在集中式环境中服务的机器台只有一台,这样对于服务不仅存在服务单点故障问题而且还存在流量问题。为了解决这个问题,就引入的分布式与集群概念。
分布式:一个业务分拆多个子业务,部署在不同的服务器上
集群:同一个业务,部署在多个服务器上
1、 dubbo 服务治理
当请求来临时,如何从多个服务器中,选择一个有效、合适的服务器,这个集群所需要面对一问题。所以在集群里面就引申出负载均衡(LoadBalance),高可用(HA),路由(Route)等概念。我们来看一下 dubbo 在进行服务调用的时候是如何处理的。
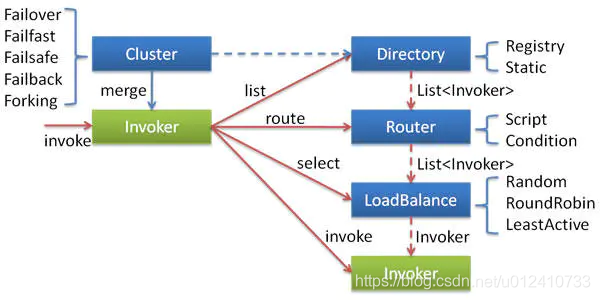
这张集群容错包含以下几个角色:
Invoker:对Provider(服务提供者) 的一个可调用 Service 接口的抽象,Invoker封装了Provider地址及Service接口信息。Cluster:Directory中的多个Invoker伪装成一个Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个Directory:代表多个Invoker,可以把它看成List<Invoker>,但与 List 不同的是,它的值可能是动态变化的,比如注册中心推送变更Router: 负责从多个Invoker中按路由规则选出子集,比如读写分离,应用隔离等LoadBalance:LoadBalance负责从多个Invoker中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选.
2、集群容错
下面我们来分析一下 Cluster, 也就是集群。集群里面包含:集群与容错两个概念。下面我们来看一下维基百科对于集群与容错的描述。
2.1 集群
计算机集群是一组松散或紧密连接的计算机,它们协同工作,因此在许多方面,它们可以被看作是一个单一的系统。与网格计算机不同,计算机集群使每个节点集执行相同的任务,由软件控制和调度。
集群的组件通常通过快速的本地区域网络连接到一起,每个节点(计算机用作服务器)运行自己的操作系统实例。在大多数情况下,所有的节点都使用相同的硬件1更好的源和相同的操作系统,尽管在某些设置中(例如使用开放源码集群应用程序资源(OSCAR)),不同的操作系统可以在每个计算机或不同的硬件上使用。
2.2 容错
容错是一种属性,它使系统能够在出现故障(或内部一个或多个故障)的情况下继续正常运行。如果它的运行质量下降,那么下降与失败的严重程度成正比,与一个天真的设计系统相比,即使是很小的故障也会导致完全崩溃。
在高可用性或生命关键系统中,容错是特别需要的。当系统的某些部分被分解时,维护功能的能力被称为优雅的降级
3、Cluster & Invoker
下面我们来看一下 Cluster & Invoker 的接口定义
Cluster
@SPI(FailoverCluster.NAME)
public interface Cluster {
/**
* Merge the directory invokers to a virtual invoker.
*
* @param <T>
* @param directory
* @return cluster invoker
* @throws RpcException
*/
@Adaptive
<T> Invoker<T> join(Directory<T> directory) throws RpcException;
}
Cluster 只定义了一个方法 join ,它的作用是将目录下面的 invoker 列表合并到虚拟调用程序中。其实就是把 Provider 端暴露的调用合并到一个集群当中。外部调用的时候不管这个服务到底有几个提供者,Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个。
Invoker
public interface Invoker<T> extends Node {
/**
* get service interface.
*
* @return service interface.
*/
Class<T> getInterface();
/**
* invoke.
*
* @param invocation
* @return result
* @throws RpcException
*/
Result invoke(Invocation invocation) throws RpcException;
}
Invoker 是 Dubbo 领域模型中非常重要的一个概念,很多设计思路都是向它靠拢。这就使得 Invoker 渗透在整个实现代码里。 下面我们用一个官方的图来说明最重要的两种 Invoker:服务提供 Invoker 和服务消费 Invoker:
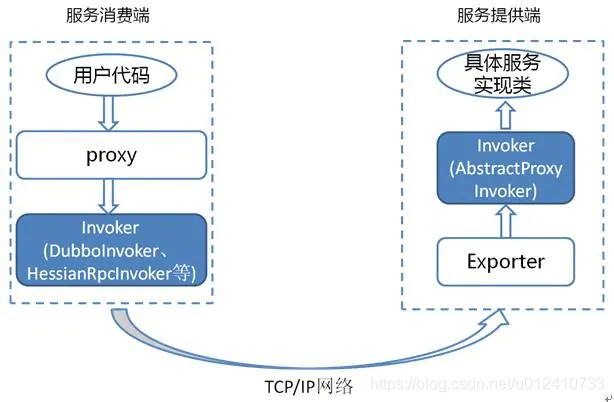
为了更好的解释上面这张图,我们结合服务消费和提供者的代码示例来进行说明:
服务消费者代码:
public class DemoClientAction {
private DemoService demoService;
public void setDemoService(DemoService demoService) {
this.demoService = demoService;
}
public void start() {
String hello = demoService.sayHello("world" + i);
}
}
上面代码中的 DemoService 就是上图中服务消费端的 proxy,用户代码通过这个 proxy 调用其对应的 Invoker 5,而该 Invoker 实现了真正的远程服务调用。
服务提供者代码:
public class DemoServiceImpl implements DemoService {
public String sayHello(String name) throws RemoteException {
return "Hello " + name;
}
}
上面这个类会被封装成为一个 AbstractProxyInvoker 实例,并新生成一个 Exporter 实例。这样当网络通讯层收到一个请求后,会找到对应的 Exporter 实例,并调用它所对应的 AbstractProxyInvoker 实例,从而真正调用了服务提供者的代码。Dubbo 里还有一些其他的 Invoker 类,但上面两种是最重要的。
4、集群容错
在 dubbo 源码中, 在包 com.alibaba.dubbo.rpc.cluster.support 中,我们可以看到 Cluster 和 Invoker 是成对出现的。
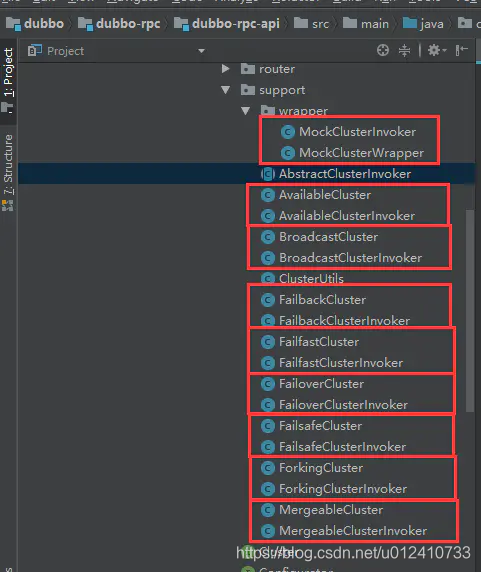
下面我们通过类图来看一下它们之间的关系:
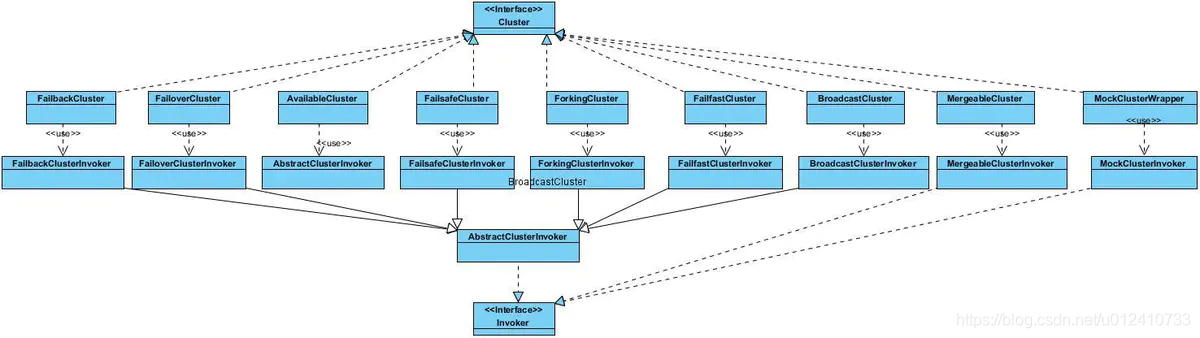
每一个 Cluster 其实都是创建一个 Cluster 调用的实例,Cluster 把集群调用功能委托给 AbstractClusterInvoker (抽象集群调用)。其实最终返回给 Consumer 的 Invoker 实例是 MockClusterInvoker 对象。这个对象持有一个 RegistryDirectory 实例(服务自动发现与注册)与一个 FailoverClusterInvoker 实例(失败转移,当出现失败,重试其它服务器,通常用于读操作,但重试会带来更长延迟。)
集群容错主要包括以下几种模式:
- Failover Cluster:失败自动切换,当出现失败,重试其它服务器 。通常用于读操作,但重试会带来更长延迟。可通过
retries="2"来设置重试次数(不含第一次)。 - Failfast Cluster:快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
- Failsafe Cluster:失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
- Failback Cluster:失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
- Forking Cluster:并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=“2” 来设置最大并行数。
- Broadcast Cluster:广播调用所有提供者,逐个调用,任意一台报错则报错 2。通常用于通知所有提供者更新缓存或日志等本地资源信息。
参考地址:
1、http://en.wikipedia.org/wiki/Computer_cluster
2、http://en.wikipedia.org/wiki/Fault-tolerant_system
3、http://dubbo.apache.org/books/dubbo-user-book/demos/fault-tolerent-strategy.html
4、http://dubbo.apache.org/books/dubbo-dev-book/implementation.html
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
