了解了Kafka的整体架构之后,我将站在客户端的角度对Kafka的生产者(Producer)和消费者(Consumer)进行讲解。本章,我们先从Producer开始,我将讲解Producer的基本原理,通过本章的内容,读者可以理解一条消息从生产到发送的整个流程。
一、基本使用
我们先来看下Producer的基本使用,一个正常的消息发送逻辑需要具备以下几个步骤 :
- 配置生产者客户端参数,创建相应的生产者实例;
- 创建待发送的消息;
- 发送消息;
- 关闭生产者实例。
来看一个示例,更好的体会下:
public class ProducerDemo {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
// 配置Broker地址,配置几台即可,Producer会从Broker拉取Topic的元数据并缓存
props.put("bootstrap.servers", "ressmix01:9092,ressmix02:9092,ressmix03:9092");
// key序列化器
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化器
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 要求所有ISR中的副本写入成功
props.put("acks", "-1");
props.put("retries", 3);
// 每个批量发送
props.put("batch.size", 323840);
props.put("linger.ms", 10);
// 发送消息的缓冲区大小,32MB
props.put("buffer.memory", 33554432);
// 发送消息的缓冲区满时,阻塞超时时间
props.put("max.block.ms", 3000);
// 创建一个Producer实例
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 创建一个条消息
ProducerRecord<String, String> record = new ProducerRecord<>(
"test-topic", "test-key", "test-value");
// 采用异步发送模式
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
// 消息发送成功
System.out.println("消息发送成功");
} else {
// 消息发送失败,需要重新发送
}
}
});
Thread.sleep(10 * 1000);
// 采用同步发送模式
// producer.send(record).get();
// 关闭Producer
producer.close();
}
}
对于 Kafka Producer 而言,它是 线程安全 的,我们可以在多线程的环境中复用它。
二、核心原理
Producer的整体架构如下,它由两个线程协调运行: 主线程 和 Sender线程 。主线程主要负责控制消息的创建和封装,Sender线程负责实际的消息发送。
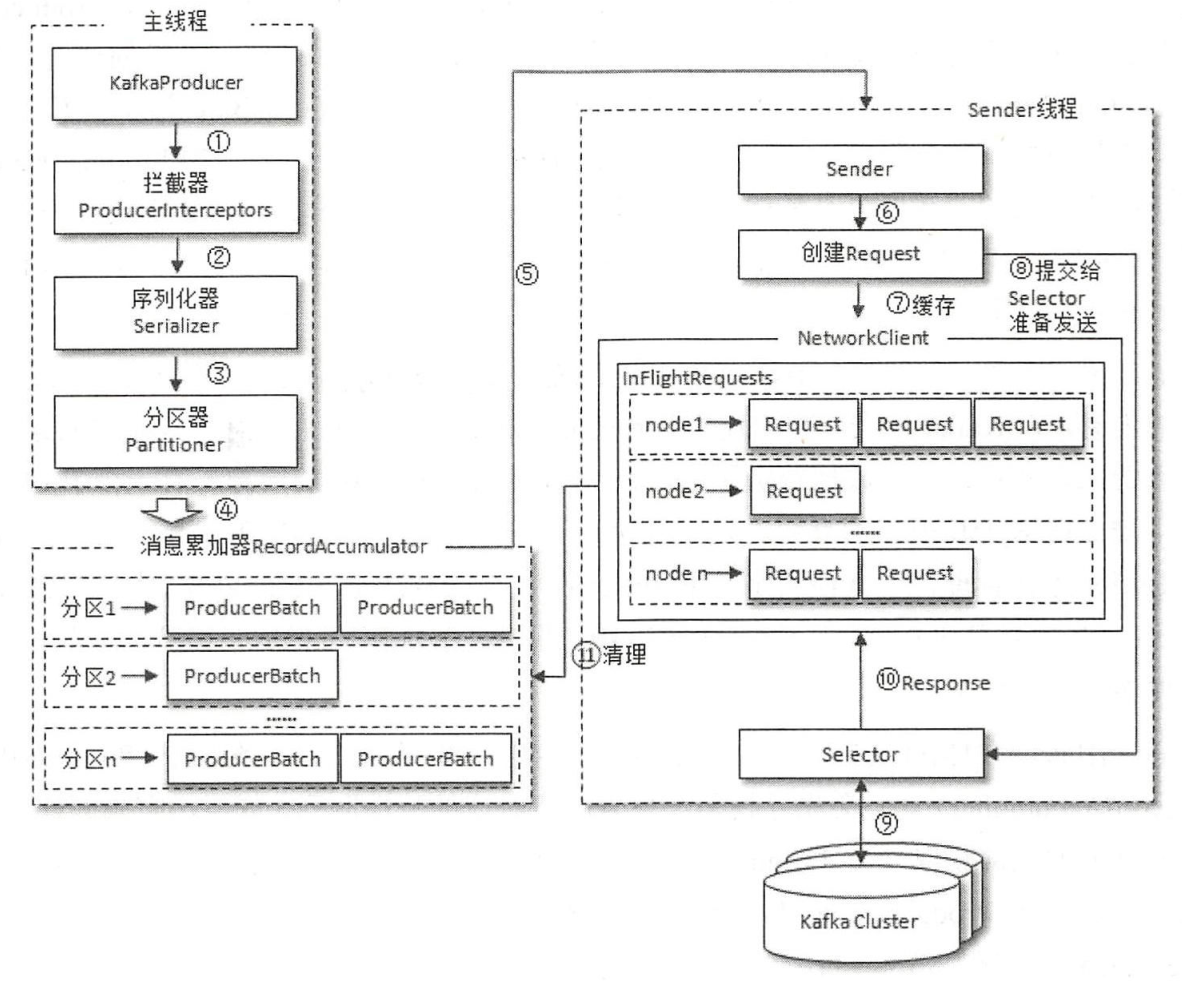
2.1 主线程
我来讲解下上述消息发送的流程,首先来看主线程的操作:
- 首先,Producer发送消息时,必须把消息封装成一个
ProducerRecord对象,里面包含了要发送的Topic、发送到哪个分区、分区Key、消息内容、时间戳等等; - 接着,如果有定义拦截器,消息会先被 拦截器 处理一下;
- 然后
ProducerRecord对象会被交给 序列化器 ,转化成自定义的协议格式; - 接着,数据会被交给 Partitioner分区器 ,它会选择一个合适的分区(默认采用轮询策略,如果指定了分区Key,则根据Key进行hash路由);
- 最后,消息会被发送到Producer内部的一块缓冲区 RecordAccumulator 里。
RecordAccumulator,也叫做消息累加器,它的内部为每个分区都准备了一个双端队列( Deque ),消息会被按批次封装成 ProducerBatch 对象并入队,ProducerBatch中可以包含多个ProducerRecord。
所以,如果Producer发送消息的速度太快,就会导致RecordAccumulator缓存空间不足,此时主线程就会阻塞,直到超时抛出异常,可以通过参数max.block.ms 配置超时时间,默认值60000,即 60 秒。
RecordAccumulator主要用来缓存消息,以便 Sender 线程可以批量发送消息,进而减少网络传输的资源消耗,提升性能 。RecordAccumulator缓存的大小可以通过Producer客户端参数
buffer.memory配置,默认32MB。
2.2 Sender线程
Producer内部还有一个Sender线程,负责消息的真正发送:
- 首先,Sender线程从 RecordAccumulator缓冲区获取消息;
- 然后,会将消息转变成
<Node, List< ProducerBatch>的形式,其中 Node 表示 Kafka集群的 Broker 节点 ; - 接着,再进行一次转换,封装成
<Node,Request>的形式; - 最后,Sender 线程在将消息发往 Broker之前,还会将消息保存到 InFlightRequests 中, InFlightRequests 的具体形式为
Map<Nodeld, Deque<Request>>,它的主要作用是缓存已经发出去但还没有收到响应的请求。InFlightRequests 中还未确认的请求越多,则说明该Node的负载越大 。
我们可以限制Producer与Broker之间连接的最多缓存请求数,通过参数
max.in.flight.requests.per.connection设置,默认值为 5,即每个连接最多只能缓存 5 个未响应的请求,超过就不能再向这个连接发送更多的请求了。如果该参数值设置为1,就表示Producer同一时间只能发送一条消息。
三、核心参数
1. ack
指定分区中必须要有多少个副本收到这条消息,生产者才会认为这条消息写入成功。
- acks = 1:默认值,即Leader成功写入即可;
- acks = 0:不管写入Broker的消息到底成功没有,发出去就认为成功了,适合实时数据流分析的业务和场景;
- acks = all/-1:等待 ISR 中的所有副本都成功 。
2. max.request.size
设置生产者能发送的消息的最大值,默认值为 1048576B,即 1MB。一般情况下,生产环境会把这个值设置得大一些,比如10MB。
3. retries
生产者发送消息失败时的重次数,默认值为 0,即不重试。如果重试达到指定次数还失败,就抛出异常。一般重试主要用于解决网络抖动和Partition Leader宕机重新选择的问题。
4. retry.backoff.ms
重试间隔时间,默认值100,即100ms。
5. request.timeout.ms
设置 Producer 等待请求响应的最长时间,默认值为30000,即30秒,超过这个时间收不到响应,就会抛出TimeoutException异常。注意,这个参数值需要比Broker端的replica.lag.time.max.ms参数值大,这样可以减少因Producer重试而引起的消息重复的概率。
6. buffer.memory
Producer客户端中用于缓存消息的缓冲区大小,默认值为33554432 ( 32MB) 。
7. max.block.ms
当生产者的发送缓冲区满了,主线程就会阻塞,默认阻塞60秒。
8. batch.size
消息会被按批次封装成 ProducerBatch 对象,这个参数用来设置batch的大小,默认值是16384,即16kb。如果batch设置太小,会导致频繁网络请求,吞吐量下降;如果batch设置太大,会导致消息被缓存很久才能发送出去,导致延时增加。一般如果要在生产环境改变该值,则需要进行压测确定。
9. linger.ms
这个参数用来设置消息在缓存区的最大逗留时间,默认值为0,即消息不过缓冲区立即被发送出去。一般生产上会设置该值为10-100ms,也就是说,消息首先进入缓冲区并按批次处理,如果100ms内batch满了(默认16kb),那么消息会被发送出去,如果100ms内batch没满,那么消息也会被发送出去。这样就可以防止消息的发送延迟过长,避免给缓冲区内存造成过大的压力。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
