在 Kafka 集群中,会有一个或多个 Broker,那么Kafka是如何管理这些Broker的呢?
从本章开始,我将讲解Kafka的 集群管理 ,这块内容本质属于 Replication Subsystem ,但是又相对独立,所以我单独拎出来讲解。
Kafka集群会选举一个Broker作为控制器( Kafka Controller ),由它来负责管理整个集群中的所有分区和副本的状态:
- 当某个分区的 Leader 副本出现故障时,由Controller负责为该分区选举新的 Leader 副本;
- 当检测到某个分区的 ISR 集合发生变化时,由Controller负责通知所有 Broker 更新其元数据信息;
- 当为某个 Topic 增加分区数量时,同样还是由Controller负责分区的重新分配。
我们先从各个Broker启动后,Controller的选举开始。
一、Controller选举
每个Broker启动后,都会创建两个与集群管理相关的重要组件: KafkaController 和 KafkaHealthcheck ,通过这两个组件,Broker集群会完成Controller的选举:
// KafkaServer.scala
class KafkaServer(val config: KafkaConfig, time: Time = Time.SYSTEM, threadNamePrefix: Option[String] = None, kafkaMetricsReporters: Seq[KafkaMetricsReporter] = List()) extends Logging with KafkaMetricsGroup {
var kafkaController: KafkaController = null
var kafkaHealthcheck: KafkaHealthcheck = null
def startup() {
try {
info("starting")
//...
// 启动KafkaController
kafkaController = new KafkaController(config, zkUtils, brokerState, time, metrics, threadNamePrefix)
kafkaController.startup()
// 启动KafkaHealthcheck
kafkaHealthcheck = new KafkaHealthcheck(config.brokerId, listeners, zkUtils, config.rack,
config.interBrokerProtocolVersion)
kafkaHealthcheck.startup()
//...
}
catch {
//...
}
}
}
1.1 初始化
KafkaController
我们先来看KafkaController的创建和初始化:
- 首先注册了一个Zookeeper监听器,用来监听ZK的Session状态变化;
- 启动组件 ZookeeperLeaderElector ,进入控制器选举流程,也就是说会选举出一个Broker作为集群管理(Controller)节点。
// KafkaController.scala
private val controllerElector = new ZookeeperLeaderElector(controllerContext, ZkUtils.ControllerPath, onControllerFailover,onControllerResignation, config.brokerId, time)
def startup() = {
inLock(controllerContext.controllerLock) {
info("Controller starting up")
// 1.注册一个监听Zookeeper Session状态的监听器
registerSessionExpirationListener()
isRunning = true
// 2.启动组件ZookeeperLeaderElector,进入Broker Leader器选举流程
controllerElector.startup
info("Controller startup complete")
}
}
private def registerSessionExpirationListener() = {
zkUtils.zkClient.subscribeStateChanges(new SessionExpirationListener())
}
KafkaHealthcheck
再来看KafkaHealthcheck的创建和初始化:
- 首先,注册了一个Zookeeper监听器,用来监听ZK的Session状态变化;
- 接着,把当前Broker的信息注册到Zookeeper的某个节点下。
// KafkaHealthcheck.scala
class KafkaHealthcheck(brokerId: Int,
advertisedEndpoints: Seq[EndPoint],
zkUtils: ZkUtils,
rack: Option[String],
interBrokerProtocolVersion: ApiVersion) extends Logging {
private[server] val sessionExpireListener = new SessionExpireListener
def startup() {
// 1.注册一个监听Zookeeper Session状态的监听器
zkUtils.zkClient.subscribeStateChanges(sessionExpireListener)
register()
}
def register() {
//...
// 注意当前Broker的信息到ZK节点中
zkUtils.registerBrokerInZk(brokerId, plaintextEndpoint.host, plaintextEndpoint.port, updatedEndpoints, jmxPort, rack,
interBrokerProtocolVersion)
}
}
KafkaHealthcheck会将当前Broker的信息注册到Zookeeper的临时节点中:/brokers/ids/[0...N]。比如,当前的BrokerID为1,那么就注册一个/brokers/ids/1节点,节点的内容包含该Broker的IP、端口等信息。
1.2 选举
我们再来看Broker是如何通过KafkaController完成选举的,实际是通过一个名为 ZookeeperLeaderElector 的组件来完成:
- ZookeeperLeaderElector在创建时,会指定要监听的Zookeeper节点——
/Controller; - ZookeeperLeaderElector启动后,会在
/Controller节点上注册一个监听器——LeaderChangeListener,一旦/Controller的内容发生变化,Broker就会收到通知。
class ZookeeperLeaderElector(controllerContext: ControllerContext,
electionPath: String,
onBecomingLeader: () => Unit,
onResigningAsLeader: () => Unit,
brokerId: Int,
time: Time) extends LeaderElector with Logging {
// -1表示当前还没有Leader Broker
var leaderId = -1
// electionPath在构造ZookeeperLeaderElector时指定:/Controller
val index = electionPath.lastIndexOf("/")
if (index > 0)
controllerContext.zkUtils.makeSurePersistentPathExists(electionPath.substring(0, index))
val leaderChangeListener = new LeaderChangeListener
def startup {
inLock(controllerContext.controllerLock) {
// 注册LeaderChangeListener监听器,当/Controller变化时,会收到通知
controllerContext.zkUtils.zkClient.subscribeDataChanges(electionPath, leaderChangeListener)
elect
}
}
}
ZookeeperLeaderElector的elect方法用来完成真正的Broker选举:
- 初始化情况下,
/Controller节点是不存在,getControllerID的解析结果就是-1,表示当前没有Leader Broker。那么当前Broker就会主动创建一个/Controller节点,并写入自己的节点信息,包含BrokerId、版本号、时间戳等等; - 如果竞争创建
/Controller节点失败了,就以最先创建的那个Broker作为Leader。
// ZookeeperLeaderElector.scala
def elect: Boolean = {
val timestamp = time.milliseconds.toString
val electString = Json.encode(Map("version" -> 1, "brokerid" -> brokerId, "timestamp" -> timestamp))
// 1.解析/Controller节点内容,获取LeaderId
leaderId = getControllerID
// 2.已经有Broker Leader了,直接返回
if(leaderId != -1) {
debug("Broker %d has been elected as leader, so stopping the election process.".format(leaderId))
return amILeader
}
try {
// 3.创建/Controller临时节点,写入当前Broker的信息
val zkCheckedEphemeral = new ZKCheckedEphemeral(electionPath,
electString,
controllerContext.zkUtils.zkConnection.getZookeeper,
JaasUtils.isZkSecurityEnabled())
zkCheckedEphemeral.create()
info(brokerId + " successfully elected as leader")
// LeaderId变成当前Broker的ID
leaderId = brokerId
onBecomingLeader()
} catch {
case _: ZkNodeExistsException =>
// 执行到这里,说明有其它Broker先一步创建成功节点,成为了Leader
leaderId = getControllerID
if (leaderId != -1)
debug("Broker %d was elected as leader instead of broker %d".format(leaderId, brokerId))
else
warn("A leader has been elected but just resigned, this will result in another round of election")
// 执行到这里,可能是发生了未知异常,则删除/Controller临时节点,这将触发新一轮选举
case e2: Throwable =>
error("Error while electing or becoming leader on broker %d".format(brokerId), e2)
resign()
}
amILeader
}
整个选举的流程,我用下面这张图表示:
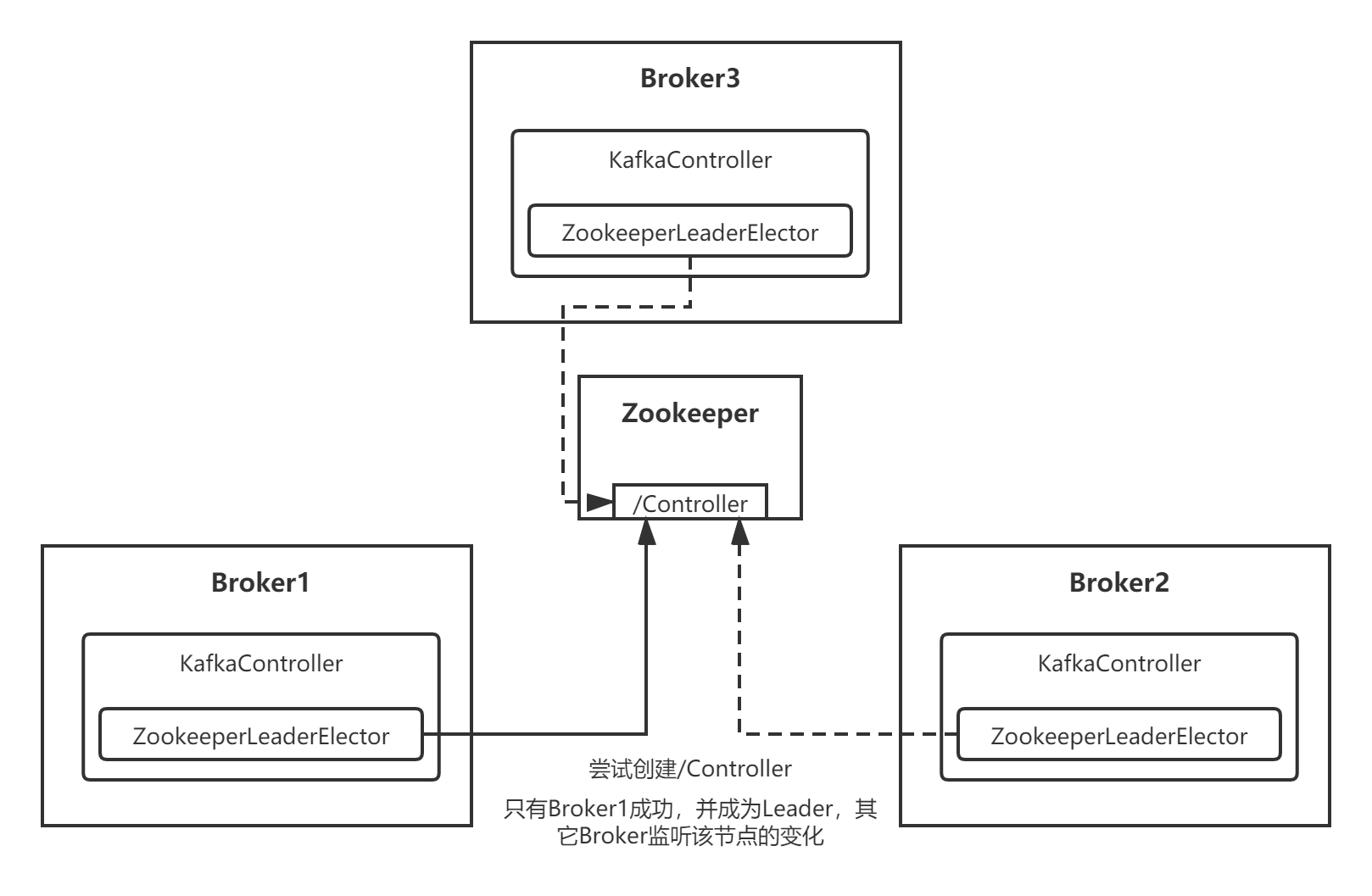
1.3 重新选举
我们再来看下,如果某个Broker成为Leader(比如上图中的Broker1),然后突然宕机挂了会如何呢?
上一节说过了,ZookeeperLeaderElector包含一个监听器——LeaderChangeListener,会监听/Controller节点的变化,由于这是一个临时节点,那么当Broker1宕机后,节点就会消失:
// ZookeeperLeaderElector.scala
class LeaderChangeListener extends IZkDataListener with Logging {
// 节点信息发生变化时触发
@throws[Exception]
def handleDataChange(dataPath: String, data: Object) {
val shouldResign = inLock(controllerContext.controllerLock) {
val amILeaderBeforeDataChange = amILeader
leaderId = KafkaController.parseControllerId(data.toString)
// 在节点变化前是Leader,但是节点变化后不是Leader
amILeaderBeforeDataChange && !amILeader
}
if (shouldResign)
onResigningAsLeader()
}
// 节点删除时触发
@throws[Exception]
def handleDataDeleted(dataPath: String) {
val shouldResign = inLock(controllerContext.controllerLock) {
amILeader // leaderId == brokerId ?
}
// 如果LeaderId发生了变化,说明要重新选举
if (shouldResign)
onResigningAsLeader()
inLock(controllerContext.controllerLock) {
elect
}
}
}
节点一消失,就会触发重新选举,上述的onResigningAsLeader方法用于取消Controller,主要是unregister一些由Controller管理的组件,重点就是最一行elect触发重新选举,上一节已经讲过了就不再赘述。
二、Broker集群伸缩
既然Broker Leader已经选举完成了,那么接下来Controller就要对整个集群进行管理了。这里有一个问题,Controller怎么知道当前集群中有哪些其它Broker呢?这些Broker的上下线(集群伸缩)又如何感知呢?
我在上一节讲过,每个Broker启动后,都会初始化一个 KafkaHealthcheck 组件,它就是来负责Broker自身的上下线的。
2.1 Broker上下线
当某个Broker启动并加入到集群后,会通过 KafkaHealthcheck 往Zookeeper注册一个临时节点:/brokers/ids/[当前BorkerID]:
// KafkaHealthcheck.scala
class KafkaHealthcheck(brokerId: Int,
advertisedEndpoints: Seq[EndPoint],
zkUtils: ZkUtils,
rack: Option[String],
interBrokerProtocolVersion: ApiVersion) extends Logging {
private[server] val sessionExpireListener = new SessionExpireListener
def startup() {
// 1.注册一个监听Zookeeper Session状态的监听器
zkUtils.zkClient.subscribeStateChanges(sessionExpireListener)
register()
}
def register() {
//...
// 注意当前Broker的信息到ZK节点中
zkUtils.registerBrokerInZk(brokerId, plaintextEndpoint.host, plaintextEndpoint.port, updatedEndpoints, jmxPort, rack,
interBrokerProtocolVersion)
}
}
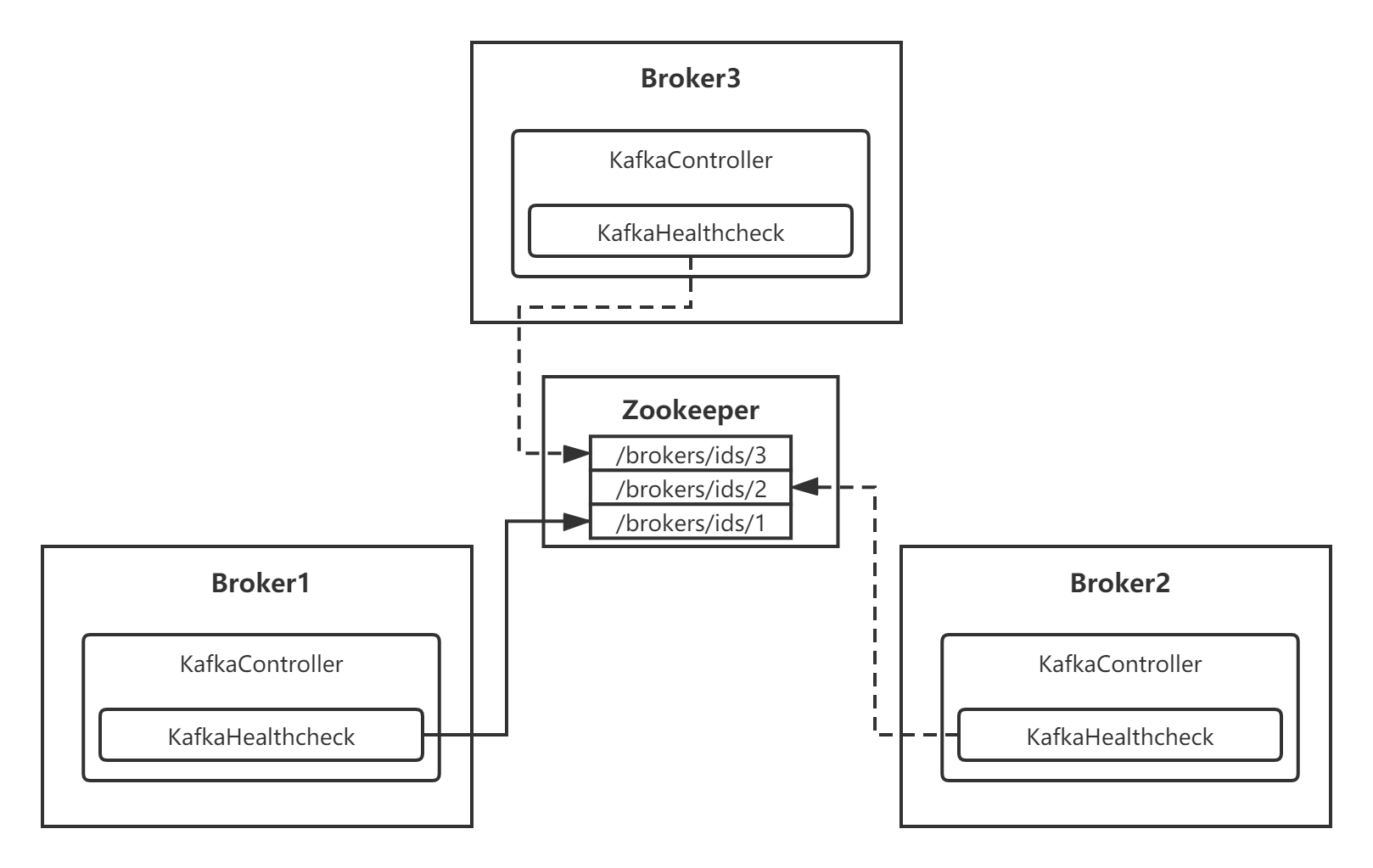
那么集群中的Controller(也就是Leader Broker)是如何感知到的呢?
2.2 Broker变动感知
Broler选举成功成为Leader后,会去监听/brokers/ids/节点的变动:
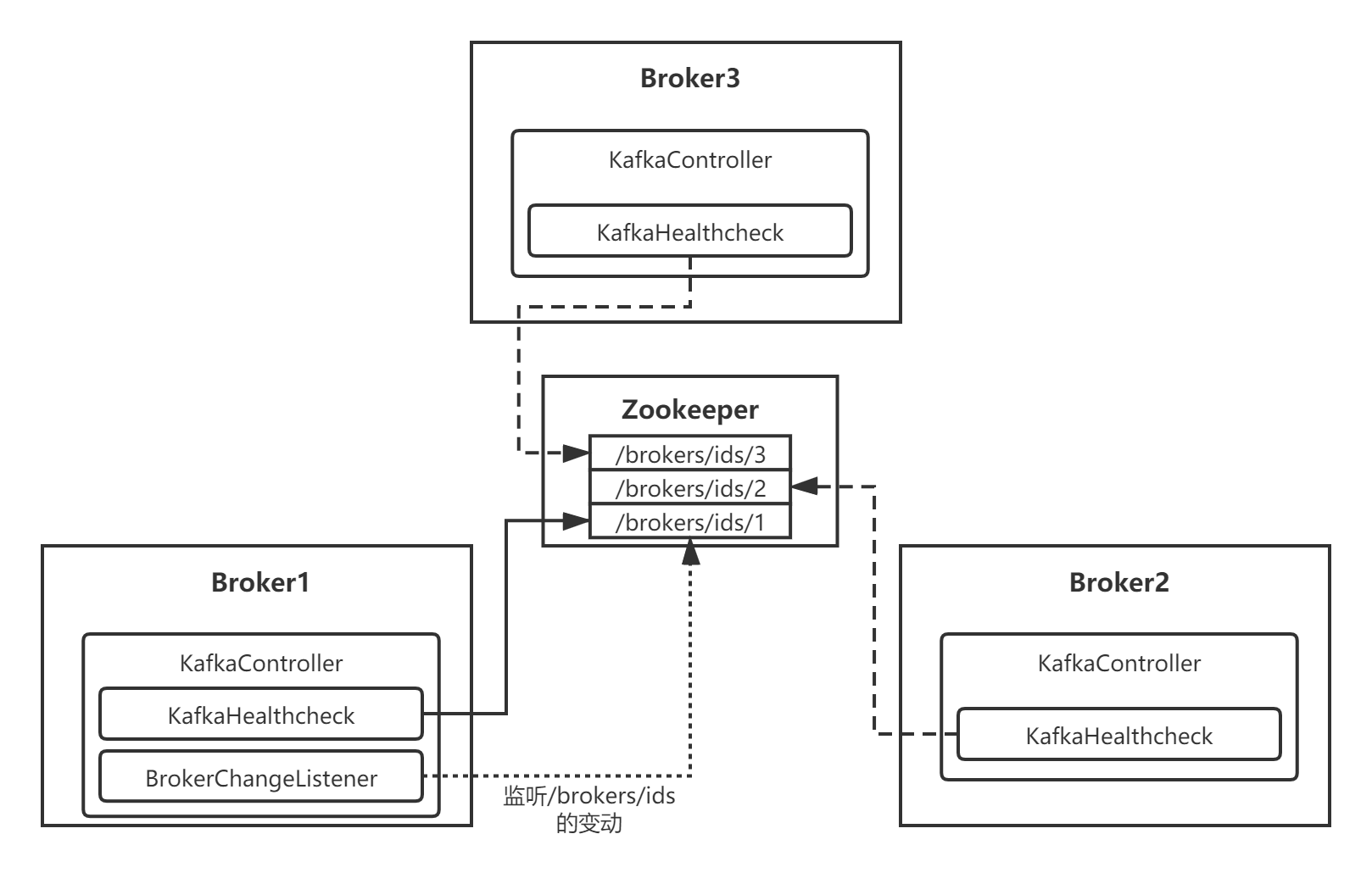
在选举流程中有这么一行代码onBecomingLeader:
// ZookeeperLeaderElector.scala
def elect: Boolean = {
//...
try {
val zkCheckedEphemeral = new ZKCheckedEphemeral(electionPath,
electString,
controllerContext.zkUtils.zkConnection.getZookeeper,
JaasUtils.isZkSecurityEnabled())
zkCheckedEphemeral.create()
info(brokerId + " successfully elected as leader")
// 当前Broker成为Leader Broker
leaderId = brokerId
//
onBecomingLeader()
} catch {
//...
}
amILeader
}
onBecomingLeader方法里面做了很多事情,主要就是Controller的管理工作,我们重点关注replicaStateMachine.registerListeners():
// KafkaController.scala
def onControllerFailover() {
if(isRunning) {
info("Broker %d starting become controller state transition".format(config.brokerId))
readControllerEpochFromZookeeper()
incrementControllerEpoch(zkUtils.zkClient)
registerReassignedPartitionsListener()
registerIsrChangeNotificationListener()
registerPreferredReplicaElectionListener()
partitionStateMachine.registerListeners()
// 关键看这里
replicaStateMachine.registerListeners()
//...
}
else
info("Controller has been shut down, aborting startup/failover")
}
Controller通过组件ReplicaStateMachine对集群中Broker的变动进行监听,使用了一个名为BrokerChangeListener的监听器:
// ReplicaStateMachine.scala
def registerListeners() {
// 注册Broker变动监听器
registerBrokerChangeListener()
}
private def registerBrokerChangeListener() = {
// BrokerIdsPath就是“/brokers/ids”
zkUtils.zkClient.subscribeChildChanges(ZkUtils.BrokerIdsPath, brokerChangeListener)
}
我们来看下BrokerChangeListener,当/brokers/ids这个节点中有子目录增减时,都会调用下面的doHandleChildChange方法:
// ReplicaStateMachine.scala
class BrokerChangeListener(protected val controller: KafkaController) extends ControllerZkChildListener {
protected def logName = "BrokerChangeListener"
def doHandleChildChange(parentPath: String, currentBrokerList: Seq[String]) {
info("Broker change listener fired for path %s with children %s".format(parentPath, currentBrokerList.sorted.mkString(",")))
inLock(controllerContext.controllerLock) {
if (hasStarted.get) {
ControllerStats.leaderElectionTimer.time {
try {
// 1.拿到“/brokers/ids”下的所有子节点
val curBrokers = currentBrokerList.map(_.toInt).toSet.flatMap(zkUtils.getBrokerInfo)
val curBrokerIds = curBrokers.map(_.id)
val liveOrShuttingDownBrokerIds = controllerContext.liveOrShuttingDownBrokerIds
// 2.拿到所有新增的Broker ID,也就是新加入集群的Broker
val newBrokerIds = curBrokerIds -- liveOrShuttingDownBrokerIds
// 3.拿到所有下线的Broker ID,也就是退出集群的Broker
val deadBrokerIds = liveOrShuttingDownBrokerIds -- curBrokerIds
val newBrokers = curBrokers.filter(broker => newBrokerIds(broker.id))
controllerContext.liveBrokers = curBrokers
val newBrokerIdsSorted = newBrokerIds.toSeq.sorted
val deadBrokerIdsSorted = deadBrokerIds.toSeq.sorted
val liveBrokerIdsSorted = curBrokerIds.toSeq.sorted
info("Newly added brokers: %s, deleted brokers: %s, all live brokers: %s"
.format(newBrokerIdsSorted.mkString(","), deadBrokerIdsSorted.mkString(","), liveBrokerIdsSorted.mkString(",")))
// 4.添加上线的Broker
newBrokers.foreach(controllerContext.controllerChannelManager.addBroker)
// 5.移除下线的Broker
deadBrokerIds.foreach(controllerContext.controllerChannelManager.removeBroker)
// 6.对新增的Broker进行处理
if(newBrokerIds.nonEmpty)
controller.onBrokerStartup(newBrokerIdsSorted)
// 7.对下线的Broker进行处理
if(deadBrokerIds.nonEmpty)
controller.onBrokerFailure(deadBrokerIdsSorted)
} catch {
case e: Throwable => error("Error while handling broker changes", e)
}
}
}
}
}
}
2.3 集群元数据推送
感知到Broker变动之后,Leader Broker(Controller)会针对上线还是下线做不同的处理,我这里针对集群上线新Broker讲解下元数据推送的过程:
// KafkaController.scala
def onBrokerStartup(newBrokers: Seq[Int]) {
info("New broker startup callback for %s".format(newBrokers.mkString(",")))
// 新增的Broker集合
val newBrokersSet = newBrokers.toSet
// 发送集群元数据信息给各个Broker
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq)
// ...
}
元数据推送的过程,依赖的还是本系列前面讲到的网络通信层,就是依赖Kafka自定义的那套NIO通信框架:
// KafkaController.scala
def sendUpdateMetadataRequest(brokers: Seq[Int], partitions: Set[TopicAndPartition] = Set.empty[TopicAndPartition]) {
try {
// 1.将更新请求打成一个batch包
brokerRequestBatch.newBatch()
// 2.添加要发送的Broker
brokerRequestBatch.addUpdateMetadataRequestForBrokers(brokers, partitions)
// 3.发送请求
brokerRequestBatch.sendRequestsToBrokers(epoch)
} catch {
case e : IllegalStateException => {
// Resign if the controller is in an illegal state
error("Forcing the controller to resign")
brokerRequestBatch.clear()
controllerElector.resign()
throw e
}
}
}
整个流程大致如下图所示,读者可以自己研究下推送集群元数据信息的源码,我不再赘述:
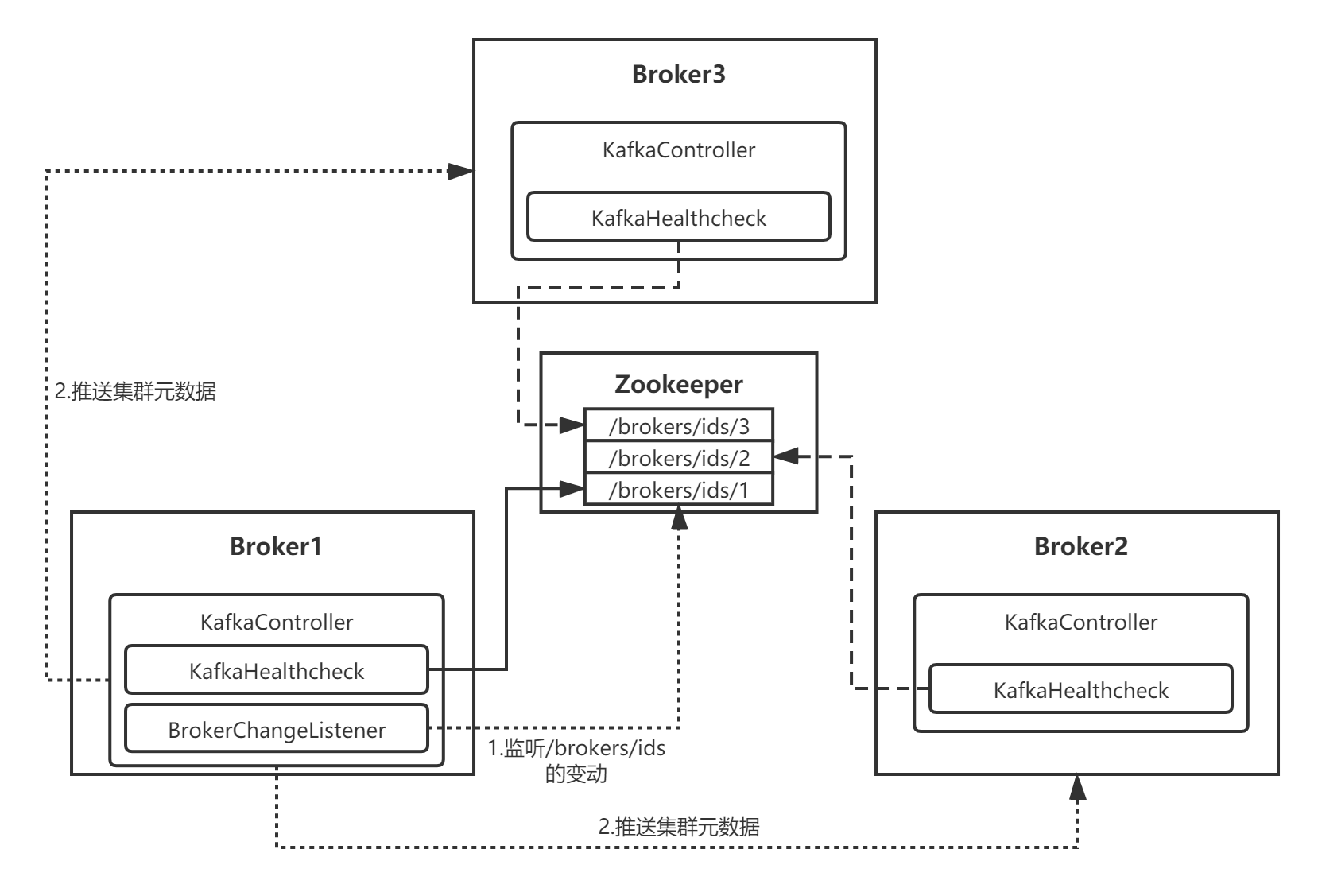
三、总结
本章,我对Kafka的Broker集群的选举流程进行了讲解,Kafka Server服务启动后,每个Broker内部都包含一个KafkaController组件,选举流程的本质就是通过该组件往Zookeeper写入节点,首先写入成功的就是Leader,即Controller。
Controller负责管理整个Broker集群,包含Broker的上下线感知,分区副本的分配、选举,集群元数据的通知更新等等。下一章,我就来讲解
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
