在集中式环境中服务的机器台只有一台,这样对于服务不仅存在服务单点故障问题而且还存在流量问题。为了解决这个问题,就引入的分布式与集群概念。
分布式:一个业务分拆多个子业务,部署在不同的服务器上
集群:同一个业务,部署在多个服务器上
当请求来临时,如何从多个服务器中,选择一个有效、合适的服务器,这个集群所需要面对一问题。所以在集群里面就引申出负载均衡(LoadBalance),高可用(HA),路由(Route)等概念。我们来看一下 dubbo 在进行服务调用的时候是如何处理的。
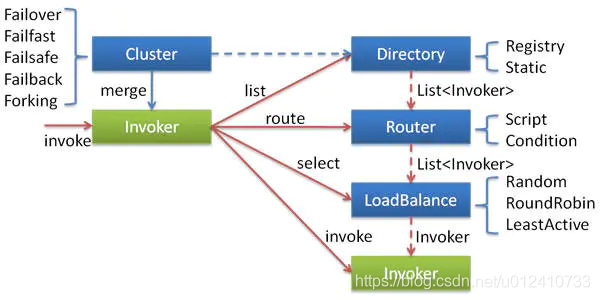
这张集群容错包含以下几个角色:
Invoker:对Provider(服务提供者) 的一个可调用 Service 接口的抽象,Invoker封装了Provider地址及Service接口信息。Cluster:Directory中的多个Invoker伪装成一个Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个Directory:代表多个Invoker,可以把它看成List<Invoker>,但与 List 不同的是,它的值可能是动态变化的,比如注册中心推送变更Router: 负责从多个Invoker中按路由规则选出子集,比如读写分离,应用隔离等LoadBalance:LoadBalance负责从多个Invoker中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选.
我们再来对照看一下 dubbo 的核心架构图。
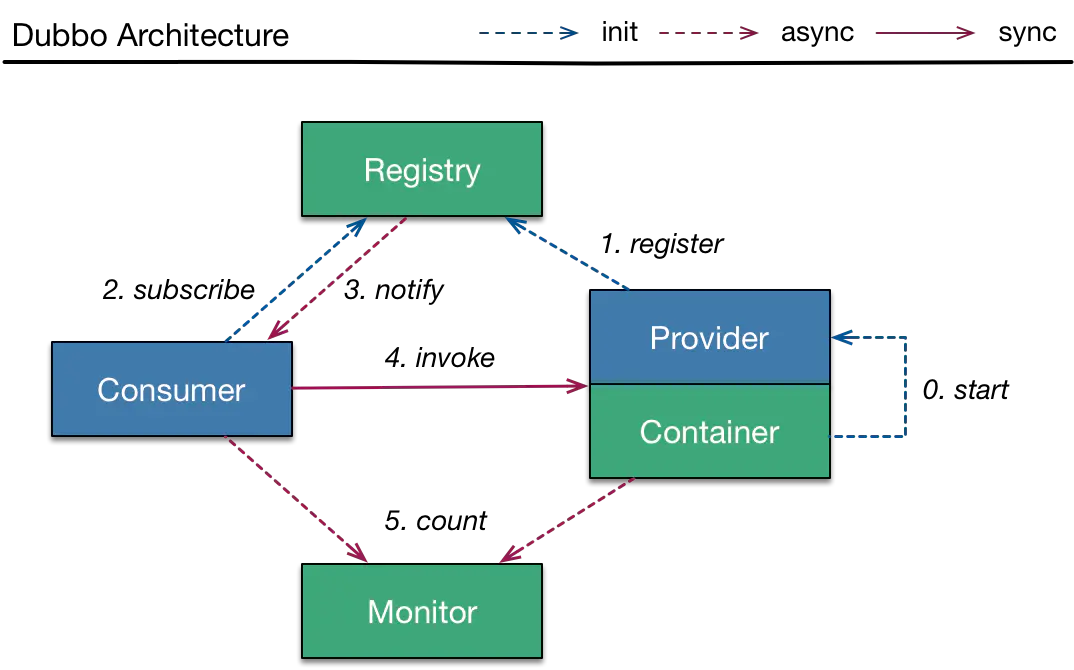
通过之前的一系列的源码分析,以及上面的二张 dubbo 架构图,我们不难得出以下结论。
当 dubbo 的 Provider 进行一次服务暴露的时候,就会有 Registry 注册一个服务,然后通过 Netty 进行暴露请求。当 Consumer 需要进行服务调用的时候,通过 Cluster 把多个服务伪装成一个 Invoke,这样对调用方就不需要关心到底有多少个服务调用方了。
集群通过到注册中心去拿暴露当前服务的接口信息的获取到 Directory (服务列表),然后通过配置的 Route (路由规则) 找到满足的 Invoke 列表,最后通过 LoadBalance 找到合适的一个 Invoke 进行远程调用。在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。这样就对服务的高可用做到了保证。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
