关于跳跃表其实在 JUC 里面有一个并发容器就是利用跳跃表来实现的:ConcurrentSkipListMap(【死磕Java并发】—–J.U.C之Java并发容器:ConcurrentSkipListMap)。这篇博客我们来分析 Redis 里面的跳跃表。
skiplist
什么是跳跃表?
百度百科是这么定义的:跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。从这里我们我们了解到,跳跃表是一种有序的数据结构,通过在节点上面增加索引(指针)从而达到快速检索的目的。
跳跃表有着不低于红黑树、AVL 数的效率,但是其原理和实现的复杂度要比他们简单多了。他的特性如下:
- 由很多层结构组成,level是通过一定的概率随机产生的
- 每一层都是一个有序的链表,默认是升序,也可以根据创建映射时所提供的Comparator进行排序,具体取决于使用的构造方法
- 最底层(Level 1)的链表包含所有元素
- 如果一个元素出现在Level i 的链表中,则它在Level i 之下的链表也都会出现
- 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素
其结构如下:
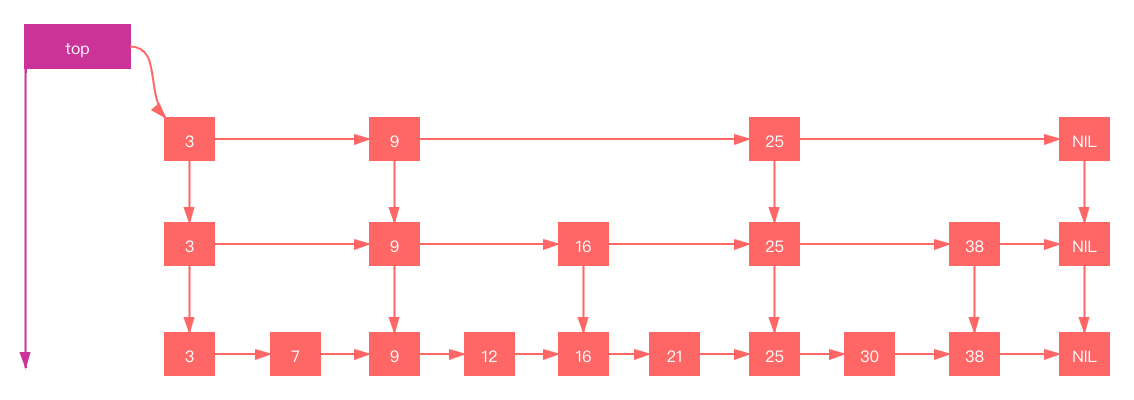
skiplist的查找
SkipListd的查找算法较为简单,对于上面我们我们要查找元素21,其过程如下:
- 比较3,大于,往后找(9),
- 比9大,继续往后找(25),但是比25小,则从9的下一层开始找(16)
- 16的后面节点依然为25,则继续从16的下一层找
- 找到21
如图(绿线所示)
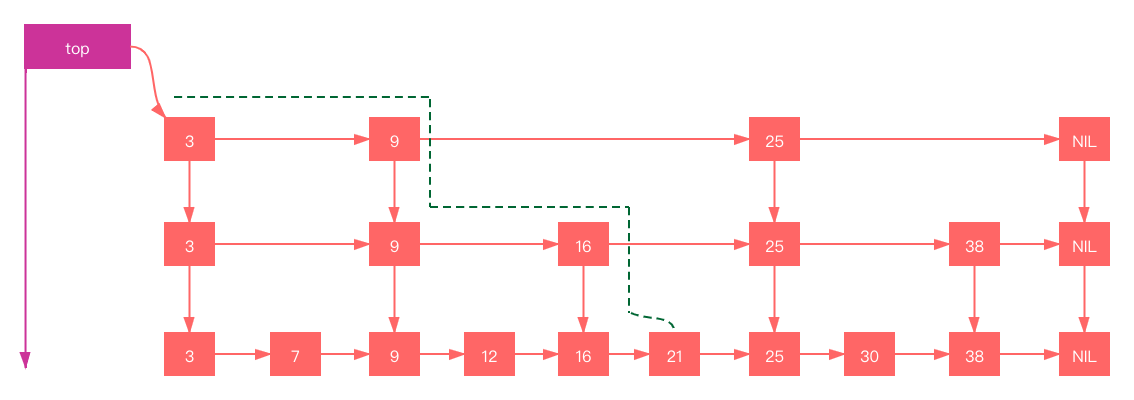
skiplist的增加
SkipList的插入操作主要包括:
- 查找合适的位置。这里需要明确一点就是在确认新节点要占据的层次K时,采用丢硬币的方式,完全随机。如果占据的层次K大于链表的层次,则重新申请新的层,否则插入指定层次
- 申请新的节点
- 调整指针
假定我们要插入的元素为23,经过查找可以确认她是位于25后,9、16、21前。当然需要考虑申请的层次K。 如果层次K > 3 需要申请新层次(Level 4)
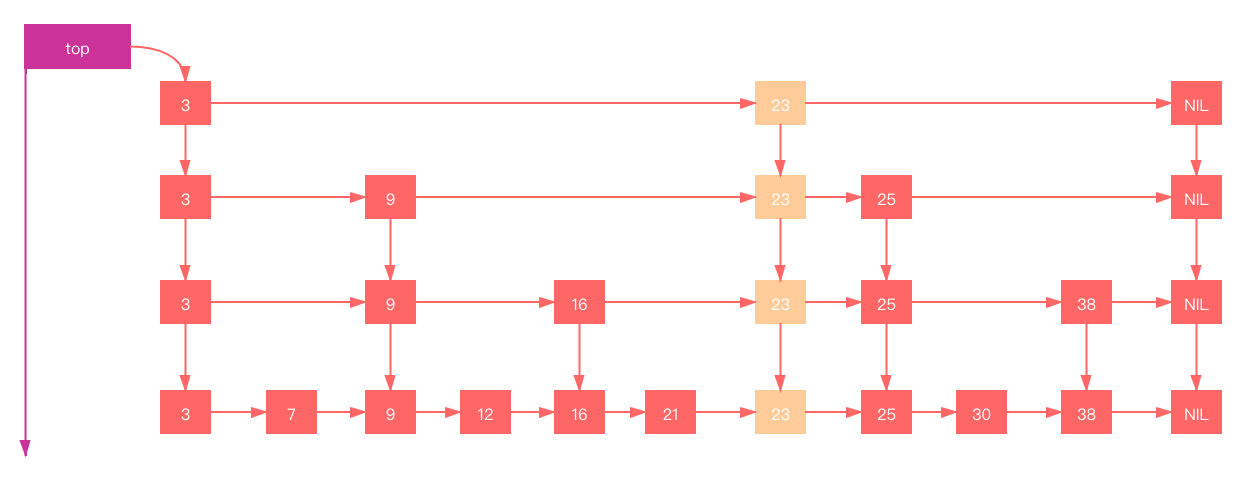
如果层次 K = 2 直接在Level 2 层插入即可。
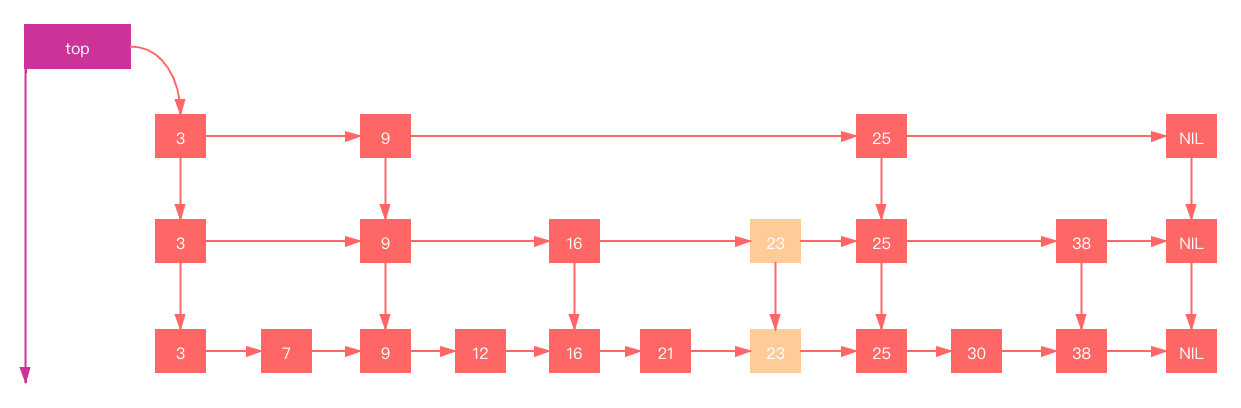
skiplist的删除
删除节点和插入节点思路基本一致:找到节点,删除节点,调整指针。 比如删除节点9,如下:
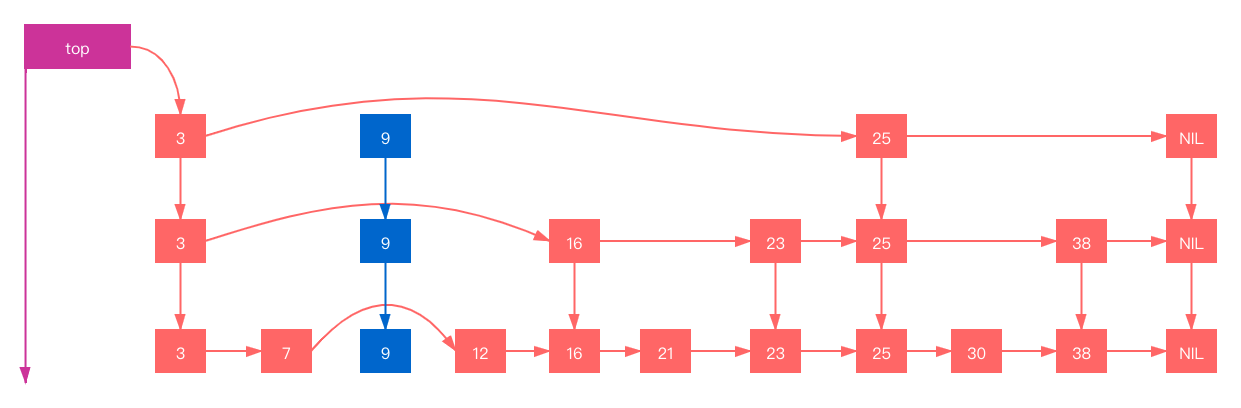
Redis 中的 skiplist
Redis 使用跳跃表作为 sorted set 的底层实现之一,为了支持 sorted set 本身的一些要求,在经典的 skiplist 基础上,Redis 里面的相应实现做了若干改动。
Redis 中的 skiplist 由 zskiplistNode 和 zskiplist 两个结构定义,其中 zskiplistNode 结构用于表示跳跃表节点,而 zskiplist 结构则用于保存跳跃表节点的相关信息。
zskiplistNode
zskiplistNode结构定义如下:
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针,用于指向上一个节点
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
//前进指针指向下一个节点
struct zskiplistNode *forward;
//到达后一个节点的跨度(两个相邻节点span为1)
unsigned int span;
} level[];//该节点在各层的信息,柔性数组成员
} zskiplistNode;
skiplist 节点的 level 数组可以包含多个元素,每一个元素都包含一个指向其他节点的指针,程序可以通过这些层来加快访问其他节点的速度。我们每次创建一个新的是 skiplist 节点的时候,都会生成一个介于 1 到 32 之间的值来作为 level 数组的大小,这个大小就是 skiplist 的 ”高度“。下图表示带有不同层高的节点:
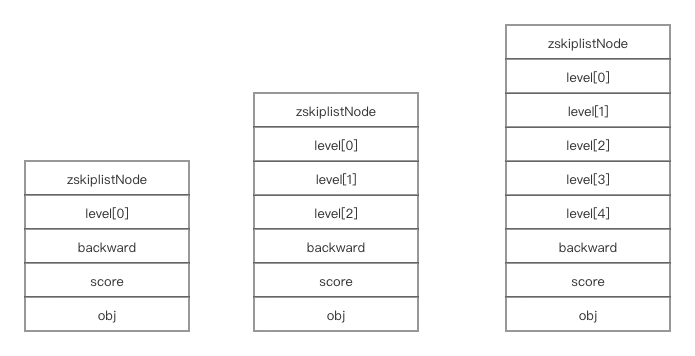
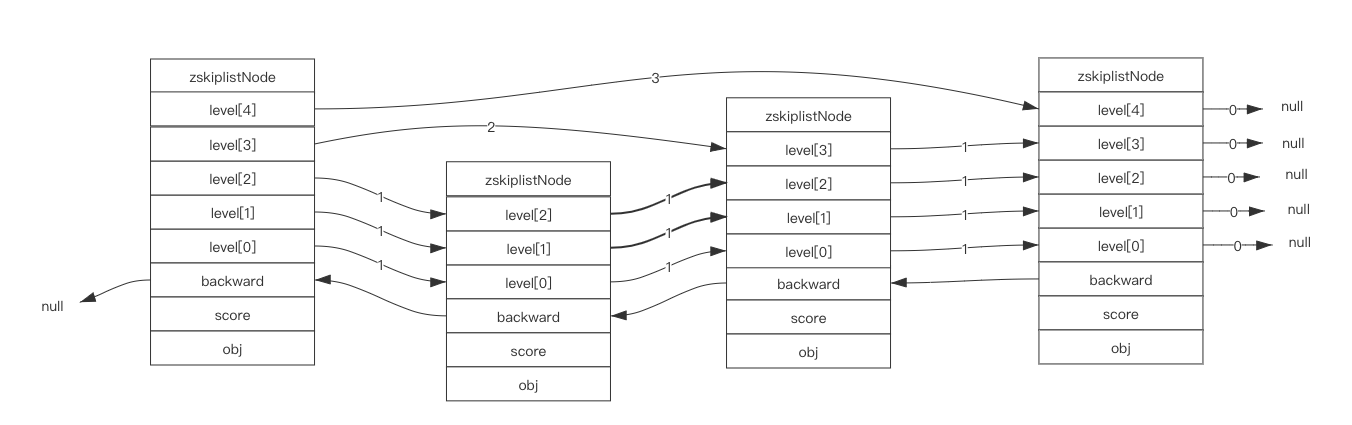
leve[x].forward 表示该 x + 1 层 的下一个节点。跳跃表节点都会出现在最底层的链表里,所以所有节点都会拥有 level[0],通过 level[0].forward 可以实现跳跃表的正向遍历。
level[x].span 表示该节点到第 x + 1 的下一个节点跳跃了多少个节点。该值越大,说明他们相距越远。指向 NULL 的所有前进指针的跨度都为 0 ,因为他们没有指向任何节点。
score,表示节点的分值,是一个 double 类型的浮点数,跳跃表中的所有节点都按分值从小到大排序。
obj,一个成员指针,他指向一个字符串对象,而字符串对象则保存着一个 SDS。
zskiplist
typedef struct zskiplist {
// 跳跃表头尾节点
struct zskiplistNode *header, *tail;
// 节点个数
unsigned long length;
// 除头结点外最大的层数
int level;
} zskiplist;
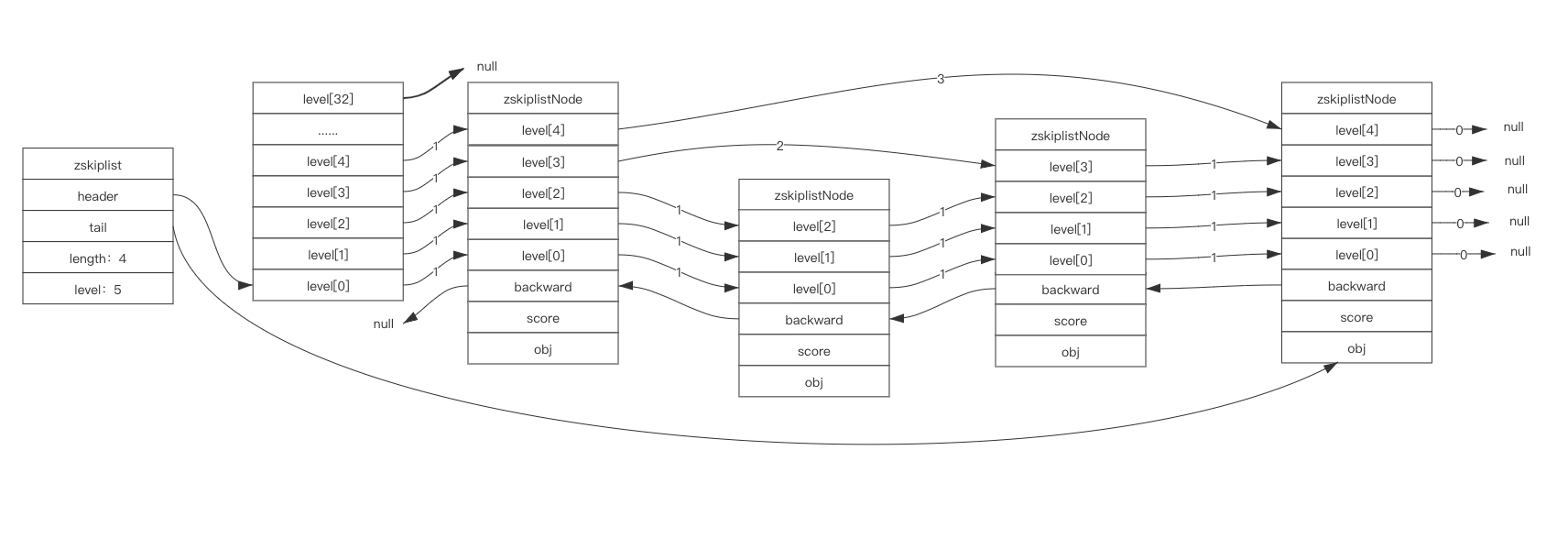
header 、tail 分别表示指向跳跃表的表头和表尾;length 属性用来记录跳跃表节点的数量;level 属性用来表示除头节点外的最大层数。
下图是一个完整的 skiplist。
关于 skiplist 的 API 就不多介绍了,有兴趣的同学可以自己去翻源代码。
为什么不用红黑树作为zset底层实现?
对于这个问题,Redis的作者 @antirez 已经说明了:
There are a few reasons:
-
They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
-
A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
-
They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
重点是这句话:They are not very memory intensive. It's up to you basically. 既然取决于自己,skiplist 实现简单就选它了。至于可能的好处和坏处大概整理了一下有这些:
- 缺点:
- 比红黑树占用更多的内存,每个节点的大小取决于该节点的层数
- 空间局部性较差导致缓存命中率低,感觉上会比红黑树更慢
- 优点:
- 实现比红黑树简单
- 比红黑树更容易扩展,作者之后实现 zrank 指令时没怎么改动代码。
- 红黑树插入删除时为了平衡高度需要旋转附近节点,高并发时需要锁。skiplist 不需要考虑。
- 一般用 zset的 操作都是执行 zrange 之类的操作,取出一片连续的节点。这些操作的缓存命中率不会比红黑树低。
参考
- 《Redis 设计与实现》
- Redis内部数据结构详解(6)——skiplist
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
