READ_HEADER读取头
我们继续上一篇,现在的状态到了读取了。首先会先解析请求头,然后看里面有没有transfer-encoding或者content-length,来进行后续的消息体读取。
case READ_HEADER: try {//读取请求头
State nextState = readHeaders(buffer);
if (nextState == null) {
return;
}
currentState = nextState;
switch (nextState) {
case SKIP_CONTROL_CHARS://没有内容,直接传递两个消息
out.add(message);
out.add(LastHttpContent.EMPTY_LAST_CONTENT);空内容
resetNow();
return;
case READ_CHUNK_SIZE://块协议传递
if (!chunkedSupported) {
throw new IllegalArgumentException("Chunked messages not supported");
}
out.add(message);
return;
default:
//没有transfer-encoding或者content-length头 表示没消息体,比如GET请求
long contentLength = contentLength();
if (contentLength == 0 || contentLength == -1 && isDecodingRequest()) {//没消息体,直接就补一个空消息体
out.add(message);//消息行和消息头
out.add(LastHttpContent.EMPTY_LAST_CONTENT);//空消息体
resetNow();//重置属性
return;
}
assert nextState == State.READ_FIXED_LENGTH_CONTENT ||
nextState == State.READ_VARIABLE_LENGTH_CONTENT;
//有消息体,就先放入行和头信息,下一次解码再进行消息体的读取
out.add(message);//
if (nextState == State.READ_FIXED_LENGTH_CONTENT) {
chunkSize = contentLength;//如果是固定长度的消息体,要保存下一次要读的消息体长度
}
return;
}
} catch (Exception e) {
out.add(invalidMessage(buffer, e));//异常了就无效
return;
}
readHeaders解析头
主要就是按行解析头消息,然后进行头信息分割,然后放入headers ,最后根据content-length来决定后面的状态,是读取固定长READ_FIXED_LENGTH_CONTENT还是可变长READ_VARIABLE_LENGTH_CONTENT,还是是读取块大小READ_CHUNK_SIZE。
private State readHeaders(ByteBuf buffer) {
final HttpMessage message = this.message;
final HttpHeaders headers = message.headers();//获得请求头
AppendableCharSequence line = headerParser.parse(buffer);//解析请求头
if (line == null) {
return null;
}
if (line.length() > 0) {
do {
char firstChar = line.charAtUnsafe(0);
if (name != null && (firstChar == ' ' || firstChar == '\t')) {
//please do not make one line from below code
//as it breaks +XX:OptimizeStringConcat optimization
String trimmedLine = line.toString().trim();
String valueStr = String.valueOf(value);
value = valueStr + ' ' + trimmedLine;
} else {
if (name != null) {
headers.add(name, value);//如果名字解析出来表示值也出来了,就添加进去
}
splitHeader(line);//分割请求头
}
line = headerParser.parse(buffer);//继续解析头
if (line == null) {
return null;
}
} while (line.length() > 0);
}
// Add the last header.
if (name != null) {//添加最后一个
headers.add(name, value);
}
// reset name and value fields 重置
name = null;
value = null;
//找content-length头信息
List<String> values = headers.getAll(HttpHeaderNames.CONTENT_LENGTH);
int contentLengthValuesCount = values.size();//长度头的值的个数
if (contentLengthValuesCount > 0) {
if (contentLengthValuesCount > 1 && message.protocolVersion() == HttpVersion.HTTP_1_1) {//如果是HTTP_1_1找到多个Content-Length是不对的,要抛异常
throw new IllegalArgumentException("Multiple Content-Length headers found");
}
contentLength = Long.parseLong(values.get(0));//获取消息体长
}
if (isContentAlwaysEmpty(message)) {//空内容
HttpUtil.setTransferEncodingChunked(message, false);//不开启块传输
return State.SKIP_CONTROL_CHARS;
} else if (HttpUtil.isTransferEncodingChunked(message)) {
if (contentLengthValuesCount > 0 && message.protocolVersion() == HttpVersion.HTTP_1_1) {//HTTP_1_1如果开启了快协议,就不能设置Content-Length了
throw new IllegalArgumentException(
"Both 'Content-Length: " + contentLength + "' and 'Transfer-Encoding: chunked' found");
}
return State.READ_CHUNK_SIZE;//块传输,要获取大小
} else if (contentLength() >= 0) {
return State.READ_FIXED_LENGTH_CONTENT;//可以固定长度解析消息体
} else {
return State.READ_VARIABLE_LENGTH_CONTENT;//可变长度解析,或者没有Content-Length,http1.0以及之前或者1.1 非keep alive,Content-Length可有可无
}
}
这里有两个要注意的,如果是HTTP1.1一个头只能对应一个值,而且Content-Length和Transfer-Encoding不能同时存在。http1.0以及之前或者http1.1没设置keepalive的话Content-Length可有可无。
Header的结构
外部看上去很像是跟MAP一样添加头信息,其实内部还是使用了数组和单链表和双向循环链表,好比是HashMap的加强版。使用了hash算法定位数组的索引,然后有冲突的时候用单链表头插进去,而且头信息顺序按照双向循环链表连起来了,方便前后定位。具体的细节可以看源码,我就不多说了。

READ_VARIABLE_LENGTH_CONTENT读取可变长内容
直接读取可读的字节,然后封装成DefaultHttpContent内容传递。
case READ_VARIABLE_LENGTH_CONTENT: {
// Keep reading data as a chunk until the end of connection is reached.
int toRead = Math.min(buffer.readableBytes(), maxChunkSize);
if (toRead > 0) {
ByteBuf content = buffer.readRetainedSlice(toRead);
out.add(new DefaultHttpContent(content));
}
return;
}
READ_FIXED_LENGTH_CONTENT读取固定长内容
固定长度就是有contentLength,读取长度,如果等于记录的长度chunkSize ,就表示读完了,直接传递最后内容DefaultLastHttpContent。否则说明没读完,就传递内容DefaultHttpContent。
case READ_FIXED_LENGTH_CONTENT: {//有固定长消息体
int readLimit = buffer.readableBytes();
if (readLimit == 0) {
return;
}
int toRead = Math.min(readLimit, maxChunkSize);//读取的个数
if (toRead > chunkSize) {//如果大于块长度chunkSize,就读chunkSize个
toRead = (int) chunkSize;
}
ByteBuf content = buffer.readRetainedSlice(toRead);
chunkSize -= toRead;
if (chunkSize == 0) {//块全部读完了
// Read all content.
out.add(new DefaultLastHttpContent(content, validateHeaders));//创建最后一个内容体,返回
resetNow();//重置参数
} else {
out.add(new DefaultHttpContent(content));//还没读完,就创建一个消息体
}
return;
}
READ_CHUNK_SIZE读取块大小
如果是chunk块传输,根据块传输协议,就应该是获取块大小。协议格式我画了个图:
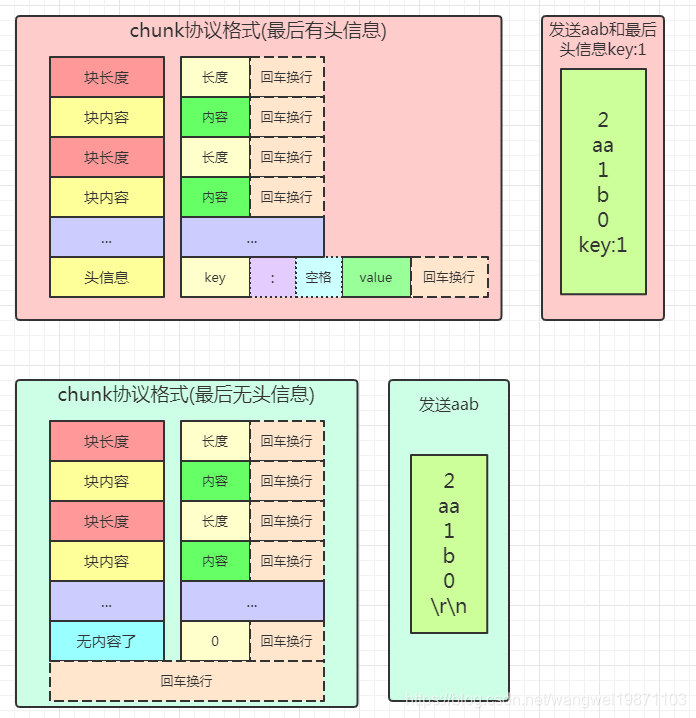
比如要传输aab,使用块协议,第一块长度是2,内容是aa,第二块长度是1,内容是b,第三块长度是0,内容是空(就有回车换行),记得长度内容后面都有回车换行啊。
case READ_CHUNK_SIZE: try {//读取块尺寸
AppendableCharSequence line = lineParser.parse(buffer);
if (line == null) {
return;
}
int chunkSize = getChunkSize(line.toString());
this.chunkSize = chunkSize;//块长度
if (chunkSize == 0) {//读到块结束标记 0\r\n
currentState = State.READ_CHUNK_FOOTER;
return;
}
currentState = State.READ_CHUNKED_CONTENT;//继续读内容
// fall-through
} catch (Exception e) {
out.add(invalidChunk(buffer, e));//无效块
return;
}
如果读取的块长度是0了,那说明要到最后一个了,状态就要转到READ_CHUNK_FOOTER,否则就转到读内容READ_CHUNKED_CONTENT。
getChunkSize获取块尺寸
这里连;,空格,控制字符都算截止符了。
private static int getChunkSize(String hex) {
hex = hex.trim();
for (int i = 0; i < hex.length(); i ++) {
char c = hex.charAt(i);
if (c == ';' || Character.isWhitespace(c) || Character.isISOControl(c)) {
hex = hex.substring(0, i);
break;
}
}
return Integer.parseInt(hex, 16);
}
READ_CHUNKED_CONTENT读取块内容
根据块长度chunkSize读取字节,如果读取长度等于chunkSize,表示读完了,需要读取分隔符,也就是换车换行了,状态转到READ_CHUNK_DELIMITER,否则就将读取的内容,封装成DefaultHttpContent传递下去,然后下一次继续读取内容。
case READ_CHUNKED_CONTENT: {//读取块内容,其实没读取,只是用切片,从切片读,不影响原来的
assert chunkSize <= Integer.MAX_VALUE;
int toRead = Math.min((int) chunkSize, maxChunkSize);
toRead = Math.min(toRead, buffer.readableBytes());
if (toRead == 0) {
return;
}
HttpContent chunk = new DefaultHttpContent(buffer.readRetainedSlice(toRead));//创建一个块,里面放的是切片
chunkSize -= toRead;
out.add(chunk);
if (chunkSize != 0) {//当前块还没接受完,就返回
return;
}
currentState = State.READ_CHUNK_DELIMITER;//接受完,找到块分割符
// fall-through
}
READ_CHUNK_DELIMITER读取块分隔符
其实就是回车换行符,找到了就转到READ_CHUNK_SIZE继续去取下一个块长度。
case READ_CHUNK_DELIMITER: {//找到块分隔符
final int wIdx = buffer.writerIndex();
int rIdx = buffer.readerIndex();
while (wIdx > rIdx) {
byte next = buffer.getByte(rIdx++);
if (next == HttpConstants.LF) {//找到换行符,继续读下一个块的大小
currentState = State.READ_CHUNK_SIZE;
break;
}
}
buffer.readerIndex(rIdx);
return;
}
READ_CHUNK_FOOTER读最后一个块
如果读取的块长度chunkSize=0的话,就说明是最后一个块了,然后要看下是否还有头信息在后面,有头信息的话会封装成DefaultLastHttpContent,如果没有的话头信息就是LastHttpContent.EMPTY_LAST_CONTENT
case READ_CHUNK_FOOTER: try {//读到最后一个了
LastHttpContent trailer = readTrailingHeaders(buffer);//读取最后的内容,可能有头信息,也可能没有
if (trailer == null) {//还没结束的,继续
return;
}
out.add(trailer);//添加最后内容
resetNow();
return;
} catch (Exception e) {
out.add(invalidChunk(buffer, e));
return;
}
readTrailingHeaders读取最后的头信息
会去读取一行,如果没读出来换行,表示可能没收到数据,也就是没读完,那就返回,继续下一次。
如果读出来发现就只有回车换行,那就说明没有头信息,结束了,就返回一个 LastHttpContent.EMPTY_LAST_CONTENT,否则的话就创建一个DefaultLastHttpContent内容,然后进行头信息的解析,解析出来的头信息就放入内容中,并返回内容。
private LastHttpContent readTrailingHeaders(ByteBuf buffer) {
AppendableCharSequence line = headerParser.parse(buffer);
if (line == null) {//没有换行,表示没读完呢
return null;
}
LastHttpContent trailer = this.trailer;
if (line.length() == 0 && trailer == null) {//直接读到\r\n 即读到空行,表示结束,无头信息,返回空内容
return LastHttpContent.EMPTY_LAST_CONTENT;
}
CharSequence lastHeader = null;
if (trailer == null) {
trailer = this.trailer = new DefaultLastHttpContent(Unpooled.EMPTY_BUFFER, validateHeaders);//空内容
}
while (line.length() > 0) {//chunk最后可能还有头信息 key: 1\r\n
char firstChar = line.charAtUnsafe(0);
if (lastHeader != null && (firstChar == ' ' || firstChar == '\t')) {
List<String> current = trailer.trailingHeaders().getAll(lastHeader);
if (!current.isEmpty()) {
int lastPos = current.size() - 1;
//please do not make one line from below code
//as it breaks +XX:OptimizeStringConcat optimization
String lineTrimmed = line.toString().trim();
String currentLastPos = current.get(lastPos);
current.set(lastPos, currentLastPos + lineTrimmed);
}
} else {//解析头信息
splitHeader(line);//
CharSequence headerName = name;
if (!HttpHeaderNames.CONTENT_LENGTH.contentEqualsIgnoreCase(headerName) &&
!HttpHeaderNames.TRANSFER_ENCODING.contentEqualsIgnoreCase(headerName) &&
!HttpHeaderNames.TRAILER.contentEqualsIgnoreCase(headerName)) {
trailer.trailingHeaders().add(headerName, value);
}
lastHeader = name;
// reset name and value fields
name = null;
value = null;
}
line = headerParser.parse(buffer);
if (line == null) {
return null;
}
}
this.trailer = null;
return trailer;
}
BAD_MESSAGE无效消息
直接略过后续一起的内容。
case BAD_MESSAGE: {
// Keep discarding until disconnection.
buffer.skipBytes(buffer.readableBytes());//坏消息,直接略过,不读
break;
}
UPGRADED协议切换
其实就是协议的转换。
case UPGRADED: {//协议切换
int readableBytes = buffer.readableBytes();
if (readableBytes > 0) {
out.add(buffer.readBytes(readableBytes));
}
break;
}
resetNow重置属性
每次成功解码操作后都要重新设置属性。
private void resetNow() {
HttpMessage message = this.message;
this.message = null;
name = null;
value = null;
contentLength = Long.MIN_VALUE;
lineParser.reset();
headerParser.reset();
trailer = null;
if (!isDecodingRequest()) {//不是请求解码,如果要升级协议
HttpResponse res = (HttpResponse) message;
if (res != null && isSwitchingToNonHttp1Protocol(res)) {
currentState = State.UPGRADED;
return;
}
}
resetRequested = false;
currentState = State.SKIP_CONTROL_CHARS;
}
至此整个基本完成了HttpRequestDecoder就是他的子类,自己看下就懂了,核心方法都被父类实现了。
给一个只用了HttpRequestDecoder的运行结果。
运行结果
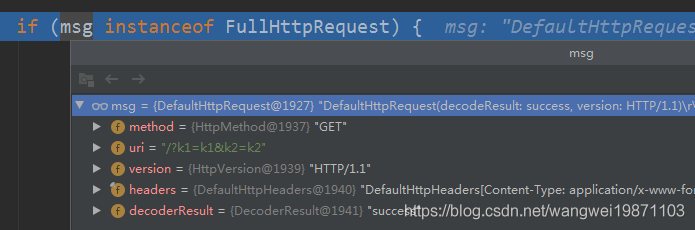
GET
先是DefaultHttpRequest:
然后LastHttpContent中的EMPTY_LAST_CONTENT:

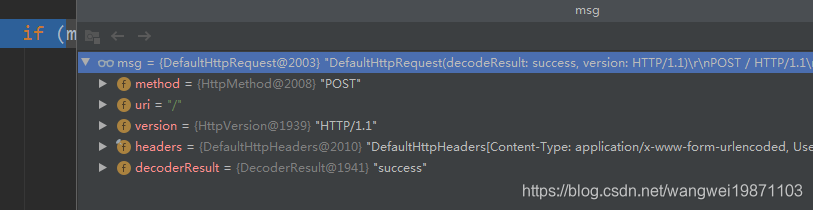
POST
先是DefaultHttpRequest:
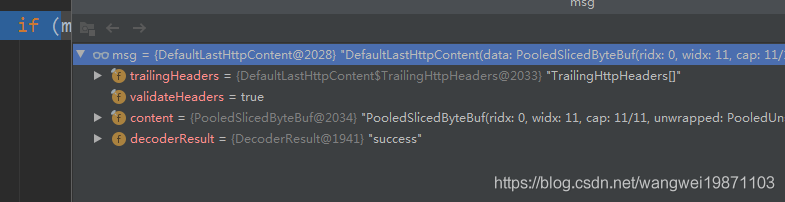
然后是DefaultLastHttpContent:

如果是发送比较大的信息,比如:
那就是可能会出现好几次消息体解析:

当然也可能一次,看接受缓冲区的情况啦:

好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
