Redis Cluster 集群伸缩原理源码剖析
1. Redis 集群伸缩教程
Redis提供了灵活的节点扩容和收缩方案。在不影响集群对外服务的情况下,可以为集群添加节点进行扩容也可以对下线节点进行缩容。
如何进行Redis Cluster的伸缩,请参考 Redis Cluster 集群扩容与收缩 本篇教程。本文详细分别使用手动命令和redis-trib.rb工具来执行Redis集群的扩容和收缩操作。
本篇文章根据Redis源码深入剖析集群伸缩的原理。Redis Cluster文件详细注释
2. 集群扩容原理剖析
集群扩容的步骤如下:
- 准备新节点
- 加入集群
- 迁移槽和数据
我们根据步骤一步一步分析。
2.1 准备新节点
本步骤就是准备新的节点和配置启动文件。具体参考 Redis Cluster 载入配置文件、节点握手、分配槽源码剖析 一文的载入配置一部分,该部分从Redis服务器的main函数开始分析,一直到服务器启动成功。
2.2 加入集群
将新节点加入集群,就是发送CLUSTER MEET命令,将准备的新节点加入到已搭建好的集群,让所有的集群中的节点“认识”新的节点。
可以参考 Redis Cluster 载入配置文件、节点握手、分配槽源码剖析 一文中的节点握手部分,该部分根据源码分析了节点握手的三过程:发送MEET消息,回复PONG消息,发送PING消息,最后讲解了Gossip协议在Redis中是如何使用的。
2.3 迁移槽和数据
集群扩容的前两步和搭建集群很像,最后一步则是将集群节点中的槽和数据迁移到新的节点中,而不是为新的节点分配槽位。因此我们重点分析这一过程。Redis Cluster文件详细注释
将 源节点的槽位和数据迁移到目标节点 中,迁移单个槽步骤如下:
-
对目标节点发送
CLUSTER SETSLOT <slot> importing <source_name>,在目标节点中将<slot>设置为 导入状态(importing) 。 -
对源节点发送
CLUSTER SETSLOT <slot> migrating <target_name>,在源节点中将<slot>设置为 导出状态(migrating) 。 -
对源节点发送
CLUSTER GETKEYSINSLOT <slot> <count>命令,获取<count>个属于<slot>的键,这些键要发送给目标节点。 -
对于第三步获得的每个键,发送
MIGRATE host port "" dbid timeout [COPY | REPLACE] KEYS key1 key2 ... keyN命令,将选中的键从源节点迁移到目标节点。- 在
Redis 3.0.7以后的版本支持了MIGRATE命令的批量迁移操作。 - 如果不支持批量迁移,那么会发送
MIGRATE host port key dbid timeout [COPY | REPLACE]命令将一个键从源节点迁移到目标节点。 - 当一次无法迁移完成时,会循环执行第三步和第四步,直到
<count>个键全部迁移完成。
- 在
-
向集群中的任意节点发送
CLUSTER SETSLOT <slot> node <target_name>,将<slot>指派给目标节点。指派信息会通过消息发送到整个集群中,然后最终所有的节点都会知道<slot>已经指派给了目标节点。
我们就根据这些步骤逐步分析:
2.3.1 目标节点中,将槽设置为导入状态
客户端连接上目标节点,并发送该命令给目标节点服务器,目标节点会调用clusterCommand()函数来执行该命令,该函数是一个通用函数,能用于执行CLUSTER开头的所有命令。该函数会判断SETSLOT选项,但是SETSLOT选项对应4种不同的函数分别是:
SETSLOT 10 MIGRATING <node ID> //设置10号槽处于MIGRATING状态,迁移到<node ID>指定的节点
SETSLOT 10 IMPORTING <node ID> //设置10号槽处于IMPORTING状态,将<node ID>指定的节点的槽导入到myself中
SETSLOT 10 STABLE //取消10号槽的MIGRATING/IMPORTING状态
SETSLOT 10 NODE <node ID> //将10号槽绑定到NODE节点上
在SETSLOT选项中先会判断myself节点是否为主节点,如果是从节点则直接返回,然后获取指定的槽号。
int slot;
clusterNode *n;
// 如果myself节点是从节点,回复错误信息
if (nodeIsSlave(myself)) {
addReplyError(c,"Please use SETSLOT only with masters.");
return;
}
// 获取槽号
if ((slot = getSlotOrReply(c,c->argv[2])) == -1) return;
本小节主要看CLUSTER SETSLOT <slot> importing <source_name>命令,在目标节点中,将槽设置为导入状态,处理importing状态的代码如下:
if (!strcasecmp(c->argv[3]->ptr,"importing") && c->argc == 5) {
// 如果该槽已经是myself节点负责,那么不进行导入
if (server.cluster->slots[slot] == myself) {
addReplyErrorFormat(c,"I'm already the owner of hash slot %u",slot);
return;
}
// 获取导入的目标节点
if ((n = clusterLookupNode(c->argv[4]->ptr)) == NULL) {
addReplyErrorFormat(c,"I don't know about node %s",(char*)c->argv[3]->ptr);
return;
}
// 为该槽设置导入目标
server.cluster->importing_slots_from[slot] = n;
// 更新集群状态和保存配置
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|CLUSTER_TODO_UPDATE_STATE);
addReply(c,shared.ok);
先判断该槽位是否已经是目标节点所负责的,如果是则不需要进行导入,否则继续调用clusterLookupNode()函数,根据<source_name>在当前集群中查找源节点,然后将服务器集群状态的importing_slots_from对应的槽和导入的源节点做映射。当前执行该命令的节点是目标节点,因此在目标节点视角中的集群,该槽已经处于导入状态。
如果执行成功,则在进入下个周期之前更新集群状态和保存配置。
最后返回客户端一个OK。
2.3.2 源节点中,将槽设置为导出状态
对源节点发送CLUSTER SETSLOT <slot> migrating <target_name>,将槽设置为导出状态,对应的代码如下:
if (!strcasecmp(c->argv[3]->ptr,"migrating") && c->argc == 5) {
// 如果该槽不是myself主节点负责,那么就不能进行迁移
if (server.cluster->slots[slot] != myself) {
addReplyErrorFormat(c,"I'm not the owner of hash slot %u",slot);
return;
}
// 获取迁移的目标节点
if ((n = clusterLookupNode(c->argv[4]->ptr)) == NULL) {
addReplyErrorFormat(c,"I don't know about node %s",(char*)c->argv[4]->ptr);
return;
}
// 为该槽设置迁移的目标
server.cluster->migrating_slots_to[slot] = n;
// 更新集群状态和保存配置
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|CLUSTER_TODO_UPDATE_STATE);
addReply(c,shared.ok);
在源节点视角的集群中,执行该命令。先会对该槽位的所有权进行判断,如果不属于源节点,那么就无权进行迁移。然后获取要迁移到的目标节点,调用clusterLookupNode()函数查找目标节点。最后将服务器集群状态中的migrating_slots_to对应的槽和导出的目标节点做映射关系。
如果执行成功,则在进入下个周期之前更新集群状态和保存配置。
最后返回客户端一个OK。
2.3.3 获取迁移槽中的键
这一步要获取迁移槽中的所有键,这些键是要从源节点发送到目标节点。因此对应的选项是getkeysinslot,代码如下:
if (!strcasecmp(c->argv[1]->ptr,"getkeysinslot") && c->argc == 4) {
/* CLUSTER GETKEYSINSLOT <slot> <count> */
long long maxkeys, slot;
unsigned int numkeys, j;
robj **keys;
// 获取槽号
if (getLongLongFromObjectOrReply(c,c->argv[2],&slot,NULL) != C_OK)
return;
// 获取打印键的个数
if (getLongLongFromObjectOrReply(c,c->argv[3],&maxkeys,NULL)
!= C_OK)
return;
// 判断槽号和个数是否非法
if (slot < 0 || slot >= CLUSTER_SLOTS || maxkeys < 0) {
addReplyError(c,"Invalid slot or number of keys");
return;
}
// 分配保存键的空间
keys = zmalloc(sizeof(robj*)*maxkeys);
// 将count个键保存到数组中
numkeys = getKeysInSlot(slot, keys, maxkeys);
// 添加回复键的个数
addReplyMultiBulkLen(c,numkeys);
// 添加回复每一个键
for (j = 0; j < numkeys; j++) addReplyBulk(c,keys[j]);
zfree(keys);
}
该函数会先根据传入的参数,获取到对应的槽号slot和要打印槽中键的个数maxkey。然后判断指定的槽号和键的个数是否合法。
然后会为回复创建一个数组,将这些键保存到该数组中。
接下来会调用getKeysInSlot()函数,最多获取maxkey个键。
最后就是回复客户端,先回复获取键的个数,然后回复每个获取的键。
Redis集群中的数据库,不仅在键值对字典中保存了当前键值对,还会在zskiplist *slots_to_keys中保存槽和键之间的关系。
当执行一个写数据库的命令时,就会调用dbAdd()函数将键加入到键值对字典中,而该函数会判断是否当前运行在集群模式下,如果运行在集群模式下则会调用slotToKeyAdd()函数将槽作为分值将键作为成员,添加到slots_to_keys跳跃表中。而刚才调用的getKeysInSlot()函数则是遍历这个跳跃表,最多返回<count>个槽中的键。
假设我们有这么几个键,他在跳跃表中的样子如下图所示:
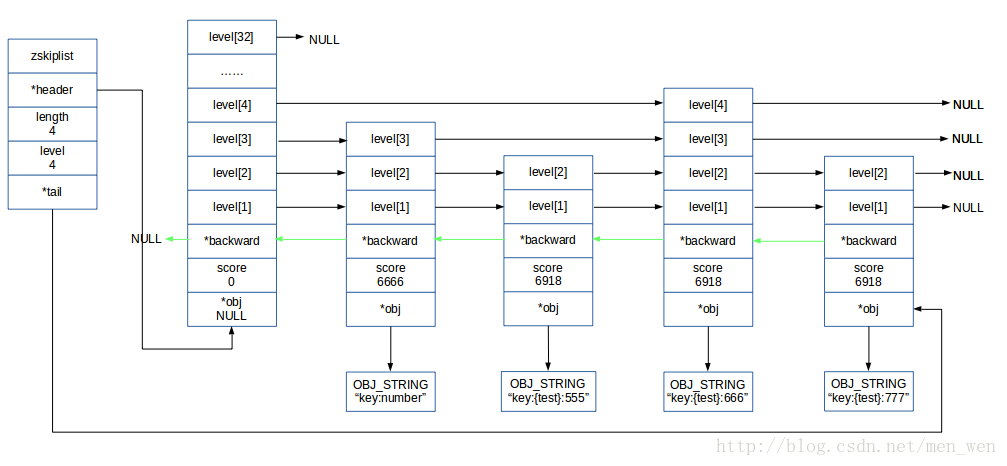
- 槽
6666有一个键,键的名字是key:number。 - 槽
6918有三个键,键的名字是key:{test}:555、key:{test}:666、和key:{test}:777。
当我们通过CLUSTER GETKEYSINSLOT <slot> <count>命令获取到<slot>中的键时,下一步就可以进行迁移了。
2.3.4 迁移槽中的键
MIGRATE命令的完整形式如下:
MIGRATE host port "" dbid timeout [COPY | REPLACE] KEYS key1 key2 ... keyN
MIGRATE host port key dbid timeout [COPY | REPLACE]
在Redis 3.0.7之后支持了第一个批量迁移的版本。Redis Cluster文件详细注释
我们将MIGRATE的执行过程分为 五个部分 详细解释。
- 解析参数和判断参数合法性
void migrateCommand(client *c) {
migrateCachedSocket *cs;
int copy, replace, j;
long timeout;
long dbid;
robj **ov = NULL; /* Objects to migrate. */
robj **kv = NULL; /* Key names. */
robj **newargv = NULL; /* Used to rewrite the command as DEL ... keys ... */
rio cmd, payload;
int may_retry = 1;
int write_error = 0;
int argv_rewritten = 0;
int first_key = 3; /* Argument index of the first key. */
int num_keys = 1; /* By default only migrate the 'key' argument. */
copy = 0;
replace = 0;
// 解析附加项
for (j = 6; j < c->argc; j++) {
// copy项:不删除源节点上的key
if (!strcasecmp(c->argv[j]->ptr,"copy")) {
copy = 1;
// replace项:替换目标节点上已存在的key
} else if (!strcasecmp(c->argv[j]->ptr,"replace")) {
replace = 1;
// keys项:指定多个迁移的键
} else if (!strcasecmp(c->argv[j]->ptr,"keys")) {
// 第三个参数必须是空字符串""
if (sdslen(c->argv[3]->ptr) != 0) {
addReplyError(c,
"When using MIGRATE KEYS option, the key argument"
" must be set to the empty string");
return;
}
// 指定要迁移的键,第一个键的下标
first_key = j+1;
// 键的个数
num_keys = c->argc - j - 1;
break; /* All the remaining args are keys. */
} else {
addReply(c,shared.syntaxerr);
return;
}
}
// 参数有效性检查
if (getLongFromObjectOrReply(c,c->argv[5],&timeout,NULL) != C_OK ||
getLongFromObjectOrReply(c,c->argv[4],&dbid,NULL) != C_OK)
{
return;
}
if (timeout <= 0) timeout = 1000;
// 检查key是否存在,至少有一个key要迁移,否则如果所有的key都不存在,回复一个"NOKEY"通知调用者,没有要迁移的键
ov = zrealloc(ov,sizeof(robj*)*num_keys);
kv = zrealloc(kv,sizeof(robj*)*num_keys);
int oi = 0;
// 遍历所有指定的键
for (j = 0; j < num_keys; j++) {
// 以读操作取出key的值对象,保存在ov中
if ((ov[oi] = lookupKeyRead(c->db,c->argv[first_key+j])) != NULL) {
// 将存在的key保存到kv中
kv[oi] = c->argv[first_key+j];
// 计数存在的键的个数
oi++;
}
}
num_keys = oi;
// 没有键存在,迁移失败,返回"+NOKEY"
if (num_keys == 0) {
zfree(ov); zfree(kv);
addReplySds(c,sdsnew("+NOKEY\r\n"));
return;
}
..................
该部分主要根据函数附加的选项,
- 如果指定了
copy,则表示不删除源节点上的key,并且设置copy = 1标识。 - 如果指定了
replace,则表示替换目标节点上已存在的key,并且设置replace = 1标识。 - 如果指定了
keys,则表示批量迁移,那么需要判断第四个参数是否是空字符串(”“),如果不是则直接返回。如果命令语法正确,则需要更新第一个指定键在参数列表中的下标first_key = j+1,和指定了键的个数num_keys = c->argc - j - 1。
解析完成后,则会判断参数的合法性,如果所有参数都合法,那么会将键值对分别保存到ov和kv数组中。如果所有指定的键都不在当前节点中,那么会回复客户端一个+NOKEY错误。
然后这些就是迁移键的准备工作,接下来就要进行迁移键。
- 发送迁移数据
try_again:
write_error = 0;
// 返回一个包含连接目标实例的TCP套接字的migrateCachedSocket结构,有可能返回一个缓存套接字
cs = migrateGetSocket(c,c->argv[1],c->argv[2],timeout);
if (cs == NULL) {
zfree(ov); zfree(kv);
return; /* error sent to the client by migrateGetSocket() */
}
// 初始化缓冲区对象cmd,用来构建SELECT命令
rioInitWithBuffer(&cmd,sdsempty());
// 创建一个SELECT命令,如果上一次要还原到的数据库ID和这次的不相同
int select = cs->last_dbid != dbid; /* Should we emit SELECT? */
// 则需要创建一个SELECT命令
if (select) {
serverAssertWithInfo(c,NULL,rioWriteBulkCount(&cmd,'*',2));
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"SELECT",6));
serverAssertWithInfo(c,NULL,rioWriteBulkLongLong(&cmd,dbid));
}
// 将所有的键值对进行加工
for (j = 0; j < num_keys; j++) {
long long ttl = 0;
// 获取当前key的过期时间
long long expireat = getExpire(c->db,kv[j]);
if (expireat != -1) {
// 计算key的生存时间
ttl = expireat-mstime();
if (ttl < 1) ttl = 1;
}
// 以"*<count>\r\n"格式为写如一个int整型的count
// 如果指定了replace,则count值为5,否则为4
// 写回复的个数
serverAssertWithInfo(c,NULL,rioWriteBulkCount(&cmd,'*',replace ? 5 : 4));
// 如果运行在进群模式下,写回复一个"RESTORE-ASKING"
if (server.cluster_enabled)
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"RESTORE-ASKING",14));
// 如果不是集群模式下,则写回复一个"RESTORE"
else
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"RESTORE",7));
// 检测键对象的编码
serverAssertWithInfo(c,NULL,sdsEncodedObject(kv[j]));
// 写回复一个键
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,kv[j]->ptr,sdslen(kv[j]->ptr)));
// 写回复一个键的生存时间
serverAssertWithInfo(c,NULL,rioWriteBulkLongLong(&cmd,ttl));
// 将值对象序列化
createDumpPayload(&payload,ov[j]);
// 将序列化的值对象写到回复中
serverAssertWithInfo(c,NULL,
rioWriteBulkString(&cmd,payload.io.buffer.ptr,sdslen(payload.io.buffer.ptr)));
sdsfree(payload.io.buffer.ptr);
// 如果指定了replace,还要写回复一个REPLACE选项
if (replace)
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"REPLACE",7));
}
errno = 0;
{
sds buf = cmd.io.buffer.ptr;
size_t pos = 0, towrite;
int nwritten = 0;
// 将rio缓冲区的数据写到TCP套接字中,同步写,如果超过timeout时间,则返回错误
while ((towrite = sdslen(buf)-pos) > 0) {
// 一次写64k大小的数据
towrite = (towrite > (64*1024) ? (64*1024) : towrite);
nwritten = syncWrite(cs->fd,buf+pos,towrite,timeout);
if (nwritten != (signed)towrite) {
write_error = 1;
goto socket_err;
}
// 记录已写的大小
pos += nwritten;
}
}
........................
要进行迁移键,必须在源节点和目标节点之间建立TCP连接。为了避免频繁的创建释放连接,因此在服务器中的server.migrate_cached_sockets字典中缓存了 最近的十个连接 。该字典的键是host:ip,字典的值是一个指针,指向migrateCachedSocket结构。该结构定义如下:
// 最大的缓存数
#define MIGRATE_SOCKET_CACHE_ITEMS 64 /* max num of items in the cache. */
// 缓存连接的生存时间10s
#define MIGRATE_SOCKET_CACHE_TTL 10 /* close cached sockets after 10 sec. */
typedef struct migrateCachedSocket {
// TCP套接字
int fd;
// 上一次还原键的数据库ID
long last_dbid;
// 上一次使用的时间
time_t last_use_time;
} migrateCachedSocket;
在调用一个migrateGetSocket()函数之前首先会在migrate_cached_sockets字典中寻找,如果没找到则新创建一个连接,并且加入到缓存字典中,返回一个迁移连接。
然后又初始化一个缓冲区对象cmd,用来做命令的缓存,首先得构建SELECT命令,以防迁移到错误的数据库。
接下来,就要遍历每一个要发送的键,对于每一个键都要做以下操作,并且都是以Redis通信协议的方式。
-
先获取键的过期时间,然后计算出键的生存时间。
-
将一个整数值写到缓冲区对象
cmd中,该整数表示之后会解析多少项。如果指定了replace,那么整数值是5,否则是4。 -
如果当前在集群模式下,那么会将
RESTORE-ASKING命令写到缓冲区对象cmd中,如果在普通的节点之间迁移,则写RESTORE命令。这两个命令都是用来反序列化的。 -
检测键名的对象编码类型是否是字符串类型的编码。
-
将当前遍历的键,写到缓冲区对象
cmd中。 -
再将该键的生存时间,也写到缓冲区对象
cmd中。 -
调用
createDumpPayload()函数将该键对应的值对象进行序列化,并且保存到另一个缓冲区对象payload中,然后将payload中的缓存写到缓冲区对象cmd中。- 序列化格式如下:| 1 bytes type | obj | 2 bytes RDB version | 8 bytes CRC64 |
-
最后,如果指定了
replace,则还需要多写一个REPLACE。
对于每一个键,经过以上操作,都会构建一个RESTORE或RESTORE-ASKING命令,这两个命令都是用来进行反序列化序列的,这两个命令唯一不同就是后者会指定一个CMD_ASKING标识。在命令表中如下:
{"restore",restoreCommand,-4,"wm",0,NULL,1,1,1,0,0},
{"restore-asking",restoreCommand,-4,"wmk",0,NULL,1,1,1,0,0}, // 多指定了一个k
{"asking",askingCommand,1,"F",0,NULL,0,0,0,0,0},
// k:为该命令执行一个隐式的 ASKING 命令,所以在集群模式下,如果槽被标记为'importing',那这个命令会被接收。
这两个命令都调用restoreCommand命令执行,因此参数上面的每一步操作都会对应这两个命令的每一个参数,如下:
RESTORE key ttl serialized-value [REPLACE]
当构建好迁移的数据后,就要发送给目标节点,调用syncWrite()函数同步将cmd的缓存写到连接的fd中,设置超时时间为timeout,每次写64K大小。如果发生写错误,会设置write_error = 1并且跳转到socket_err的错误处理代码。
- 目标节点执行反序列化命令并回复
当将构建好的反序列化命令发送给目标节点后,目标节点会执行后并回馈给源节点一些信息,源节点根据这些信息来信息判断目标节点是否执行成功。
首先会执行SELECT命令,进行切换数据库,以防发生错误。
然后目标节点接收到源节点发送过来的RESTORE或者restore-asking命令后,会调用restoreCommand()函数执行命令。该函数代码如下:
void restoreCommand(client *c) {
long long ttl;
rio payload;
int j, type, replace = 0;
robj *obj;
// 解析REPLACE选项,如果指定了该选项,设置replace标识
for (j = 4; j < c->argc; j++) {
if (!strcasecmp(c->argv[j]->ptr,"replace")) {
replace = 1;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
// 如果没有指定替换标识,但是键存在,回复一个错误
if (!replace && lookupKeyWrite(c->db,c->argv[1]) != NULL) {
addReply(c,shared.busykeyerr);
return;
}
// 获取生存时间
if (getLongLongFromObjectOrReply(c,c->argv[2],&ttl,NULL) != C_OK) {
return;
} else if (ttl < 0) {
addReplyError(c,"Invalid TTL value, must be >= 0");
return;
}
// 验证RDB版本和数据校验和
if (verifyDumpPayload(c->argv[3]->ptr,sdslen(c->argv[3]->ptr)) == C_ERR)
{
addReplyError(c,"DUMP payload version or checksum are wrong");
return;
}
// 初始化缓冲区对象payload并设置缓冲区的地址,读出了序列化数据到缓冲区中
rioInitWithBuffer(&payload,c->argv[3]->ptr);
// 类型错误
if (((type = rdbLoadObjectType(&payload)) == -1) ||
((obj = rdbLoadObject(type,&payload)) == NULL))
{
addReplyError(c,"Bad data format");
return;
}
// 如果指定了替代的标识,那么删除旧的键
if (replace) dbDelete(c->db,c->argv[1]);
// 添加键值对到数据库中
dbAdd(c->db,c->argv[1],obj);
// 设置生存时间
if (ttl) setExpire(c->db,c->argv[1],mstime()+ttl);
signalModifiedKey(c->db,c->argv[1]);
addReply(c,shared.ok);
server.dirty++;
}
该函数首先会解析是否指定了REPLACE选项,如果指定了,那么设置replace = 1,否则回复一个-ERR。
但是如果没有指定REPLACE选项,但是在数据库中却存在该键,那么回复-BUSYKEY。
从参数中获取生存时间ttl,如果生存时间小于0,则回复一个错误。
然后,调用verifyDumpPayload()函数从序列化的数据中验证RDB版本和校验和,如果出错则回复一个错误。
接下来将序列化数据保存到缓冲区对象payload中,然后根据序列化的格式,读出键的值对象的编码类型,然后根据编码类型在读出值对象。
如果指定了replace标识,那么会调用dbDelete()将该将从数据库中删除。
如果获取了生存时间ttl,调用setExpire()函数设置该键的生存时间。
最后执行成功,发送修改键的信号,更新脏键,并且回复一个+OK。
当命令执行完成后,目标节点将回复发送给源节点,源节点根据回复来判断是否执行成功。
- 读取发送过去的命令回复
// 读取命令的回复
char buf1[1024]; /* Select reply. */
char buf2[1024]; /* Restore reply. */
// 如果指定了select,读取该命令的回复
if (select && syncReadLine(cs->fd, buf1, sizeof(buf1), timeout) <= 0)
goto socket_err;
// 读RESTORE的回复
int error_from_target = 0;
int socket_error = 0;
int del_idx = 1; /* Index of the key argument for the replicated DEL op. */
// 没有指定copy选项,分配一个新的参数列表空间
if (!copy) newargv = zmalloc(sizeof(robj*)*(num_keys+1));
// 读取每一个键的回复
for (j = 0; j < num_keys; j++) {
// 同步读取每一个键的回复,超时timeout
if (syncReadLine(cs->fd, buf2, sizeof(buf2), timeout) <= 0) {
socket_error = 1;
break;
}
// 如果指定了select,检查select的回复
if ((select && buf1[0] == '-') || buf2[0] == '-') {
// 如果select回复错误,那么last_dbid就是无效的了
if (!error_from_target) {
cs->last_dbid = -1;
addReplyErrorFormat(c,"Target instance replied with error: %s",
(select && buf1[0] == '-') ? buf1+1 : buf2+1);
error_from_target = 1;
}
} else {
// 没有指定copy选项,要删除源节点的键
if (!copy) {
// 删除源节点的键
dbDelete(c->db,kv[j]);
// 发送信号
signalModifiedKey(c->db,kv[j]);
// 更新脏键个数
server.dirty++;
// 设置删除键的列表
newargv[del_idx++] = kv[j];
incrRefCount(kv[j]);
}
}
}
........................
先调用syncReadLine()读一行回复,也就是SELECT命令的回复,保存到buf1中。
然后循环读取每一个键执行的回复,保存在buf2中,如果buf1或者buf2的第一个字符是'-',表示目标节点执行RESTORE命令发生了错误,那么需要重置last_dbid,因为缓存的已经失效。
如果回复的成功执行的信息。呢么根据是否指定了copy,如果没有指定,表示要删除源节点的键。那么调用dbDelete()函数将该键从源节点的数据库中删除,并且要将删除的键保存到newargv参数列表中。
- 错误处理
执行以上代码时,可能会发生错误,有些错误无法挽回,直接返回,有些错误则可以执行重试操作。代码如下:
// 套接字错误,第一个键就错误,可以进行重试
if (!error_from_target && socket_error && j == 0 && may_retry &&
errno != ETIMEDOUT)
{
goto socket_err; /* A retry is guaranteed because of tested conditions.*/
}
// 套接字错误,关闭迁移连接
if (socket_error) migrateCloseSocket(c->argv[1],c->argv[2]);
// 没有指定copy选项
if (!copy) {
// 如果删除了键
if (del_idx > 1) {
// 创建一个DEL命令,用来发送到AOF和从节点中
newargv[0] = createStringObject("DEL",3);
// 用指定的newargv参数列表替代client的参数列表
replaceClientCommandVector(c,del_idx,newargv);
argv_rewritten = 1;
} else {
zfree(newargv);
}
newargv = NULL; /* Make it safe to call zfree() on it in the future. */
}
// 执行到这里,如果还没有跳到socket_err,那么关闭重试的标志,跳转到socket_err
if (!error_from_target && socket_error) {
may_retry = 0;
goto socket_err;
}
// 不是目标节点的回复错误
if (!error_from_target) {
// 更新最近一次使用的数据库ID
cs->last_dbid = dbid;
addReply(c,shared.ok);
} else {
/* On error we already sent it in the for loop above, and set
* the curretly selected socket to -1 to force SELECT the next time. */
}
// 释放空间
sdsfree(cmd.io.buffer.ptr);
zfree(ov); zfree(kv); zfree(newargv);
return;
socket_err:
sdsfree(cmd.io.buffer.ptr);
// 如果没有重写client参数列表,关闭连接,因为要保持一致性
if (!argv_rewritten) migrateCloseSocket(c->argv[1],c->argv[2]);
zfree(newargv);
newargv = NULL; /* This will get reallocated on retry. */
// 如果可以重试,跳转到try_again
if (errno != ETIMEDOUT && may_retry) {
may_retry = 0;
goto try_again;
}
zfree(ov); zfree(kv);
addReplySds(c,
sdscatprintf(sdsempty(),
"-IOERR error or timeout %s to target instance\r\n",
write_error ? "writing" : "reading"));
return;
}
如果出现了套接字错误,第一个键就错误,可以进行重试,跳转到socket_err代码。
如果出现了套接字错误,关闭迁移连接。
如果没有指定copy选项,并且进行了删除键的操作,那么要调用replaceClientCommandVector()函数,将客户端的参数列表替换为DEL命令,因为执行了删除键的操作,要传播到从节点和AOF文件中。并且设置重写参数列表的标识argv_rewritten = 1
。如果以上条件都不满足,则会关闭重试执行的标识,跳转到socket_err代码。
如果不是目标节点的回复的错误,则可以更新缓存的上一次使用的数据库id。
在socket_err代码部分,如果没有重写客户端的参数列表,要关闭迁移连接,因为要保持一致性。如果可以重试,那么跳转到try_again发送迁移数据那一步,进行重新尝试执行MIGRATE命令。
如果都无法重试,最后就会回复一个-IOERR错误。
到此源节点执行MIGRATE命令,就执行完成。也就是说槽中的数据已经迁移完成,下一步执行CLUSTER SETSLOT <slot> node <target_name>命令将槽位在指派给目标节点,就大功告成。
2.3.5 迁移槽位
执行玩MIGRATE命令将槽中的所有键迁移完成后,最后只要将槽位指派给目标节点就完成整个迁移操作。Redis Cluster文件详细注释
在任意节点执行CLUSTER SETSLOT <slot> NODE <target_name>命令,最后都会将该信息通过消息发送给每一个集群节点,但是redis-trib.rb工具选择给每一个主节点发送该命令,这样可以阻止槽位和错误节点相关联,可以更少的重定向就能找到正确的节点。处理该命令对应的代码如下:
if (!strcasecmp(c->argv[3]->ptr,"node") && c->argc == 5) {
/* CLUSTER SETSLOT <SLOT> NODE <NODE ID> */
// 查找到目标节点
clusterNode *n = clusterLookupNode(c->argv[4]->ptr);
// 目标节点不存在,回复错误信息
if (!n) {
addReplyErrorFormat(c,"Unknown node %s",(char*)c->argv[4]->ptr);
return;
}
// 如果这个槽已经由myself节点负责,但是目标节点不是myself节点
if (server.cluster->slots[slot] == myself && n != myself) {
// 保证该槽中没有键,否则不能指定给其他节点
if (countKeysInSlot(slot) != 0) {
addReplyErrorFormat(c,
"Can't assign hashslot %d to a different node "
"while I still hold keys for this hash slot.", slot);
return;
}
}
// 该槽处于被迁移的状态但是该槽中没有键
if (countKeysInSlot(slot) == 0 && server.cluster->migrating_slots_to[slot])
// 取消迁移的状态
server.cluster->migrating_slots_to[slot] = NULL;
// 如果该槽处于导入状态,且目标节点是myself节点
if (n == myself &&
server.cluster->importing_slots_from[slot])
{
// 手动迁移该槽,将该节点的配置纪元设置为一个新的纪元,以便集群可以传播新的版本。
// 注意,如果这导致与另一个获得相同配置纪元的节点冲突,例如因为取消槽的同时发生执行故障转移的操作,则配置纪元冲突的解决将修复它,指定不同节点有一个不同的纪元。
if (clusterBumpConfigEpochWithoutConsensus() == C_OK) {
serverLog(LL_WARNING,"configEpoch updated after importing slot %d", slot);
}
// 取消槽的导入状态
server.cluster->importing_slots_from[slot] = NULL;
}
clusterDelSlot(slot);
// 将slot槽指定给n节点
clusterAddSlot(n,slot);
} else {
addReplyError(c,"Invalid CLUSTER SETSLOT action or number of arguments");
return;
}
// 更新集群状态和保存配置
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|CLUSTER_TODO_UPDATE_STATE);
addReply(c,shared.ok);
首先会根据<target_name>参数在集群中查找目标节点,如果目标节点不在集群中,那么回复错误信息,直接返回。
如果是在源节点上执行该命令,那么如果指定的<slot>是源节点负责,并且源节点不等于目标节点,那么需要判断槽位中是否还有键没有迁移,如果槽中还有键存在,则回复错误信息,直接返回。
无论在什么节点上执行该命令,如果判断到指定的<slot>已经空了,并且该槽处于导出状态,都要取消导出的状态。
如果是在目标节点上执行该命令,则且该槽处于导入状态,那么会调用clusterBumpConfigEpochWithoutConsensus()函数来设置目标节点的纪元来解决不同节点的配置纪元configEpoch可能发生冲突的情况。然后目标节点取消该槽位的导入状态。
关于纪元的讲解可以参考@gqtcgq的文章(http://blog.csdn.net/gqtcgq/article/details/51830428)
最后更新集群中的槽位状态,将指定的<slot>槽位分配给目标节点。然后回复客户端一个OK表示执行成功。
这样,整个集群扩容的过程就完成了。
3 集群收缩的原理
集群收缩的过程就是现将下线的节点中的所有槽和数据迁移到目标节点中,然后通过CLUSTER FORGET <NODE ID>命令来让集群中所有的节点都知道下线的节点,并且忘记他。但是建议使用redis-trib.rb工具的del-node来收缩集群,防止频繁执行CLUSTER FORGET命令。Redis Cluster文件详细注释
CLUSTER FORGET <NODE ID>命令的原理就是让下线的节点在某段时间内取消与所有集群节点的交互行为。具体代码如下:
if (!strcasecmp(c->argv[1]->ptr,"forget") && c->argc == 3) {
// 根据<NODE ID>查找节点ilil
clusterNode *n = clusterLookupNode(c->argv[2]->ptr);
// 没找到
if (!n) {
addReplyErrorFormat(c,"Unknown node %s", (char*)c->argv[2]->ptr);
return;
// 不能删除myself
} else if (n == myself) {
addReplyError(c,"I tried hard but I can't forget myself...");
return;
// 如果myself是从节点,且myself节点的主节点是被删除的目标键,回复错误信息
} else if (nodeIsSlave(myself) && myself->slaveof == n) {
addReplyError(c,"Can't forget my master!");
return;
}
// 将n添加到黑名单中
clusterBlacklistAddNode(n);
// 从集群中删除该节点
clusterDelNode(n);
// 更新状态和保存配置
clusterDoBeforeSleep(CLUSTER_TODO_UPDATE_STATE|
CLUSTER_TODO_SAVE_CONFIG);
addReply(c,shared.ok);
}
该函数先根据指定的下线节点的ID在集群中查找该节点,如果不能找到则回复错误信息。
如果指点的节点是当前myself节点,回复错误信息,直接返回。
如果当前myself节点是从节点,但是要忘记的节点是myself节点的主节点,回复错误信息,返回。
调用clusterBlacklistAddNode()函数将要下线的节点加入黑名单中,这个黑名单是一个字典,保存要下线的节点名字。
然后将下线节点从集群中删除,并回复一个ok给客户端。
我们来关注一下下线节点黑名单。clusterBlacklistAddNode()函数代码如下:
void clusterBlacklistAddNode(clusterNode *node) {
dictEntry *de;
// 获取node的ID
sds id = sdsnewlen(node->name,CLUSTER_NAMELEN);
// 先清理黑名单中过期的节点
clusterBlacklistCleanup();
// 然后将node添加到黑名单中
if (dictAdd(server.cluster->nodes_black_list,id,NULL) == DICT_OK) {
// 如果添加成功,创建一个id的复制品,以便能够在最后free
id = sdsdup(id);
}
// 找到指定id的节点
de = dictFind(server.cluster->nodes_black_list,id);
// 为其设置过期时间
dictSetUnsignedIntegerVal(de,time(NULL)+CLUSTER_BLACKLIST_TTL);
sdsfree(id);
}
黑名单中的节点生存时间只有60s,每次加入节点都会先清理过期的节点,然后加入新的节点并且设置过期时间。加入黑名单中节点不会与其他节点进行消息交互,如果超过60s,该节点就会从黑名单中清理,再次发送消息时,就会重新进行握手,最终重新上线。因此只有60s的时间让所有集群节点忘记下线节点。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
