本系列的第6篇《再不会“降维打击”你就Out了!》讲述了递归算法的意义、套路,第7篇《神力加身!动态编程》讲述了递归算法的优化,但是在大量的实际项目、工程和大家关心的求职面试中,却会碰到大量消除递归的需求。于是产生了两个问题:
1. 为什么会有消除递归的需求?
2. 如果都采用非递归的方式,那么递归算法的独特价值又是什么呢?
本文以此为引子,将以你在任何其他算法书中都不会看到的方式,向你揭示递归的高阶技巧,让你彻底掌握递归与非递归的左右互搏之术。
今天的小汽车会逐步加速,各位乘客要系好安全带:)


1. 从哪里来、回到哪里去
递归算法在运行的时候,是不断重入同一函数的,既然是重入,就必然要搞清楚一个基本的问题——从哪里来、回到哪里去?
用专业一点的术语讲,就是要解决“上下文”问题。
当今流行的经典计算机体系结构和编程语言都采用堆栈来解决上下文的保存和恢复问题。
2. 什么是堆栈?
堆栈本质用以下两点概括:
- 一段存储空间(通常是内存);
- 一组向这段存储空间存、取数据的操作。它满足“后进先出”原则。
打个形象的比方:
堆栈就相当于茶壶,向堆栈中存数据就相当于向茶壶里加水,取数据就相当于从茶壶里倒出水。
很显然,最新加进茶壶的水在最上层,从茶壶里倒出水的时候,也是这部分水先被倒出来。


3. 堆栈的好处是什么?
用一句通俗的话来总结就是:历史倒序回放,只问元芳:)
把每次放入数据的动作,看作是历史上的一个时刻的话,那么N次放入数据,就相当于历史上的N个时刻。它们组成了一段历史,这段历史保存在了堆栈中。




从堆栈中取数据,就相当于回放一个历史时刻。根据堆栈操作的“后进先出”原则,堆栈中每次取出的“历史时刻”都是“最近时刻”。将堆栈中的数据逐一取出,就相当于将历史倒序回放。
从上面的过程可以看出,每次倒放“最近时刻”的时候,不需要管当前状态,只要简单向堆栈这个“元芳”要就好了。
用专业一点的话来总结就是:堆栈起到了历史上下文与当前上下文解耦的作用。
前面提到递归重入的时候,需要保存历史上下文。堆栈正好可以做这件事情。
4. 递归调用/重入 = 函数调用 = 堆栈利用
递归的实现载体是函数。
计算机利用堆栈来实现函数调用。
具体过程简化如下:
第一步:将参数压入堆栈
第二步:将返回地址压入堆栈
第三步:保存上次函数调用栈帧的位置
第四步:执行函数体内的业务逻辑
第五步:恢复上次函数调用栈帧的位置
第六步:将返回地址从堆栈中弹出、跳转到该地址执行
推论4.1:
想返回到哪里去,就把对应的地址提前放入堆栈。
递归调用也好、递归重入也好,说白了都是函数调用。递归重入展开,对计算机系统(编译器+运行时环境)而言,就是针对同一递归函数,不断重复上述过程,直到递归展开结束。
5. 堆栈的代价
堆栈的本质是一段存储空间,递归重入的次数越多,那么要保存的历史上下文也越多,这意味着储存空间的开销也越大。但是存储空间的大小是有限的。如果超出这个限制,就会遭遇常说的“堆栈溢出”问题。
那么如何解决这个问题呢?
答案很简单:把历史上下文中将来不再用的部分扔掉、节省存储。


这就是消除递归的需求的真正意义所在。
6. 递归算法与消除递归算法的配合
根据《再不会“降维打击”你就Out了!》一文中所提到的:
传统算法是以“步骤”为中心的,必须有步骤的全景视图才能求解;


而递归算法是以“状态/规模”为中心的,只要得到状态转移函数就可以求解。

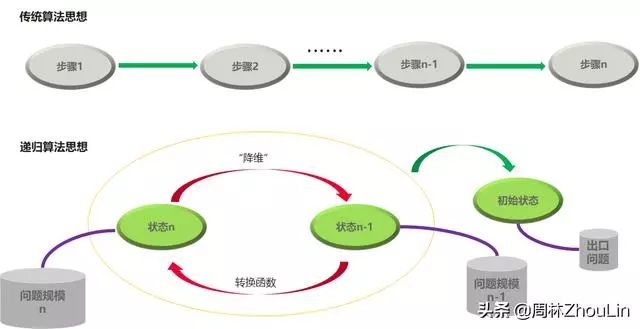

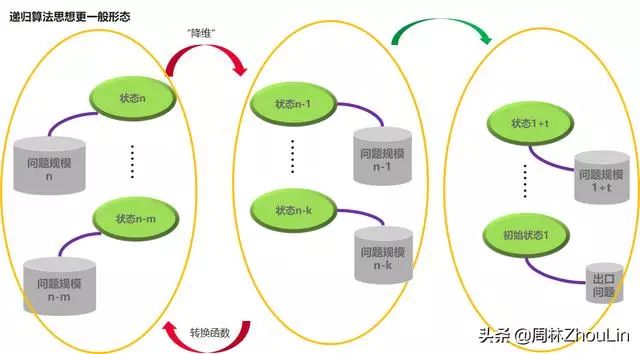

所以,递归算法的独特价值在于:
- 能简单的得到问题的解法;
- 得到解法之后,再通过“消除递归算法”转化成非递归算法、解决无用存储的节省问题
——完美!


7. 递归模型
无外乎以下三种:
左递归:
f(n):ret_v1=call f(g1(n));ret_v2=call f(g2(n));doSomething_2(ret_v1, ret_v2);
右递归:
f(n):doSomething;call f(g1(n));call f(g2(n));
混合式递归:
f(n):ret_v1=call f(g1(n));doSomething(ret_v1);call f(g2(n));
8. 奔跑吧!“消除递归算法”
本系列的第7篇《神力加身!动态编程》中讲述的、自底向上的“动态规划”其实就是一种消除递归算法。
实现“动态规划”的窍门在于:画出如《神力加身!动态编程》一文中所展示的递归展开树,然后从最深的叶子节点开始向上循环处理。
另一种消除递归算法就是“人肉模拟法”——人肉模拟计算机系统对递归算法的实现,也就是章节4描述的步骤。这个也是“消除递归的万能算法”。
步骤中最关键的就是返回地址的处理——它指示了“从哪里来、到哪里去”。


如果递归实现体中有多个子递归调用,那么当递归函数返回时,若不清楚返回地址的话,则你会不知道到底是从哪个子递归返回的。所以返回地址在这里非常重要。
那么如何得到返回地址呢?很多编程语言并不能直接得到地址。变通的方法是找到返回地址的对应物。
推论8.1:
返回地址对应递归展开树中的某个节点。
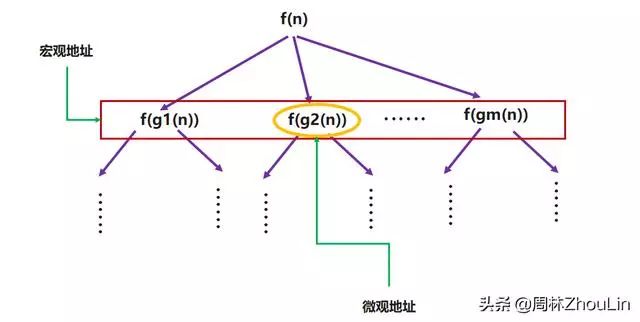

定位递归展开树中的任意一个节点,需要两部分位置信息:
- 在树的哪一层("宏观地址")?
这个可由递归调用的的参数决定。
- 在该层逻辑时序链的哪个节点("微观地址")?
这个可由如下几种方法确定:
(1)该层各子递归在程序实际运行时的调用次序(适用于调用次序图是单向直线型);
(2)该层各子递归在程序实际运行时的上下文环境标识(适用于调用次序图是非单向直线型);
(3)优化后的等价递归模型中,该层各子递归在程序实际运行时的调用次序(适用于调用次序图是单向直线型);
(4)优化后的等价递归模型中,该层各子递归在程序实际运行时的上下文环境标识(适用于调用次序图是非单向直线型)。
注意:不要只是以各子递归在代码中的静态位置来判断调用次序,有的时候实际运行时的调用次序与代码中的静态位置次序是不一样的。
看一个例子:
f(n):int i=0;do {if(i>1) {call f(g1(n));}f(g2(n));i=i+2;if(i==10) {f(g3(n));}} while(i<11);
实际运行时的调用次序图如下:
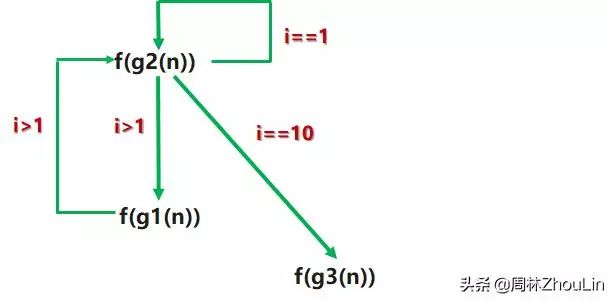

显然,这与f(g1(n))、f(g2(n))、f(g3(n))在代码中静态出现的次序是不同的。
这个例子的“微观地址”用方法(1)搞不定,要用方法(2):因为实际的调用次序图不是单向直线型——它有分支、有环……
综上所述,可得消除递归算法如下:
第一步:画出递归展开树。
目的:
-
识别递归展开路径。
-
识别自底向上收敛的起点条件(初始节点)。
该节点是递归展开之后,首次开始返回的地方。
递归展开到初始节点这一段路径,对应着非递归算法代码的第一部分。
- 识别自底向上收敛的终点的条件。此时历史路径全部遍历完,所以堆栈变空,这个可以作为到达终点的条件。
这对应着非递归算法代码的外部大循环。
第二步:检查展开树中同一层中是否有多个子递归调用;若是,识别各子递归调用之间,从逻辑关系本质上看,到底是并列关系还是时序关系。
若是时序关系,画出逻辑时序链。
并列关系、时序关系的判别方法:
如果交换相应子递归调用的位置,最终整体运行结果没有影响的话,那么就是并列关系;否则,就是时序关系。
并列关系就意味着可以对普通的人肉模拟法进行优化。
第三步:若第二步的分析结果是时序关系,则根据逻辑时序链,设计相应的上下文环境标志或者编号用于"微观地址"的锚定;若是并列关系,则用人肉模拟法消除递归时,可以把对应的几个子递归调用的非递归代码合并。
逻辑时序链中有几条线段,就意味着上下文环境标志或者编码的取值需要有几种状态。
关于并列关系的非递归代码合并:
- 检查是否可以将原始递归模型转换为右递归模型。
考察下面这个左递归模型的递归展开树:
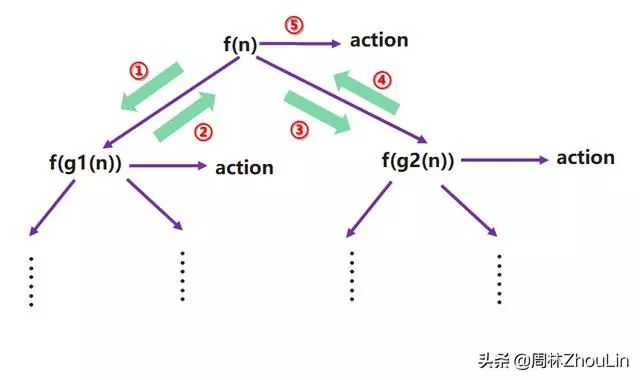

从上图可以看出:在第5步action(业务逻辑)被处理之前,必须要额外处理第2步和第4步的子递归调用返回。这两步会带来如下的两个额外负担:
第一,会增加出栈、入栈的次数;
第二,根据本章节开头所说的,为了区别当前是到第2步还是到第4步了(到底是从f(g1(n))返回的,还是从f(g2(n))返回的),需要增加额外的标志来做判别。
下面来看看右递归模型是如何避免上述问题的:
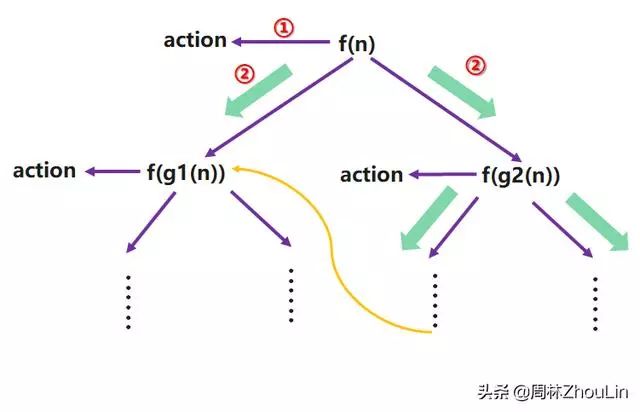

从上图的右递归展开树可以看出:
由于action的处理在子递归调用之前,所以子递归调用结束后,从逻辑意义上讲,就不再需要返回到父节点了。这就有效避免了左递归展开树的第2步和第4步。
那么在其中的子递归调用结束后,如何跳到和它是并列关系的另一个子递归继续执行呢?也就是上图中的黄色连线的效果是如何实现的呢?
根据推论4.1,我们提前把另一个子递归节点放入堆栈就好了。这个可以在上面右递归模型展开树的第2步中完成。
- 并列关系的处理要小心使用多线程范式。
因为随着递归展开树往下生长,并列关系裂变得越来越多,这会造成线程数目的不断膨胀、消耗系统资源。
第四步:针对前三步的分析结果,决策采用动态规划还是人肉模拟法、决策是否借助堆栈。
堆栈中存放:锚定"宏观地址"的参数和锚定"微观地址"的标志或者编号。
推论8.2:
每从堆栈中弹出一次“宏观地址”,就意味着主递归调用返回一层;
每在堆栈中处理一次“微观地址”锚定,就意味着相应某个子递归调用结束。
推论8.2是用人肉模拟法消除递归时,非常实用的技巧。利用它可以将递归算法中的代码与非递归算法中的代码一一对应。
沿着递归展开路径的逆向方向:
如果路径上的每个节点可以逐个直接访问到,那么就可以直接利用动态规划、通过循环结构进行自底向上的收敛;
如果不能逐个直接访问到,那么就必须用堆栈把历史路径保存下来,用于后续的“历史逆序回放”。
第五步:沿递归展开路径逆向收敛、消除递归。
这对应着非递归算法代码的第二部分——在大循环中,采用动态规划进行归纳或者采用人肉模拟法不断弹出堆栈、做业务处理。
以上步骤中最关键的是画出各子递归调用之间的逻辑时序图。
下面我们来应用上述套路来玩票两个"名震江湖"的算法题。
9. 非递归方式后序遍历二叉树
后序遍历二叉树的规则如下:
规则1: 从根节点开始,按照规则2进行递归处理;
规则2: 对于当前节点,先遍历其左子树、再遍历其右子树、最后访问该节点。
显然,这是个递归形式的定义很容易写出对应的递归算法:
class BinaryNode {
private String node_key;
private BinaryNode left_child;
private BinaryNode right_child;
public BinaryNode(String node_key, BinaryNode left_child, BinaryNode right_child) {
this.node_key=node_key;
this.left_child=left_child;
this.right_child=right_child;
}
public BinaryNode getLeftChild() {
return this.left_child;
}
public BinaryNode setLeftChild(BinaryNode left) {
return this.left_child=left;
}
public BinaryNode getRightChild() {
return this.right_child;
}
public BinaryNode setRightChild(BinaryNode right) {
return this.right_child=right;
}
public String getKey() {
return node_key;
}
}
public class TraversalEntity{
public static void postOrderTraversal_recursive(BinaryNode root) {
if(root==null) {
System.out.println("This tree is empty!");
return;
}
postOrderTraversal_recursive(root.getLeftChild());
postOrderTraversal_recursive(root.getRightChild());
System.out.println(root->node_key)
}
public static void main(String args[]) {
// 创建用于测试的二叉树
// 调用postOrderTraversal_recursive()
...
}
}
下面开始应用消除递归套路:
第一步:画出递归展开树。
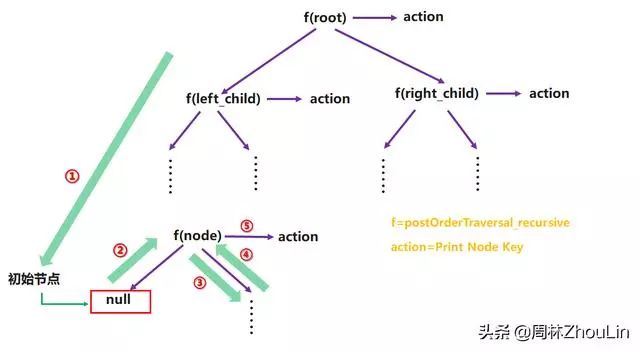

第二步:识别各子递归调用之间的逻辑关系。
显然,交换postOrderTraversal(left_child)和postOrderTraversal(right_child)的调用位置,就违背了后序遍历的规则,所以这两个子递归调用之间,不是并列关系、是时序关系。逻辑时序链如下:


第三步:设计"微观地址"的锚定。
上图中的逻辑时序链只有一段,所以只需要设计一个标志就可以了:
该标志取值为false的时候,表明调用返回发生在postOrderTraversal(left_child);
该标志取值为true的时候,表明调用返回发生在postOrderTraversal(right_child)。
第四步:决策采用动态规划还是人肉模拟法、决策是否借助堆栈。
因为是用单向链表作为二叉树的数据结构,所以沿着递归展开路径的逆向方向,节点不能逐一直接访问到。不能直接采用动态规划、必须借助堆栈。
第五步:沿递归展开路径逆向收敛、消除递归。
自底向上收敛的起点条件——识别初始节点——递归展开之后,首次返回的节点:该节点为空节点。
自底向上收敛的终点的条件:堆栈变空。
综上所述,非递归式后序遍历算法如下:
import java.util.Stack;
class BinaryNode {
private String node_key;
private BinaryNode left_child;
private BinaryNode right_child;
public BinaryNode(String node_key, BinaryNode left_child, BinaryNode right_child) {
this.node_key=node_key;
this.left_child=left_child;
this.right_child=right_child;
}
public BinaryNode getLeftChild() {
return this.left_child;
}
public BinaryNode setLeftChild(BinaryNode left) {
return this.left_child=left;
}
public BinaryNode getRightChild() {
return this.right_child;
}
public BinaryNode setRightChild(BinaryNode right) {
return this.right_child=right;
}
public String getKey() {
return node_key;
}
}
class ElementInfo {
private boolean flag;
private BinaryNode node_item;
public ElementInfo(boolean flag, BinaryNode node_item) {
this.flag=flag;
this.node_item=node_item;
}
public boolean getFlag() {
return this.flag;
}
public void setFlag(boolean flag) {
this.flag=flag;
}
public BinaryNode getNode() {
return this.node_item;
}
}
public class TraversalEntity{
public static void postOrderTraversal_nonrecursive(BinaryNode root) {
//开始翻译递归展开树的编号1部分
if(root == null) {
System.out.println("This tree is empty!");
return;
}
BinaryNode p=root.getLeftChild();
ElementInfo e=new ElementInfo(false, root);
Stack<ElementInfo> stack=new Stack<ElementInfo>();
stack.push(e);
do {
while(p!=null) {
e=new ElementInfo(false, p);
stack.push(e);
p=p.getLeftChild();
}
//开始翻译递归展开树的编号2部分
//递归展开树的编号4部分也在这里
ElementInfo current=stack.pop();
BinaryNode node_item=current.getNode();
if(!current.getFlag()) {
p=node_item.getRightChild();
//这块代码是为了性能加速,减少不必要的压栈、出栈
if(p==null) {
System.out.println(node_item.getKey());
}
//开始翻译递归展开树的编号3部分
else {
current.setFlag(true);
stack.push(current);
}
}
//开始翻译递归展开树的编号5部分
else {
System.out.println(node_item.getKey());
}
} while(!stack.empty());
}
//Test
public static void main(String[] args) {
BinaryNode level_4_1=new BinaryNode("level_4_1", null, null);
BinaryNode level_4_2=new BinaryNode("level_4_2", null, null);
BinaryNode level_3_1=new BinaryNode("level_3_1", null, level_4_1);
BinaryNode level_3_2=new BinaryNode("level_3_2", level_4_2, null);
BinaryNode level_2_1=new BinaryNode("level_2_1", level_3_1, level_3_2);
BinaryNode level_2_2=new BinaryNode("level_2_2", null, null);
BinaryNode level_2_3=new BinaryNode("level_2_3", null, null);
BinaryNode level_2_4=new BinaryNode("level_2_4", null, null);
BinaryNode level_1_1=new BinaryNode("level_1_1", level_2_1, level_2_2);
BinaryNode level_1_2=new BinaryNode("level_1_2", level_2_3, level_2_4);
BinaryNode root=new BinaryNode("root", level_1_1, level_1_2);
postOrderTraversal_nonrecursive(root);
}
}
10. 非递归方式反转二叉树
Google曾经把这个作为面试题,难倒过国外的"大牛",以致其在互联网上吐槽:)
所谓的反转二叉树,就是从根节点开始递归地将左右子树相互交换。
显然,这也是个递归式定义,很容易写出对应的递归算法:
BinaryNode InvertBinaryTree_recursive(BinaryNode current_node) {
if(current_node==null)
return null;
BinaryNode left=current_node.getLeftchild();
BinaryNode right=current_node.getRightChild();
left=InvertBinaryTree_recursive(left);
right=InvertBinaryTree_recursive(right);
current_node.setLeftChild(right);
current_node.setRightChild(left);
return current_node;
}
还是根据上面的递归消除套路来求出对应的非递归算法:
第一步:画出递归展开树。
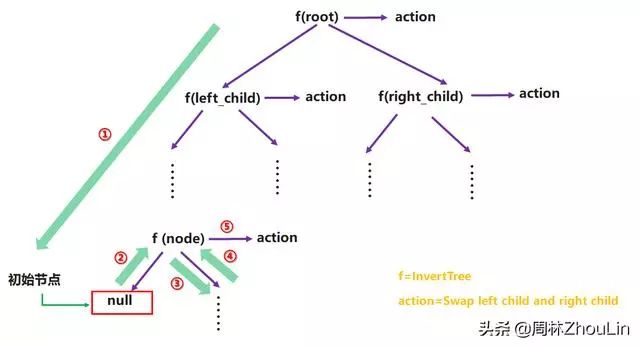

第二步:识别各子递归调用之间的逻辑关系。
交换InvertTree(left_child)和InvertTree(right_child)的调用位置,对整个程序运行结果没有影响,所以这两个子递归调用之间是并列关系。
第三步:设计"微观地址"的锚定。
因为不存在逻辑时序链,所以不需要设计"微观地址"的锚定。
因为是并列关系,所以这两个子递归调用的非递归代码可以合并。
根据在第8章节中讲到的:尝试转化成右递归模型。
合并后的优化递归展开树为:
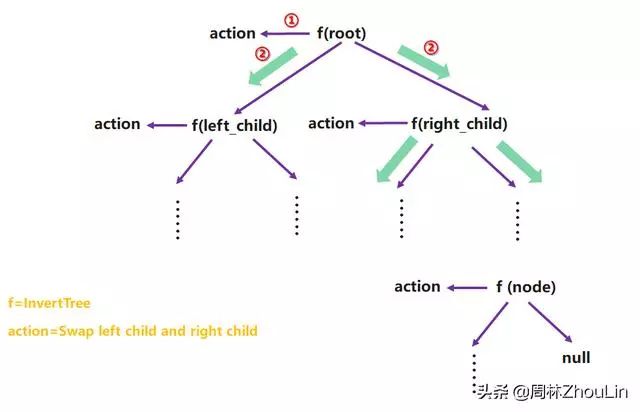

第四步:决策采用动态规划还是人肉模拟法、决策是否借助堆栈。
因为是用单向链表作为二叉树的数据结构,所以沿着递归展开路径的逆向方向,节点不能逐一直接访问到。不能直接采用动态规划、必须借助堆栈。
第五步:沿递归展开路径逆向收敛、消除递归。
自底向上收敛的起点条件——识别初始节点——递归展开之后,首次返回的节点:该节点为空节点。
自底向上收敛的终点的条件:堆栈变空。
综上所述,非递归式后序遍历算法如下:
public class TraversalEntity {
public static void InvertBinaryTree_nonrecursive(BinaryNode root) {
//开始翻译递归展开树的编号1部分
if(root==null)
return;
BinaryNode current=root;
BinaryNode left=root.getLeftChild();
BinaryNode right=root.getRightChild();
Stack<BinaryNode> stack=new Stack<BinaryNode>();
stack.push(current);
do {
//因为是并列关系,所以合并两个子递归调用的非递归代码
if(left!=null) { //针对子递归InvertTree(left_child)
stack.push(left);
}
if(right!=null) { //针对子递归InvertTree(right_child)
stack.push(right);
}
//开始翻译递归展开树的编号2部分
current=stack.pop();
left=current.getLeftChild();
right=current.getRightChild();
current.setLeftChild(right);
current.setRightChild(left);
} while(!stack.empty());
}
}
其实这一题还有其他非递归的解法。
上面我们用单向链表来存储二叉树节点,如果改用数组来存储,就可以利用完全二叉树子节点在数组中的下标与父节点在数组中的下标的线性关系来快速处理消除递归。
后面会专门写一篇关于线性表数据结构的应用的文章,来专门阐述这样的算法。
总结
递归算法到非递归算法的转换,是算法中比较复杂、高阶的内容。
其应用,无论是在编译原理还是人工智能领域都随处可见。
本篇文章致力于用形式化的套路,带领你彻底入门这项技术。
从此,面对类似的问题,笑看风云淡、游刃有余。
结束
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
