nacos数据一致性服务执行流程
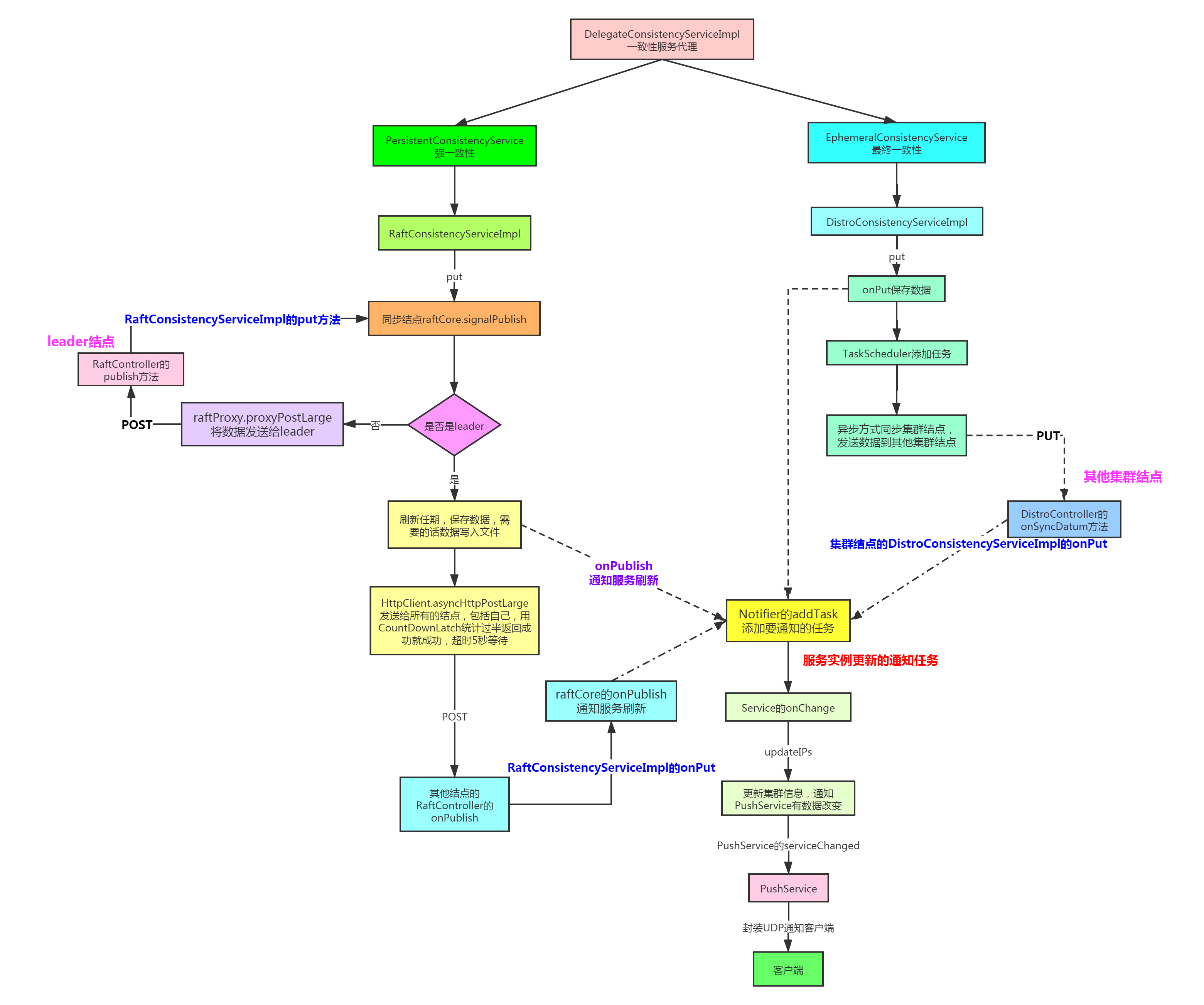
数据一致性
其实nacos内部提供两种数据同步方案AP和CP,而且是混用的,只要你的实例是临时的默认用AP,如果是永久的要就用CP。两个数据一致性服务的处理器类结构:
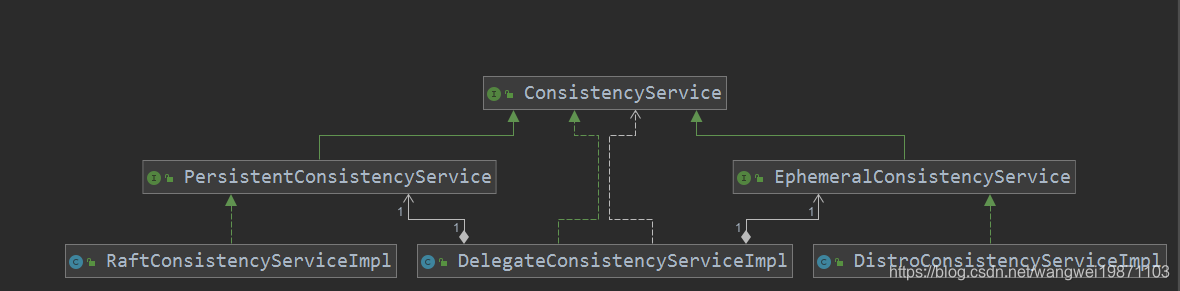
可以看到,左边的RaftConsistencyServiceImpl就是CP的实现类,右边的DistroConsistencyServiceImpl就是AP的实现类,我们注册实例的时候通常是DelegateConsistencyServiceImpl来帮助我们判断该用临时的还是永久的服务,其实他内部就是代理这两个:
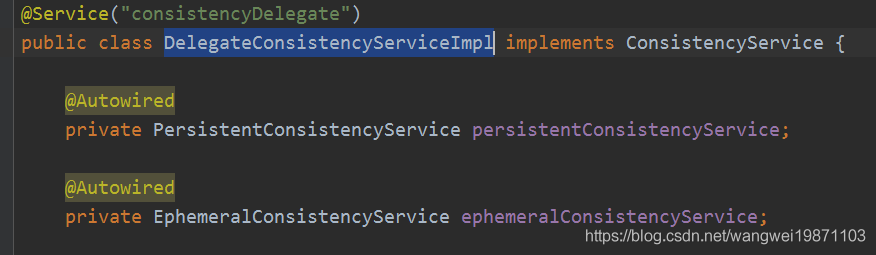
具体怎么同步的,我们先来讲AP的TaskScheduler任务同步。
TaskScheduler的run临时数据同步
只要有服务实例的改变,就会让最终一致性服务去做数据同步,其实就是放进一个队列里,然后同步任务从队列中获取要同步的服务key,然后判断数量是不是超过1000或者超时2秒了,是的话就创建SyncTask同步任务并提交,给每一个服务器集群去同步,其实这个属于最终一致性的同步方案。
@Override
public void run() {
List<String> keys = new ArrayList<>();
while (true) {
try {
//阻塞2秒获取key
String key = queue.poll(partitionConfig.getTaskDispatchPeriod(),
TimeUnit.MILLISECONDS);
//不为空,表示获取到了
if (Loggers.DISTRO.isDebugEnabled() && StringUtils.isNotBlank(key)) {
Loggers.DISTRO.debug("got key: {}", key);
}
//没有服务器继续
if (dataSyncer.getServers() == null || dataSyncer.getServers().isEmpty()) {
continue;
}
//为空继续
if (StringUtils.isBlank(key)) {
continue;
}
//还没数据
if (dataSize == 0) {
keys = new ArrayList<>();
}
keys.add(key);
dataSize++;//数据+1
//达到分区批量同步数,默认1000个或者同步时间超时,默认2秒
if (dataSize == partitionConfig.getBatchSyncKeyCount() ||
(System.currentTimeMillis() - lastDispatchTime) > partitionConfig.getTaskDispatchPeriod()) {
//获取所有集群服务器
for (Server member : dataSyncer.getServers()) {
if (NetUtils.localServer().equals(member.getKey())) {//本机不同步
continue;
}
SyncTask syncTask = new SyncTask();
syncTask.setKeys(keys);//发送的服务key
syncTask.setTargetServer(member.getKey());//发送的目标,IP:port
if (Loggers.DISTRO.isDebugEnabled() && StringUtils.isNotBlank(key)) {
Loggers.DISTRO.debug("add sync task: {}", JSON.toJSONString(syncTask));
}
//提交同步任务
dataSyncer.submit(syncTask, 0);
}
lastDispatchTime = System.currentTimeMillis();//重置
dataSize = 0;
}
} catch (Exception e) {
Loggers.DISTRO.error("dispatch sync task failed.", e);
}
}
}
DataSyncer的submit
提交一个同步任务,如果是新任务的话要去重,删除新的key,因为有可能会有相同的key的任务在重试或者等待重试。然后进行相关key的服务实例集合获取,序列化后同步到目标服务器,如果失败的话还要重试,成功就删除任务返回。
public void submit(SyncTask task, long delay) {
// If it's a new task:
if (task.getRetryCount() == 0) {//新的任务
Iterator<String> iterator = task.getKeys().iterator();
while (iterator.hasNext()) {//去重
String key = iterator.next();
if (StringUtils.isNotBlank(taskMap.putIfAbsent(buildKey(key, task.getTargetServer()), key))) {//已经存在的
// associated key already exist:
if (Loggers.DISTRO.isDebugEnabled()) {
Loggers.DISTRO.debug("sync already in process, key: {}", key);
}
iterator.remove();//删除新的任务里的key,理论上应该是删除旧的,但是此时旧的可能已经在执行了,所以删除新的
}
}
}
if (task.getKeys().isEmpty()) {
// all keys are removed:
return;
}
//全局执行器执行数据同步任务
GlobalExecutor.submitDataSync(() -> {
// 1. check the server
if (getServers() == null || getServers().isEmpty()) {
Loggers.SRV_LOG.warn("try to sync data but server list is empty.");
return;
}
List<String> keys = task.getKeys();
if (Loggers.SRV_LOG.isDebugEnabled()) {
Loggers.SRV_LOG.debug("try to sync data for this keys {}.", keys);
}
// 这里又会去重一次,应该keys里可能有重复的,但是里面获取的时候去重了
Map<String, Datum> datumMap = dataStore.batchGet(keys);
if (datumMap == null || datumMap.isEmpty()) {//服务实例集合空了就删除相应任务
// clear all flags of this task:
for (String key : keys) {
taskMap.remove(buildKey(key, task.getTargetServer()));
}
return;
}
byte[] data = serializer.serialize(datumMap);//服务实例集合序列化
long timestamp = System.currentTimeMillis();
boolean success = NamingProxy.syncData(data, task.getTargetServer());//发送
if (!success) {//失败就重试
SyncTask syncTask = new SyncTask();
syncTask.setKeys(task.getKeys());
syncTask.setRetryCount(task.getRetryCount() + 1);
syncTask.setLastExecuteTime(timestamp);
syncTask.setTargetServer(task.getTargetServer());
retrySync(syncTask);
} else {//成功了就删除任务
// clear all flags of this task:
for (String key : task.getKeys()) {
taskMap.remove(buildKey(key, task.getTargetServer()));
}
}
}, delay);
}
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
