
概述
在计算机系统中,加密与安全是至关重要的概念。
想象一下,当B想要发送一封邮件给A时,邮件可能在传送过程中遭到黑客的窃听,这就需要 防止信息泄露 。此外,黑客还可能篡改邮件内容,因此A需要确保她能够辨别出邮件是 否被篡改 。最后,黑客可能会冒充B发送虚假邮件给A,这需要A有能力 辨别真伪 。
为了应对这些潜在的安全威胁,我们需要采取以下三项措施:
- 防止窃听
- 防止篡改
- 防止伪造
计算机加密技术旨在实现上述目标。现代计算机密码学建立在严格的数学理论基础上,并逐渐发展成为一门科学。对于大多数开发者来说,设计安全的加密算法是一项艰巨的任务,验证加密算法的安全性则更加困难。目前认为安全的加密算法也只是尚未被攻破。因此,为了编写安全的计算机程序,我们应遵循以下原则:
- 不要设计自己的加密算法
- 不要自行实现已有的加密算法
- 不要修改已有的加密算法
接下来,我们将一起探讨最常用的加密算法,以及Java实现。
什么是编码
编码是一种将符号、文字或其他数据转换为特定格式或标准的过程。
编码是计算机科学中的一个重要概念,它指的是将符号、文字或其他数据转换为特定格式或标准的过程。这种转换是为了方便存储、传输和处理数据。编码可以涵盖多种形式,包括数字编码、字符编码、图像编码、音频编码等。
数字编码是将数字转换为计算机可以理解的二进制形式的过程,通常涉及将十进制数字转换为二进制或其他进制的表示形式。
字符编码是将字符映射到数字或比特序列的过程,以便计算机能够处理和存储文本数据。常见的字符编码包括ASCII(美国信息交换标准代码)、Unicode等。
图像编码是将图像数据转换为计算机可识别的格式的过程,常见的图像编码包括JPEG、PNG、GIF等。
音频编码是将声音数据转换为数字形式的过程,以便计算机可以处理和存储音频数据。常见的音频编码包括MP3、AAC、WAV等。
通过编码,我们能够将各种类型的数据转换为计算机可以处理的形式,从而实现数据的存储、传输和处理。

编码分类
ASCII码 (最多只能有128个字符)
ASCII码( American Standard Code for Information Interchange,美国信息交换标准代码 ) 就是一种常见的字符编码标准。在ASCII码中,每个字符都被赋予一个唯一的数值表示,通常是一个字节(8位)。
例如,字母’A’的ASCII编码是十六进制的0x41,字母’B’是0x42,字母’C’是0x43,以此类推。ASCII码包含了标准的英文字母、数字、标点符号以及一些控制字符的编码,共计128个字符。
下面是一些常见字符的ASCII编码示例:
| 字符 | ASCII编码 |
|---|---|
| A | 0x41 |
| B | 0x42 |
| C | 0x43 |
| D | 0x44 |
| … | … |
字母’A’的ASCII编码为0x41,这是因为ASCII编码是一种固定长度的字符编码标准,用一个字节(8位)表示一个字符。在ASCII编码中,大写字母’A’的编码是65,换算成十六进制就是0x41。
ASCII编码是根据英语字母表中的顺序进行编码的,因此大写字母’A’在ASCII编码中是排在字母表的第一个位置,其对应的十进制数值为65,换算成十六进制即为0x41。
Code: 字符转换成ascii码
public static void main(String[] args) {
char a = 'a';
int b = a;
// 打印b,在ascii当中十进制的数字对应是多少
System.out.println(b);
// 定义字符串
String aaZ = "Artisan";
// 需要拆开字符串
char[] chars = aaZ.toCharArray();
for (char aChar : chars) {
int asciicode = aChar;
System.out.println(asciicode);
}
}

ASCII码对照表
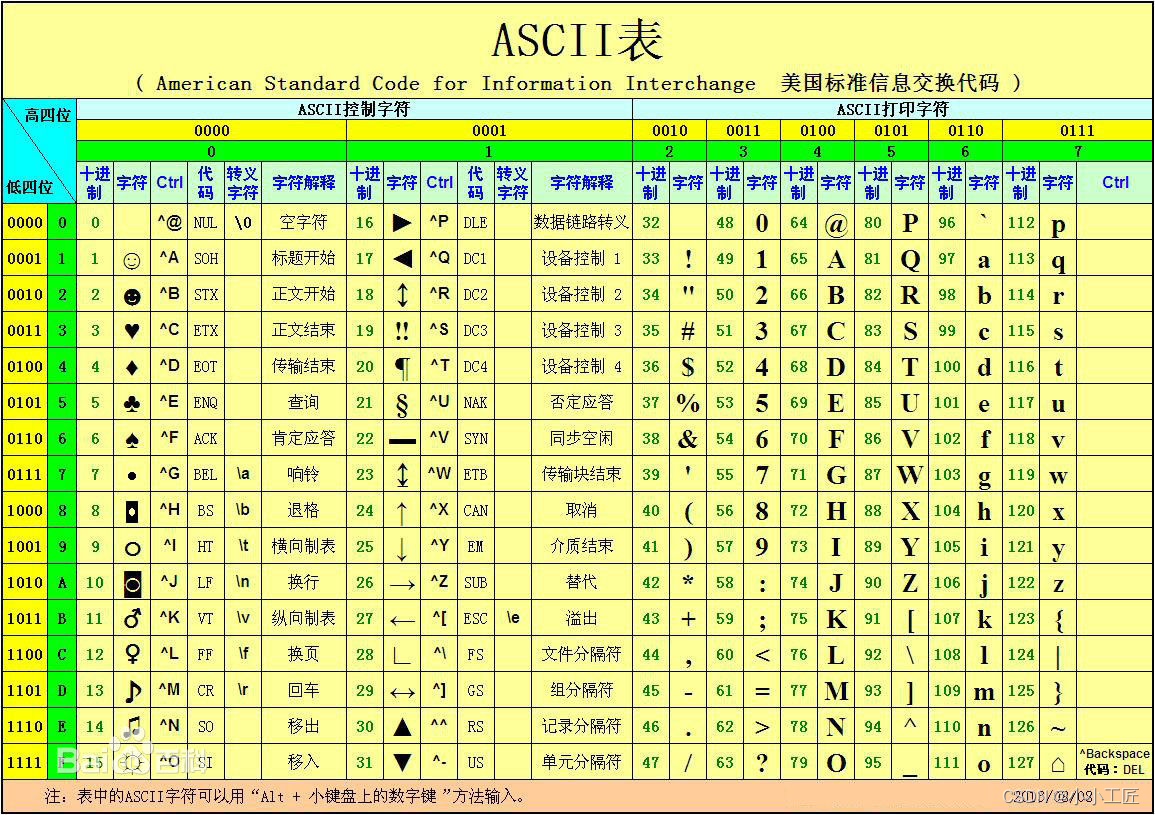
| 二进制 | 十进制 | 十六进制 | 字符/缩写 | 解释 |
|---|---|---|---|---|
| 00000000 | 0 | 00 | NUL(NULL) | 空字符 |
| 00000001 | 1 | 01 | SOH | 标题开始 |
| 00000010 | 2 | 02 | STX | 正文开始 |
| 00000011 | 3 | 03 | ETX | 正文结束 |
| 00000100 | 4 | 04 | EOT | 传输结束 |
| 00000101 | 5 | 05 | ENQ | 请求 |
| 00000110 | 6 | 06 | ACK | 回应/响应/收到通知 |
| 00000111 | 7 | 07 | BEL | 响铃 |
| 00001000 | 8 | 08 | BS | 退格 |
| 00001001 | 9 | 09 | HT | 水平制表符 |
| 00001010 | 10 | 0A | LF/NL | 换行键 |
| 00001011 | 11 | 0B | VT | 垂直制表符 |
| 00001100 | 12 | 0C | FF/NP | 换页键 |
| 00001101 | 13 | 0D | CR | 回车键 |
| 00001110 | 14 | 0E | SO | 不用切换 |
| 00001111 | 15 | 0F | SI | 启用切换 |
| 00010000 | 16 | 10 | DLE | 数据链路转义 |
| 00010001 | 17 | 11 | DC1/XON | 设备控制1/传输开始 |
| 00010010 | 18 | 12 | DC2 | 设备控制2 |
| 00010011 | 19 | 13 | DC3/XOFF | 设备控制3/传输中断 |
| 00010100 | 20 | 14 | DC4 | 设备控制4 |
| 00010101 | 21 | 15 | NAK | 无响应/非正常响应/拒绝接收 |
| 00010110 | 22 | 16 | SYN | 同步空闲 |
| 00010111 | 23 | 17 | ETB | 传输块结束/块传输终止 |
| 00011000 | 24 | 18 | CAN | 取消 |
| 00011001 | 25 | 19 | EM | 已到介质末端/介质存储已满/介质中断 |
| 00011010 | 26 | 1A | SUB | 替补/替换 |
| 00011011 | 27 | 1B | ESC | 逃离/取消 |
| 00011100 | 28 | 1C | FS | 文件分割符 |
| 00011101 | 29 | 1D | GS | 组分隔符/分组符 |
| 00011110 | 30 | 1E | RS | 记录分离符 |
| 00011111 | 31 | 1F | US | 单元分隔符 |
| 00100000 | 32 | 20 | (Space) | 空格 |
| 00100001 | 33 | 21 | ! | |
| 00100010 | 34 | 22 | " | |
| 00100011 | 35 | 23 | # | |
| 00100100 | 36 | 24 | $ | |
| 00100101 | 37 | 25 | % | |
| 00100110 | 38 | 26 | & | |
| 00100111 | 39 | 27 | ’ | |
| 00101000 | 40 | 28 | ( | |
| 00101001 | 41 | 29 | ) | |
| 00101010 | 42 | 2A | * | |
| 00101011 | 43 | 2B | + | |
| 00101100 | 44 | 2C | , | |
| 00101101 | 45 | 2D | - | |
| 00101110 | 46 | 2E | . | |
| 00101111 | 47 | 2F | / | |
| 00110000 | 48 | 30 | 0 | |
| 00110001 | 49 | 31 | 1 | |
| 00110010 | 50 | 32 | 2 | |
| 00110011 | 51 | 33 | 3 | |
| 00110100 | 52 | 34 | 4 | |
| 00110101 | 53 | 35 | 5 | |
| 00110110 | 54 | 36 | 6 | |
| 00110111 | 55 | 37 | 7 | |
| 00111000 | 56 | 38 | 8 | |
| 00111001 | 57 | 39 | 9 | |
| 00111010 | 58 | 3A | : | |
| 00111011 | 59 | 3B | ; | |
| 00111100 | 60 | 3C | < | |
| 00111101 | 61 | 3D | = | |
| 00111110 | 62 | 3E | > | |
| 00111111 | 63 | 3F | ? | |
| 01000000 | 64 | 40 | @ | |
| 01000001 | 65 | 41 | A | |
| 01000010 | 66 | 42 | B | |
| 01000011 | 67 | 43 | C | |
| 01000100 | 68 | 44 | D | |
| 01000101 | 69 | 45 | E | |
| 01000110 | 70 | 46 | F | |
| 01000111 | 71 | 47 | G | |
| 01001000 | 72 | 48 | H | |
| 01001001 | 73 | 49 | I | |
| 01001010 | 74 | 4A | J | |
| 01001011 | 75 | 4B | K | |
| 01001100 | 76 | 4C | L | |
| 01001101 | 77 | 4D | M | |
| 01001110 | 78 | 4E | N | |
| 01001111 | 79 | 4F | O | |
| 01010000 | 80 | 50 | P | |
| 01010001 | 81 | 51 | Q | |
| 01010010 | 82 | 52 | R | |
| 01010011 | 83 | 53 | S | |
| 01010100 | 84 | 54 | T | |
| 01010101 | 85 | 55 | U | |
| 01010110 | 86 | 56 | V | |
| 01010111 | 87 | 57 | W | |
| 01011000 | 88 | 58 | X | |
| 01011001 | 89 | 59 | Y | |
| 01011010 | 90 | 5A | Z | |
| 01011011 | 91 | 5B | [ | |
| 01011100 | 92 | 5C | \ | |
| 01011101 | 93 | 5D | ] | |
| 01011110 | 94 | 5E | ^ | |
| 01011111 | 95 | 5F | _ | |
| 01100000 | 96 | 60 | ` | |
| 01100001 | 97 | 61 | a | |
| 01100010 | 98 | 62 | b | |
| 01100011 | 99 | 63 | c | |
| 01100100 | 100 | 64 | d | |
| 01100101 | 101 | 65 | e | |
| 01100110 | 102 | 66 | f | |
| 01100111 | 103 | 67 | g | |
| 01101000 | 104 | 68 | h | |
| 01101001 | 105 | 69 | i | |
| 01101010 | 106 | 6A | j | |
| 01101011 | 107 | 6B | k | |
| 01101100 | 108 | 6C | l | |
| 01101101 | 109 | 6D | m | |
| 01101110 | 110 | 6E | n | |
| 01101111 | 111 | 6F | o | |
| 01110000 | 112 | 70 | p | |
| 01110001 | 113 | 71 | q | |
| 01110010 | 114 | 72 | r | |
| 01110011 | 115 | 73 | s | |
| 01110100 | 116 | 74 | t | |
| 01110101 | 117 | 75 | u | |
| 01110110 | 118 | 76 | v | |
| 01110111 | 119 | 77 | w | |
| 01111000 | 120 | 78 | x | |
| 01111001 | 121 | 79 | y | |
| 01111010 | 122 | 7A | z | |
| 01111011 | 123 | 7B | { | |
| 01111100 | 124 | 7C | ||
| 01111101 | 125 | 7D | } | |
| 01111110 | 126 | 7E | ~ | |
| 01111111 | 127 | 7F | DEL | 删除 |
Unicode (用于表示世界上几乎所有的文字和符号)
Unicode是一种广泛使用的字符编码标准,用于表示世界上几乎所有的文字和符号 。相比于ASCII编码的128个字符,Unicode可以表示更多的字符,包括中文、日文、阿拉伯文等。
中文的Unicode编码示例如下:
| 汉字 | Unicode编码 | UTF-8编码 |
|---|---|---|
| 中 | 0x4e2d | 0xe4b8ad |
| 文 | 0x6587 | 0xe69687 |
| 编 | 0x7f16 | 0xe7bc96 |
| 码 | 0x7801 | 0xe7a081 |
| … | … | … |
另外,UTF-8是一种变长编码,用于将Unicode字符编码成字节序列 。对于英文字符,UTF-8使用一个字节表示,而对于中文等Unicode字符,则需要多个字节来表示。例如, 汉字’中’的UTF-8编码是0xe4b8ad,它需要3个字节来表示 。
UTF-8编码的复杂性在于它是一种不定长编码,字符的编码长度取决于Unicode编码的范围。但是,通过给定字符的Unicode编码,可以推算出它在UTF-8编码中所占用的字节数。
URL编码 (解决服务器只能识别ASCII字符的问题)
URL编码是一种用于在URL中传输数据时使用的编码方式。它通常被用于对URL的参数部分进行编码,以确保传输的数据符合URL的规范。举例来说:
如果我们想在URL中传输非ASCII字符,比如中文或日文等,由于许多服务器只能识别ASCII字符,因此我们需要对这些非ASCII字符进行编码。URL编码就是为了解决这个问题而设计的 。
URL编码的规则如下:
- 对于
A~Z、a~z、0~9以及-、_、.、*这些字符,保持不变; - 对于其他字符,首先转换为其对应的UTF-8编码,然后将每个字节表示为%XX的形式。
- URL编码总是使用大写字母表示
举例来说,如果字符中的UTF-8编码是0xe4b8ad,那么它的URL编码就是%E4%B8%AD
举个例子
https://www.artisan.com/s?wd=%E4%B8%AD%E6%96%87

其实就是 https://www.artisan.com/s?wd=中文
实现:编码_URLEncoder
package com.artisan.securityalgjava.urlencode;
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/
public class UrlEncoderTest {
public static void main(String[] args) throws UnsupportedEncodingException {
// 编码
String result = URLEncoder.encode("中文!", StandardCharsets.UTF_8.toString());
System.out.println(result);
}
}

中的URL编码是%E4%B8%AD,文的URL编码是%E6%96%87,!虽然是ASCII字符,也要对其编码为%21
和标准的URL编码稍有不同,URLEncoder把空格字符编码成+,而现在的URL编码标准要求空格被编码为%20, 服务器都可以处理这两种情况
实现: 解码_URLDecoder
URL编码的字符串对其进行解码还原成原始字符串
// 解码
String decode = URLDecoder.decode("%E4%B8%AD%E6%96%87%21", StandardCharsets.UTF_8.toString());
System.out.println(decode);

小结
URL编码是编码算法,不是加密算法。URL编码的目的是把任意文本数据编码为%前缀表示的文本,编码后的文本仅包含A~Z,a~z,0~9,-,_,.,*和%,便于浏览器和服务器处理。
Base64编码
Base64 编码是一种将二进制数据编码为文本格式的方法,它可以将任意长度的二进制数据转换为纯文本,并且只包含一组特定的字符集,包括 A~Z、a~z、0~9、+、/、=。
Base64 编码的原理是将 3 字节的二进制数据按照 6 位一组进行分组,然后将每组 6 位的二进制数转换为对应的整数,再根据整数对应的索引查表,将索引对应的字符拼接起来,得到编码后的字符串。
具体步骤如下:
- 将原始二进制数据每 3 个字节分为一组。
- 将每组 3 个字节转换为 4 个 6 位的二进制数。
- 将每个 6 位的二进制数转换为对应的整数。
- 将每个整数使用查表的方式映射到对应的字符集合中的字符。
- 将得到的字符拼接成一个字符串作为 Base64 编码结果。
由于 Base64 编码的特性,它常用于在网络上传输数据,例如在电子邮件中传输二进制文件或在网页中嵌入图片等。由于其将二进制数据编码为文本的特点,使得它可以直接作为文本传输,而无需担心编码后的数据会包含特殊字符或控制字符。
举个例子:3个byte数据分别是e4、b8、ad,按 6 bit分组得到39、0b、22、2d
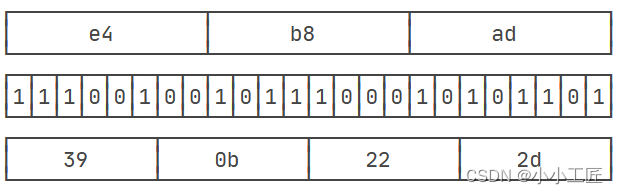
6位整数的范围总是
0~63,所以,能用64个字符表示:字符A~Z对应索引0~25,字符a~z对应索引26~51,字符0~9对应索引52~61,最后两个索引62、63分别用字符+和/表示
实现:编码_Base64.getEncoder()
package com.artisan.securityalgjava.base64;
import java.util.Arrays;
import java.util.Base64;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/
public class Base64Test {
public static void main(String[] args) {
// 创建一个包含中文字符 "中" 的字节数组
byte[] bytes = {(byte) 0xe4, (byte) 0xb8, (byte) 0xad};
// 使用 Base64 编码器将字节数组转换为 Base64 字符串
String result = Base64.getEncoder().encodeToString(bytes);
System.out.println(result);
}
}

实现:解码_Base64.getDecoder
package com.artisan.securityalgjava.base64;
import java.util.Arrays;
import java.util.Base64;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/
public class Base64Test {
public static void main(String[] args) {
// 创建一个包含中文字符 "中" 的字节数组
byte[] bytes = {(byte) 0xe4, (byte) 0xb8, (byte) 0xad};
// 使用 Base64 编码器将字节数组转换为 Base64 字符串
String result = Base64.getEncoder().encodeToString(bytes);
System.out.println(result);
// 使用 Base64 解码器将 Base64 字符串解码为字节数组
byte[] decode = Base64.getDecoder().decode(result);
System.out.println(Arrays.toString(decode));
}
}
将包含中文字符 “中” 的字节数组进行 Base64 编码,然后再解码回原始字节数组,并打印结果。
byte[]数组长度不是3的整数倍
如果输入的byte[]数组长度不是3的整数倍真么办?这种情况下,需要对输入的末尾补一个或两个0x00, 编码后,在结尾加一个=表示补充了1个0x00,加两个=表示补充了2个0x00,解码的时候,去掉末尾补充的一个或两个0x00即可 。
实际上,因为编码后的长度加上=总是4的倍数,所以即使不加=也可以计算出原始输入的byte[]
看代码
import java.util.Arrays;
import java.util.Base64;
public class Base64Test {
// 定义一个静态方法用于测试 Base64 编码和解码
static void testCase() {
// 输入的字节数组,包含一个中文字符和一个 ASCII 字符
byte[] input = new byte[] { (byte) 0xe4, (byte) 0xb8, (byte) 0xad, 0x21 };
// 使用 Base64 编码器将字节数组转换为 Base64 字符串
String b64encoded = Base64.getEncoder().encodeToString(input);
// 使用 Base64 编码器进行无填充的 Base64 编码
String b64encoded2 = Base64.getEncoder().withoutPadding().encodeToString(input);
// 打印两种编码结果
System.out.println("Base64 编码结果1: " + b64encoded);
System.out.println("Base64 编码结果2: " + b64encoded2);
// 使用 Base64 解码器将 Base64 字符串解码为字节数组
byte[] output = Base64.getDecoder().decode(b64encoded2);
// 打印解码后的字节数组
System.out.println("解码后的字节数组: " + Arrays.toString(output));
}
public static void main(String[] args) {
// 调用测试方法
testCase();
}
}

Base64.getUrlEncoder()
标准的 Base64 编码在某些场景下不适合在 URL 中使用 ,因为它会包含字符 +、/ 和 =,而这些字符在 URL 中可能会引起解析错误或歧义。
为了解决这个问题,可以使用一种 针对 URL 的 Base64 编码 ,它对标准的 Base64 编码做了简单的修改,即将 + 替换为 -,将 / 替换为 _,从而避免了在 URL 中可能引起问题的字符。
这种修改后的 Base64 编码仍然可以通过标准的 Base64 解码器进行解码,因为这两种编码方式只是字符替换的差异,不影响原始数据的编码规则和解码逻辑。
base64 是 3个字节为一组,一个字节 8位,一共 就是24位 ,然后,把3个字节转成4组,每组6位,
3 * 8 = 4 * 6 = 24 ,每组6位,缺少的2位,会在高位进行补0 ,这样做的好处在于 ,base取的是后面6位,去掉高2位 ,那么base64的取值就可以控制在0-63位了,所以就叫base64,111 111 = 32 + 16 + 8 + 4 + 2 + 1 =
static void urlEncoder() {
// 创建一个字节数组作为输入数据
byte[] input = new byte[]{0x01, 0x02, 0x7f, 0x00};
// 使用 URL 安全的 Base64 编码器将字节数组转换为 Base64 字符串
String result = Base64.getUrlEncoder().encodeToString(input);
System.out.println("URL 编码结果: " + result);
// 使用 URL 安全的 Base64 解码器将 Base64 字符串解码为字节数组
byte[] decode = Base64.getUrlDecoder().decode(result);
System.out.println("解码后的字节数组: " + Arrays.toString(decode));
}
演示了如何使用 URL 安全的 Base64 编码器将字节数组进行编码,以及如何使用相应的解码器将编码后的 Base64 字符串解码回原始的字节数组。URL 安全的 Base64 编码会将 + 替换为 -,将 / 替换为 _,以避免在 URL 中可能引起问题的字符。
0x01, 0x02, 0x7f, 0x00 是十六进制表示法,表示了四个字节的值。在 Java 中,0x 前缀表示后面的数字是十六进制数。
0x01表示十进制数值为 10x02表示十进制数值为 20x7f表示十进制数值为 1270x00表示十进制数值为 0
因此,input 这个字节数组包含了四个字节,分别是 1、2、127 和 0。

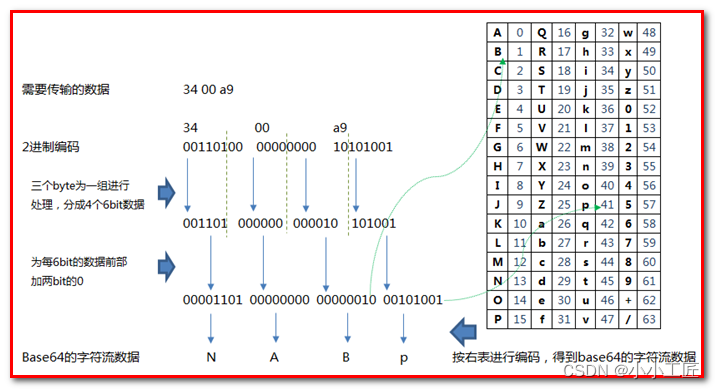
base64 构成原则
① 小写 a - z = 26个字母
② 大写 A - Z = 26个字母
③ 数字 0 - 9 = 10 个数字
④ + / = 2个符号
我们发现base64有个 = 号,但是在映射表里面没有发现 = 号 , 这个地方需要注意,等号非常特殊,因为base64是三个字节一组 ,如果当我们的位数不够的时候,会使用等号来补齐
小结
Base64 编码是一种常用的 将二进制数据转换为文本数据的方法 ,适用于需要在文本环境中传输二进制数据的场景,比如电子邮件、XML 数据传输等。
然而, Base64 编码会将原始数据的长度增加约 1/3,这会降低传输效率 。因此,在一些对传输效率要求较高的场景下,可能会选择其他更高效的编码方式,比如 Base32、Base48 或 Base58 编码。这些编码方式可以根据实际需求选择字符集合的大小,以权衡编码效率和字符集合大小之间的关系。不过,无论是哪种编码方式,它们都是一种编码算法,而不是加密算法,因为它们不会对数据进行加密,只是将数据转换成不同的形式。
总结
- URL 编码是一种编码算法,其目的是将任意文本数据编码为
%前缀表示的文本形式,以便在网络中传输,特别是用于浏览器和服务器之间的通信,以处理一些特殊字符或者非 ASCII 字符。 - Base64 编码同样是一种编码算法,它将任意二进制数据编码为文本形式,方便在文本环境中传输,但编码后的数据量会增加原始数据的约 1/3。这种编码在很多场景中使用,比如电子邮件、XML 数据传输等,以便在文本协议中传输二进制数据。
虽然它们都是编码算法而不是加密算法,但它们在不同的场景中有着不同的用途和目的。

Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
