本章,我们来看下Elasticsearch的持久化原理,也就是数据在底层究竟是如何写入到磁盘上的。开始之前,先来了解一个基本概念—— Segment 。
一、Segment File
我们知道,在Elasticsearch中创建一个index索引时,需要指定shard分片,一个shard分片在底层其实是一个Lucene索引,它 由若干个segment文件和对应的commit point(提交点文件)构成 。

segment文件可以理解成底层存储document数据的文件,ES进行检索时最终是从它里面检索出数据的;而commit point文件可以理解成一个保存了若干segment信息的列表,它标识着这个commit point前所有旧的segment file文件。
举个例子,当Elasticsearch创建commit point文件时,会已有一些segment文件是已经存在的,那commit point就保存着这些旧的segment文件的信息:

二、写入流程
一条document数据被写入磁盘会经历以下几个过程:
1.1 write
首先,document会被写入 in-memory buffer 中,所谓 in-memory buffer 其实就是应用内存。同时,document数据会被写入 translog 日志文件。

1.2 refresh
每隔1秒,Elasticsearch会执行一次 refresh 操作:将buffer中的数据refresh到filesystem cache中的一个新segment file中。filesystem cache其实就是os cache,性能非常好。注意,此时的segment file仅仅是存在于os cache中的缓存数据,并不存在于磁盘上。

refresh操作完成后,buffer会被清空。另外,如果buffer满了也会执行refresh。 当数据进入filesystem cache后,其实就可以被检索到了 。
为什么说Elasticsearch是准实时(NRT,near real-time)的?因为默认每隔1秒refresh一次,所以写入的数据1秒之后才能被检索到。可以通过index的
index.refresh_interval参数配置refresh的时间间隔。
1.3 flush
上述过程中,segment file一直存在于os cache中,如果发生宕机,cache中的数据就会丢失。所以需要有一种机制能将os cache中的数据写入磁盘文件。这一过程在Elasticsearch中就叫做 flush 。
在refresh的过程中,os cache中的segment file会越来越多(每次refresh都会创建一个新的segment file), translog 日志文件也会越来越大。当translog大到一定程度的时候,就会触发 flush 操作:
- flush的第一步,将buffer中的现有数据refresh到os cache中,清空buffer;
- 在磁盘上写入一个commit point文件,里面标识着这个commit point前os cache中的所有旧segment file文件数据;
- 强行将os cache中的所有数据
fsync到磁盘文件中去; - 最后将translog清空,因为此时里面记录的数据此时都已经被fsync到磁盘了。
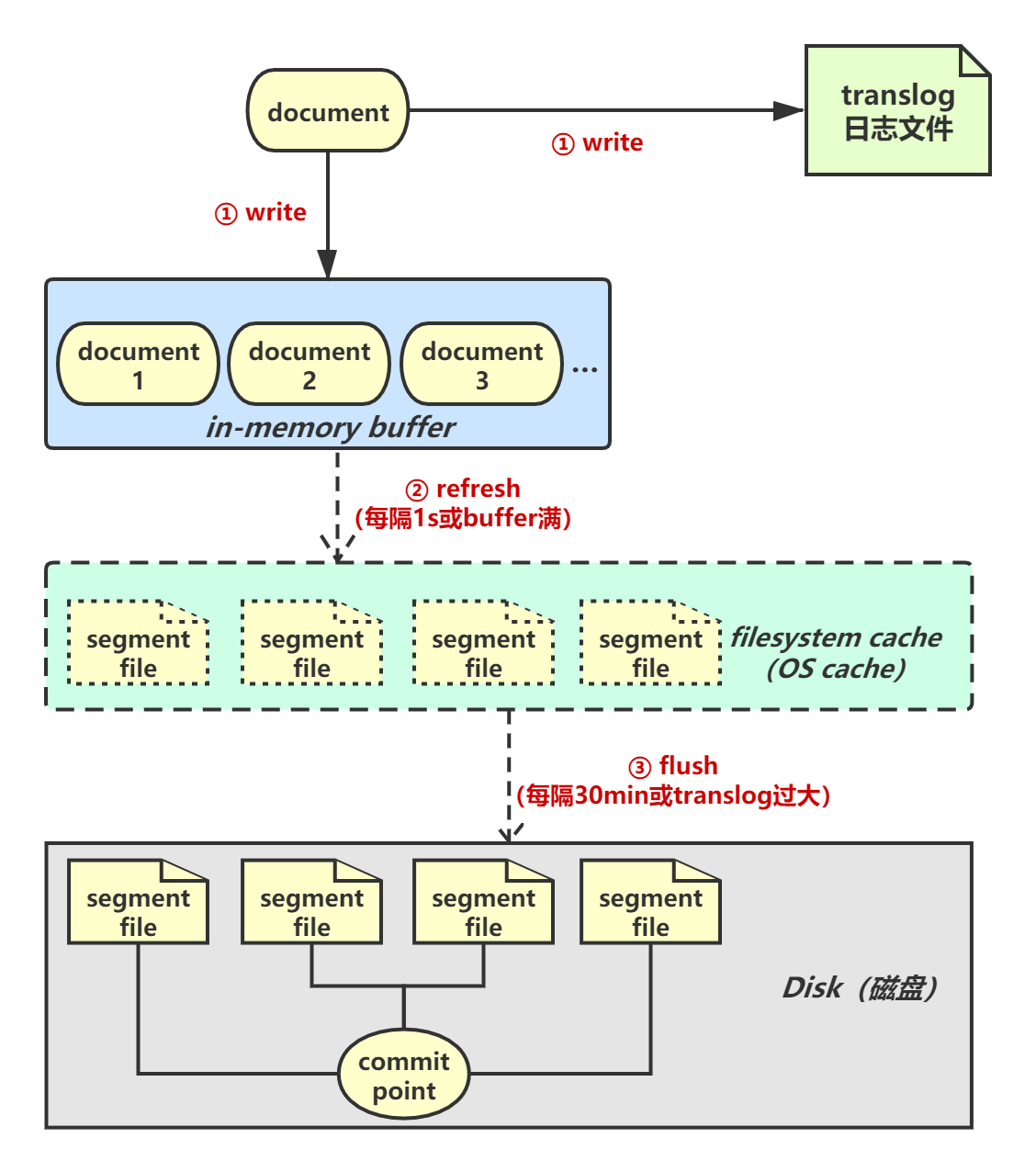
默认每隔30分钟会自动执行一次 flush 操作,但是如果translog过大,也会提前触发。
这里来思考下,translog日志文件的作用是什么?
在执行flush操作之前,数据要么是停留在buffer中,要么是停留在os cache中,此时一旦这台机器宕机,数据就全丢了。所以,需要将数据写入到一个专门的日志文件中,此时即使机器宕机了,再次重启时,Elasticsearch会自动读取translog日志文件中的数据,恢复到内存buffer和os cache中去。
另外,translog中的数据,本身也是先写入os cache,然后默认每隔5秒刷一次到磁盘中。所以默认情况下,即使有translog保证可用性,也可能丢失5s的数据。此时数据仅仅停留在buffer或者translog文件的os cache中,如果此时机器挂了,会丢失这5秒钟的数据。

如果你希望一定不能丢失数据的话,可以设置index的
index.translog.durability参数,使每次写入一条数据,都是写入buffer,同时fsync写入磁盘上的translog文件,但是这会导致写性能、吞吐量严重下降。
1.4 merge
由于每refresh一次,就会os cache中产生一个新的segment file,所以随着segment file越来越多,搜索的性能会降低。此时,Elasticsearch会定期执行 merge 操作。
每次merge时,ES会选择一些相似大小的segment进行合并,同时会将那些标识为deleted的document物理删除掉。合并后新的segment file会被写入磁盘,同时会新建commit point文件,里面标识着所有合并后新的segment file。
三、总结
本章,我介绍了Elasticsearch的持久化原理,核心就是refresh、flush、merge这三个操作。目前很多开源分布式框架都采用了这种数据持久化的思路。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
