5-2、protocol:RPC调用层
如果您直接看阿里提供的DUBBO框架的技术文档,您可以看到几个关键字和几张工作图。不过您肯定是无法通过那几张图搞清楚DUBBO框架的每一层是如何进行衔接,如何进行脱耦的。在这几篇文章中,我会主要从设计思路上,从DUBBO所采用的设计模式层面上,尽可能的向读者表达DUBBO框架的设计思路。
在DUBBO框架中,有一个自己的RPC协议,名字叫做dubbo(小写的)。不止如此,DUBBO框架的RPC层还支持多种RPC协议的使用( hessian、thrift、RMI),还支持webservice协议和纯http协议。那么DUBBO框架是如何确认“哪个接口使用哪一种协议”这个问题的呢?要说清楚这个问题,就需要从DUBBO框架RPC层的模块设计入手:
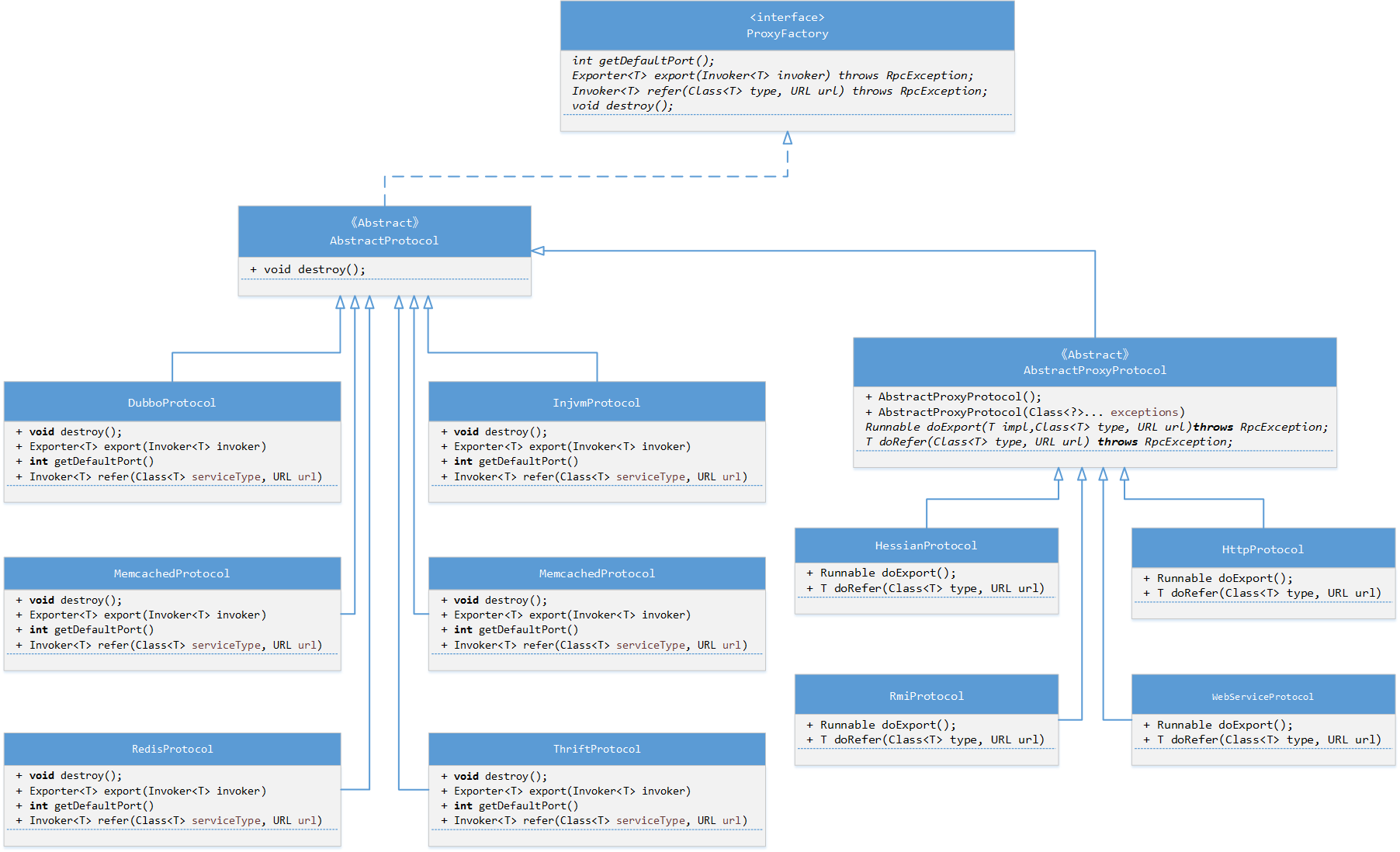
就像前文提到的那样:关键模块的实现类的实例化都是通过DUBBO框架中的SPI机制完成的。例如Proxy层中的具体代理、RPC层的具体协议等等。我会通过代码跟踪的方式,详细介绍DUBBO框架RPC层的实例化过程。(DUBBO框架中,SPI的具体实现在com.alibaba.dubbo.common.extension包中,最主要的实现类是ExtensionLoader)
当DUBBO框架启动时,ExtensionLoader会加载所有的扩展点设置(见com.alibaba.dubbo.common.extension.SPI注解符)。ExtensionLoader会通过loadExtensionClasses()私有方法找到“com.alibaba.dubbo.rpc.Protocol”接口所匹配的配置文件:
// 此方法已经getExtensionClasses方法同步过(这句注释不是我加的)。
private Map<String, Class<?>> loadExtensionClasses() {
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if(defaultAnnotation != null) {
String value = defaultAnnotation.value();
if(value != null && (value = value.trim()).length() > 0) {
String[] names = NAME_SEPARATOR.split(value);
if(names.length > 1) {
throw new IllegalStateException("more than 1 default extension name on extension " + type.getName() + ": " + Arrays.toString(names));
}
if(names.length == 1) cachedDefaultName = names[0];
}
}
Map<String, Class<?>> extensionClasses = new HashMap<String, Class<?>>();
// yinwenjie加的注释:加载接口类对应的配置文件
loadFile(extensionClasses, DUBBO_INTERNAL_DIRECTORY);
loadFile(extensionClasses, DUBBO_DIRECTORY);
loadFile(extensionClasses, SERVICES_DIRECTORY);
return extensionClasses;
}
然后通过“ExtensionLoader.createExtension(String name)”私有方法生成相应的实例。注意下图中外部传入的’name’变量,是我在< dubbo:protocol >标签中填写的name=”thrift”。以下是这部分源代码:
@SuppressWarnings("unchecked")
private T createExtension(String name) {
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
EXTENSION_INSTANCES.putIfAbsent(clazz, (T) clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
injectExtension(instance);
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (wrapperClasses != null && wrapperClasses.size() > 0) {
for (Class<?> wrapperClass : wrapperClasses) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
}
}
调用效果如下:
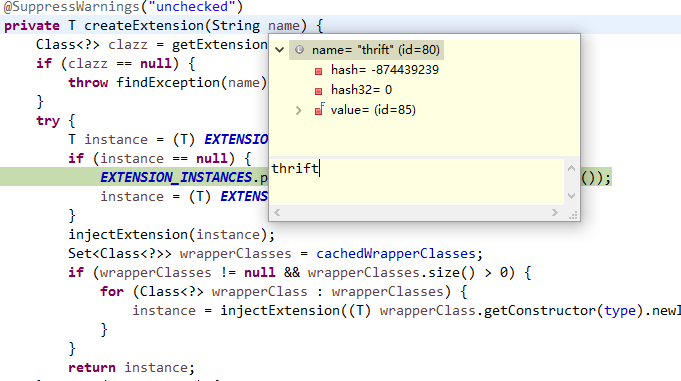
在DUBBO框架中,您通过config配置文件所配置的“具体实现”,基本上都是通过这种方式进行加载的。通过由SPI支持的生成方式,和各种protocol协议定义的实现,使得DUBBO框架具备了在RPC层支持多种协议的功能特性。
6、config:配置模块和配置层
config模块负责管理DUBBO框架中的所有配置信息,在DUBBO框架启动/工作中,为各个模块提供配置点信息。在这个小节中,我们不会分析config模块怎么使用的(如果您想了解DUBBO框架的配置规范,可以参考DUBBO框架的用户手册),这个小节我们主要对config模块的设计结构、启动方式进行分析:
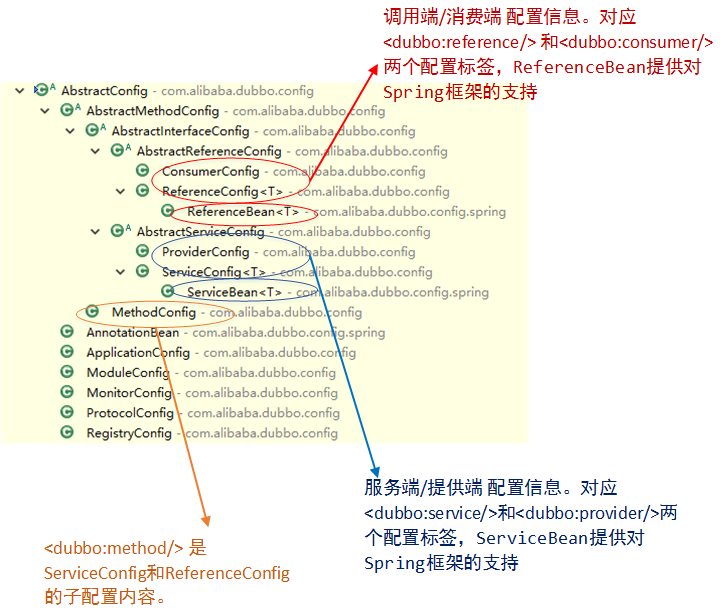
上图中,没有特别说明的ApplicationConfig、ModuleConfig、ProtocolConfig等类分别对应了
这些配置标签对应的config类中,AnnotationBean类、ReferenceBean类和ServiceBean类提供了配置标签和Spring框架的结合机制。接下来我们以ServiceBean为例,为大家讲解< dubbo:service >标签中的配置信息加载过程。
首先我们需要清楚的是:和< dubbo:service >标签相关的标签还包括了:< dubbo:provider/ >、< dubbo:application/ > 、< dubbo:module/ >、< dubbo:registry/ >、< dubbo:monitor/ >和
< dubbo:protocol/ >标签。这些辅助(依赖)标签在您定义< dubbo:service >的时候,有的是必须定义的有的是可以选择性定义的。
也就是说在进行< dubbo:service >标签初始化时,还需要对可能存在的以上这些辅助标签一起进行初始化。然后作为< dubbo:service >标签的关联信息,一同写入到spring容器中进行保存 。在ServiceConfig类及其父类AbstractServiceConfig、AbstractInterfaceConfig中,定义了这些关联属性,代码片段如下:
public abstract class AbstractInterfaceConfig extends AbstractMethodConfig {
.......
// 服务监控
protected MonitorConfig monitor;
// 代理类型
protected String proxy;
// 集群方式
protected String cluster;
// 应用信息
protected ApplicationConfig application;
// 模块信息
protected ModuleConfig module;
// 注册中心
protected List<RegistryConfig> registries;
// 允许的协议
protected List<ProtocolConfig> protocols;
.......
}
当Spring框架的配置文件被加载完成时,ServiceBean所实现的接口定义InitializingBean中的方法afterPropertiesSet()会被激活运行。以下是代码片段:
// 试图寻找<dubbo:provider/>标签的定义
if (getProvider() == null) {
Map<String, ProviderConfig> providerConfigMap = applicationContext == null ? null : BeanFactoryUtils.beansOfTypeIncludingAncestors(applicationContext, ProviderConfig.class, false, false);
if (providerConfigMap != null && providerConfigMap.size() > 0) {
Map<String, ProtocolConfig> protocolConfigMap = applicationContext == null ? null : BeanFactoryUtils.beansOfTypeIncludingAncestors(applicationContext, ProtocolConfig.class, false, false);
// .......(省略了一些处理代码)
// 如果处理成功则作为ServiceBean的属性进行关联
if (providerConfig != null) {
setProvider(providerConfig);
}
}
}
//试图寻找<dubbo:application/>标签的定义
if (getApplication() == null
&& (getProvider() == null || getProvider().getApplication() == null)) {
Map<String, ApplicationConfig> applicationConfigMap = applicationContext == null ? null : BeanFactoryUtils.beansOfTypeIncludingAncestors(applicationContext, ApplicationConfig.class, false, false);
// .......(省略了一些处理代码)
// 如果处理成功则作为serviceBean的属性进行关联
if (applicationConfig != null) {
setApplication(applicationConfig);
}
}
// ..... 接着处理其它可能存在标签
在DUBBO框架中,最重要的两个标签是< dubbo:service/ >标签和< dubbo:reference/ >标签。这两个标签都是和Spring框架进行了依赖的,通过对< dubbo:service/ >标签的初始化过程也可以知道< dubbo:reference/ >标签的初始化过程了。
7、registry:注册中心模块
首先要说明的是,DUBBO框架的注册中心模块是用来统筹DUBBO服务端(服务提供者)和客户端(服务消费者)的各种状态、事件。以便DUBBO框架的各端能够知晓当前整个分布式环境的全局,新的服务能够注册进来,并且可以被消费端发现;
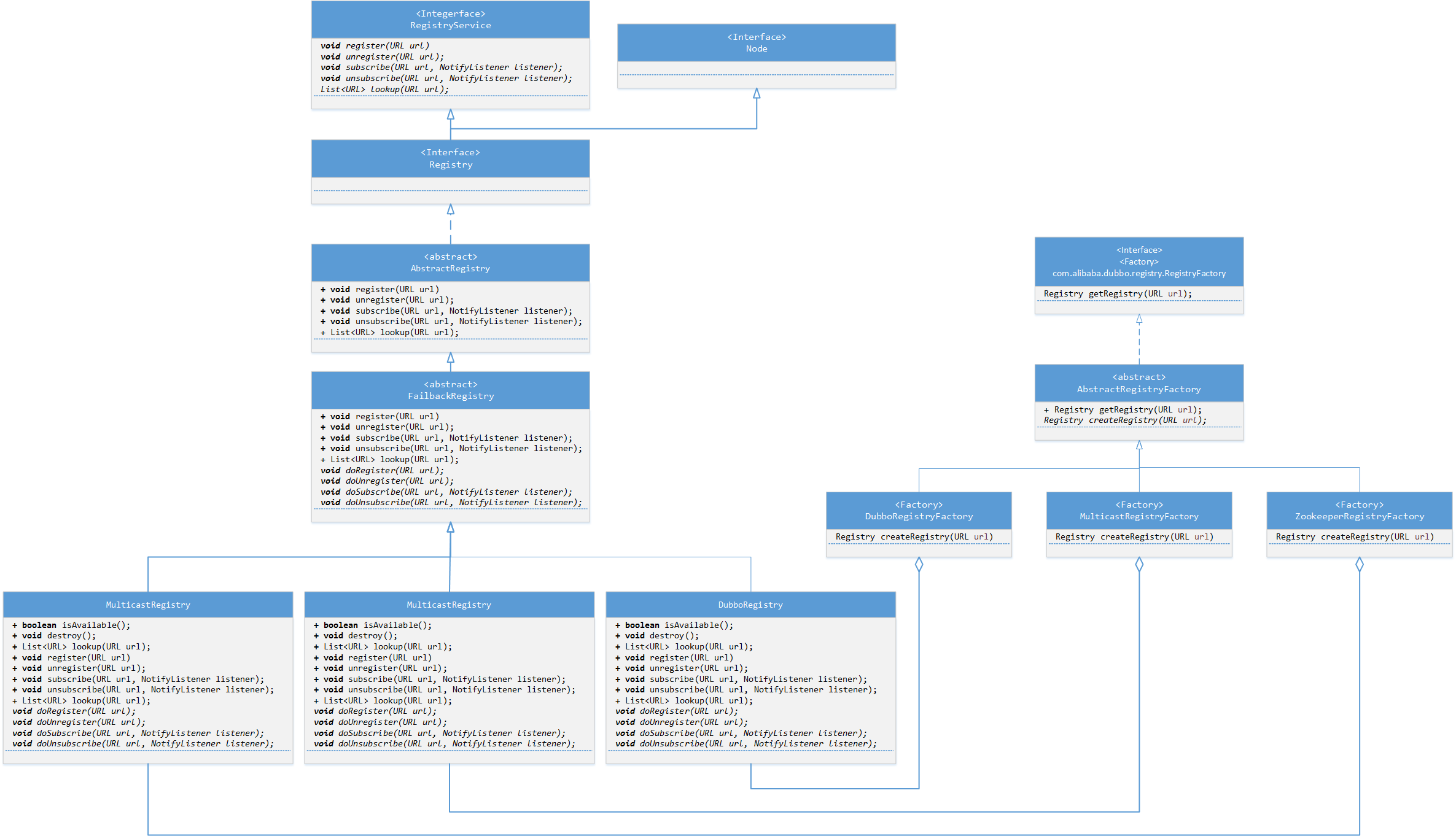
DUBBO框架的注册中心有多种实现,既有大家熟悉的Zookeeper实现,还有Multicast网络广播的实现、Redis缓存服务的实现和本地实现,下图是Registry模块的主要类图——您会发现是一个典型的工厂方法模式(原图比较大,被缩小了。请点击新的页签进行查看)。
7-1、DUBBO内部的URL
在介绍DUBBO中Registry工作过程之前,首先需要介绍DUBBO框架中“com.alibaba.dubbo.common.URL”这个类。在DUBBO框架中,各模块(各层)间传递消息的主要描述方式,是通过DUBBO框架中的这个类完成的。下面是这个类的主要代码片段:
public final class URL implements Serializable {
private static final long serialVersionUID = -1985165475234910535L;
private final String protocol;
private final String username;
private final String password;
private final String host;
private final int port;
private final String path;
private final Map<String, String> parameters;
// ==== cache ====
/*
* yinwenjie加的注释:
* 请注意这部分代码。其中带有volatile关键字。
* 意味着当多线程环境下每个线程拿到的都是这些属性的最新值。
*
* 另外,这些属性都还带有transient关键字。
* 意味着当URL对象被序列化时,这些属性不会被序列化
*/
private volatile transient Map<String, Number> numbers;
private volatile transient Map<String, URL> urls;
private volatile transient String ip;
private volatile transient String full;
private volatile transient String identity;
private volatile transient String parameter;
private volatile transient String string;
protected URL() {
this.protocol = null;
this.username = null;
this.password = null;
this.host = null;
this.port = 0;
this.path = null;
this.parameters = null;
}
public URL(String protocol, String host, int port) {
this(protocol, null, null, host, port, null, (Map<String, String>) null);
}
public URL(String protocol, String host, int port, String[] pairs) {
// 变长参数...与下面的path参数冲突,改为数组
this(protocol, null, null, host, port, null, CollectionUtils.toStringMap(pairs));
}
public URL(String protocol, String host, int port, Map<String, String> parameters) {
this(protocol, null, null, host, port, null, parameters);
}
//.........(省略了一部分构造函数)
public URL(String protocol, String username, String password, String host, int port, String path, Map<String, String> parameters) {
if ((username == null || username.length() == 0)
&& password != null && password.length() > 0) {
throw new IllegalArgumentException("Invalid url, password without username!");
}
this.protocol = protocol;
this.username = username;
this.password = password;
this.host = host;
this.port = (port < 0 ? 0 : port);
this.path = path;
// trim the beginning "/"
while(path != null && path.startsWith("/")) {
path = path.substring(1);
}
if (parameters == null) {
parameters = new HashMap<String, String>();
} else {
parameters = new HashMap<String, String>(parameters);
}
this.parameters = Collections.unmodifiableMap(parameters);
}
// ........还有很多代码
}
那么DUBBO框架中的URL信息是怎么描述的呢?我们举几个实际的例子进行说明:
zookeeper://10.5.1.246:2181/com.alibaba.dubbo.registry.RegistryService?application=ws-demo&dubbo=2.4.10&interface=com.alibaba.dubbo.registry.RegistryService&pid=1144×tamp=1451030327372
dubbo://10.5.1.121:20880/yinwenjie.test.dubboService.iface.MyService?anyhost=true&application=ws-demo&dubbo=2.4.10&interface=yinwenjie.test.dubboService.iface.MyService&methods=doMyTest&pid=1144&side=provider×tamp=1451030346703
实例中的第一个URL描述了DUBBO框架注册中心层的协议描述。表示注册层使用的协议是zookeeper,访问地址为10.5.1.246,访问端口为2181。访问路径为com.alibaba.dubbo.registry.RegistryService。剩下的是参数信息,存储在URL类中的parameters属性。
实例中的第二个URL描述,是DUBBO框架Protocol层的协议描述。表示Protocol层使用的具体协议是“dubbo”(这个是DUBBO框架中自带的一种RPC协议);访问地址为:10.5.1.121(我的主机提供的一个可访问IP);访问端口为20880;访问路径为yinwenjie.test.dubboService.iface.MyService。剩下的参数信息,存储在URL类中的parameters属性。其中比较重要的参数包括了RPC协议的版本号,timestamp时间戳、methods接口方法信息等。
虽然我查询了尽可能多的DUBBO框架开发的公开文档,但是我并没有找到DUBBO框架的作者对“为什么会采用这种信息描述形式”的原因说明。可能DUBBO的作者们并没有进行这部分的文档编辑(可能性较低),也有可能DUBBO的作者们将这部分描述作为了内部文档,并没有开放;但是根据我肤浅的理解,作者应该有出于这样的考虑:
我们观察分布式系统的工作环境就可以发现, DUBBO框架中的每一个服务生产者/服务消费者节点的版本很有可能是不一样的 。如果不同版本中同样的协议描述存在差异(这种差异可能和微小,就是增加或者减少了一个属性),就会导致DUBBO框架中协议信息描述对象的修改。但如果采用URL格式进行描述就不会出现这样的问题,特别是将URL的属性放入到Map中;另外采用URL形式进行协议描述也增加了DUBBO框架开发调试阶段的信息可读性。
7-2、Registry工作过程
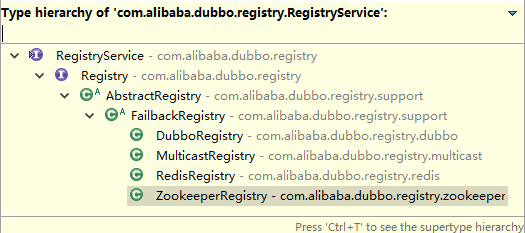
接下来,我们看看Registry注册中心的一个具体实现ZookeeperRegistry的工作过程。首先我们看看Registry注册中心最顶层的接口RegistryService有一些什么样的定义(这个接口是注册服务层的基本接口):
package com.alibaba.dubbo.registry;
import java.util.List;
import com.alibaba.dubbo.common.URL;
/**
* RegistryService. (SPI, Prototype, ThreadSafe)
*
* @see com.alibaba.dubbo.registry.Registry
* @see com.alibaba.dubbo.registry.RegistryFactory#getRegistry(URL)
* @author william.liangf
*/
public interface RegistryService {
/**
* 注册数据,比如:提供者地址,消费者地址,路由规则,覆盖规则,等数据。
*
* 注册需处理契约:<br>
* 1. 当URL设置了check=false时,注册失败后不报错,在后台定时重试,否则抛出异常。<br>
* 2. 当URL设置了dynamic=false参数,则需持久存储,否则,当注册者出现断电等情况异常退出时,需自动删除。<br>
* 3. 当URL设置了category=routers时,表示分类存储,缺省类别为providers,可按分类部分通知数据。<br>
* 4. 当注册中心重启,网络抖动,不能丢失数据,包括断线自动删除数据。<br>
* 5. 允许URI相同但参数不同的URL并存,不能覆盖。<br>
*
* @param url 注册信息,不允许为空,如:dubbo://10.20.153.10/com.alibaba.foo.BarService?version=1.0.0&application=kylin
*/
void register(URL url);
/**
* 取消注册.
*
* 取消注册需处理契约:<br>
* 1. 如果是dynamic=false的持久存储数据,找不到注册数据,则抛IllegalStateException,否则忽略。<br>
* 2. 按全URL匹配取消注册。<br>
*
* @param url 注册信息,不允许为空,如:dubbo://10.20.153.10/com.alibaba.foo.BarService?version=1.0.0&application=kylin
*/
void unregister(URL url);
/**
* 订阅符合条件的已注册数据,当有注册数据变更时自动推送.
*
* 订阅需处理契约:<br>
* 1. 当URL设置了check=false时,订阅失败后不报错,在后台定时重试。<br>
* 2. 当URL设置了category=routers,只通知指定分类的数据,多个分类用逗号分隔,并允许星号通配,表示订阅所有分类数据。<br>
* 3. 允许以interface,group,version,classifier作为条件查询,如:interface=com.alibaba.foo.BarService&version=1.0.0<br>
* 4. 并且查询条件允许星号通配,订阅所有接口的所有分组的所有版本,或:interface=*&group=*&version=*&classifier=*<br>
* 5. 当注册中心重启,网络抖动,需自动恢复订阅请求。<br>
* 6. 允许URI相同但参数不同的URL并存,不能覆盖。<br>
* 7. 必须阻塞订阅过程,等第一次通知完后再返回。<br>
*
* @param url 订阅条件,不允许为空,如:consumer://10.20.153.10/com.alibaba.foo.BarService?version=1.0.0&application=kylin
* @param listener 变更事件监听器,不允许为空
*/
void subscribe(URL url, NotifyListener listener);
/**
* 取消订阅.
*
* 取消订阅需处理契约:<br>
* 1. 如果没有订阅,直接忽略。<br>
* 2. 按全URL匹配取消订阅。<br>
*
* @param url 订阅条件,不允许为空,如:consumer://10.20.153.10/com.alibaba.foo.BarService?version=1.0.0&application=kylin
* @param listener 变更事件监听器,不允许为空
*/
void unsubscribe(URL url, NotifyListener listener);
/**
* 查询符合条件的已注册数据,与订阅的推模式相对应,这里为拉模式,只返回一次结果。
*
* @see com.alibaba.dubbo.registry.NotifyListener#notify(List)
* @param url 查询条件,不允许为空,如:consumer://10.20.153.10/com.alibaba.foo.BarService?version=1.0.0&application=kylin
* @return 已注册信息列表,可能为空,含义同{@link com.alibaba.dubbo.registry.NotifyListener#notify(List<URL>)}的参数。
*/
List<URL> lookup(URL url);
}
从上面给出的类结构图来看,无论您使用的是Redis作为注册中心的媒介,还是使用Zookeeper作为注册中心的媒介,还是DUBBO框架所支持的任意一种注册中心媒介,他们都实现了RegistryService接口。也就是说,这些注册中心至少有四个基本功能。注册、取消注册、订阅、取消订阅。
那么针对Zookeeper的实现,这些功能是怎么实现的呢?请看以下部分AbstractRegistry类的代码:
public abstract class AbstractRegistry implements Registry {
// 。。。。。 省略了部分代码
// 存放已被注册的URL信息
private final Set<URL> registered = new ConcurrentHashSet<URL>();
// 存放已被订阅的监听映射信息,从subscribed的接口来看,一个URL可以有多个订阅的监听
private final ConcurrentMap<URL, Set<NotifyListener>> subscribed = new ConcurrentHashMap<URL, Set<NotifyListener>>();
// 存放在某个事件中,已完成事件通知的订阅信息
private final ConcurrentMap<URL, Map<String, List<URL>>> notified = new ConcurrentHashMap<URL, Map<String, List<URL>>>();
// ........ 又省略很多代码。重点来看那四个方法的实现:
// 实现register方法
public void register(URL url) {
........
registered.add(url);
}
// 实现unregister方法
public void unregister(URL url) {
........
registered.remove(url);
}
// 实现subscribe方法
public void subscribe(URL url, NotifyListener listener) {
Set<NotifyListener> listeners = subscribed.get(url);
if (listeners == null) {
subscribed.putIfAbsent(url, new ConcurrentHashSet<NotifyListener>());
listeners = subscribed.get(url);
}
listeners.add(listener);
}
// 实现unsubscribe方法
public void unsubscribe(URL url, NotifyListener listener) {
Set<NotifyListener> listeners = subscribed.get(url);
if (listeners != null) {
listeners.remove(listener);
}
}
}
上面的代码很简单,就是将调用者给定的URL信息和监听信息,按照既定的本地存储格式进行存入。代码到这里,注册过程离完成还早着呢!首先考虑一个问题,根据特定的某种注册中心实现介质,是不是还有一些特有的注册动作要执行呢?答案肯定是的。
例如这里基于zookeeper的注册中心实现,肯定 还需要通知远程连接的zookeeper,将注册URL信息或者监听信息进行存入;如果操作出现错误,还要将之前已经写入结构的注册URL信息或者监听信息进行删除或者记录没有成功的操作(以便随后自动重试) 。
这个过程不是由AbstractRegistry类完成的,而是由其子类FailbackRegistry、ZookeeperRegistry类完成的;我们先来看看FailbackRegistry这个类中的关键:
public abstract class FailbackRegistry extends AbstractRegistry {
// 。。。。。。yinwenjie的注释:省略了很多代码
public void register(URL url) {
// 执行AbstractRegistry中的register方法
super.register(url);
// 清除可能存在的URL错误记录
failedRegistered.remove(url);
failedUnregistered.remove(url);
try {
// 向服务器端发送注册请求(等一下见ZookeeperRegistry的错误方法)
doRegister(url);
} catch (Exception e) {
Throwable t = e;
// 如果开启了启动时检测,则直接抛出异常
boolean check = getUrl().getParameter(Constants.CHECK_KEY, true)
&& url.getParameter(Constants.CHECK_KEY, true)
&& ! Constants.CONSUMER_PROTOCOL.equals(url.getProtocol());
boolean skipFailback = t instanceof SkipFailbackWrapperException;
if (check || skipFailback) {
if(skipFailback) {
t = t.getCause();
}
// 抛出异常
throw new IllegalStateException("Failed to register " + url + " to registry " + getUrl().getAddress() + ", cause: " + t.getMessage(), t);
} else {
// 因为后续要重试,所以只需要显示错误日志。不用抛出异常
logger.error("Failed to register " + url + ", waiting for retry, cause: " + t.getMessage(), t);
}
// 将失败的注册请求记录到失败列表,定时重试
failedRegistered.add(url);
}
}
//。。。。。。。又忽略了很多代码
// ==== 模板方法,FailbackRegistry子类必须实现这些方法 ====
protected abstract void doRegister(URL url);
protected abstract void doUnregister(URL url);
protected abstract void doSubscribe(URL url, NotifyListener listener);
protected abstract void doUnsubscribe(URL url, NotifyListener listener);
}
很明显FailbackRegistry并不是用来进行zookeeper相关注册或者监听映射过程的,而是 起到一个承上启下的作用,隔离处理过程中的公共过程和特有过程 。这是一个很好的处理思路,各位读者阅读别人的代码就是为了学习这些处理思路。
那么我们再来看ZookeeperRegistry中,针对zookeeper的特定处理过程(这个就简单了,按照已经确定的zookeeper目录结构,进行写操作即可):
public class ZookeeperRegistry extends FailbackRegistry {
// 。。。。。省略了很多代码
// com.alibaba.dubbo.remoting.zookeeper.ZookeeperClient接口
// 在DUBBO框架中,这个接口一共有两个实现
private final ZookeeperClient zkClient;
// 。。。。。又省略了很多代码
protected void doRegister(URL url) {
try {
// 这里进行zookeeper相关的特有操作
zkClient.create(toUrlPath(url), url.getParameter(Constants.DYNAMIC_KEY, true));
} catch (Throwable e) {
throw new RpcException("Failed to register " + url + " to zookeeper " + getUrl() + ", cause: " + e.getMessage(), e);
}
}
// 。。。。。省略了很多代码
}
8、下文介绍
好吧,我承认从介绍DUBBO框架开始的几篇文章,我引用了开源软件中大量的代码片段。这些代码片段主要还是为读者介绍设计思路和开源软件作者的coding技巧。各位读者一定要有耐心,静心阅读这些代码和我的注释说明(这是一种重要的修禅方式)。
另外,在书写这两篇DUBBO框架的代码分析文章中,我发现文章内容越来越偏离我这个专栏的中心思想。所以在完成DUBBO框架Registry的代码分析后,我决定暂停这部分的写作(后面的专栏中,我还会抽时间将分析继续)以便让文章回归专栏的中心思想。再说,我也不希望在RPC和服务治理的知识体系上耽误太多的时间。
从下一篇文章开始,我将进入这个专栏下一部分的写作,也就是系统间通讯的另一个知识体系ESB技术。严格来说,RPC与服务治理 和 ESB企业服务总线他们都是SOA思想的一个实现,但是两个知识体系的使用环境、工作原理都是不一样的(当然承载他们的基础知识都已一样的,所以学好基础非常重要)。敬请各位读者期待后续的专题文章。
最后感谢各位读者对我的关注,上一篇专题文章《架构设计:系统间通信(17)——服务治理与Dubbo 中篇(分析)》居然在10天时间内突破了1万的阅读量,网络上的转发数量更是不计其数。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
