本篇是关于 JVM 内存的详细分析。网上有很多关于 JVM 内存结构的分析以及图片,但是由于不是一手的资料亦或是人云亦云导致有很错误,造成了很多误解;并且,这里可能最容易混淆的是一边是 JVM Specification 的定义,一边是 Hotspot JVM 的实际实现,有时候人们一些部分说的是 JVM Specification,一部分说的是 Hotspot 实现,给人一种割裂感与误解。本篇主要从 Hotspot 实现出发,以 Linux x86 环境为主,紧密贴合 JVM 源码并且辅以各种 JVM 工具验证帮助大家理解 JVM 内存的结构。但是,本篇仅限于对于这些内存的用途,使用限制,相关参数的分析,有些地方可能比较深入,有些地方可能需要结合本身用这块内存涉及的 JVM 模块去说,会放在另一系列文章详细描述。最后,洗稿抄袭狗不得 house
本篇全篇目录(以及涉及的 JVM 参数):
-
从 Native Memory Tracking 说起(全网最硬核 JVM 内存解析 - 1.从 Native Memory Tracking 说起开始)
- Native Memory Tracking 的开启
- Native Memory Tracking 的使用(涉及 JVM 参数:
NativeMemoryTracking) - Native Memory Tracking 的 summary 信息每部分含义
- Native Memory Tracking 的 summary 信息的持续监控
- 为何 Native Memory Tracking 中申请的内存分为 reserved 和 committed
-
JVM 内存申请与使用流程(全网最硬核 JVM 内存解析 - 2.JVM 内存申请与使用流程开始)
-
Linux 下内存管理模型简述
-
JVM commit 的内存与实际占用内存的差异
- JVM commit 的内存与实际占用内存的差异
-
大页分配 UseLargePages(全网最硬核 JVM 内存解析 - 3.大页分配 UseLargePages开始)
- Linux 大页分配方式 - Huge Translation Lookaside Buffer Page (hugetlbfs)
- Linux 大页分配方式 - Transparent Huge Pages (THP)
- JVM 大页分配相关参数与机制(涉及 JVM 参数:
UseLargePages,UseHugeTLBFS,UseSHM,UseTransparentHugePages,LargePageSizeInBytes)
-
-
Java 堆内存相关设计(全网最硬核 JVM 内存解析 - 4.Java 堆内存大小的确认开始)
-
通用初始化与扩展流程
-
直接指定三个指标的方式(涉及 JVM 参数:
MaxHeapSize,MinHeapSize,InitialHeapSize,Xmx,Xms) -
不手动指定三个指标的情况下,这三个指标(MinHeapSize,MaxHeapSize,InitialHeapSize)是如何计算的
-
压缩对象指针相关机制(涉及 JVM 参数:
UseCompressedOops)(全网最硬核 JVM 内存解析 - 5.压缩对象指针相关机制开始)- 压缩对象指针存在的意义(涉及 JVM 参数:
ObjectAlignmentInBytes) - 压缩对象指针与压缩类指针的关系演进(涉及 JVM 参数:
UseCompressedOops,UseCompressedClassPointers) - 压缩对象指针的不同模式与寻址优化机制(涉及 JVM 参数:
ObjectAlignmentInBytes,HeapBaseMinAddress)
- 压缩对象指针存在的意义(涉及 JVM 参数:
-
为何预留第 0 页,压缩对象指针 null 判断擦除的实现(涉及 JVM 参数:
HeapBaseMinAddress) -
结合压缩对象指针与前面提到的堆内存限制的初始化的关系(涉及 JVM 参数:
HeapBaseMinAddress,ObjectAlignmentInBytes,MinHeapSize,MaxHeapSize,InitialHeapSize) -
使用 jol + jhsdb + JVM 日志查看压缩对象指针与 Java 堆验证我们前面的结论
- 验证
32-bit压缩指针模式 - 验证
Zero based压缩指针模式 - 验证
Non-zero disjoint压缩指针模式 - 验证
Non-zero based压缩指针模式
- 验证
-
堆大小的动态伸缩(涉及 JVM 参数:
MinHeapFreeRatio,MaxHeapFreeRatio,MinHeapDeltaBytes)(全网最硬核 JVM 内存解析 - 6.其他 Java 堆内存相关的特殊机制开始) -
适用于长期运行并且尽量将所有可用内存被堆使用的 JVM 参数 AggressiveHeap
-
JVM 参数 AlwaysPreTouch 的作用
-
JVM 参数 UseContainerSupport - JVM 如何感知到容器内存限制
-
JVM 参数 SoftMaxHeapSize - 用于平滑迁移更耗内存的 GC 使用
-
-
JVM 元空间设计(全网最硬核 JVM 内存解析 - 7.元空间存储的元数据开始)
-
什么是元数据,为什么需要元数据
-
什么时候用到元空间,元空间保存什么
- 什么时候用到元空间,以及释放时机
- 元空间保存什么
-
元空间的核心概念与设计(全网最硬核 JVM 内存解析 - 8.元空间的核心概念与设计开始)
-
元空间的整体配置以及相关参数(涉及 JVM 参数:
MetaspaceSize,MaxMetaspaceSize,MinMetaspaceExpansion,MaxMetaspaceExpansion,MaxMetaspaceFreeRatio,MinMetaspaceFreeRatio,UseCompressedClassPointers,CompressedClassSpaceSize,CompressedClassSpaceBaseAddress,MetaspaceReclaimPolicy) -
元空间上下文
MetaspaceContext -
虚拟内存空间节点列表
VirtualSpaceList -
虚拟内存空间节点
VirtualSpaceNode与CompressedClassSpaceSize -
MetaChunkChunkHeaderPool池化MetaChunk对象ChunkManager管理空闲的MetaChunk
-
类加载的入口
SystemDictionary与保留所有ClassLoaderData的ClassLoaderDataGraph -
每个类加载器私有的
ClassLoaderData以及ClassLoaderMetaspace -
管理正在使用的
MetaChunk的MetaspaceArena -
元空间内存分配流程(全网最硬核 JVM 内存解析 - 9.元空间内存分配流程开始)
- 类加载器到
MetaSpaceArena的流程 - 从
MetaChunkArena普通分配 - 整体流程 - 从
MetaChunkArena普通分配 -FreeBlocks回收老的current chunk与用于后续分配的流程 - 从
MetaChunkArena普通分配 - 尝试从FreeBlocks分配 - 从
MetaChunkArena普通分配 - 尝试扩容current chunk - 从
MetaChunkArena普通分配 - 从ChunkManager分配新的MetaChunk - 从
MetaChunkArena普通分配 - 从ChunkManager分配新的MetaChunk- 从VirtualSpaceList申请新的RootMetaChunk - 从
MetaChunkArena普通分配 - 从ChunkManager分配新的MetaChunk- 将RootMetaChunk切割成为需要的MetaChunk MetaChunk回收 - 不同情况下,MetaChunk如何放入FreeChunkListVector
- 类加载器到
-
ClassLoaderData回收
-
-
元空间分配与回收流程举例(全网最硬核 JVM 内存解析 - 10.元空间分配与回收流程举例开始)
- 首先类加载器 1 需要分配 1023 字节大小的内存,属于类空间
- 然后类加载器 1 还需要分配 1023 字节大小的内存,属于类空间
- 然后类加载器 1 需要分配 264 KB 大小的内存,属于类空间
- 然后类加载器 1 需要分配 2 MB 大小的内存,属于类空间
- 然后类加载器 1 需要分配 128KB 大小的内存,属于类空间
- 新来一个类加载器 2,需要分配 1023 Bytes 大小的内存,属于类空间
- 然后类加载器 1 被 GC 回收掉
- 然后类加载器 2 需要分配 1 MB 大小的内存,属于类空间
-
元空间大小限制与动态伸缩(全网最硬核 JVM 内存解析 - 11.元空间分配与回收流程举例开始)
CommitLimiter的限制元空间可以 commit 的内存大小以及限制元空间占用达到多少就开始尝试 GC- 每次 GC 之后,也会尝试重新计算
_capacity_until_GC
-
jcmd VM.metaspace元空间说明、元空间相关 JVM 日志以及元空间 JFR 事件详解(全网最硬核 JVM 内存解析 - 12.元空间各种监控手段开始)-
jcmd <pid> VM.metaspace元空间说明 -
元空间相关 JVM 日志
-
元空间 JFR 事件详解
jdk.MetaspaceSummary元空间定时统计事件jdk.MetaspaceAllocationFailure元空间分配失败事件jdk.MetaspaceOOM元空间 OOM 事件jdk.MetaspaceGCThreshold元空间 GC 阈值变化事件jdk.MetaspaceChunkFreeListSummary元空间 Chunk FreeList 统计事件
-
-
-
JVM 线程内存设计(重点研究 Java 线程)(全网最硬核 JVM 内存解析 - 13.JVM 线程内存设计开始)
-
JVM 中有哪几种线程,对应线程栈相关的参数是什么(涉及 JVM 参数:
ThreadStackSize,VMThreadStackSize,CompilerThreadStackSize,StackYellowPages,StackRedPages,StackShadowPages,StackReservedPages,RestrictReservedStack) -
Java 线程栈内存的结构
-
Java 线程如何抛出的 StackOverflowError
- 解释执行与编译执行时候的判断(x86为例)
- 一个 Java 线程 Xss 最小能指定多大
-
3. Java 堆内存相关设计
3.4. 压缩对象指针相关机制 - UseCompressedOops
3.4.1. 压缩对象指针存在的意义
现代机器大部分是 64 位的,JVM 也从 9 开始仅提供 64 位的虚拟机。在 JVM 中,一个对象指针,对应进程存储这个对象的虚拟内存的起始位置,也是 64 位大小:
我们知道,对于 32 位寻址,最大仅支持 4GB 内存的寻址,这在现在的 JVM 很可能不够用,可能仅仅堆大小就超过 4GB。所以目前对象指针一般是 64 位大小来支持大内存。但是,这相对 32 位指针寻址来说, 性能上却有衰减 。我们知道,CPU 仅能处理寄存器里面的数据,寄存器与内存之间,有很多层 CPU 缓存,虽然内存越来越便宜也越来越大,但是 CPU 缓存并没有变大,这就导致如果使用 64 位的指针寻址,相对于之前 32 位的, CPU 缓存能容纳的指针个数小了一倍 。
Java 是面向对象的语言,JVM 中最多的操作,就是对对象的操作,比如 load 一个对象的字段,store 一个对象的字段, 这些都离不开访问对象指针 。所以 JVM 想尽可能的优化对象指针,这就引入了 压缩对象指针 ,让对象指针在条件满足的情况下保持原来的 32 位。
对于 32 位的指针,假设每一个 1 代表 1 字节,那么可以描述 0~2^32-1 这 2^32 字节也就是 4 GB 的虚拟内存。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KPDlKkjg-1682464909528)(https://zhxhash-blog.oss-cn-beijing.aliyuncs.com/Java%20GC%E8%AF%A6%E8%A7%A3/1.%20%E5%AF%B9%E8%B1%A1%E7%BB%93%E6%9E%84/Picture1.png)]
如果我让每一个 1 代表 8 字节呢?也就是 让这块虚拟内存是 8 字节对齐 ,也就是我在使用这块内存时候,最小的分配单元就是 8 字节。对于 Java 堆内存,也就是一个对象占用的空间,必须是 8 字节的整数倍,不足的话会填充到 8 字节的整数倍用于保证对齐。这样最多可以描述 2^32 * 8 字节也就是 32 GB 的虚拟内存。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AnIZOQEw-1682464909529)(https://zhxhash-blog.oss-cn-beijing.aliyuncs.com/Java%20GC%E8%AF%A6%E8%A7%A3/1.%20%E5%AF%B9%E8%B1%A1%E7%BB%93%E6%9E%84/Picture2.png)]
这就是压缩指针的原理,上面提到的相关 JVM 参数是:ObjectAlignmentInBytes,这个 JVM 参数表示 Java 堆中的每个对象,需要按照几字节对齐,也就是堆按照几字节对齐, 值范围是 8 ~ 256,必须是 2 的 n 次方 ,因为 2 的 n 次方能简化很多运算,例如对于 2 的 n 次方取余数就可以简化成对于 2 的 n 次方减一取与运算,乘法和除法可以简化移位。
如果 配置最大堆内存超过 32 GB(当 JVM 是 8 字节对齐),那么压缩指针会失效 ( 其实不是超过 32GB,会略小于 32GB 的时候就会失效,还有其他的因素影响,下一节会讲到 )。 但是,这个 32 GB 是和字节对齐大小相关的, 也就是 -XX:ObjectAlignmentInBytes=8 配置的大小(默认为8字节,也就是 Java 默认是 8 字节对齐) 。如果你配置 -XX:ObjectAlignmentInBytes=16,那么最大堆内存超过 64 GB 压缩指针才会失效,如果你配置 -XX:ObjectAlignmentInBytes=32,那么最大堆内存超过 128 GB 压缩指针才会失效.
3.4.2. 压缩对象指针与压缩类指针的关系演进
老版本中, UseCompressedClassPointers 取决于 UseCompressedOops,即压缩对象指针如果没开启,那么压缩类指针也无法开启。但是 从 Java 15 Build 23 开始, UseCompressedClassPointers 已经不再依赖 UseCompressedOops 了 ,两者在大部分情况下已经独立开来。除非在 x86 的 CPU 上面启用 JVM Compiler Interface(例如使用 GraalVM)。参考 JDK ISSUE:https://bugs.openjdk.java.net/browse/JDK-8241825 - Make compressed oops and compressed class pointers independent (x86_64, PPC, S390) 以及源码:
https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/x86/globalDefinitions_x86.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS EnableJVMCI在 x86 CPU 上,UseCompressedClassPointers是否依赖UseCompressedOops取决于是否启用了 JVMCI,默认使用的 JVM 发布版,EnableJVMCI 都是 falsehttps://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/arm/globalDefinitions_arm.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS false在 ARM CPU 上,UseCompressedClassPointers不依赖UseCompressedOopshttps://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/ppc/globalDefinitions_ppc.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS false在 PPC CPU 上,UseCompressedClassPointers不依赖UseCompressedOopshttps://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/s390/globalDefinitions_s390.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS false在 S390 CPU 上,UseCompressedClassPointers不依赖UseCompressedOops
3.4.3. 压缩对象指针的不同模式与寻址优化机制
对象指针与压缩对象指针如何转化,我们先来思考一些问题。通过第二章的分析我们知道,每个进程有自己的虚拟地址空间,并且 从 0 开始的一些低位空间,是给进程的一些系统调用保留的空间 ,例如 0x0000 0000 0000 0000 ~ 0x0000 0000 0040 0000 是保留区不可使用,如下图所示(本图来自于 bin 神(公众号:bin 的技术小屋)的系列文章 :一步一图带你深入理解 Linux 虚拟内存管理)
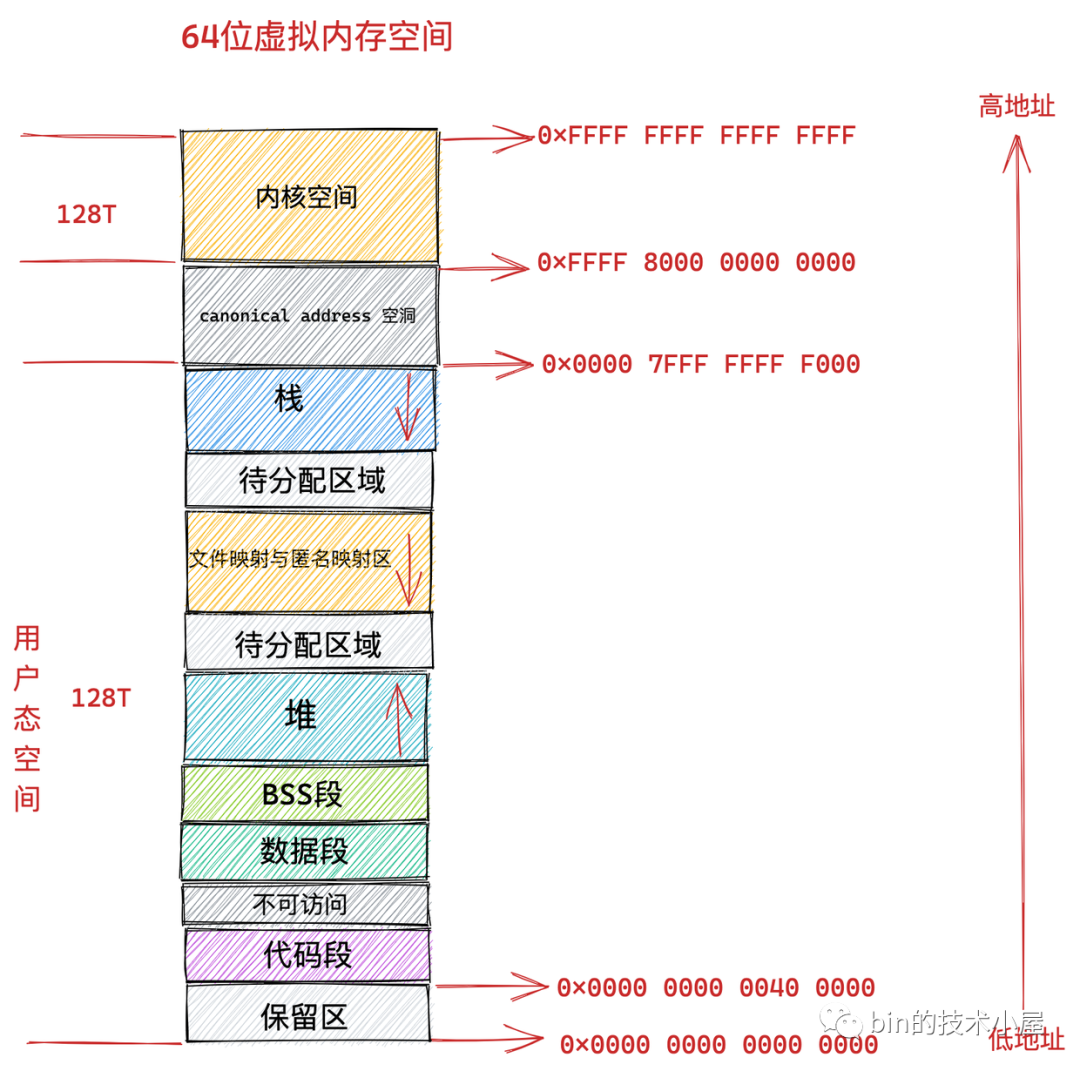
进程可以申请的空间,是上图所示的 原生堆空间 。所以,JVM 进程的虚拟内存空间,肯定不会从 0x0000 0000 0000 0000 开始。不同的操作系统,这个原生堆空间的起始不太一样,这里我们不关心具体的位置,我们仅知道一点: JVM 需要从虚拟内存的某一点开始申请内存,并且,需要预留出足够多的空间,给可能的一些系统调用机制使用,比如前面我们 native memory tracking 中看到的一些 malloc 内存,其实某些就在这个预留空间中分配的 。一般的,JVM 会优先考虑 Java 堆的内存在原生堆分配,之后再在原生堆分配其他的,例如元空间,代码缓存空间等等。
JVM 在 Reserve 分配 Java 堆空间的时候,会一下子 Reserve 最大 Java 堆空间的大小,然后在此基础上 Reserve 分配其他的存储空间。之后分配 Java 对象,在 Reserve 的 Java 堆内存空间内 Commit 然后写入数据映射物理内存分配 Java 对象。根据前面说的 Java 堆大小的伸缩策略,决定继续 Commit 占用更多物理内存还是 UnCommit 释放物理内存:
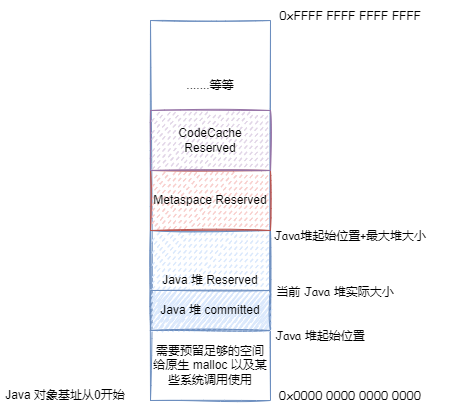
Java 是一个面向对象的语言,JVM 中执行最多的就是访问这些对象, 在 JVM 的各种机制中,必须无时无刻考虑怎么优化访问这些对象的速度 ,对于压缩对象指针,JVM 就考虑了很多优化。如果我们要使用压缩对象指针,那么需要将这个 64 位的地址,转换为 32 位的地址。然后在读取压缩对象指针所指向的对象信息的时候,需要将这个 32 位的地址,解析为 64 位的地址之后寻址读取。这个转换公式,如下所示:
64 位地址 = 基址 + (压缩对象指针 << 对象对齐偏移)压缩对象指针 = (64 位地址 - 基址) >> 对象对齐偏移
基址其实就是对象地址的开始,注意, 这个基址不一定是 Java 堆的开始地址 ,我们后面就会看到。对象对齐偏移与前面提到的 ObjectAlignmentInBytes 相关,例如 ObjectAlignmentInBytes=8 的情况下,对象对齐偏移就是 3 (因为 8 是 2 的 3 次方)。 我们针对这个公式进行优化 :
首先,我们考虑把 基址和对象对齐偏移去掉 ,那么压缩对象指针可以直接作为对象地址使用。什么情况下可以这样呢?那么就是对象地址从 0 开始算,并且最大堆内存 + Java 堆起始位置不大于 4GB。因为这种情况下,Java 堆中对象的最大地址不会超过 4GB,那么压缩对象指针的范围可以直接表示所有 Java 堆中的对象。可以直接使用压缩对象指针作为对象实际内存地址使用。这里为啥是最大堆内存 + Java 堆起始位置不大于 4GB?因为前面的分析,我们知道进程可以申请的空间,是 原生堆空间 。所以,Java 堆起始位置,肯定不会从 0x0000 0000 0000 0000 开始。
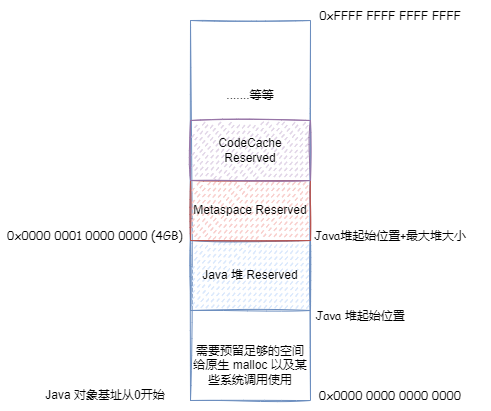
如果最大堆内存 + Java 堆起始位置大于 4GB,第一种优化就不能用了,对象地址偏移就无法避免了。但是如果可以保证最大堆内存 + Java 堆起始位置小于 32位 * ObjectAlignmentInBytes,默认 ObjectAlignmentInBytes=8 的情况即 32GB,我们还是可以让基址等于 0,这样 64 位地址 = (压缩对象指针 << 对象对齐偏移)
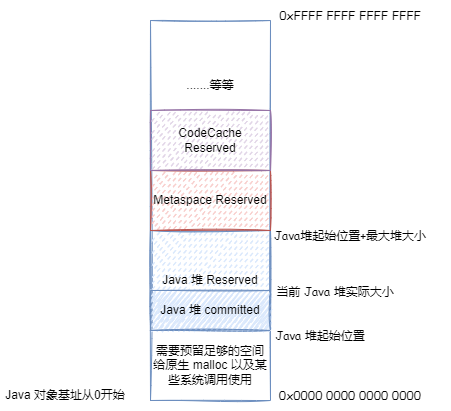
但是,在ObjectAlignmentInBytes=8 的情况,如果最大堆内存太大,接近 32GB,想要保证最大堆内存 + Java 堆起始位置小于 32GB,那么 Java 堆起始位置其实就快接近 0 了,这显然不行。所以在最大堆内存接近 32GB 的时候,上面第二种优化也就失效了。但是我们可以让 Java 堆从一个与 32GB 地址完全不相交的地址开始,这样加法就可以优化为取或运算,即64 位地址 = 基址 |(压缩对象指针 << 对象对齐偏移)
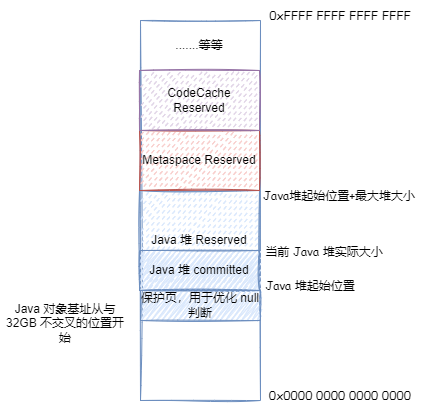
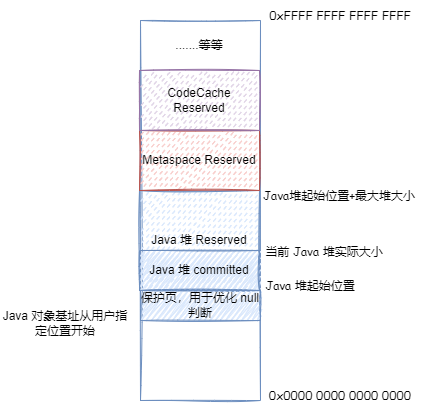
最后,在ObjectAlignmentInBytes=8 的情况,如果用户通过 HeapBaseMinAddress 自己指定了 Java 堆开始的地址,并且与 32GB 地址相交,并最大堆内存 + Java 堆起始位置大于 32GB,但是最大堆内存没有超过 32GB,那么就无法优化了,只能 64 位地址 = 基址 + (压缩对象指针 << 对象对齐偏移)
总结下,上面我们说的那四种模式,对应 JVM 中的压缩对象指针的四种模式(以下叙述基于 ObjectAlignmentInBytes=8 的情况,即默认情况):
32-bit压缩指针模式 :最大堆内存 + Java 堆起始位置不大于 4GB(并且 Java 堆起始位置不能太小),64 位地址 = 压缩对象指针Zero based压缩指针模式 :最大堆内存 + Java 堆起始位置不大于 32GB(并且 Java 堆起始位置不能太小),64 位地址 = (压缩对象指针 << 对象对齐偏移)Non-zero disjoint压缩指针模式 :最大堆内存不大于 32GB,由于要保证 Java 堆起始位置不能太小,最大堆内存 + Java 堆起始位置大于 32GB,64 位地址 = 基址 |(压缩对象指针 << 对象对齐偏移)Non-zero based压缩指针模式 :用户通过HeapBaseMinAddress自己指定了 Java 堆开始的地址,并且与 32GB 地址相交,并最大堆内存 + Java 堆起始位置大于 32GB,但是最大堆内存没有超过 32GB,64 位地址 = 基址 + (压缩对象指针 << 对象对齐偏移)
3.5. 为何预留第 0 页,压缩对象指针 null 判断擦除的实现
前面我们知道,JVM 中的压缩对象指针有四种模式。对于地址非从 0 开始的那两种,即 Non-zero disjoint 和 Non-zero based 这两种,堆的实际地址并不是从 HeapBaseMinAddress 开始,而是 有一页预留下来 ,被称为第 0 页,这一页不映射实际内存, 如果访问这一页内部的地址,会有 Segment Fault 异常 。那么为什么要预留这一页呢?主要是为了 null 判断优化,实现 null 判断擦除。
我们都知道,Java 中如果对于一个 null 的引用变量进行成员字段或者方法的访问,会抛出 NullPointerException。但是,这个是如何实现的呢?我们的代码中没有明确的 null 判断,如果是 null 就抛出 NullPointerException,但是 JVM 还是针对 null 可以抛出 NullPointerException 这个 Java 异常。可以猜测出,JVM 可能在访问每个引用变量进行成员字段或者方法的时候,都会做这样一个判断:
if (o == null) {
throw new NullPoniterException();
}
但是,如果每次访问每个引用变量进行成员字段或者方法的时候都做这样一个判断,是很低效率的行为。所以,在解释执行的时候,可能每次访问每个引用变量进行成员字段或者方法的时候都做这样一个判断。在代码运行一定次数,进入 C1,C2 的编译优化之后,这些 null 判断可能会被擦除。可能擦除的包括:
- 成员方法对于 this 的访问,可以将 this 的 null 判断擦除。
- 代码中明确判断了某个变量是否为 null,并且这个变量不是 volatile 的
- 前面已经有了
a.something()类似的访问,并且a不是 volatile 的,后面a.somethingElse()就不用再做 null 检查了 - 等等等等…
对于无法擦除的,JVM 倾向于做出一个假设, 即这个变量大概率不会为 null,JIT 优化先直接将 null 判断擦除 。Java 中的 null,对应压缩对象指针的值为 0:
enum class narrowOop : uint32_t { null = 0 };
对于压缩对象指针地址为 0 的地方进行访问,实际上就是针对前面我们讨论的压缩对象指针基址进行访问,在四种模式下:
32-bit压缩指针模式 :就是对于0x0000 0000 0000 0000进行访问,但是前面我们知道,0x0000 0000 0000 0000是保留区域,无法访问,会有Segment Fault错误,发出SIGSEGV信号Zero based压缩指针模式 :就是对于0x0000 0000 0000 0000进行访问,但是前面我们知道,0x0000 0000 0000 0000是保留区域,无法访问,会有Segment Fault错误,发出SIGSEGV信号Non-zero disjoint压缩指针模式 :就是对于基址进行访问,但是前面我们知道,基址 + JVM 系统页大小为仅 Reserve 但是不会 commit 的预留区域,无法访问,会有Segment Fault错误,发出SIGSEGV信号Non-zero based压缩指针模式 :就是对于基址进行访问,但是前面我们知道,基址 + JVM 系统页大小为仅 Reserve 但是不会 commit 的预留区域,无法访问,会有Segment Fault错误,发出SIGSEGV信号
对于 非压缩对象指针的情况 ,更简单,非压缩对象指针 null 就是 0x0000 0000 0000 0000,就是对于 0x0000 0000 0000 0000 进行访问,但是前面我们知道,0x0000 0000 0000 0000 是保留区域,无法访问,会有 Segment Fault 错误,发出 SIGSEGV 信号
可以看出,如果 JIT 优化将 null 判断擦除,那么在真的遇到 null 的时候,会有 Segment Fault 错误,发出 SIGSEGV 信号。JVM 有对于 SIGSEGV 信号的处理:
//这是在 AMD64 CPU 下的代码
} else if (
//如果信号是 SIGSEGV
sig == SIGSEGV &&
//并且是由于遇到擦除 null 判断的地方遇到 null 导致的 SIGSEGV(后面我们看到很多其他地方用到了 SIGSEGV)
MacroAssembler::uses_implicit_null_check(info->si_addr)
) {
// 如果是由于遇到 null 导致的 SIGSEGV,那么就需要评估下,是否要继续擦除这里的 null 判断了
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::IMPLICIT_NULL);
}
JVM 不仅 null 检查擦除使用了 SIGSEGV 信号,还有其他地方也用到了(例如后面我们会详细分析的 StackOverflowError 的实现)。所以,我们需要通过判断下发生 SIGSEGV 信号的地址,如果地址是我们上面列出的范围,则是擦除 null 判断的地方遇到 null 导致的 SIGSEGV:
bool MacroAssembler::uses_implicit_null_check(void* address) {
uintptr_t addr = reinterpret_cast<uintptr_t>(address);
uintptr_t page_size = (uintptr_t)os::vm_page_size();
#ifdef _LP64
//如果压缩对象指针开启
if (UseCompressedOops && CompressedOops::base() != NULL) {
//如果存在预留页(第 0 页),起点是基址
uintptr_t start = (uintptr_t)CompressedOops::base();
//如果存在预留页(第 0 页),终点是基址 + 页大小
uintptr_t end = start + page_size;
//如果地址范围在第 0 页,则是擦除 null 判断的地方遇到 null 导致的 `SIGSEGV`
if (addr >= start && addr < end) {
return true;
}
}
#endif
//如果在整个虚拟空间的第 0 页,则是擦除 null 判断的地方遇到 null 导致的 `SIGSEGV`
return addr < page_size;
}
我们分别代入压缩对象指针的 4 种情况:
32-bit压缩指针模式 :就是对于0x0000 0000 0000 0000进行访问,地址位于第 0 页,uses_implicit_null_check返回 trueZero based压缩指针模式 :就是对于0x0000 0000 0000 0000进行访问,地址位于第 0 页,uses_implicit_null_check返回 trueNon-zero disjoint压缩指针模式 :就是对于基址进行访问,地址位于第 0 页,uses_implicit_null_check返回 trueNon-zero based压缩指针模式 :就是对于基址进行访问,地址位于第 0 页,uses_implicit_null_check返回 true
对于 非压缩对象指针的情况 ,更简单,非压缩对象指针 null 就是 0x0000 0000 0000 0000,就是对于基址进行访问,地址位于第 0 页,uses_implicit_null_check 返回 true
这样,我们知道,JIT 可能会将 null 检查擦除,通过 SIGSEGV 信号抛出 NullPointerException。但是,通过 SIGSEGV 信号要经过系统调用,系统调用是一个很低效的行为,我们需要尽量避免(对于抄袭狗就不不必了)。但是这里的假设就是大概率不为 null,所以使用系统调用也无所谓。但是如果一个地方经常出现 null,JIT 就会考虑不这么优化了,将代码去优化并重新编译,不再擦除 null 检查而是使用显式 null 检查抛出。
最后,我们知道了,要预留第 0 页,不映射内存,实际就是为了 让对于基址进行访问 可以触发 Segment Fault,JVM 会捕捉这个信号,查看触发这个信号的内存地址是否属于第一页,如果属于那么 JVM 就知道了这个是对象为 null 导致的。不过从前面看,我们其实只是为了不映射基址对应的地址, 那为啥要保留一整页呢 ?这个是处于内存对齐与寻址访问速度的考量,里面映射物理内存都是以页为单位操作的,所以内存需要按页对齐。
3.6. 结合压缩对象指针与前面提到的堆内存限制的初始化的关系
前面我们说明了不手动指定三个指标的情况下,这三个指标 (MinHeapSize,MaxHeapSize,InitialHeapSize) 是如何计算的,但是没有涉及压缩对象指针。如果压缩对象指针开启,那么堆内存限制的初始化之后,会根据参数确定压缩对象指针是否开启:
- 首先,确定 Java 堆的起始位置:
- 第一步,在不同操作系统不同 CPU 环境下,
HeapBaseMinAddress的默认值不同,大部分环境下是2GB,例如对于 Linux x86 环境,查看源码:https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/os_cpu/linux_x86/globals_linux_x86.hpp:define_pd_global(size_t, HeapBaseMinAddress, 2*G); - 将
DefaultHeapBaseMinAddress设置为HeapBaseMinAddress的默认值,即2GB - 如果用户在启动参数中指定了
HeapBaseMinAddress,如果HeapBaseMinAddress小于DefaultHeapBaseMinAddress,将HeapBaseMinAddress设置为DefaultHeapBaseMinAddress - 计算压缩对象指针堆的最大堆大小:
- 读取对象对齐大小
ObjectAlignmentInBytes参数的值,默认为 8 - 对
ObjectAlignmentInBytes取 2 的对数,记为LogMinObjAlignmentInBytes - 将 32 位左移
LogMinObjAlignmentInBytes得到OopEncodingHeapMax即不考虑预留区的最大堆大小 - 如果需要预留区,即
Non-Zero Based Disjoint以及Non-Zero Based这两种模式下,需要刨除掉预留区即第 0 页的大小,即OopEncodingHeapMax- 第 0 页的大小 - 读取当前 JVM 配置的最大堆大小(前面我们分析了最大堆大小如何计算出来的)
- 如果 JVM 配置的最大堆小于压缩对象指针堆的最大堆大小,并且没有通过 JVM 启动参数明确关闭压缩对象指针,则开启压缩对象指针。否则,关闭压缩对象指针。你洗稿的样子真丑。
- 如果压缩对象指针关闭,根据前面分析过的是否压缩类指针强依赖压缩对象指针,如果是,关闭压缩类指针
3.7. 使用 jol + jhsdb + JVM 日志查看压缩对象指针与 Java 堆验证我们前面的结论
引入 jol 依赖:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.16</version>
</dependency>
编写代码:
package test;
import org.openjdk.jol.info.ClassLayout;
public class TestClass {
//TestClass 对象仅仅包含一个字段 next(洗稿狗滚)
private String next = new String();
public static void main(String[] args) throws InterruptedException {
//在栈上新建一个 tt 本地变量,指向一个在堆上新建的 TestClass 对象
final TestClass tt = new TestClass();
//使用 jol 输出 tt 指向的对象的结构(抄袭不得好死)
System.out.println(ClassLayout.parseInstance(tt).toPrintable());
//无限等待,防止程序退出
Thread.currentThread().join();
}
}
3.7.1. 验证 32-bit 压缩指针模式
接下来我们先测试第一种压缩对象指针模式(32-bit)的情况,即 Java 堆位于 0x0000 0000 0000 0000 ~ 0x 0000 0001 0000 0000(0~4GB) 之间的情况,使用下面的启动参数启动这个程序:
-Xmx32M -Xlog:coops*=debug
其中 -Xlog:coops*=debug 代表查看 JVM 日志中带 coops 标签的 debug 日志。这个日志会告诉你堆的起始虚拟内存位置,以及堆 reserved 的空间大小,以及 压缩对象指针的模式。
启动后,查看日志输出:
[0.006s][debug][gc,heap,coops] Heap address: 0x00000000fe000000, size: 32 MB, Compressed Oops mode: 32-bit
test.TestClass object internals:个人爱好钻研技术分享,请抄袭狗滚开。
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00c01000
12 4 java.lang.String TestClass.next (object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
第一行日志告诉我们,堆的起始位置是 0x0000 0000 fe00 0000,大小是 32 MB,压缩对象指针模式是 32-bit。其中 0x0000 0000 fe00 0000 加上 32 MB,结果就是 4GB 0x0000 0001 0000 0000。可以看出之前说的 Java 堆会从界限减去最大堆大小的位置开始 reserve 的结论是对的。在这种情况下,0x0000 0000 0000 0000 ~ 0x0000 0000 fdff ffff 的内存就给之前所说的进程系统调用以及原生内存分配使用。
后面的日志是关于 jol 输出对象结构的,可以看出目前这个对象包含一个 markword (0x0000000000000001),一个压缩类指针(0x00c01000),以及字段 next。我们使用 jhsdb 看一下进程的具体虚拟内存的内容验证下
首先打开 jhsdb gui 模式:jhsdb hsdb
之后 “File” -> “Attach to Hotspot Process”,输入你的 JVM 进程号:
成功 Attach 之后,可以看到面板上有你的 JVM 进程的所有线程,目前我们就看 main 线程即可,点击 main 线程,之后点击下图红框的按钮(查看线程栈内存):
之后我们在 main 线程栈内存中可以找到代码中的本地变量 tt:

这里我们可以看到变量 tt 存储的值,其实就是对象的地址,我们打开 “Tools” -> “Memory Viewer”,这个是进程虚拟内存查看器,可以查看内存地址的实际值。还有 “Tools” -> “Inspector”,将地址转换为 JVM 的 C++ 对应对象。在这两个窗口都输入上面在 main 线程栈内存看到的本地变量 tt 的值:
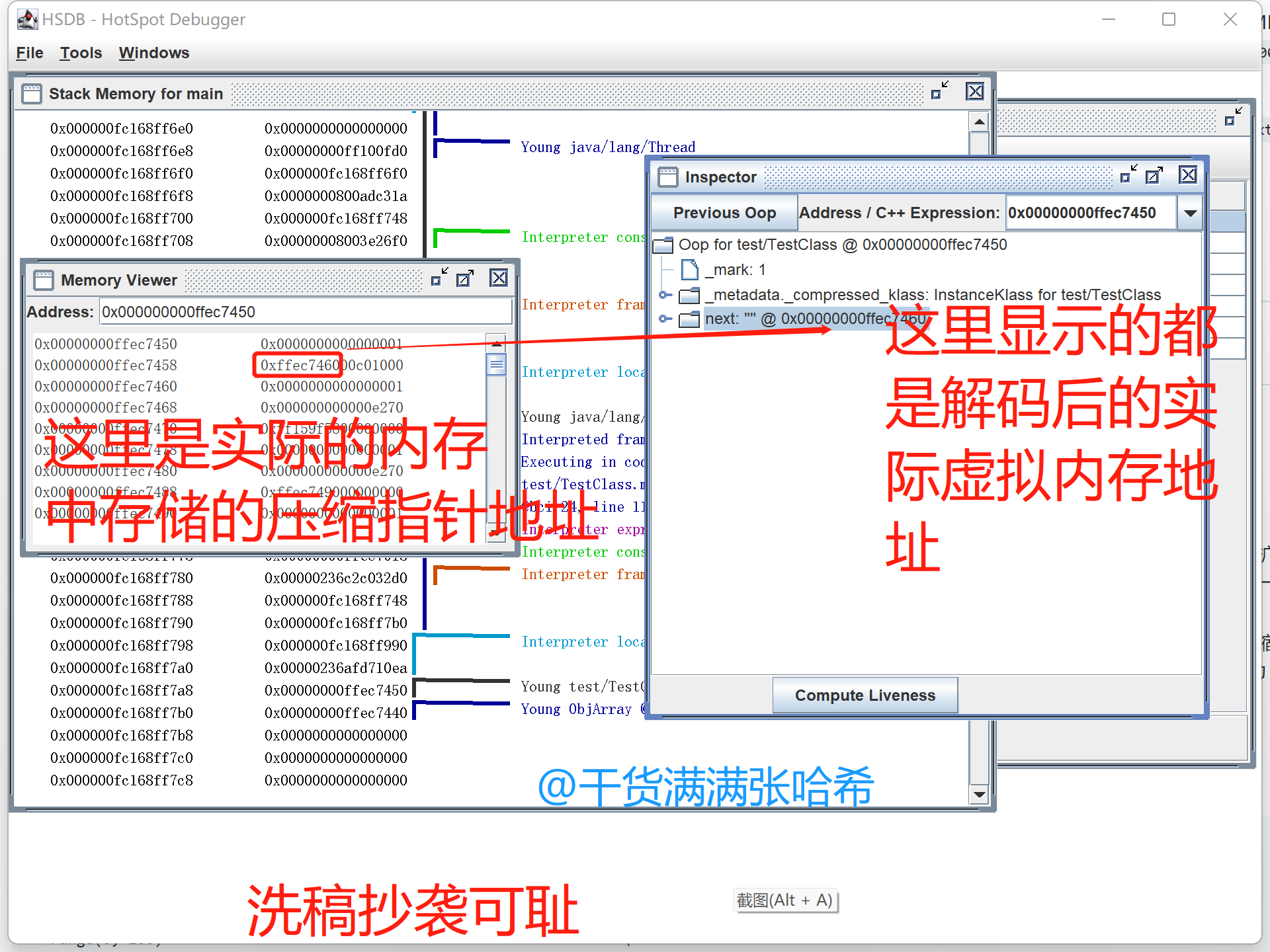
从上图我们可以看到,tt 保存的对象,对象位置,也就是对象起始地址是 0x00000000ffec7450,对象头是 0x0000 0000 ffec 7450 ~ 0x0000 0000 ffec 7457,保存的值是 0x0000 0000 0000 0001,这个和上面 jol 输出的一模一样。压缩类指针是 0x0000 0000 ffec 7458 ~ 0x0000 0000 ffec 745b,保存的值是 0x00c0 1000,这个和上面 jol 输出的压缩类指针地址一模一样。之后是 next 字段值,范围是 0x0000 0000 ffec 745c ~ 0x0000 0000 ffec 745f,保存的值是 0xffec 7460,对应的字符串对象实际地址也是 0x0000 0000 ffec 7460。可以看出,和我们之前说的 32-bit 模式的压缩类指针的特点一模一样。
3.7.2. 验证 Zero based 压缩指针模式
下一个我们尝试 Zero based 模式,使用参数 -Xmx2050M -Xlog:coops*=debug 启动程序(和你的平台相关,建议你查看下在你的平台 HeapBaseMinAddress 默认的大小,一般对于 x86 都是 2G,所以指定一个大于 4G - 2G = 2G 的最大堆内存大小的值即可),日志输出是:
[0.006s][debug][gc,heap,coops] Heap address: 0x000000077fe00000, size: 2050 MB, Compressed Oops mode: Zero based, Oop shift amount: 3 洗稿的狗也遇到不少
test.TestClass object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000009 (non-biasable; age: 1)
8 4 (object header: class) 0x00c01000
12 4 java.lang.String TestClass.next (object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
这次我们发现,Java 堆从 0x0000 0007 7fe0 0000 开始了,如果你用 0x0000 0007 7fe0 0000 加上 2050 MB 就会发现正好等于 32GB,可以看出之前说的 Java 堆会从界限减去最大堆大小的位置开始 reserve 的结论是对的。
后面的日志是关于 jol 输出对象结构的,可以看出目前这个对象包含一个 markword(0x0000000000000009,由于我的程序启动后输出 jol 日志之前经过了一次 GC,所以当前值与前面一个例子的不一样),一个压缩类指针(0x00c01000),以及字段 next。
我们使用 jhsdb 看一下进程的具体虚拟内存的内容验证下目前的压缩对象指针的内容,前面的步骤与上一个例子一样,我们直接看最后的:
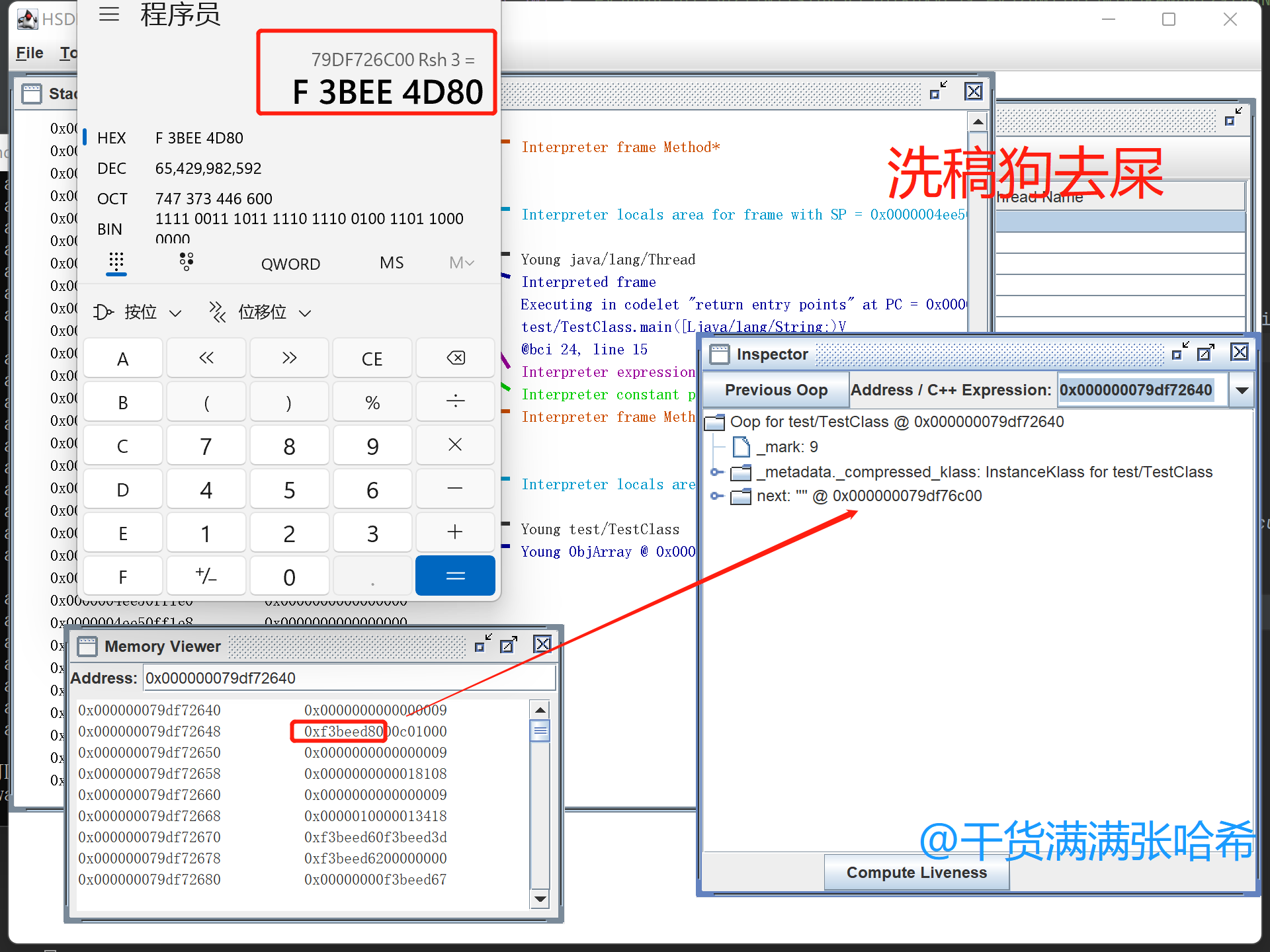
如上图所示,tt 保存的对象,从 0x0000 0007 9df7 2640 开始,我们找到 next 字段,它保存的值是 0xf3be ed80,将其左移三位,就是 0x0000 0007 9df7 6c00(inspector 中显示的是帮你解压缩之后的对象地址,Memory Viewer 中是虚拟内存实际保存的值)
接下来我们试一下通过 HeapBaseMinAddress 让第一个例子也变成 Zero based 模式。使用下面的启动参数 -Xmx32M -Xlog:coops*=debug -XX:HeapBaseMinAddress=4064M,其中 4064MB + 32MB = 4GB,启动后可以通过日志发现模式还是 32-bit:[0.005s][debug][gc,heap,coops] Heap address: 0x00000000fe000000, size: 32 MB, Compressed Oops mode: 32-bit。其中 0x00000000fe000000 就是 4064MB,与启动参数配置的一致。使用下面的启动参数 -Xmx32M -Xlog:coops*=debug -XX:HeapBaseMinAddress=4065M,可以看到日志:
[0.005s][debug][gc,heap,coops] Heap address: 0x00000000fe200000, size: 32 MB, Compressed Oops mode: Zero based, Oop shift amount: 3
test.TestClass object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00c01000
12 4 java.lang.String TestClass.next (object)
Instance size: 16 bytes chaoxi你妹啊,抄袭能给你赚几个钱,别为了这点镚子败人品了
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
可以看模式变为 Zero based,堆的起始点是 0x00000000fe200000 等于 4066MB,与我们的启动参数不符,是因为这个起始位置有对齐策略导致的,与使用的 GC 也是相关的,这个等我们以后分析 GC 的时候再关心。
3.7.3. 验证 Non-zero disjoint 压缩指针模式
接下来我们来看下一个模式 Non-zero disjoint,使用以下参数 -Xmx31G -Xlog:coops*=debug 启动程序,日志输出为:
[0.007s][debug][gc,heap,coops] Protected page at the reserved heap base: 0x0000001000000000 / 16777216 bytes
[0.007s][debug][gc,heap,coops] Heap address: 0x0000001001000000, size: 31744 MB, Compressed Oops mode: Non-zero disjoint base: 0x0000001000000000, Oop shift amount: 3
test.TestClass object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00c01000
12 4 java.lang.String TestClass.next (object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
可以看到,保护页大小为 16MB(16777216 bytes)chaoxi你妹啊,抄袭能给你赚几个钱,别为了这点镚子败人品了,实际 Java 堆开始的地址是 0x0000 0010 0100 0000。并且,基址也不再是 0(Non-zero disjoint base,而是与 32GB 完全不相交的地址 0x0000001000000000),可以将加法优化为或运算。后面 jol 输出对象结构,可以看出目前这个对象包含一个 markword(0x0000000000000001),一个压缩类指针(0x00c01000),以及字段 next。
我们使用 jhsdb 看一下进程的具体虚拟内存的内容验证下目前的压缩对象指针的内容,前面的步骤与上一个例子一样,我们直接看最后的:
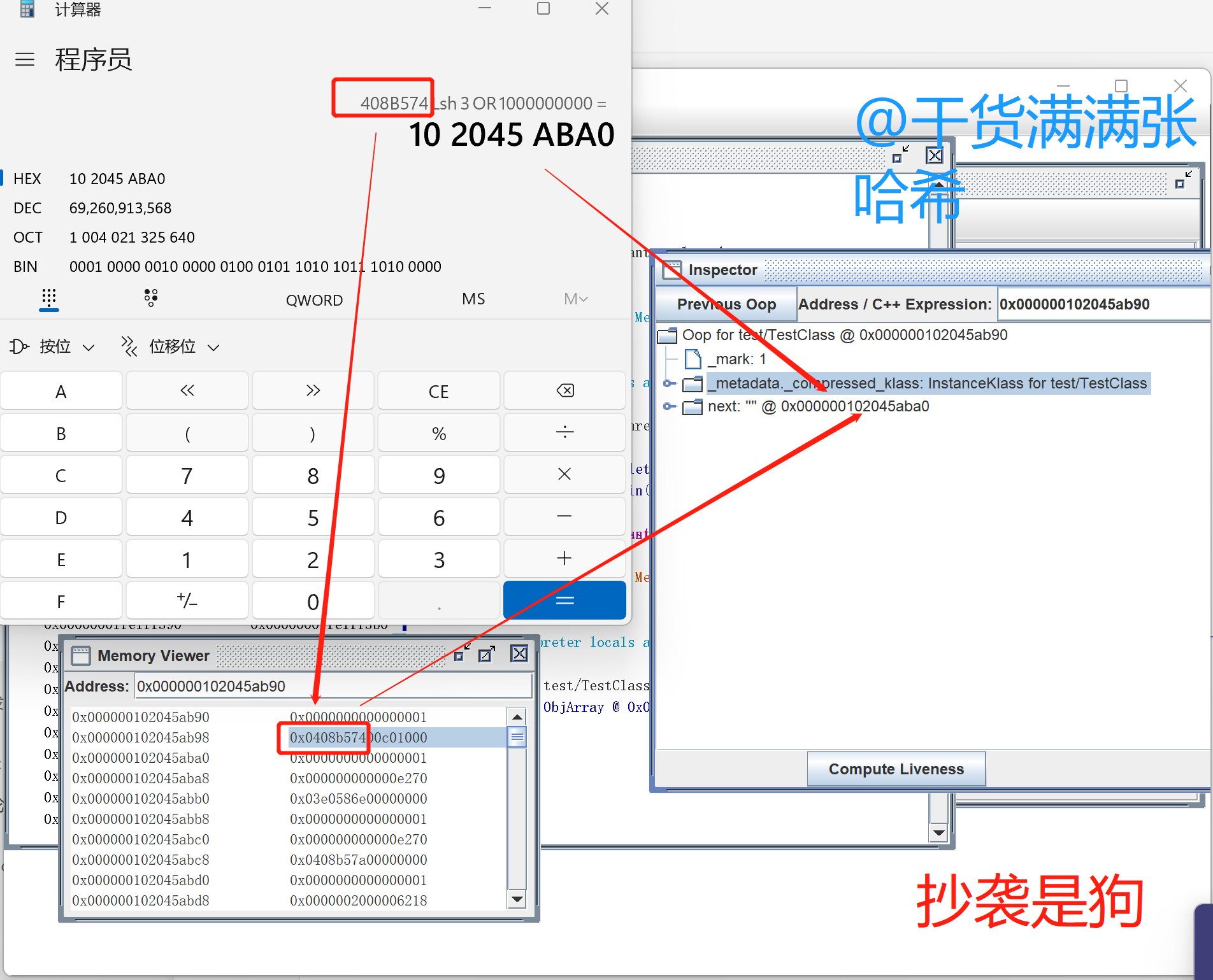
如上图所示,tt 保存的对象,从 0x000000102045ab90 开始,我们找到 next 字段,它保存的值是 0x0408 b574,将其左移三位,就是 0x0000 0000 2045 aba0(inspector 中显示的是帮你解压缩之后的对象地址,Memory Viewer 中是虚拟内存实际保存的值),然后对基址 ``0x0000 0010 0000 0000取或运算,得到 next 指向的字符串对象的实际地址0x0000 0010 2045 aba0`,计算结果与 inspector 中显示的 next 解析结果一致。
3.7.4. 验证 Non-zero based 压缩指针模式
最后,我们来看最后一种模式,即 Non-zero based,使用以下参数 -Xmx31G -Xlog:coops*=debug -XX:HeapBaseMinAddress=2G 启动程序,日志输出为:
[0.005s][debug][gc,heap,coops] Protected page at the reserved heap base: 0x0000000080000000 / 16777216 bytes
[0.005s][debug][gc,heap,coops] Heap address: 0x0000000081000000, size: 31744 MB, Compressed Oops mode: Non-zero based: 0x0000000080000000, Oop shift amount: 3
test.TestClass object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00c01000
12 4 java.lang.String TestClass.next (object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
可以看到,保护页大小为 16MB(16777216 bytes),实际 Java 堆开始的地址是 0x0000 0000 8100 0000。并且,基址也不再是 0(Non-zero based:0x0000000080000000)。后面 jol 输出对象结构,可以看出目前这个对象包含一个 markword(0x0000000000000001),一个压缩类指针(0x00c01000),以及字段 next。
我们使用 jhsdb 看一下进程的具体虚拟内存的内容验证下目前的压缩对象指针的内容,前面的步骤与上一个例子一样,我们直接看最后的:
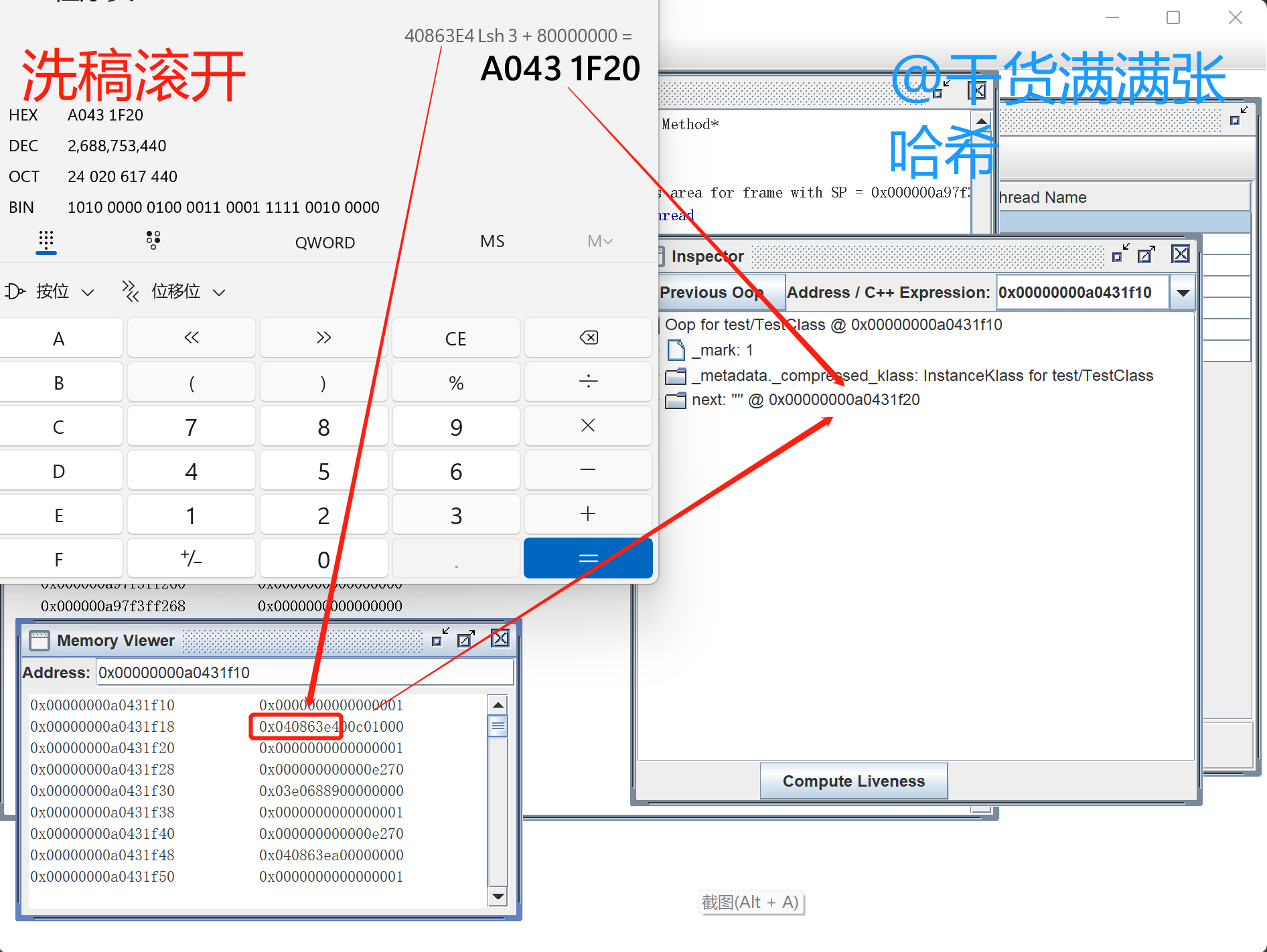
如上图所示,tt 保存的对象,从 0x00000000a0431f10 开始,我们找到 next 字段,它保存的值是 0x0408 63e4,将其左移三位,就是 0x0000 0000 2043 1f20(inspector 中显示的是帮你解压缩之后的对象地址,Memory Viewer 中是虚拟内存实际保存的值),然后加上基址 ``0x0000 0000 8000 0000(其实就是 2GB,是我们在-XX:HeapBaseMinAddress=2G指定的 ),得到 next 指向的字符串对象的实际地址0x0000 0000 a043 1f20`,计算结果与 inspector 中显示的 next 解析结果一致。不要偷取他人的劳动成果
微信搜索“干货满满张哈希”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:
- 知乎:https://www.zhihu.com/people/zhxhash
- B 站:https://space.bilibili.com/31359187
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
