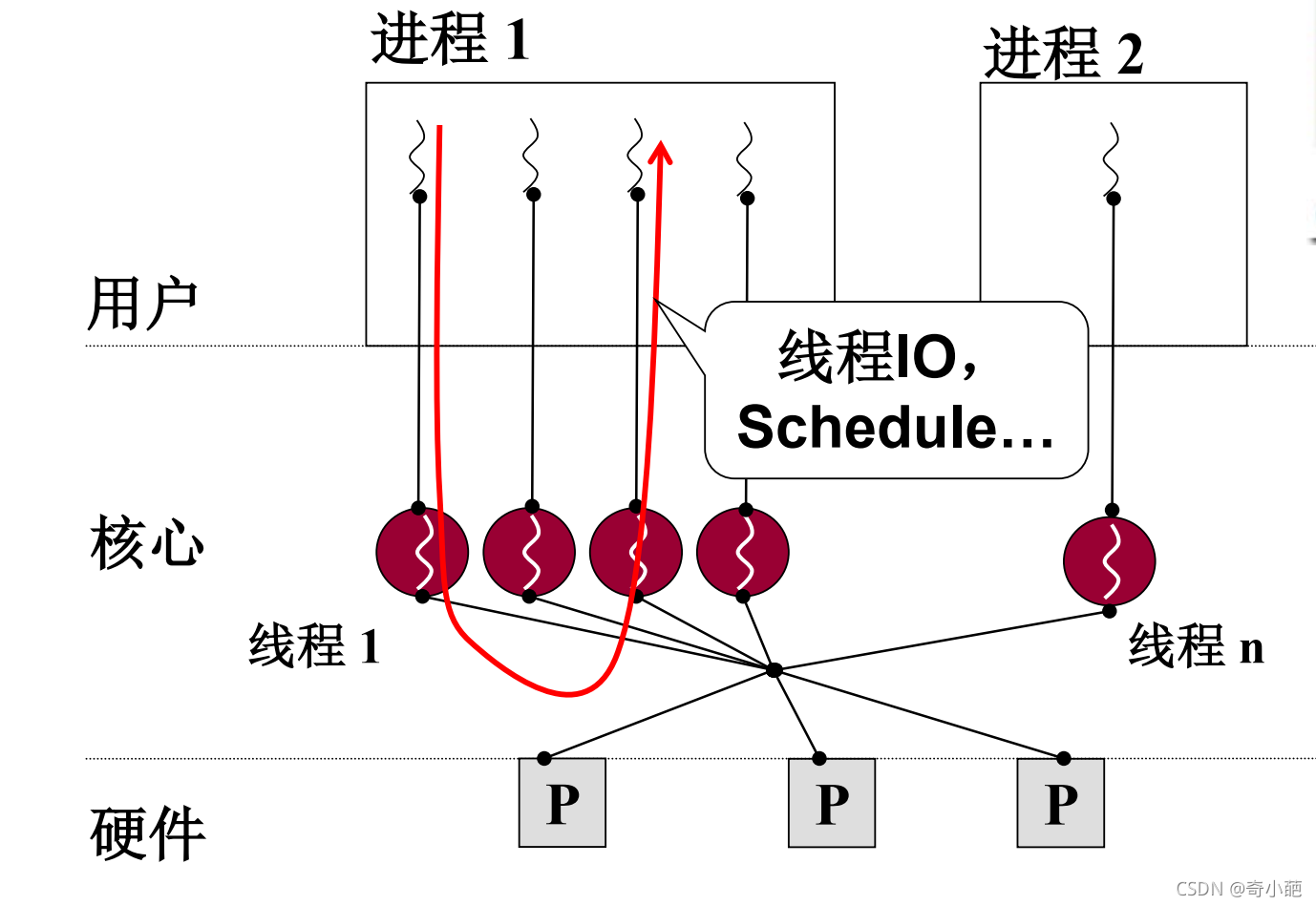
2 内核级线程上下文切换
现在操作系统都是多核,为了充分发挥操作系统的并行能力,所以就使用一个用户线程映射到一个内核级线程,也就是说一个用户线程就要创建一个内核级线程,随之而导致的时内核级线程的开销增大,所以系统中会限制线程数量,对于目前的windows/linux等操作系统均采用这种模型。
我们还是以实际的例子来说明,操作系统是如何完成内核级线程的上下文切换的原理,每个用户级线程即需要一个栈,而 内核级线程需要一套栈即两个栈:用户栈 + 内核栈 ,仍然是之前A,B,C的例子
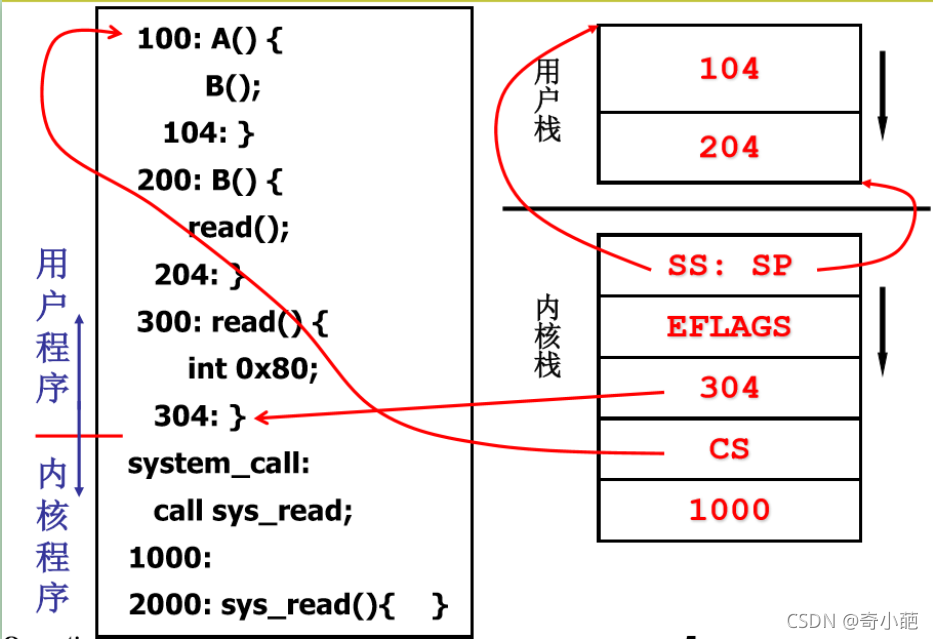
- 线程1,A函数调用B,首先此时要将104的地址压入线程1的栈,此时104进入用户栈,对于B函数,会调用到read接口,此时再将204入栈,由于read接口是一个系统调用,此时要立刻用户空间进入到内核态。
- 进入到内核态的时候,就需要保存此时用户空间的状态,以便返回的用户空间时使用,首先会将栈段寄存器SS(存放段地址,基地址)和栈指针SP(寄存器存放偏移地址),同时将此时标志寄存器(EFLAGS)进内核的栈,然后将此时的用户态用户运行到那里,包括此时运行的PC和下一条指令,页就是PC(304),CS,IP
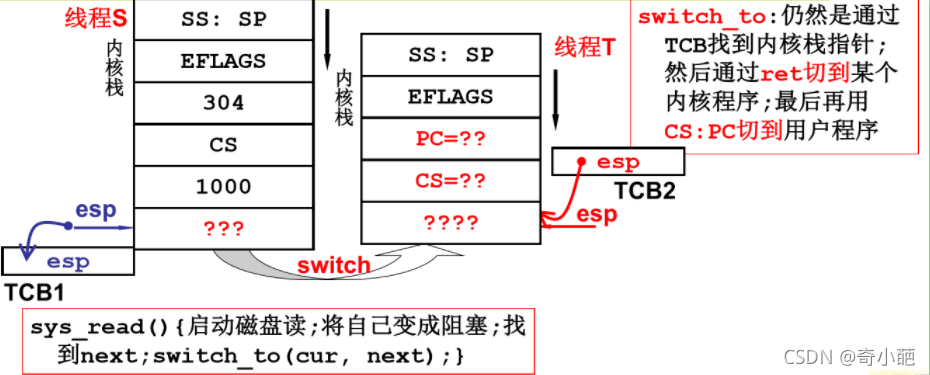
然后就执行sys_read就进入内核态,启动磁盘读,将自己变成阻塞状态,然后进程切换到另外一个进程运行,内核线程调度使用switch_to() , 并切换栈
- 执行switch_to, cur 是当前线程的TCB, next 是下一个线程的TCB。当前esp(栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶)被赋值 为 TCB1 中的值,而当内核切换的时候线程T执行,那么esp就必须执行TCB2中的值
- 对于切换到线程T,就需要执行到用户态的进程,因为操作系统主要就是完成用户任务而设计,所以在线程T中的内核态运行一小段时候就要返回到用户态执行,所以线程T的内核态主要是通过iret切换到用户态的CP:PS
对于整个过程可以理解为如下图所示:
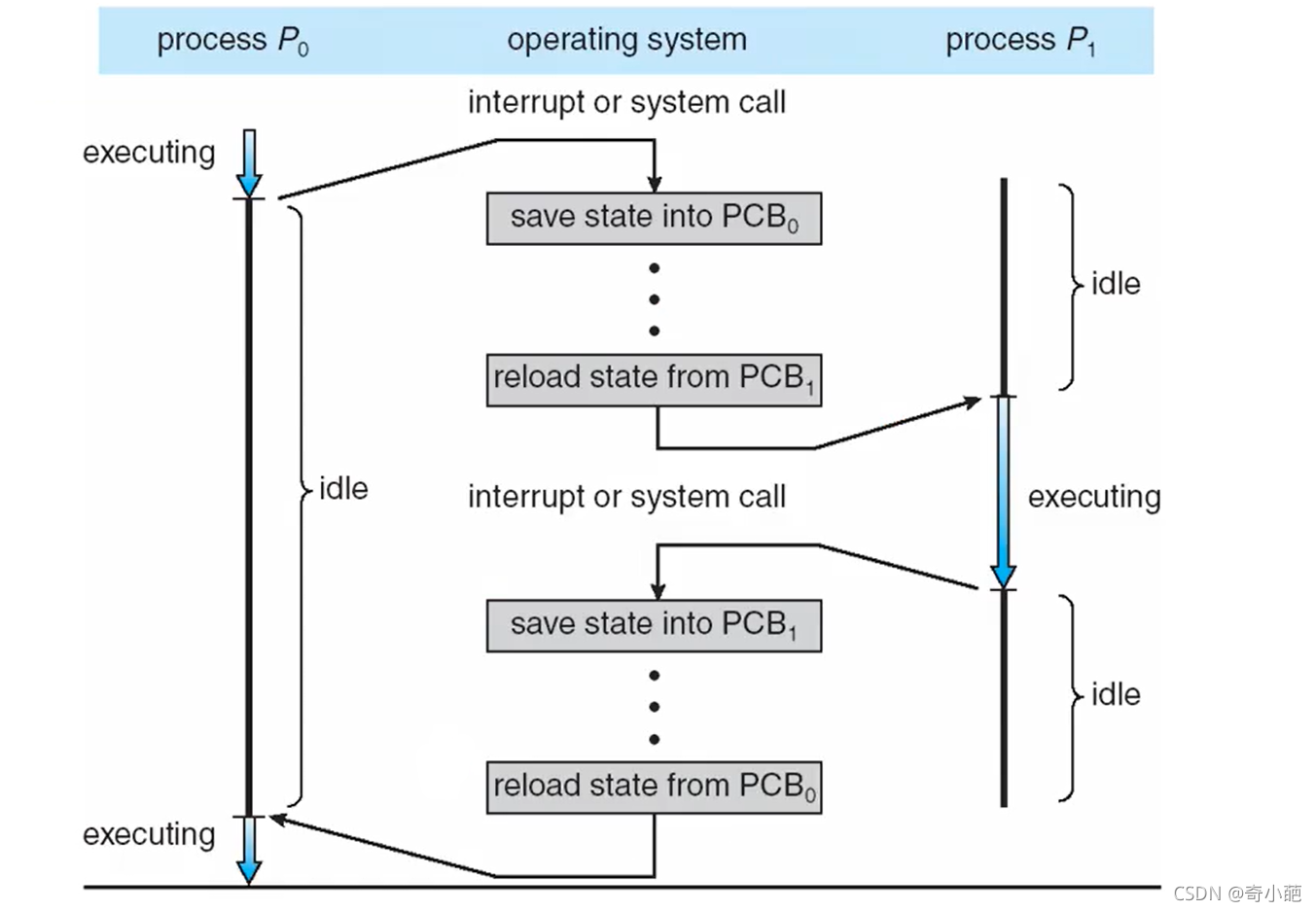
- 首先是蓝色的部分,线程1在运行过程中,通过系统调用进程到内核态,此时发生系统阻塞,需要调度,内核态此时保持用户态的现场到内核栈中,然后通过调度子系统调度到线程2中运行,此时发生线程控制块的切换,从TCB1切换到TCB2
- 切换到线程2的TCB时候,TCB中存放了内核栈的指针,此时运行在内核态,此时内核态运行一段收尾代码后,一般会通过iret指令,切换线程2的用户空间,执行用户空间的代码,就完成的用户栈的切换过程
所以对于内核级线程,分为用户态和内核态,例如process 1,用户进程中有线程A和线程B,它们共享进程的内存空间,分别有自己的用户栈,用于存放自己的调用过程,同时在内核空间,有属于自己的PCB,但是对于每一个进程有一个内核栈
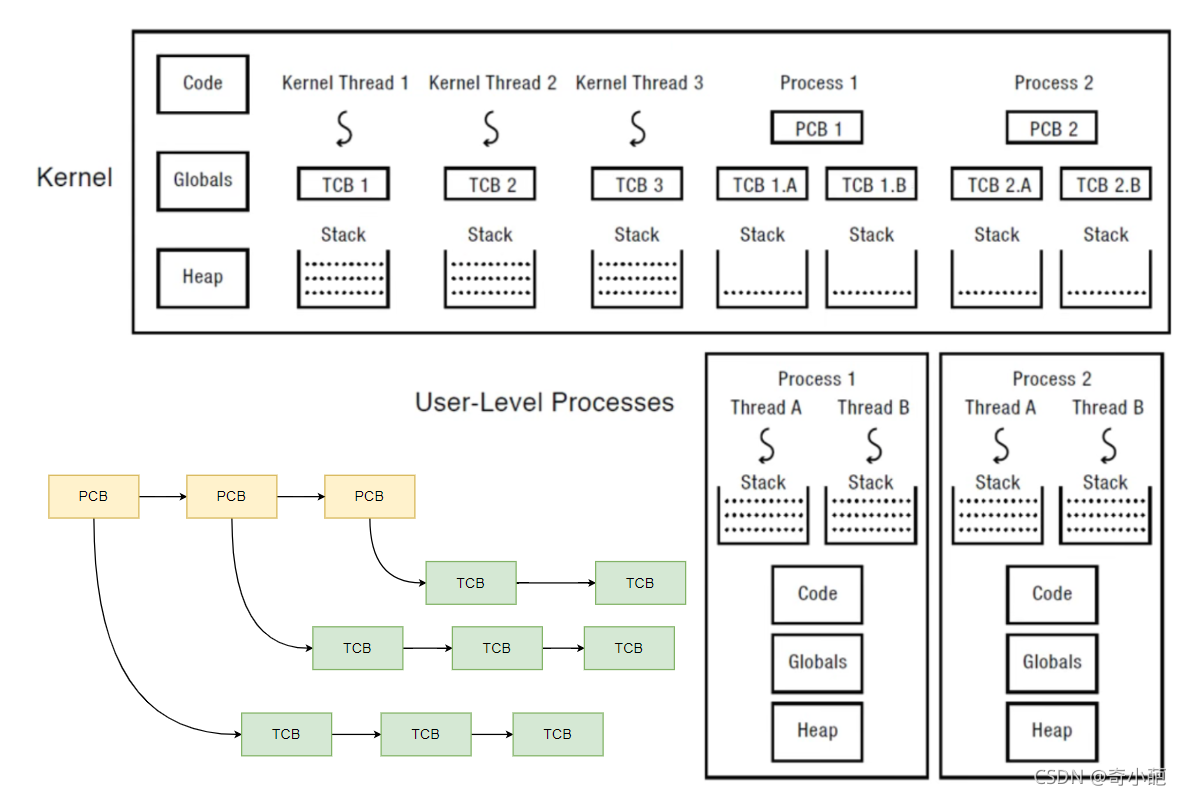
3 进程切换的时机
对于一个进程由哪些部分组成呢?主要包括用户空间和内核空间,其如下图所示:
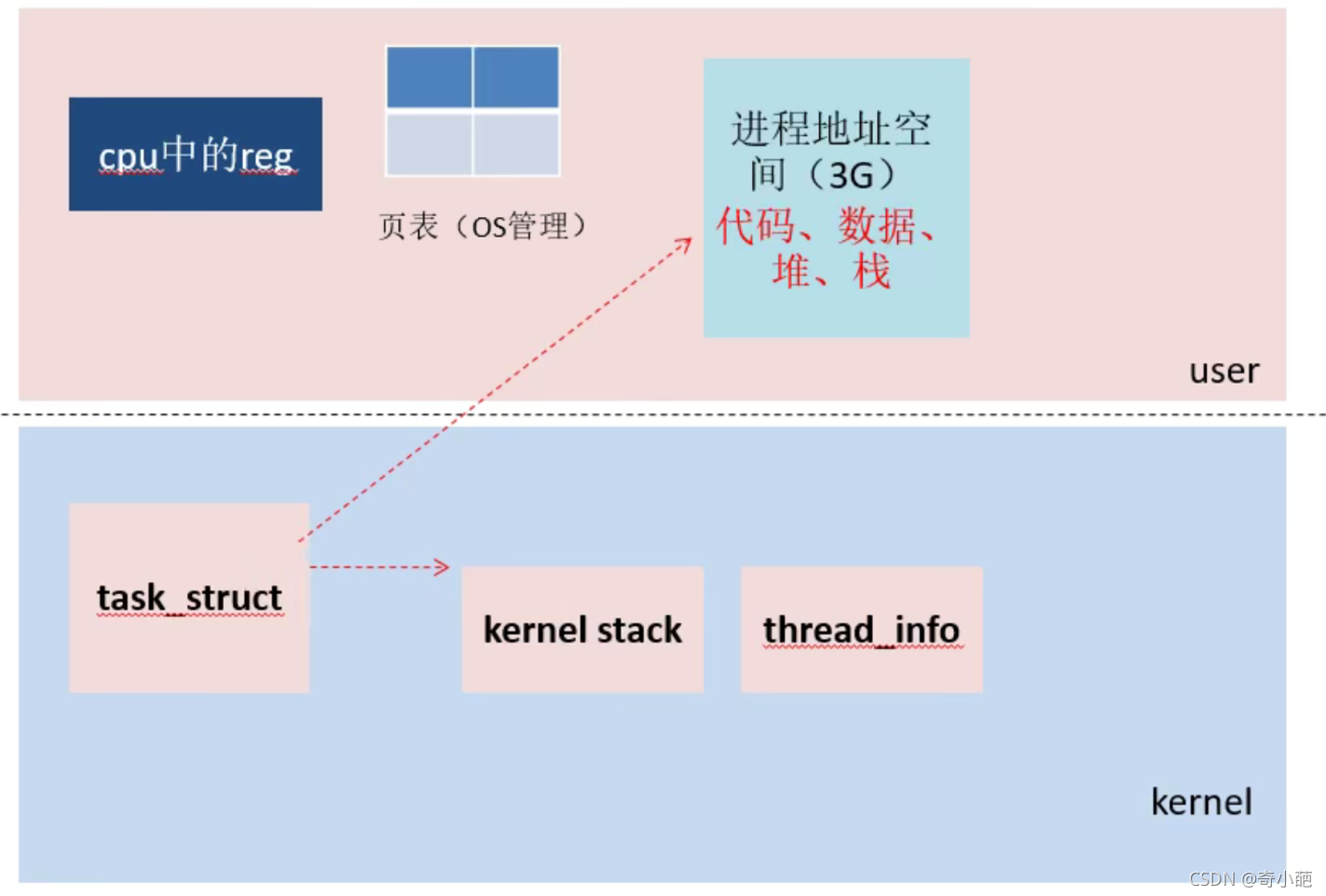
- 用户空间的进程地址空间一般由代码段、数据段、堆、栈组成,由task_struct的VMA维护,同时所有的内存空间都是存放在该进程的页表中,CPU中的reg也是由页表机制来管理
- 内核空间进程地址空间维护了一个进程的控制块PCB task_struct,主要是内核栈和用户栈信息thread_info,这两个用户维护进程的上下文切换中有大用途
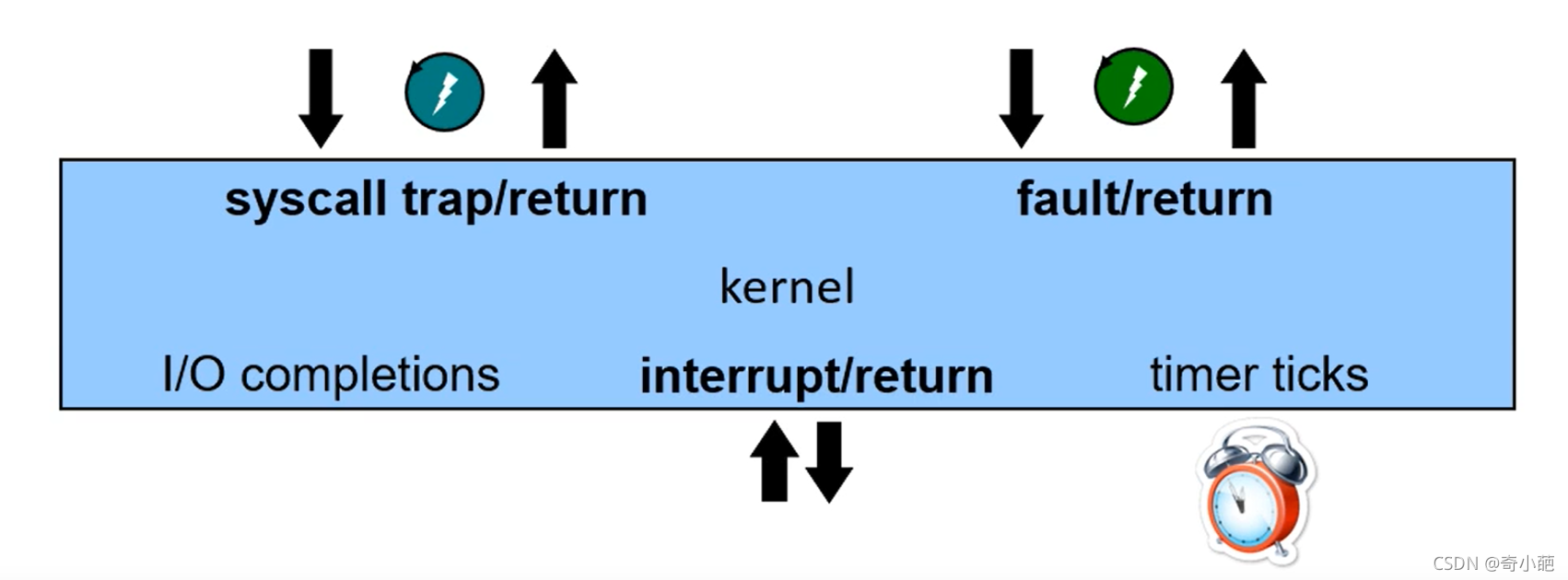
这个在[进程管理(十四)–linux进程管理]((9条消息) 进程管理(十四)–linux进程管理_奇小葩-CSDN博客)章节中已经有详细介绍,要想进行进程的切换,那么OS必须首先获得控制权,其主要在以下情况下得到控制权
- trap: 进程主动的切换,主要是通过执行一个system call
- Exception: 被动的切换,执行了一个意外的操作,例如常见的page fault
- Interrupt: 硬件设备请求OS服务 ,比如time中断,IO中断
4 进程切换
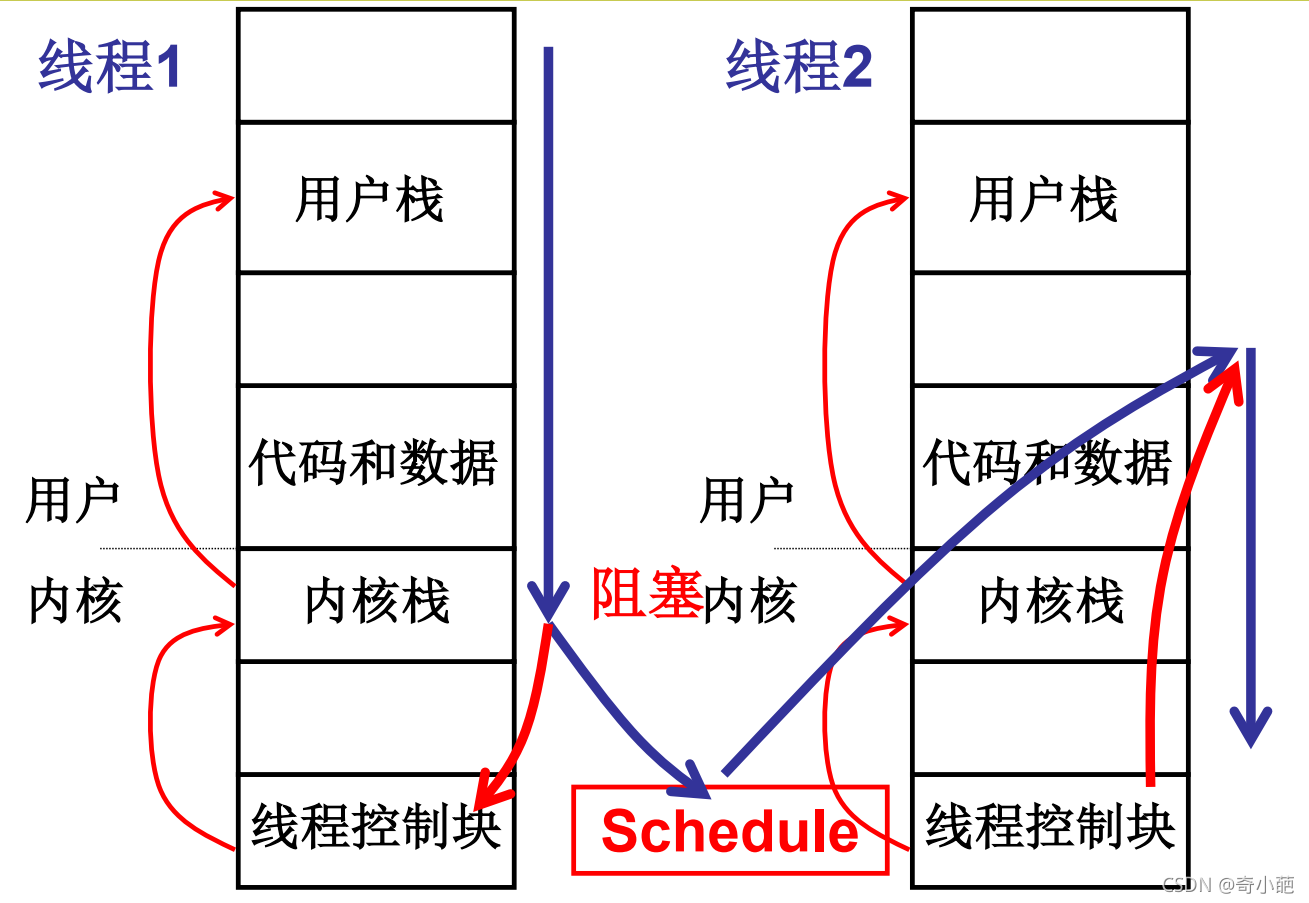
基于内核栈实现进程的切换的基本思路
1, 当进程由用户态进入内核态时,主要是通过系统调用或者中断,会引起堆栈切换,没用户信息会被压入到内核栈中,包括此时的用户的栈指针,PC和程序状态保存在内核栈中
2, 当进入到内核后,此时由于某些原因,由于该进程需要读取磁盘或者网络等信息,变成阻塞状态,或者时间片用完,此时需要让出CPU,重新引起调度时,操作系统会找到一个新的进程的PCB,并完成新进程PCB的切换
3, 当完成新进程的切换时,内核也完成了内核栈的切换,那么当中断返回时,执行IRET,弹出的就是新进程的EIP,从而跳转到新进程的用户指令进行执行。
这个切换的核心就是构建出内核栈的样子,要在适当的地方压入栈,适当的地方返回地址,并根据内核栈的样子,编写响应的汇编代码,完成内核堆栈的入栈和出站操作,以便保证顺利完成进程切换。
4.1 中断入口
操作系统负责进程的调度和切换,所以进程的切换一定是内核中发生,而用户程序是运行在内核态,所以就需要使用系统调用进入到内核态。主要的伪代码如下:
push ds;
mov ds, 内核段号
system_call
4.2 中断处理
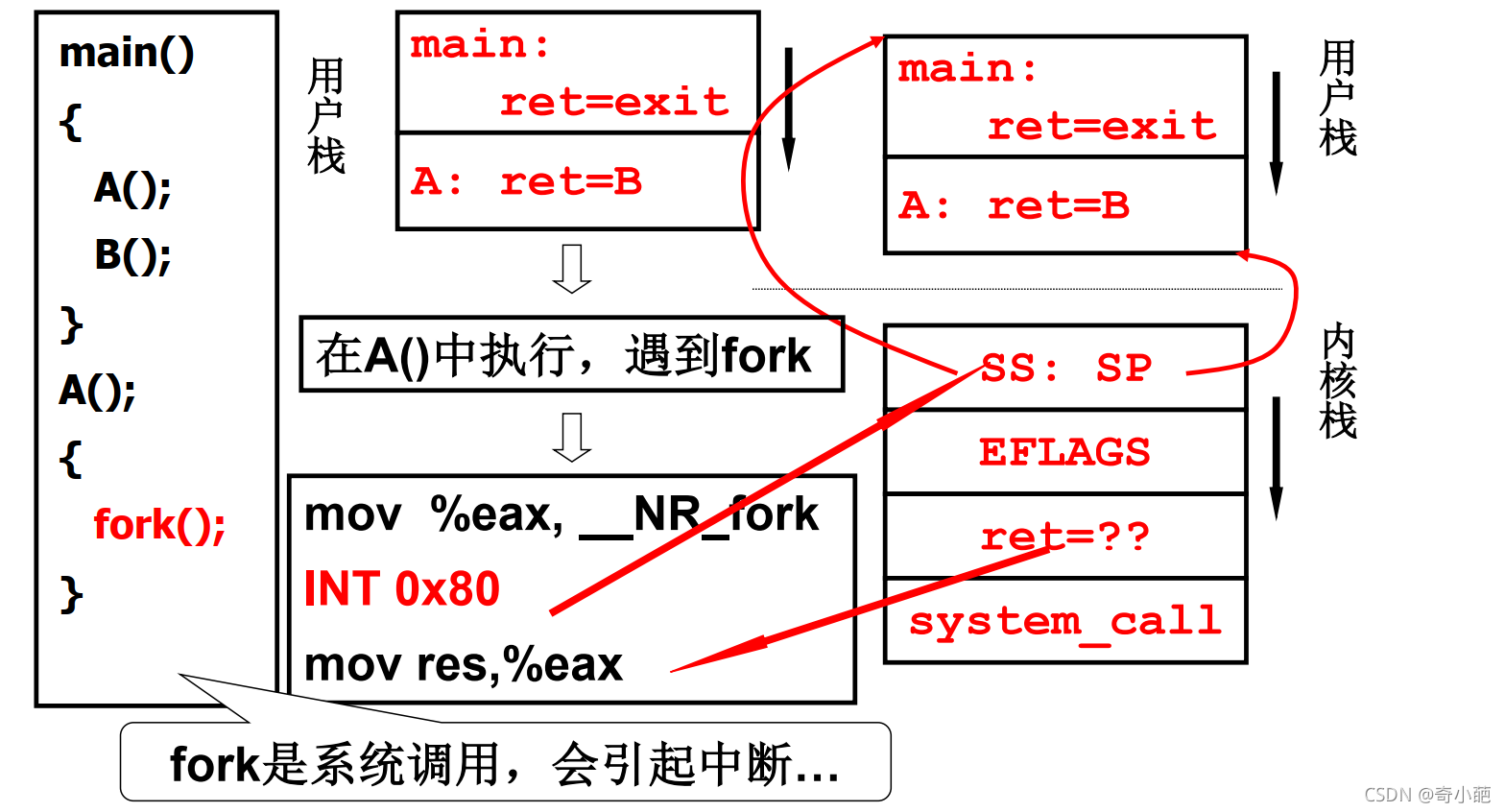
用户态进入内核态,要发生堆栈的切换,系统调用的核心指令对于X86来说是指令int 0x80,这个系统调用中断。 当执行int 0x80 这条语句时由用户态进入内核态时,CPU会自动按照***SS、ESP、EFLAGS、CS、EIP***的顺序,将这几个寄存器的值压入到内核栈中,由于执行int 0x80时还未进入内核,所以压入内核栈的这五个寄存器的值是用户态时的值,其中***EIP* 为int 0x80的下一条语句 "=a" (__res),这条语句的含义是 将eax所代表的寄存器的值放入到_res变量中。所以当应用程序在内核中返回时,会继续执行 “=a” (__res) 这条语句。**这个过程完成了进程切换中的第一步, 通过在内核栈中压入用户栈的ss、esp建立了用户栈和内核栈的联系,形象点说,即在用户栈和内核栈之间拉了一条线,形成了一套栈。

在system_call中执行完相应的系统调用sys_call_xx后,又将函数的返回值eax压栈。若引起调度,则跳转执行reschedule。否则则执行ret_from_sys_call。

在执行schedule前将ret_from_sys_call压栈,因为schedule是c函数,所以在c函数末尾的},相当于ret指令,将会弹出ret_from_sys_call作为返回地址,跳转到ret_from_sys_call执行。 总之,在系统调用结束后,将要中断返回前,内核栈主要是SS:SP指向用户栈,EFLAGS标志寄存器,返回地址EIP,还有一些其他的other Registers:EAX,EBX等,如下图所示
4.3 找到当前进程的PCB和新进程的PCB
当前进程的PCB 当前进程的PCB是用一个全局变量current指向的*(在sched.c中定义)* ,所以current即指向当前进程的PCB,pnext就指向下个进程的PCB。 在schedule()*函数中,当调用函数*switch_to(pent, _LDT(next))*时,会依次将返回地址**}***、参数2 ***_LDT(next)***、参数1 * pnext**压栈。当执行*switch_to*的返回指令ret时,就回弹出schedule()函数的 }执行*schedule()*函数的返回指令
4.4 switch_to
对于schedule中switch_to,表示要取出表示下一个进程的PCB参数,并与当前的current做一个比较,如果是当前的current,则什么也不做;如果不等于当前的curret,则开始进程切换,以次完成PCB的切换,内核栈的切换等
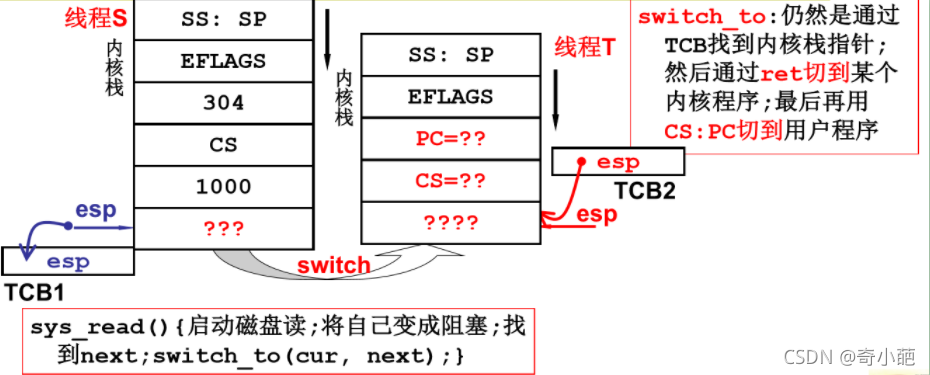
在schedule.c中定义struct tss_struct *tss=&(init_task.task.tss)这样一个全局变量,即0号进程的tss,所有进程都共用这个tss,任务切换时不再发生变化。 虽然所有进程共用一个tss,但不同进程的内核栈是不同的,所以在每次进程切换时,需要更新tss中esp0的值,让它指向新的进程的内核栈,并且要指向新的进程的内核栈的栈底,即要保证此时的内核栈是个空栈,帧指针和栈指针都指向内核栈的栈底。
4.5 中断出口
PC的切换对于被切换出去的进程,当再次被调度的时,根据切换出去的进程的内核栈的样子,switch_to的最后一句指令ret会弹出switch_to后面的指令,作为返回地址继续执行,将弹出ret_from_sys_call作为返回地址,在ret_from_sys_call中继续进行一些处理,最后执行iret指令,进行终端返回,将弹出原来用户进程被中断的地方作为返回地址,继续被中断处执行。
5. 总结
对于进程切换不同于我们熟知的“模式切换”,模式切换,CPU还是在同一进程中运行systemcall或者中断上下文;而进程切换是CPU转向另外一个进程执行,进程切换改变当前的进程空间,其主要的工作如下:
- 保持当前进程的硬件上下文(PC/SP和通用寄存器等),对于linux系统而言,其硬件上下文大部分都保存在struct thread_struct thread中,但通用寄存器等都保存在内核栈中
- 修改当前进程的PCB,比如将其状态由运行态修改为就绪或者等待态,并将该进程PCB加入到相关队列中
- 调度另外一个进程,修改被调度进程的PCB,并将其状态修改为运行
- 将“当前进程"的管理数据改为调度进程的存储数据,如页表,TLB,同时恢复新进程的硬件上下文,让PC执行新进程的代码
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
