前面章节,我对Java网络编程的核心原理以及Netty这个主流的开源网络通信框架的原理和底层源码进行了详尽的分析。从本章开始,我将完成一个相对完整的 RPC 框架原型,帮助大家加深对 Netty 的理解,同时让大家看看实际的项目中到底是如何运用Netty进行开发的。
RPC 又称远程过程调用(Remote Procedure Call),用于解决分布式系统中服务之间的调用问题,目前主流的RPC框架有Dubbo、Thrift、gRPC 等。RPC 框架包含三个最重要的组件,分别是客户端、服务端和注册中心:

在一次 RPC 调用流程中,这三个组件是这样交互的:
- 服务端在启动后,将自己的服务信息注册到注册中心,客户端向注册中心订阅服务地址;
- 客户端从服务列表中选取其中一个的服务地址,然后通过本地代理模块 Proxy 调用服务端;
- Proxy 模块负责将方法、参数等数据转化成网络字节流,通过网络发送给服务端;
- 服务端接收到数据后进行解码,得到请求信息并进行处理,最后将结果响应给客户端。
虽然 RPC 调用流程很容易理解,但是实现一个完整的 RPC 框架涉及到很多内容,例如服务注册与发现、通信协议与序列化、负载均衡、动态代理等等,下面我一一进行讲解。
关于RPC框架的更多介绍以及分布式系统设计的核心思路,请参考我的专栏《分布式系统从理论到实战》。
一、基本功能
我们先来看要设计一个 RPC 框架,需要满足哪些基本功能要求。
1.1 服务注册/发现
在 RPC 框架中,一般使用注册中心来实现服务注册和发现的功能:
- 服务提供方节点上线后向注册中心注册服务地址,节点下线时需要从注册中心将节点元数据信息移除;
- 服务消费方节点向服务端发起调用时,从注册中心获取服务端的服务列表,然后在通过负载均衡算法选择其中一个服务节点进行调用。
在设计服务注册/发现机制时,特别需要注意服务下线的设计,也就是注册中心对服务下线的感知。实现服务优雅下线,比较好的方式是采用 主动通知 + 心跳检测 的方案。除了服务提供方下线时主动通知注册中心下线外,还需要增加节点与注册中心的心跳检测功能,心跳检测可以由节点或者注册中心负责,例如服务节点可以向注册中心每 60s 发送一次心跳包,如果 3 次心跳包都没有收到请求结果,可以认为该服务节点已经下线。
1.2 通信协议
既然 RPC 是远程调用,必然离不开网络通信协议。客户端在向服务端发起调用之前,需要考虑采用何种方式将调用信息进行编码,并传输到服务端。RPC 框架对性能有非常高的要求,目前主流 RPC 框架都支持多种协议,比如TCP、HTTP 协议,gRPC 则采用HTTP2。
除了协议本身之外,还需要考虑数据内容以及序列化算法,消费方一般需要将调用的接口、方法、请求参数、调用属性等信息序列化成二进制字节流传递给服务提供方,服务端接收到数据后,再把二进制字节流反序列化得到调用信息,然后利用反射调用对应方法,最后将返回结果、返回码、异常信息等返回给客户端。
比较常用的序列化算法有 Kryo、Hessian、Protobuf 等,这些序列化算法比 Java 原生的序列化更加高效:
- Kryo:序列化后占用字节数较少,网络传输效率更高,但是不支持跨语言;
- Hessian:目前业界使用较为广泛的序列化协议,它的兼容性好,支持跨语言,API 方便使用,序列化后的字节大小适中;
- Protobuf: gRPC 框架默认使用的序列化协议,Google 出品,支持跨语言、跨平台,具有较好的扩展性,并且性能优于 Hessian。但是 Protobuf 使用时需要编写特定的
.prpto文件,然后进行静态编译成不同语言的程序后拷贝到项目工程中,一定程度增加了开发复杂度。
关于序列化/反序列化,在使用时需要注意:
- 减少不必要的字段以及精简字段的长度,从而降低序列化后占用的字节数;
- 提供不同的序列化策略:可以将不同的字段拆分至不同的线程里进行反序列化,例如 Netty I/O 线程可以只负责 className 和 消息头 Header 的反序列化,然后根据 Header 分发到不同的业务线程池中,由业务线程负责反序列化消息内容 Content,这样可以有效地降低 I/O 线程的压力。
1.3 调用方式
成熟的 RPC 框架一般会提供四种调用方式:同步Sync、异步Future、回调Callback和单向 Oneway。
同步Sync
客户端线程发起 RPC 调用后,当前线程会一直阻塞,直至服务端返回结果或者处理超时异常。同步Sync调用一般是 RPC 框架默认的调用方式,为了保证系统可用性,客户端设置合理的超时时间是非常重要的。

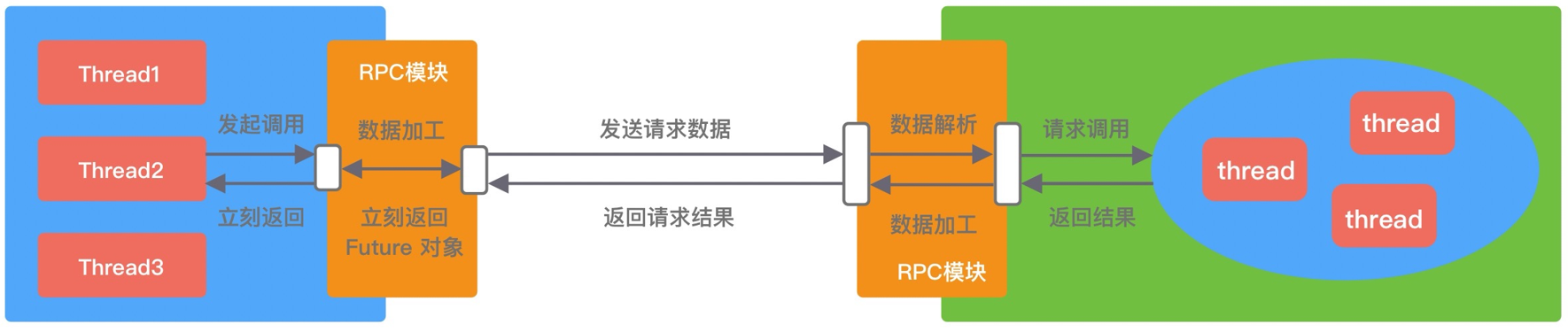
异步Future
客户端发起RPC调用后不会再阻塞等待,而是拿到 RPC 框架返回的 Future 对象,调用结果会被服务端缓存,客户端自行决定后续何时获取返回结果。当客户端主动获取结果时,该过程是阻塞等待的。Future 异步调用过程如下图所示:
回调Callback
客户端发起RPC调用时,将 Callback 对象传递给 RPC 框架,无须同步等待返回结果,直接返回。当获取到服务端响应结果或者超时异常后,再执行用户注册的 Callback 回调。所以 Callback 接口一般包含 onResponse 和 onException 两个方法,分别对应成功返回和异常返回两种情况。

单向Oneway
客户端发起请求之后直接返回,忽略返回结果。Oneway 方式是最简单的,具体调用过程如下图所示:

1.4 线程模型
线程模型是 RPC 框架需要重点关注的部分。首先,我们需要明确 I/O 线程 和 业务线程 的区别,以 Dubbo 框架为例(Dubbo 底层使用 Netty 进行网络通信):
- I/O 线程:Netty 中的 Boss 和 Worker 线程池,就可以看作 I/O 线程,主要负责处理网络数据,例如事件轮询、编解码、数据传输等;
- 业务线程:负责处理业务逻辑,比如数据库查询、复杂规则计算等各类耗时逻辑。
I/O 线程不应该进行复杂耗时的操作,必须将这些请求分发到业务线程池中进行处理,以免阻塞 I/O 线程。Dubbo 框架则更为灵活,提供了 5 种分发策略,让用户自己选择请求在哪类线程中处理:
| 策略类型 | 策略说明 |
|---|---|
| all | 所有消息都派发到业务线程池,这些消息包括请求、响应、连接事件、断开事件等,响应消息会优先使用对于请求所使用的线程池。 |
| direct | 所有消息都不派发到业务线程池,全部在I/O线程上直接执行 |
| message | 只有请求、响应消息派发到业务线程池,其他消息如连接事件、断开事件、心跳事件等,直接在I/O线程上执行 |
| execution | 只把请求类消息派发到业务线程池处理,但是响应、连接事件、断开事件、心跳事件等消息直接在I/O线程上执行 |
| connection | 在I/O线程上将连接事件、断开事件放入队列,有序地逐个执行,其他消息派发到业务线程池处理 |
1.5 负载均衡
在分布式系统中,服务提供者和服务消费者都会有多个节点,客户端在发起调用之前,需要感知有多少服务提供者节点可用,然后从中选取一个进行调用。所以,客户端需要根据服务端节点的状态信息,按照不同的策略实现负载均衡。
下面我介绍几种最常用的负载均衡策略:
- Round-Robin 轮询 :Round-Robin 是最简单有效的负载均衡策略,并没有考虑服务端节点的实际负载水平,而是依次轮询服务端节点;
- Weighted Round-Robin 权重轮询 :对不同负载水平的服务端节点增加权重系数,这样可以通过权重系数减少性能较差或者配置较低的节点流量。权重系数可以根据服务端负载水平实时进行调整,使集群达到相对均衡的状态;
- Least Connections 最少连接数 :客户端根据服务端节点当前的连接数进行负载均衡,客户端会选择连接数最少的一台服务器进行调用。Least Connections 策略只是服务端状态的其中一种维度,我们可以演化出最少请求数、CPU 利用率最低等其他维度的负载均衡方案;
- Consistent Hash 一致性 Hash :采用一致性 Hash 算法,通过 Hash 函数将对象和服务器节点放置在哈希环上,一般来说服务器可以选择 IP + Port 进行 Hash,采用该算法时,服务节点扩容或者下线时,可以尽可能保证客户端请求还是固定分配到同一个服务节点。
1.6 动态代理
RPC 框架一般通过服务端的接口存根进行调用,那怎么做到像调用本地接口一样调用远端服务呢?这就要依赖动态代理,以此屏蔽 RPC 框架的调用细节。
代理类是在运行时生成的,所以代理类的生成速度、生成的字节码大小都会影响 RPC 框架整体的性能和资源消耗,比较主流的动态代理框架有:JDK 动态代理、Cglib、Javassist、ASM、Byte Buddy:
- JDK 动态代理 :JDK 动态代理所生成的代理类是接口的实现类,不能代理接口中不存在的方法。在底层,JDK 动态代理是通过反射调用的形式代理类中的方法,比直接调用肯定是性能要慢的;
- Cglib 动态代理 :Cglib 是基于 ASM 字节码生成框架实现的,Cglib 生成的代理类是继承于被代理类的。Cglib并没有采用反射的方式调用被代理的方法,而是运行时动态生成一个新的 FastClass 子类,向子类中写入调用目标方法的逻辑,同时该子类会为代理类分配一个index 索引,FastClass 通过索引定位到需要调用的方法,这是一种空间换时间的优化思路;
- Javassist 和 ASM :二者都是 Java 字节码操作框架,使用起来难度较大,需要开发者对 Class 文件结构以及 JVM 都有所了解,但是它们都比反射的性能要高;
- Byte Buddy : 也是一个字节码生成和操作的类库,相比于 Javassist 和 ASM,Byte Buddy 提供了更加便捷的 API,用于创建和修改 Java 类,无须理解字节码的格式,而且 Byte Buddy 更加轻量,性能更好。
二、架构设计
上述是一个 RPC 框架最基本且核心的功能,如果你能自己动手完成上述功能,那么一个简易的 RPC 框架的 MVP 原型就完成了。但是,光这样还是远远不够的,我在专栏《分布式系统从理论到实战》中曾经反复强调过,设计一个分布式系统,必须从 高性能 、 高可用 、 可扩展 、 数据一致性 四个维度出发,考虑方方面面。
对于一个RPC框架而言,可扩展主要是服务提供方、消费方、注册中心的扩展,数据一致性也主要是注册中心对自身注册表维护的数据一致性。所以,本节,我主要从高性能和高可用两个维度来讨论RPC框架本身的架构设计,主要看看它在这两方面应该还需要满足哪些要求。
2.1 高性能
RPC 框架的性能取决于很多因素,我们通常会关注几个方面:I/O 模型、网络参数、序列化方法、内存管理等。接下来,我逐一介绍 RPC 框架针对性能这一块的常见设计。
I/O 模型
Netty 提供了高效的主从 Reactor 多线程模型,主Reactor线程负责新的网络连接 Channel 创建,然后把 Channel 注册到从Reactor线程,由从 Reactor 线程负责处理后续的 I/O 操作。
主从 Reactor 多线程模型很好地解决了高并发场景下单个 NIO 线程无法承载海量客户端连接建立以及 I/O 操作的性能瓶颈。所以,我们在I/O模型上,可以参考Netty的设计,比如Dubbo直接使用了Netty作为底层通讯组件,而Kafka则基于原生的Java NIO实现了Reactor模式。
以Netty为例,我们可以采用如下方式配置主从 Reactor 线程模型:
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
线程池中的线程数默认为 CPU核数 * 2 ,但这并不一定是最佳数量,需要根据实际的压测情况进行适当调整。
Netty 还提供了一个参数ioRatio,用于调整处理 I/O 事件 和 普通任务 的时间比例,默认值为50。对于高并发的 RPC 调用场景,ioRatio可以适当调大,让 Netty 有更多的时间执行 I/O 事件。
网络参数配置
如果底层采用TCP协议通信,那么我们一般会对TCP参数进行优化。以Netty为例,它提供了 ChannelOption 以便于我们优化 TCP 参数配置:
TCP_NODELAY
是否开启 Nagle 算法。Nagle 算法通过缓存的方式将网络数据包累积到一定量才会发送,从而避免频繁发送小的数据包。Nagle 算法 在海量流量的场景下非常有效,但是会造成一定的数据延迟。如果对数据传输延迟敏感,那么应该禁用该参数。
SO_BACKLOG
已完成三次握手的请求队列最大长度。同一时刻服务端可能会处理多个连接,在高并发海量连接的场景下,该参数应适当调大。但是 SO_BACKLOG 也不能太大,否则无法防止 SYN-Flood 攻击。
SO_SNDBUF/SO_RCVBUF
TCP 发送缓冲区和接收缓冲区的大小。为了能够达到最大的网络吞吐量,SO_SNDBUF 不应当小于带宽和时延的乘积。SO_RCVBUF 一直会保存数据到应用进程读取为止,如果 SO_RCVBUF 满了,接收端会通知对端 TCP 协议中的滑动窗口关闭,保证 SO_RCVBUF 不会溢出。
SO_SNDBUF/SO_RCVBUF 大小的设置建议参考消息的平均大小,不要按照最大消息来进行设置,这样会造成额外的内存浪费。更灵活的方式是可以动态调整缓冲区的大小,这时候就体现出 ByteBuf 的优势,Netty 提供的 ByteBuf 是可以支持动态调整容量的,而且提供了开箱即用的工具,例如可动态调整容量的接收缓冲区分配器 AdaptiveRecvByteBufAllocator。
SO_KEEPALIVE
连接保活。启用 TCP SO_KEEPALIVE 属性,TCP 会主动探测连接状态,Linux 默认为2小时进行一次心跳检测。TCP的KEEPALIVE机制主要用于回收死亡时间较长的连接,不适合实时性高的场景。
在海量连接的场景下,也许会遇到类似 "too many open files" 的报错,所以 Linux 操作系统最大文件句柄数基本是必须要调优,可以通过 vi /etc/security/limits.conf,添加如下配置:
soft nofile 1000000
hard nofile 1000000
修改保存以后,执行 sysctl -p 命令使配置生效,然后通过ulimit -a命令查看参数是否生效。
高低水位线
使用Netty,我们还可以设置高低水位线WRITE_BUFFER_HIGH_WATER_MARK和WRITE_BUFFER_LOW_WATER_MARK,这是两个非常重要的流控参数:
Netty 每次添加数据时都会累加数据的字节数,然后判断缓存大小是否超过所设置的高水位线,如果超过了高水位,那么 Channel 会被设置为不可写状态,直到缓存的数据大小低于低水位线以后,Channel 才恢复成可写状态;
Netty 默认的高低水位线配置是 32K ~ 64K,可以根据发送端和接收端的实际情况合理设置高低水位线,如果你没有足够的测试数据作为参考依据,建议不要随意更改高低水位线。高低水位线的设置方式如下:
// Server
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.childOption(ChannelOption.WRITE_BUFFER_HIGH_WATER_MARK, 32 * 1024);
bootstrap.childOption(ChannelOption.WRITE_BUFFER_LOW_WATER_MARK, 8 * 1024);
// Client
Bootstrap bootstrap = new Bootstrap();
bootstrap.option(ChannelOption.WRITE_BUFFER_HIGH_WATER_MARK, 32 * 1024);
bootstrap.option(ChannelOption.WRITE_BUFFER_LOW_WATER_MARK, 8 * 1024);
当缓存超过了高水位,Channel 会被设置为不可写状态,调用 isWritable() 方法会返回 false。所以建议在 Channel 写数据之前,使用 isWritable() 方法来判断缓存水位情况,防止因为接收方处理较慢造成 OOM。推荐的使用方式如下:
if (ctx.channel().isActive() && ctx.channel().isWritable()) {
ctx.writeAndFlush(message);
} else {
// handle message
}
序列化方式
在网络通信过程中,必然涉及序列化和反序列化操作,即将对象编码成字节,再把字节解码成对象的过程。序列化和反序列化属于高频且较笨重的操作,属于 RPC 框架中一个重要的性能优化点。在选择序列化方式时需要综合考虑各方面因素,如高性能、跨语言、可维护性、可扩展性等。
比较常用的序列化算法有 Kryo、Hessian、Protobuf 等,这些第三方序列化算法都比 Java 原生的序列化操作都更加高效。综合各方面因素以及实际口碑,个人比较推荐使用 Hessian 和 Protobuf 序列化协议。
关于 RPC 框架序列化进一步的性能优化采用章节1.2的建议:
内存管理
由于涉及网络I/O,那么必然涉及内存数据的拷贝,那么如何对内存进行管理就是RPC框架性能优化的一个核心问题。可以参考Netty的设计:
Netty 会使用堆外内存 DirectBuffer 进行 Socket 读写,相比使用HeapBuffer减少了一次内存拷贝。但是,堆外内存的创建和销毁成本更高,所以Netty又使用内存池来提高性能。对于数据量较小的一些场景,可以考虑直接使用 HeapBuffer,由 JVM 负责内存的分配和回收可能效率更高。
此外,Netty 还提供了一些技巧来避免内存拷贝:
- CompositeByteBuf 是 Netty 中实现零拷贝机制非常重要的一个数据结构,它可以组合多个 Buffer 对象合并成一个逻辑上的对象,避免通过传统内存拷贝的方式将几个 Buffer 合并成一个大的 Buffer,我们经常使用 CompositeByteBuf 拼接协议数据的 头部信息 Header 和消息体数据 Body。
- 在失败重试的场景,如果想保留 ByteBuf 继续使用,可以使用 copy() 方法拷贝原始 ByteBuf 的所有信息。但是深拷贝非常耗费性能,所以可以使用浅拷贝操作
oldBuffer.duplicate().retain()复制出独立的读写索引,底层分配的内存、引用计数都是与原始 ByteBuf 共享的,其中 retain() 又会将 ByteBuffer 的引用计数加 1,从而避免了 ByteBuffer 被释放。
GC优化
对不同场景下的网络应用程序进行 JVM 参数调优,可以取得很好的性能提升,以及避免 OOM 风险。不同业务系统的特性是不一样的,在此我只给出一些重要的注意事项。
- 堆内存 :-Xms 和 -Xmx 参数,-Xmx 用于控制 JVM Heap 的最大值,必须设置其大小,合理调整 -Xmx 有助于降低 GC 开销,提升系统吞吐量。-Xms 表示 JVM Heap 的初始值,对于生产环境的服务端来说 -Xms 和 -Xmx 最好设置为相同值;
- 堆外内存 :DirectByteBuffer 最容易造成 OOM 的情况,DirectByteBuffer 对象的回收需要依赖 Old GC 或者 Full GC 才能触发清理。如果长时间没有 Old GC 或者 Full GC 执行,那么堆外内存即使不再使用,也会一直在占用内存不释放。我们最好通过 JVM 参数
-XX:MaxDirectMemorySize指定堆外内存的上限大小,当堆外内存的大小超过该阈值时,就会触发一次 Full GC 进行清理回收,如果在 Full GC 之后还是无法满足堆外内存的分配,那么程序将会抛出 OOM 异常; - 新生代 :-Xmn 调整新生代大小,-XX:SurvivorRatio 设置 SurvivorRatio 和 eden 区比例。我们经常遇到 YGC 频繁的情况,应该清楚程序中对象的基本分布情况,如果存在大量朝生夕灭的对象,应适当调大新生代;反之应适当调大老年代。例如在类似百万长连接、推送服务等延迟敏感的场景中,老年代的内存增长缓慢,优化年轻代的空间大小以及各区的比例可以带来更大的收益。
native支持
从 4.0.16 版本起,Netty 提供了用 C++ 编写 JNI 调用的 Socket Transport,相比 JDK NIO 具备更高的性能和更低的 GC 成本,并且支持更多的 TCP 参数。
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-transport-native-epoll</artifactId>
<version>4.1.42.Final</version>
</dependency>
使用 Netty Native 非常简单,只需要替换相应的类即可:

线程绑定
如果是经常关注系统性能调优,一定挖掘过 Linux 操作系统 CPU 亲和性 的黑科技招数。CPU 亲和性是指在多核 CPU 的机器上线程可以被强制运行在某个 CPU 上,而不会调度到其他 CPU,也被称为绑核。当绑定线程到某个固定的 CPU 后,不仅可以避免 CPU 切换的开销,而且可以提高 CPU Cache 命中率,对系统性能有一定提升。
在 C/C++、Golang 中实现绑核操作是非常容易的事,遗憾的是在 Java 中是比较麻烦的。目前 Java 中有一个开源 affinity 类库,GitHub 地址https://github.com/OpenHFT/Java-Thread-Affinity。如果你的项目想引入使用它,需要先引入 Maven 依赖:
<dependency>
<groupId>net.openhft</groupId>
<artifactId>affinity</artifactId>
<version>3.0.6</version>
</dependency>
affinity 类库可以和 Netty 轻松集成,比较常用的方式是创建一个 AffinityThreadFactory,然后传递给 EventLoopGroup,AffinityThreadFactory 负责创建 Worker 线程并完成绑核。代码实现如下所示:
ThreadFactory threadFactory = new AffinityThreadFactory("worker", AffinityStrategies.DIFFERENT_CORE);
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup(4, threadFactory);
ServerBootstrap serverBootstrap = new ServerBootstrap().group(bossGroup, workerGroup);
2.2 高可用
RPC 框架作为一个分布式框架,需要考虑很多可用性方面的问题。
连接假死
客户端的心跳检测对于任何长连接的应用来说,都是一个非常基础的功能。要理解心跳的重要性,首先需要从网络连接假死的现象说起。
什么是连接假死呢?如果底层的TCP连接已经断开,但是服务器端并没有正常地关闭套接字,服务器端认为这条TCP连接仍然是存在的。连接假死的具体表现如下:
- 在服务器端,会有一些处于TCP_ESTABLISHED状态的“正常”连接;
- 但在TCP客户端,已经显示连接已经断开;
- 客户端此时虽然可以进行断线重连操作,但是上一次的连接状态依然被服务器端认为有效,并且服务器端的资源得不到正确释放,包括套接字上下文以及接收/发送缓冲区。
连接假死的情况虽然不常见,但是确实存在。服务器端长时间运行后,会面临大量假死连接得不到正常释放的情况。由于每个连接都会耗费CPU和内存资源,因此大量假死的连接会逐渐耗光服务器的资源,使得服务器越来越慢,IO处理效率越来越低,最终导致服务器崩溃。
连接假死通常是由以下多个原因造成的,例如:
- 应用程序出现线程堵塞,无法进行数据的读写;
- 网络相关的设备出现故障,例如网卡、机房故障;
- 网络丢包,公网环境非常容易出现丢包和网络抖动等现象。
解决假死的有效手段是:
- 客户端定时进行心跳检测;
- 服务器端定时进行空闲检测。
TCP 中已经有 SO_KEEPALIVE 参数,为什么我们还要在应用层加入心跳机制呢? TCP KEEPALIVE 是有严重缺陷的,KEEPALIVE 设计初衷是为了清除和回收处于死亡状态的连接,只能检查连接是否活跃,但是不能判断连接是否可用,例如服务端如果处于高负载假死状态,但是连接依然是处于活跃状态的。而心跳机制不仅能说明应用程序是活跃状态,更重要的是可以判断应用程序是否还在正常工作。
服务端空闲连接检测
服务端空闲连接检测,是指每隔一段时间,服务端就检测连接是否有数据读写,如果服务端一直能收到客户端连接发送过来的数据,说明连接处于活跃状态。
Netty 提供了开箱即用的 IdleStateHandler 来实现连接空闲检测,如果我们想把一定时间间隔内没有读到数据的客户端连接进行关闭,可以采取如下的实现方式:
public class RpcIdleStateHandler extends IdleStateHandler {
public RpcIdleStateHandler() {
// IdleStateHandler 的构造函数支持设置读空闲时间、写空闲时间、读写空闲时间
// 如果服务端60s没未读到数据,就会回调channelIdle()方法
super(60, 0, 0, TimeUnit.SECONDS);
}
@Override
protected void channelIdle(ChannelHandlerContext ctx, IdleStateEvent evt) {
ctx.channel().close();
}
}
IdleStateHandler的构造函数一共有四个参数:
- 第一个参数:入站空闲检测时长,表示一段时间内如果没有数据入站,就判定空闲;
- 第二个参数:出站空闲检测时长,表示一段时间内如果没有数据出站,就判定空闲;
- 第三个参数:出/入站检测时长,表示一段时间内如果没有数据出站或者入站,就判定空闲;
- 最后一个参数:表示时间单位,比如
TimeUnit.SECONDS表示秒。
IdleStateHandler 实现连接空闲检测的底层原理是,向任务队列中添加定时任务,判断 channelRead() 或 write() 方法是否发生空闲超时。
IdleStateHandler 实现了
ChannelDuplexHandler,也就是说,它既是一个入站Handler,又是一个出站Handler。
客户端心跳检测
心跳检测,是指服务端需要通过心跳机制判断客户端是否存活,因为即使服务端一段时间内没收到客户端发送的数据,也不能说明连接是假死状态,有可能就是客户端长时间没有数据需要发送,但连接本身还是健康状态。服务端如果有 N 次没收到心跳数据,则可以判断当前客户端已经下线或处于不健康状态
Netty 中并没有对心跳检测的现成实现,但是客户端可以采用 EventLoop 提供的 schedule() 方法向任务队列中添加心跳数据上报的定时任务,如下所示:
public class RpcHeartBeatHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
super.channelActive(ctx);
// 客户端与服务端成功建立连接后,开始发起定时心跳
doHeartBeatTask(ctx);
}
private void doHeartBeatTask(ChannelHandlerContext ctx) {
ctx.executor().schedule(() -> {
if (ctx.channel().isActive()) {
HeartBeatData heartBeatData = buildHeartBeatData();
ctx.writeAndFlush(heartBeatData);
doHeartBeatTask(ctx);
}
}, 10, TimeUnit.SECONDS); //10s后执行
}
}
注意,空闲检测时间间隔一般要大于 2 个周期的心跳检测时间间隔,主要是为了排除网络抖动等原因造成服务端未能成功收到心跳包。
解码保护
Netty 在实现数据解码时,需要等待到缓冲区有足够多的字节才能开始解码。为了避免缓冲区缓存太多数据,造成内存耗尽,我们可以在解码器中设置一个最大字节阈值,然后结合 Netty 提供的 TooLongFrameException异常,通知 ChannelPipeline 中其他 ChannelHandler。示例如下:
public class MyDecoder extends ByteToMessageDecoder {
private static final int MAX_FRAME_LIMIT = 1024;
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
int readable = in.readableBytes();
if (readable > MAX_FRAME_LIMIT) {
in.skipBytes(readable);
throw new TooLongFrameException("too long frame");
}
// decode...
}
}
线程池隔离
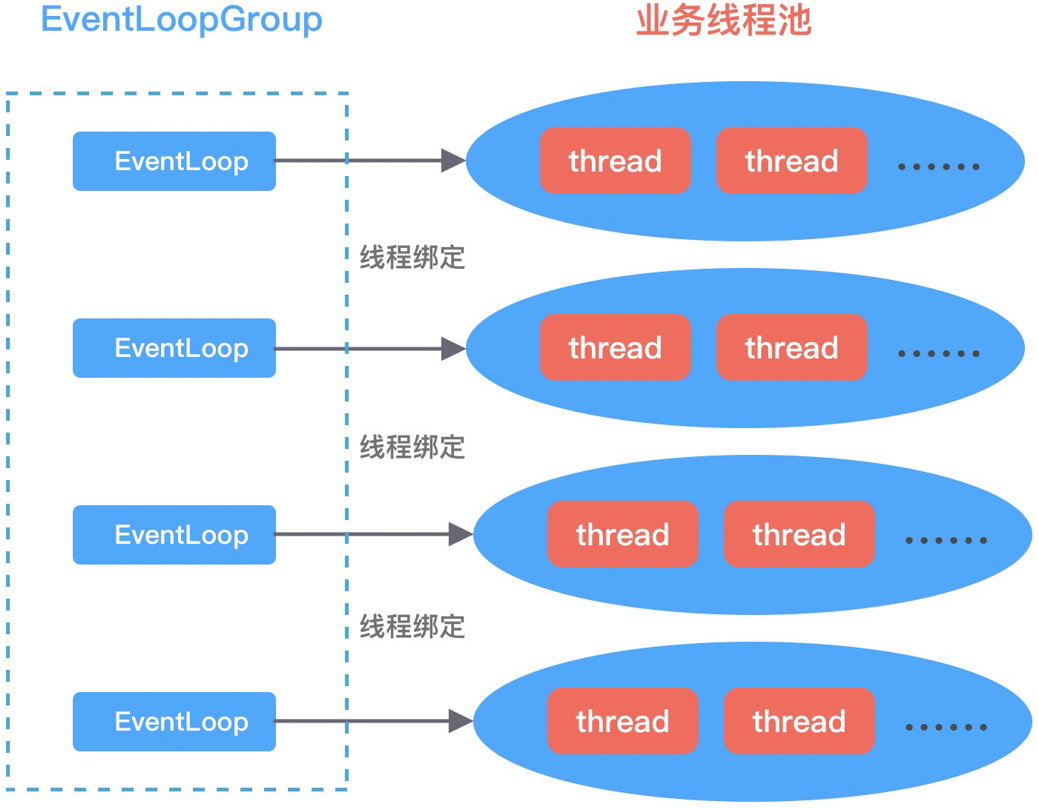
我们知道,如果有复杂且耗时的业务逻辑,推荐的做法是在 ChannelHandler 处理器中自定义新的业务线程池,将耗时的操作提交到业务线程池中执行。建议根据业务逻辑的核心等级拆分出多个业务线程池,如果某类业务逻辑出现异常造成线程池资源耗尽,也不会影响到其他业务逻辑,从而提高应用程序整体可用率。对于 Netty I/O 线程来说,每个 EventLoop 可以与某类业务线程池绑定,避免出现多线程锁竞争。如下图所示:
流量整形
流量整形(Traffic Shaping)是一种主动控制服务流量输出速率的措施,保证下游服务能够平稳处理。流量整形和流控的区别在于,流量整形不会丢弃和拒绝消息,无论流量洪峰有多大,它都会采用令牌桶算法控制流量以恒定的速率输出,如下图所示:

Netty 通过实现流量整形的抽象类 AbstractTrafficShapingHandler,提供了三种类型的流量整形策略:GlobalTrafficShapingHandler、ChannelTrafficShapingHandler 和 GlobalChannelTrafficShapingHandler,它们之间的关系如下:
GlobalTrafficShapingHandler = ChannelTrafficShapingHandler + GlobalChannelTrafficShapingHandler
- GlobalChannelTrafficShapingHandler:全局流量整形 GlobalChannelTrafficShapingHandler 作用范围是所有 Channel,用户可以设置全局报文的接收速率、发送速率、整形周期;
- ChannelTrafficShapingHandler:Channel 级流量整形 ChannelTrafficShapingHandler 作用范围是单个 Channel,可以对不同的 Channel 设置流量整形策略;
举个简单的例子,火爆的旅游景区不仅在大门口对游客限流(相当于 GlobalChannelTrafficShapingHandler),而且在景区内部不同的小景点也对游客有限流(相当于 ChannelTrafficShapingHandler),这两个流量整形策略加起来就是 GlobalTrafficShapingHandler。
流量整形并不能保证系统处于安全状态,当流量洪峰过大,数据会一直积压在内存中,所以流量整形和流控应该结合使用才能保证系统的高可用。
重试机制
为了保障服务的稳定性和容错性,重试机制是一般可以帮助我们解决不少问题,例如网络抖动、请求超时等场景都需要重试机制。
关于 RPC 框架的重试机制有几点最佳实践和注意事项:
- 服务提供方接口需要保证幂等才可以考虑使用重试机制,例如数据插入、更新操作,无论重复请求多少次都不会产生任何影响;
- 重试机制虽然可以提升服务可用性,但是重试可能会导致服务提供方流量倍增,极端情况下甚至造成雪崩。服务调用方最好设置合理的服务调用超时时间以及失败重试次数,需要综合考虑服务调用的平均耗时、TP99响应时间、服务重要等级等因素。为了防止重试引发的流量风暴,服务提供方必须考虑熔断、限流、降级等保护措施;
- RPC 框架的重试机制一般会采取 指数退避 策略,即两次重试时间间隔以指数级增加,例如 1s、2s、4s、8s,以此类推,同时必须限制最大延迟时间。指数退避会存在 负载峰值 问题,例如服务提供方可能在某一时刻发生 FullGC, 导致同一时间产生超时重试的请求增多。为了解决负载峰值问题,可以在重试间隔中增加随机值,将请求分摊在不同的时间点中;
- 在负载均衡选择服务节点时,应该剔除上次重试失败的节点,进一步提高重试的成功率。
集群容错
集群容错,是指服务消费者调用服务提供者集群时发生异常时的处理方案。以 Dubbo 框架为例,提供了六种内置的集群容错措施。
- Failover,失效转移策略 :Failover 是 Dubbo 默认的集群容错措施,当出现调用失败时,会重新尝试调用其他服务节点。对于幂等性操作我们可以选择 Failover 策略,但是重试的副作用在上文中我们已经提到过,如果服务提供者出现问题可能会产生大量的重试请求;
- Failfast,快速失败策略 :Failfast 非常适合非幂等性操作,服务消费者只发起一次调用,如果出现失败的情况则立刻报错,不进行任何重试。Failfast 的缺点就是需要服务消费者自己控制重试逻辑;
- Failsafe,失效安全策略 :Failsafe 策略在出现异常时,直接忽略不抛异常。Failsafe 策略适合执行非核心的操作,如监控日志记录;
- Failback,失效自动恢复策略 :服务消费者调用失败后,Dubbo 会记录此次失败请求到队列中,然后定时重新发送该请求。Failback 策略适用于实时性不高的场景,如消息推送;
- Forking,并行措施 :服务调用者并行调用多个服务提供者节点,只要有一个调用成功就返回结果。通常用于实时性要求较高的操作,而且可以降低 TP999 指标,但是需要牺牲一定的服务器资源;
- Broadcast,广播措施 :Broadcast 策略会广播所有的服务提供者,逐个调用,任意一台失败则等待广播最后完成之后抛出,通常用于更新服务提供方的本地资源状态。
以上几种集群容错策略,需要根据实际的业务场景进行配置选择,Dubbo 给我们提供了 Cluster 扩展接口,我们可以自己定制集群的容错模式。
实现 RPC 框架高可用的措施还有很多,如限流保护、动态扩容、平滑重启、服务治理等等,由于篇幅有限,我在这里就不一一展开了。
三、总结
本章,我对实现一个RPC框架的基本功能和架构设计进行了讲解。后续章节,我会基于Netty,完整实现一个 RPC 框架的基础功能,帮助大家掌握Netty在实战中的运用。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
