上一章 简述了主从复制的基本配置,以及抓包查看了数据复制的一些工作流程,本章将通过源码去深入分析 redis 主从节点数据复制的要点逻辑:复制命令,master 服务副本 ID,复制偏移量,积压缓冲区。
redis 是纯 c 源码,阅读起来实现比较清晰,缺点:它也是一个异步的网络框架,回调处理的逻辑理解有点费劲。
1. 数据结构
1.1. redisServer
redis master / slave 节点数据结构 redisServer。
#define CONFIG_RUN_ID_SIZE 40
struct redisServer {
...
list *slaves, *monitors; /* List of slaves and MONITORs */
...
/* Replication (master) */
char replid[CONFIG_RUN_ID_SIZE+1]; /* My current replication ID. */
char replid2[CONFIG_RUN_ID_SIZE+1]; /* replid inherited from master*/
long long master_repl_offset; /* My current replication offset */
long long master_repl_meaningful_offset; /* Offset minus latest PINGs. */
long long second_replid_offset; /* Accept offsets up to this for replid2. */
char *repl_backlog; /* Replication backlog for partial syncs */
long long repl_backlog_size; /* Backlog circular buffer size */
long long repl_backlog_histlen; /* Backlog actual data length */
long long repl_backlog_idx; /* Backlog circular buffer current offset,
that is the next byte will'll write to.*/
long long repl_backlog_off; /* Replication "master offset" of first
...
/* Replication (slave) */
char *masterhost; /* Hostname of master */
int masterport; /* Port of master */
client *master; /* Client that is master for this slave */
client *cached_master; /* Cached master to be reused for PSYNC. */
int repl_state; /* Replication status if the instance is a slave */
...
char master_replid[CONFIG_RUN_ID_SIZE+1]; /* Master PSYNC runid. */
long long master_initial_offset; /* Master PSYNC offset. */
}
- master
| 结构成员 | 描述 |
|---|---|
| slaves | slaves副本链接列表。 |
| replid | 副本id,只有master有自己独立的replid,如果服务是slave,那么它需要复制master的replid,进行填充。 |
| replid2 | master历史replid。复制双方断开链接或者故障转移过程中,服务节点角色发生改变,需要缓存旧的masterreplid到replid2。因为所有slave数据都来自master。复制双方重新建立链接后,通过PSYNC<replid><offset>命令进行数据复制。 |
| master_repl_offset | master数据偏移量。复制双方是异步进行的,所以数据并不是严格的数据强一致。 |
| second_replid_offset | 历史数据偏移量。与replid2搭配使用。 |
| repl_backlog | 积压缓冲区。被设计成环形数据结构(连续内存空间)。 |
| repl_backlog_size | 积压缓冲区容量。可以通过配置文件进行配置。 |
| repl_backlog_histlen | 积压缓冲区实际填充了多少数据。 |
| repl_backlog_idx | 积压缓冲区,当前填充数据的位置。 |
| repl_backlog_off | 积压缓冲区数据起始位置。server.repl_backlog_off=server.master_repl_offset+1 |
- slave
| 结构成员 | 描述 |
|---|---|
| masterhost | 保存master节点的主机地址。 |
| masterport | 保存master节点的端口。 |
| repl_state | 副本状态,复制双方建立数据复制要经过很多步骤,而这些步骤被进行到哪个环节被记录在repl_state。(您可以为记录异步通信状态机的当前状态。) |
| master | slave链接master的客户端链接。 |
| cached_master | slave与master断开链接后,原链接被释放回收。为方便断线重连后数据重复被利用,需要缓存master链接数据到cached_master。 |
| master_replid | master的replid。 |
| master_initial_offset | slave通过命令PSYNC向master全量复制的数据偏移量。 |
1.2. client
master 与 slave 节点间异步通信链接对象。
typedef struct client {
...
long long read_reploff; /* Read replication offset if this is a master. */
long long reploff; /* Applied replication offset if this is a master. */
char replid[CONFIG_RUN_ID_SIZE+1]; /* Master replication ID (if master). */
...
}
| 结构成员 | 描述 |
|---|---|
| replid | master副本id。 |
| read_reploff | slave当前向master读取的数据偏移量。 |
| masterport | slave当前实际处理的数据偏移量。因为异步复制,有些读数据,读出来没有完全处理完,还在缓冲区里。例如tcp粘包问题,数据没有接收完整,等原因。 |
2. PSYNC
slave 主动链接 master,会发送 PSYNC 命令给 master,请求 master 进行数据复制。master 通过该命令的参数 <master_replid> 和 <master_offset> 信息对比,确认数据复制是采用全量复制,还是增量复制。
PSYNC <master_replid> <master_offset>
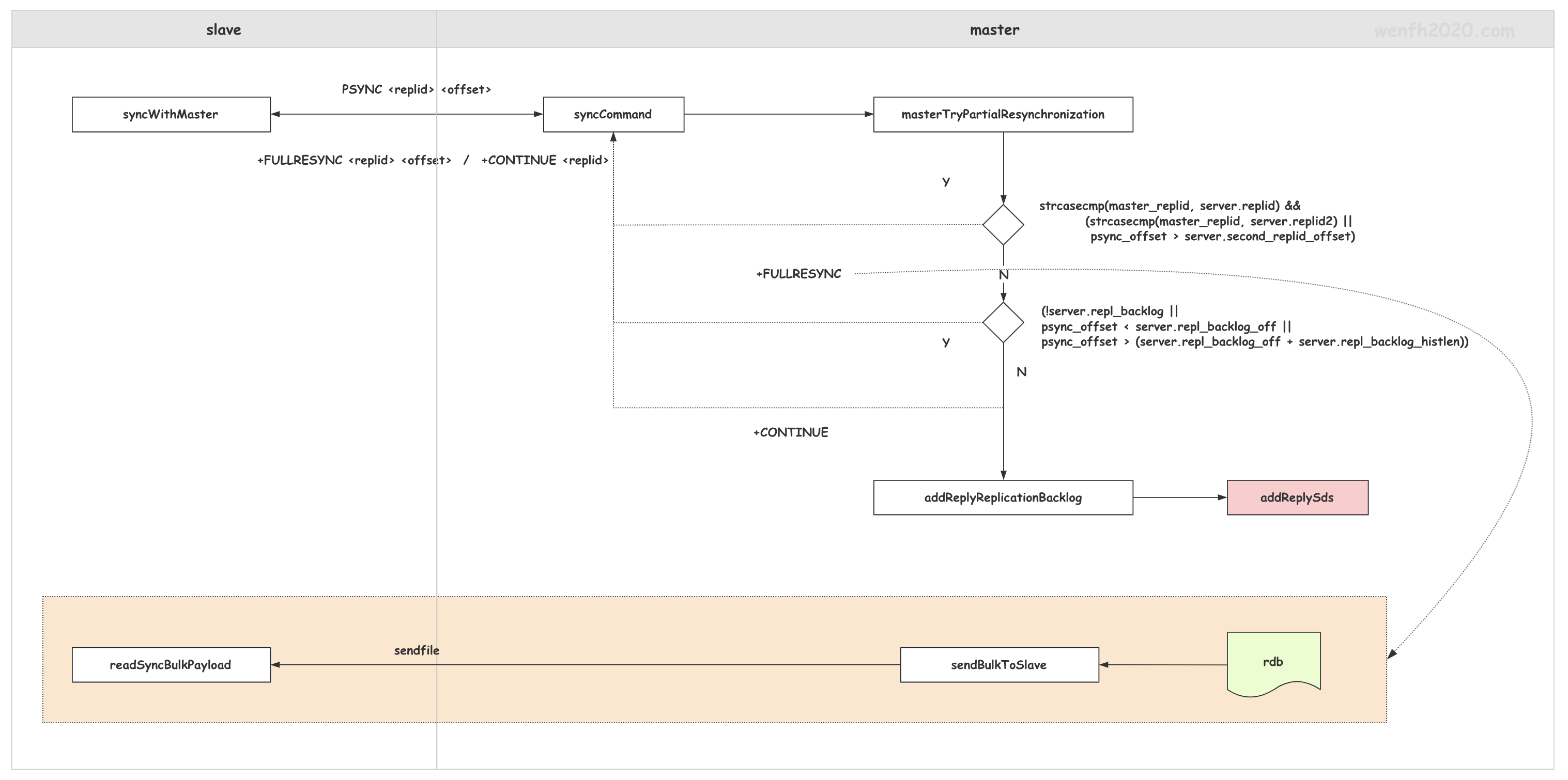
2.1. slave
- salve 发送 PSYNC 命令给 master。
void syncWithMaster(connection *conn) {
...
if (server.repl_state == REPL_STATE_SEND_PSYNC) {
// slave 发送 PSYNC 命令给 master。
if (slaveTryPartialResynchronization(conn,0) == PSYNC_WRITE_ERROR) {
err = sdsnew("Write error sending the PSYNC command.");
goto write_error;
}
server.repl_state = REPL_STATE_RECEIVE_PSYNC;
return;
}
...
/* slave 处理 PSYNC 命令的回复数据包。*/
psync_result = slaveTryPartialResynchronization(conn,1);
...
/* 增量复制。
* slave 通过 readQueryFromClient 异步接收 master 增量数据。
* 复制双方链接成功,slave 通过 replicationResurrectCachedMaster
* 绑定 readQueryFromClient 异步接收复制数据。*/
if (psync_result == PSYNC_CONTINUE) {
...
return;
}
/* 全量复制。
* slave 通过 readSyncBulkPayload() 异步接收 master 发送的 rdb 文件数据。*/
if (connSetReadHandler(conn, readSyncBulkPayload) == C_ERR) {
...
goto error;
}
}
- slave 处理 master 回复:根据回复协议分析,确认数据的复制方式:数据复制/增量复制,并做相应的处理。
int slaveTryPartialResynchronization(connection *conn, int read_reply) {
...
if (!read_reply) {
/* 发送 */
...
/* 复制双方有可能是断线重连,断线后,原来的链接 server.master 失效,被回收,
* 为了重复利用原有数据,slave 会缓存 server.master 链接到 server.cached_master。*/
if (server.cached_master) {
psync_replid = server.cached_master->replid;
// slave 发送当前的数据偏移量。
snprintf(psync_offset, sizeof(psync_offset), "%lld",
server.cached_master->reploff+1);
} else {
// slave 第一次链接 master,还没有 master 对应数据,所以用特殊符号标识。
psync_replid = "?";
memcpy(psync_offset,"-1",3);
}
// slave 发送 PSYNC 命令到 master。
reply = sendSynchronousCommand(SYNC_CMD_WRITE, conn, "PSYNC",
psync_replid, psync_offset, NULL);
...
}
/* 接收 */
...
/* 全量复制。
* slave 接收到 master 的回复:+FULLRESYNC <replid> <offset>
* slave 先更新对应数据,后续 readSyncBulkPayload() 异步接收 master 发送的 rdb 文件数据,
* 当 rdb 文件数据接收完毕,slave 重新加载对应的 rdb 文件,这样实现全量复制。*/
if (!strncmp(reply,"+FULLRESYNC",11)) {
char *replid = NULL, *offset = NULL;
/* FULL RESYNC, parse the reply in order to extract the run id
* and the replication offset. */
replid = strchr(reply,' ');
if (replid) {
replid++;
offset = strchr(replid,' ');
if (offset) offset++;
}
if (!replid || !offset || (offset-replid-1) != CONFIG_RUN_ID_SIZE) {
// 全量复制出现错误。
memset(server.master_replid,0,CONFIG_RUN_ID_SIZE+1);
} else {
// slave 更新 master 对应的 replid 和 offset。
memcpy(server.master_replid, replid, offset-replid-1);
server.master_replid[CONFIG_RUN_ID_SIZE] = '\0';
server.master_initial_offset = strtoll(offset,NULL,10);
}
// 链接成功,清除旧的缓存链接数据,建立新的通信链接。
replicationDiscardCachedMaster();
sdsfree(reply);
return PSYNC_FULLRESYNC;
}
/* 增量复制
* slave 接收到 master 的回复:+CONTINUE <new repl ID> */
if (!strncmp(reply,"+CONTINUE",9)) {
/* 检查 master 是否有新的 <new repl ID>,
* 有可能 redis 集群故障转移后,集群产生新的 master。*/
char *start = reply+10;
char *end = reply+9;
while(end[0] != '\r' && end[0] != '\n' && end[0] != '\0') end++;
if (end-start == CONFIG_RUN_ID_SIZE) {
char new[CONFIG_RUN_ID_SIZE+1];
memcpy(new,start,CONFIG_RUN_ID_SIZE);
new[CONFIG_RUN_ID_SIZE] = '\0';
if (strcmp(new, server.cached_master->replid)) {
/* 缓存旧的 replid2 和 second_replid_offset。
* 因为当前 slave 可能有子服务 sub-slave,需要方便它们进行数据复制。*/
memcpy(server.replid2,server.cached_master->replid,
sizeof(server.replid2));
server.second_replid_offset = server.master_repl_offset+1;
/* 更新 slave 当前的 replid。一般只有 master 才有自己独立的 replid。
* 所以 slave 的 replid 保存 master 的 replid。*/
memcpy(server.replid,new,sizeof(server.replid));
/* 更新 master client 对应的 replid。
* 因为增量复制是之前曾经链接成功的,后来断开链接了,
* 需要缓存断开的链接方,便后续重连操作。
* 所以会将原来 server.master,缓存到 server.cached_master。
* 当重连成功后 server.cached_master 会被清空。
* 详看 replicationResurrectCachedMaster()。*/
memcpy(server.cached_master->replid,new,sizeof(server.replid));
/* 如果当前 slave 有子服务 sub-slave,
* 那么断开子服务链接,让它们重新走 PSYNC 复制流程。*/
disconnectSlaves();
}
}
sdsfree(reply);
// 链接成功,清除旧的缓存链接数据,建立新的通信链接。
replicationResurrectCachedMaster(conn);
// 如果积压缓冲区被清空,那么重新创建,如果有 sub-slave 方便数据复制。
if (server.repl_backlog == NULL) createReplicationBacklog();
return PSYNC_CONTINUE;
}
...
}
2.2. master
- 处理 slave 发送的 PSYNC 命令。
void syncCommand(client *c) {
...
if (!strcasecmp(c->argv[0]->ptr,"psync")) {
/* 检查复制方式。
* 增量复制,master 从缓冲区给 slave 发送增量数据。
* 全量复制,master 创建 rdb 快照,异步发送 slave */
if (masterTryPartialResynchronization(c) == C_OK) {
server.stat_sync_partial_ok++;
return;
}
...
}
...
/* 全量复制。*/
server.stat_sync_full++;
/* 更新链接同步状态,建立 slave 数据复制链接。*/
c->replstate = SLAVE_STATE_WAIT_BGSAVE_START;
if (server.repl_disable_tcp_nodelay)
connDisableTcpNoDelay(c->conn); /* Non critical if it fails. */
c->repldbfd = -1;
c->flags |= CLIENT_SLAVE;
listAddNodeTail(server.slaves,c);
/* 创建复制的积压缓冲区对应数据。*/
if (listLength(server.slaves) == 1 && server.repl_backlog == NULL) {
/* When we create the backlog from scratch, we always use a new
* replication ID and clear the ID2, since there is no valid
* past history. */
changeReplicationId();
clearReplicationId2();
createReplicationBacklog();
}
...
/* 如果当前没有子进程正在建立 rdb 文件快照。开始创建 rdb 文件快照 流程。
* 否则放在时钟里进行定期检查处理,延时该流程。*/
if (!hasActiveChildProcess()) {
startBgsaveForReplication(c->slave_capa);
}
...
return;
}
- 检查处理复制方式。
int masterTryPartialResynchronization(client *c) {
...
// 检查 replid 是否一致,检查 slave 的数据偏移量是否超出缓存数据偏移量的范围。
if (strcasecmp(master_replid, server.replid) &&
(strcasecmp(master_replid, server.replid2) ||
psync_offset > server.second_replid_offset)) {
...
// 全量复制
goto need_full_resync;
}
// 检查 slave 的数据偏移量,是否在主服务的数据缓冲区范围内。
if (!server.repl_backlog ||
psync_offset < server.repl_backlog_off ||
psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen)) {
...
// 全量复制
goto need_full_resync;
}
...
// 增量复制
if (c->slave_capa & SLAVE_CAPA_PSYNC2) {
buflen = snprintf(buf,sizeof(buf),"+CONTINUE %s\r\n", server.replid);
} else {
buflen = snprintf(buf,sizeof(buf),"+CONTINUE\r\n");
}
// 发送 +CONTINUE 增量复制回包。注意这里是同步发送的,避免异步导致新的数据到来破坏当前同步场景。
if (connWrite(c->conn,buf,buflen) != buflen) {
freeClientAsync(c);
return C_OK;
}
// 发送增量数据。
psync_len = addReplyReplicationBacklog(c,psync_offset);
...
return C_OK; /* The caller can return, no full resync needed. */
need_full_resync:
return C_ERR;
}
3. 服务副本 ID
每个 master 拥有自己的副本 ID
slave 向 master 复制数据,需要记录下 master 的
// master 接收 slave 的 PSYNC 命令,检查 replid 是否一致。
int masterTryPartialResynchronization(client *c) {
...
// 检查 replid 是否一致。
if (strcasecmp(master_replid, server.replid) &&
(strcasecmp(master_replid, server.replid2) ||
psync_offset > server.second_replid_offset)) {
...
goto need_full_resync;
}
...
// 增量复制
return C_OK; /* The caller can return, no full resync needed. */
// 全量复制
need_full_resync:
return C_ERR;
}
4. 复制偏移量
主从服务双方会维护一个复制偏移量(一个数据统计值)。
master 把需要数据复制给 slave 的数据填充到 积压缓冲区 ,并且更新复制偏移量的值。这样,双方的偏移量可以通过对比,可以知道双方数据相差多少。
4.1. master
struct redisServer {
...
long long master_repl_offset; /* My current replication offset */
...
}
// master 需要复制给 slave 的数据都会调用 feedReplicationBacklog,写入缓冲区并更新复制偏移量。
void feedReplicationBacklog(void *ptr, size_t len) {
...
// master 复制偏移量
server.master_repl_offset += len;
...
}
4.2. slave
typedef struct client {
...
long long reploff; /* Applied replication offset if this is a master. */
...
}
/* 增量复制和正常链接下的数据复制。
* slave 接收到 master 发送的数据,处理命令后,偏移量增加已处理数据数量
* (因为 TCP 有可能因为粘包问题,接收数据不是完整的,所以不能全部处理完)。*/
int processCommandAndResetClient(client *c) {
int deadclient = 0;
server.current_client = c;
if (processCommand(c) == C_OK) {
if (c->flags & CLIENT_MASTER && !(c->flags & CLIENT_MULTI)) {
// 接收数据后,追加已处理的数据总量到复制偏移量。
c->reploff = c->read_reploff - sdslen(c->querybuf) + c->qb_pos;
}
...
}
...
}
// 断线重连,slave 向 master 发送 PSYNC 命令,确认是增量复制,还是全量复制。
int slaveTryPartialResynchronization(connection *conn, int read_reply) {
...
if (!read_reply) {
...
if (server.cached_master) {
psync_replid = server.cached_master->replid;
// 断线重连 slave 发送保存的数据偏移量。
snprintf(psync_offset,sizeof(psync_offset),"%lld",
server.cached_master->reploff+1);
} else {
// slave 第一次链接 master,还没有偏移量,所以用 -1 填充。
psync_replid = "?";
memcpy(psync_offset,"-1",3);
}
// slave 发送 PSYNC 命令到 master。
reply = sendSynchronousCommand(SYNC_CMD_WRITE,conn,"PSYNC",
psync_replid,psync_offset,NULL);
...
}
...
// slave 接收到 master 的回复,进行全量复制。
if (!strncmp(reply,"+FULLRESYNC",11)) {
...
memcpy(server.master_replid, replid, offset-replid-1);
server.master_replid[CONFIG_RUN_ID_SIZE] = '\0';
// 更新最新的数据偏移量。
server.master_initial_offset = strtoll(offset,NULL,10);
...
return PSYNC_FULLRESYNC;
}
...
}
// 全量复制,slave 接收 master 发送的 rdb 文件数据,加载数据并初始化数据偏移量。
void readSyncBulkPayload(connection *conn) {
...
replicationCreateMasterClient(server.repl_transfer_s,rsi.repl_stream_db);
...
// slave 更新这个值,因为 slave 有可能要复制数据到 sub-slave。
server.master_repl_offset = server.master->reploff;
...
}
void replicationCreateMasterClient(connection *conn, int dbid) {
...
// slave 更新数据偏移量到 reploff。
server.master->reploff = server.master_initial_offset;
...
}
4.3. rdb
双方全量复制,通过 rdb 文件传输。rdb 会保存 replid 和 server.master_repl_offset 信息。
int rdbSaveInfoAuxFields(rio *rdb, int rdbflags, rdbSaveInfo *rsi) {
...
/* Handle saving options that generate aux fields. */
if (rsi) {
// 当前 master 正在操作的 db。
if (rdbSaveAuxFieldStrInt(rdb,"repl-stream-db",rsi->repl_stream_db) == -1)
return -1;
// master 的 replid。
if (rdbSaveAuxFieldStrStr(rdb,"repl-id",server.replid) == -1)
return -1;
// master 的数据偏移量。
if (rdbSaveAuxFieldStrInt(rdb,"repl-offset",server.master_repl_offset) == -1)
return -1;
}
...
return 1;
}
5. 复制积压缓冲区
复制积压缓冲区,是一个连续内存空间,被设计成 环形数据结构 。
master 把需要复制到 slave 的数据,填充到积压缓冲区里。当复制双方增量复制时,master 从缓冲区中取增量数据,发送给 slave。
master 淘汰过期数据,也需要复制给 slave。查看函数的实现:replicationFeedSlaves()
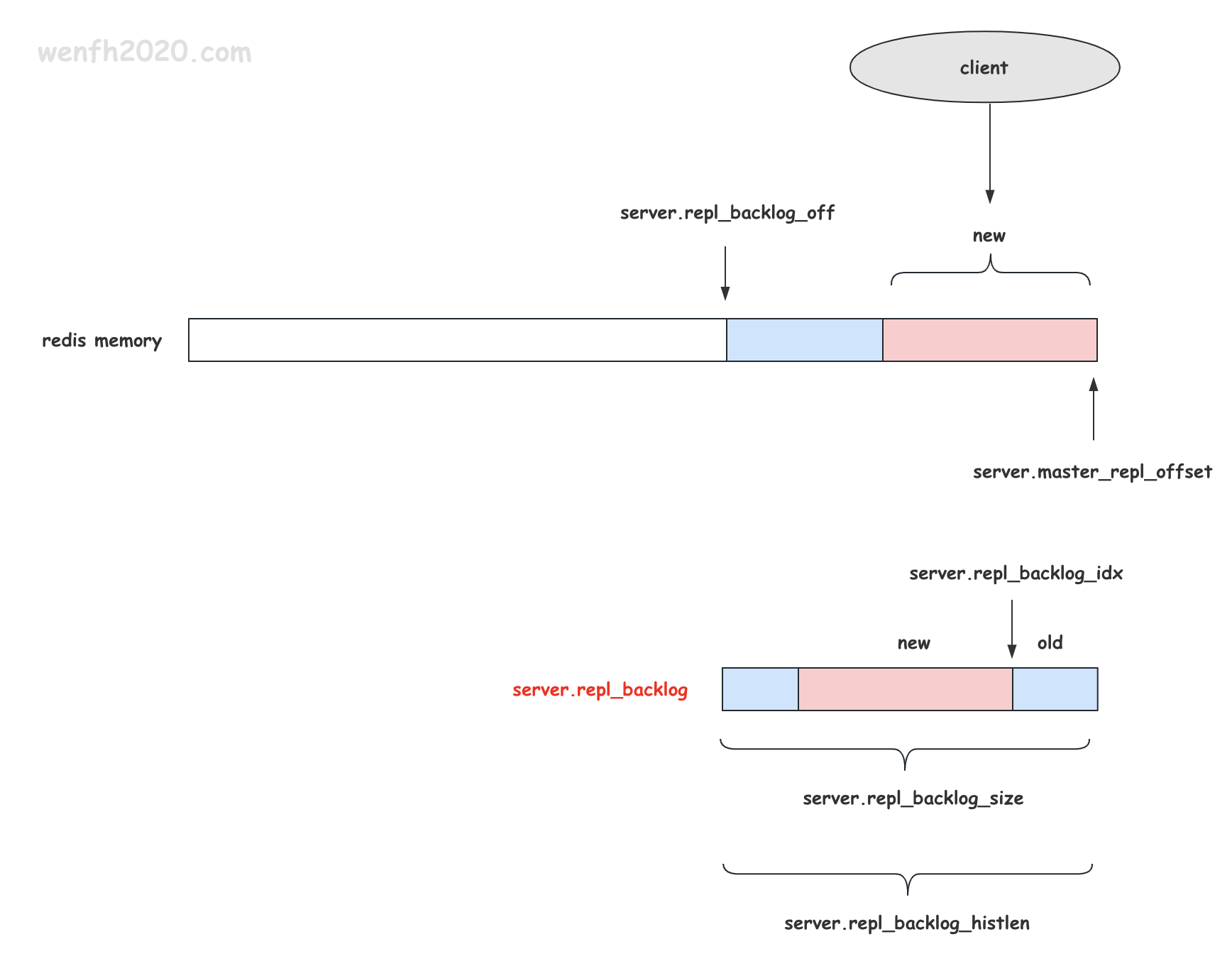
- master 填充积压缓冲区。
void feedReplicationBacklog(void *ptr, size_t len) {
unsigned char *p = ptr;
// 客户端写数据,主服务,当前数据偏移量,实时增加对应的数据量。
server.master_repl_offset += len;
// 这是一个环形数据空间,repl_backlog_idx 是当前写数据位置。
while(len) {
// 往缓冲区填充数据,不能超过缓冲区范围。当填满缓冲区后,再缓冲区起始位置开始填充数据。
size_t thislen = server.repl_backlog_size - server.repl_backlog_idx;
if (thislen > len) thislen = len;
memcpy(server.repl_backlog+server.repl_backlog_idx,p,thislen);
server.repl_backlog_idx += thislen;
if (server.repl_backlog_idx == server.repl_backlog_size)
server.repl_backlog_idx = 0;
len -= thislen;
p += thislen;
// 缓冲区实际填充数据长度。
server.repl_backlog_histlen += thislen;
}
// 缓冲区实际填充数据长度,不能超过缓冲区大小。
if (server.repl_backlog_histlen > server.repl_backlog_size)
server.repl_backlog_histlen = server.repl_backlog_size;
// 数据缓冲区起始位置内存数据,在 redis 整个内存的数据偏移量。
server.repl_backlog_off = server.master_repl_offset -
server.repl_backlog_histlen + 1;
}
- master 从积压缓冲区发送增量数据给 slave。
// 根据 slave 的数据偏移量,master 回复数据增量。
long long addReplyReplicationBacklog(client *c, long long offset) {
long long j, skip, len;
// 如果数据缓冲区还没有数据,不需要回复。
if (server.repl_backlog_histlen == 0) {
serverLog(LL_DEBUG, "[PSYNC] Backlog history len is zero");
return 0;
}
// 计算 slave 的偏移量在缓冲区的哪个位置上。
skip = offset - server.repl_backlog_off;
// j 是缓冲区 buffer 数据起始偏移位置,因为是环装结构,所以需要取模 repl_backlog_size。
j = (server.repl_backlog_idx +
(server.repl_backlog_size-server.repl_backlog_histlen)) %
server.repl_backlog_size;
// 数据增量在缓冲区起始偏移位置。
j = (j + skip) % server.repl_backlog_size;
// 增量数据长度。
len = server.repl_backlog_histlen - skip;
// 发送缓冲区增量数据。
while(len) {
long long thislen =
((server.repl_backlog_size - j) < len) ?
(server.repl_backlog_size - j) : len;
addReplySds(c,sdsnewlen(server.repl_backlog + j, thislen));
len -= thislen;
j = 0;
}
return server.repl_backlog_histlen - skip;
}
6. 总结
- 数据复制关键理解 PSYNC 命令复制双方的实现逻辑。
- 复制双方是异步复制,所以 slave 与 master 数据并非严格一致,slave 有一定延时。
- 全量数据复制,涉及到 rdb 文件传输,数据量大时,耗时较长。redis 支持一主多从,并不是 slave 越多越好,如果多个 slave 同时掉线,需要全量复制,如果 redis 数据量很大,master 性能肯定会大受影响,这时候可以考虑 sub-slave。
- redis 采用异步架构,所以需要比较熟悉异步回调处理。与同步比较,逻辑不够直观,复杂的回调逻辑经常会把人绕晕。
7. 参考
- Replication
- 《redis 设计与实现》—— 第十五章 - 复制。
- Codis 与 RedisCluster 的原理详解
- redis系列–主从复制以及redis复制演进
- Redis Replication 实现原理
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
