1、概述
从本篇文章开始,我们将向读者介绍几种Redis的高可用高负载集群方案。除了介绍Redis 3.X版本中推荐的原生集群方案外,还会介绍使用第三方组件搭建Redis集群的方法。本文我们会首先介绍Redis的高可用集群方案。
2、Redis高可用方案
Redis提供的高可用方案和我们介绍过的很多软件的高可用方案类似,都是使用主从节点的思路。即是有一个Master节点在平时提供服务,另外一个或多个Slave节点在平时不提供服务(或只提供数据读取服务)。当Master节点由于某些原因停止服务后,再人工/自动完成Slave节点到Master节点的切换工作,以便整个Redis集群继续向外提供服务。既然是要进行角色切换,且要求这些节点针对外部调用者来说没有任何不同, 最重要的就是Master节点和Slave节点的数据同步过程。数据同步最关键的设计思路是如何在数据一致性和同步性能上找到一个完美的平衡点 。
同步复制的工作思路可以概括为:Master节点的任何数据变化都会立即同步到一个或多个Slave节点上。只要一个Slave节点同步失败(例如超时),都会认为整个数据写操作过程失败。这样的设计考虑侧重于 保证各节点上的数据绝对一致,完全没有考虑对Master节点的响应性能,甚至会出现Master节点为了保证数据一致性而停止对后续写操作请求的响应 。
异步复制的工作思路可以概括为:Master节点首先保证对外部请求的响应性能,它和Slave节点的数据同步一般由一个新的进程/线程独立完成。数据复制过程由Slave节点周期性发起或者由它一直驻留在Master节点的连接进行实时监控又或者由Master节点主动推送数据,再或者是同时使用多个异步复制过程。 由于在Slave节点进行数据同步时,Master节点一直在处理新的数据写请求,所以Slave节点已完成同步的数据和Master上的实时数据一般会存在一些差异 。例如MySQL原生支持的数据复制过程,就是一个异步过程。
很显然异步复制思路在对调用者的响应性能上,表现要比同步复制好得多。 但如果由于异步复制而导致的节点间数据差异达到某种程度,就失去了数据同步的意义了。所以如何减少节点间的数据差异就成为异步复制过程中需要关注的要点 。而后者的处理办法就有很多了,例如MySQL由第三方插件支持的半同步方式,又例如讲解ActiveMQ消息队列时提到的AutoAck和DUPS_OK_ACK,再例如我们下文介绍的Diskless Replication和Master写保护。
2-1、主从复制工作过程
Redis的主从复制功能除了支持一个Master节点对应多个Slave节点的同时进行复制外,还支持Slave节点向其它多个Slave节点进行复制。这样就使得架构师能够灵活组织业务缓存数据的传播,例如使用多个Slave作为数据读取服务的同时,专门使用一个Slave节点为流式分析工具服务。Redis的主从复制功能分为两种数据同步模式:全量数据同步和增量数据同步。

上图简要说明了Redis中Master节点到Slave节点的全量数据同步过程。当Slave节点给定的run_id和Master的run_id不一致时,或者Slave给定的上一次增量同步的offset的位置在Master的环形内存中无法定位时(后文会提到),Master就会对Slave发起全量同步操作。这时 无论您是否在Master打开了RDB快照功能,它和Slave节点的每一次全量同步操作过程都会更新/创建Master上的RDB文件 。在Slave连接到Master,并完成第一次全量数据同步后,接下来Master到Slave的数据同步过程一般就是增量同步形式了(也称为部分同步)。增量同步过程不再主要依赖RDB文件,Master会将新产生的数据变化操作存放在一个内存区域,这个内存区域采用环形构造。过程如下:

为什么在Master上新增的数据除了根据Master节点上RDB或者AOF的设置进行日志文件更新外,还会同时将数据变化写入一个环形内存结构,并以后者为依据进行Slave节点的增量更新呢?主要原因有以下几个:
- 由于网络环境的不稳定,网络抖动/延迟都可能造成Slave和Master暂时断开连接,这种情况要远远多于新的Slave连接到Master的情况。如果以上所有情况都使用全量更新,就会大大增加Master的负载压力——写RDB文件是有大量I/O过程的,虽然Linux Page Cahe特性会减少性能消耗。
- 另外在数据量达到一定规模的情况下,使用全量更新进行和Slave的第一次同步是一个不得已的选择——因为要尽快减少Slave节点和Master节点的数据差异。所以只能占用Master节点的资源和网络带宽资源。
- 使用内存记录数据增量操作,可以有效减少Master节点在这方面付出的I/O代价。而做成环形内存的原因,是为了保证在满足数据记录需求的情况下尽可能减少内存的占用量。这个环形内存的大小,可以通过repl-backlog-size参数进行设置。
Slave重连后会向Master发送之前接收到的Master run_id信息和上一次完成部分同步的offset的位置信息。如果Master能够确定这个run_id和自己的run_id一致且能够在环形内存中找到这个offset的位置,Master就会发送从offset的位置开始向Slave发送增量数据。那么连接正常的各个Slave节点如何接受新数据呢?连接正常的Slave节点将会在Master节点将数据写入环形内存后,主动接收到来自Master的数据复制信息。
2-2、基本Master/Slave配置
Redis提供的主从复制功能的配置信息,在Redis主配置文件的“REPLICATION”部分。以下是这个部分的主要参数项说明:
- slaveof
:如果您需要将某个节点设置为某个Master节点的Slave节点,您需要在这里指定Master节点的IP信息和端口信息。这个设置项默认是关闭的,也即是说Master节点不需要设置这个参数。另外,除了通过配置文件设置外,您还可以通过Redis的客户端命令进行slaveof设定。 - slave-serve-stale-data:当master节点断开和当前salve节点的连接或者当前slave节点正在进行和master节点的数据同步时,如果收到了客户端的数据读取请求,slave服务器是否使用陈旧数据向客户端提供服务。该参数的默认值为yes。
- slave-read-only 是否将salve节点设置为“只读”。一旦设置为“只读”,表示这个Salve节点只会进行数据读取服务,如果客户端直接向这个Salve节点发送写数据的请求,则会收到错误提示。建议采用默认的“yes”值进行设定。
- repl-diskless-sync:上文已经介绍过Redis的主从复制功能基于RDB,后者的过程是将数据刷入RDB文件(实际上是Linux的Page Cache区域),然后基于RDB文件内容的更新情况和Salve当前已同步的数据标记点来进行Salve上的数据更新。所以这个过程实际会增加一定的数据延迟,消耗一定的处理资源。基于这个情况,Redis中提供了一种不经过物理磁盘设备就进行主从数据同步的技术,称为diskless。但是直到Redis version 3.2这个技术也一直处于试验状态,所以并不推荐在生产环境下使用:“
WARNING: DISKLESS REPLICATION IS EXPERIMENTAL CURRENTLY”。 - repl-diskless-sync-delay:这个参数只有在上一个参数设置为“yes”时才起作用,主要是设置在进行两次diskless模式的数据同步操作的时间间隔。默认为5秒。
- repl-ping-slave-period:Slave节点向Master节点发送ping指令的事件间隔,默认为10秒。
- repl-timeout:这是一个超时间,当某些操作达到这个时间时,Master和Slave双方都会认为对方已经断开连接。实际上您可以将这个时间看成是一个租约到期的时间。那么这个操作时间会影响哪些操作呢?A、向Slave进行的数据同步操作本身不能超过这个时间;B、Slave向Master发送一个PING指令并等待响应的时间;C、Master向Slave发送PONG回复并等待ACK的时间。
- repl-disable-tcp-nodelay:这个选项的默认值为no,它对优化主从复制时使用的网络资源非常有用。要明白这个参数的含义,就首先要解释一下tcp-nodelay是个什么玩意儿?TCP数据报的报文头包含很多属性,这些属性基本上起到记录和保证传输目的、传输状态的作用,但没有数据报的所携带的业务数据(称之为有效载荷)。那么很明显,20个字节内容的信息分成20个数据报进行传输和只用一个数据报进行传输,需要占用的网络资源就完全不一样。JohnNagle在1984年发明了一种减轻网络传输压力的算法,就是为了解决这个问题(算法的名字就叫做“Nagle”,后续的技术人员又做了很多改进和升级)。其基本思路就是将要发送的内容凑够一定的数量后,再用一个数据报发送出去。如果该属性设置为yes,Redis将使用“Nagle”算法(或类似算法),让数据报中的有效载荷凑够一定数量后,在发送出去;设置成no,Redis就不会这么做。
- repl-backlog-size:上文已经介绍过了Redis中为了进行增量同步所准备的环形内存区域,以及Redis这样做的原因额,所以这里就不再赘述了。这个选项就是用来设置环形内存的大小的,这个选项的默认值为1MB;正式的生产环境下可以稍微加大一些,例如5MB。
- slave-priority:当前Slave节点的优先级权重。我们后文会介绍一款Redis自带的监控和故障转移工具:Redis Sentinel,这个工具允许一个Master节点下有多个Slave节点,并且可以自动切换Slave节点为Master节点。如果Slave节点的优先级权重值越低,就会再切换时有限成为新的Master节点。
- min-slaves-to-write和min-slaves-max-lag:为了尽可能避免Master节点对应的多个Slave节点在数据复制过程中数据差异被越拉越大。Redis服务提供了一组拒绝数据写操作的策略,这个策略可以解释为:当Master上在min-slaves-max-lag时间(单位秒)间隔后,任然有min-slaves-to-write个Slave和它正常连接,那么Master才允许进行数据写操作。
2-3、Master和Slave设置实例
讨论了Redis中主从复制的基本原理和Redis主配置文件中针对主从复制的设定选项意义后,我们来看一个实际设置过程。注意,由于这个过程非常简单所以我们会“非常快”。首先Master服务器不需要针对主从复制做任何的设置(这不包括对主从复制过程的配置优化)。所以我们就直接来看Slave节点的配置:
- Slave节点上我们只需要做一件事情,就是打开slaveof选项:
......
# slaveof选项的设置,给定master节点的ip和port就可以了
# 192.168.61.140就是master节点
slaveof 192.168.61.140 6379
......
- 接着,我们马上就可以看看同步效果了。首先确保您的master节点使工作正常的,然后就可以启动Slave节点了:
......
5349:S 17 Dec 04:20:00.773 * Connecting to MASTER 192.168.61.140:6379
5349:S 17 Dec 04:20:00.773 * MASTER <-> SLAVE sync started
5349:S 17 Dec 04:20:00.774 * Non blocking connect for SYNC fired the event.
5349:S 17 Dec 04:20:00.775 * Master replied to PING, replication can continue...
5349:S 17 Dec 04:20:00.776 * Partial resynchronization not possible (no cached master)
5349:S 17 Dec 04:20:00.782 * Full resync from master: 976f0b31cbf6acd4fcc888301ea4639a7c591136:1
5349:S 17 Dec 04:20:00.864 * MASTER <-> SLAVE sync: receiving 119 bytes from master
5349:S 17 Dec 04:20:00.865 * MASTER <-> SLAVE sync: Flushing old data
5349:S 17 Dec 04:20:00.865 * MASTER <-> SLAVE sync: Loading DB in memory
5349:S 17 Dec 04:20:00.865 * MASTER <-> SLAVE sync: Finished with success
5349:S 17 Dec 04:20:01.068 * Background append only file rewriting started by pid 5352
5349:S 17 Dec 04:20:01.082 * AOF rewrite child asks to stop sending diffs.
5352:C 17 Dec 04:20:01.082 * Parent agreed to stop sending diffs. Finalizing AOF...
5352:C 17 Dec 04:20:01.082 * Concatenating 0.00 MB of AOF diff received from parent.
5352:C 17 Dec 04:20:01.082 * SYNC append only file rewrite performed
5352:C 17 Dec 04:20:01.082 * AOF rewrite: 6 MB of memory used by copy-on-write
5349:S 17 Dec 04:20:01.168 * Background AOF rewrite terminated with success
5349:S 17 Dec 04:20:01.168 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
5349:S 17 Dec 04:20:01.168 * Background AOF rewrite finished successfully
......
笔者在Slave节点上开启了定期的RDB快照和AOF日志功能,所以各位读者可以忽略那些日志信息,直接关注“Connecting to MASTER ….”和“MASTER <-> SLAVE …….”这些日志信息就好。
- 以下是Master节点上给出的日志信息
......
5614:M 17 Dec 04:20:00.789 * Slave 192.168.61.145:6379 asks for synchronization
5614:M 17 Dec 04:20:00.789 * Full resync requested by slave 192.168.61.145:6379
5614:M 17 Dec 04:20:00.789 * Starting BGSAVE for SYNC with target: disk
5614:M 17 Dec 04:20:00.791 * Background saving started by pid 5620
5620:C 17 Dec 04:20:00.814 * DB saved on disk
5620:C 17 Dec 04:20:00.815 * RDB: 6 MB of memory used by copy-on-write
5614:M 17 Dec 04:20:00.875 * Background saving terminated with success
5614:M 17 Dec 04:20:00.877 * Synchronization with slave 192.168.61.145:6379 succeeded
......
看来Master节点收到了Slave节点的连接信息,并完成了全量数据同步操作。
2-4、关闭RDB功能的说明
以上介绍的Master节点和Slave节点的设置是否特别简单?是的,实际上只需要打开了Slave节点上“REPLICATION”区域的slaveof选项就可以让Redis的主从复制功能运作起来。现在我们往回倒,回到上一篇文章的介绍。在上一篇文章介绍RDB快照功能的配置项时,文章提到了可以用以下方式关闭RDB快照功能:
# 以下为默认的设置为,注释掉即可
# save 900 1
# save 300 10
# save 60 10000
# 在设置以下选项,就可以关闭RDB功能
save ""
但是根据本文对Redis主从复制的介绍,我们可以发现 Redis的RDB快照功能实际上是无法真正关闭的 !以上所谓关闭RDB功能的设置,只是关闭了Redis服务在正常工作时定期快照的条件设定,但只要有Slave节点请求全量数据同步,Master节点就会强制做一次RDB快照。并且如果客户端主动发送BGSAVE命令,要求Redis服务进行RDB快照时,Redis也会被动执行RDB快照操作。
但是 本文还是建议在组建Redis高可用集群时,关闭Master节点上的RDB功能 。读者一定要清楚这样做的原因:这不是为了像个别网络资料说的那样真正关闭Redis的RDB快照功能,而是尽可能减少Master上主动进行RDB操作的次数,并将RDB快照工作转移到各个Slave节点完成。
3、Redis Sentinel
Redis服务提供了性能较高的主从复制功能,但是没有提供原生的Master——Slave的切换功能。也就是说如果您只是配置了Redis的主从复制功能,那么在Master节点出现故障时,您必须手动将一台Slave状态的节点切换为Master状态。当然这个问题在Redis Version 2.8 版本前是有标准解决方案的,那就是:Keepalived + Redis服务组成的高可用集群。
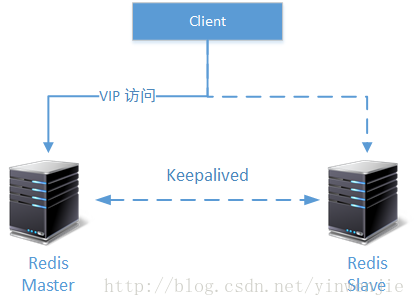
由Keepalived监控Redis高可用集群中Master节点的工作状态,并在异常情况下切换另一个节点接替工作。但是,这个方案是有一些问题了,其中之一就是所有的Slave节点在Standby状态时无法分担Master节点的任何性能压力——即使您设置了read-only等参数也不行,因为VIP根本不会把请求切过去。并且这种方式还不太方便监控Redis高可用集群中各个服务节点的实时状态。
从Version 2.8版本开始,Redis提供了一个原生的主从状态监控和切换的组件——Redis Sentinel。通过它技术人员不但可以完成Redis高可用集群的适时监控,还可以通过编程手段减轻集群中Master节点中读操作的压力。本节内容,我们向读者介绍这个Redis Sentinel的简单使用。
3-1、基本配置
由于Redis Sentinel是Redis原生支持的,以Redis Version 3.2为例,在下载安装后就可以直接使用命令“redis-sentinel”启动Sentinel了。Sentinel的主配置文件模板存放在Redis安装目录的下,默认名为“sentinel.conf”。以下命令可以启动Sentinel(启动Sentinel所依据的配置文件是一定要携带的参数):
# redis-sentinel ./sentinel.conf
Redis Sentinel本身也支持集群部署,而且为了在生产环境下避免Sentinel单点故障,所以也建议同时部署多个Sentinel节点。部署多个Sentinel还有一个原因,就是提高Master——Slave切换的准确性。以下的配置文件介绍会说明这一点。
下面我们介绍一些Sentinel主配置文件中的关键配置,注意Sentinel主配置文件也有类似Redis主配置文件提供的访问保护模式(protected-mode)、访问者权限控制(auth-pass)等,但是它们的意义基本上类似前文介绍过的,在Redis主配置文件中的相似内容,所以这里就不再赘述了。
-
sentinel monitor
: 这个属性是Redis Sentinel中的最主要设置元素,换句话说如果要开启Sentinel甚至可以只设置这个属性。它包括了四个参数:master-name,这个参数是一个英文名说明了Sentinel服务监听的Master节点的别名,如果一个Sentinel服务需要同时监控多个Master,这需要设置多个不同的master-name;ip和redis-port,指向sentinel需要监控的Redis集群最初的那个Master节点(为什么会是最初呢?后文会说明)的ip和端口;quorum,投票数量这个参数很重要,如果是Sentinel集群方式下,它设定“当quorum个Sentinel认为Master异常了,就判定该Master真的异常了”。单个Sentinel节点认为Master下线了被称为主管下线,而quorum个Sentinel节点都认为Master下线的情况被称为客观下线。
-
sentinel parallel-syncs
: 一旦原来的Master节点被认为客观下线了,Sentinel就会启动切换过程。大致来讲就是从当前所有Slave节点选择一个节点成为新的Master节点(这时在Redis中设定的slave-priority参数就会起作用了)。而其它的Slave其slaveof的Master信息将被sentinel切换到新的Master上。而一次同时并行切换多少个Slave到新的Master上就是这个参数决定的。如果整个Redis高可用集群的节点数量不多(没有超过6个),建议使用默认值就可以了。
-
主配置文件中被rewrite的参数内容:sentinel.conf文件中的配置内容会随着Sentinel的监控情况发生变化——由Sentinel程序动态写入到文件中。例如sentinel known-slave参数、sentinel current-epoch参数和sentinel leader-epoch参数。
注意,在Sentinel中您只需要配置最初的Master的监控位置,无需配置Master下任何Slave的位置,Sentinel会自己识别到这些Master直接的或者间接的Slave。
3-2、切换效果
介绍完配置后,我们来简单看一个Sentinel工作和切换的例子。这个例子中的有一个Master节点和一个Slave节点,当Master节点出现故障时,通过Sentinel监控到异常情况并自动完成Slave状态的切换。
-
首先请保证您的Master节点和Slave节点都是正常工作的,这个过程可以参见笔者之前文章的介绍:
| 节点地址|节点作用| | :-----: | :-----: | | 192.168.61.140 | RedisMaster | | 192.168.61.145 | RedisSlave | | 192.168.61.140 | RedisSentinel |
这里就不再赘述Redis Master和Redis Slave的内容了,因为在本文第2节中已经详细介绍过。实际上您只需要打开Slave节点的主配置文件,并增加slaveof的配置信息,将其指向Master的IP和端口就可以了。以下是Sentinel节点主要更改的配置信息:
......
sentinel monitor mymaster 192.168.61.140 6379 1
......
由于在测试环境中我们只使用了一个Sentinel节点,所以设置sentinel monitor配置项中的quorum为1就可以了,代表有一个Sentinel节点认为Master不可用了,就开启故障转移过程。当然生产环境下不建议这样使用。
- 之后我们使用以下Sentinel的主要配置信息启动Sentinel:
# redis-sentinel ./sentinel.conf
......
8576:X 19 Dec 00:49:01.085 # Sentinel ID is 5a5eb7b97de060e7ad5f6aa20475a40b3d9fd3e1
8576:X 19 Dec 00:49:01.085 # +monitor master mymaster 192.168.61.140 6379 quorum 1
......
-
之后主动终止原来Master的运行过程(您可以直接使用kill命令,或者拔掉网线,又索性直接关机),来观察Slave节点和Sentinel节点的日志情况:
当断开原来的Master节点后,Slave节点将提示连接失效并开始重试。当Sentinel开始进入故障转移并完成后,Salve又会打印相应的过程信息:
......
8177:S 19 Dec 00:53:17.467 * Connecting to MASTER 192.168.61.140:6379
8177:S 19 Dec 00:53:17.468 * MASTER <-> SLAVE sync started
8177:S 19 Dec 00:53:17.468 # Error condition on socket for SYNC: Connection refused
......
8177:M 19 Dec 00:53:18.134 * Discarding previously cached master state.
8177:M 19 Dec 00:53:18.134 * MASTER MODE enabled (user request from 'id=3 addr=192.168.61.140:51827 fd=5 name=sentinel-5a5eb7b9-cmd age=258 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=0 qbuf-free=32768 obl=36 oll=0 omem=0 events=r cmd=exec')
8177:M 19 Dec 00:53:18.138 # CONFIG REWRITE executed with success.
......
从以上Slave节点的内容可以看到,Slave被切换成了Master状态。那么Sentinel本身有哪些重要的日志信息呢?如下所示:
......
// 当前Sentinel节点确定原Master主观下线
8576:X 19 Dec 00:53:18.074 # +sdown master mymaster 192.168.61.140 6379
// 由于设置的quorum为1,所以一个Sentinel节点的主管下线就认为Master客观下线了
8576:X 19 Dec 00:53:18.074 # +odown master mymaster 192.168.61.140 6379 #quorum 1/1
// 第三代,每转移一次故障epoch的值+1,
// 不好意思,在书写测试实例前,本人已经自行测试了两次故障转移,所以这里看到的epoch为3
// 这个信息会自动写入到Sentinel节点的主配置文件中
8576:X 19 Dec 00:53:18.074 # +new-epoch 3
// 开始进行故障转移
8576:X 19 Dec 00:53:18.074 # +try-failover master mymaster 192.168.61.140 6379
// 选举出主导故障转移的Sentinel节点,因为不是所有Sentinel节点都会主导这个过程
8576:X 19 Dec 00:53:18.084 # +vote-for-leader 5a5eb7b97de060e7ad5f6aa20475a40b3d9fd3e1 3
8576:X 19 Dec 00:53:18.084 # +elected-leader master mymaster 192.168.61.140 6379
8576:X 19 Dec 00:53:18.084 # +failover-state-select-slave master mymaster 192.168.61.140 6379
// 选择提升哪一个slave作为新的master
8576:X 19 Dec 00:53:18.156 # +selected-slave slave 192.168.61.145:6379 192.168.61.145 6379 @ mymaster 192.168.61.140 6379
8576:X 19 Dec 00:53:18.156 * +failover-state-send-slaveof-noone slave 192.168.61.145:6379 192.168.61.145 6379 @ mymaster 192.168.61.140 6379
8576:X 19 Dec 00:53:18.211 * +failover-state-wait-promotion slave 192.168.61.145:6379 192.168.61.145 6379 @ mymaster 192.168.61.140 6379
// 提升原来的slave
8576:X 19 Dec 00:53:19.201 # +promoted-slave slave 192.168.61.145:6379 192.168.61.145 6379 @ mymaster 192.168.61.140 6379
// 试图重写所有salves节点的配置信息,并让它们指向新的master
8576:X 19 Dec 00:53:19.201 # +failover-state-reconf-slaves master mymaster 192.168.61.140 6379
// 故障转移结束
8576:X 19 Dec 00:53:19.250 # +failover-end master mymaster 192.168.61.140 6379
// 最终完成master节点的切换
8576:X 19 Dec 00:53:19.250 # +switch-master mymaster 192.168.61.140 6379 192.168.61.145 6379
// 注意原有的master节点会再显示一条作为主观下线,但是这次下线信息是以salve身份通知的
// 这是因为这次故障切换后,原来的master就算再上线,也只会作为Slave节点了
8576:X 19 Dec 00:53:19.251 * +slave slave 192.168.61.140:6379 192.168.61.140 6379 @ mymaster 192.168.61.145 6379
8576:X 19 Dec 00:53:49.305 # +sdown slave 192.168.61.140:6379 192.168.61.140 6379 @ mymaster 192.168.61.145 6379
......
通过Slave节点和Sentinel节点的日志可以看到,在经过了短暂的时间后Sentinel成功将唯一一个Slave节点转换成了Master节点,并继续向外部提供服务。
- 之后我们重新启动原有Master节点,看看会发生什么:
# 以下是原有Master启动后,在Sentinel显示的信息
......
8576:X 19 Dec 01:31:12.743 * +reboot slave 192.168.61.140:6379 192.168.61.140 6379 @ mymaster 192.168.61.145 6379
8576:X 19 Dec 01:31:12.805 # -sdown slave 192.168.61.140:6379 192.168.61.140 6379 @ mymaster 192.168.61.145 6379
......
一个非常重要的现象是,当原来的Master节点再次启动时, **即使配置文件中没有设定slaveof信息,它也会在Sentinel的协调下称为Slave节点** 。这是因为任何一次Master到Slave的切换都是要付出代价的,其中除了状态本身的判断外,还有Sentinel自身协调和选举过程(选举哪一个Sentinel进行实质的切换动作),还有新的Master的选定问题,甚至包括Slave的slaveof目标变化过程中需要处理的数据一致性问题等等工作。所以最好的办法就是: **只要能够保证Redis高可用集群持续工作,就不进行Master状态的切换** 。
3-3、Java客户端配合Sentinel的使用
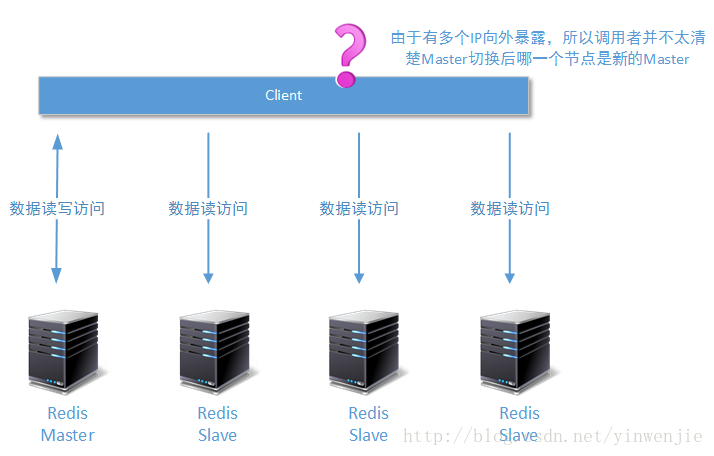
通过Sentinel组建的高可用集群对比通过第三方软件组建的高可用集群而言,有其明显的优点。例如可以实时返回集群中每个Redis节点的状态,且各节点间更能保持最佳的数据一致性,另外还可以在必要的时候通过转移客户端读操作,减轻Master节点的工作压力。但是它也有一个很明显的缺点,就是由于整个集群可以向调用者开放多个Redis节点的地址,且Sentinel本身并不能充当路由器的作用,所以当Redis高可用集群进行状态切换时,客户端可能并不清楚原有的Master节点已经失效了。如下图所示:
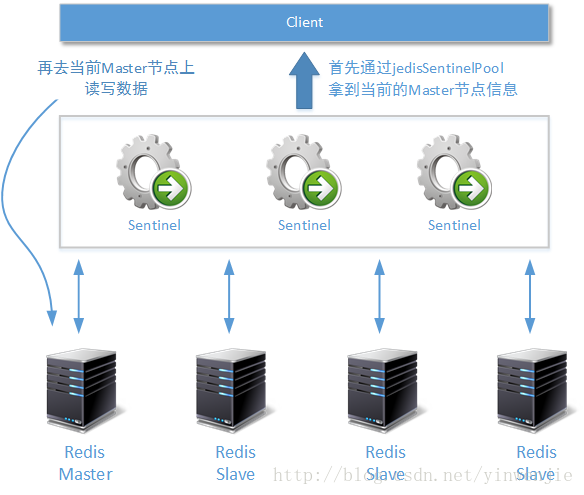
还好的是,Java最常用的Redis客户端jedis提供了一组针对Sentinel的集群工具,让客户端可以在获取当前Redis高可用集群中的Master节点后,再在这个Master节点上完成数据读写操作。但另外一个读操作的负载问题还是没有被解决,所有的读操作也只会在Master节点完成。
我们来看看一些关键代码:
......
// 这是基本的连接配置
// 当让这些属性都可以根据您的实际情况进行更改
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(100);
poolConfig.setMaxIdle(50);
poolConfig.setMinIdle(20);
poolConfig.setMaxWaitMillis(6 * 1000);
poolConfig.setTestOnBorrow(true);
// 以下是可用的多个Sentinel节点的ip和端口
Set<String> jedisClusterNodes = new HashSet<String>();
jedisClusterNodes.add("192.168.61.140:26379");
//如果有多个Sentinel一个一个添加进去
//jedisClusterNodes.add("192.168.61.139:26379");
JedisSentinelPool jedisSentinelPool = new JedisSentinelPool("mymaster", jedisClusterNodes , poolConfig);
// 开始插入信息
for(Integer index = 0 ; index < 10000 ; index++) {
// 获取最新的master信息
Jedis master = null;
try {
master = jedisSentinelPool.getResource();
} catch(JedisConnectionException e) {
// 如果出现异常,说明当前的maser断开了连接,那么等待一段时间后重试
LOGGER.info("master is loss , waiting for try again......");
synchronized (MasterSlaveApp.class) {
MasterSlaveApp.class.wait(5000);
}
index--;
continue;
}
// 开始正式插入
master.set(("key" + index).getBytes(), index.toString().getBytes());
LOGGER.info("write : " + "key" + index);
synchronized (MasterSlaveApp.class) {
// 停止0.5秒,以便观察现象
MasterSlaveApp.class.wait(500);
}
}
jedisSentinelPool.close();
......
在示例代码中Sentinel节点只有一个,存在于192.168.61.140:26379上。如果是生产环境建议不要对Sentinel进行单点部署,否则一旦Sentinel单点崩溃会造成整个Redis高可用集群在客户端无法进行Master节点的切换。在初始阶段192.168.61.140:6379是master节点,然后我们在程序执行过程中将原有的master节点关闭,这时上面的客户端代码片段可能的输出以下日志信息(部分):
......
14639 [main] INFO redis_test.test.MasterSlaveApp - write : key29
16144 [main] INFO redis_test.test.MasterSlaveApp - master is loss , waiting for try again......
22148 [main] INFO redis_test.test.MasterSlaveApp - master is loss , waiting for try again......
28151 [main] INFO redis_test.test.MasterSlaveApp - master is loss , waiting for try again......
34155 [main] INFO redis_test.test.MasterSlaveApp - master is loss , waiting for try again......
40159 [main] INFO redis_test.test.MasterSlaveApp - master is loss , waiting for try again......
十二月 20, 2016 4:12:22 下午 redis.clients.jedis.JedisSentinelPool initPool
信息: Created JedisPool to master at 192.168.61.145:6379
46163 [main] INFO redis_test.test.MasterSlaveApp - master is loss , waiting for try again......
51166 [main] INFO redis_test.test.MasterSlaveApp - write : key30
51670 [main] INFO redis_test.test.MasterSlaveApp - write : key31
......
==================================
后文内容预告:
4、Redis负载均衡方案
4-1、Twitter Twemproxy
4-2、Twemproxy存在的问题
5、Redis 3.X Cluster
5-1、Redis Cluster 简介
5-2、Redis Cluster 搭建实例
5-3、Client连接到Redis Cluster
==========各位读者对文章逻辑如果有质疑,欢迎在评论区留言。感谢帮助我指出错误的读者。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
