缓存模块和装饰器模式
一、缓存模块
- Mybatis缓存模块的核心功能是提供缓存的读取(基于Map来实现),在核心功能的基础之上添加了很多附加功能,比如FIFO淘汰,LRU淘汰,阻塞缓存,定时清空的缓存,打印日志等,这些附加功能就是通过装饰器模式来添加到核心功能上去的。(类似于参考文章中的普通玩家,Vip玩家之类的)
二、装饰器模式
- 给主核心功能添加附加功能,并且能够自由的组合,使用继承不灵活,且附加功能可能很多,继承将导致类非常庞大不可维护。
- 具体可以参考装饰器模式07-结构型模式(中)
三、目录结构
- 包:org.apache.ibatis.cache包
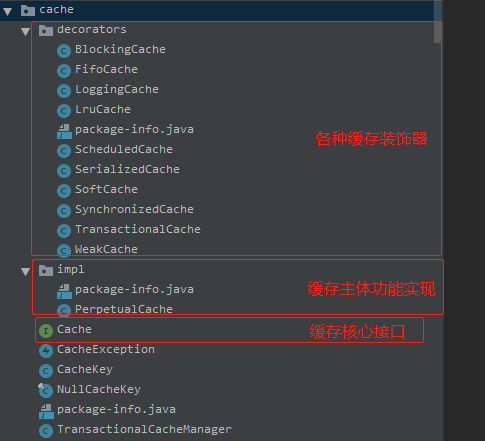
- 图中可以看到缓存的核心接口,主体功能实现类和各种附加功能装饰器,由此形成了各具特色的缓存。
四、源码解析
4.1 接口
- Cache,核心功能接口
public interface Cache {
//缓存实现类的id
String getId();
//往缓存中添加数据,key一般是CacheKey对象
void putObject(Object key, Object value);
//根据指定的key从缓存获取数据
Object getObject(Object key);
//根据指定的key从缓存删除数据
Object removeObject(Object key);
//清空缓存
void clear();
//获取缓存的个数
int getSize();
//获取读写锁
ReadWriteLock getReadWriteLock();
}
4.2 实现类
- 实现类PerpetualCache实现了基本的主体功能
public class PerpetualCache implements Cache {
private final String id;
private Map<Object, Object> cache = new HashMap<>();
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
}
4.3 装饰器类
- 装饰器类给基本实现类添对应的功能
4.3.1 FifoCache
- FifoCache让缓存具备FIFO的淘汰策略
/**
* FIFO (first in, first out) cache decorator
*
* @author Clinton Begin
* 给缓存添加淘汰策略,实现FIFO的功能
* 1.我们发现FifoCache也实现了Cache接口,因此它的行为和PerpetualCache几乎是一致的(都实现了Cache接口定义的方法)
* 并且FifoCache的这些方法的实现,内部都是调用PerpetualCache的实现,因为PerpetualCache才是缓存功能真正的实现者嘛。
* 2.但是FifoCache也有自己需要添加的功能,需要实现FIFO的功能,因此FifoCache内部维护着一个FIFO队列的keyList,队列里
* 保存着缓存的数据的key,在每一次保存数据的时候都会检查FIFO队列对起进行维护,超过设定大小就会去除最旧的key,同时把
* 缓存中的key也删除。这样就为缓存实现了FIFO的淘汰策略
* <p>
* 小结一下:
* 为线程添加缓存FIFO淘汰功能修改的地方只有一下2处,其他都是原封不动的调用PerpetualCache的方法:
* A.存入元素时,需要检查FIFO队列
* B.清理缓存时,清除FIFO队列
*/
public class FifoCache implements Cache {
//真正的缓存功能实现对象
private final Cache delegate;
//FIFO队列
private Deque<Object> keyList;
//队列大小,默认1024
private int size;
public FifoCache(Cache delegate) {
this.delegate = delegate;
this.keyList = new LinkedList<Object>();
this.size = 1024;
}
@Override
public String getId() {
return delegate.getId();
}
@Override
public int getSize() {
return delegate.getSize();
}
public void setSize(int size) {
this.size = size;
}
@Override
public void putObject(Object key, Object value) {
//存入元素时,检查FIFO队列
cycleKeyList(key);
delegate.putObject(key, value);
}
@Override
public Object getObject(Object key) {
return delegate.getObject(key);
}
@Override
public Object removeObject(Object key) {
return delegate.removeObject(key);
}
@Override
public void clear() {
//清理操作时,将FIFO队列也清除
delegate.clear();
keyList.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
private void cycleKeyList(Object key) {
//新添加的key需要保存到keyList里面
keyList.addLast(key);
//判断是否到了最大长度,到了的话需要移除头部最旧的key,同时把缓存中对应的key也删除掉
if (keyList.size() > size) {
Object oldestKey = keyList.removeFirst();
delegate.removeObject(oldestKey);
}
}
}
- FIFO的实现思路是:内部维护一个Deque的FIFO队列,每次存入元素时检查FIFO队列,清理缓存时,清除FIFO队列,不需要额外太多的工作。
4.3.2 LruCache
- LruCache让缓存具备LRU的淘汰策略
/**
* Lru (least recently used) cache decorator
* 为缓存添加LRU的淘汰策略
* 1.LRU的实现思路是,额外维护一个LRU队列按照key的访问顺序保存缓存的key,它是基于LinkedHashMap实现的
* 2.每次put新增缓存,新的缓存key会被放在LRU队列尾部,并且会判断LRU队列中队列头部的最旧的那个key是否需要删除,
* 如果长度达到了1024就把LRU队列中这个key删除并把这个key记录到一个变量eldestKey中,然后会判断eldestKey是否
* 为null,如果不为null就在缓存队列中删除这个最旧的key
* (参考LinkedHashMap#afterNodeInsertion)
* 3.每次get获取缓存的时候,在缓存队列获取缓存数据之前,会在LRU队列中获取一次key,这个获取其实并不是得到他的返回值,
* 仅仅只是触发一次排除,get之后这个key就会被放在LRU队列的尾部,让队列按照LRU原则排序排序
* (参考LinkedHashMap.get和LinkedHashMap.afterNodeAccess)
*
* @author Clinton Begin
*/
public class LruCache implements Cache {
private final Cache delegate;
//1.keyMap是一个LinkedHashMap,也是一个LRU队列,他是按照元素的访问顺序排队的,最久未被访问的元素排在
//队头,最近访问的元素排在队尾(value和key是一样的,其实就是一个有序的链表)
private Map<Object, Object> keyMap;
//2.记录最老的key
private Object eldestKey;
//3.构造方法初始化LRU队列长度为1024
public LruCache(Cache delegate) {
this.delegate = delegate;
setSize(1024);
}
@Override
public String getId() {
return delegate.getId();
}
@Override
public int getSize() {
return delegate.getSize();
}
//4.初始化LRU队列
public void setSize(final int size) {
//1.LinkedHashMap的元素是有序的,可以按照插入顺序或者按访问顺序(调用get方法)。构造方法的第三个参数可以指定使用哪一种顺序排序
//true按照访问顺序排序,
//false按照插入顺序排序
//这里是按照访问顺序排序,符合LRU思想
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
/**
* LinkedHashMap的removeEldestEntry方法,只要返回true,就会自动删除最近最少使用的key
* 默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至
* 链表尾部,不断访问可以形成按访问顺序排序的链表。可以重写removeEldestEntry方法返回
* true值指定插入元素时移除最老的元素
*
* 这里的删除逻辑是这样的,在每一次插入一个新的元素之后,LinkedHashMap里面都会调用removeEldestEntry
* 方法来判断是否需要删除元素,而传给removeEldestEntry的参数就是链表的头指针,也就是是将最旧的元素传进来,
* 如果方法一直返回false说明队列永远不会删除元素。这里我们的逻辑是大于1024长度之后,就会返回true,那么返
* 回true之后LinkedHashMap就会把first代表的最旧的元素删除,与此同时我们会把这个最旧的key记录到eldestKey变量,
* 因为仅仅删除了这个LRU队列还不够,我们还需要删除真正的缓存队列,缓存队列这个删除逻辑是在put进元素的时候回去检
* 查,在cycleKeyList中实现,可参考LinkedHashMap#afterNodeInsertion方法
* */
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
boolean tooBig = size() > size;
if (tooBig) {
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
@Override
public void putObject(Object key, Object value) {
delegate.putObject(key, value);
//1.put进来一个缓存之后,将这个key放到LRU队列尾部,并判断是否有最旧的元素需要删除。逻辑都在cycleKeyList里面实现
cycleKeyList(key);
}
@Override
public Object getObject(Object key) {
//1.这里访问get方法就是为了让这个访问的key放到队列的尾部,因此keyMap是按照访问顺序排序的,最久未被
//问的会放在队列的前面,这里访问该key,就会把置于队尾,实现LRU
//可以参考LinkedHashMap.get和LinkedHashMap.afterNodeAccess
//touch
keyMap.get(key);
return delegate.getObject(key);
}
@Override
public Object removeObject(Object key) {
return delegate.removeObject(key);
}
@Override
public void clear() {
delegate.clear();
//清理缓存的时候也要清理key集合
keyMap.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
//将key放到LRU队列尾部,并判断是否有最旧的key需要删除
private void cycleKeyList(Object key) {
//1.这一步就会将key放到LRU队列的尾部,为什么是尾部,参考LinkedHashMap.afterNodeAccess
keyMap.put(key, key);
//2.如果有最旧的key需要删除,就删掉
//LinkedHashMap删除key是在LinkedHashMap#afterNodeInsertion中调用的,这只是把LRU队列的key删除了,但是真正的缓存队列还没有删除key,
//但是会把key赋值给eldestKey,每一次放进缓存的时候都会来检查,发现有eldestKey,就把他从真正的缓存队列里面清除,并把eldestKey置null
if (eldestKey != null) {
delegate.removeObject(eldestKey);
eldestKey = null;
}
}
}
- 1.LRU的实现思路是,额外维护一个LRU队列按照key的访问顺序保存缓存的key,它是基于LinkedHashMap实现的
- 2.每次put新增缓存,新的缓存key会被放在LRU队列尾部,并且会判断LRU队列中队列头部的最旧的那个key是否需要删除,如果长度达到了1024就把LRU队列中这个key删除并把这个key记录到一个变量eldestKey中,然后会判断eldestKey是否为null,如果不为null就在缓存队列中删除这个最旧的key(参考LinkedHashMap#afterNodeInsertion)
- 3.每次get获取缓存的时候,在缓存队列获取缓存数据之前,会在LRU队列中获取一次key,这个获取其实并不是得到他的返回值,仅仅只是触发一次排除,get之后这个key就会被放在LRU队列的尾部,让队列按照LRU原则排序排序(参考LinkedHashMap.get和LinkedHashMap.afterNodeAccess)
- LinkedHashMap#afterNodeInsertion和afterNodeAccess
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
4.4 小结
- 如果熟悉装饰器模式,结合注释对上面的两种缓存增强应该比较容易理解,剩余的几种就不一一解析了,思想是一样,只是在装饰器内部实现了需要增强的功能点。
五、缓存功能解读
- 前面我们没有对缓存本身功能实现进行解读。缓存模块对应的是一级缓存,不管是否使用一级缓存都是存在的,不使用的话可以通过配置在每次查询之前清空缓存,或者将一级缓存配置为SATEMENT,查询完就会清空一级缓存。
5.1 实现要点
- 缓存模块的实现比较简单,主要在PerpetualCache中,内部封装一个HashMap来保存每一个缓存的k-v对,缓存的存取方法实际上都是对map的操作
5.2 缓存Key
- 一级缓存是基于sqlSession的,因此如果有2个映射文件里面有2个完全一模一样的sql语句,查询2次,第二次也会走数据库,因为是2个不同的sqlSession。
- 一级缓存的key值的设计比较复杂,判断两个key一样需要满足的条件比较多,如下所示:
/**
* CacheKey#equals
* 缓存key的设计包含命名空间,分页信息,sql语句 ,参数值的信息,在BaseExecutor#createCacheKey这里是创建cacheKey的方法,包含了上面的四个要素。
* 判断2个key相等的逻辑
* 1.是一个对象,那么返回true
* 2.被比较对象类型不是CacheKey,直接返回false
* 3.hashcode不一样,返回false
* 4.checksum不一样,返回false
* 5.count不一样,返回false
* 6.updateList列表不一样,返回false
* 7.满足上面的条件,返回true,认为两个缓存key是一样的
*/
@Override
public boolean equals(Object object) {
if (this == object) {
return true;
}
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
if (hashcode != cacheKey.hashcode) {
return false;
}
if (checksum != cacheKey.checksum) {
return false;
}
if (count != cacheKey.count) {
return false;
}
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (thisObject == null) {
if (thatObject != null) {
return false;
}
} else {
if (!thisObject.equals(thatObject)) {
return false;
}
}
}
return true;
}
- 具体涉及到缓存在整个Mybatis查询生命周期中的功能,后面分析Mybatis的核心流程的时候再分析,本文主要是引入缓存模块在设计上使用装饰器模式来实现,值得学习和研究。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
