4-3、InnoDB中的锁
虽然锁机制是InnoDB引擎中为了保证事务性而自然存在的,在索引、表结构、配置参数一定的前提下,InnoDB引擎加锁过程是一样的,所以理论上来说也就 不存在“锁机制能够提升性能”这样的说法 。但如果技术人员不理解InnoDB中的锁机制或者混乱、错误的索引定义和同样混乱的SQL写操作语句共同作用,那么导致死锁出现的可能性就越大,需要InnoDB进行死锁检测的情况就越多,最终导致不必要的性能浪费甚至事务执行失败。所以理解InnoDB引擎中的锁机制可以帮助我们在高并发系统中尽可能 不让锁和死锁成为数据库服务的一个性能瓶颈 。
4-3-1、InnoDB中的锁类型
本文讲解的锁机制主要依据MySQL Version 5.6以及之前的版本(这是目前线上环境使用最多的版本),在MySQL Version 5.7以及最新的MySQL 8.0中InnoDB引擎的锁类型发生了一些变化(后文会提及),但基本思路没有变化。InnoDB引擎中的锁类型按照独占形式可以分为共享锁和排它锁(还有意向性共享锁和意向性排它锁);按照锁定数据的范围可以分为行级锁(其它引擎中还有页级锁的定义)、间隙锁、间隙复合锁??和表锁;为了保证锁的粒度能够至上而下传递,InnoDB中还设计有不能被用户干预的意向共享锁和意向排它锁。
- 共享锁(S锁)
由于InnoDB引擎支持事务,所以需要锁机制在多个事务同时工作时保证每个事务的ACID特性。共享锁的特性是多个事务可以同时为某个资源加锁后进行读操作,并且这些事务间不会出现相互等待的现象。
- 排它锁(X锁)
排它锁又被称为独占锁,一旦某个事务对资源加排它锁,其它事务就不能再为这个资源加共享锁或者排它锁了。一直要等待到当前的独占锁从资源上解除后,才能继续对资源进行操作。排它锁只会影响其他事务的加锁操作,也就是说如果其它事务只是使用简单的SELECT查询语句检索资源,就不会受到影响, 因为这些SELECT查询语句不会试图为资源加任何锁,也就不会受资源上已有的排它锁的影响 。我们可以用一张表表示排它锁和共享锁的互斥关系:
| 锁类型 | 共享锁S | 排它锁X |
|---|---|---|
| 共享锁S | 不互斥:多个共享锁不会相互影响相互等待 | 互斥:如果某个资源要加共享锁,则需要等待到资源上的排它锁配解除后,才能进行这个操作 |
| 排它锁X | 互斥:如果资源要加排它锁,则需要等待到资源上所有共享锁都被解除后,才能进行这个操作 | 互斥:如果某个资源要加排它锁,则需要等待到资源上的排它锁配解除后,才能进行这个操作 |
排它锁和共享锁的互斥关系
- 行级锁(Record lock)
行级锁是InnoDB引擎中对锁的最小支持粒度,即是指这个锁可以锁定数据表中某一个具体的数据行,锁的类型可以是排它锁也可以是共享锁。例如读者可以在两个独立事务中同时使用以下语句查询指定的行,但是两个事务并不会相互等待:
# lock in share mode 是为满足查询条件的数据行加共享锁
# 注意它和直接使用select语句的不同特性
select * from myuser where id = 6 lock in share mode;
- 间隙锁(GAP锁)
间隙锁只有在特定事务级别下才会使用,具体来说是“可重复读”(Repeatable Read )这样的事务级别,这也是InnoDB引擎默认的事务级别,它的大致解释是无论在这个事务中执行多少次相同语句的当前读操作,其每次读取的记录内容都是一样的,并不受外部事务操作的影响。间隙锁主要为了防止多个事务在交叉工作的情况下,特别是同时进行数据插入的情况下出现幻读。举一个简单的例子,事务A中的操作正在执行以下update语句的操作:
......
# 事务A正在执行一个范围内数据的更新操作
# 大意是说将用户会员卡号序列大于10的所有记录中user_name字段全部更新为一个新的值
update myuser set user_name = '用户11' where user_number >= 10;
......
其中user_number带有一个索引(后续我们将讨论这个索引类型对间隙锁策略的影响),这样的检索条件很显然会涉及到一个范围的数据都将被更新(例如user_number==10、13、15、17、19、21……),于此同时有另一个事务B正在执行以下语句:
......
# 事务B正在执行一个插入操作
insert into myuser(.........,'user_number') values (.........,11);
# 插入一个卡号为11的新会员,然后提交事务B
......
如果InnoDB只锁住user_number值为10的非聚簇索引和相应的聚簇索引,显然就会造成一个问题:在A事务处理过程中,突然多出了一条满足更新条件的记录。事务A会很纠结的,很尴尬的。如果读者是InnoDB引擎的开发者,您会怎么做呢?正确的做法是为满足事务A所执行检索条件的整个范围加锁, 这个锁不是加在某个或某几个具体的记录上,因为那样做还是无法限制类似插入“一个卡号为11的新纪录”这样的情况 ,而是加在到具体索引和下一个索引之间,告诉这个索引B+树的其它使用者,包括这个索引在内的之后区域都不允许使用。这样的锁机制称为间隙锁(GAP锁)。
间隙锁和行级锁组合起来称为Next-Key Lock,实际上这两种锁一般情况下都是组合工作的。
- 表级锁:没有可以检索的索引,就无法使用InnoDB特定的锁。另外,索引失效InnoDB也会为整个数据表加锁。如果表级锁的性质是排它锁(实际上大多数情况是这样的锁),那么所有试图为这张数据表中任何资源加共享锁或者排它锁的事务都必须等待在数据表上的排它锁被解除后,才能继续工作。表级锁可以看作基于InnoDB引擎工作的数据表的 最悲观锁,它是InnoDB引擎为了保持事务特性的一场豪赌 。例如我们有如下的数据表结构:
uid(PK) varchar
user_name varchar
user_sex int
这张数据表中只有一个由uid字段构成的主索引。接着两个事务同时执行以下语句:
begin;
select * from t_user where uid = 2 lock in share mode;
#都先不执行commit,以便观察现象
#commit;
这里的select查询虽然使用的检索依据是uid, 但是设置检索条件时uid的varchar类型却被错误的使用成了int类型 。那么数据表将不再使用索引进行检索,转而进行全表扫秒。这是一种典型的索引失效情况,最终读者观察到的现象是,在执行以上同一查询语句的两个事务中,有一个返回了查询结果,但是另外一个一直为等待状态。以上的小例子也可以让读者看到,科学管理索引在InnoDB引擎中是何等重要。本文后续部分将向读者介绍表级锁的实质结构。
- 意向共享锁(IS锁)和意向排它锁(IX锁)
为了在某一个具体索引上加共享锁,事务需要首先为涉及到的数据表加意向共享锁(IS锁);为了在某一个具体所以上加排它锁,事务需要首先为涉及到的数据表加意向排它锁(IX锁)。这样InnoDB可以整体把握在并发的若干个事务中,让哪些事务优先执行更能产生好的执行效果。意向共享锁是InnoDB引擎自动控制的,开发人员无法人工干预,也不需要干预。
4-3-2、加锁过程实例
InnoDB引擎中的锁机制基于索引才能工作。对数据进行锁定时并不是真的锁定数据本身,而是对数据涉及的聚集索引和非聚集索引进行锁定 。在之前的文章中我们已经介绍到,InnoDB引擎中的索引按照B+树的结构进行组织,那么加锁的过程很明显就是在对应的B+树上进行加锁位置检索和进行标记的过程。并且InnoDB引擎中的非聚簇索引最终都要依靠聚簇索引才能找到具体的数据记录位置,所以加锁的过程都涉及到对聚簇索引进行操作。
SELECT关键字的查询操作一般情况下都不会涉及到锁的问题(这种类型的读操作称为快照读),但并不是所有的查询操作都不涉及到锁机制。只要SELECT属于某种写操作的前置子查询/检索或者开发人员显式为SELECT加锁,这些SELECT语句就涉及到锁机制——这种读操作称为当前读。而执行Update、Delete、Insert操作时,InnoDB会根据会根据操作中where检索条件所涉及的一条或者多条数据加排它锁。
为了进一步详细说明各种典型的加锁过程,本小节为读者准备了几个实例场景,并使用图文混合的方式从索引逻辑层面上进行说明。后续的几种实例场景都将以以下数据表和数据作为讲解依据:
CREATE TABLE `myuser` (
`Id` int(11) NOT NULL AUTO_INCREMENT,
`user_name` varchar(255) NOT NULL DEFAULT '',
`usersex` int(9) NOT NULL DEFAULT '0',
`user_number` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`Id`),
UNIQUE KEY `number_index` (`user_number`),
KEY `name_index` (`user_name`)
)
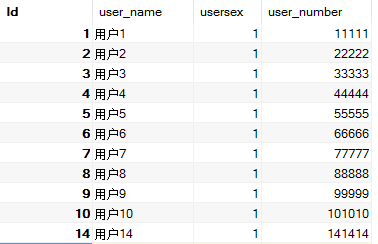
这张表中有三个索引,一个是以id字段为依据的聚簇索引,一个是以user_name字段为依据的非唯一键非聚簇索引,最后一个是以user_number字段为依据的唯一键非聚簇索引。我们将在实例场景中观察唯一键索引和非唯一键索引在加锁,特别是加GAP锁的情况的不同点。这张数据表中的数据情况如下图所示:
4-3-2-1、 行锁加锁过程
首先我们演示一个工作在InnoDB引擎下的数据表只加行锁的情况。
begin;
update myuser set user_name = '用户11' where id = 10;
commit;
以上事务中只有一条更新操作,它直接使用聚簇索引作为检索条件。聚簇索引肯定是一个唯一键索引,所以InnoDB得出的加锁条件也就不需要考虑类似“insert into myuser(id,………) values(10,………)”这样的字段重复情况。因为如果有事务执行了这样的语句,就会直接报错退出。那么最终的加锁结果就是:只需要在聚簇索引上加X锁。
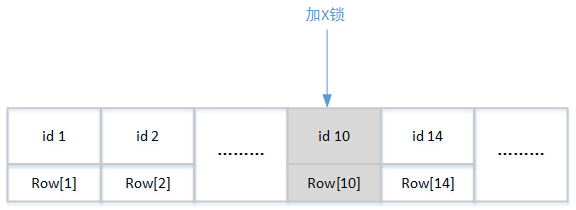
(额~~~你要问我为什么树结构会是连续遍历的?请重读B+树的介绍)
其它事务依然可以对聚簇索引上的其它节点进行操作,例如使用update语句更新id为14的数据:
begin;
update myuser set user_name = '用户1414' where id = 14;
commit;
当然,由于这样的执行过程没有在X锁临近的边界加GAP锁,所以开发人员也可以使用insert语句插入一条id为11的数据:
begin;
insert into myuser(id,user_name,usersex,user_number) values (11,'用户1_1',1,'110110110');
commit;
4-3-2-2、间隙锁加锁过程
工作在InnoDB引擎下的数据表,更多的操作过程都涉及到加间隙锁(GAP)的情况,这是因为毕竟大多数情况下我们定义和使用的索引都不是唯一键索引,都在“可重复读”的事务级别下存在“幻读”风险。请看如下事务执行过程:
begin;
update myuser set usersex = 0 where user_name = '用户8'
commit;
这个事务操作过程中的update语句,使用非唯一键非聚簇索引’name_index’进行检索。InnoDB引擎进行分析后发现存在幻读风险,例如可能有一个事务在同时执行以下操作:
begin;
insert into myuser(id,user_name,usersex,user_number) values (11,'用户8',1,'110110110');
# 或者执行以下插入
# insert into myuser(id,user_name,usersex,user_number) values (11,'用户88',1,'110110110');
commit;
所以InnoDB需要在X锁临近的位置加GAP锁,避免幻读:
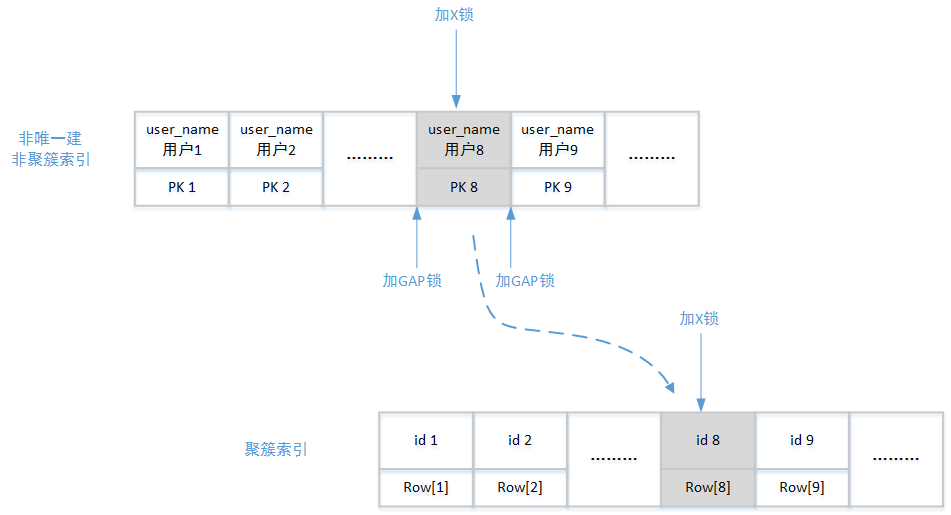
以上示意图有一个注意点,在许多技术文章中对GAP锁的讲解都是以int字段类型为基准,但是这里讲解所使用的类型是varchar。所以在加GAP锁的时候,看似’用户8’和’用户9’这两个索引节点没有中间值了。但是 字符串也是可以排序的 ,所以’用户8’和’用户9’这两个字符串之间实际上是可以放置很多中间值的,例如’用户88’、’用户888’、’用户8888’等。
这就是为什么另外的事务执行类似”insert into myuser(id,user_name,usersex,user_number) values (11,’用户88’,1,’110110110’);”这样的语句,同样会进入等待状态:因为有GAP锁进行独占控制。
4-3-2-3、表锁加锁过程
上文已经提到,索引一旦失效InnoDB也会为整个数据表加锁。那么“为整个数据表加锁”这个动作怎么理解呢?很多技术文章在这里一般都概括为一句话“在XXX数据表上加锁”。要弄清楚表锁的加载位置,我们就需要进行实践验证。首先,为了更好的查看InnoDB引擎的工作状态和加锁状态,我们需要打开InnoDB引擎的监控功能:
# 使用以下语句开启锁监控
set GLOBAL innodb_status_output=ON;
set GLOBAL innodb_status_output_locks=ON;
接下来我们就可以使用myuser数据表中没有键立索引的“usersex”字段进行加锁验证:
begin;
update myuser set user_name = '用户1414' where usersex = 1;
# 先不忙使用commit,以便观察锁状态
#commit;
在执行以上事务之前,myuser数据表中最新的记录情况如下图所示:
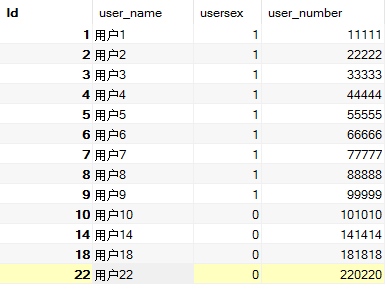
可以看到myuser数据表中一共有13条记录,其中满足“usersex = 1”的数据一共有9条记录。那么按照InnoDB引擎行锁机制来说,就应该只有这9条记录被锁定,那么是否如此呢?我们通过执行InnoDB引擎的状态监控功能来进行验证:
show engine innodb status;
# 以下是执行结果(省略了一部分不相关信息)
=====================================
2016-10-06 22:22:49 2f74 INNODB MONITOR OUTPUT
=====================================
.......
------------
TRANSACTIONS
------------
Trx id counter 268113
Purge done for trx's n:o < 268113 undo n:o < 0 state: running but idle
History list length 640
LIST OF TRANSACTIONS FOR EACH SESSION:
......
---TRANSACTION 268103, ACTIVE 21 sec
2 lock struct(s), heap size 360, 14 row lock(s), undo log entries 9
MySQL thread id 5, OS thread handle 0x1a3c, query id 311 localhost 127.0.0.1 root cleaning up
TABLE LOCK table `qiang`.`myuser` trx id 268103 lock mode IX
RECORD LOCKS space id 1014 page no 3 n bits 152 index `PRIMARY` of table `qiang`.`myuser` trx id 268103 lock_mode X
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
0: len 8; hex 73757072656d756d; asc supremum;;
Record lock, heap no 79 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 6; hex 000000041723; asc #;;
2: len 7; hex 2c000001e423fd; asc , # ;;
3: len 8; hex e794a8e688b73130; asc 10;;
4: len 4; hex 80000000; asc ;;
5: len 4; hex 80018a92; asc ;;
Record lock, heap no 80 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 4; hex 8000000e; asc ;;
1: len 6; hex 000000041721; asc !;;
2: len 7; hex 2b000001db176a; asc + j;;
3: len 8; hex e794a8e688b73134; asc 14;;
4: len 4; hex 80000000; asc ;;
5: len 4; hex 80022866; asc (f;;
Record lock, heap no 81 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 4; hex 80000012; asc ;;
1: len 6; hex 00000004171f; asc ;;
2: len 7; hex 2a000001da17b2; asc * ;;
3: len 8; hex e794a8e688b73138; asc 18;;
4: len 4; hex 80000000; asc ;;
5: len 4; hex 8002c63a; asc :;;
Record lock, heap no 82 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 4; hex 80000016; asc ;;
1: len 6; hex 00000004171d; asc ;;
2: len 7; hex 290000024d0237; asc ) M 7;;
3: len 8; hex e794a8e688b73232; asc 22;;
4: len 4; hex 80000000; asc ;;
5: len 4; hex 80035c3c; asc \<;;
Record lock, heap no 86 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 4; hex 80000001; asc ;;
1: len 6; hex 000000041747; asc G;;
2: len 7; hex 41000002580110; asc A X ;;
3: len 10; hex e794a8e688b731343134; asc 1414;;
4: len 4; hex 80000001; asc ;;
5: len 4; hex 80002b67; asc +g;;
...... 这里为节约篇幅,省略了6条行锁记录......
Record lock, heap no 93 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 4; hex 80000008; asc ;;
1: len 6; hex 000000041747; asc G;;
2: len 7; hex 410000025802b4; asc A X ;;
3: len 10; hex e794a8e688b731343134; asc 1414;;
4: len 4; hex 80000001; asc ;;
5: len 4; hex 80015b38; asc [8;;
Record lock, heap no 94 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 4; hex 80000009; asc ;;
1: len 6; hex 000000041747; asc G;;
2: len 7; hex 410000025802f0; asc A X ;;
3: len 10; hex e794a8e688b731343134; asc 1414;;
4: len 4; hex 80000001; asc ;;
5: len 4; hex 8001869f; asc ;;
......
通过以上日志我们观察到的比较重要情况是,编号为268103的事务拥有两个锁结构(2 lock struct(s)),其中一个锁结构是意向性排它锁IX,这个锁结构一共锁定了一条记录(这条记录并不是myuser数据表中的一条记录);另外一个锁结构是排它锁(X),这个锁结构加载在主键索引上(“page no 3 n bits 152 index ‘PRIMARY’ of table ‘qiang’.’myuser’”),并且锁定了13条记录。这13条记录就是myuser数据表中的所有数据记录,并非我们最先预计的9条记录。
这就是表锁在锁定规律上的具体表现:因为不能基于索引检索查询条件,所以就只能基于聚集索引进行全表扫描。因为不能确定聚集索引上哪些Page中数据满足检索条件,所以只能用排它锁一边锁定数据一边进行检索。因为要满足事务的ACID特性,所以在事务完成执行(或错误回滚)前都不能解除锁定:
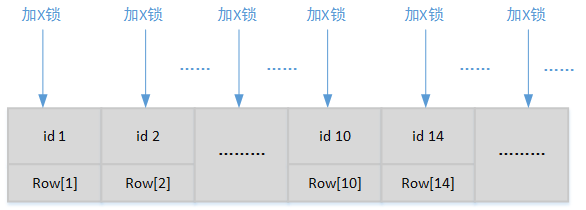
由于我们一直讨论的InnoDB引擎默认的事务级别是“可重复度”(Repeatable Read),所以为了避免幻读,InnoDB还会在每一个排它性行锁周围都加上间隙锁(GAP)。那么在这个事务级别下表锁最终的逻辑表现就如下图所示:
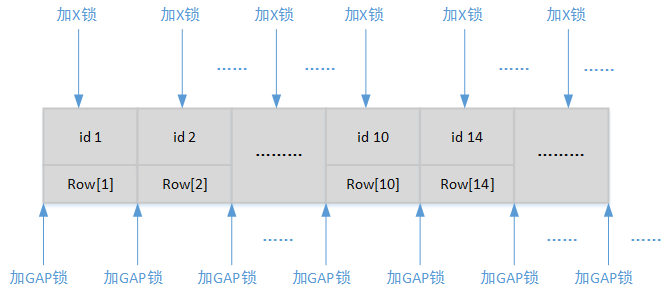
是的,没有索引可以提供检索依据的数据表正在进行一场豪赌!这还是只有13条数据的情况下,那么试想一下如果数据表中有10,000,000条记录呢?这不仅造成资源的浪费,更重要的是 表锁是造成死锁的重要原因,而且由此引发的InnoDB自动解锁代价非常昂贵 (后文会详细讲到)。
4-3-3、死锁
一旦构成死锁,InnoDB会尽可能的帮助开发者解除死锁。其做法是自动终止一些事务的运行从而释放锁定状态。在上一小节我们示范的多个加锁场景,它们虽然都构成锁等待,但是都没有构成死锁。那么本文就要首先说明一下,什么样的情况才构成死锁。
4-3-3-1、什么是死锁
两个或者多个事务相互等待对方已锁定的资源,而彼此都不为协助对方达成操作目而主动释放已锁定的资源,这样的情况就称为死锁。请区分正常的锁等待和死锁的区别,例如以下示意图中的锁等待并不构成死锁:
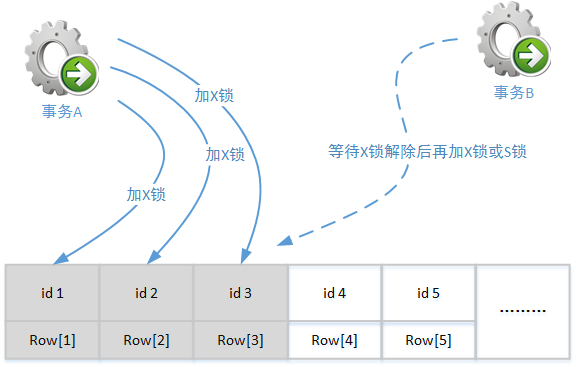
上图中的情况只能称为锁资源等待,这是因为当A事务完成处理后就会释放所占据的资源上的锁,这样B事务就可以继续进行处理。并且在这个过程中没有任何因素阻止A事务完成,也没有任何因素阻止B事务在随后的操作中获取锁。但是,以下示意图中的两个事务就在相互等待对方已锁定的资源,这就称为死锁:
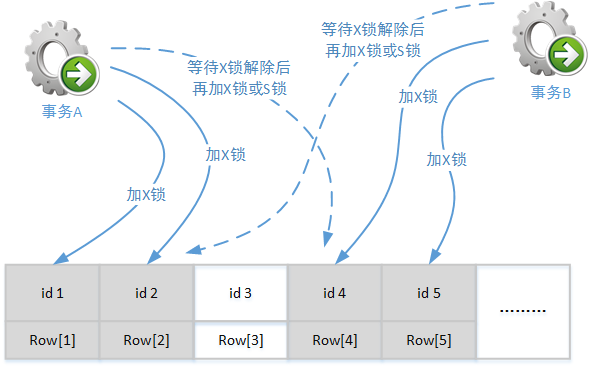
上图中A事务已为id1和id2这两个索引项加锁,当它准备为id4这个索引加锁时,却发现id4已经被事务B加锁,于是事务A进行等待过程。恰巧的是,B事务在为id4、id5加锁后,正在等待为id2这个索引项加锁。于是最后造成的结果就是事务A和事务B相互等待对方释放资源。注意,由于需要保证事务的ACID特性,所以A事务已经锁定的索引id1、id2在事务A的等待过程中,是不会被释放的;同样事务B已经锁定的索引id4、id5在等待过程中也不会被释放。很明显如果没有外部干预,这个互相等待的过程将一直持续下去。这就是一个典型的死锁现象。在实际应用场景中,往往会由超过两个事务共同构成死锁现象,甚至会出现强制终止某一个等待的事务后依然不能解除死锁的复杂情况。
4-3-3-2、死锁出现的原因
死锁造成的根本原因和上层MySQL服务和下层InnoDB引擎的协调方式有关: 在上层MySQL服务和下层InnoDB引擎配合进行Update、Delete和Insert操作时, 对满足条件的索引加X锁的操作是逐步进行的 。
当InnoDB进行update、delete或者insert操作时,如果有多条记录满足操作要求,那么InnoDB引擎会锁定一条记录(实际上是相应的索引)然后再对这条记录进行处理,完成后再锁定下一条记录进行处理。 这样依次循环直到所有满足条件的数据被处理完,最后再统一释放事务中的所有锁 。如果这个过程中某个将要锁定的记录已经被其它事务抢先锁定,则本事务就进入等待状态,一直等待到锁定的资源被释放为止。
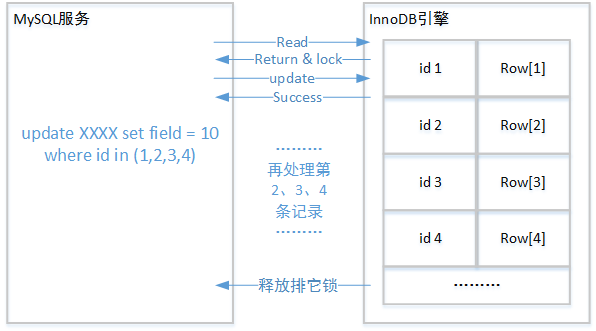
要知道在正式的生成环境中,可能会同时有多个事务对某一个数据表上同一个范围内的数据进行加锁(加X锁后进行写操作)操作。而InnoDB引擎和MySQL服务的交互采用的这种方式很可能使这些事务各自持有某些记录的行锁,但又不构成让事务继续执行下去的条件。那为什么说在生产环境下,多数死锁状态的出现是因为表锁导致的呢?
- 首先,表锁本身并不会导致死锁,它只是InnoDB中的一种机制 。但是表锁会一次锁定数据表中的所有聚集索引项。这就增加了表锁所在事务需要等待前序事务执行完毕才能继续执行的几率。而且这种等待状态还很可能在一个事务中出现多次——因为有多个事务在同时执行嘛。在这个过程中由于表锁逐渐占据了聚簇索引上绝大多数的索引项,所以这又增加了和其它正在执行的事务抢占锁定资源的,最终增加了死锁发生的几率。
- 由于需要进行表锁定的事务,需要将数据表中的所有聚集索引全部锁定后(如果在默认的事务级别下还要加GAP锁),才能完成事务的执行过程,所以这会导致后序事务全部进入等待状态。而InnoDB引擎根本无法预知表锁所在事务是否占据了后续资源需要使用的索引项。这就与之前的提到的情况一样,增加了死锁发生的几率。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
