本章,我将对 dubbo-cluster 模块中的Router路由机制进行讲解。Router 的主要功能就是根据用户配置的路由规则以及请求携带的信息,过滤出符合条件的 Invoker 集合,供后续负载均衡逻辑使用。
在上一章介绍 RegistryDirectory 的实现时,我们看到了 RouterChain 这个 Router 链的存在,但是没有深入分析,下面我就对 RouterChain 进行分析。
一、RouterChain
1.1 核心字段
RouterChain的核心字段如下:
// RouterChain.java
public class RouterChain<T> {
// 待过滤的 Invoker 集合
private List<Invoker<T>> invokers = Collections.emptyList();
// 真正要使用的 Router 集合
// 不仅包括了上面 builtinRouters 集合中全部的 Router 对象,还包括通过 addRouters() 方法添加的 Router 对象
private volatile List<Router> routers = Collections.emptyList();
// 激活的内置 Router 集合
private List<Router> builtinRouters = Collections.emptyList();
}
在 RouterChain 的构造函数中,会在传入的 URL 参数中查找 router 参数值,并根据该值获取确定激活的 RouterFactory,之后通过 Dubbo SPI 机制加载这些激活的 RouterFactory 对象,由 RouterFactory 创建内置 Router 实例:
// RouterChain.java
private RouterChain(URL url) {
// 通过ExtensionLoader加载激活的RouterFactory
List<RouterFactory> extensionFactories = ExtensionLoader.getExtensionLoader(RouterFactory.class)
.getActivateExtension(url, "router");
// 遍历所有RouterFactory,调用其getRouter()方法创建相应的Router对象
List<Router> routers = extensionFactories.stream()
.map(factory -> factory.getRouter(url))
.collect(Collectors.toList());
// 初始化buildinRouters字段以及routers字段
initWithRouters(routers);
}
public void initWithRouters(List<Router> builtinRouters) {
this.builtinRouters = builtinRouters;
this.routers = new ArrayList<>(builtinRouters);
// 这里会对routers集合进行排序
this.sort();
}
1.2 addRouter方法
完成内置 Router 的初始化之后,在 Directory 实现中还可以通过 addRouter() 方法添加新的 Router 实例到 routers 字段中:
// RouterChain.java
public void addRouters(List<Router> routers) {
List<Router> newRouters = new ArrayList<>();
// 添加builtinRouters集合
newRouters.addAll(builtinRouters);
// 添加传入的Router集合
newRouters.addAll(routers);
// 重新排序
CollectionUtils.sort(newRouters);
this.routers = newRouters;
}
1.3 route方法
RouterChain.route() 方法会遍历 routers 字段,逐个调用 Router 对象的 route() 方法,对 invokers 集合进行过滤,具体实现如下:
// RouterChain.java
public List<Invoker<T>> route(URL url, Invocation invocation) {
List<Invoker<T>> finalInvokers = invokers;
// 遍历全部的Router对象
for (Router router : routers) {
finalInvokers = router.route(finalInvokers, url, invocation);
}
return finalInvokers;
}
二、RouterFactory
了解了 RouterChain 的大致逻辑之后,我们知道 真正进行路由的是 routers 集合中的 Router 对象 。接下来我们再来看 RouterFactory 这个工厂接口, RouterFactory 接口是一个扩展接口 ,具体定义如下:
// RouterFactory.java
@SPI
public interface RouterFactory {
// 动态生成的适配器会根据protocol参数选择扩展实现
@Adaptive("protocol")
Router getRouter(URL url);
}
2.1 继承关系
RouterFactory 接口有很多实现类,如下图所示:
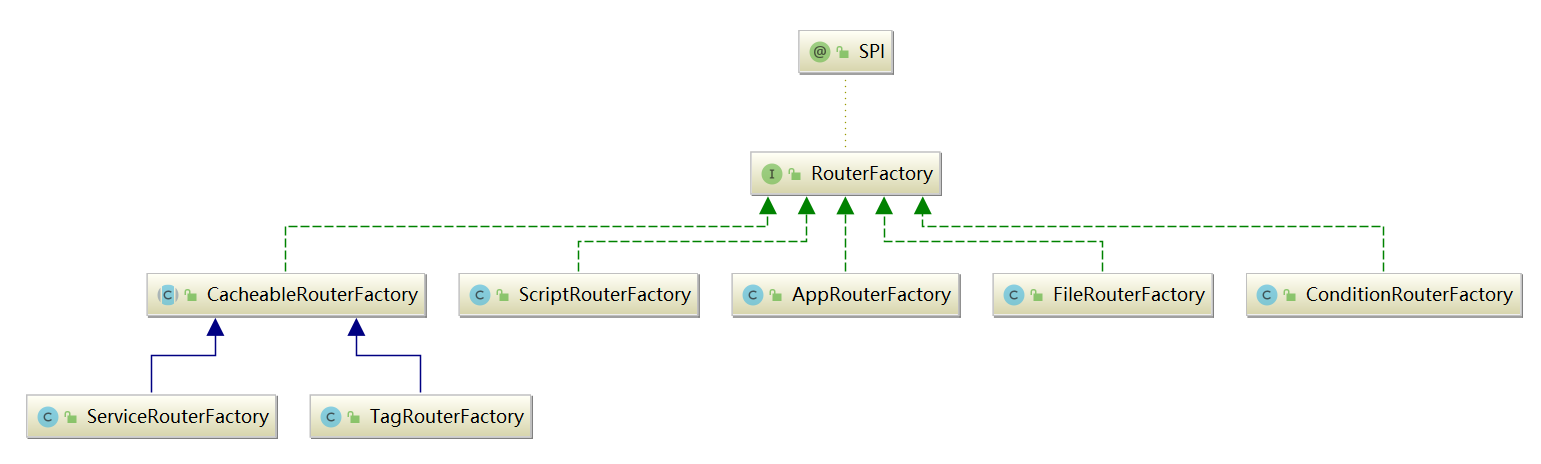
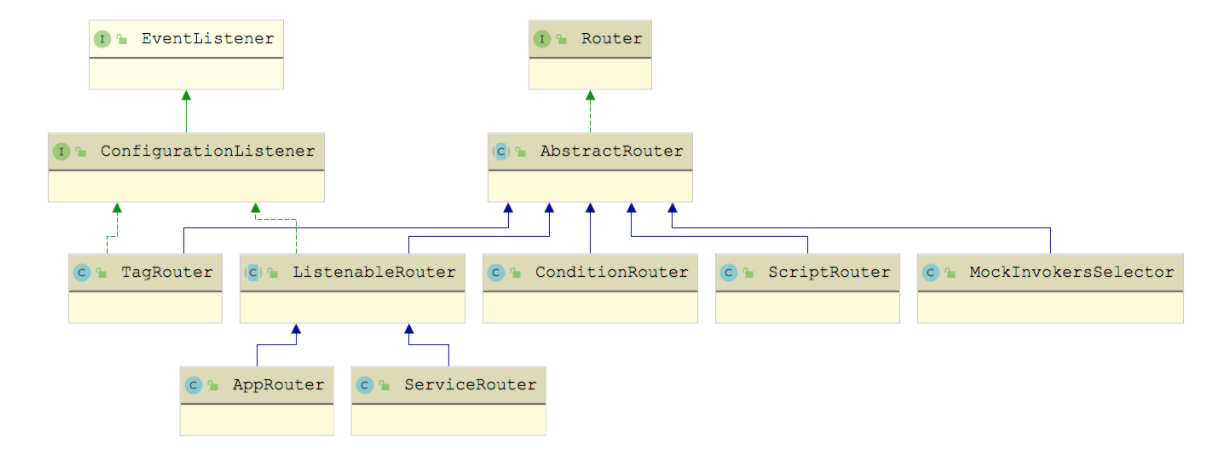
下面我们就来深入介绍下每个 RouterFactory 实现类以及对应的 Router 实现对象。 Router 决定了一次 Dubbo 调用的目标服务,Router 接口的每个实现类代表了一个路由规则 ,当 Consumer 访问 Provider 时,Dubbo 根据路由规则筛选出合适的 Provider 列表,之后通过负载均衡算法再次进行筛选。Router 接口的继承关系如下图所示:
2.2 ConditionRouterFactory
首先来看 ConditionRouterFactory 实现,其扩展名为 condition,在其 getRouter() 方法中会创建 ConditionRouter 对象,如下所示:
// ConditionRouterFactory.java
public class ConditionRouterFactory implements RouterFactory {
public static final String NAME = "condition";
@Override
public Router getRouter(URL url) {
return new ConditionRouter(url);
}
}
ConditionRouter
ConditionRouter 是基于条件表达式的路由实现类 ,下面就是一条基于条件表达式的路由规则:
host = 192.168.0.100 => host = 192.168.0.150
在上述规则中:
=>之前的为 Consumer 匹配的条件,该条件中的所有参数会与 Consumer 的 URL 进行对比,当 Consumer 满足匹配条件时,会对该 Consumer 的此次调用执行=>后面的过滤规则;=>之后为 Provider 地址列表的过滤条件,该条件中的所有参数会和 Provider 的 URL 进行对比,Consumer 最终只拿到过滤后的地址列表。
如果 Consumer 匹配条件为空,表示 => 之后的过滤条件对所有 Consumer 生效 ,例如:=> host != 192.168.0.150,含义是所有Consumer 都不能请求 192.168.0.150 这个 Provider 节点。
如果 Provider 过滤条件为空,表示禁止访问所有 Provider ,例如:host = 192.168.0.100 =>,含义是 192.168.0.100 这个 Consumer 不能访问任何 Provider 节点。
ConditionRouter 的核心字段有如下几个:
- url(URL 类型):路由规则的 URL,可以从 rule 参数中获取具体的路由规则;
- ROUTE_PATTERN(Pattern 类型):用于切分路由规则的正则表达式;
- priority(int 类型):路由规则的优先级,用于排序,该字段值越大,优先级越高,默认值为 0;
- force(boolean 类型):当路由结果为空时,是否强制执行。如果不强制执行,则路由结果为空的路由规则将会自动失效;如果强制执行,则直接返回空的路由结果;
- whenCondition(Map 类型):Consumer 匹配的条件集合,通过解析条件表达式 rule 的
=>之前半部分,可以得到该集合中的内容; - thenCondition(Map 类型):Provider 匹配的条件集合,通过解析条件表达式 rule 的
=>之后半部分,可以得到该集合中的内容。
在 ConditionRouter 的构造方法中,会根据 URL 中携带的相应参数初始化 priority、force、enable 等字段,然后从 URL 的 rule 参数中获取路由规则进行解析,具体的解析逻辑是在 init() 方法中实现的,如下所示:
// ConditionRouter.java
public void init(String rule) {
// 将路由规则中的"consumer."和"provider."字符串清理掉
rule = rule.replace("consumer.", "").replace("provider.", "");
// 按照"=>"字符串进行分割,得到whenRule和thenRule两部分
int i = rule.indexOf("=>");
String whenRule = i < 0 ? null : rule.substring(0, i).trim();
String thenRule = i < 0 ? rule.trim() : rule.substring(i + 2).trim();
// 解析whenRule和thenRule,得到whenCondition和thenCondition两个条件集合
Map<String, MatchPair> when = StringUtils.isBlank(whenRule) || "true".equals(whenRule) ? new HashMap<String, MatchPair>() : parseRule(whenRule);
Map<String, MatchPair> then = StringUtils.isBlank(thenRule) || "false".equals(thenRule) ? null : parseRule(thenRule);
this.whenCondition = when;
this.thenCondition = then;
}
whenCondition 和 thenCondition 两个集合中,Key 是条件表达式中指定的参数名称(例如 host = 192.168.0.150 这个表达式中的 host)。ConditionRouter 支持三类参数:
- 服务调用信息,例如,method、argument 等;
- URL 本身的字段,例如,protocol、host、port 等;
- URL 上的所有参数,例如,application 等。
Value 是 MatchPair 对象,包含两个 Set 类型的集合—— matches 和 mismatches。在 使用 MatchPair 进行过滤 的时候,会按照下面四条规则执行。
- 当 mismatches 集合为空的时候,会逐个遍历 matches 集合中的匹配条件,匹配成功任意一条即会返回 true。这里具体的匹配逻辑以及后续 mismatches 集合中条件的匹配逻辑,都是在 UrlUtils.isMatchGlobPattern() 方法中实现,其中完成了如下操作:如果匹配条件以 "$" 符号开头,则从 URL 中获取相应的参数值进行匹配;当遇到 "" 通配符的时候,会处理""通配符在匹配条件开头、中间以及末尾三种情况;
- 当 matches 集合为空的时候,会逐个遍历 mismatches 集合中的匹配条件,匹配成功任意一条即会返回 false;
- 当 matches 集合和 mismatches 集合同时不为空时,会优先匹配 mismatches 集合中的条件,成功匹配任意一条规则,就会返回 false;若 mismatches 中的条件全部匹配失败,才会开始匹配 matches 集合,成功匹配任意一条规则,就会返回 true;
- 当上述三个步骤都没有成功匹配时,直接返回 false。
上述流程具体实现在 MatchPair 的 isMatch() 方法中,比较简单,这里就不再展示。
了解了每个 MatchPair 的匹配流程之后,我们来看 parseRule() 方法是如何解析一条完整的条件表达式,生成对应 MatchPair 的 ,具体实现如下:
// ConditionRouter.java
private static Map<String, MatchPair> parseRule(String rule) throws ParseException {
Map<String, MatchPair> condition = new HashMap<String, MatchPair>();
MatchPair pair = null;
Set<String> values = null;
// 首先,按照ROUTE_PATTERN指定的正则表达式匹配整个条件表达式
final Matcher matcher = ROUTE_PATTERN.matcher(rule);
while (matcher.find()) { // 遍历匹配的结果
// 每个匹配结果有两部分(分组),第一部分是分隔符,第二部分是内容
String separator = matcher.group(1);
String content = matcher.group(2);
if (StringUtils.isEmpty(separator)) { // ---(1) 没有分隔符,content即为参数名称
pair = new MatchPair();
// 初始化MatchPair对象,并将其与对应的Key(即content)记录到condition集合中
condition.put(content, pair);
}
else if ("&".equals(separator)) { // ---(4)
// &分隔符表示多个表达式,会创建多个MatchPair对象
if (condition.get(content) == null) {
pair = new MatchPair();
condition.put(content, pair);
} else {
pair = condition.get(content);
}
}else if ("=".equals(separator)) { // ---(2)
// =以及!=两个分隔符表示KV的分界线
if (pair == null) {
throw new ParseException("..."");
}
values = pair.matches;
values.add(content);
}else if ("!=".equals(separator)) { // ---(5)
if (pair == null) {
throw new ParseException("...");
}
values = pair.mismatches;
values.add(content);
}else if (",".equals(separator)) { // ---(3)
// 逗号分隔符表示有多个Value值
if (values == null || values.isEmpty()) {
throw new ParseException("...");
}
values.add(content);
} else {
throw new ParseException("...");
}
}
return condition;
}
介绍完 parseRule() 方法的实现之后,我们可以再通过下面这个条件表达式示例的解析流程,更深入地体会 parseRule() 方法的工作原理:
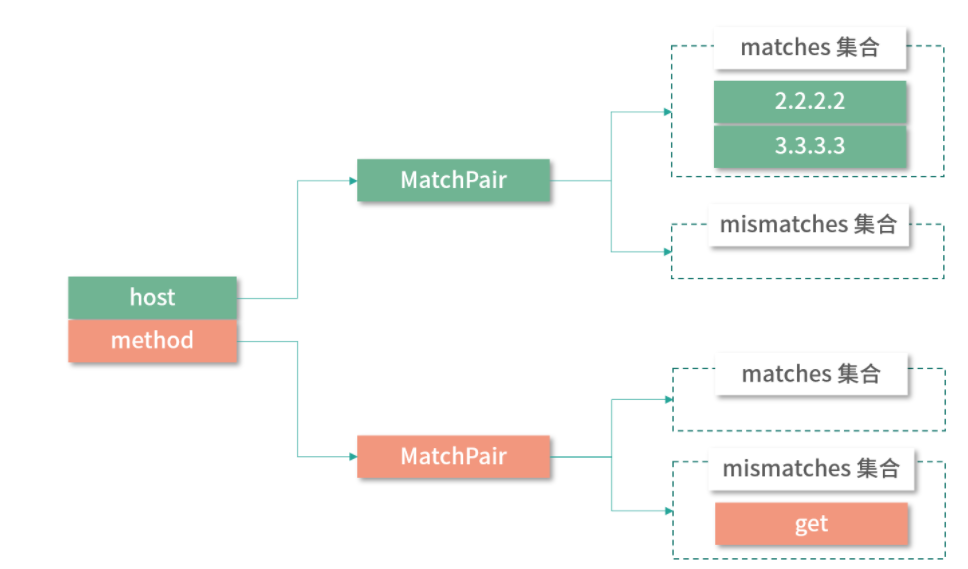
host = 2.2.2.2,1.1.1.1,3.3.3.3 & method !=get => host = 1.2.3.4
经过 ROUTE_PATTERN 正则表达式的分组之后,我们得到如下分组:

我们先来看 => 之前的 Consumer 匹配规则的处理。
- 分组 1 中,separator 为空字符串,content 为 host 字符串。此时会进入上面示例代码展示的 parseRule() 方法中(1)处的分支,创建 MatchPair 对象,并以 host 为 Key 记录到 condition 集合中。
- 分组 2 中,separator 为 "=" 空字符串,content 为 "2.2.2.2" 字符串。处理该分组时,会进入 parseRule() 方法中(2) 处的分支,在 MatchPair 的 matches 集合中添加 "2.2.2.2" 字符串。
- 分组 3 中,separator 为 "," 字符串,content 为 "3.3.3.3" 字符串。处理该分组时,会进入 parseRule() 方法中(3)处的分支,继续向 MatchPair 的 matches 集合中添加 "3.3.3.3" 字符串。
- 分组 4 中,separator 为 "&" 字符串,content 为 "method" 字符串。处理该分组时,会进入 parseRule() 方法中(4)处的分支,创建新的 MatchPair 对象,并以 method 为 Key 记录到 condition 集合中。
- 分组 5 中,separator 为 "!=" 字符串,content 为 "get" 字符串。处理该分组时,会进入 parseRule() 方法中(5)处的分支,向步骤 4 新建的 MatchPair 对象中的 mismatches 集合添加 "get" 字符串。
最后,我们得到的 whenCondition 集合如下图所示:
同理,parseRule() 方法解析上述表达式 => 之后的规则得到的 thenCondition 集合,如下图所示:

了解了 ConditionRouter 解析规则的流程以及 MatchPair 内部的匹配原则之后,ConditionRouter 中最后一个需要介绍的内容就是它的 route() 方法了。
ConditionRouter.route() 方法首先会尝试前面创建的 whenCondition 集合,判断此次发起调用的 Consumer 是否符合表达式中 => 之前的 Consumer 过滤条件,若不符合,直接返回整个 invokers 集合;若符合,则通过 thenCondition 集合对 invokers 集合进行过滤,得到符合 Provider 过滤条件的 Invoker 集合,然后返回给上层调用方。ConditionRouter.route() 方法的核心实现如下:
// ConditionRouter.java
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation)
throws RpcException {
// ...通过enable字段判断当前ConditionRouter对象是否可用
// ...当前invokers集合为空,则直接返回
// 匹配发起请求的Consumer是否符合表达式中=>之前的过滤条件
if (!matchWhen(url, invocation)) {
return invokers;
}
// 判断=>之后是否存在Provider过滤条件,若不存在则直接返回空集合,表示无Provider可用
List<Invoker<T>> result = new ArrayList<Invoker<T>>();
if (thenCondition == null) {
return result;
}
// 逐个判断Invoker是否符合表达式中=>之后的过滤条件
for (Invoker<T> invoker : invokers) {
if (matchThen(invoker.getUrl(), url)) {
// 记录符合条件的Invoker
result.add(invoker);
}
}
if (!result.isEmpty()) {
return result;
} else if (force) {
// 在无Invoker符合条件时,根据force决定是返回空集合还是返回全部Invoker
return result;
}
return invokers;
}
2.3 ScriptRouterFactory
ScriptRouterFactory 的扩展名为 script,其 getRouter() 方法中会创建一个 ScriptRouter 对象并返回:
// ScriptRouterFactory.java
public class ScriptRouterFactory implements RouterFactory {
public static final String NAME = "script";
@Override
public Router getRouter(URL url) {
return new ScriptRouter(url);
}
}
ScriptRouter
ScriptRouter 支持 JDK 脚本引擎的所有脚本 ,例如,JavaScript、JRuby、Groovy 等,通过 type=javascript 参数设置脚本类型,缺省为 javascript。下面我们就定义一个 route() 函数进行 host 过滤:
function route(invokers, invocation, context){
var result = new java.util.ArrayList(invokers.size());
var targetHost = new java.util.ArrayList();
targetHost.add("10.134.108.2");
// 遍历Invoker集合
for (var i = 0; i < invokers.length; i) {
// 判断Invoker的host是否符合条件
if(targetHost.contains(invokers[i].getUrl().getHost())){
result.add(invokers[i]);
}
}
return result;
}
// 立即执行route()函数
route(invokers, invocation, context)
我们可以将上面这段代码进行编码并作为 rule 参数的值添加到 URL 中,在这个 URL 传入 ScriptRouter 的构造函数时,即可被 ScriptRouter 解析。ScriptRouter 的 核心字段 有如下几个:
- url(URL 类型):路由规则的 URL,可以从 rule 参数中获取具体的路由规则。
- priority(int 类型):路由规则的优先级,用于排序,该字段值越大,优先级越高,默认值为 0。
- ENGINES(ConcurrentHashMap 类型):这是一个 static 集合,其中的 Key 是脚本语言的名称,Value 是对应的 ScriptEngine 对象。这里会按照脚本语言的类型复用 ScriptEngine 对象。
- engine(ScriptEngine 类型):当前 ScriptRouter 使用的 ScriptEngine 对象。
- rule(String 类型):当前 ScriptRouter 使用的具体脚本内容。
- function(CompiledScript 类型):根据 rule 这个具体脚本内容编译得到。
在 ScriptRouter 的构造函数中,首先会初始化 url 字段以及 priority 字段(用于排序),然后根据 URL 中的 type 参数初始化 engine、rule 和 function 三个核心字段 ,具体实现如下:
// ScriptRouter.java
public ScriptRouter(URL url) {
this.url = url;
this.priority = url.getParameter(PRIORITY_KEY, SCRIPT_ROUTER_DEFAULT_PRIORITY);
// 根据URL中的type参数值,从ENGINES集合中获取对应的ScriptEngine对象
engine = getEngine(url);
// 获取URL中的rule参数值,即为具体的脚本
rule = getRule(url);
Compilable compilable = (Compilable) engine;
// 编译rule字段中的脚本,得到function字段
function = compilable.compile(rule);
}
接下来看 ScriptRouter 对 route() 方法的实现,其中首先会创建调用 function 函数所需的入参,也就是 Bindings 对象,然后调用 function 函数得到过滤后的 Invoker 集合,最后通过 getRoutedInvokers() 方法整理 Invoker 集合得到最终的返回值:
// ScriptRouter.java
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException {
// 创建Bindings对象作为function函数的入参
Bindings bindings = createBindings(invokers, invocation);
if (function == null) {
return invokers;
}
// 调用function函数,并在getRoutedInvokers()方法中整理得到的Invoker集合
return getRoutedInvokers(function.eval(bindings));
}
private <T> Bindings createBindings(List<Invoker<T>> invokers, Invocation invocation) {
Bindings bindings = engine.createBindings();
// 与前面的javascript的示例脚本结合,我们可以看到这里在Bindings中为脚本中的route()函数提供了invokers、Invocation、context三个参数
bindings.put("invokers", new ArrayList<>(invokers));
bindings.put("invocation", invocation);
bindings.put("context", RpcContext.getContext());
return bindings;
}
2.4 FileRouterFactory
FileRouterFactory 是 ScriptRouterFactory 的装饰器 ,其扩展名为 file,FileRouterFactory 在 ScriptRouterFactory 基础上 增加了读取文件的能力 。我们可以将 ScriptRouter 使用的路由规则保存到文件中,然后在 URL 中指定文件路径,FileRouterFactory 从中解析到该脚本文件的路径并进行读取,调用 ScriptRouterFactory 去创建相应的 ScriptRouter 对象。
下面我们来看 FileRouterFactory 对 getRouter() 方法的具体实现,其中完成了 file 协议的 URL 到 script 协议 URL 的转换,如下是一个转换示例,首先会将 file:// 协议转换成 script:// 协议,然后会添加 type 参数和 rule 参数,其中 type 参数值根据文件后缀名确定,该示例为 js,rule 参数值为文件内容。
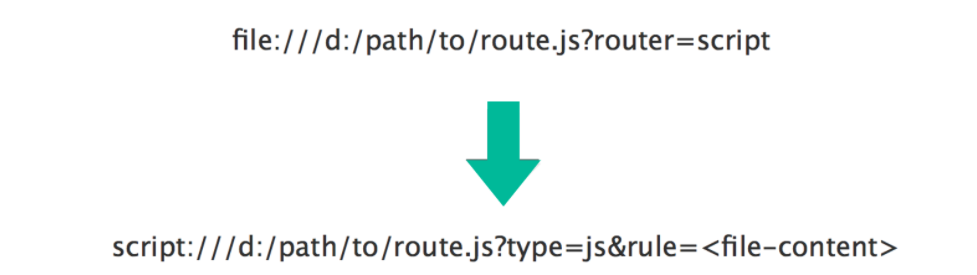
我们可以再结合接下来这个示例分析 getRouter() 方法的具体实现:
// FileRouterFactory.java
public class FileRouterFactory implements RouterFactory {
public static final String NAME = "file";
private RouterFactory routerFactory;
public void setRouterFactory(RouterFactory routerFactory) {
this.routerFactory = routerFactory;
}
@Override
public Router getRouter(URL url) {
try {
// 默认使用script协议
String protocol = url.getParameter(ROUTER_KEY, ScriptRouterFactory.NAME);
String type = null;
String path = url.getPath();
// 获取脚本文件的语言类型
if (path != null) {
int i = path.lastIndexOf('.');
if (i > 0) {
type = path.substring(i + 1);
}
}
// 读取脚本文件中的内容
String rule = IOUtils.read(new FileReader(new File(url.getAbsolutePath())));
// 创建script协议的URL
boolean runtime = url.getParameter(RUNTIME_KEY, false);
URL script = URLBuilder.from(url)
.setProtocol(protocol)
.addParameter(TYPE_KEY, type)
.addParameter(RUNTIME_KEY, runtime)
.addParameterAndEncoded(RULE_KEY, rule)
.build();
// 获取script对应的Router实现
return routerFactory.getRouter(script);
} catch (IOException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
}
2.5 TagRouterFactory
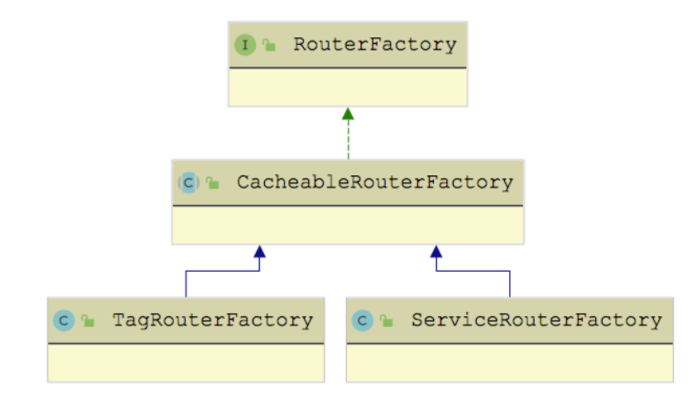
TagRouterFactory 作为 RouterFactory 接口的扩展实现 ,其扩展名为 tag。但是需要注意的是,TagRouterFactory 与 ConditionRouterFactory、ScriptRouterFactory 的不同之处在于:它是 通过继承 CacheableRouterFactory 这个抽象类,间接实现了 RouterFactory 接口 。
// TagRouterFactory.java
@Activate(order = 100)
public class TagRouterFactory extends CacheableRouterFactory {
public static final String NAME = "tag";
@Override
protected Router createRouter(URL url) {
return new TagRouter(url);
}
}
CacheableRouterFactory 抽象类中维护了一个 ConcurrentMap 集合,用来缓存 Router,其中的 Key 是 ServiceKey。在 CacheableRouterFactory 的 getRouter() 方法中,会优先根据 URL 的 ServiceKey 查询 routerMap 集合,查询失败之后会调用 createRouter() 抽象方法来创建相应的 Router 对象。在 TagRouterFactory.createRouter() 方法中,创建的自然就是 TagRouter 对象了。
// CacheableRouterFactory.java
public abstract class CacheableRouterFactory implements RouterFactory {
private ConcurrentMap<String, Router> routerMap = new ConcurrentHashMap<>();
@Override
public Router getRouter(URL url) {
return routerMap.computeIfAbsent(url.getServiceKey(), k -> createRouter(url));
}
protected abstract Router createRouter(URL url);
}
TagRouter
通过 TagRouter,我们可以将某一个或多个 Provider 划分到同一分组,约束流量只在指定分组中流转,这样就可以轻松达到流量隔离的目的,从而支持灰度发布等场景。
目前,Dubbo 提供了动态和静态两种方式给 Provider 打标签,其中动态方式就是通过服务治理平台动态下发标签,静态方式就是在 XML 等静态配置中打标签。Consumer 端可以在 RpcContext 的 attachment 中添加 request.tag 附加属性,注意 保存在 attachment 中的值将会在一次完整的远程调用中持续传递 ,我们只需要在起始调用时进行设置,就可以达到标签的持续传递。
了解了 Tag 的基本概念和功能之后,我再简单介绍一个 Tag 的使用示例。
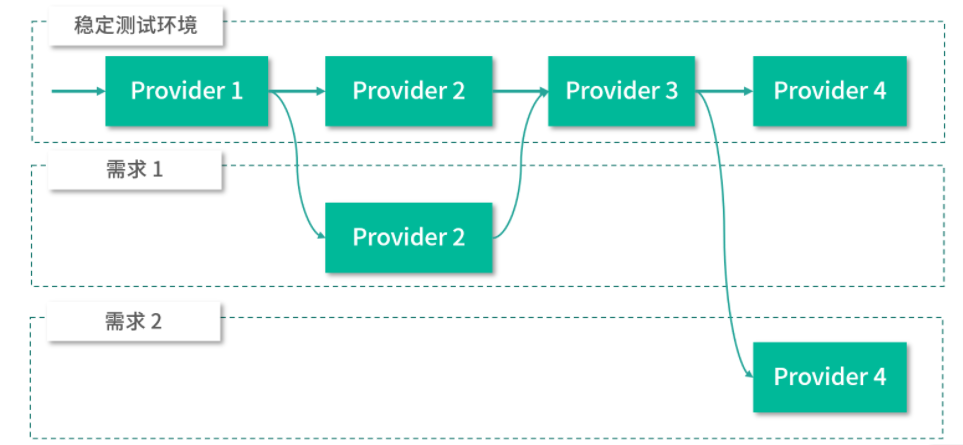
在实际的开发测试中,一个完整的请求会涉及非常多的 Provider,分属不同团队进行维护,这些团队每天都会处理不同的需求,并在其负责的 Provider 服务中进行修改,如果所有团队都使用一套测试环境,那么测试环境就会变得很不稳定。如下图所示,4 个 Provider 分属不同的团队管理,Provider 2 和 Provider 4 在测试环境测试,部署了有 Bug 的版本,这样就会导致整个测试环境无法正常处理请求,在这样一个不稳定的测试环境中排查 Bug 是非常困难的,因为可能排查到最后,发现是别人的 Bug。

为了解决上述问题,我们可以针对每个需求分别独立出一套测试环境,但是这个方案会占用大量机器,前期的搭建成本以及后续的维护成本也都非常高。
下面是一个通过 Tag 方式实现环境隔离的架构图,其中,需求 1 对 Provider 2 的请求会全部落到有需求 1 标签的 Provider 上,其他 Provider 使用稳定测试环境中的 Provider;需求 2 对 Provider 4 的请求会全部落到有需求 2 标签的 Provider 4 上,其他 Provider 使用稳定测试环境中的 Provider。
在一些特殊场景中,会有 Tag 降级的场景,比如找不到对应 Tag 的 Provider,会按照一定的规则进行降级。如果在 Provider 集群中不存在与请求 Tag 对应的 Provider 节点,则默认将降级请求 Tag 为空的 Provider;如果希望在找不到匹配 Tag 的 Provider 节点时抛出异常的话,我们需设置 request.tag.force = true。
如果请求中的 request.tag 未设置,只会匹配 Tag 为空的 Provider,也就是说即使集群中存在可用的服务,若 Tag 不匹配也就无法调用。一句话总结, 携带 Tag 的请求可以降级访问到无 Tag 的 Provider,但不携带 Tag 的请求永远无法访问到带有 Tag 的 Provider 。
下面我们再来看 TagRouter 的具体实现。在 TagRouter 中持有一个 TagRouterRule 对象的引用,在 TagRouterRule 中维护了一个 Tag 集合,而在每个 Tag 对象中又都维护了一个 Tag 的名称,以及 Tag 绑定的网络地址集合,如下图所示:
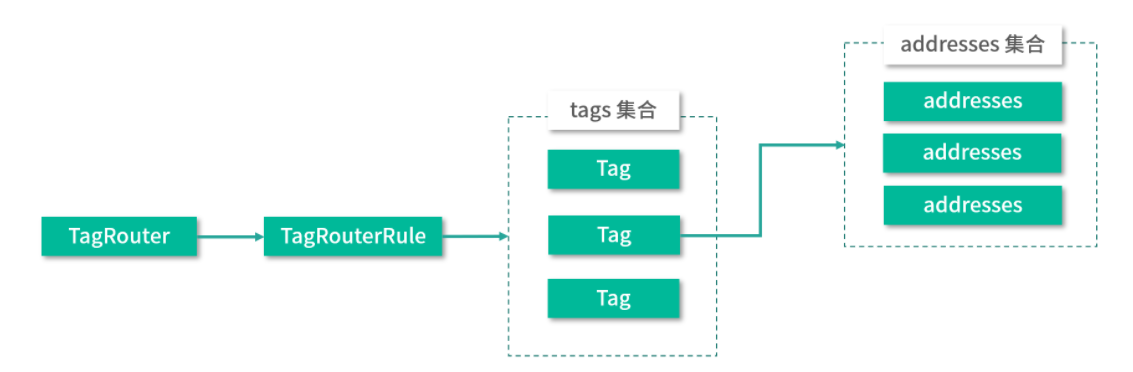
另外,在 TagRouterRule 中还维护了 addressToTagnames、tagnameToAddresses 两个集合(都是 Map `> 类型),分别记录了 Tag 名称到各个 address 的映射以及 address 到 Tag 名称的映射。在 TagRouterRule 的 init() 方法中,会根据 tags 集合初始化这两个集合。
了解了 TagRouterRule 的基本构造之后,我们继续来看 TagRouter 构造 TagRouterRule 的过程。TagRouter 除了实现了 Router 接口之外,还实现了 ConfigurationListener 接口,如下图所示:
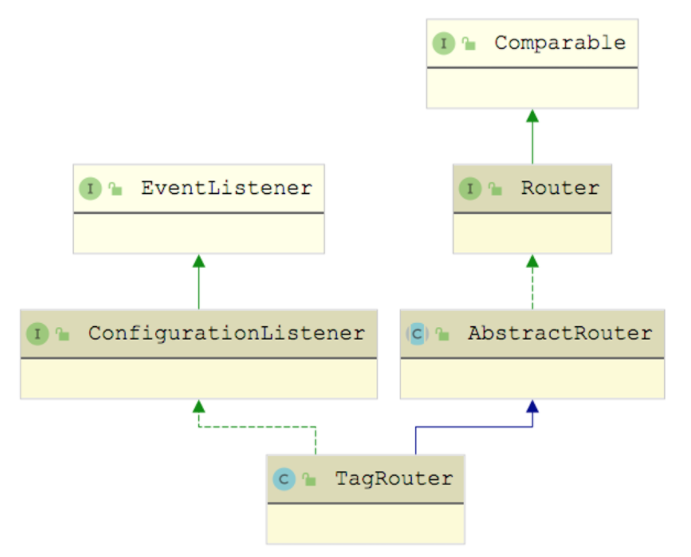
ConfigurationListener 用于监听配置的变化,其中就包括 TagRouterRule 配置的变更 。当我们通过动态更新 TagRouterRule 配置的时候,就会触发 ConfigurationListener 接口的 process() 方法,TagRouter 对 process() 方法的实现如下:
// TagRouter.java
public synchronized void process(ConfigChangedEvent event) {
// DELETED事件会直接清空tagRouterRule
if (event.getChangeType().equals(ConfigChangeType.DELETED)) {
this.tagRouterRule = null;
}
// 其他事件会解析最新的路由规则,并记录到tagRouterRule字段中
else {
this.tagRouterRule = TagRuleParser.parse(event.getContent());
}
}
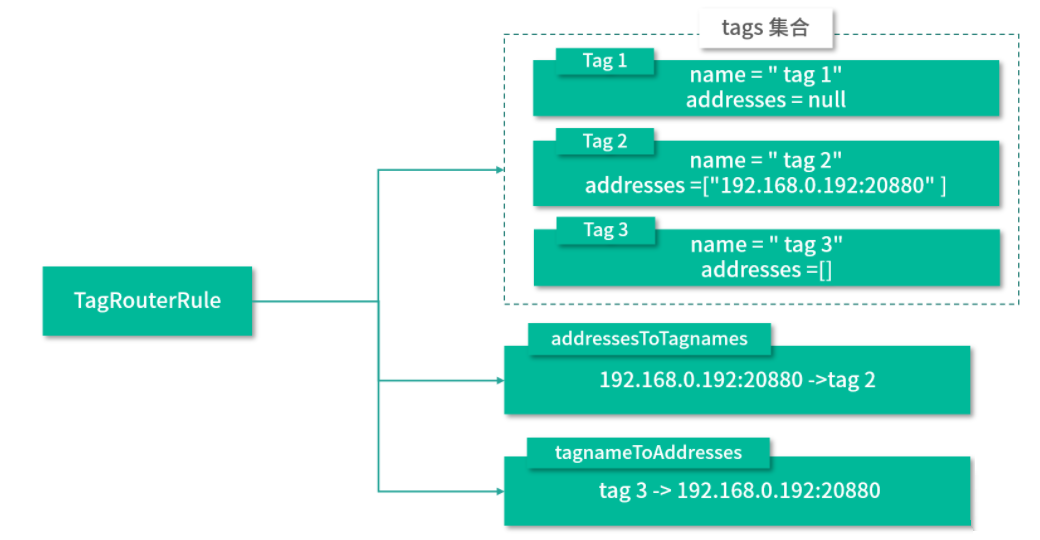
我们可以看到,如果是删除配置的操作,则直接将 tagRouterRule 设置为 null,如果是修改或新增配置,则通过 TagRuleParser 解析传入的配置,得到对应的 TagRouterRule 对象。TagRuleParser 可以解析 yaml 格式的 TagRouterRule 配置,下面是一个配置示例:
force: false
runtime: true
enabled: false
priority: 1
key: demo-provider
tags:
- name: tag1
addresses: null
- name: tag2
addresses: ["30.5.120.37:20880"]
- name: tag3
addresses: []
经过 TagRuleParser 解析得到的 TagRouterRule 结构,如下所示:
除了上图展示的几个集合字段,TagRouterRule 还从 AbstractRouterRule 抽象类继承了一些控制字段,后面介绍的 ConditionRouterRule 也继承了 AbstractRouterRule。
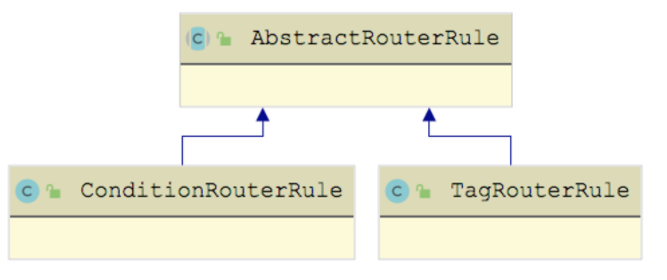
AbstractRouterRule 中核心字段的具体含义大致可总结为如下。
- key(string 类型)、scope(string 类型):key 明确规则体作用在哪个服务或应用。scope 为 service 时,key 由 [{group}:]{service}[:{version}] 构成;scope 为 application 时,key 为 application 的名称。
- rawRule(string 类型):记录了路由规则解析前的原始字符串配置。
- runtime(boolean 类型):表示是否在每次调用时执行该路由规则。如果设置为 false,则会在 Provider 列表变更时预先执行并缓存结果,调用时直接从缓存中获取路由结果。
- force(boolean 类型):当路由结果为空时,是否强制执行,如果不强制执行,路由结果为空的路由规则将自动失效。该字段默认值为 false。
- valid(boolean 类型):用于标识解析生成当前 RouterRule 对象的配置是否合法。
- enabled(boolean 类型):标识当前路由规则是否生效。
- priority(int 类型):用于表示当前 RouterRule 的优先级。
- dynamic(boolean 类型):表示该路由规则是否为持久数据,当注册方退出时,路由规则是否依然存在。
我们可以看到,AbstractRouterRule 中的核心字段与前面的示例配置是一一对应的。
我们知道,Router 最终目的是要过滤符合条件的 Invoker 对象,下面我们一起来看 TagRouter 是如何使用 TagRouterRule 路由逻辑进行 Invoker 过滤的,大致步骤如下。
-
如果 invokers 为空,直接返回空集合。
-
检查关联的 tagRouterRule 对象是否可用,如果不可用,则会直接调用 filterUsingStaticTag() 方法进行过滤,并返回过滤结果。在 filterUsingStaticTag() 方法中,会比较请求携带的 tag 值与 Provider URL 中的 tag 参数值。
-
获取此次调用的 tag 信息,这里会尝试从 Invocation 以及 URL 的参数中获取。
-
如果
此次请求指定了 tag 信息
,则首先会获取 tag 关联的 address 集合。
- 如果 address 集合不为空,则根据该 address 集合中的地址,匹配出符合条件的 Invoker 集合。如果存在符合条件的 Invoker,则直接将过滤得到的 Invoker 集合返回;如果不存在,就会根据 force 配置决定是否返回空 Invoker 集合。
- 如果 address 集合为空,则会将请求携带的 tag 值与 Provider URL 中的 tag 参数值进行比较,匹配出符合条件的 Invoker 集合。如果存在符合条件的 Invoker,则直接将过滤得到的 Invoker 集合返回;如果不存在,就会根据 force 配置决定是否返回空 Invoker 集合。
- 如果 force 配置为 false,且符合条件的 Invoker 集合为空,则返回所有不包含任何 tag 的 Provider 列表。
-
如果 此次请求未携带 tag 信息 ,则会先获取 TagRouterRule 规则中全部 tag 关联的 address 集合。如果 address 集合不为空,则过滤出不在 address 集合中的 Invoker 并添加到结果集合中,最后,将 Provider URL 中的 tag 值与 TagRouterRule 中的 tag 名称进行比较,得到最终的 Invoker 集合。
上述流程的具体实现是在 TagRouter.route() 方法中,如下所示:
// TagRouter.java
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException {
//... 如果invokers为空,直接返回空集合(略)
final TagRouterRule tagRouterRuleCopy = tagRouterRule;
if (tagRouterRuleCopy == null || !tagRouterRuleCopy.isValid() || !tagRouterRuleCopy.isEnabled()) {
return filterUsingStaticTag(invokers, url, invocation);
}
// 检查关联的tagRouterRule对象是否可用,如果不可用,则会直接调用filterUsingStaticTag() 方法进行过滤
List<Invoker<T>> result = invokers;
// 获取此次调用的tag信息,尝试从Invocation以及URL中获取
String tag = StringUtils.isEmpty(invocation.getAttachment(TAG_KEY)) ? url.getParameter(TAG_KEY) :
invocation.getAttachment(TAG_KEY);
if (StringUtils.isNotEmpty(tag)) { // 此次请求一个特殊的tag
// 获取tag关联的address集合
List<String> addresses = tagRouterRuleCopy.getTagnameToAddresses().get(tag);
if (CollectionUtils.isNotEmpty(addresses)) {
// 根据上面的address集合匹配符合条件的Invoker
result = filterInvoker(invokers, invoker -> addressMatches(invoker.getUrl(), addresses));
// 如果存在符合条件的Invoker,则直接将过滤得到的Invoker集合返回
// 如果不存在符合条件的Invoker,根据force配置决定是否返回空Invoker集合
if (CollectionUtils.isNotEmpty(result) || tagRouterRuleCopy.isForce()) {
return result;
}
} else {
// 如果 address 集合为空,则会将请求携带的 tag 与 Provider URL 中的 tag 参数值进行比较,匹配出符合条件的 Invoker 集合。
result = filterInvoker(invokers, invoker -> tag.equals(invoker.getUrl().getParameter(TAG_KEY)));
}
if (CollectionUtils.isNotEmpty(result) || isForceUseTag(invocation)) {
return result; // 存在符合条件的Invoker或是force配置为true
}else { // 如果 force 配置为 false,且符合条件的 Invoker 集合为空,则返回所有不包含任何 tag 的 Provider 列表。
List<Invoker<T>> tmp = filterInvoker(invokers, invoker -> addressNotMatches(invoker.getUrl(),
tagRouterRuleCopy.getAddresses()));
return filterInvoker(tmp, invoker -> StringUtils.isEmpty(invoker.getUrl().getParameter(TAG_KEY)));
}
} else {
// 如果此次请求未携带 tag 信息,则会先获取 TagRouterRule 规则中全部 tag 关联的 address 集合。
List<String> addresses = tagRouterRuleCopy.getAddresses();
if (CollectionUtils.isNotEmpty(addresses)) {
// 如果 address 集合不为空,则过滤出不在 address 集合中的 Invoker 并添加到结果集合中。
result = filterInvoker(invokers, invoker -> addressNotMatches(invoker.getUrl(), addresses));
if (CollectionUtils.isEmpty(result)) {
return result;
}
}
// 如果不存在符合条件的 Invoker 或是 address 集合为空,则会将请求携带的 tag 与 Provider URL 中的 tag 参数值进行比较,得到最终的 Invoker 集合。
return filterInvoker(result, invoker -> {
String localTag = invoker.getUrl().getParameter(TAG_KEY);
return StringUtils.isEmpty(localTag) || !tagRouterRuleCopy.getTagNames().contains(localTag);
});
}
}
2.6 ServiceRouterFactory
除了前文介绍的 TagRouterFactory 继承了 CacheableRouterFactory 之外, ServiceRouterFactory 也继承 CachabelRouterFactory,具有了缓存的能力 ,具体继承关系如下图所示:
// ServiceRouterFactory.java
@Activate(order = 300)
public class ServiceRouterFactory extends CacheableRouterFactory {
public static final String NAME = "service";
@Override
protected Router createRouter(URL url) {
return new ServiceRouter(url);
}
}
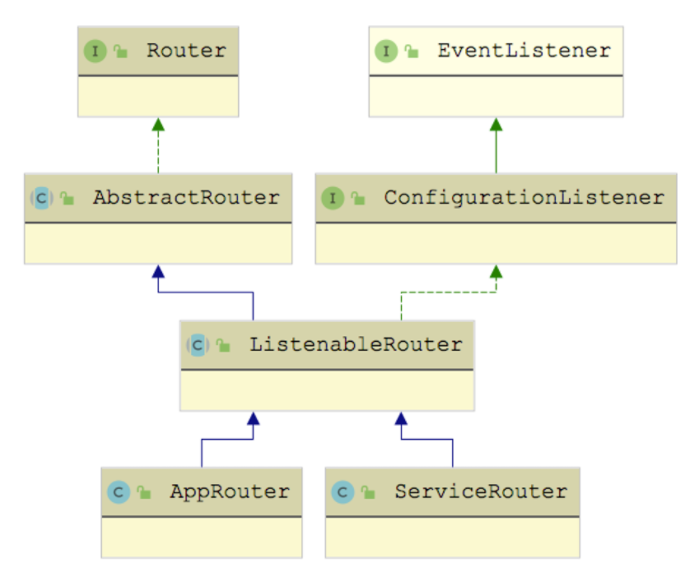
ServiceRouterFactory 创建的是 ServiceRouter,与 ServiceRouter 类似的是 AppRouter, 两者都继承了 ListenableRouter 抽象类 (虽然 ListenableRouter 是个抽象类,但是没有抽象方法留给子类实现),继承关系如下图所示:
ListenableRouter
ListenableRouter 在 ConditionRouter 基础上添加了动态配置的能力 ,ListenableRouter 的 process() 方法与 TagRouter 中的 process() 方法类似:
- 对于
ConfigChangedEvent.DELETE事件,直接清空 ListenableRouter 中维护的 ConditionRouterRule 和 ConditionRouter 集合的引用; - 对于
ADDED、UPDATED事件,则通过 ConditionRuleParser 解析事件内容,得到相应的 ConditionRouterRule 对象和 ConditionRouter 集合。
这里的 ConditionRuleParser 同样是以 yaml 文件的格式解析 ConditionRouterRule 的相关配置。ConditionRouterRule 中维护了一个 conditions 集合(List<String> 类型),记录了多个 Condition 路由规则,对应生成多个 ConditionRouter 对象。
整个解析 ConditionRouterRule 的过程,与前文介绍的解析 TagRouterRule 的流程类似,这里不再赘述。
在 ListenableRouter 的 route() 方法中,会遍历全部 ConditionRouter 过滤出符合全部路由条件的 Invoker 集合,具体实现如下:
// ListenableRouter.java
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException {
if (CollectionUtils.isEmpty(invokers) || conditionRouters.size() == 0) {
return invokers; // 检查边界条件,直接返回invokers集合
}
for (Router router : conditionRouters) { // 路由规则进行过滤
invokers = router.route(invokers, url, invocation);
}
return invokers;
}
ServiceRouter 和 AppRouter 都是简单地继承了 ListenableRouter 抽象类,且没有覆盖 ListenableRouter 的任何方法,两者只有以下两点区别。
- 一个是 priority 字段值不同 。ServiceRouter 为 140,AppRouter 为 150,也就是说 ServiceRouter 要先于 AppRouter 执行。
- 另一个是获取 ConditionRouterRule 配置的 Key 不同 。ServiceRouter 使用的 RuleKey 是由 {interface}:[version]:[group] 三部分构成,获取的是一个服务对应的 ConditionRouterRule。AppRouter 使用的 RuleKey 是 URL 中的 application 参数值,获取的是一个服务实例对应的 ConditionRouterRule。
三、总结
本章,我重点介绍了 Router 接口的相关内容。首先我介绍了 RouterChain 的核心实现以及构建过程,然后讲解了 RouterFactory 接口和 Router 接口中核心方法的功能。最后,我对RouterFactory的所有默认实现进行了分析。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
