日志文件记录了影响 MySQL数据库的各种类型活动。 MySQL数据库中常见的日志文件有:
- 错误日志(error log)
- 二进制日志(binlog)
- 慢查询日志(slow query log)
- 查询日志(log)
这些日志文件可以帮助DBA对 MySQL数据库的运行状态进行诊断,从而更好地进行数据库层面的优化。
1、错误日志
错误日志文件对 MySQL的启动、运行、关闭过程进行了记录。 MySQL DBA在遇到问题时应该首先查看该文件以便定位问题。该文件不仅记录了所有的错误信息,也记录一些警告信息或正确的信息。用户可以通过命令SHOW VARIABLES LIKE 'log_error'来定位该文件,如
mysql> SHOW VARIABLES LIKE 'log_error';
+---------------+----------------------------------------+
| Variable_name | Value |
+---------------+----------------------------------------+
| log_error | /usr/local/mysql/data/mysqld.local.err |
+---------------+----------------------------------------+
1 row in set (0.00 sec)
当出现MySQL数据库不能正常启动时,第一个必须查找的文件应该就是错误日志文件,该文件记录了错误信息,能很好地指导用户发现问题。当数据库不能重启时,通过查错误日志文件可以得到如下内容:

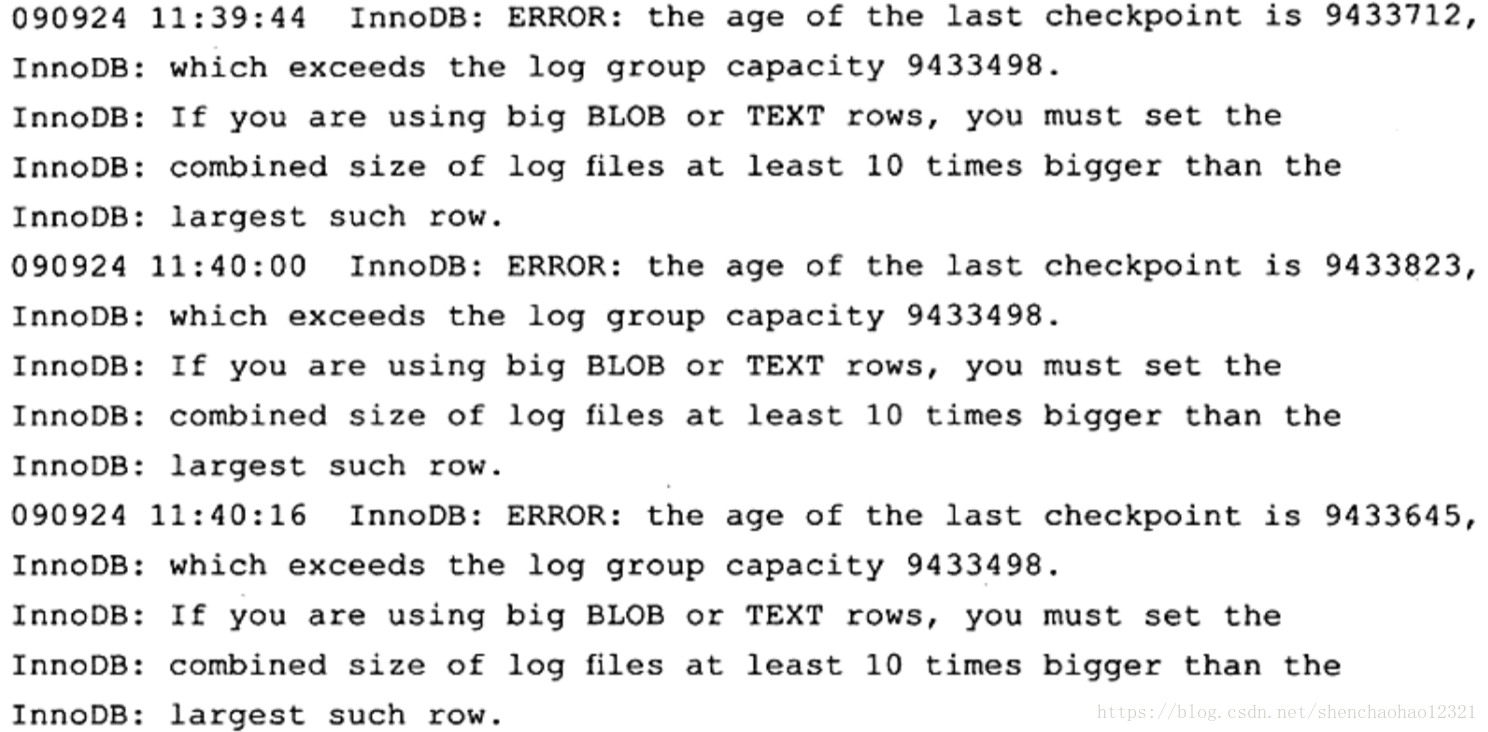
这里,错误日志文件提示了找不到权限库 mysql,所以启动失败。有时用户可以直接在错误日志文件中得到优化的帮助,因为有些警告(warning)很好地说明了问题所在。而这时可以不需要通过查看数据库状态来得知,例如,下面的错误文件中的信息可能告诉用户需要增大 InnoDB存储引擎的 redo log:
2、慢查询日志
可以通过错误日志得到一些关于数据库优化的信息,而慢查询日志(slow log)可帮助DBA定位可能存在问题的SQL语句,从而进行SQL语句层面的优化。例如,可以在 MySQL启动时设一个阈值,将运行时间超过该值的所有SQL语句都记录到慢查询日志文件中。DBA每天或每过一段时间对其进行检查,确认是否有SQL语句需要进行优化。该阈值可以通过参数 long_query_time来设置,默认值为10,代表10秒。
在默认情况下, MySQL数据库并不启动慢查询日志,用户需要手工将这个参数设为ON:
mysql> SHOW VARIABLES LIKE 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
mysql> SHOW VARIABLES LIKE 'log_slow_queries';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| log_slow_queries| ON |
+-----------------+-----------+
mysql5.6版本以上,取消了参数log_slow_queries,更改为slow_query_log,还需要加上 slow_query_log = on 否则,还是没用。
mysql> SHOW VARIABLES LIKE 'slow_query_log';
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| slow_query_log | OFF |
+----------------+-------+
1 row in set (0.00 sec)
mysql> SHOW VARIABLES LIKE 'slow_query_log_file';
+---------------------+------------------------------------------------------+
| Variable_name | Value |
+---------------------+------------------------------------------------------+
| slow_query_log_file | /usr/local/mysql/data/my-computer-slow.log |
+---------------------+------------------------------------------------------+
这里有两点需要注意。首先,设置 long_query_time这个阈值后, MySQL数据库会记录运行时间超过该值的所有SQL语句,但运行时间正好等于 long_query_time的情况并不会被记录下。也就是说,在源代码中判断的是大于long_query_time,而非大于等于。其次,从 MySQL5.1开始, long_query_time开始以微秒记录SQL语句运行的时间,之前仅用秒为单位记录。而这样可以更精确地记录SQL的运行时间,供DBA分析。对DBA来说,一条SQL语句运行0.5秒和0.05秒是非常不同的,前者可能已经进行了表扫,后面可能是进行了索引。
另一个和慢查询日志有关的参数是 log_queries_not_using_indexes,如果运行的SQL语句没有使用索引,则 MySQL数据库同样会将这条SQL语句记录到慢查询日志文件。
首先确认打开了log_queries_not_using_indexes:
mysql> SHOW VARIABLES LIKE 'log_queries_not_using_indexes';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| log_queries_not_using_indexes | ON |
+-------------------------------+-------+
1 row in set (0.00 sec)
My SQL5.6.5版本开始新增了一个参数 log_throttle_queries_not_using_indexes,用来表示每分钟允许记录到 slow log的且未使用索引的SQL语句次数。该值默认为0,表示没有限制。在生产环境下,若没有使用索引,此类SQL语句会频繁地被记录到slow log,从而导致 slow log文件的大小不断增加,故DBA可通过此参数进行配置。
mysql> SHOW VARIABLES LIKE 'log_throttle_queries_not_using_indexes';
+----------------------------------------+-------+
| Variable_name | Value |
+----------------------------------------+-------+
| log_throttle_queries_not_using_indexes | 0 |
+----------------------------------------+-------+
1 row in set (0.00 sec)
DBA可以通过慢查询日志来找出有问题的SQL语句,对其进行优化。然而随着MySQL数据库服务器运行时间的增加,可能会有越来越多的SQL查询被记录到了慢查询日志文件中,此时要分析该文件就显得不是那么简单和直观的了。而这时 MySQL数据库提供的 mysqldumpslow命令,可以很好地帮助DBA解决该问题。
如果用户希望得到执行时间最长的10条SQL语句,可以运行如下命令:
mysqldumpslow -s al -n l0 david.log
MySQL5.1开始可以将慢查询的日志记录放入一张表中,这使得用户的查询更加方便和直观。慢查询表在mysql架构下,名为 slow_log,其表结构定义如下:
mysql> show create table mysql.slow_log\G
*************************** 1. row ***************************
Table: slow_log
Create Table: CREATE TABLE `slow_log` (
`start_time` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6),
`user_host` mediumtext NOT NULL,
`query_time` time(6) NOT NULL,
`lock_time` time(6) NOT NULL,
`rows_sent` int(11) NOT NULL,
`rows_examined` int(11) NOT NULL,
`db` varchar(512) NOT NULL,
`last_insert_id` int(11) NOT NULL,
`insert_id` int(11) NOT NULL,
`server_id` int(10) unsigned NOT NULL,
`sql_text` mediumblob NOT NULL,
`thread_id` bigint(21) unsigned NOT NULL
) ENGINE=CSV DEFAULT CHARSET=utf8 COMMENT='Slow log'
1 row in set (0.00 sec)
参数 log_output指定了慢查询输出的格式,默认为FILE,可以将它设为 TABLE,然后就可以查询 mysql架构下的slow_log表了,如:
mysql> show variables like 'log_output';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_output | FILE |
+---------------+-------+
1 row in set (0.00 sec)
mysql> set global log_output='TABLE';
Query OK, 0 rows affected (0.01 sec)
mysql> show variables like 'log_output';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_output | TABLE |
+---------------+-------+
1 row in set (0.00 sec)
mysql> select sleep(11);
+-----------+
| sleep(11) |
+-----------+
| 0 |
+-----------+
1 row in set (10.02 sec)
mysql> select * from mysql.slow_log\G
*************************** 1. row ***************************
start_time: 2018-10-09 15:36:30.948543
user_host: root[root] @ localhost []
query_time: 00:00:11.001354
lock_time: 00:00:00.000000
rows_sent: 1
rows_examined: 0
db: information_schema
last_insert_id: 0
insert_id: 0
server_id: 0
sql_text: select sleep(11)
thread_id: 4
1 row in set (0.00 sec)
参数 log_output是动态的,并且是全局的,因此用户可以在线进行修改。在上表中人为设置了睡眠(sleep)10秒,那么这句SQL语句就会被记录到 slow_log表了。
查看 slow_log表的定义会发现该表使用的是CSV引擎,对大数据量下的查询效率可能不高。用户可以把 slow_log表的引擎转换到 MyISAM,并在 start_time列上添加索引以进一步提高査询的效率。但是,如果已经启动了慢查询,将会提示错误:
mysql>ALTER TABLE mysql.slow_log ENGINE=MyISM;
ERROR 1580 (HY000): You cannot 'ALTER a log table if logging is enabled
mysql>SET GLOBAL slow query log=off;
Query OK, 0 rows affected (0.00 sec)
mysql>ALTER TABLE mysql slow log ENGINE=MyISAM;
Query OK,1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
不能忽视的是,将 slow_log表的存储引擎更改为MyAM后,还是会对数据库造成额外的开销。不过好在很多关于慢查询的参数都是动态的,用户可以方便地在线进行设置或修改。
MySQL的 slow_log通过运行时间来对SQL语句进行捕获,这是一个非常有用的优化技巧。但是当数据库的容量较小时,可能因为数据库刚建立,此时非常大的可能是数据全部被缓存在缓冲池中,SQL语句运行的时间可能都是非常短的,一般都是0.5秒。
InnoSQL版本加强了对于SQL语句的捕获方式。在原版 MySQL的基础上在slow log中增加了对于逻辑读取(logical reads)和物理读取(physical reads)的统计。这里的物理读取是指从磁盘进行IO读取的次数,逻辑读取包含所有的读取,不管是磁盘还是缓冲池。例如
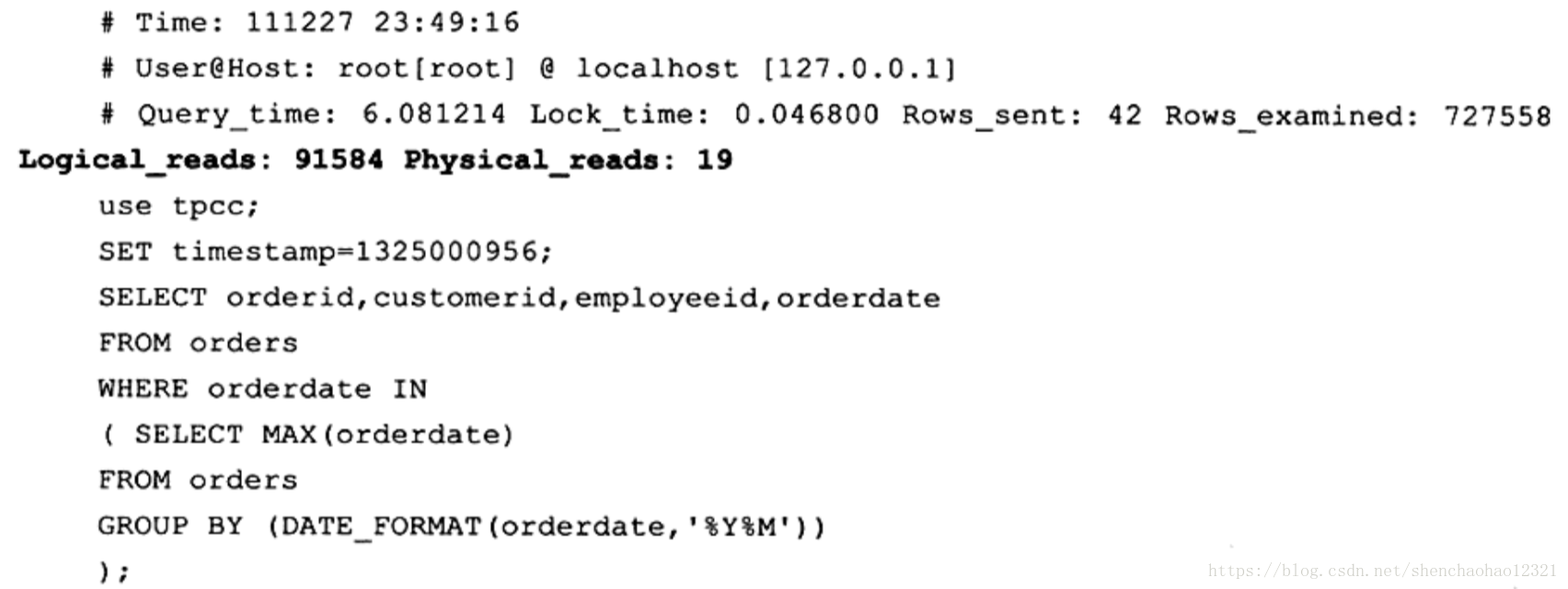
从上面的例子可以看到该子查询的逻辑读取次数是91584次,物理读取为19次。从逻辑读与物理读的比例上看,该SQL语句可进行优化。
用户可以通过额外的参数 long_query_io将超过指定逻辑IO次数的SQL语句记录到slow log中。该值默认为100,即表示对于逻辑读取次数大于100的SQL语句,记录到slow log中。而为了兼容原 MySQL数据库的运行方式,还添加了参数 slow_query_type,用来表示启用 slow log的方式,可选值为:
- 0表示不将SQL语句记录到 slow log
- 1表示根据运行时间将SQL语句记录到 slow log
- 2表示根据逻辑IO次数将SQL语句记录到 slow log
- 3表示根据运行时间及逻辑IO次数将SQL语句记录到 slow log
3、查询日志
查询日志记录了所有对 MySQL数据库请求的信息,无论这些请求是否得到了正确的执行。默认文件名为:主机名.log。如查看一个查询日志路径:
mysql> SHOW VARIABLES LIKE 'general_log%';
+------------------+-------------------------------------------------+
| Variable_name | Value |
+------------------+-------------------------------------------------+
| general_log | OFF |
| general_log_file | /usr/local/mysql/data/my-computer.log |
+------------------+-------------------------------------------------+
2 rows in set (0.00 sec)
查询日志。它记录所有MySQL活动,在诊断问题是非常有用。日志文件可能会很快的变得非常大,因此不应该长期使用它。此日志通常名为hostname.log。
同样地,从 MySQL5.1开始,可以将查询日志的记录放入mysq架构下的 general_log表中,该表的使用方法和前面小节提到的 slow log基本一样,这里不再赘述。
4、二进制日志
二进制日志(binary log)记录了对 MySQL数据库执行更改的所有操作,但是不包括 SELECT和SHOW这类操作,因为这类操作对数据本身并没有修改。然而,若操作本身并没有导致数据库发生变化,那么该操作可能也会写入二进制日志。例如:
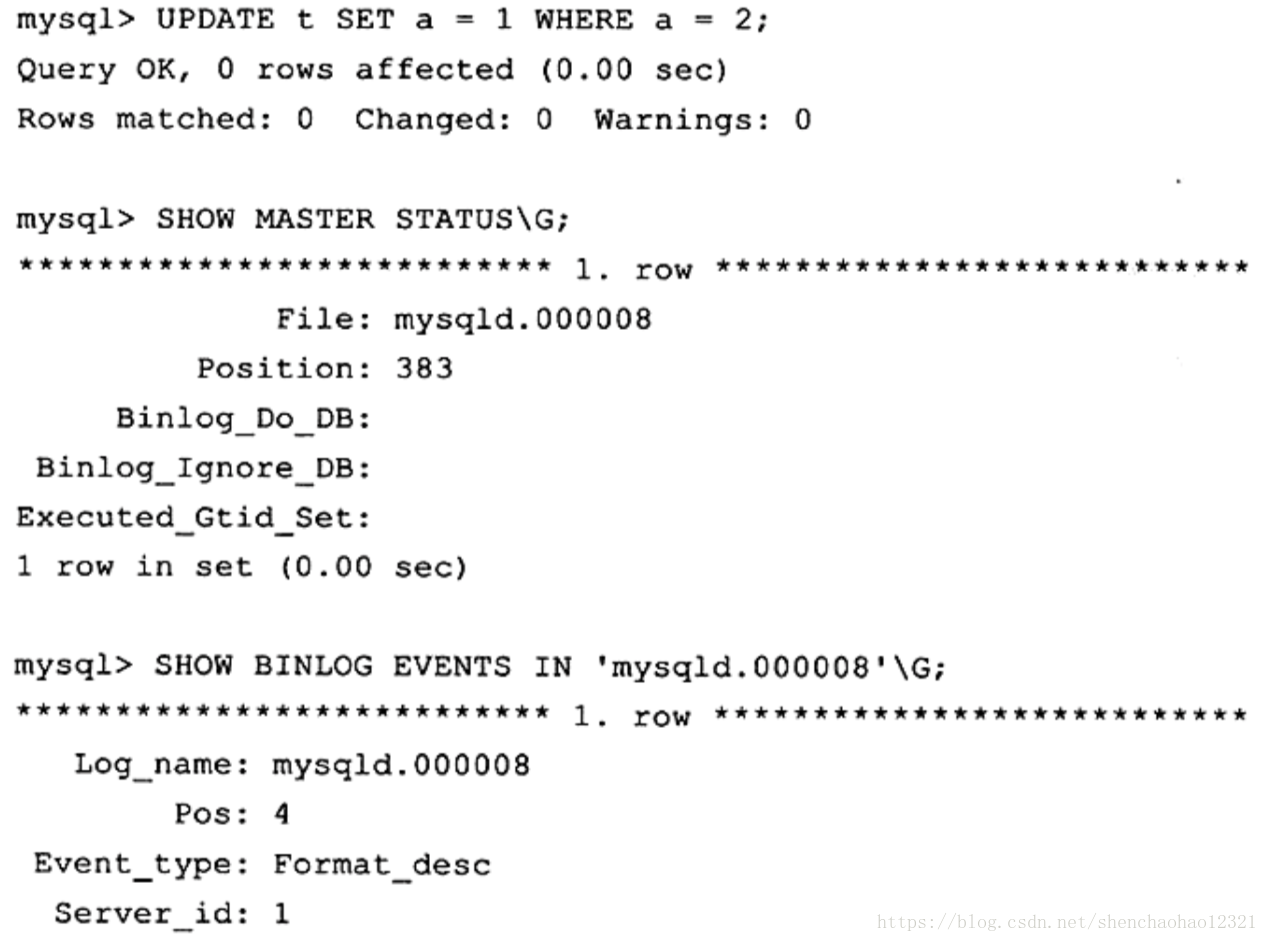

从上述例子中可以看到, MySQL数据库首先进行 UPDATE操作,从返回的结果看到 Changed为0,这意味着该操作并没有导致数据库的变化。但是通过命令SHOW BINLOG EVENT可以看出在二进制日志中的确进行了记录。
如果用户想记录 SELECT和SHOW操作,那只能使用查询日志,而不是二进制日志。此外,二进制日志还包括了执行数据库更改操作的时间等其他额外信息。总的来说,二进制日志主要有以下几种作用。
- 恢复(recovery):某些数据的恢复需要二进制日志,例如,在一个数据库全备文件恢复后,用户可以通过二进制日志进行 point-in-time的恢复。
- 复制(replication):其原理与恢复类似,通过复制和执行二进制日志使一台远程的 MySQL数据库(一般称为slave或 standby)与一台 MySQL数据库(一般称为 master或 primary)进行实时同步。
- 审计(audit):用户可以通过二进制日志中的信息来进行审计,判断是否有对数据库进行注入的攻击。
查看到binlog日志为OFF关闭状态:
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | OFF |
+---------------+-------+
1 row in set (0.00 sec)
通过配置参数 log-bin[=name]可以启动二进制日志。
退出MySQL,使用vi编辑器修改MySQL的my.cnf配置文件。
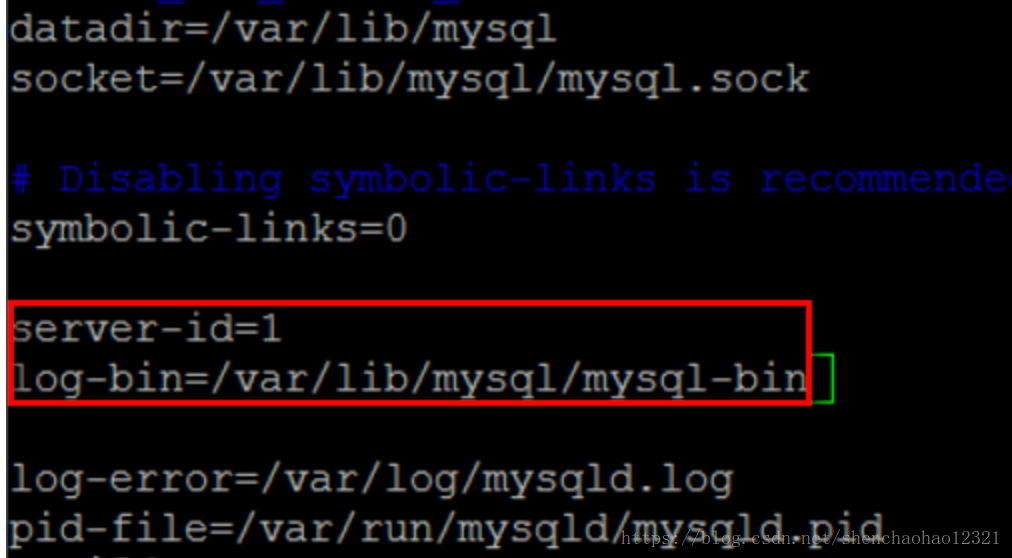
server-id表示单个结点的id,这里由于只有一个结点,所以可以把id随机指定为一个数,这里将id设置成1。若集群中有多个结点,则id不能相同, 第二句是指定binlog日志文件的名字为mysql-bin,以及其存储路径。
此时再次进入MySQL,查看binlog日志的状态。显示binlog日志为ON开启状态。
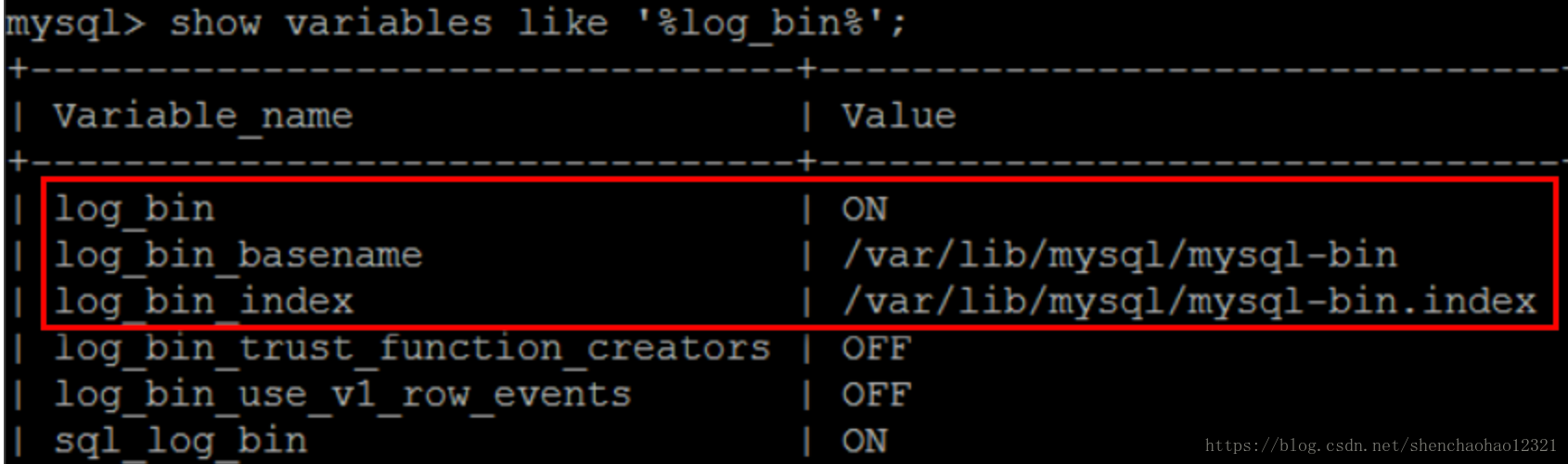
如果不指定name则默认二进制日志文件名为主机名,后缀名为二进制日志的序列号,所在路径为数据库所在目录( datadir)。如:
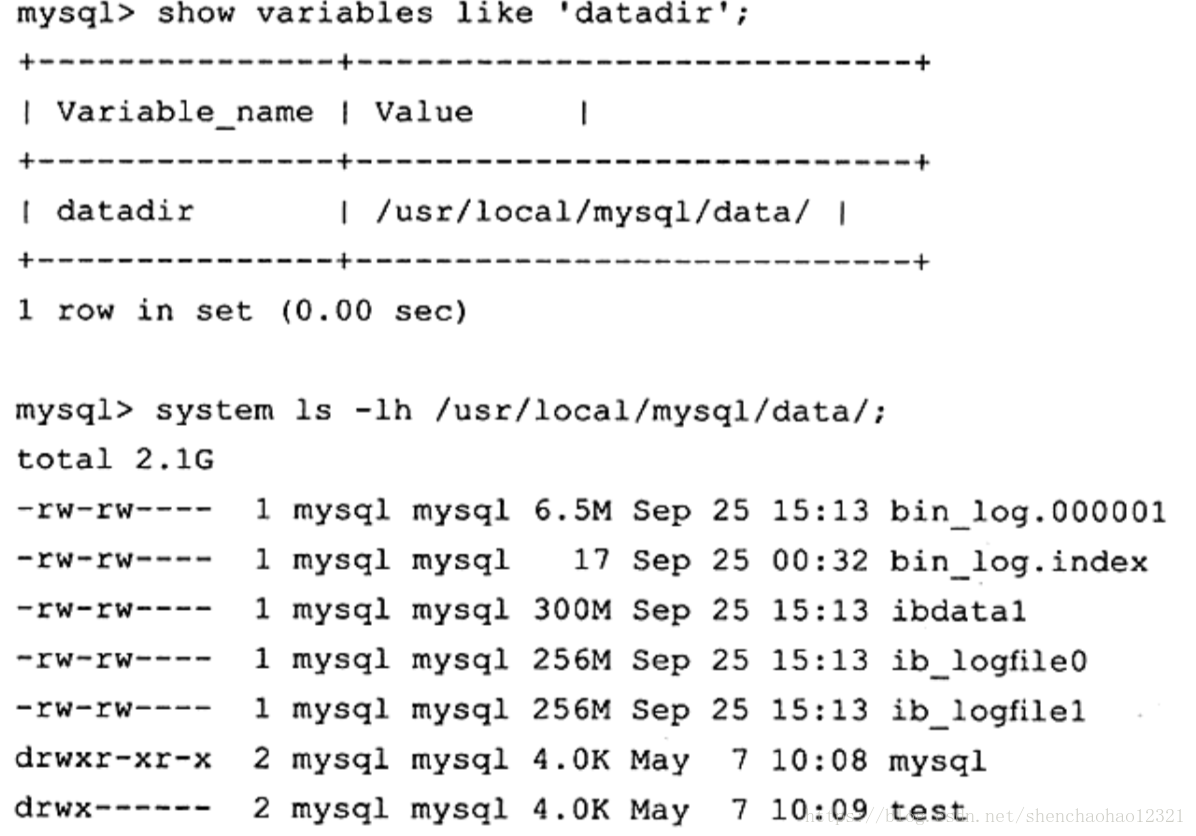
这里的 bin_log.00001即为二进制日志文件,我们在配置文件中指定了名字,所以没有用默认的文件名。 bin_log.index为二进制的索引文件,用来存储过往产生的二进制日志序号,在通常情况下,不建议手工修改这个文件。
二进制日志文件在默认情况下并没有启动,需要手动指定参数来启动。可能有人会质疑,开启这个选项是否会对数据库整体性能有所影响。不错,开启这个选项的确会影响性能,但是性能的损失十分有限。根据 MySQL官方手册中的测试表明,开启二进制日志会使性能下降1%但考虑到可以使用复制( replication)和 point-in-time的恢复,这些性能损失绝对是可以且应该被接受的。
以下配置文件的参数影响着二进制日志记录的信息和行为:
- max_binlog_size
- binlog_cache_size
- sync_binlog
- binlog_do_db
- binlog_ignore_db
- log_slave_update
- binlog_format
参数 max_binlog_size指定了单个二进制日志文件的最大值,如果超过该值,则产生新的二进制日志文件,后缀名+1,并记录到 index文件。从 MySQL5.0开始的默认值为1073741824,代表1G(在之前版本中 max_binlog_size默认大小为1.1G)。
当使用事务的表存储引擎(如 InnodB存储引擎)时,所有未提交( uncommitted)的二进制日志会被记录到一个缓存中去,等该事务提交(committed)时直接将缓冲中的二进制日志写入二进制日志文件,而该缓冲的大小由 binlog_cache_size决定,默认大小为32K。此外, binlog_cache_size是基于会话( session)的,也就是说,当一个线程开始一个事务时,MyQL会自动分配一个大小为 binlog_cache_size的缓存,因此该值的设置需要相当小心,不能设置过大。当一个事务的记录大于设定的 binlog_cache_size时, MySQL会把缓冲中的日志写人一个临时文件中,因此该值又不能设得太小。通过SHOW GLOBAL STATUS命令查看 binlog_cache_use、 binlog_cache_disk_use的状态,可以判断当前 binlog_cache_size的设置是否合适。 binlog_cache_use记录了使用缓冲写进制日志的次数, binlog_cache_disk_use记录了使用临时文件写二进制日志的次数。现在来看一个数据库的状态:

使用缓冲次数为33553,临时文件使用次数为0。看来32KB的缓冲大小对于当前这个 MySQL数据库完全够用,暂时没有必要增加 binlog_cache_size的值。
在默认情况下,二进制日志并不是在每次写的时候同步到磁盘(用户可以理解为缓冲写)。因此,当数据库所在操作系统发生宕机时,可能会有最后一部分数据没有写入二进制日志文件中,这会给恢复和复制带来问题。参数 sync_binlog=[N]表示每写缓冲多少次就同步到磁盘。如果将N设为1,即 sync_binlog=1表示采用同步写磁盘的方式来写二进制日志,这时写操作不使用操作系统的缓冲来写二进制日志。 sync_binlog的默认值为0,如果使用 InnoDB存储引擎进行复制,并且想得到最大的高可用性,建议将该值设为ON。不过该值为ON时,确实会对数据库的IO系统带来一定的影响。
但是,即使将 sync_binlog设为1,还是会有一种情况导致问题的发生。当使用InnoDB存储引擎时,在一个事务发出 COMMIT动作之前,由于 sync_binlog为1,因此会将二进制日志立即写入磁盘。如果这时已经写人了二进制日志,但是提交还没有发生,并且此时发生了宕机,那么在 MySQL数据库下次启动时,由于 COMMIT操作并没有发生,这个事务会被回滚掉。但是二进制日志已经记录了该事务信息,不能被回滚。这个问题可以通过将参数 innodb_support_xa设为1来解决,虽然 innodb_support_xa与XA事务有关,但它同时也确保了二进制日志和 InnoDB存储引擎数据文件的同步。
参数 binlog-do-db和 binlog-ignore-db表示需要写入或忽略写入哪些库的日志。默认为空,表示需要同步所有库的日志到二进制日志。
如果当前数据库是复制中的 slave角色,则它不会将从 master取得并执行的二进制日志写入自己的二进制日志文件中去。如果需要写人,要设置log-slave-update。如果需要搭建 master=> slave=> slave架构的复制,则必须设置该参数。
binlog_format参数十分重要,它影响了记录二进制日志的格式。在 MySQL5.1版本之前,没有这个参数。所有二进制文件的格式都是基于SQL语句(statement)级别的,因此基于这个格式的二进制日志文件的复制( Replication)和 Oracle的逻辑 Standby有点相似。同时,对于复制是有一定要求的。如在主服务器运行rand、uuid等函数,又或者使用触发器等操作,这些都可能会导致主从服务器上表中数据的不一致(not sync)另一个影响是,会发现 InnoDB存储引擎的默认事务隔离级别是 REPEATABLE READ。
这其实也是因为二进制日志文件格式的关系,如果使用 READ COMMITTED的事务隔离级别(大多数数据库,如 Oracle, Microsoft SQL Server数据库的默认隔离级别),会出现类似丢失更新的现象,从而出现主从数据库上的数据不一致。
MySQL5.1开始引入了 binlog_format参数,该参数可设的值有 STATEMENT、ROW和 MIXED。
(1)STATEMENT格式和之前的 MySQL版本一样,二进制日志文件记录的是日志的逻辑SQL语句。
(2)在ROW格式下,二进制日志记录的不再是简单的SQL语句了,而是记录表的行更改情况。基于ROW格式的复制类似于 Oracle的物理 Standby(当然,还是有些区别)。同时,对上述提及的 Statement格式下复制的问题予以解决。从 MySQL5.1版本开始,如果设置了 binlog_format为ROW,可以将 InnoDB的事务隔离基本设为READ COMMITTED,以获得更好的并发性。
(3)在MXED格式下, MySQL默认采用 STATEMENT格式进行二进制日志文件的记录,但是在一些情况下会使用ROW格式,可能的情况有:
- 1)表的存储引擎为NDB,这时对表的DML操作都会以ROW格式记录。
- 2)使用了UUID()、 USER()、 CURRENT_USER()、 FOUND_ROWS()、 ROW_COUNT()
- 等不确定函数。
- 3)使用了 INSERT DELAY语句。
- 4)使用了用户定义函数(UDF)
- 5)使用了临时表(temporary table)
此外, binlog_format参数还有对于存储引擎的限制,如表所示。
| 存储引擎 | Row格式 | Statement格式 |
|---|---|---|
| 存储引擎 | Row格式 | Statement格式 |
| InnoDB | Yes | Yes |
| MyISAM | Yes | Yes |
| HEAP | Yes | Yes |
| MERGE | Yes | Yes |
| NDB | Yes | No |
| Archive | Yes | Yes |
| CSV | Yes | Yes |
| Federate | Yes | Yes |
| Blockhole | No | Yes |
binlog_format是动态参数,因此可以在数据库运行环境下进行更改,例如,我们可以将当前会话的 binlog_format设为ROW,如:
mysql> SET @@session.binlog_format='ROW';
Query OK, 0 rows affected (0.00 sec)
mysql> select @@session.binlog_format;
+-------------------------+
| @@session.binlog_format |
+-------------------------+
| ROW |
+-------------------------+
1 row in set (0.00 sec)
当然,也可以将全局的 binlog_format设置为想要的格式,不过通常这个操作会带来问题,运行时要确保更改后不会对复制带来影响。如:
mysql> SET @@global.binlog_format='ROW';
Query OK, 0 rows affected (0.00 sec)
mysql> select @@global.binlog_format;
+------------------------+
| @@global.binlog_format |
+------------------------+
| ROW |
+------------------------+
1 row in set (0.00 sec)
在通常情况下,我们将参数 binlog_format设置为ROW,这可以为数据库的恢复和复制带来更好的可靠性。但是不能忽略的一点是,这会带来二进制文件大小的增加,有些语句下的ROW格式可能需要更大的容量。比如我们有两张一样的表,大小都为100W,分别执行 UPDATE操作,观察二进制日志大小的变化:
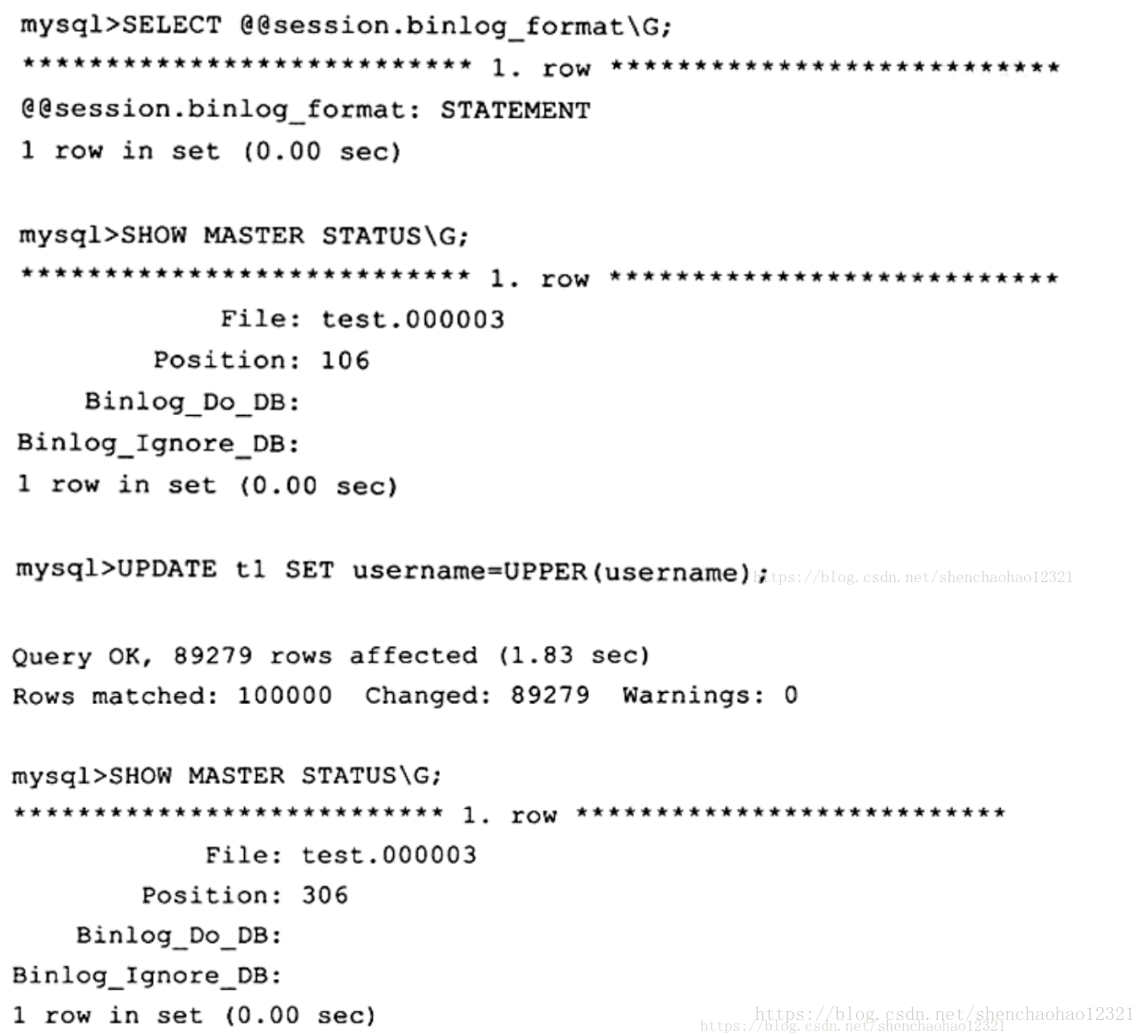
可以看到,在 binlog format格式为 STATEMENT的情况下,执行 UPDATE语句后二进制日志大小只增加了200字节(306-106)。如果使用ROW格式,同样对t2表进行操作,可以看到:
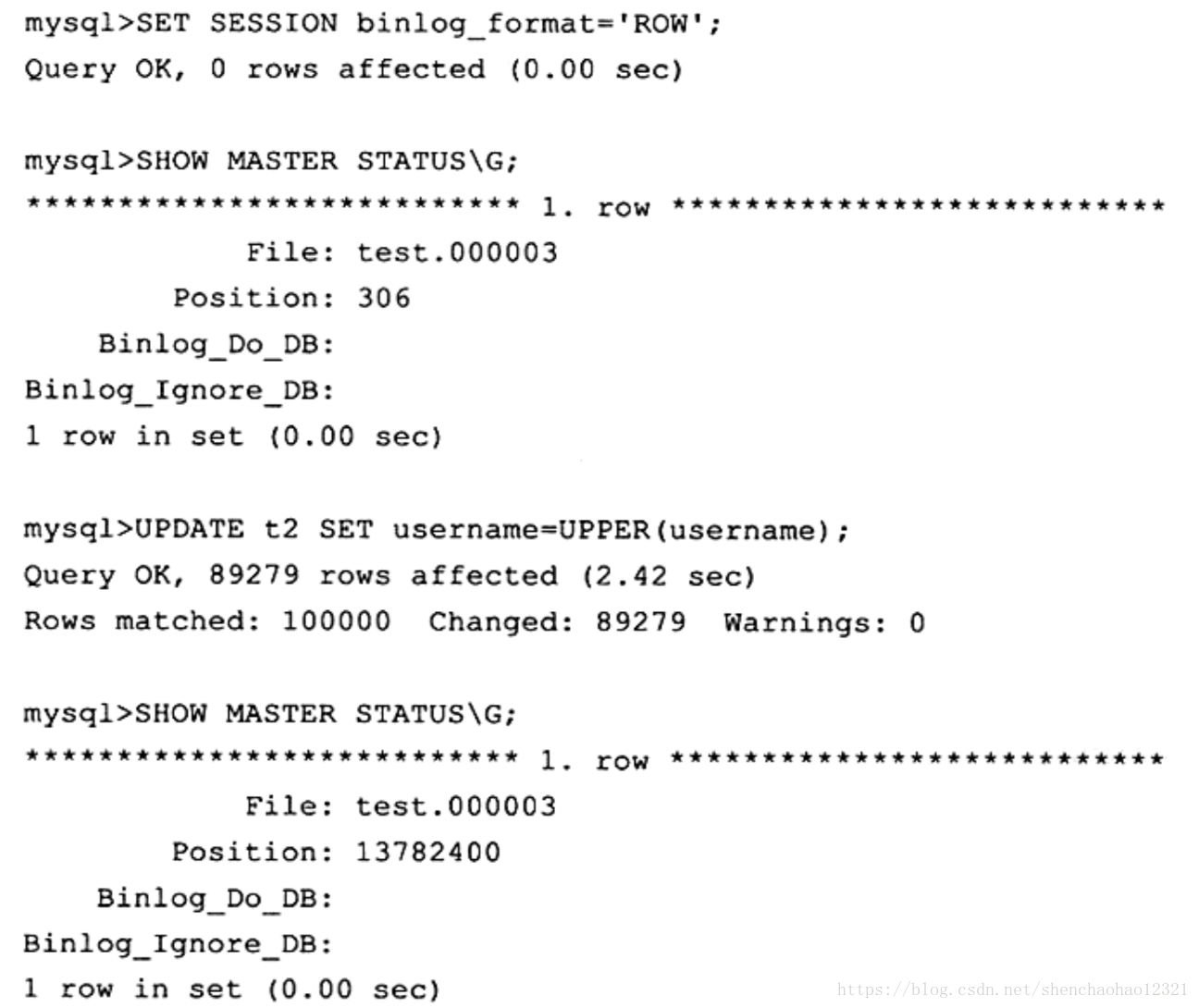
这时会惊讶地发现,同样的操作在ROW格式下竟然需要13782094字节,二进制日志文件的大小差不多增加了13MB,要知道t2表的大小也不超过17MB。而且执行时间也有所增加(这里我设置了sync_binlog=1)。这是因为这时 MySQL数据库不再将逻辑的SQL操作记录到二进制日志中,而是记录对于每行的更改。
上面的这个例子告诉我们,将参数 binlog_format设置为ROW,会对磁盘空间要求有一定的增加。而由于复制是采用传输二进制日志方式实现的,因此复制的网络开销也有所增加。
进制日志文件的文件格式为二进制(好像有点废话),不能像错误日志文件、慢查询日志文件那样用cat、head、tail等命令来查看。要查看二进制日志文件的内容,必须通过 MySQL提供的工具 mysqlbinlog。对于 STATEMENT格式的二进制日志文件,在使用 mysqlbinlog后,看到的就是执行的逻辑SQL语句,如:
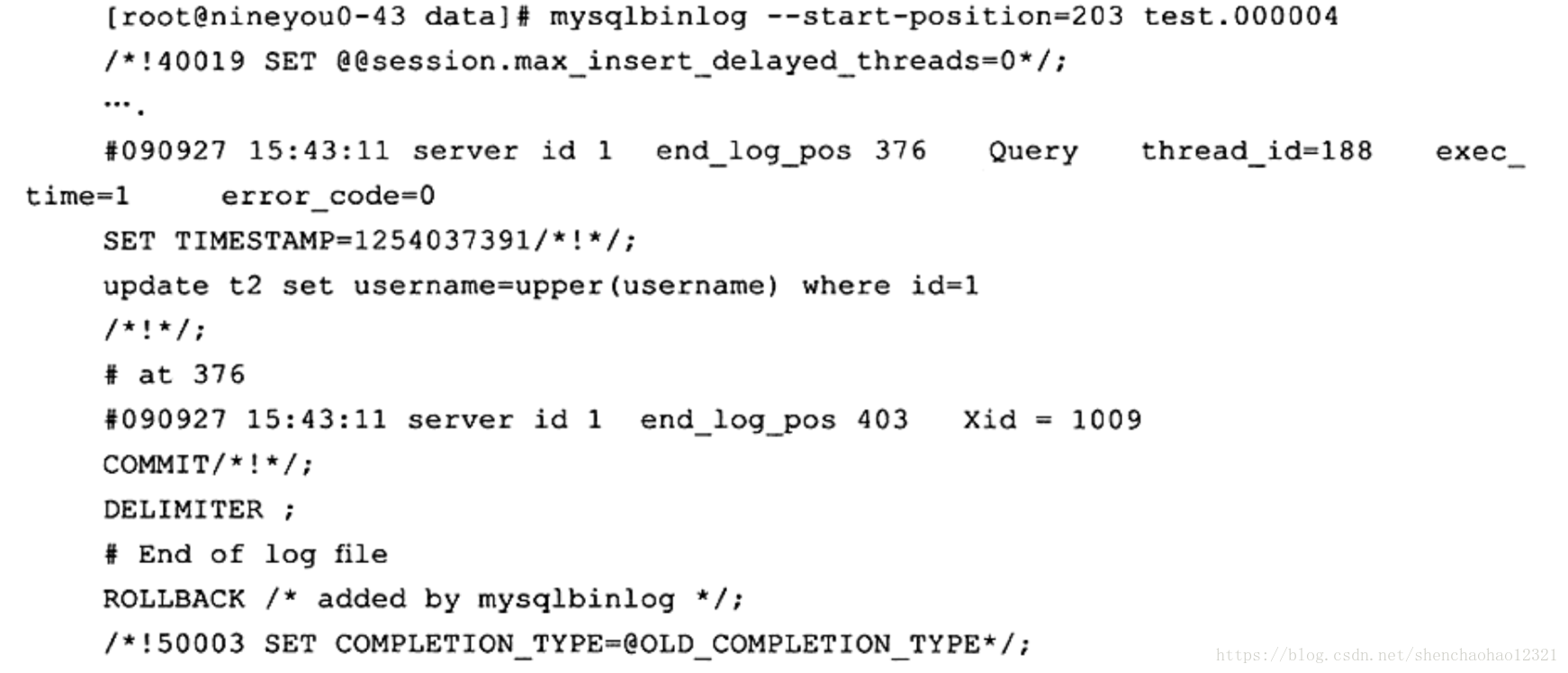
通过SQL语句 UPDATE t2 SET username= UPPER( username) WHERE id=1可以看到,二进制日志的记录采用SQL语句的方式。在这种情况下, mysqlbinlog和 Oracle LogMiner类似。但是如果这时使用ROW格式的记录方式,会发现 mysqlbinlog的结果变得“不可读”( unreadable),如:
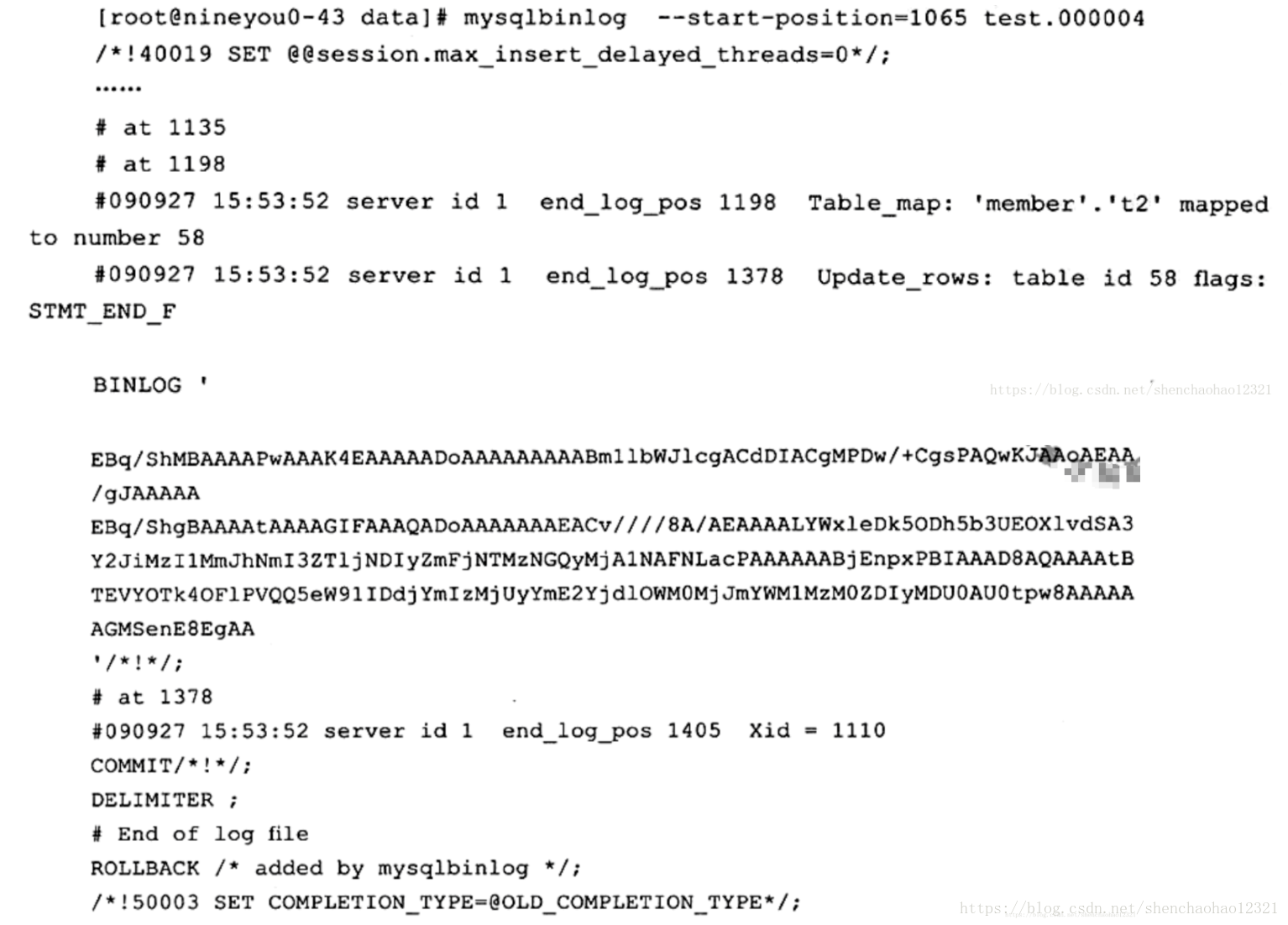
这里看不到执行的SQL语句,反而是一大串用户不可读的字符。其实只要加上参数或-vv就能清楚地看到执行的具体信息了。-vv会比-v多显示出更新的类型。加上-vv选项,可以得到:
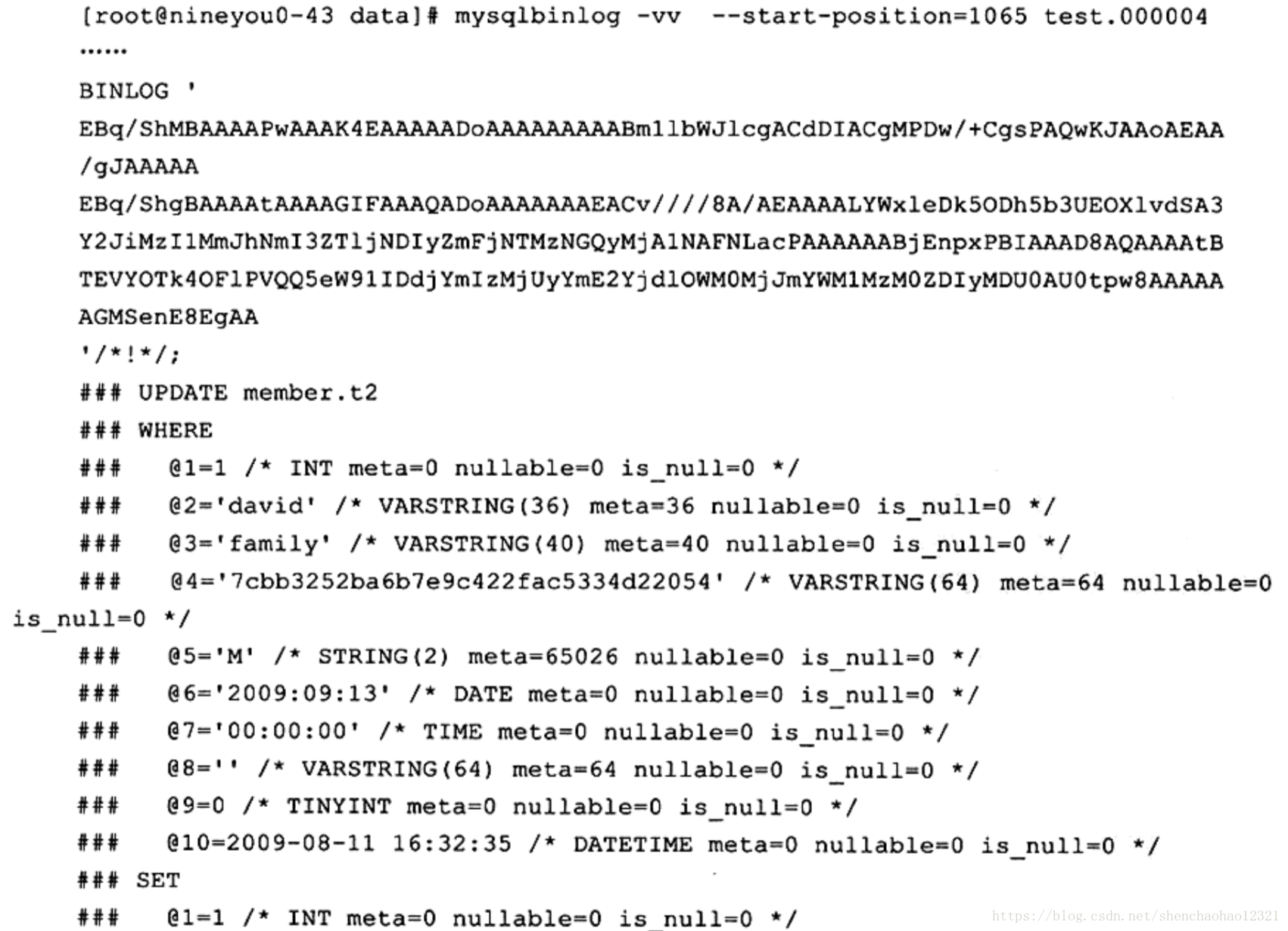
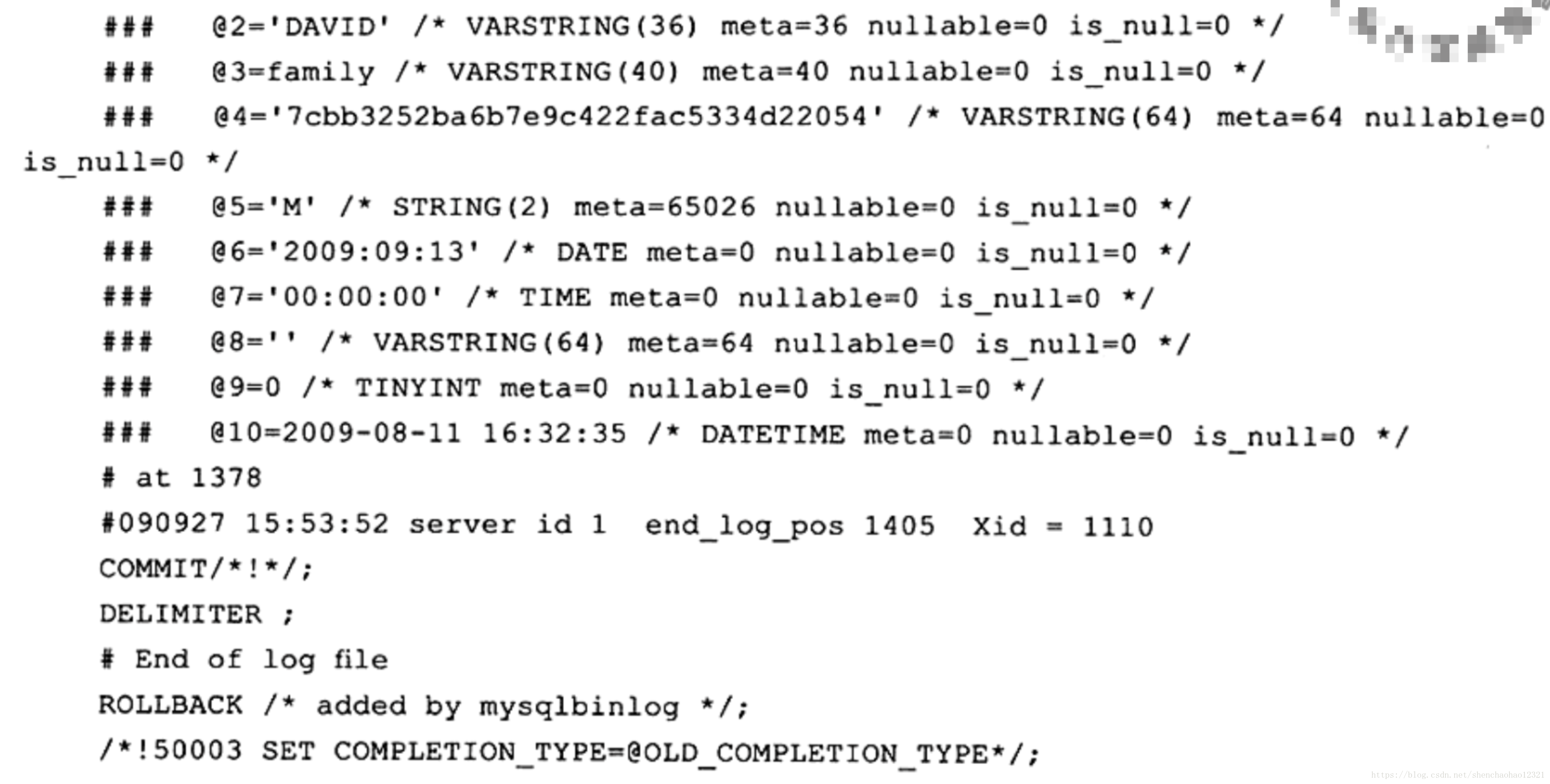
现在 mysqlbinlog向我们解释了它具体做的事情。可以看到,一句简单的 update t2 set username= upper( username) where id=1语句记录了对于整个行更改的信息,这也解释了为什么前面更新了10W行的数据,在ROW格式下,二进制日志文件会增大13MB。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
