本章,我将讲解Hystrix的第一个核心功能——资源隔离。Hystrix 采用了 Bulkhead Partition 舱壁隔离技术,来对外部依赖进行资源隔离,进而避免任何外部依赖的故障导致本服务的崩溃。
Hystrix进行资源隔离的基本思想是: 将对某一个依赖服务的所有调用请求,全部隔离在同一份资源池内,不会去用其它的资源 ,一共有两种实现方案:线程池隔离和信号量隔离。
不理解?没关系,我们先来看下故障场景,然后看看Hystrix的这两种解决方案。
一、故障场景
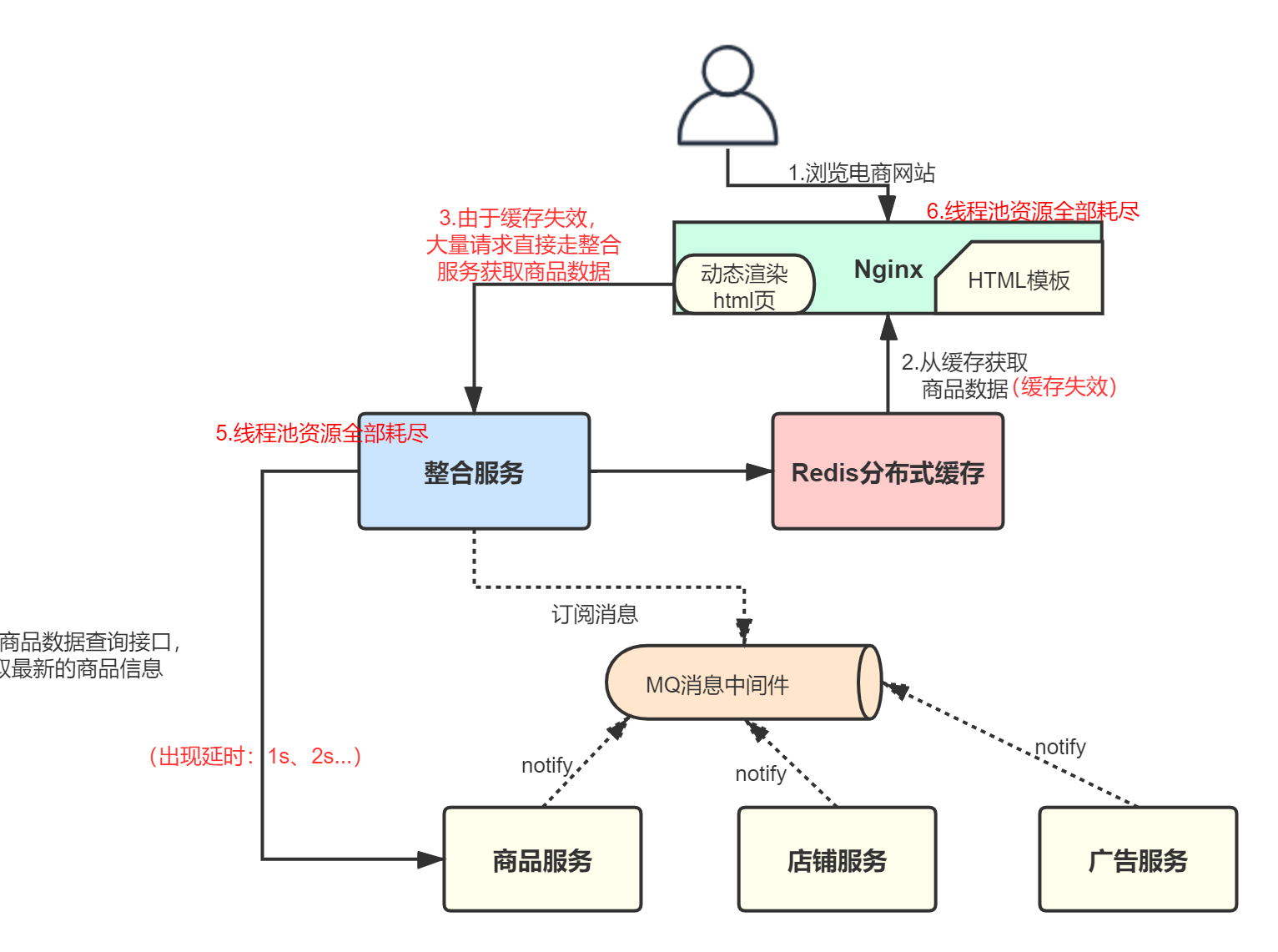
我们以上一章的电商系统为例,看下故障场景: 商品服务接口调用故障,导致整合服务耗尽了自身的服务器资源 。
- 商品服务出现接口故障,开始发生延迟、卡顿;
- 整合服务能够提供的线程资源假设为100个,每个线程去调用商品服务的接口时,都会hang住很长时间;
- 假设此时Redis缓存和Nginx本地缓存都过期失效了,那大量的请求会直接去访问整合服务,获取商品数据;
- 整合服务由于商品服务的超时,线程池资源被占满,层层级联向上,导致Nignx的线程一个个被hang住,最终Nginx的线程池资源占满,商品页无法正常显示;
- 与此同时,由于Nginx上的线程资源全部被占用,也会导致通过Nginx调用其它服务的请求无法正常使用线程资源。
二、线程池隔离
线程池隔离,是Hystrix最基本的资源隔离技术。Hystrix会将每一次服务调用请求,封装在一个Command对象内,每个Command都是使用线程池内的一个线程去执行的,这样就能跟调用线程本身隔离开来,避免因为外部依赖的接口调用超时,导致调用线程本身被卡死的情况。
以上面的整合服务为例,假设现在并发调用量为1000,分配的隔离线程池内线程数为10个,那最多就只会用这10个线程去调用依赖接口,不会因为依赖接口的调用延迟,将机器上的其它所有线程资源耗尽:

2.1 使用示例
线程池机制,每个command运行在一个线程中,限流是通过线程池的大小来控制的:
// to use thread isolation
HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(ExecutionIsolationStrategy.THREAD)
我们用Hystrix的线程池隔离技术对上一章中的整合服务进行重写,防止因为商品服务的故障耗尽整合服务中的所有线程资源。
首先用HystrixCommand对请求进行封装:
/**
* 封装获取商品信息的请求,采用线程池隔离。
* HystrixCommand中的泛型是请求返回的类型,此处是商品信息ProductInfo
*/
public class GetProductInfoCommand extends HystrixCommand<ProductInfo> {
private final Long productId;
public GetProductInfoCommand(Long productId) {
// 将command与线程池关联
super(HystrixCommandGroupKey.Factory.asKey("GetProductInfoCommandGroup"));
this.productId = productId;
}
/**
* run方法里执行的是真正请求处理逻辑
*/
@Override
protected ProductInfo run() {
// 调用商品服务的接口,获取商品id对应的商品的最新数据
String url = "http://127.0.0.1:8082/getProductInfo?productId=" + productId;
String response = HttpClientUtils.sendGetRequest(url);
return JSONObject.parseObject(response, ProductInfo.class);
}
}
然后改写整合服务中的原接口,就完成了最基本的资源隔离:
@Controller
public class CacheController {
@RequestMapping("/change/product")
@ResponseBody
public String changeProduct(Long productId) {
HystrixCommand<ProductInfo> command = new GetProductInfoCommand(productId);
// 这里会使用Hystrix分配的线程去同步执行
ProductInfo product = command.execute();
System.out.println(product);
return "success";
}
}
Hystrix还支持HystrixObservableCommand,HystrixObservableCommand可以用来支持获取多个结果的请求。比如,利用HystrixObservableCommand实现查询多个商品信息的示例如下:
/**
* 封装获取多个商品信息的请求。
*/
public class GetProductInfoListCommand extends HystrixObservableCommand<ProductInfo> {
private final Long[] productIds;
public GetProductInfoListCommand(Long[] productIds) {
super(HystrixCommandGroupKey.Factory.asKey("GetProductInfoListCommandGroup"));
this.productIds = productIds;
}
@Override
protected Observable<ProductInfo> construct() {
return Observable.create(new Observable.OnSubscribe<ProductInfo>() {
@Override
public void call(Subscriber<? super ProductInfo> observer) {
try {
for (Long id : productIds) {
String url = "http://127.0.0.1:8082/getProductInfo?productId=" + productId;
String response = HttpClientUtils.sendGetRequest(url);
ProductInfo productInfo = JSONObject.parseObject(response, ProductInfo.class);
// 每次返回一条数据,都会调用onNext
observer.onNext(productInfo);
}
observer.onCompleted();
} catch (Exception e) {
observer.onError(e);
}
}
} ).subscribeOn(Schedulers.io());
}
}
@Controller
public class CacheController {
@RequestMapping("/change/products")
@ResponseBody
public String changeProduct(Long[] productIds) {
HystrixCommand<ProductInfo> command = new GetProductInfoListCommand(productId);
// 这里会使用Hystrix分配的线程去执行
Observable<ProductInfo> ob = command.observe();
ob.subscribe(new Observer<ProductInfo>() {
@Override
public void onCompleted() {
System.out.println("获取完了所有商品数据");
}
@Override
public void onError(Throwable e) {
e.printStackTrace();
}
@Override
public void onNext(ProductInfo v) {
// 处理结果
System.out.println(v);
}
});
return "success";
}
}
2.2 优缺点
优点:
- 任何一个依赖服务都可以被隔离在自己的线程池内,即使自己的线程池资源填满了,也不会影响任何其他的服务调用;
- 服务可以随时引入一个新的依赖服务,因为即使这个新的依赖服务有问题,也不会影响其它任何服务的调用;
- 当一个故障的依赖服务重新变好的时候,可以通过清理掉线程池,瞬间恢复该服务的调用;
- 如果一个client调用库配置有问题,线程池的健康状况随时会报告,比如成功/失败/拒绝/超时的次数统计,然后可以近实时热修改依赖服务的调用配置,而不用停机;
- 如果一个服务本身发生了修改,需要重新调整配置,此时线程池的健康状况也可以随时发现,比如成功/失败/拒绝/超时的次数统计,然后可以近实时热修改依赖服务的调用配置,而不用停机;
- 基于线程池的异步本质,可以在同步的调用之上,构建一层异步调用层。
缺点:
- 线程池机制最大的缺点就是增加了cpu的开销(除了tomcat本身的调用线程之外,还有hystrix自己管理的线程池);
- 每个command的执行都依托一个独立的线程,会进行排队、调度,还有上下文切换。
Hystrix官方曾做过一个统计,Netflix API每天通过Hystrix执行10亿次调用,每个服务实例有40个以上的线程池,每个线程池有10个左右的线程。通过对比多线程异步调用和同步调用,最后发现,用Hystrix的额外开销就是给请求带来了3ms左右的延时,最多延时在10ms以内,相比于可用性和稳定性的提升,这是可以接受的。
三、信号量隔离
除了线程池隔离,Hystrix还提供了 信号量隔离 技术。信号量(Semaphore),它跟线程池有什么区别呢?事实上,Hystrix使用的信号量其实就是 J.U.C 中的Semaphore。
如果采用信号量隔离技术, 每接收一个请求,都是服务自身线程去直接调用依赖服务 ,信号量就相当于一道关卡,每个线程通过关卡后,信号量数量减1,当为0时不再允许线程通过,而是直接执行fallback逻辑并返回,说白了仅仅做了一个限流。
3.1 使用示例
信号量机制,command是运行在调用线程中,限流通过信号量的容量来控制的:
// to use semaphore isolation
HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(ExecutionIsolationStrategy.SEMAPHORE)
以整合服务为例,我们一般会将数据量较小但访问很频繁的数据,放到内存中。当整合服务调用商品服务获取到商品信息后,假设还要去查找商品是属于哪个地理位置(比如省、市、卖家等),这些信息是保存在内存中的,可能是个复杂的耗时操作。
此时就可以封装一个基于信号量隔离获取商户位置信息的请求:
/**
* 封装获取商品位置信息的Command,采用信号量隔离,默认信号量10
*/
public class GetLocationCommand extends HystrixCommand<Location> {
private final Long cityId;
public GetLocationCommand(Long cityId) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("GetLocationCommandGroup"))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(ExecutionIsolationStrategy.SEMAPHORE)));
this.cityId = cityId;
}
@Override
protected Location run() {
// 从内存中查找商品的位置信息,假设是一个本地耗时操作
Location location = LocationCache.getLocation(cityId);
return location;
}
}
然后改写缓存服务中的原接口,新增获取商品位置信息的逻辑:
@Controller
public class CacheController {
@RequestMapping("/change/product")
@ResponseBody
public String changeProduct(Long productId) {
// 1.获取商品信息(线程池隔离)
HystrixCommand<ProductInfo> productCommand = new GetProductInfoCommand(productId);
ProductInfo product = productCommand.execute();
System.out.println(product);
// 2.查找商品的位置信息(信号量隔离)
HystrixCommand<Location> locationCommand = new GetLocationCommand(info.getCityId());
Location location = locationCommand.execute();
info.setLocation(location);
return "success";
}
}
3.2 优缺点
如果采用线程池隔离技术,整合服务每接收一个请求,都会将请求转交给线程池中的线程中执行,相当于真正执行依赖接口调用的是线程池中的线程,一旦线程池满了以后,服务自身的线程不会因为接口调用延迟或故障而hang住,而是直接调用Hristrix的fallback逻辑并返回。
所以,通过比较我们可以发现,线程池隔离和信号量隔离适用于不同的业务场景:
- 线程池隔离 :适合绝大多数的场景,由于是采用线程池对依赖服务进行调用,所以能够对整个调用过程进行管控,比如处理timeout问题;不太适合超高并发场景,此时每个服务实例每秒都有几百QPS,如果用线程池隔离,由于服务自身的总线程数不会太多,所以可能撑不住那么高的并发。
- 信号量隔离 :适合对服务自身的一些复杂业务逻辑进行普通限流,一般不涉及网络请求,不需要捕获timout之类的网络异常;不太适合对外部依赖的访问(比如调用其它微服务的某个接口或第三方接口),而是比如
对 J.U.C 并发编程感兴趣的童鞋,可以看看我写《透彻理解Java并发编程》 。
四、最佳实践
4.1 线程池隔离
采用线程池机制进行资源隔离时,需要考虑一个问题,如何进行线程池资源的划分?以整合服务为例,如果该服务除了依赖商品服务外,再依赖一个广告服务,那么该如何分配广告服务和商品服务各自的线程池资源呢?
Hystrix中,每个HystrixCommand对象都可以设置command key、group key、thread pool key,以此来对各个服务需要的线程池资源进行划分:
command key
表示一类command,可以理解为底层依赖服务的一个接口(类比成商品服务的其中一个接口),默认为类名。
group key
表示许多类command的聚合,可以理解为一个底层依赖服务(类比成整个商品服务),这个服务可以暴露很多接口(每个接口就是上面的command key)。
通过上述的逻辑组合,一个group key内就有许多command key,就可以统计出一个服务内的各个接口的调用情况,比如成功、失败、超时次数等等。
threadpool key
表示一个HystrixThreadPool(即一个线程池),默认的threadpool key就是group key,如果不想直接用group key,也可以手动设置threadpool key。
Hystrix用threadpool key来进行统一的监控、统计、缓存线程池信息:
public CommandHelloWorld(String name) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("HelloWorldGroup"))
.andCommandKey(HystrixCommandKey.Factory.asKey("HelloWorldKey"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("HelloWorldPool")));
this.name = name;
}
总结一下,一般来说每个服务有多个接口,并有自己独立的线程池,所以我们在定义上述三种key的时候,就可以按下面这种方式划分:
- 一个服务对应一个group key,threadpool key默认为group key,就表示这个服务的线程池;
- 该服务中的每个接口单独定义一个command key。
当然,也存在一种情况:一个服务内的某些接口并发访问量差异特别大,此时你可能希望对这个服务内的这些接口单独用一个线程池,这是就可以指定threadpool key的值。从逻辑上来说,多个command key依然属于一个command group,只不过某些command key有自己的线程池,这样做到了更细粒度的资源控制。
4.2 线程池大小
coreSize表示HystrixThreadPool线程池的大小,默认是10,一般默认值就够了,可以通过下面的方式手动设置:
HystrixThreadPoolProperties.Setter().withCoreSize(int value)
4.3 缓冲队列大小
HystrixCommand除了支持execute这种同步调用方式外,还支持queue方式,即HystrixCommand.queue(),此时会先将调用请求放入一个队列中,等待后续异步执行。
如果queue满了,线程池也满了,那再有请求过来就会被直接reject(被拒绝的请求会走fallback降级逻辑),queueSizeRejectionThreshold参数可以动态控制queue的最大大小,默认值是5,可以通过下面的方式手动设置:
HystrixThreadPoolProperties.Setter().withQueueSizeRejectionThreshold(int value)
4.4 信号量数量
execution.isolation.semaphore.maxConcurrentRequests参数可以控制信号量的数量,超过这个数量的并发请求就会被reject。
默认值是10,可以设置的小一些,因为信号量是基于调用线程本身去执行command的,不能从timeout中抽离,如果设置的太大,有延时发生时,可能瞬间导致服务本身的线程资源被占满。
HystrixCommandProperties.Setter().withExecutionIsolationSemaphoreMaxConcurrentRequests(int value)
五、总结
本章我主要讲解了Hystrix的两种资源隔离技术:线程池隔离和信号量隔离,并分别针对它们的用法和使用场景做了介绍。相信读者已经对Hystrix的主要功能有了一个初步了解,下一章我将讲解Hystrix的整个请求流程。
关于信号量和线程池的用法和底层实现原理,读者如果想要更深入的了解,可以参考我的《透彻理解Java并发编程》中的进阶篇系列,里面有专门的章节进行讲解。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
