Kafka Broker基于Reactor模式,通过I/O多路复用来完成请求的处理,所以具有极高的吞吐量。关于I/O多路复用,我在其它的专栏里反复讲解过多次了。本章,我再来针对Kafka讲解下它是如何实现多路复用的。
一、工作流程
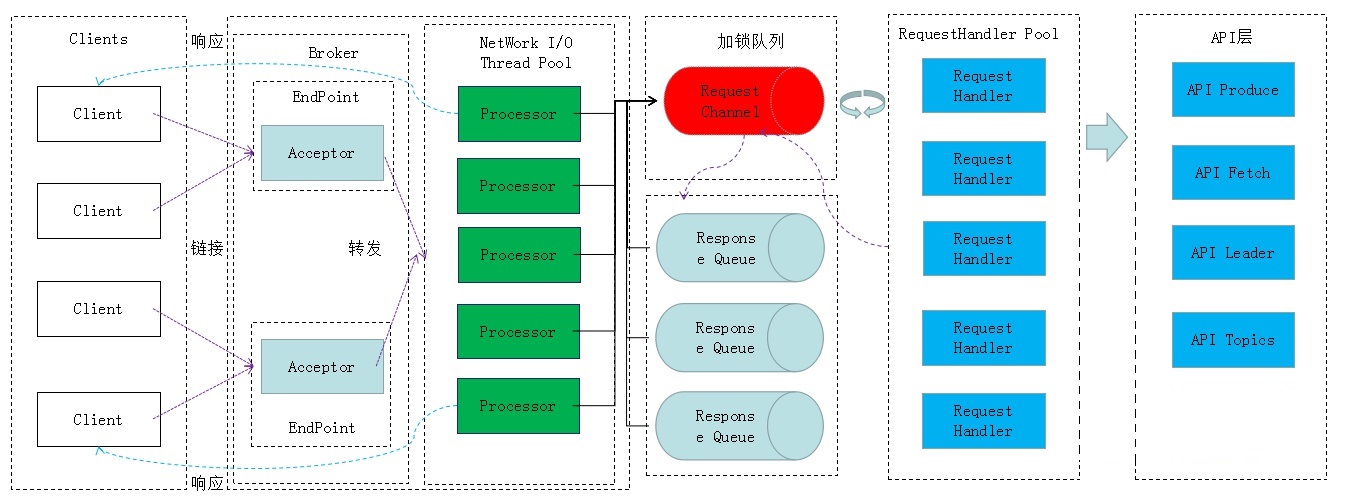
每个Kafka Broker上都有一个Acceptor线程和多个Processor线程:
- Kafka Broker通过Acceptor监听每个新的Socket连接,建立连接成功后,会采用Round Robin的轮询方式,将Socket连接分配给Processor线程;
- Processor线程负责处理这个Socket连接,每一个Processor都有一个Selector,可以非阻塞的处理多个客户端的读写请求,包括读取数据和将响应返回给对应Client,但是Processor本身不处理具体的业务逻辑;
- 所有Processor都会把请求放入一个Broker全局唯一的请求队列,默认大小是500,可以通过
queued.max.requests参数设置; - 接着,有一个 KafkaRequestHandler 线程池负责不停的从队列中获取请求来处理,这个线程池大小默认是8个,可通过
num.io.threads参数控制,处理完请求后的响应,会放入每个Processor自己的响应队列ResponseQueue里; - 最后,Processor会监听自己的响应队列,把响应拿出来通过Socket连接返回给客户端。
整个流程如下图:
通过参数
num.network.threads可以设置processor线程的数量,默认值是3。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
