集中式应用进行服务化拆分后,必然会出现一个问题:如何保证各个节点(Node)之间的数据一致性?
比如以下场景:
用户首先发起一次更新操作,映射到节点A;然后,用户又做了一次查询操作,操作映射到了节点B,此时A和B的数据如果不一致,对用户来说就会造成困扰。
分布式系统为了提高可用性,必然会引入 冗余机制(副本) ,而冗余便带来了上面描述的一致性问题。为了解决这类问题,加州大学伯克利分校的Eric Brewer) 教授提出了 CAP 猜想。2年后, Seth Gilbert 和 Nancy Lynch 从理论上证明了猜想的可能性。从此,CAP 理论正式在学术上成为了分布式计算领域的公认定理。
一、CAP三指标
CAP 理论是一个很好的思考框架,它对分布式系统的特性做了高度抽象,抽象成了 一致性 、 可用性 和 分区容错性 ,并对特性间的冲突做了总结。一旦掌握它,我们自然而然就能根据业务场景的特点进行权衡,设计出适合的系统模型。

我们先来看看CAP理论中三个指标的含义。
1.1 一致性(Consistence)
一致性,指的是客户端的每次读操作,不管访问哪个节点,要么读到的都是同一份最新数据,要么读取失败。
注意,一致性是站在客户端的视角出发的,并不是说在某个时间点分布式系统的所有节点的数据是一致的。事实上,在一个事务执行过程中,系统就是处于一种不一致状态,但是客户端是无法读取事务未提交的数据的,此时客户端会直接读取失败。
CAP理论中的一致性是强一致性,举个例子来理解下:
初始时,节点1和节点2的数据是一致的,然后客户端向节点1写入了新数据“X = 2”:

节点1在本地更新数据后,通过节点间的通讯,同步数据到节点2,确认节点2写入成功后,然后返回成功给客户端:

这样两个节点的数据就是一致的了,之后,不管客户端访问哪个节点,读取到的都是同一份最新数据。如果节点2在同步数据的过程中,有另外的客户端来访问任意节点,都会拒绝,这就是强一致性。
1.2 可用性(Availability)
可用性,指的是客户端的请求,不管访问哪个节点,都能得到响应数据,但不保证是同一份最新数据。你也可以把可用性看作是分布式系统对访问本系统的客户端的另外一种承诺: 我尽力给你返回数据,不会不响应你,但是我不保证每个节点给你的数据都是最新的 。
这个指标强调的是服务可用,但不保证数据的一致。
1.3 分区容错性(Network partitioning)
分区容错性,指的是当节点间出现消息丢失、高延迟或者已经发生网络分区时,系统仍然可以继续提供服务。也就是说,分布式系统在告诉访问本系统的客户端: 不管我的内部出现什么样的数据同步问题,我会一直运行,提供服务 。
分区容错性,强调的是集群对分区故障的容错能力。 因为分布式系统与单机系统不同,它涉及到多节点间的通讯和交互,节点间的分区故障是必然发生的,所以在分布式系统中分区容错性是必须要考虑的。
既然分区容错是必须要考虑的,那么这时候系统该如何运行呢?是选择一致性(C)呢,还是选择可用性(P)呢?这就引出了著名的“CAP不可能三角”。
二、CA/CP/AP选择
所谓“CAP不可能三角”,其实就是CAP理论中提到的: 对于一个分布式系统而言,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)3 个指标不可兼得,只能在 3 个指标中选择 2 个 。
上面说过了,因为只要有网络交互就一定会有延迟和数据丢失,而这种状况我们必须接受,同时还必须保证系统不能挂掉,所以节点间的分区故障是必然发生的。也就是说,分区容错性(P)是前提,是必须要保证的。
所以理论上CAP一般只能取CP或AP,CA只存在于集中式应用中。
2.1 CP架构
当选择了一致性(C)的时候,如果因为消息丢失、延迟过高发生了网络分区,那么这个时候,当集群节点接收到来自客户端的写请求时,因为无法保证所有节点都是最新信息,所以系统将返回写失败错误,也就是说集群拒绝新数据写入。
如下图,T1时刻,客户端往节点A写入 Message 2 ,此时发生了网络分区,节点A的数据无法同步到节点B;T2时刻,如果客户端分别读取了节点A和节点B的数据,就会出现数据不一致。
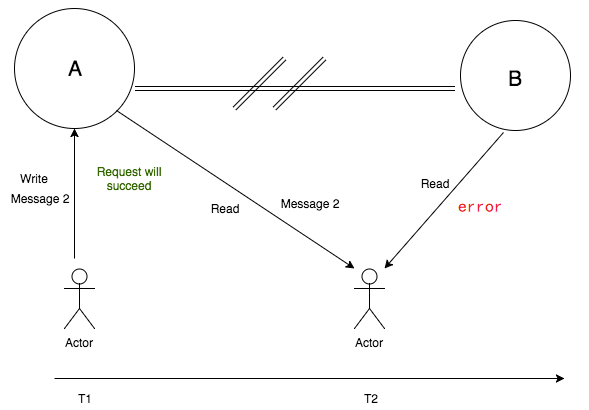
此时,为了保证一致性(C),客户端从节点B读取数据时,节点B应当返回 error ,提示客户端”系统发生了错误”,这种方式相当于放弃了可用性(A),此时CAP三者只能满足CP。
2.2 AP架构
当选择了可用性(A)的时候,系统将始终处理客户端的查询,返回特定信息,如果发生了网络分区,一些节点将无法返回最新的特定信息,它们将返回自己当前的相对新的信息。
如下图,T1时刻,客户端往节点A写入 Message 2 ,此时发生了网络分区,节点A的数据无法同步到节点B;T2时刻,客户端访问节点B时,节点B将自己当前拥有的数据 Message 1 返回给客户端,而实际上当前最新数据已经是 Message2 了,这就不满足一致性(C),此时CAP三者只能满足AP。

注意:这里节点B返回的 Message 1 虽然不是一个”正确“的结果,但是一个”合理“的结果,因为节点B只是返回的不是最新结果,并不是一个错乱的值。
三、总结
本章,我对CAP理论进行了基本的讲解,总结一下:
- CA 模型:在分布式系统中不存在,因为舍弃 P,意味着舍弃分布式系统,就比如单机版关系型数据库 MySQL,如果 MySQL 要考虑主备或集群部署时,它必须考虑 P。
- CP 模型:采用 CP 模型的分布式系统,一旦因为消息丢失、延迟过高发生了网络分区,就影响用户的体验和业务的可用性。因为为了防止数据不一致,集群将拒绝新数据的写入,典型的应用是 ZooKeeper,Etcd 和 HBase。
- AP 模型:采用 AP 模型的分布式系统,实现了服务的高可用。用户访问系统的时候,都能得到响应数据,不会出现响应错误,但当出现分区故障时,相同的读操作,访问不同的节点,得到响应数据可能不一样。典型应用就比如 Cassandra 和 DynamoDB。
最后,关于CAP 理论有个误解:就是认为无论在什么情况下,分布式系统都只能在 C 和 A 中选择 1 个。 事实上,在不存在网络分区的情况下(也就是分布式系统正常运行时),C 和 A 能够同时保证。只有当发生分区故障的时候,也就是说需要 P 时,才会在 C 和 A 之间做出选择。
所以,我们在进行系统设计时,需要根据实际的业务场景, 在一致性和可用性之间做出权衡。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
