讲解完了Kafka的各个组件的核心工作原理,接下来的章节我会通过一个实际生产案例介绍Kafka的使用,我们先来看下整个案例的背景。
一、案例背景
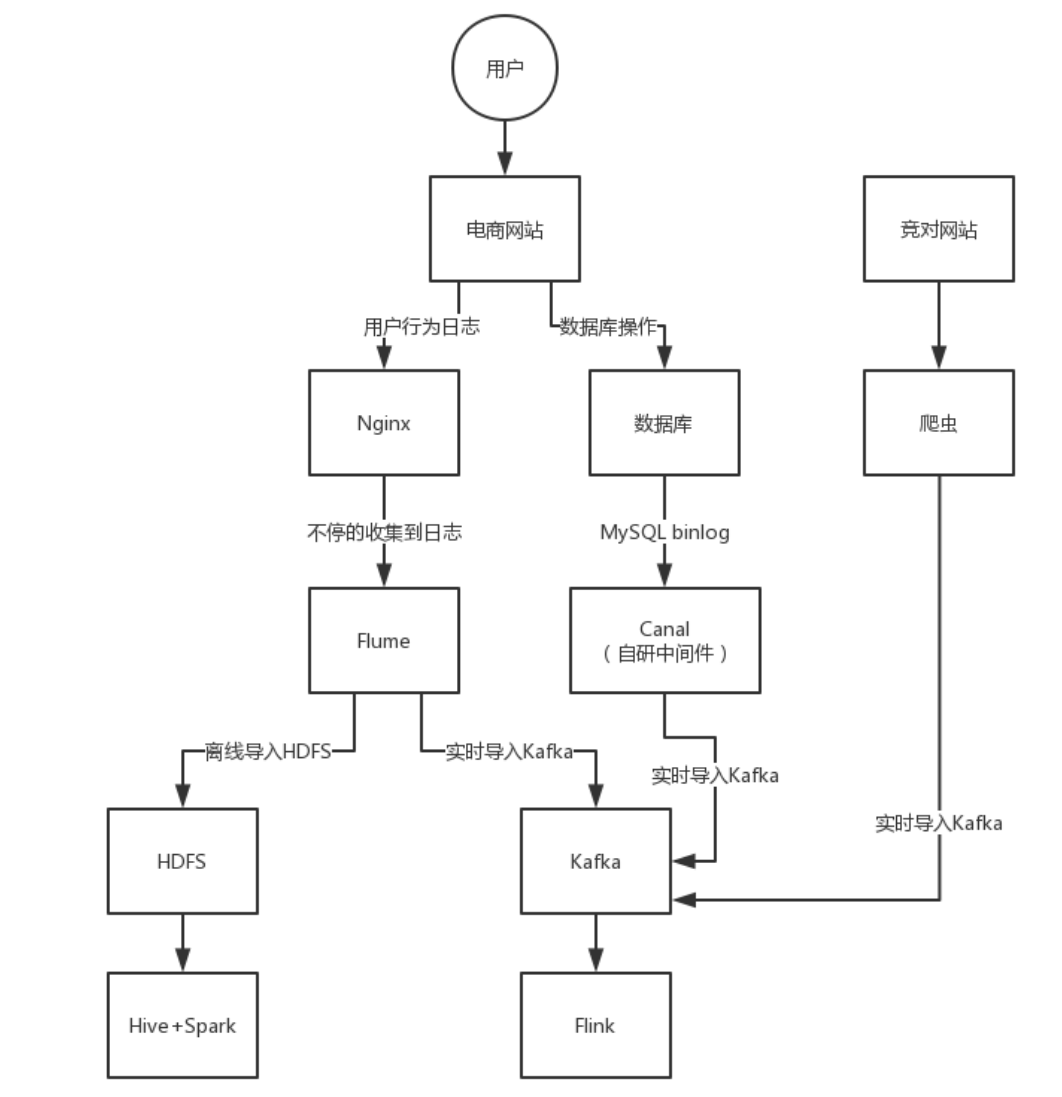
我们生产环境运行着一个中小型的电商平台,假设用户量为1000W,我们需要通过Kafka来对各类数据进行采集,那么问题来了,1000W的用户量每天会生成多大的数据呢?数据量的评估对Kafka的部署至关重要。
这种中小型电商网站,每天的数据来源主要有三部分构成:
- 用户行为日志;
- 业务数据;
- 竞品数据。
1.1 用户行为日志
日志数据很好理解,就是用户访问我们的网站时,系统记录的各种各样的日志,这些日志记录了用户的行为,比如搜索商品、浏览详情页、下单、评价……电商网站最核心的链路:搜索、筛选、详情页、购物车、下单、支付、评价。
那么,对于一个有着1000万注册用户的电商网站,每天会产生多少日志数据呢?我们来估算下:
假设日活用户300W,每个用户每天浏览网站共有100次行为操作(这已经算是比较高的了),那么总共的用户行为日志就是3亿/天。
1.2 业务数据
电商网站有大量的表,假设有100张表,每张表每天都涉及大量的数据库增删改操作,每次增删改就算一条数据变更记录。那么,假设一笔订单涉及5次增删改操作,一天50w订单,就有250w次操作,100张表大约就算2亿次操作。
所以,数据库每天最终会有2亿条的变更记录。
1.3 竞品数据
电商网站一般都会用爬虫抓竞争对手网站的商品数据。假设有三个同类的竞争对手网站,每个网站的商品数量在100万左右,那么每天爬虫就需要爬300万条数据。由于每个商品每天的信息在不停变化,所以爬虫可能需要不停地抓取对方网站的数据,假设每隔10分钟抓取一次,那么每个商品一天要抓取60 / 10 * 24 ≈ 150次,300万商品就是5亿数据。
总结,经过上面的分析,对于一个1000W用户的电商网站,每天大约会产生3+2+5=10亿的数据。这些数据经过Kafka的采集,可以用来做用户行为分析、网站运营分析、竞争对手分析,协助网站的产品经理、运营人员、企业高层把控网站运营状况,以此做出对应决策。
我上面的这些分析只是一个经验预估,实际生产环境,我们需要以压测产生的实际数据为准进行评估。
二、集群规划
经过上面的背景介绍,我们再来看下在这种每日10亿数据量的场景下,Kafka会有哪些性能问题?我们生产环境的Kafka集群应该如何来规划和部署?
2.1 峰值并发量
先来计算下峰值并发量,对于一个电商平台来说,大部分流量来自每日8:00- 24:00这16个小时内,根据2/8定理——80%的交易发生在20%的时间,所以峰值流量估算如下:
1000000000 * 0.8 / (16 * 0.2 * 60 * 60) = 69444
也就是说,日数据量达到10亿时,每日的峰值QPS可能达到6W, Kafka集群需要能抗住高峰期的6万QPS 。
一般来说,在公司预算充足的情况下,会尽量控制高峰QPS占集群总QPS的30%左右,也就是说假设峰值QPS是6W,那么集群的总QPS达到20W是一个比较安全的水平。
笔者17年的时候,曾经与支付宝、微信、京东金融等第三方支付机构搞过双11联合压测演练,当时我们的快捷支付子系统做改造,作为上游应用,预期是能抗住这些机构每秒1万TPS(注意,这里是TPS)的交易,但是出于安全性考虑,实际压测是要达到总TPS的30%的目标,也就是抗住4万左右TPS。
2.2 数据量
Kafka集群默认保留最近7天的数据。 那么, 每天10亿数据,假设每个Topic的分区有2个副本,那么每天Kafka在磁盘上需要保留10亿 * 2 = 20亿数据,7天一共140亿数据。
假设每条数据1kb,140亿条数据大约就是12TB,也就是说 整个Kafka集群的磁盘空间至少需要容纳12TB的数据 。
事实上,很多MySql同步的binlog日志是到不了1kb的,也就几十字节,几百个字节;用户行为日志,也不一定有1kb/条,所以具体还是看你们公司采集的数据,根据线上的运行情况估算一下平均每条数据有多大。
2.3 机器配置
接着,我们继续看具体到机器配置该如何选型,其实无非就是从内存、CPU、硬盘、网卡等方面考量。单台物理机部署Kafka,抗个3万到4万QPS没啥问题,所以20万QPS大概要5台物理机。
内存
Kafka集群部署时,对内存的规划是很有讲究的,它大量用到了内存映射和零拷贝,写数据基本上优先让数据写入OS Cache,消费时也优先从OS Cache里读取。虽然Kafka Broker本身采用Scala语言开发,基于JVM,但事实上Kafka并没有在JVM堆内存里放入过多的数据,所以不需要给Kafka Jvm堆内存分配太大的空间,基本上5G就够了。
所以,部署Kafka集群的机器,应该 重点考虑给机器的OS Cache分配较大的空间 ,这块空间越大,能够缓存的数据就越多。那么到底应该分配多大的内存空间呢?
我们已经知道,Kafka的日志文件是以分区(Partition)为维度划分的,且每个分区的日志文件是分段的,读写基本都是针对最新的那个分段日志,所以 最理想情况是让每个分区的最新分段日志都能够缓存在OS Cache中 。
假设集群一共有100个Topic,每个Topic有6个Partition,读写都是针对Leader Partition的,总共就是100 * 6 = 600个Leader Partition,平均到6台机器上去,每台机器100个Partition,每个Partition的最新分段日志文件大小默认是1GB,所以单台机器上,最新分段日志文件总大小是100G。
所以说,理想情况下,单台机器如果有100GB内存给OS Cache的话,该机器上的所有Partition的最新分段日志数据都可以缓存到OS Cache里了。一般来说,一个1G的分段日志大约能存储几千万条消息,但 消费比较频繁的一般也就是最新的10%的数据,所以基本只要保证最新写入的10%的数据驻留在内存中就可以了 。
总结一下,Kafka的机器对内存要求较高,内存容量一般根据总分区数计算,保证一台机器上所有分区的最新分段日志文件的前10%数据能够被缓存,以100个Topic,每个Topic6个分区计算,6台机器每台大约需要100 * 6/6 * 1 * 10% = 10G。所以 生产环境的Kafka机器,一般都会用16G以上内存(JVM分配一部分内存) 。
CPU
再来看下CPU规划,这个主要就是看Kafka Broker进程里会有多少个线程。如果线程特别多,但是CPU核很少,就会导致机器的CPU负载很高,整体工作线程的执行效率不高。
Kafka Broker后台一般都会有几百个线程运行,比如Acceptor线程、Processor线程(默认3个)、Handler线程(默认8个),日志清理线程等等。所以4核肯定是不行的,一般建议生产环境16核以上。
网卡
网卡这块的话,现在一般就是在 千兆网卡(1GB / s) 和万兆网卡(10GB / s)之间选择,主要考虑数据传输量的大小。
高峰期每秒6万QPS,也就是60mb/s的数据量,同时Kafka Broker之间会进行数据同步,所以多估算一些,假设按照5倍估算,每秒大概传输300mb左右的数据,所以千兆网卡基本足够了。
硬盘
硬盘主要是考虑两方面:容量和类型。
类型的话,主要就是SSD固态硬盘和机械硬盘的选型,SSD快在磁盘的随机读写,所以对于MySQL集群这类系统,用SSD可以大幅提升读写性能。但是,对于Kafka来说是否必要呢?Kafka采用的是顺序写日志,机械硬盘的顺序写性能和SSD是差不多的,除非你的公司真不差钱,否则 用机械硬盘就可以了 。
容量的话,看给Kafka集群分配多少台机器,假设总数据量是12TB,分6台物理机,那么每台2TB的硬盘容量就够了。
综上所述,在峰值请求6万QPS,日数据量12TB的场景下,可以这样用5台物理机搭建Kafka集群,每台机器的配置如下:
- 硬盘:2块1-2TB的机械硬盘,7200转;
- 内存:16GB,JVM分配6G,剩余的给OS Cache;
- CPU:16核
- 网络:千兆网卡
三、参数配置
Kafka集群规划完成后,还需要对机器进行一些基本的调优。OS层面的东西就不赘述了,一般由公司运维人员进行调优并分配机器,主要来看下Kafka自身的一些参数设置。
broker.id
这个是每个broker的唯一id。
log.dirs
Kafka的所有数据写入到这个目录下的硬盘文件中,可以设置多个目录,这样Kafka可以将数据分散到多块硬盘,提升吞吐量。
zookeeper.connect
Zookeeper集群地址。
listeners
Broker监听客户端发起请求的端口号。
unclean.leader.election.enable
是否允许OSR列表中的Follower选举为新的Leader,1.0版本后的默认值为false。
delete.topic.enable
是否允许删除Topic,默认值为true。
log.retention.hours
日志保留时间,默认7天。
log.retention.bytes
分区的数据量如果超过了该值,就会自动清理数据,默认值-1,表示不按照这个策略来清理。这个参数一般不常用。
min.insync.replicas
写入消息时,要求ISR列表中至少有几个节点才能写入成功,一般与acks = -1配合起来使用。
num.network.threads
负责转发请求给Woker线程的网络请求处理线程的数量,默认值是3,高负载场景下可以设置大一些。
num.io.threads
实际处理请求的线程数量,默认值是8,高负载场景下可以设置大一些。
message.max.bytes
Broker能接受的最大消息大小,默认是977kb,生产一般会设置大一些,比如10mb。
log.flush.interval.messages
每次刷盘时的消息数量
log.flush.interval.ms
刷盘间隔
JVM参数
Kafka的JVM配置是在启动脚本中bin/kafka-start-server.sh。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
