1 介绍
Redis是我们在业务开发中很重要的一个辅助,能够极大提高我们系统的运行效率,为后端的存储服务减少压力,提升用户使用体验。
但是作为一个辅助提升速度的组件,如果自己存在请求延迟的情况,那将是一个巨大的灾难,可能引起整条业务链路的雪崩。
在我以往的博客里面,也有过相应的案例,比如 《架构与思维:一次缓存雪崩的灾难复盘》。
但在实际业务场景中,可能有更加复杂的原因导致Redis访问效率变慢,下面我们详细来分析下。
2 发现和监测Redis的慢执行
2.1 如何判断Redis变慢了
在之前的章节中,我们根据官网的资料有过这样的结论:
在较高的配置基准下(比如 8C 16G +),在连接数为0~10000的时候,最高QPS可达到120000。Redis以超过60000个连接为基准,仍然能够在这些条件下维持50000个q/s,体现了超高的性能。下图中横轴是连接数,纵轴是QPS。
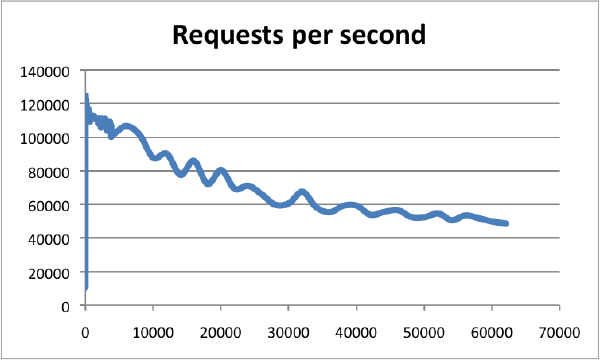
可见,Redis的性能和流量可抗性是极其高的,从客户端request发出到接受到response,这个处理过程时间是极短的,一般是微秒级别。
而对比Redis出现性能瓶颈的时候,就会有比较异常的表现,如达到几秒甚至几十秒,这时候我们就可以认定 Redis 性能变差了,需要去优化。
感知到 Redis的变慢了,接下来我们要做的就是验证和确认,这样才能有针对性的进行优化。
我们通过以下方法进行验证和分析。
2.1 基线延迟测试
redis-cli 提供了一个指令选项 --intrinsic-latency,用于监测和统计某个时间段内Redis的最大延迟。这个选项可以用来评估Redis本身的性能,并且可以作为Redis的基准性能。
使用--intrinsic-latency选项需要指定时长,例如120秒。在指定的时间段内,redis-cli会记录每个秒级的最大延迟。这个最大延迟可以反映出Redis本身的性能,不受网络或其他外部因素的影响。
你可以通过以下命令使用--intrinsic-latency选项:
redis-cli --intrinsic-latency 120
执行该命令后,redis-cli会输出在120秒内的最大延迟统计信息。
需要注意的是,--intrinsic-latency选项从Redis的2.8.7版本开始支持。如果你使用的是较早的版本,可能无法使用该选项。
redis-cli --intrinsic-latency 120
Max latency so far: 5 microseconds.
Max latency so far: 14 microseconds.
Max latency so far: 33 microseconds.
Max latency so far: 52 microseconds.
Max latency so far: 70 microseconds.
Max latency so far: 130 microseconds.
Max latency so far: 272 microseconds.
Max latency so far: 879 microseconds.
Max latency so far: 1079 microseconds.
Max latency so far: 1665 microseconds.
Max latency so far: 1665 microseconds.
可以看到,当前运行的最大延迟是 1665 微秒,所以基线延迟的性能是 1665 (约 1.6 毫秒)微秒。
可以在终端上连接Redis的服务端进行测试,避免客户端测试因为网络的影响导致差异较大。
可以通过-h host -p port 来连接到服务端。
redis-cli --latency -h `host` -p `port`
2.2 监控慢指令
在算法设计中,最优的时间复杂度是O(1) 和 O(log N)。
一样的 ,Redis官方也尽量自身的操作指令尽量的高效,尽量节省时间复杂度。但是涉及到集合操作、全量的复杂度一般为O(N),
- 集合全量查询:HGETALL、SMEMBERS
- 集合的聚合操作:SORT、LREM、 SUNION
- SORTEDSET类型命令:ZDELRANGEBYSCORE
排查是否使用了慢指令,可以用如下几种方式:
- 使用一些工具进行操作的延时监控,如 latency-monitor
- 通过查询 Redis 的慢日志来分析执行慢查询的操作(下面会详细说到)
如果只是简单判断是否使用了慢速查询,还可以使用命令 top、htop、prstat 等检查 Redis 主进程的 CPU 消耗即可
2.3 监控慢日志
在 Redis 中,slowlog 是一个用于查询和记录执行时间较长的命令的命令。它可以帮助你找出哪些命令的执行时间超过了设定的阈值,并且将这些命令记录下来,以便后续分析和优化。
默认情况下命令执行时间超过 10ms 就会被记录到日志,这个只记录执行时间,摒弃了 io 往返或者网络延迟引起的响应慢部分。
如果你想修改慢查询的时间阈值,自定义慢查询的耗时标准,可以执行如下命令:
redis-cli CONFIG SET slowlog-log-slower-than 3330
这边为什么使用 3330 ,是因为我们采用上面基线延迟测试值的double。
slowlog 命令的基本语法如下:
slowlog get [count]
其中,count 是一个可选参数,表示要返回的 slow log 的数量。如果不指定 count,则默认返回最近的 slow log。
当执行 slowlog get 命令时,Redis 会返回最近的一些 slow log,每个 slow log 包含以下信息:
- unique ID:该 slow log 的唯一 ID。
- 时间戳:该 slow log 记录的时间戳。
- 命令:执行了哪些命令。
- 执行时间:执行该命令所花费的时间(以微秒为单位)。
你可以通过 slowlog get 命令来查看最近的 slow log,以便找出需要优化的命令。此外,你还可以通过 slowlog-max-len 参数来设置 slow log 的最大长度,以避免日志过多占用过多内存。
# 举例:读取最近2个慢查询
127.0.0.1:6381> SLOWLOG get 2
1) 1) (integer) 17
2) (integer) 1693641198
3) (integer) 5427
4) 1) "hgetall"
2) "all.uer_info"
1) 1) (integer) 18
2) (integer) 1693641217
3) (string) "GET"
4) (integer) 3771
第一个 HGET 命令,共 4 个字段:
- 字段 1:代表 slowlog 出现的序号,服务启动后递增加码,当前为 17。
- 字段 2:查询时的 Unix 时间戳。
- 字段 3:查询执行的时间数(微秒),当前值5472(5.472微秒) 比 3330多,所以被记录下来。
- 字段 4: 表示查询的命令和参数, 如 hgetall all.user_info。
这样的做法是输出慢查询,提供开发同学排查的方向。
3 解决Redis慢执行问题
根据我们之前的知识,Redis 的数据读写这个主操作是由单线程执行,如果被影响,导致阻塞,那么性能就会大大降低。
所以,如何避免主线程阻塞,是我们解决Redis慢执行的一个关键因素。以下从一个方向
3.1 网络通信延迟
互联网时代,客户端访问Redis服务端的时候很可能回到网络延迟较高,这样,客户端连接并请求的的效率就会变低。
如果是多个数据中心或者多网络分区的场景(两地三中心、异地多活),这种情况就更明显,毕竟数据在网络中传输都是视距离时延的。
通过 TCP/IP 连接或 Unix 域连接连接到 Redis,1 Gbit/s 的网络延迟大约为 200 us。
从下面这个图看到往返时间RTT(Round trip time),执行过程为:
-
发送命令
-
命令进入队列,待执行
-
执行命令
-
返回执行结果
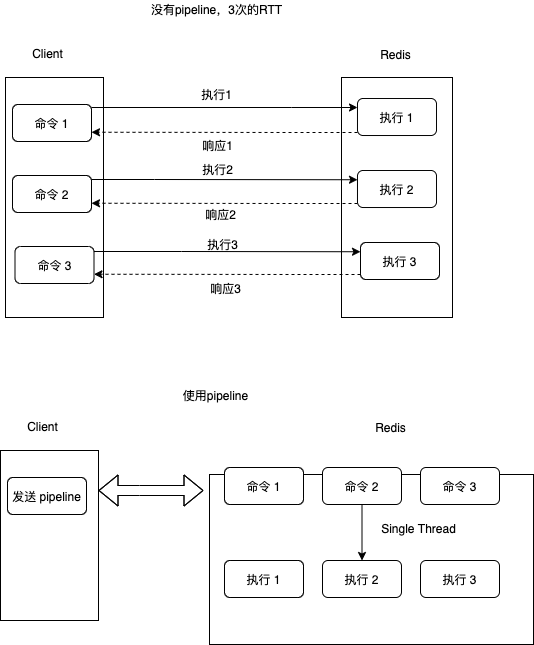
上面的图明显有效节约了RTT的次数,提高了效率。类似MGET和MSET等命令是Redis中用于批量操作多个key-value的命令,而Redis的很多其他命令,
如 hgetall,不支持批量操作,需要消耗 N 次 RTT ,这个时候需要 pipeline 来解决这个问题。
Redis pipeline 将多个命令连接在一起来减少网络响应往返次数。
3.2 慢指令导致的延迟
我们上面与分析过慢指令,在算法设计中,最优的时间复杂度是O(1) 和 O(log N)。所以当我们确认了有慢查询指令。可以通过以下两种方式解决:
- 在 Cluster 集群中,复杂度高于O(1) 和 O(log N)的操作使用Slava从库执行,大部分复杂执行都是非写的,所以应该要避免阻塞主线程。当然,在Client执行也是可以的。
- 使用高效命令代替慢执行的命令,同时避免单次查询大量数据,采用增量获取的办法(参考 SCAN、SSCAN、HSCAN、ZSCAN)。
- 生产环境中禁用KEYS 命令,它在调试的时候会遍历所有的键值对,操作延时较高。
3.3 Fork 生成 RDB 导致的延迟
我们在数据持久化的篇章中,说过数据持久化的一些办法,包括RDB内存快照和AOF日志。使用的不合理,也会照成Redis的性能大打折扣。
生成 RDB 快照(参考这篇 《Redis系列2:数据持久化提高可用性》),Redis 必须 fork 后台进程,
做了fork操作之后,实际是拆分了执行出去,因为在主线程中执行,所以会导致性能降低,操作延迟。
在Redis 中可以使用操作系统的 COW(Copy On Write,多进程写时复制技术) 来快速持久化,减少内存占用。
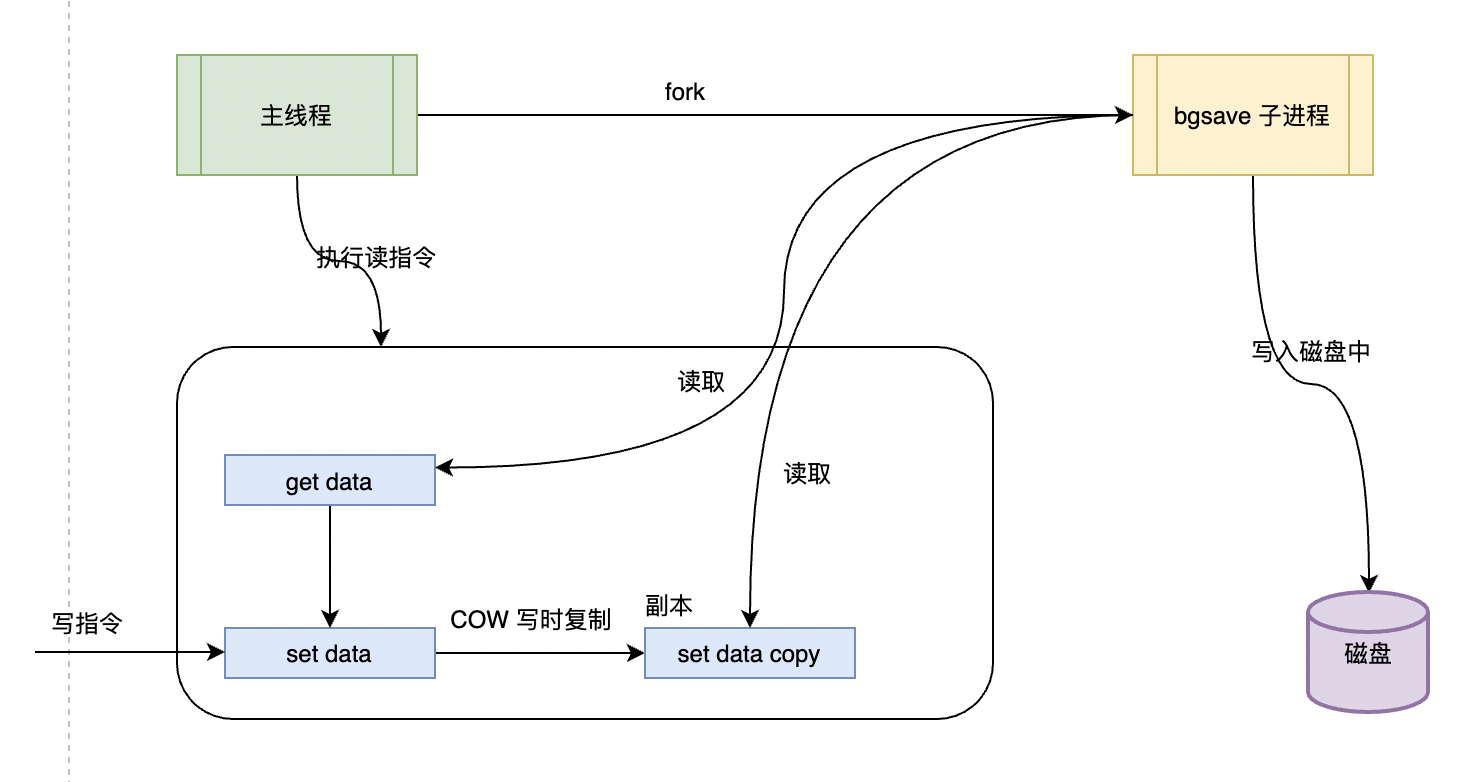
Redis在执行 bgsave 时,涉及到内存和磁盘的分配和复制,并且从库加载 RDB 期间无法提供读写服务,为了保障高效率,
主库的数据量大小尽量控制在 2~4G 左右,超过4G,会让从库加载效率变慢,从而影响业务操作。
3.4 AOF 文件系统或 RDB 大内存页问题,包括 AOF 持久化阻塞、大内存页等
Linux 2.6.38 版本之后开始支持内存大页,最大可以支持2MB的内存页分配,而之前的常规页是按照4KB来分配的。
这样的话,会导致Redis本身的一些持久化操作的问题,(参考这篇 《Redis系列2:数据持久化提高可用性》)。
- Redis 使用了 fork 生成 RDB 持久化, COW在数据被修改的时候,会复制一份数据。内存页太大的话,即使客户端修改的量很小,也会复制2MB的大页内存,导致性能变慢。
- AOF 日志存储了 Redis 服务器的顺序指令序列,AOF 日志只记录对内存进行修改的指令记录。如果内存页那太大,单次重放(replay)的内容过多,也会导致性能变慢
可以使用指令来disable Linux 内存大页:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
3.5 操作系统 Swap 操作问题,包括内存磁盘数据转换、内存清理等
Swap是操作系统中的一种虚拟内存技术,用于在物理内存不足时将一部分数据从物理内存中移动到硬盘上,以释放物理内存空间,避免系统因为内存不够而导致的 oom 情况。Swap操作包括“换出”(swap out)和“换入”(swap in)两个过程。
- Swap out是指将一部分数据从物理内存中移动到交换空间(swap space)中,以释放物理内存空间。当操作系统需要更多的内存空间时,它会根据一定的算法来决定哪些数据应该被移动到交换空间中。这些数据通常是最近最少使用的或者最不可能被再次使用的。
- Swap in是指将一部分数据从交换空间中移动到物理内存中。当操作系统需要访问被移动到交换空间中的数据时,它会根据一定的算法来决定哪些数据应该被移动到物理内存中。这些数据通常是最近被访问的或者最可能被再次访问的。
Swap操作可以帮助操作系统在物理内存不足时继续运行程序,但是过度的swap操作可能会导致系统性能下降,因为硬盘访问速度比物理内存慢得多。因此,合理配置和管理swap空间对于系统性能优化非常重要。
通常建议将swap空间设置为物理内存的1.5到2倍,并且应该避免在swap空间中频繁进行大量的读写操作。
既然swap的操作引发是由于内存空间不够导致的操作,那看看我们的Redis里面有哪些操作会引起这类行为:
- 使用超额的内存,比可用内存更多
- 再比如上面说的那几点:RDB Fork操作以及大文件生成,AOF日志记录和指令同步。都可能导致大量的内存占用,触发了 swap。
3.5.1 对swap导致的性能问题进行排查
# 获取Redis 实例的进程ID(pid):
$ redis-cli info | grep process_id
process_id:12893
# 根据进程进入 /proc 文件系统目录:
cd /proc/12893
# 打开 smaps 的文件,查找所有文件中所有的 swap 操作:
# 这边可以看到,当使用内存达到810554 kb 时,swap内存达到37kb。
$ cat smaps | egrep '^(Swap|Size)'
Size: 241 kB
Swap: 0 kB
Size: 172 kB
Swap: 0 kB
Size: 810554 kB
Swap: 37 kB
如果 Swap 是 0 kb,或者小量的kb,应该都是正常的。但当出现百 M,甚至 GB 级别的 swap 大小时,内存就明显吃紧了,大概率会导致线上请求变慢。
可以用如下办法进行解决:
- 资源补充:内存进行扩容。
- 单一职责原则:Redis在独占的主机上运行,避免其他高内存占用服务的资源抢占。
- 分治理念:增加 Cluster 集群的数量进行分担,减少单个实例所需的内存消耗。
3.6 AOF 的写回策略为 always,导致每个操作都要同步刷回磁盘
为了保证数据可靠性,Redis 使用 AOF 和 RDB 快照实现快速恢复和持久化。
(参考这篇 《Redis系列2:数据持久化提高可用性》)
AOF(Append-Only File)作为Redis用于缓存持久化的一种方式,当你选择 "always" 作为 AOF 的写回策略时,这意味着每一个写操作都会被立即同步到磁盘中。
虽然这种策略可以最大限度地保证数据的安全性,但是它对性能的影响也是最大的,因为每次写操作都需要等待磁盘 I/O 完成。如果你的应用可以接受一点点数据丢失的风险,或者你的应用主要是读操作,你可能会想要调整 AOF 的写回策略以提高性能。
以下是几种可能的解决方案:
- 调整 AOF 写回策略 :Redis 提供了几种 AOF 写回策略,包括 "always"(每个操作都立即写回)、"everysec"(每秒写回一次)、"no"(由操作系统决定何时写回)。如果你的应用可以接受一些数据丢失的风险,你可以尝试将 AOF 写回策略调整为 "everysec" 或 "no"。
- 使用 RDB 持久化 :与 AOF 不同,RDB(Redis DataBase)持久化是通过生成数据快照来实现的。你可以配置 Redis 在指定的时间间隔内生成 RDB 快照,这种方式对性能的影响相对较小。
- 优化硬件 :如果你的硬件(例如磁盘)性能较低,那么 I/O 操作可能会成为瓶颈。在这种情况下,你可能需要升级你的硬件。
- 使用缓存 :如果你的应用主要是读操作,你可以考虑使用缓存来减轻数据库的负载。例如,你可以使用 Redis 的内存存储功能,或者使用其他的缓存系统。
注意,调整持久化策略或使用缓存都可能会增加数据丢失的风险,因此你需要根据你的应用需求和风险承受能力来选择合适的策略。
3.7 expires 淘汰过期数据
参考这篇文章《Redis系列18:过期数据的删除策略》,我们有详细的描述
Redis 有两种方式淘汰过期数据:
- 惰性删除:当接收请求的时候发现 key 已经过期,才执行删除;
- 定时删除:每 100 毫秒删除一些过期的 key。
定时任务的发起的频率由redis.conf配置文件中的hz来进行配置
# 代表每1s 运行 10次
hz 10
Redis 默认每 1 秒运行 10 次,也就是每 100 ms 执行一次,每次随机抽取一些设置了过期时间的 key(这边注意不是检查所有设置过期时间的key,而是随机抽取部分),检查是否过期,如果发现过期了就直接删除。
该定时任务的具体流程如下:
- 定时serverCron方法去执行清理,执行频率根据redis.conf中的hz配置的值
- 执行清理的时候,不是去扫描所有的key,而是去扫描所有设置了过期时间的key(redisDb.expires)
- 如果每次去把所有过期的key都拿过来,那么假如过期的key很多,就会很慢,所以也不是一次性拿取所有的key
- 根据hash桶的维度去扫描key,扫到20(可配)个key为止。假如第一个桶是15个key ,没有满足20,继续扫描第二个桶,第二个桶20个key,由于是以hash桶的维度扫描的,所以第二个扫到了就会全扫,总共扫描35个key
- 找到扫描的key里面过期的key,并进行删除
- 删除完检查过期的 key 超过 25%,继续执行4、5步
大家看最后一步,如果一致有超过25%的过期key,就会导致 Redis 一直去删除来释放内存,而删除是阻塞的。
所以,需要避免大量 key 过期早同一时期过期,这样可能需要重复删除多次才能降低到 25% 以下。
解决方案:
可以给缓存设置过期时间时加上一个随机值时间(在 EXPIREAT 和 EXPIRE 的过期时间参数上,加上一个一定大小范围内的随机数),使得每个key的过期时间分布开来,不会集中在同一时刻失效。
随机值我们团队的做法是:n * 3/4 + n * random() 。所以,比如你原本计划对一个缓存建立的过期时间为8小时,那就是6小时 + 0~2小时的随机值。
这样保证了均匀分布在 6~8小时之间。如图:

3.8 优化 bigkey
bigkey 是指含有较大数据或含有大量成员、列表数的 Key。以下是一些实际的例子:
- 一个 STRING Key 的Value过大,比如超过 5MB
- 一个 LIST 类型的 Key,它的List Size太大,比如10000 个
- 一个 ZSET 类型的 Key,它的Member Size太大,比如 10000 个
- 一个 HASH 格式的 Key,它的Member Size太大,比如 10000个,或者Value值总量过大,比如 100MB
bigkey 带来问题如下:
- OOM,或者达到 maxmemory 阈值导致请求阻塞或者key被驱逐。
- Redis Cluster 的数据负载最小粒度为 Key,这样如果某个node上有一个bigkey,就可能导致内存不均衡。
- bigkey 的读写都有有较大的带宽占用、内存占用,混合使用云主机情况下,会影响其他服务的资源存量。
- 删除一个 bigkey 造成主库较长时间的阻塞甚至引发同步中断或主从切换。
优化 Redis 的 bigkey 可以从以下几个方面入手:
- 拆分 bigkey:将一个含有大量成员、列表数或数据大小的 Key 拆分成多个小 Key,每个 Key 的成员数量或数据大小在合理范围内。这样可以避免单个 Key 占用过多内存,并且可以提高 Redis 的读写性能。
- 异步清理 bigkey:Redis 4.0 版本提供了 UNLINK 命令,可以用来安全地删除 bigkey,避免对 Redis 实例造成过大的负载。可以通过将 UNLINK 命令放在异步任务中执行,以避免对主线程造成阻塞。
- 使用更合适的数据结构:根据实际需求选择更合适的数据结构,比如使用哈希表(hash)代替字符串(string),使用有序集合(sorted set)代替列表(list)等。这样可以减少数据的内存占用,提高读写性能。
- 控制 key 的数量:尽量避免使用过多的 Key,尤其是在使用 Redis Cluster 时,过多的 Key 会导致数据分布不均,影响集群的性能和稳定性。
- 使用压缩功能:Redis 提供了压缩功能,可以将 bigkey 的数据进行压缩后再存储,减少内存占用和网络传输开销。但是需要注意的是,压缩和解压操作会增加 CPU 的负载,需要根据实际情况权衡利弊。
- 差异化过期时间:如果一批 key 的确是同时过期,可以在 EXPIREAT 和 EXPIRE 的过期时间参数上,加上一个一定大小范围内的随机数
3.9 其他原因
- 复杂度过高的命令或查询全量数据。
- 内存达到 maxmemory。
- 客户端使用短连接和 Redis 相连。
- Redis 实例的数据量大,导致生成 RDB 或 AOF 重写耗时严重。
- Redis 实例运行机器的内存不足,导致 swap 发生,Redis 需要到 swap 分区读取数据。
- 进程绑定 CPU 不合理。
- Redis 实例运行机器上开启了透明内存大页机制。
- 网卡压力过大。
- Redis 实例之间以及内部数据传输阻塞,包括客户端、磁盘、主从通信、切片集群通信等问题。
- 多 CPU 多核架构问题,包括绑核、绑 CPU 等。
- sql 语句执行阻塞,包括慢查询、过期 key 等问题。
4 总结
优化步骤如下:
-
获取 Redis 的基线延迟情况
-
开启慢指令监控,定位慢指令导致的问题,分析并优化。
-
开启慢请求日志,分析执行时间超时情况,以便分析和优化。
-
解决常见的Redis慢执行问题
- 网络通信延迟
- 慢指令导致的延迟
- Fork 生成 RDB 导致的延迟
- AOF 文件系统或 RDB 大内存页问题,包括 AOF 持久化阻塞、大内存页等
- 操作系统 Swap 操作问题,包括内存磁盘数据转换、内存清理等
- 对swap导致的性能问题进行排查
- AOF 的写回策略为 always,导致每个操作都要同步刷回磁盘
- expires 淘汰过期数据
- 优化 bigkey
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
