1、概述
从本篇文章开始我们将花一定的篇幅向读者介绍MySQL的各种服务集群的搭建方式。大致的讨论思路是从最简的MySQL主从方案开始介绍,通过这种方案的不足延伸出更复杂的集群方案,并介绍后者是如何针对这些不足进行改进的。MySQL的集群技术方案特别多,这几篇文章会选择一些典型的集群方案向读者进行介绍。
2、MySQL最简单主从方案及工作原理
我们讲解的版本还是依据目前在生产环境上使用最多的Version 5.6进行,其中一些特性在Version 5.7和最新的Version 8.0中有所改进,但这不影响读者通过文章去理解构建MySQL集群的技术思路,甚至可以将这种机制延续到MariaDB。例如马上要提到的MySQL自带的日志复制机制(Replicaion机制)。
MySQL自带的日志复制机制称为MySQL-Replicaion。从MySQL很早的 Version 5.1版本就有Replicaion技术,发展到现有版本该技术已经非常成熟,通过它的支持技术人员可以做出多种MySQL集群结构。当然,后文我们还会介绍一些由第三方软件/组件支持的MySQL集群方案。
2-1、MySQL-Replicaion基本工作原理
Replicaion机制从技术层面讲,存在两种基本角色:Master和Salve 。Master节点负责在Replicaion机制中,向一个或者多个目标输出数据,而Salve节点负责在Replicaion机制中接受Master节点传来的数据。 在实际业务环境下,Master节点和Salve节点还分别有另外一个名字:Write节点和Read节点——是的,利用Replicaion机制我们可以搭建以读写分离为目标的MySQL集群服务 。但是为了保证读者在阅读文章内容时不会产生歧义,在本文(和后续文章)中我们都将使用Master节点和Salve节点这样的称呼。Replicaion机制依靠MySQL服务的二进制日志同步数据:
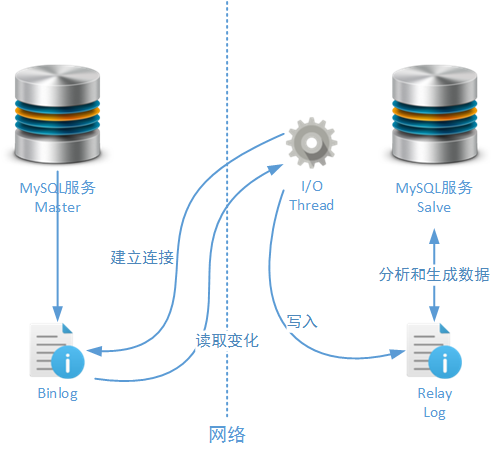
如上图所示,Salve在启动后会建立一个和Master节点的网络连接,当Master节点的二进制日志发生变化后,一个或者多个MySQL Salve服务节点就会通过网络接监听到这些变化日志。接着Salve节点会首先在本地将这些变化写入中继日志文件(Relay Log),这样做是为了尽量避免MySQL服务在出现异常时同步数据失败,其原理和之前介绍过的InnoDB Log的工作原理相似。当中继日志文件发生完成记录后,MySQL Salve服务会将这些变化反映到对应的数据表中,完成一次数据同步过程。最后Salve会更新重做日志文件中的更新点(Position),并准备下一次Replicaion操作。
在这个过程中多个要素都可以进行配置,例如可以通过sync_binlog参数配置Master节点上数据操作次数和日志写入次数配比关系、可以通过binlog_format参数配置日志数据的信息结构、可以通过sync_relay_log参数配置Salve节点上系统接收日志数据与写入中继日志文件次数的配比关系。这些参数和其它一些在示例中使用的参数会在本文后续小节进行介绍。
2-2、MySQL一主多从搭建方式
介绍完MySQL Replicaion机制的基本工作方式后,我们紧接着就来快速搭建由一个Master节点和一个Salve节点构成的MySQL集群。读者可以从这个一主一从的MySQL集群方案扩展出任何一主多从的集群方案:
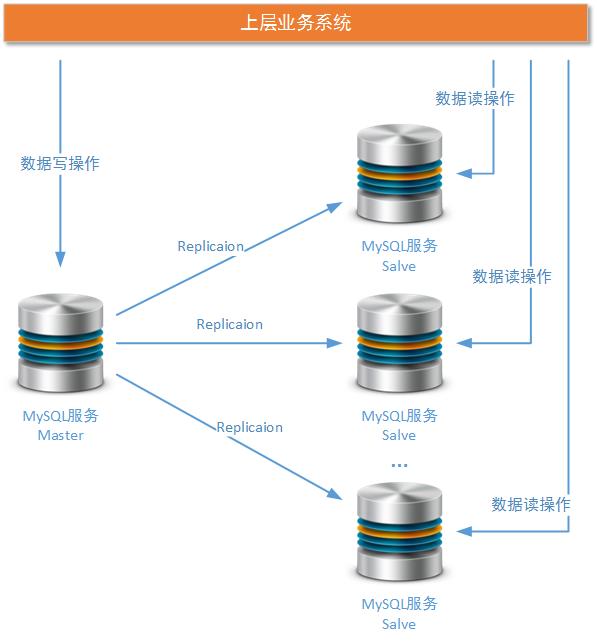
这个实例我们使用Version 5.6版本进行设置,当然version 5.7版本的安装也是类似的。另外,在Linux 操作系统上(Centos 5.6/5.7/6.X)安装MySQL服务和进行基本设置的过程,由于篇幅和文章定位原因这里就不再进行赘述。我们将分别在如下ip的Linux操作安装集群的Master节点和Salve节点:
- MySQL Master服务:192.168.61.140
- MySQL Salve服务:192.168.61.141
2-2-1、设置Master服务器
首先需要更改MySQL Master服务my.cnf主配置文件的信息, 主要目的是开启Master节点上的二进制日志功能 (注意这里说的日志并不是InnoDB引擎日志)。
# my.cnf文件中没有涉及Replicaion机制的配置信息,就不在这里列出了
......
# 开启日志
log_bin
# 以下这些参数会在后文进行说明
sync_binlog=1
binlog_format=mixed
binlog-do-db=qiang
binlog_checksum=CRC32
binlog_cache_size=2M
max_binlog_cache_size=1G
max_binlog_size=100M
# 必须为这个MySQL服务节点设置一个集群中唯一的 server id信息
server_id=140
......
在Master节点的设置中,有很多参数可以对日志的生成、存储、传输过程进行控制。具体可以参见MySQL官网中的介绍:http://dev.mysql.com/doc/refman/5.7/en/replication-options-binary-log.html。这里我们主要对以上配置示例中出现的参数进行概要介绍:
- sync_binlog:该参数可以设置为1到N的任何值。该参数表示MySQL服务在成功完成多少次不可分割的数据操作后(例如InnoDB引擎下的事务操作),才进行一次二进制日志文件的写入操作。设置成1时,写入日志文件的次数是最频繁的,也会造成一定的I/O性能消耗,但同时这样的设置值也是最安全的。
- binlog_format:该参数可以有三种设置值:row、statement和mixed。row代表二进制日志中记录数据表每一行经过写操作后被修改的最终值。各个参与同步的Salve节点,也会参照这个最终值,将自己数据表上的数据进行修改;statement形式是在日志中记录数据操作过程,而非最终的执行结果。各个参与同步的Salve节点会解析这个过程,并形成最终记录;mixed设置值,是以上两种记录方式的混合体,MySQL服务会自动选择当前运行状态下最适合的日志记录方式。
- binlog-do-db:该参数用于设置MySQL Master节点上需要进行Replicaion操作的数据库名称。
- binlog_checksum:该参数用于设置Master节点和Salve节点在进行日志文件数据同步时,所使用的日志数据校验方式。这个参数是在version 5.6版本开始才支持的新配置功能,默认值就是CRC32。 如果MySQL集群中有MySQL 节点使用的是version 5.5或更早的版本,请设置该参数的值为none 。
- binlog_cache_size:该参数设置Master节点上为每个客户端连接会话(session)所使用的,在事务过程中临时存储日志数据的缓存大小。如果没有使用支持事务的引擎,可以忽略这个值的设置。但是一般来说我们都会使用InnoDB引擎,所以该值最好设置成1M——2M,如果经常会执行较复杂的事务,则可以适当加大为3M——4M。
- max_binlog_cache_size:该值表示整个MySQL服务中,能够使用的binlog_cache区域的最大值。该值不以session为单位,而是对全局进行设置。
- max_binlog_size : 该参数设置单个binlog文件的最大大小。MySQL服务为了避免binlog日志出错或者Salve同步失败,会在两种情况下创建新的binlog文件:一种情况是MySQL服务重启后,另一种情况是binlog文件的大小达到一个设定的阀值(默认为1GB)。max_binlog_size参数就是设置这个阀值的。
完成my.cnf文件的更改后,重启Linux MySql服务新的配置就生效了。接下来需要在Master节点中设置可供连接的Salve节点信息,包括进行Replicaion同步的用户和密码信息:
# 只用MySQL客户端,都可以进行设置:
# 这里我们直接使用root账号进行同步,但是生产环境下不建议这样使用
> grant replication slave on *.* to root@192.168.61.141 identified by '123456'
# 通过以下命令,可以查看设置完成后的Master节点工作状态
> show master status;
+----------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------+----------+--------------+------------------+-------------------+
| kp2-bin.000002 | 404 | qiang | | |
+----------------+----------+--------------+------------------+-------------------+
以上master节点状态的描述中,File属性说明了当前二进制日志文件的名称,它的默认位置在Linux操作系统下的var/lib/mysql目录下。Position属性说明了当前已完成日志同步的数据点在日志文件中的位置。Binlog_Do_DB属性是我们之前设置的,需要进行Replicaion操作的数据库名称,Binlog_Ignore_DB属性就是明确忽略的,不需要进行Replicaion操作的数据库名称。
2-2-2、设置Salve服务器
完成MySQL Master服务的配置后,我们来看看Salve节点该如何进行设置。这里我们只演示一个Salve节点的设置,如果您还要在集群中增加新的Salve节点,那么配置过程都是类似的。无非是要注意在Master节点上增加新的Salve节点描述信息。
首先我们还是需要设置Salve节点的my.cnf文件:
# my.cnf文件中没有涉及Replicaion机制的配置信息,就不在这里列出了
......
# 开启日志
log-bin
sync_relay_log=1
# 必须为这个MySQL服务节点设置一个集群中唯一的server id信息
server_id=140
......
在MySQL官方文档中也详细描述了中继日志的各种控制参数,这里我们只使用了sync_relay_log参数。这个参数说明了Salve节点在成功接受到多少次Master同步日志信息后,才刷入中继日志文件。这个参数可以设置为1到N的任意一个值,当然设置为1的情况下虽然会消耗一些性能,但对于日志数据来说却是最安全的。
Salve的设置相对简单,接下来我们需要在Salve端开启相应的同步功能。主要是指定用于同步的Master服务地址、用户和密码信息:
# 请注意这里设置的用户名和密码信息要和Master上的设置一致
# 另外master log file所指定的文件名也必须和Master上使用的日志文件名一致
> change master to master_host='192.168.61.140',master_user='root',master_password='123456', master_log_file='kp2-bin.000002',master_log_pos=120;
# 启动Savle同步
> start slave;
# 然后我们就可以使用以下命令查看salve节点的同步状态
> show slave status;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.61.140
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: kp2-bin.000002
Read_Master_Log_Pos: 404
Relay_Log_File: vm2-relay-bin.000002
Relay_Log_Pos: 565
Relay_Master_Log_File: kp2-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
Master_Server_Id: 140
Master_UUID: 19632f72-9a90-11e6-82bd-000c290973df
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
......
Auto_Position: 0
完成以上过程,一主一从的MySQL集群就配置完成了。
2-3、一主多从方案的使用建议
一主多从的MySQL集群方案, 已经可以解决大部分系统结构化数据存储的性能要求 。特别是那种数据查询频率/次数远远大于数据写入频率/次数的业务场景,例如电商系统的商品模块、物流系统的车辆/司机信息模块、电信CRM系统的客户信息模块、监控系统中保存的基本日志数据。但是这种架构方案并不能解决所有的问题,而且方案本身有一些明显的问题(后文详细讨论),所以在这里本文需要为各位将要使用类似MySQL集群方案的读者提供一些使用建议。
-
Master单节点性能应该足够强大,且只负责数据写入操作:一主多从的MySQL集群方式 主要针对读密集型业务系统,其主要目标是将MySQL服务的读写压力进行分离 。所以Master节点需要集中精力处理业务的写操作请求,这也就意味着业务系统所有的写操作压力都集中到了这一个节点上(write业务操作)。我们暂且不去分析这个现象可能导致的问题(后续内容会提到这种做法的问题),但这至少要求Master节点的性能足够强大。这里的性能不单单指通过MySQL InnoDB引擎提供的各种配置(一般我们使用InnoDB引擎),并结合业务特点所尽可能榨取的性能,最根本的还需要提升Master节点的硬件性能。
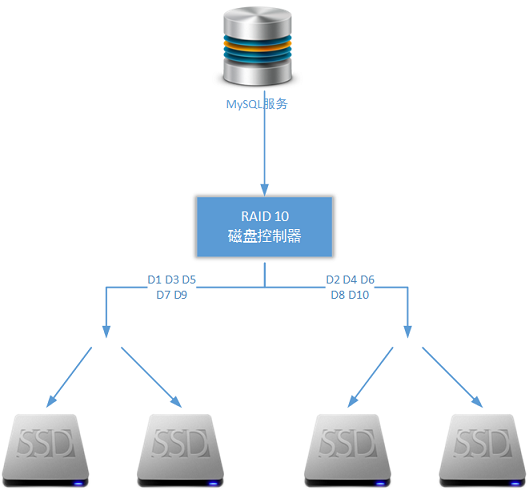
使用固态硬盘作为MySQL服务的块存储基础,并使用RAID 10磁盘阵列作为硬件层构建方案——这是生产环境下单个MySQL服务节点的基本组成逻辑,当然读者可以视自己生产环境下的的实际容量和性能要求进行必要的调整:
-
应使用一个独立的Salve节点作为备用的Master节点, 虽然这种方式不可作为异地多活方案的基础但可作为本地高可用方案的实现基础 。当然,为了防止由于日志错误导致的备份失败,这个备份的Salve节点也可以采用MySQL Replicaion机制以外的第三方同步机制,例如:Rsync、DRBD。Rsync是笔者在工作实践中经常使用的,进行MySQL数据增量同步的方式,而DRBD的差异块同步方式是互联网上能够找到最多资料的方式:
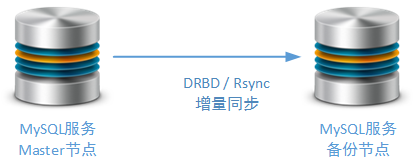
在后续的文章中,我们还会专门讨论针对Master节点的集群调整方案,并且建议读者如何使用适合系统自身业务的高可用方案。例如使用Keepalived / Heartbeat进行主备Master节点的切换:
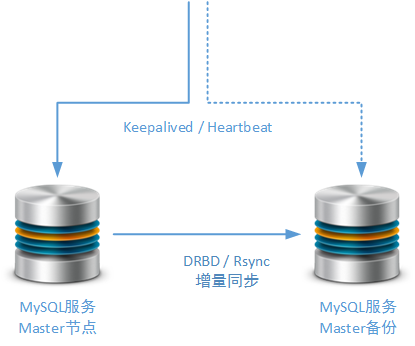
-
复杂的统计查询需要专门的Salve节点进行支持。参与生产环境实时业务处理的任何MySQL服务节点,在这些服务节点上所运行的SQL查询应该尽可能简单,并且需要使用索引对检索进行支持。特别是数据量非常大的数据表,必须保证所有的检索操作都有索引提供支持,否则Table Full Scan的检索过滤方式不但会拖慢检索操作本身,还可能会明显拖慢其它的事务操作。通过MySQL提供的执行计划功能,技术人员能够很方便实现以上的要求。如果您的业务系统存在复杂的业务查询要求,例如周期性的财务流水报表,周期性的业务分组统计报表等,那么您最好专门 准备一个(或多个)脱离实时业务的Salve节点 ,完成这个工作。
3、方案暴露的问题
但是这种MySQL集群方案也存在很多问题需要进一步改进。 在后续的文章中,我们会依次讨论MySQL集群中还存在的以下问题 :
- 面向上层系统的问题:在MySQL一主多从集群中,存在过个服务节点。那么当上层业务系统进行数据库操作时(无论是写操作还是读操作),是否需要明确知道这些具体的服务节点,并进行连接呢?要知道,当上层业务系统需要控制的要素变得原来越多时,需要业务系统开发人员投入的维护精力就会呈几何级增长。
- 高可用层面的问题:在MySQL一主多从集群中,虽然存在多个Salve节点(read业务性质节点),但是一般只存在一个Master节点(write业务性质节点)。某一个(或多个)Salve节点崩溃了,不会对整个集群造成太大影响(但可能影响上层业务系统的某一个子系统)。那么MySQL集群的短板在于只有一个Master节点——一旦它崩溃了,整个集群就基本上无法正常工作。所以我们必须想一些办法改变这个潜在风险。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
