HttpRequestDecoder
这东西一看就知道是HTTP请求的解码器,就是用来解析HTTP协议格式的。我们用一个简单的例子来说,就下面这个,一个请求解码,一个响应编码,最后一个自定义的处理器,我们来分析下,请求解码做了什么。
pipeline.addLast(new HttpRequestDecoder());
pipeline.addLast(new HttpResponseEncoder());
pipeline.addLast("MyTestHttpServerHandler", new MyHttpServerHandler());
类结构
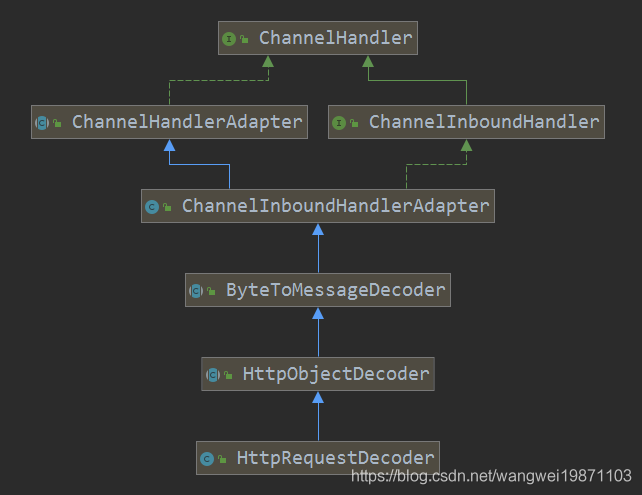
看到他是继承了一个HttpObjectDecoder,这个应该是一个通用的HTTP解码器,也是继承以前讲过的ByteToMessageDecoder,我们先来看下HttpRequestDecoder这个类,其实没多少东西,主要的在HttpObjectDecoder都实现了。从下面可以看到其实这个类本身没实现什么解码逻辑,主要的还是在他的父类。
public class HttpRequestDecoder extends HttpObjectDecoder {
//构造函数
public HttpRequestDecoder() {
}
c HttpRequestDecoder(
int maxInitialLineLength, int maxHeaderSize, int maxChunkSize) {
super(maxInitialLineLength, maxHeaderSize, maxChunkSize, true);
}
public HttpRequestDecoder(
int maxInitialLineLength, int maxHeaderSize, int maxChunkSize, boolean validateHeaders) {
super(maxInitialLineLength, maxHeaderSize, maxChunkSize, true, validateHeaders);
}
public HttpRequestDecoder(
int maxInitialLineLength, int maxHeaderSize, int maxChunkSize, boolean validateHeaders,
int initialBufferSize) {
super(maxInitialLineLength, maxHeaderSize, maxChunkSize, true, validateHeaders, initialBufferSize);
}
//根据请求行创建HttpMessage 版本,方法,URI
@Override
protected HttpMessage createMessage(String[] initialLine) throws Exception {
return new DefaultHttpRequest(
HttpVersion.valueOf(initialLine[2]),
HttpMethod.valueOf(initialLine[0]), initialLine[1], validateHeaders);
}
//无效请求
@Override
protected HttpMessage createInvalidMessage() {
return new DefaultFullHttpRequest(HttpVersion.HTTP_1_0, HttpMethod.GET, "/bad-request", validateHeaders);
}
//是否是请求解码
@Override
protected boolean isDecodingRequest() {
return true;
}
}
HttpObjectDecoder
基本属性
我们先了解下一些重要的属性,因为要解析HTTP协议格式,所以需要有换行符解析器,请求头解析器,还要看是否是用content-length传输还是用transfer-encoding块传输。还定义了一些状态,用来执行不同的逻辑。
private static final String EMPTY_VALUE = "";//请求头空值
private final int maxChunkSize;//块的最大长度
private final boolean chunkedSupported;//是否支持分块chunk发送
protected final boolean validateHeaders;//是否验证头名字合法性
private final HeaderParser headerParser;//请求头解析器
private final LineParser lineParser;//换行符解析器
private HttpMessage message;//请求的消息,包括请求行和请求头
private long chunkSize;//保存下一次要读的消息体长度
private long contentLength = Long.MIN_VALUE;//消息体长度
private volatile boolean resetRequested;//重置请求
// These will be updated by splitHeader(...)
private CharSequence name;//头名字
private CharSequence value;//头的值
private LastHttpContent trailer;//请求体结尾
·/** 状态
* The internal state of {@link HttpObjectDecoder}.
* <em>Internal use only</em>.
*/
private enum State {
SKIP_CONTROL_CHARS,//检查控制字符
READ_INITIAL,//开始读取
READ_HEADER,//读取头
READ_VARIABLE_LENGTH_CONTENT,//读取可变长内容,用于chunk传输
READ_FIXED_LENGTH_CONTENT,//读取固定长内容 用于Content-Length
READ_CHUNK_SIZE,//chunk传输的每个chunk尺寸
READ_CHUNKED_CONTENT,//每个chunk内容
READ_CHUNK_DELIMITER,//chunk分割
READ_CHUNK_FOOTER,//最后一个chunk
BAD_MESSAGE,//无效消息
UPGRADED//协议切换
}
//状态
private State currentState = State.SKIP_CONTROL_CHARS;
构造函数
构造函数,参数对应一行最大长度,请求头的最大长度,请求体或者某个块的最大长度,是否支持chunk块传输。
protected HttpObjectDecoder() {
this(4096, 8192, 8192, true);
}
/**
* Creates a new instance with the specified parameters.
*/
protected HttpObjectDecoder(
int maxInitialLineLength, int maxHeaderSize, int maxChunkSize, boolean chunkedSupported) {
this(maxInitialLineLength, maxHeaderSize, maxChunkSize, chunkedSupported, true);
}
/**
* Creates a new instance with the specified parameters.
*/
protected HttpObjectDecoder(
int maxInitialLineLength, int maxHeaderSize, int maxChunkSize,
boolean chunkedSupported, boolean validateHeaders) {
this(maxInitialLineLength, maxHeaderSize, maxChunkSize, chunkedSupported, validateHeaders, 128);
}
protected HttpObjectDecoder(
int maxInitialLineLength, int maxHeaderSize, int maxChunkSize,
boolean chunkedSupported, boolean validateHeaders, int initialBufferSize) {
checkPositive(maxInitialLineLength, "maxInitialLineLength");
checkPositive(maxHeaderSize, "maxHeaderSize");
checkPositive(maxChunkSize, "maxChunkSize");
AppendableCharSequence seq = new AppendableCharSequence(initialBufferSize);
lineParser = new LineParser(seq, maxInitialLineLength);
headerParser = new HeaderParser(seq, maxHeaderSize);
this.maxChunkSize = maxChunkSize;
this.chunkedSupported = chunkedSupported;
this.validateHeaders = validateHeaders;
}
AppendableCharSequence 可添加的字符序列
这个底层是一个字符数组,可以动态添加到最后,具体的源码可以自己看看,因为下面要用,所以我就提一下。
HeaderParser头解析器
其实就是检查字节缓冲区,获取一行头信息,ByteProcessor 这个就是处理是否遇到某个字节,就是process方法。这边处理的就是如果发现是回车,就不添加任何字符,返回true,继续解析,遇到换行就返回false,不解析了,否则将字符添加到字符序列中,返回true,继续解析。
private static class HeaderParser implements ByteProcessor {
private final AppendableCharSequence seq;//可添加的字符序列
private final int maxLength;//最大长度
private int size;//索引
HeaderParser(AppendableCharSequence seq, int maxLength) {
this.seq = seq;
this.maxLength = maxLength;
}
//解析缓冲区
public AppendableCharSequence parse(ByteBuf buffer) {
final int oldSize = size;
seq.reset();
int i = buffer.forEachByte(this);
if (i == -1) {//没读到换行,或者报异常了
size = oldSize;
return null;
}
buffer.readerIndex(i + 1);
return seq;
}
//读到的字符个数清零
public void reset() {
size = 0;
}
//处理数据,遇到换行了就结束
@Override
public boolean process(byte value) throws Exception {
char nextByte = (char) (value & 0xFF);
if (nextByte == HttpConstants.CR) {//遇到回车符,直接返回true,不添加字符
return true;
}
if (nextByte == HttpConstants.LF) {//遇到换行符,就会结束
return false;
}
if (++ size > maxLength) {//溢出了
throw newException(maxLength);
}
seq.append(nextByte);//添加
return true;
}
//头过大
protected TooLongFrameException newException(int maxLength) {
return new TooLongFrameException("HTTP header is larger than " + maxLength + " bytes.");
}
}
process哪里用到呢
其实是在parse方法的buffer.forEachByte(this)里。
forEachByte
这个方法就是传一个字节处理器,然后字节缓冲区挨个处理字节,返回索引。
@Override
public int forEachByte(ByteProcessor processor) {
ensureAccessible();
try {
return forEachByteAsc0(readerIndex, writerIndex, processor);
} catch (Exception e) {
PlatformDependent.throwException(e);
return -1;
}
}
forEachByteAsc0
这个就是具体的方法啦,里面调用了processor的process方法,从头到位把每个字节传进去处理,如果有遇到换行符,会返回相应索引,否则就是-1。
int forEachByteAsc0(int start, int end, ByteProcessor processor) throws Exception {
for (; start < end; ++start) {
if (!processor.process(_getByte(start))) {
return start;
}
}
return -1;//表示没有遇到换行符
}
LineParser行解析器
继承了头解析器,只是解析的时候要reset一下,就是把读到的个数清0,因为是一行行读,每次读完一行就得清理个数。虽然字符串序列可以不处理,可以复用。
private static final class LineParser extends HeaderParser {
LineParser(AppendableCharSequence seq, int maxLength) {
super(seq, maxLength);
}
@Override
public AppendableCharSequence parse(ByteBuf buffer) {
reset();//从头开始,要重置索引
return super.parse(buffer);
}
@Override
protected TooLongFrameException newException(int maxLength) {
return new TooLongFrameException("An HTTP line is larger than " + maxLength + " bytes.");
}
}
decode解码
这个是最核心的方法,包括了解析请求行,请求头,请求体,但是会将请求行和请求头整合起来形成一个请求DefaultHttpRequest传递到后面,把请求体再封装成消息体传递到后面,因为请求体可能很大,所以也可能会有多次封装,那后面处理器就可能收到多次消息体。如果是GET的话是没有消息体的,首先收到一个DefaultHttpRequest,然后是一个空的LastHttpContent。如果是POST的话,先收到DefaultHttpRequest,然后可能多个内容DefaultHttpContent和一个DefaultLastHttpContent。下面我们来看源码,这个方法源码很长,所以我打算按照状态来讲。
检查并略过控制字符SKIP_CONTROL_CHARS
首先我们要检查下我们的字节缓冲区里面是不是全是控制字符(类似回车换行,空格这种),如果是的话就不处理,返回了,不是的话就略过控制字符,然后返回。如果不全是控制字符,那就状态切换到READ_INITIAL开始读取。
case SKIP_CONTROL_CHARS: {
if (!skipControlCharacters(buffer)) {
return;//如果全是控制字符就返回了
}
currentState = State.READ_INITIAL;
}
skipControlCharacters略过控制字符
这个方法就是看没有不是控制字符的,如果全是控制字符,就返回false,有不是控制字符的就略过控制字符并返回true。具体方法就是从可读索引开始,直接获取对应的无符号字节,然后判断是不是ISO的控制字符或者空格,如果不是,直接就返回,否则就继续,直到遇到不是的位置,然后要略过控制字符。
private static boolean skipControlCharacters(ByteBuf buffer) {
boolean skiped = false;
final int wIdx = buffer.writerIndex();
int rIdx = buffer.readerIndex();
while (wIdx > rIdx) {
int c = buffer.getUnsignedByte(rIdx++);//获取无符号字节
if (!Character.isISOControl(c) && !Character.isWhitespace(c)) {//不是ISO的控制字符也不是空格
rIdx--;
skiped = true;//有不是控制字符的,直接返回
break;
}
}
buffer.readerIndex(rIdx);//略过控制字符
return skiped;
}
开始读取READ_INITIAL
会开始读取一行,如果没有读到换行符,可能是因为数据还没收全,那就什么都不做,返回。
否则就开始分割,分割出方法,URI,协议,当然如果请求头无效,就不管了,重新返回到SKIP_CONTROL_CHARS状态。如果是有效的,就封装成请求消息HttpMessage包括请求行和请求头信息,讲状态切换到READ_HEADER读头信息。
case READ_INITIAL: try {//读取请求行
AppendableCharSequence line = lineParser.parse(buffer);//解析一行数据
if (line == null) {//没解析到换行符
return;
}
String[] initialLine = splitInitialLine(line);//行分割后的数组
if (initialLine.length < 3) {//小于3个就说明格式(方法 URI 版本)不对,直接忽略
// Invalid initial line - ignore.
currentState = State.SKIP_CONTROL_CHARS;
return;
}
message = createMessage(initialLine);//创建请求消息
currentState = State.READ_HEADER;
// fall-through
} catch (Exception e) {
out.add(invalidMessage(buffer, e));
return;
}
splitInitialLine分割请求行
可以看到其实执行了3次检测,刚好把请求行给分割出来,最后用字符串切割出来封装成数组返回。
//按空格进行一行的分割
private static String[] splitInitialLine(AppendableCharSequence sb) {
int aStart;
int aEnd;
int bStart;
int bEnd;
int cStart;
int cEnd;
aStart = findNonWhitespace(sb, 0);//找出不是空格的第一个索引
aEnd = findWhitespace(sb, aStart);//找出空格索引
bStart = findNonWhitespace(sb, aEnd);
bEnd = findWhitespace(sb, bStart);
cStart = findNonWhitespace(sb, bEnd);
cEnd = findEndOfString(sb);
return new String[] {
sb.subStringUnsafe(aStart, aEnd),
sb.subStringUnsafe(bStart, bEnd),
cStart < cEnd? sb.subStringUnsafe(cStart, cEnd) : "" };
}
createMessage创建请求消息
创建一个DefaultHttpRequest,就是一个HttpRequest接口的默认实现,封装请求行和请求头信息。
@Override
protected HttpMessage createMessage(String[] initialLine) throws Exception {
return new DefaultHttpRequest(
HttpVersion.valueOf(initialLine[2]),//协议版本
HttpMethod.valueOf(initialLine[0]), initialLine[1], validateHeaders);//方法和URI
}
invalidMessage无效消息
创建一个无效消息,状态直接为BAD_MESSAGE无效,把缓冲区内的数据直接都略过,如果请求消息没创建好,就创建一个,然后设置失败结果并带上异常信息返回。
private HttpMessage invalidMessage(ByteBuf in, Exception cause) {
currentState = State.BAD_MESSAGE;//设置无效数据,这样后面同一个消息的数据都会被略过
in.skipBytes(in.readableBytes());//直接不可读,略过可读数据
if (message == null) {
message = createInvalidMessage();
}
message.setDecoderResult(DecoderResult.failure(cause));//设置失败
HttpMessage ret = message;
message = null;
return ret;
}
createInvalidMessage创建完整的请求
直接返回完整的请求消息,参数设置成有问题的就可以了。
@Override
protected HttpMessage createInvalidMessage() {
return new DefaultFullHttpRequest(HttpVersion.HTTP_1_0, HttpMethod.GET, "/bad-request", validateHeaders);
}
刚好讲完了解析请求行,好像有点多了,下一篇再讲解析头吧。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
