1、概述
目前业界有很多消息中间件可供大家选择,主要分为两类:需要付费的商业软件和开源共享的非商业软件。对于商业软件您和您的团队可以选择IBM WebSphere集成的MQ功能,也可以选择Oracle WebLogic集成的MQ功能。本文首先介绍除Apache ActiveMQ以外的两款开源共享的消息中间件产品,然后列举三个实际的业务常见,为读者介绍如何在这些实际业务中使用消息中间件解决问题。
2、RabbitMQ及特性
RabbitMQ基于Erlang语言开发和运行。它与Apache ActiveMQ有很多相同的特性,例如RabbitMQ完整支持多种消息协议:AMQP、STOMP、MQTT、HTTP,我们使用RabbitMQ时会默认使用AMQP1.0 协议。当然,RabbitMQ作为Apache ActiveMQ最主要的竞品之一也有其独特的功能特性。例如RabbitMQ支持一套特有的Routing-Exchange消息路由规则。这套规则可以按照消息内容,自动将消息归类到不同的消息队列中。关于这套Routing-Exchange消息路由规则可参见我另一篇文章的详细介绍:架构设计:系统间通信(20)——MQ:消息协议(下)
2-1、RabbitMQ软件特性
下面我们来看看RabbitMQ官网上对这款消息中间件软件的特性介绍:
- Reliability(可靠性):
RabbitMQ offers a variety of features to let you trade off performance with reliability, including persistence, delivery acknowledgements, publisher confirms, and high availability.
RabbitMQ支持消息持久化、消息重试操作(比ActiveMQ的相关功能还要强大)、消息回执确认规则、消息生产者发送确认机制(实际上是消息生产者端的一种事务机制)和高可用性HA(多节点热备方案)等特性来提供RabbitMQ服务的高可靠性。
- Flexible Routing(灵活的路由规则):
Messages are routed through exchanges before arriving at queues. RabbitMQ features several built-in exchange types for typical routing logic. For more complex routing you can bind exchanges together or even write your own exchange type as a plugin.
这就是我们提到的RabbitMQ所支持的一套特有的Routing-Exchange消息路由规则。 一定注意这套规则不是AMQP协议规范提供的 。关于个消息路由规则可参见我另一篇文章的详细介绍:架构设计:系统间通信(20)——MQ:消息协议(下)
- Clustering(RabbitMQ服务集群):
Several RabbitMQ servers on a local network can be clustered together, forming a single logical broker。
RabbitMQ服务集群主要解决的问题是单个RabbitMQ服务节点的性能瓶颈。关于RabbmitMQ集群的搭建过程由于本文篇幅限制,我将随后安排时间为各位读者详细介绍。
- Plugin System & Federation(支持第三方插件模块,其中RabbitMQ Federation [插件]需要特别说明):
RabbitMQ ships with a variety of plugins extending it in different ways, and you can also write your own.
For servers that need to be more loosely and unreliably connected than clustering allows, RabbitMQ offers a federation model.
RabbitMQ支持第三方扩展插件,在RabbitMQ的官网上(http://www.rabbitmq.com/plugins.html)列举了各种由RabbitMQ官方开发的插件,以及实验性质的插件,包括(但不限于):rabbitmq_federation、rabbitmq_management、rabbitmq_mqtt、rabbitmq_stomp、rabbitmq_tracing等等。您还可以按照RabbitMQ提供的插件规范,开发您自己的RabbitMQ-Plugins。特别说明一下rabbitmq_federation 插件:这个插件允许您在多个RabbitMQ Clusters之间传递消息。
- Multi-protocol(多协议支持):
RabbitMQ supports messaging over a variety of messaging protocols.
上文已经提到,RabbitMQ完整支持多种消息协议,包括:AMQP(默认使用该协议)、STOMP、MQTT、HTTP。其中一些协议要安装相应的插件进行支持,例如rabbitmq_stomp插件。
- Many Clients(多客户端/多语言支持):
There are RabbitMQ clients for almost any language you can think of.
您可以想到的各种编程语言都可以作为RabbitMQ的客户端进行连接,包括(但不限于):Java 、.NET 、Ruby、 Python 、PHP、 JavaScript、Scala、Groovy……
- Tracing(消息追溯):
If your messaging system is misbehaving, RabbitMQ offers tracing support to let you find out what’s going on.
如果您发现发送给RabbitMQ的消息存在异常(如发送到了错误的队列中,发送给了错误的订阅者等等),RabbitMQ提供了消息处理过程追溯功能,以便帮助开发人员分析错误原因。
2-2、RabbitMQ使用概要
RabbitMQ的安装过程非常简单:由于RabbitMQ是基于Erlang语言开发并运行的,所以 安装RabbitMQ的第一步是安装Erlang运行环境 。您可以在https://www.erlang-solutions.com/resources 下载最新Erlang版本进行安装(注意不同的RabbitMQ版本有不同的Erlang最低版本要求,笔者使用的RabbitMQ版本为V3.5.4,Erlang版本为V18.0);
接下来您可以在RabbitMQ官方(http://www.rabbitmq.com/)下载各种RabbitMQ的安装版本,建议直接使用各种操作系统对应的rpm文件进行安装即可。安装完成后,可以使用15672端口访问RabbitMQ的管理界面(默认的用户名和密码都是guest)
以下代码演示了如何使用RabbitMQ的客户端开发包,进行消息生产和消费。RabbitMQ的客户端开发包可以在RabbitMQ官网进行下载(http://www.rabbitmq.com/java-client.html),也可以使用Mavean官方库进行导入:
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>3.5.4</version>
</dependency>
- RabbitMQ消息生产者
package com.yinwenjie.test.testRabbitMQ;
import java.io.IOException;
import java.util.Date;
import java.util.UUID;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import com.rabbitmq.client.AMQP.BasicProperties;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
/**
* 这个测试类,用于模拟消息生成者,每100毫秒,向rabbit集群写入不同的消息
* @author yinwenjie
*/
public class RabbitProducerThread implements Runnable {
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(RabbitProducerThread.class);
public static void main(String[] args) throws Exception {
new Thread(new RabbitProducerThread()).start();
}
public void run() {
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("localhost");
//连接集群节点就这么设置
// connectionFactory.newConnection(addrs)
Connection conn = null;
Channel producerChannel = null;
try {
conn = connectionFactory.newConnection();
producerChannel = conn.createChannel();
} catch (Exception e) {
RabbitProducerThread.LOGGER.error(e.getMessage() , e);
System.exit(-1);
}
//然后每隔100毫秒,发送一条数据
while(true) {
// 消息的唯一编号
String uuid = UUID.randomUUID().toString();
String message = uuid + ";time=" + new Date().getTime();
//设置一些参数
BasicProperties properties = new BasicProperties().builder().type("String").
contentType("text").contentEncoding("UTF-8").messageId(uuid).build();
try {
//第一个参数是exchange交换器的名字
//第二个参数是进行消息路由的关键key
producerChannel.basicPublish("com.ai.sboss.arrangement.event", "com.ai.sboss.arrangement.event.queues", properties, message.getBytes());
RabbitProducerThread.LOGGER.info("消息发送:" + message);
} catch (IOException e) {
RabbitProducerThread.LOGGER.error(e.getMessage() , e);
}
synchronized (this) {
try {
this.wait(3000);
} catch (InterruptedException e) {
RabbitProducerThread.LOGGER.error(e.getMessage() , e);
}
}
}
}
}
- RabbitMQ消息消费者
package com.yinwenjie.test.testRabbitMQ;
import java.io.IOException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import com.rabbitmq.client.AMQP.BasicProperties;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.QueueingConsumer;
/**
* 这个测试类,用于模拟消息消费者
* @author yinwenjie
*/
public class RabbitConsumerThread implements Runnable {
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(RabbitConsumerThread.class);
public static void main(String[] args) throws Exception {
new Thread(new RabbitConsumerThread()).start();
}
public void run() {
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("localhost");
//连接集群节点就这么设置
//connectionFactory.newConnection(addrs)
Connection conn = null;
Channel consumerChannel = null;
try {
conn = connectionFactory.newConnection();
consumerChannel = conn.createChannel();
} catch (Exception e) {
RabbitConsumerThread.LOGGER.error(e.getMessage() , e);
System.exit(-1);
}
//开始监控消息,(ack是手动的)
QueueingConsumer queueingConsumer = null;
try {
queueingConsumer = new QueueingConsumer(consumerChannel);
// 设置消费者订阅的消息队列名:com.ai.sboss.arrangement.event.queues
consumerChannel.basicConsume("com.ai.sboss.arrangement.event.queues", false, queueingConsumer);
} catch (IOException e) {
RabbitConsumerThread.LOGGER.error(e.getMessage() , e);
System.exit(-1);
}
//停顿200毫秒,才处理下一条,以便模拟事件处理对应的消耗事件
while(true) {
QueueingConsumer.Delivery delivery = null;
try {
delivery = queueingConsumer.nextDelivery();
} catch (Exception e) {
RabbitConsumerThread.LOGGER.error(e.getMessage() , e);
}
long deliverytag = delivery.getEnvelope().getDeliveryTag();
byte[] messageBytes = delivery.getBody();
BasicProperties properties = delivery.getProperties();
String message = new String(messageBytes);
RabbitConsumerThread.LOGGER.info("收到事件======message = " + message + " | properties =" +properties);
//这里停顿200毫秒,模拟业务时间
synchronized (this) {
try {
this.wait(200);
} catch (InterruptedException e) {
RabbitConsumerThread.LOGGER.error(e.getMessage() , e);
}
}
RabbitConsumerThread.LOGGER.info("事件message = " + message + "处理完成,发送ack。等待下一条消息");
try {
// 发送ack:消息处理成功的确认信号
consumerChannel.basicAck(deliverytag, false);
} catch (IOException e) {
RabbitConsumerThread.LOGGER.error(e.getMessage() , e);
}
}
}
}
3、场景应用——电子政务平台:驾驶人违法记录同步功能
3-1、业务场景说明
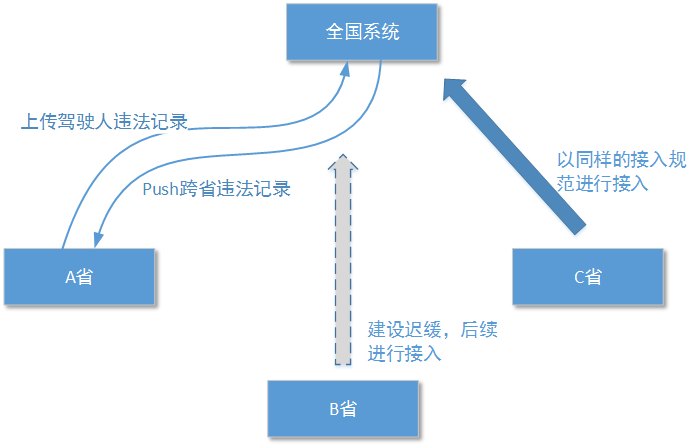
只是一个为了汇总全国机动车违法记录而设计的多系统数据同步功能。最主要的功能是进行违法记录的上传以及在各省间同步跨省违法记录。在进行架构设计之前,我们首先需要了解一些关于整个系统业务背景: 任何系统设计都不能脱离系统实际业务背景而存在 !
- 首先整个系统分为全国系统和32个省级系统 :由于每个省都有符合该省实际情况的、处理过程完全不同的违法记录处理操作。并且每个省的驾管系统电子化推进情况也不尽相同:有的省已经走在了全国的前列,基本上所有驾管业务数据都已经与全国系统实现了同步;有的省可能才开始建设,甚至都没有自己的违法记录电子信息。
- 违法记录信息的同步过程分为上行同步和下行同步 :驾驶人违法记录信息需要从省级系统实现到全国系统的同步(至于是省级系统确认违法信息时立即进行同步,还是省级系统在某个固定的时间周期统一进行同步,这就是给各省级系统自己的处置权了),这样的同步过程称为 上行同步 。如果某个违法者是在本省违法的,那么直接进行上行同步就可以了;如果某个违法者是在外省违法,那么除了进行上行同步外, 当全国系统发现这是一条异地违法记录,并且违法者身份证所在省已经接入了全国系统 ,就需要通过全国系统将这条违法记录 向违法者身份证所在省 的省级系统进行同步,这样的同步过程称为 下行同步 。
- 如果某省的系统新接入了全国系统,那么全国系统需要在这个省的系统同步功能模块准备好后,将这个省接入全国系统前所相关的跨省异地违法记录全部进行一次上行同步和下行同步 。那么什么叫“省级系统准备好”呢?不一定接入全国系统的每个省级系统都能立刻稳定的工作,任何系统都有一个稳定周期。在这个稳定周期内,开发团队需要完成诸如观察系统工作情况、调整功能模块的运算性能、进行软件Bug修改、进行软件操作过程优化等等工作。
- 另外各省的软件供应商不尽一样,使用的开发语言也不相同。所以在考虑接入方案时,需要方案支持多种编程语言,或者是使用多种语言都支持的一种通用协议。另外省级系统和全国系统应该尽可能的进行业务脱耦,这样才可以保证省级系统的软件供应商不必为了实现违法记录上行同步和下行同步功能专门更改编程语言,也不必为了实现以上功能专门调整省级系统的固有业务过程和系统架构(有的时候因为技术问题调整业务过程客户方是绝对不会答应的)。
- 由于是演示场景,目的是演示消息系统中间件在这个需求场景实现方案中的作用。所以我们假设整个需求环境是具有“要实现违法记录信息同步”的前置功能/前置条件的。这些前置功能/前置环境包括(但不限于):全国驾驶人基本档案信息库(这部分信息可能也是通过各省级系统同步而来)、全国人口身份信息库等。
3-2、总体设计思路
以上业务场景是一个典型的需要使用支持事务的消息中间件的应用场景—— 追求消息到达和处理的稳定性 ,您可以使用本章我们详细介绍的ActiveMQ也可以使用上一节介绍的RabbitMQ:因为他们都支持多语言接入,都提供消息事务支持,都支持消费者侧的消息回执确认。另外,这个业务场景中也要兼顾一定的数据吞吐量。
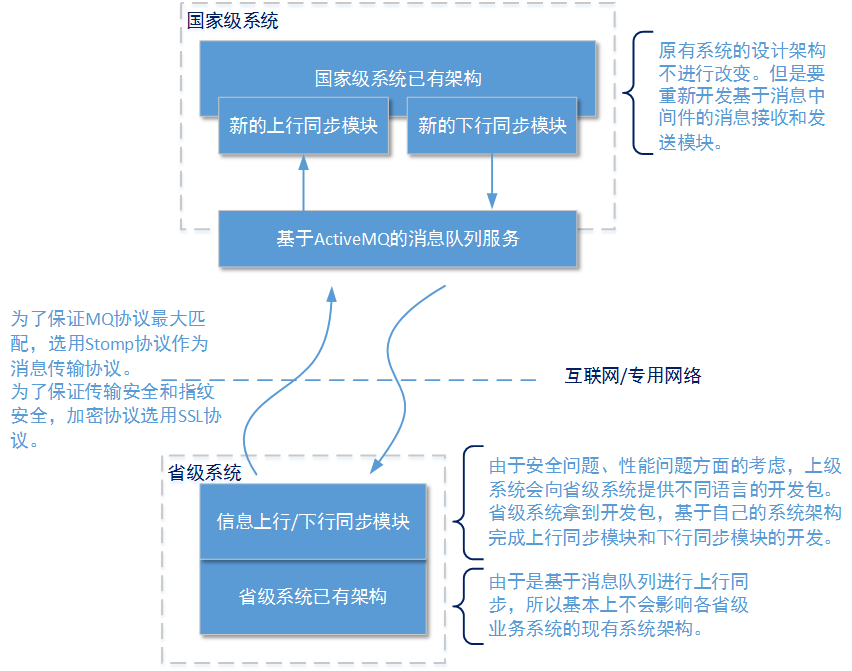
- 在已有的系统中加入消息队列服务最大的目的是 保持已有系统的原始架构不作调整 。不作调整的原因可能是因为原有系统由于设计不当已经不可能再做大的调整,否则将付出无法承受的代价;也可能是由于非技术原因,技术团队没有相应的权限调整已有架构设计。
- 采用消息队列服务方案的另一个优点是可以 缓解数据洪峰 。在这个示例场景中最典型的体现就是:需求中明确的提到,当一个省级系统新接入时,需要进行一次完整的违法记录的上行同步和下行同步。这样的话有可能在这个省级系统上积累了7、8年的违法记录会被同步到全国系统,这个过程可能会出现一定的数据堆积。但是由于我们给出的消息服务中间件的数据持久化性能较为强劲(请参见下一小节的详细设计),所以数据同步压力基本上不会传递到上层系统的业务处理层。
- 分析场景中对于省级系统接入的需求描述,技术层面上最大的几个问题是:不同省级系统采用的架构不一样,使用的编程语言不一样,技术团队水平不一样。为了保证接入方案的安全效果、性能效果和工作效率, 全国系统应该为省级系统提供不同的语言开发包和集成文档 (类似于集成微信/支付宝/淘宝等开放平台);根据经验,全国系统应首先为各省级系统优先提供JAVA和C#的集成开发包。
- 开发包中主要对连接消息服务队列的行为进行封装、对上行消息和下行消息的文本格式进行规范(保证各省系统上行消息的文本格式是一致的,保证各省收到的下行消息都是上级系统所统一的格式)、 对消息的加密和解密协议进行封装、对消息发送过程和消息订阅过程进行封装(包括消息生产者进行上行消息的发送和消息消费者进行下行消息的接收)。另外,为了保证传输过程文本消息的通讯安全,开发包中还封装了SSL加密/解密过程。
- 最后,由于要保证所有的上行消息和下行消息一定会被目标系统正常处理。所以这些消息都应该是PERSISTENT Meaage形式的消息。并且无论是上行消息还是下行消息, 都应该在超出重试次数后被放置到“死信队列”(Dead Letter Queue),以便进行人工干预 。重试次数应该设置为2——3次左右,因为ActiveMQ默认重发6次(redeliveryCounter==6)的值过大,在消息出现问题时重试次数过多会严重影响消息中间件服务的处理效率。
3-3、消息队列服务详细设计
下面我们来具体分析一下在这个实例场景下消息队列服务部分的架构设计(即上图中“基于ActiveMQ的消息队列服务”部分的设计)。架构详细设计部分分为硬件结构设计和软件规则设计部分,我们首先讨论硬件设计部分的方案。
3-3-1、硬件方案部分
其中硬件部分的设计来源于上一节文章中已经提到的ActiveMQ服务集群的综合应用(《架构设计:系统间通信(26)——ActiveMQ集群方案(下)》),为了保证每个ActiveMQ节点都能高效工作,我们还按照上文提到的ActiveMQ服务单节点的性能优化原则进行了相应配置(《架构设计:系统间通信(22)——提高ActiveMQ工作性能(上)》)。
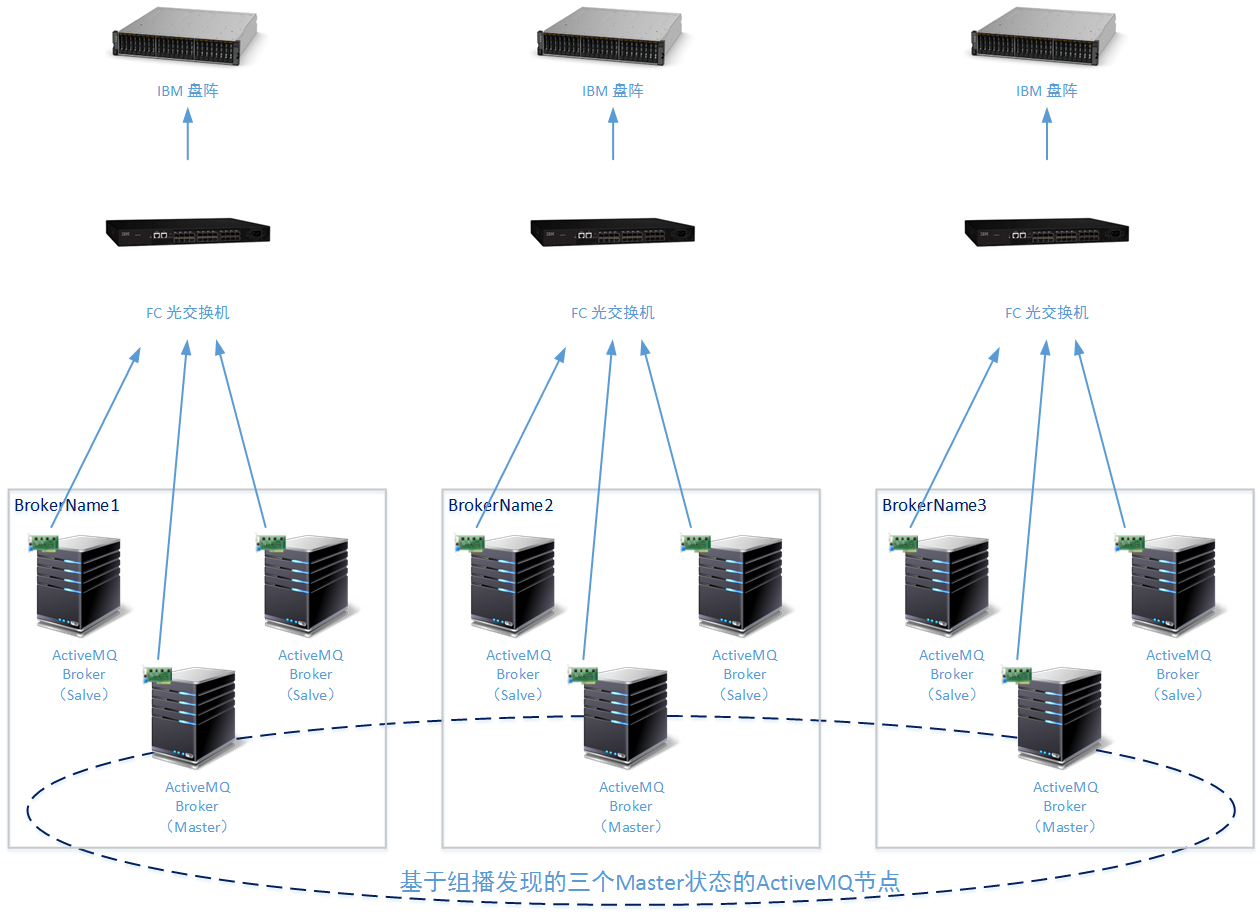
在这个示例的应用场景中,虽然高并发性并不是建设方主要追求的。但如上文所述,为了保证在数据洪峰出现时数据处理压力不传递给业务服务,并且ActiveMQ服务集群能够尽快完成数据洪峰的吞吐工作(在建设方预算允许的情况下),我们为每一组ActiveMQ M/S集群选择了IBM的基于SAN(Storage Area Network)的共享存储解决方案。其中使用的IBM Storwize V7000存储盘阵设置成RIDA5模式,并配置20TB存储空间。
实际上在这个示例场景中,之所以采用这样的硬件设计方案更是为了在有限的篇幅内为读者讲解更多的设计方式。由于使用了基于SAN的共享存储方案,所以之前提到的LevelDB + zookeeper的热备方案就不必再使用了(当然LevelDB + zookeeper的方案也是可选方案)。为了节约成本,也可以多组SAN共享存储使用用一台FC 光交换机和一台存储盘阵,但是 这样可能出现因为FC光交换机的单点故障或者磁盘阵列单点故障导致整个集群宕机的情况 :

3-3-2、软件规则部分
在前文提到,由于省级系统都使用了全国系统统一提供的开发包进行上行消息和下行消息的处理,所以接入消息同步功能的所有系统都不必担心消息文本的格式问题;那么在ActiveMQ消息队列服务的业务规则部分,最重要的规则就是如何规划上行消息和下行消息存储的队列。
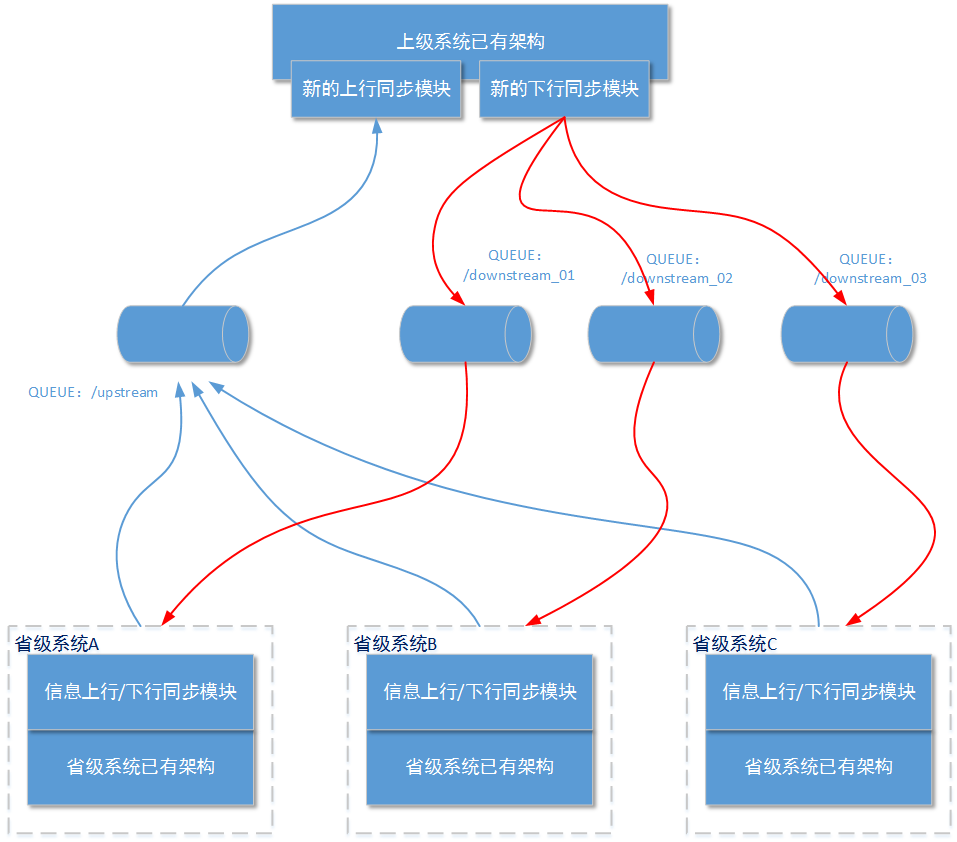
如上图所示所有省级系统的上行消息同时共享一个消息队列,这是因为这些省级系统都是使用上级系统统一提供的开发包进行二次开发,所以无论哪个省级系统向上同步的消息格式都是一致的(且进行了内容加密),所以它们可以共享一个消息队列,并由上级系统使用一套相同的处理逻辑进行接受。
当上级系统发现有跨省产生的违法记录时,就需要通过下行队列将这个违法记录发送给违法者所在省的省级系统,这些下行信息由于有不同的消费者(省级系统),且这些消费者所涉及的业务处理逻辑都可能不一样,所以应该使用不同的消息队列来发送针对不同省级系统的下行队列。另外,这样的消息下发机制还可以保证在省级系统出现故障时,下行消息不会丢失——直到这些下行消息被对应的省级系统正确处理。
3-4、主要代码片段
由于整个方案需要相当的代码编写工作,所以不可能在这个示例场景中演示所有的代码实现。为了让读者能够了解其中更细节的实现情况,在这个小节中我们重点演示主要的代码实现片段(使用Java语言)。包括省级系统开发包中如何进行上行队列的连接,如何开始监听下行队列—— 只有同时成功建立上行队列连接和下行队列连接,才能认为信息同步模块启动成功了 。
为了保证信息同步模块独立于现有系统的其他功能模块进行工作,应该使用专门的新线程建立上行队列连接和下行队列连接:
package mq.test.blog;
import javax.jms.Connection;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.MessageConsumer;
import javax.jms.MessageListener;
import javax.jms.MessageProducer;
import javax.jms.Session;
import org.apache.activemq.ActiveMQConnectionFactory;
import org.apache.activemq.ActiveMQPrefetchPolicy;
import org.apache.activemq.RedeliveryPolicy;
import org.apache.activemq.command.ActiveMQQueue;
/**
* 这个启动器用于启动上行队列和下行队列的连接。
* 上行队列是一个独立的线程,下行队列也是一个独立的线程。
*
* 另外,上行队列和下行队列都可以使用同一个session
* @author yinwenjie
*/
public class ClientStartup implements Runnable {
/**
* 下行队列名称(可存放于配置文件中)
*/
private String downStream = "downStream";
/**
* 保证整个进程只有一个Producer被创建和使用
*/
private static MessageProducer PRODUCER;
/**
* 标示该启动器是否正常连接到消息中间件服务
*/
private static boolean ISSTARTED = false;
/**
* 这个静态方法用于从ClientStartup启动器中获取整个进程中唯一一个消息生产者。
* 注意,为了保证该进程其它线程安全获取ClientStartup.PRODUCER,
* 所以只有等待run()方法成功运行完成,该ClientStartup.PRODUCER才能被其它线程拿到。
* @return
*/
public static MessageProducer getNewInstanceProducer() {
synchronized (ClientStartup.class) {
while(!ClientStartup.ISSTARTED) {
try {
ClientStartup.class.wait();
} catch (InterruptedException e) {
e.printStackTrace(System.out);
}
}
}
return ClientStartup.PRODUCER;
}
@Override
public void run() {
// 开发包中对于消息中间件服务的连接一定要使用故障转移
ActiveMQConnectionFactory connectionFactory = new ActiveMQConnectionFactory("failover:(tcp://192.168.61.138:61616,tcp://192.168.61.139:61616)");
// 这是上行消息队列
ActiveMQQueue upstreamQueue = new ActiveMQQueue("upstream");
// 这是下行消息队列
// 下行消息队列必须由上级系统创建,并且在下级系统使用的开发包所对应的配置文件中进行配置
ActiveMQQueue downStreamQueue = new ActiveMQQueue(this.downStream);
//============开始创建
Connection connection = null;
Session session = null;
try {
//ack优化选项
connectionFactory.setOptimizeAcknowledge(true);
connectionFactory.setProducerWindowSize(2048000);
connectionFactory.setSendAcksAsync(true);
//ack信息最大发送周期
connectionFactory.setOptimizeAcknowledgeTimeOut(5000);
//连接属性优化:设置重试次数为2
RedeliveryPolicy redeliveryPolicy = connectionFactory.getRedeliveryPolicy();
redeliveryPolicy.setMaximumRedeliveries(2);
//连接属性优化:设置预取数量
ActiveMQPrefetchPolicy prefetchPolicy = connectionFactory.getPrefetchPolicy();
prefetchPolicy.setQueuePrefetch(20);
//设置获取消息的线程池大小
connectionFactory.setMaxThreadPoolSize(2);
connection = connectionFactory.createQueueConnection();
//连接
connection.start();
//建立会话(设置一个带有事务特性的会话)
session = connection.createSession(true, Session.AUTO_ACKNOWLEDGE);
} catch(Exception e) {
e.printStackTrace(System.out);
return;
}
//===========首先进行订阅消费者连接(下行消息队列的连接)
//注意,正式代码中不应该允许JMS Client创建一个新的队列
//所以应该使用其它方式(例如其他查询接口),在创建前判断队列是否已经存在
MessageConsumer consumer;
try {
consumer = session.createConsumer(downStreamQueue);
consumer.setMessageListener(new MessageListener() {
@Override
public void onMessage(Message message) {
/*
* 这里进行正式业务的处理
* */
}
});
} catch (JMSException e) {
e.printStackTrace(System.out);
// 一旦出错,就关闭整个连接,退出启动过程
try {
connection.close();
} catch (JMSException e1) {
e.printStackTrace(System.out);
}
return;
}
//==========然后创建消息生产者俩呢及(上行消息队列的连接)
try {
ClientStartup.PRODUCER = session.createProducer(upstreamQueue);
} catch (JMSException e) {
e.printStackTrace(System.out);
// 一旦出错,就关闭整个连接,退出启动过程
try {
connection.close();
} catch (JMSException e1) {
e.printStackTrace(System.out);
}
return;
}
//==========通知其他线程可以获取producer了
ClientStartup.ISSTARTED = true;
synchronized (ClientStartup.class) {
ClientStartup.class.notify();
}
//==========锁定该线程
synchronized (this) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace(System.out);
}
}
}
public static void main(String[] args) {
new Thread(new ClientStartup()).start();
}
}
3-5、其它说明
- 安全性考量:在正式环境中使用消息队列中间件服务一定要做相关的安全性设置。包括启用消息队列服务的用户名和密码、启用消息队列服务自带的SSL加密设置。如果您使用的消息队列服务不自带SSL加密,则一定要自己进行加密。幸运的是,如果您使用的是ActiveMQ,那么以上两种安全性要求都可以满足。甚至ActiveMQ还支持为每一个队列单独进行用户名和密码设置。
- 错误数据的处理:在正式环境中使用消息队列中间件服务一定要假设 会发生传输的消息由于各种业务原因导致的消费者处理错误的情况 。所以对超出redeliveryCounter重试次数的错误消息一定要转存到另外的“待处理区域”,并在后续进行人工干预。在ActiveMQ中这个“待处理区域”就是死消息队列:ActiveMQ.DLQ。
- 在产品预算内赋予消息服务中间件最大的可用性:类似于ActiveMQ、RabbitMQ这样的消息队列中间件,其目的 并不是一味地追求单位时间内消息数据的吞吐量/并发量的处理能力 。它们的功能中涵盖了诸多功能:事务机制、确认机制、重试机制、热备机制等等,都是为了一个更重要的功能目的: 保证消息完整可达 。所以您和您的团队一定要 按照业务特性 来确定是否适合使用这样的中间件服务,并且您需要在预算范围内为您的消息服务中间件配置多个服务节点、多个存储单元,以便保证消息队列中间件能够完成它的任务——消息完整可达。
下文我们一起讨论一下那些 专门解决高数据吞吐性能问题 的消息中间件产品以及它们的应用场景。
(接下文)
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
