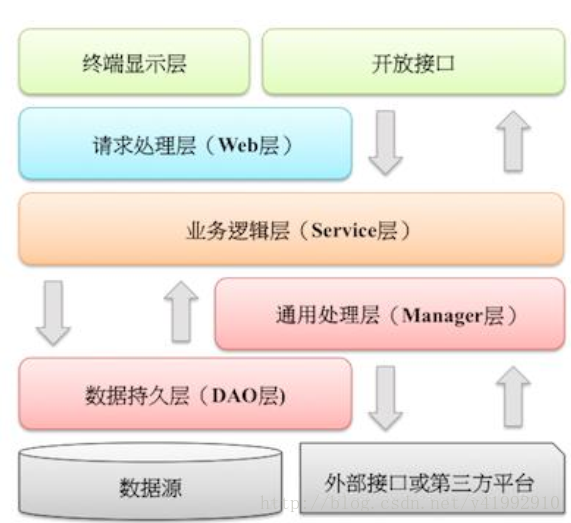
在《阿里巴巴 Java 开发规范》手册最后一节的应用分层中推荐了应用系统的分层结构。
我比较赞同这种分层结构,这种分层结构带来了诸多好处,但是有一个麻烦之处就是分层领域模型,也就是我们所说的各种 O,比如 DTO、POJO、DO、VO 等等,这样就导致我们项目中存在各种属性相同的 xxO,对于有些工作经验的小伙伴们来说知道使用 BeanUtils 来实现属性复制,但是对于工作经验不是很多的小伙伴可能就是各种 set 和 get 了。这是非常尴尬的一件事。
Spring 的 BeanUtils 虽然可以满足我们大部分的需要,但是只能赋值属性名相同且类型一致的两个属性,比如 VO 里面的 beginTime 是 String 类型的,而 BO 里面的 beginTime 是 Date 类型就无法赋值了。怎么解决这种问题呢?使用 Orika。
Orika 它简化了不同层对象之间映射过程。使用字节码生成器创建开销最小的快速映射,比其他基于反射方式实现(如,Dozer)更快。
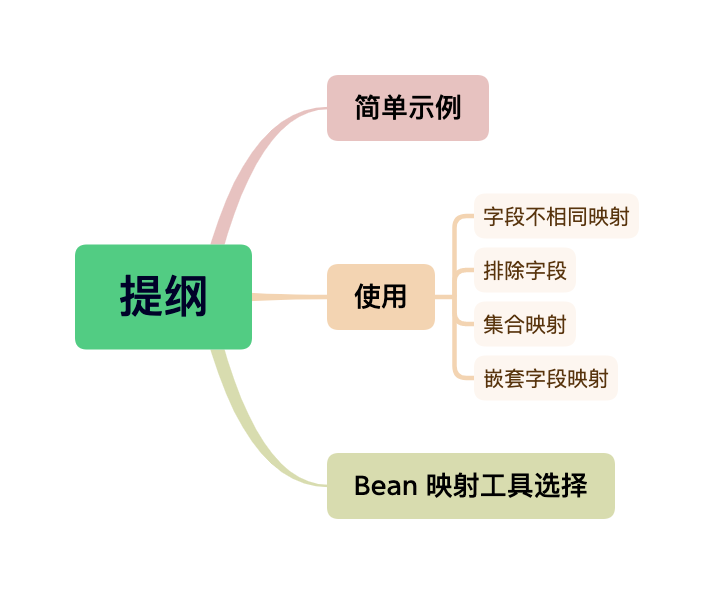
简单示例
- 先定义两个需要转换的 VO 和 BO
public class UserVO {
private String userName;
private Integer userAge;
}
public class UserBO {
private String userName;
private Integer userAge;
}
- 测试
Orika 的基础类是 MapperFactory,其用于配置映射并获得用于执行映射工作的 MapperFacade 实例,如下:
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
我们将 UserVO 当做源数据,将 UserBO 当做目标数据,如下:
public static void main(String[] args){
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
mapperFactory.classMap(UserVO.class,UserBO.class);
MapperFacade mapperFacade = mapperFactory.getMapperFacade();
UserVO userVO = new UserVO("chenssy",18);
UserBO userBO = mapperFacade.map(userVO,UserBO.class);
System.out.println("userName:" + userBO.getUserName() + " --- userAge:" + userBO.getUserAge() );
}
运行结果:
userName:chenssy --- userAge:18
这只是一个比较简单的示例,到这里,可能有小伙伴说:使用 Spring 的 BeanUtils 也可以实现,而且代码量更加少,更加简单,那下面小编就演示他的高级功能,看 Spring BeantUtils 是否还能够实现。
使用
使用 Orika 需要添加 maven 映射:
<dependency>
<groupId>ma.glasnost.orika</groupId>
<artifactId>orika-core</artifactId>
<version>1.4.6</version>
</dependency>
字段不相同映射
上面的示例源对象和目标对象两者的属性都一致,如果两者的属性不一致该如何处理呢?如下:
public class UserVO {
private String userName;
private Integer userAge;
}
public class UserBO {
private String name;
private Integer userAge;
}
我们需要将 userName 的值赋值给 name,userAge 的值赋值给 age,字段映射如下:
public static void main(String[] args){
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
mapperFactory.classMap(UserVO.class, UserBO.class)
.field("userName","name")
.field("userAge","userAge").register();
MapperFacade mapperFacade = mapperFactory.getMapperFacade();
UserVO userVO = new UserVO("chenssy-2",19);
UserBO userBO = mapperFacade.map(userVO,UserBO.class);
System.out.println("userName:" + userBO.getName() + " --- userAge:" + userBO.getUserAge() );
}
运行结果如下:
userName:chenssy-2 --- userAge:19
在这里需要注意的是:在进行字段映射时不能忘记调用 register() 方法,它是为了给 MapperFactory 注册配置信息的。
如果按照上面的使用方法,则需要在注册属性映射时要注册所有的属性,哪怕只有一个属性不一致也要注册所有字段映射,包括相同的字段。这种方式会让人崩溃的,比如有 20 个属性只要 1 个不同,难道也需要配置其余 19 个相同的属性?当然不,我们可以通过设置缺省映射配置,这样就无效显示定义映射的。如下:
mapperFactory.classMap(UserVO.class, UserBO.class)
.field("userName","name")
.byDefault().register();
一样可以得到上面相同的运行结果。
排除字段
在我们实际工作中,对于一个 DO 赋值,我们可能只需要其中某一些字段,对于其他的字段我们需要排除掉,这个时候,我们就可以使用 exclude() 不希望该字段参与映射。比如上面实例的 userAge。如下:
mapperFactory.classMap(UserVO.class, UserBO.class)
.field("userName","name")
.exclude("userAge")
.byDefault().register();
运行结果如下:
userName:chenssy-2 --- userAge:null
集合映射
List 集合
将 UserVO 集合数据拷贝到 UserBO 集合中。一般这种情况在我们实际工作中是非常多见的。
不多说,直接上代码。
public static void main(String[] args){
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
MapperFacade mapperFacade = mapperFactory.getMapperFacade();
mapperFactory.classMap(UserVO.class,UserBO.class);
List<UserVO> userList = new ArrayList<>();
userList.add(new UserVO("chenssy_1",18));
userList.add(new UserVO("chenssy_2",19));
userList.add(new UserVO("chenssy_3",20));
//进行集合复制
List<UserBO> userBoList = mapperFacade.mapAsList(userList,UserBO.class);
for(UserBO userBO : userBoList){
System.out.println("userName:" + userBO.getUserName() + " --- userAge:" + userBO.getUserAge() );
}
}
运行结果:
userName:chenssy_1 --- userAge:18
userName:chenssy_2 --- userAge:19
userName:chenssy_3 --- userAge:20
其实代码与简单示例中的代码没什么区别,仅仅只是将 map() 方法替换成了 mapAsList() 方法,至于 Map、Set,则 Orika 都提供了相应的方法可以进行映射,这里就不多介绍了。
VO 中有集合
我们可能会遇到这样一种情况,那就是 VO 中包含着一个或者多个集合属性,我们需要将他们的值拷贝到另一个 BO 中的集合属性中。如下:
public class UserBOList {
private List<UserBO> list;
}
public class UserVOList {
private List<UserVO> list;
}
UserBOList 和 UserVOList 中包含一个 List,分别是 UserBO 和 UserVO 的集合。
public static void main(String[] args){
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
// 注意这里是 List 的集合中的对象数据
mapperFactory.classMap(UserVO.class,UserBO.class)
.field("userName","name")
.field("userAge","userAge")
.byDefault()
.register();
List<UserVO> list = new ArrayList<>();
list.add(new UserVO("chenssy_11",118));
list.add(new UserVO("chenssy_22",228));
list.add(new UserVO("chenssy_33",338));
UserVOList userVOList = new UserVOList();
userVOList.setList(list);
UserBOList userBOList = mapperFactory.getMapperFacade().map(userVOList,UserBOList.class);
for(UserBO userBO : userBOList.getList()){
System.out.println("userName:" + userBO.getName() + " --- userAge:" + userBO.getUserAge() );
}
}
运行结果:
userName:chenssy_11 --- userAge:118
userName:chenssy_22 --- userAge:228
userName:chenssy_33 --- userAge:338
Map 转换
Map 转换 Bean 是非常常见的常见,下面就演示下,如何利用 Orika 完成 Map 到 Bean 的转换过程。
public static void main(String[] args){
Map<String,Object> map = new HashMap<>();
map.put("userName","chenssy1");
map.put("userAge",18);
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
mapperFactory.classMap(HashMap.class, UserBO.class)
.field("userName","userName")
.field("userAge","userAge")
.byDefault()
.register();
UserBO userBO = mapperFactory.getMapperFacade().map(map,UserBO.class);
System.out.println("userName:" + userBO.getUserName() + " --- userAge:" + userBO.getUserAge() );
}
就是如此的简单。
嵌套字段映射
加入在源数据对象中,有另外一个 DTO 需要保持我们映射的值。
这种场景还是挺多见的,不多说,直接看代码。
public class Person {
private UserVO userVO;
}
Person 中包含 UserVO 实例。那如何将其映射到目标对象中呢?为了访问嵌套 DTO 的属性并映射到目标对象,我们只需要使用 . 即可,如下:
public static void main(String[] args){
MapperFactory mapperFactory = new DefaultMapperFactory.Builder().build();
mapperFactory.classMap(Person.class, UserBO.class)
.field("userVO.userName","name")
.field("userVO.userAge","userAge")
.register();
UserVO userVO = new UserVO("chenssy",18);
Person person = new Person(userVO);
UserBO userBO = mapperFactory.getMapperFacade().map(person,UserBO.class);
System.out.println("userName:" + userBO.getName() + " --- userAge:" + userBO.getUserAge() );
}
运行结果:
userName:chenssy --- userAge:18
Bean 映射工具选择
以下内容摘自:https://www.jianshu.com/p/40e0e64797b9
- BeanUtils
Apache的BeanUtils和spring的BeanUtils中拷贝方法的原理都是先用jdk中 java.beans.Introspector类的getBeanInfo()方法获取对象的属性信息及属性get/set方法,接着使用反射(Method的invoke(Object obj, Object... args))方法进行赋值。Apache支持名称相同但类型不同的属性的转换,spring支持忽略某些属性不进行映射,他们都设置了缓存保存已解析过的BeanInfo信息。
- BeanCopier
cglib的BeanCopier采用了不同的方法:它不是利用反射对属性进行赋值,而是直接使用ASM的MethodVisitor直接编写各属性的get/set方法(具体过程可见BeanCopier类的generateClass(ClassVisitor v)方法)生成class文件,然后进行执行。由于是直接生成字节码执行,所以BeanCopier的性能较采用反射的BeanUtils有较大提高,这一点可在后面的测试中看出。
- Dozer
使用以上类库虽然可以不用手动编写get/set方法,但是他们都不能对不同名称的对象属性进行映射。在定制化的属性映射方面做得比较好的有Dozer,Dozer支持简单属性映射、复杂类型映射、双向映射、隐式映射以及递归映射。可使用xml或者注解进行映射的配置,支持自动类型转换,使用方便。但Dozer底层是使用reflect包下Field类的set(Object obj, Object value)方法进行属性赋值,执行速度上不是那么理想。
- Orika
那么有没有特性丰富,速度又快的Bean映射工具呢.,Orika是近期在github活跃的项目,底层采用了javassist类库生成Bean映射的字节码,之后直接加载执行生成的字节码文件,因此在速度上比使用反射进行赋值会快很多。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
