常见的数据库对象
| 对象 | 描述 |
|---|---|
| 表 | 基本的数据存储集合,由行和列组成 |
| 视图 | 从表中抽出的逻辑上相关的数据集合 |
| 序列 | 提供有规律的数值 |
| 索引 | 提高查询的效率 |
| 同义词 | 给对象起别名 |
视图
什么是视图?
- 视图是一个 虚 表 \color{red}{虚表} 虚表
- 视图建立在已有表的基础上,视图赖以建立的这些表称为 基 表 \color{red}{基表} 基表
- 向视图提供数据内容的语句为 s e l e c t 语 句 \color{red}{select 语句} select语句,可以将视图理解为 存 储 起 来 的 s e l e c t 语 句 \color{red}{存储起来的select语句} 存储起来的select语句
- 视图向用户提供基表数据的另一种表现形式
- 最 大 的 优 点 就 是 简 化 复 杂 的 查 询 。 \color{red}{最大的优点就是简化复杂的查询。} 最大的优点就是简化复杂的查询。
视图的优点
创建视图的语法
create [or replace] [force|noforce] view viewName
[(alias[, alisa]...)]
[with check option [constraint constraint]]
[with read only [constraint constraint]];
- force:子查询不一定存在
- noforce:子查询存在(默认)
- with read only:只能做查询操作
- 子查询可以是复杂的select语句
示例:建立一个视图,此视图包括了20号部门的全部员工信息
create view empView20 as select * from emp t where t.deptno=20;
select * from empView20;

语法2:
create or replace view 视图名称 as 子查询
如果视图已经存在我们可以使用语法2来创建视图,这样已有的视图会被覆盖。
create or replace view wmpView20 as select * from emp t where t.deptno=10;
select * from empView20;


简单视图和复杂视图
| 特性 | 简单视图 | 复杂视图 |
|---|---|---|
| 表的数量 | 一个 | 一个或多个 |
| 函数 | 没有 | 有 |
| 分组 | 没有 | 有 |
| DML操作 | 可以 | 有时可以 |
不 建 议 通 过 视 图 对 表 中 数 据 进 行 修 改 , 因 为 会 受 到 很 多 的 限 制 。 \color{red}{不建议通过视图对表中数据进行修改,因为会受到很多的限制。} 不建议通过视图对表中数据进行修改,因为会受到很多的限制。
创建复杂视图
示例:查询各个部门的最低工资,最高工资,平均工资
create view dept_sum_vu
(name, minsal, maxsal, avgsal)
as select d.department_name, MIN(e.salary),
MAX(e.salary), AVG(e.salary)
from employees e, departments d
where e.department_id = d.department_id
group by d.department_name;
视图中使用DML的规定
-
可以在简单视图中执行DML操作
-
当视图定义中包含以下元素之一时不饿能使用delete:
- 组函数
- GROUP BY 子句
- DISTINCT 关键字
- ROWNUM 伪列
-
当视图定义中包含以下元素之一时不能使用update:
- 组函数
- GROUP BY 子句
- DISTINCT 关键字
- ROWNUM 伪列
- 列的定义方式为表达式
-
当视图定义中包含以下元素之一时不能使用insert:
- 组函数
- GROUP BY 子句
- DISTINCT 关键字
- ROWNUM 伪列
- 列的定义方式为表达式
- 列中非空的列在视图定义中未包括
屏蔽DML操作
- 可以使用WITH READ ONLY 选项屏蔽对视图的DML操作
- 任何DML操作都会返回一个Oracle server 错误
删除视图
删除视图只是删除视图的定义,并不会删除基本表的数据。
drop view vie;
drop view empView20;
序列
在很多数据库中都存在一个自动增长的列,如果现在要想在oracle中完成自动增长的功能,则只能依靠序列完成,所有的自动增长操作,需要用户手工完成处理。并且Oracle将序列值装入内存可以提高访问效率。
序列:可供多个用户用来产生唯一数值的数据库对象:
- 自动提供唯一的数值
- 共享对象
- 主要用于提供主键值
- 将序列值装入内存可以提高访问效率
语法:
create sequence 序列名
[increment by n]
[start with n]
[{MAXVALUE n| NOMAXVALUE}]
[{MINVALUE n| NOMINVALUE}]
[{CYCLE|NOCYCLE}]
[{CACHE n| NOCACHE}];
示例:
create sequence dept_deptid_seq
increment by 10
start with 120
maxvalue 9999
nocache
nocycle;
Sequence created.
查询序列
查询数据字典视图USER_SEQUENCES获取序列定义信息:
select sequence_name, min_value, max_value, increment_by, last_number
from user_sequences;
- 如果指定NOCACHE选项,则列LAST_NUMBER显示序列中下一个有效的值
序列创建完成之后,所有的自动增长应该由用户自己处理,所以在序列中提供了以下的两种操作:
- nextval:取得序列的下一个内容
- currval:取得序列的当前内容
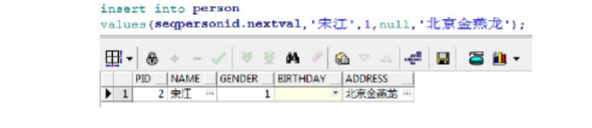
在插入数据时需要自增的主键中可以这样使用
序列可能产生裂缝的原因:
- 回滚
- 系统异常
- 多个表公用一个序列
修改序列
修改序列的增量,最大值,最小值,循环选项或是否装入内存
alter sequence dept_deptid_seq
increment by 20
maxvalue 999999
nochche
noccle;
修改序列的注意事项
- 必须时序列的拥有者或对序列有ALTER权限
- 只有将来的序列值会被改变
- 改变序列的初始值只能通过删除序列之后重建序列的方法实现
删除序列
- 使用drop sequence 语句删除序列
- 删除之后,序列不能再次被引用
drop sequence dept_deptid_seq;
Sequence dropped.
索引
索引是用于加速数据存取的数据对象。合理的使用索引可以大大降低i/o的次数,从而提高数据访问性能。
- 一种独立于表的模式对象,可以存储在与表不同的磁盘或表空间中
- 索引被删除或损坏,不会对 表产生影响,其影响的只是查询的速度
- 索引一旦建立,Oracle管理系统会对其进行自动维护,而且由Oracle管理系统决定何时使用索引,用户不用再查询语句中指定使用哪个索引
- 再删除一个表时,所有基于该表的索引会自动被删除
- 通过指针加速Oracle服务器的查询速度
- 通过快读定位数据的方法,减少磁盘 I/O
1. 单列索引:
单列索引是基于单个列所建立的索引,比如:
create index 索引名 on 表明(列名);
2. 复合索引:
复合索引是基于两个列或多个列的索引。在同一张表上可以有多个索引,但是要求列的组合必须不同,例如:
create index emp_idxl on emp(ename, job);
create index emp_idx1 on emp(job, ename);
示例:给person表的name属性建立索引
create index pname_index on person(name);
示例:给person表创建一个name和gender的索引
create index pname_gender_index on person(name, gender);
什么时候创建索引
- 列中数据值分布范围很广
- 列经常在where子句或连接条件中出现
- 表经常被访问而且数据量很大,访问的数据大概占数据总量的2%到4%
什么时候不要创建索引
- 表很小
- 列不经常作为连接条件或出现在where子句中
- 查询的数据大于2%到4%
- 表经常更新
查询索引
可以使用数据字典视图USER_INDEXES和USER_IND_COLUMNS查看索引的信息

删除索引
- 使用DROP INDEX命令删除索引
drop index indexName;
- 删除索引UPPER LAST NAME IDX
drop index upper_last_name_idx;
Index dropped.
- 只有索引的拥有者或拥有drop any index 权限的用户才可以删除索引
同义词
- 方便范文其它用户的对象
- 缩短对象名字的长度
create [public] SYNONYM synonym
for object;
创建同义词
示例:为视图DEPT_SUM_VU创建同义词
create synonym d_sum
for dept_sum_vu;
Synonym Created.
删除同义词
drop synonym d_sum;
Synonym dropped.
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
