前面一章主要学习了文件系统的存储和分配方式的理论知识,本章接着理论知识,如何设计一个文件系统(本章不涉及任何代码实现),其主要的内容包括如下:
- 如何一步步设计一个文件系统,了解文件系统由那些组成
- 当我们读写文件时底层的工作原理是什么,从组成到实现原理
1. 文件系统的组成部分
对于文件系统我们只需要支持两种最基本的操作:读和写,就可以解决长期的存储问题。不过,这里存在很多不便于实现的操作,特别是有很多程序或者多用户使用着的大型系统上,很容易产生一些问题,例如:
- 如何找到对应的信息?
- 如何防止一个用户读取/写入另外一个用户的数据?
- 如何直到哪些块是空闲的?
对于用户关心的是文件是怎么命名的,可以进行哪些操作,目录树是怎么样的以及类似的表面问题,而实现者感兴趣的是文件和目录是怎么存储的,磁盘空间是怎么管理的以及怎么是系统有效而可靠地工作等。
1.1 data Block(数据区块)的出现
硬盘最底层的读写IO一次是一个扇区512字节,如果要读写大量文件,以扇区为单位肯定很慢很消耗性能,所以硬盘使用了一个称作逻辑块的概念。逻辑块是逻辑的,由磁盘驱动器负责维护和操作,它并非是像扇区一样物理划分的。一个逻辑块的大小可能包含一个或多个扇区,每个逻辑块都有唯一的地址,称为LBA。有了逻辑块之后,磁盘控制器对数据的操作就以逻辑块为单位,一次读写一个逻辑块,磁盘控制器知道如何将逻辑块翻译成对应的扇区并读写数据。
到了linux操作系统层面,通过文件系统提供了一个也称为块的读写单元,文件系统的数据块大小一般为4K,文件系统数据块也是逻辑概念,是文件系统层次维护的,而磁盘上的逻辑数据块是由磁盘控制器维护的,文件系统的IO管理器知道如何将它的数据块翻译成磁盘维护的数据块地址LBA。
- 对于使用文件系统的IO操作来说,比如读写文件,这些IO的基本单元是文件系统上的数据块,一次读写一个文件系统数据块。
- 比如需要读一个或多个块时,文件系统的IO管理器首先计算这些文件系统块对应在哪些磁盘数据块,也就是计算出LBA,然后通知磁盘控制器要读取哪些块的数据,硬盘控制器将这些块翻译成扇区地址,然后从扇区中读取数据,再通过硬盘控制器将这些扇区数据重组写入到内存中去。
文件系统block的出现使得在文件系统层面上读写性能大大提高,也大量减少了碎片。但是它的副作用是可能造成空间浪费。由于文件系统以block为读写单元,即使存储的文件只有1K大小也将占用一个block,剩余的空间完全是浪费的。在某些业务需求下可能大量存储小文件,这会浪费大量的空间。
1.2 inode的出现
上面我们用到了block,假设block的大小为1KB,仅仅存储一个10MB的文件就需要10240个block,而且这些block很可能在位置上是不连续的,读取该文件就难道就需要从前往后扫描整个文件系统的块,然后找出属于该文件的块吗?
显然,这种方式太慢太傻瓜了,现在这种情况,存在什么问题呢?
- 当我们创建一个文件,我们怎么才能找到刚刚创建的文件呢?根据块号么?用户程序不关心,就像我们去书店,如果叫你提供书的编号,而不是书名一样,显然是不合理的。因此我们给每个文件起一个名字,通过名字来寻找,那么就要有一个地方,记录文件名与块号的对应关系
- 如果我们要读取一个只占用1个block的文件,难道我们只需要读取一个block吗?目前的情况,我们不知道什么时候扫描到,扫描到了也不直到这个文件是不是已经完整了不需要扫描其他的block。
- 每个文件都有属性(如权限,大小,访问时间戳等),这些属性类的元数据存储在哪里呢?难道也要和文件的数据部分存储在块中吗?
- 如果一个文件占用多个block,那是不是每个属于该文件的block都需要存储一份文件元数据,很显然,每个数据block中都存储一份元数据太浪费空间了
- 如果不在每个block中存储元数据文件系统,又怎么直到某个Block是不是属于该文件呢?
对于文件系统的设计者的解决方法是使用索引,通过扫描索引找到对应的数据,而且索引可以存储部分数据。
在文件系统上索引技术具体化为索引节点(index node),在索引节点上存储的部分数据即为文件的属性元数据及其他少量信息。一般来说索引占用的空间相比其索引的文件数据而言占用的空间就小得多,扫描它比扫描整个数据要快得多,否则索引就没有存在的意义。这样一来就解决了前面所有的问题。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。inode包括文件的元信息,内容如下:
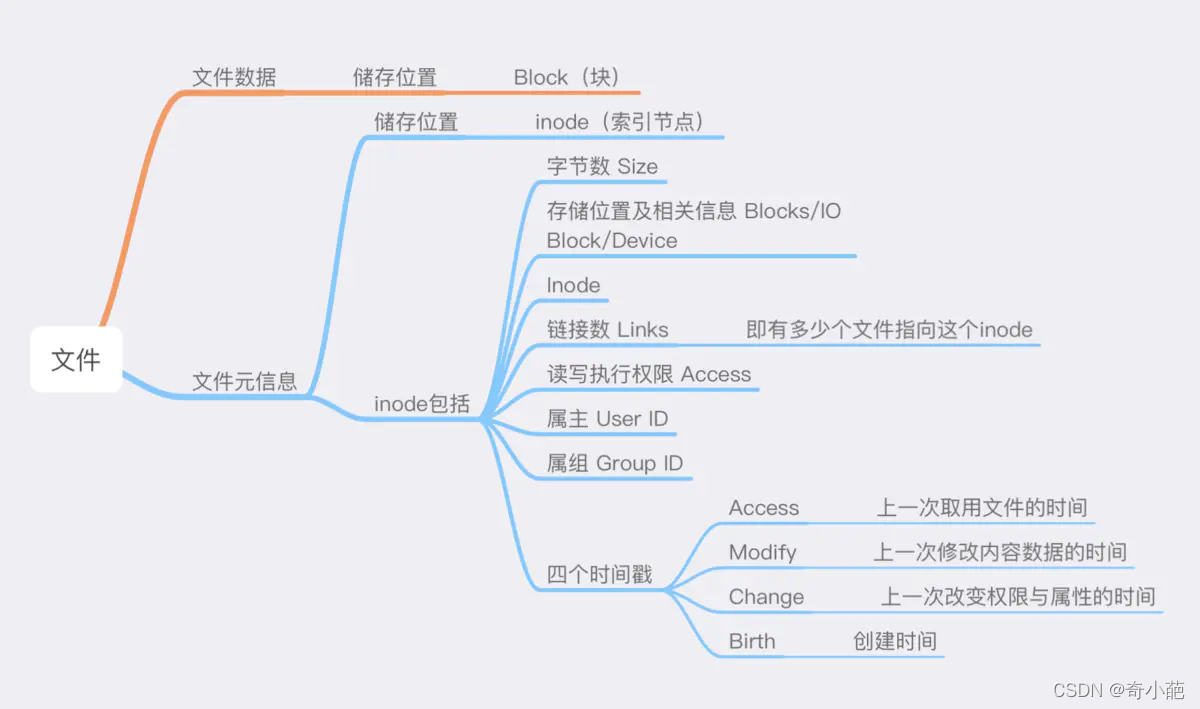
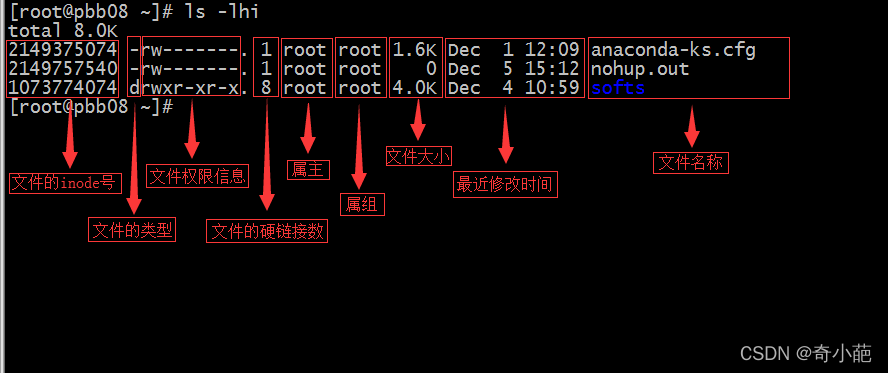
可以用stat命令,查看某个文件的inode信息,总之,除了文件名以外的所有文件信息,都存在inode之中。

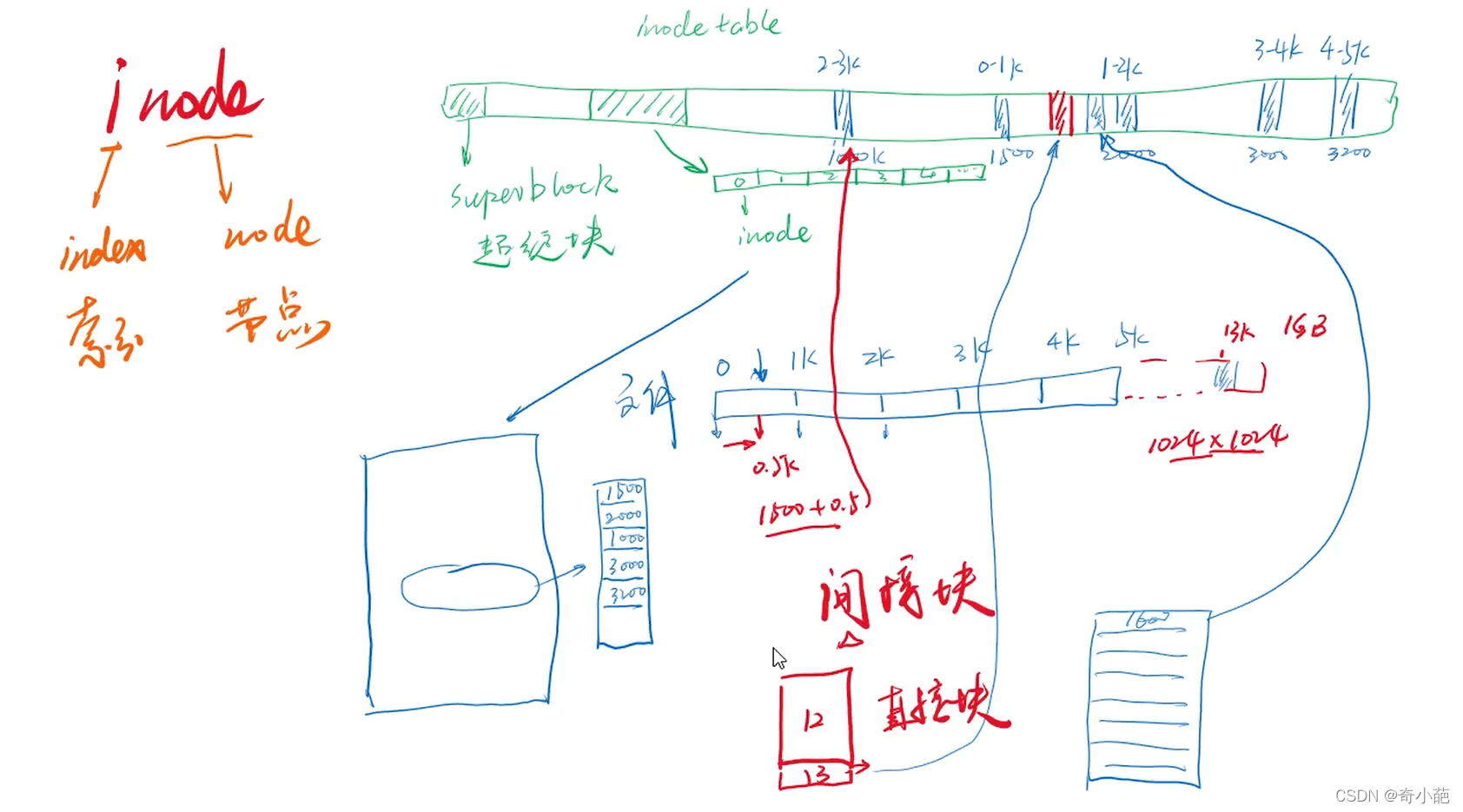
inode也会消耗硬盘空间,所以格式化的时候,操作系统自动将硬盘分成两个区域,一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点大小,一般是128字节或256字节,inode节点的总数,在格式化时就给定,一般是1KB或者2KB就设置一个inode,假定在一个1G的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就达到128MB,占据整块硬盘的12.8%,查看每个硬盘分区的inode总数和已经使用的数量,可以使用df命令

查看每个inode节点的大小,可以用如下命令:sudo dumpe2fs -h /dev/sda1 | grep "Inode size”

由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。所以对于inode,我们需要了解
- 每个inode节点大小,一般是128字节或256字节
- 每个文件都仅会占用一个inode而已
- 文件系统能够创建的文件数量与inode的数量有关
- 系统读取文件时,需要先找到inode,并分析inode所记录的权限与用户是否相符,若相符才能开始实际读取blcok的内容
我们大致分析一下inode、block与文件系统大小的关系,一个inode记录一个block要花掉256字节,假设我们有一个文件400M,并且每个block为4K时,那么至少也要十万个Block号码的记录,inode哪有这么多可记录的信息呢?为此系统将inode记录与block记录定义为多级索引
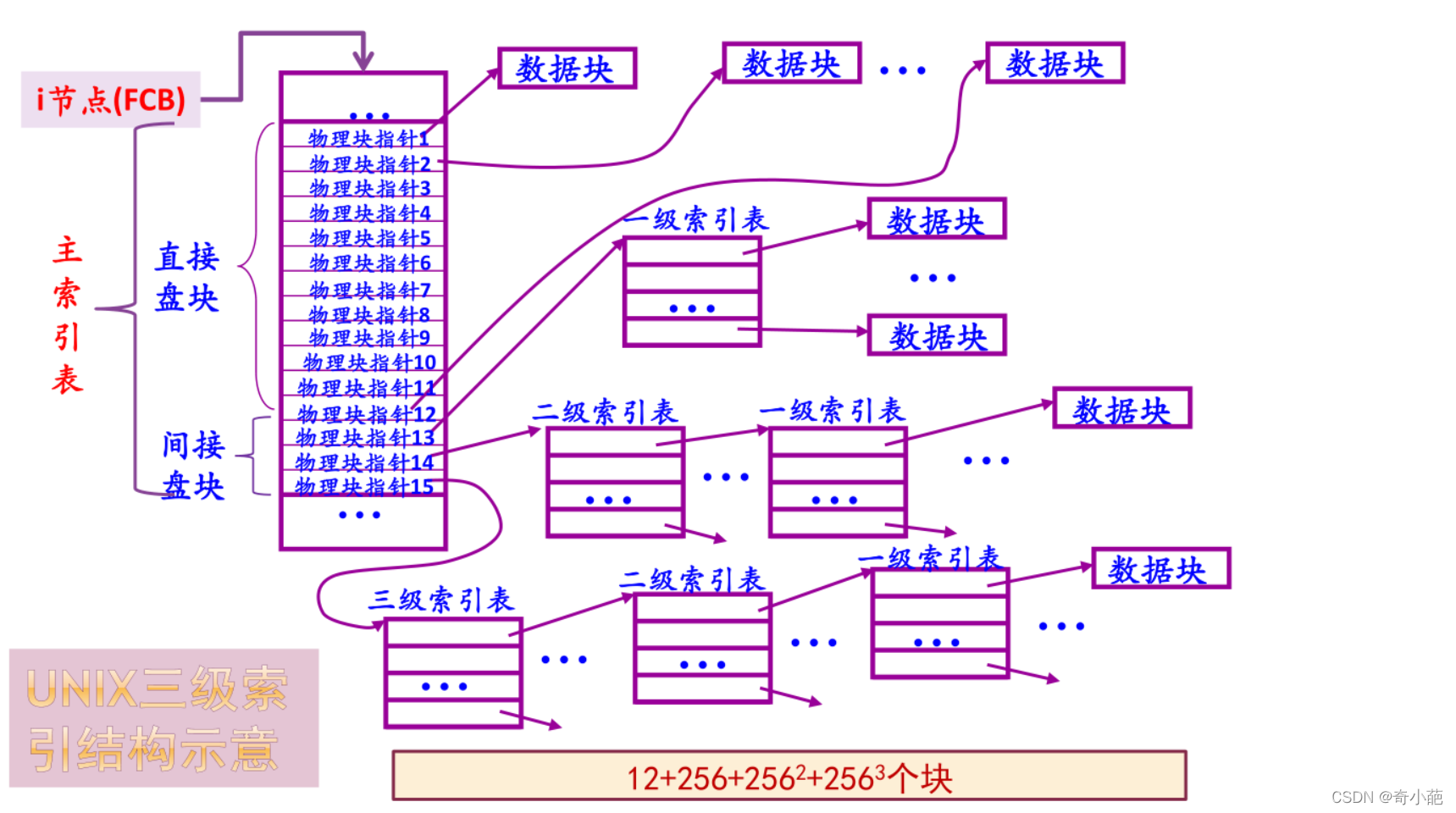
所谓的间接就是再拿一个 block 来当作记录 block 号码的记录区,如果文件太大时, 就会使用间接的 block 来记录编号。这样inode能够制定多少个block呢?我们以较小的1K block来说明,如下:
- 12个直接指向:12 * 1K = 12K,由于是直接指向,所以总共可以记录12笔记录
- 间接指向:如果文件大于12块,则利用第13项指向一个物理块,在该物理块中存放文件物理块的块号(一级索引),假设扇区大小为512字节,物理块等于扇区块大小,一级索引表可以存放256个物理块
- 对于更大的文件,还可以利用第14和第15项,作为二级和三级索引表
总结:将直接、间接、双间接、三间接加总,得到 12 + 256 + 256256 + 256256*256 (K) = 16GB
此时我们直到当文件系统将block格式化为1k大小时,能够容纳的最大文件为16GB,比较以下文件系统线指标的结果可以发现是一直的。
inode大小为128字节的倍数,最小为128字节。它有默认值大小,它的默认值由/etc/mke2fs.conf文件中指定。不同的文件系统默认值可能不同。
[defaults]
base_features = sparse_super,large_file,filetype,dir_index,ext_attr
default_mntopts = acl,user_xattr
enable_periodic_fsck = 0
blocksize = 4096
inode_size = 256
inode_ratio = 16384
reserved_ratio = 1.0
[fs_types]
ext3 = {
features = has_journal
}
ext4 = {
features = has_journal,extent,huge_file,dir_nlink,extra_isize,uninit_bg
inode_size = 256
}
同样观察到这个文件中还记录了blocksize的默认值和inode分配比率inode_ratio。inode_ratio=16384表示每16384个字节即16KB就分配一个inode号,由于默认blocksize=4KB,所以每4个block就分配一个inode号。当然分配的这些inode号只是预分配,并不真的代表会全部使用,毕竟每个文件才会分配一个inode号。但是分配的inode自身会占用block,而且其自身大小256字节还不算小,所以inode号的浪费代表着空间的浪费。
既然知道了inode分配比率,就能计算出每个块组分配多少个inode号,也就能计算出inode table占用多少个block。
inode节点的最大数量,在格式化时就给定**。在初始化文件系统时,inode table初始大小为0,然后,操作系统每分配4096B给data area,就分配inode大小的空间(256B)给inode table,保持4096 : 256 =16 : 1的分配比例。注意,此处仅仅是 保持data area与inode table的分配比例(如16:1) ,与未来一个inode指向多少block无关。
如果文件系统中大量存储电影等大文件,inode号就浪费很多,inode占用的空间也浪费很多。但是没办法,文件系统又不知道你这个文件系统是用来存什么样的数据,多大的数据,多少数据。
当然inode size、inode分配比例、block size都可以在创建文件系统的时候人为指定。
1.3 bmap(块位图)出现
在向硬盘存储数据时,文件系统需要直到哪些块是空闲的,哪些块是已经被占用的?从现在的方法,我们只能采用最笨的方法当然是从前往后扫描,遇到空闲块就存储一部分,继续扫描直到存储完所有的数据。
对于这种问题,也可以参考上面使用的索引的方法,但是仅仅1G的文件系统就有1K大小的block共1024*1024=1048576个,如果是100G、500G甚至更大,仅仅使用索引的数量和空间占用就极其大,这时候就出现了一种更高一级的优化方法:使用块位图( bitmap简称bmap )
位图只使用0和1标识对应block是空闲还是被占用,0和1在位图中的位置和block的位置一一对应,第一位标识第一个块,第二个位标识第二个块,依次下去直到标记完所有的block。

考虑下为什么这种方式更优化呢?在位图中,1个字节8个位,可以表示8个block,对于一个block大小为1KB,容量为1G的文件系统而言,block的数量应该是10241024个,所以在位图中使用10241024/8 = 131072字节=128K,即1G的文件只需要128个block做位图就可以完成一一对应,通过扫描这个100多个block就能直到那些block是空闲的,速度提高了很多。
但是我们需要注意的是, bmap优化针对写优化,因为只有写才需要找到空闲的block并分配空闲block; 对于读而言,只需要通过inode找到block的位置即可,CPU就能迅速的计算出block在物理磁盘的地址,CPU的计算速度很快,计算block的时间几乎可以忽略不计,那么读速度基本认为是受硬盘本身性能的影响而与文件系统无关。
大多数稍微大一点的文件可能都会存储在不连续的block上,而且使用了一段时间的文件系统可能会有不少碎片,这时硬盘的随机读取性能直接决定了读数据的速度,这也是机械硬盘速度相比于固态硬盘慢很多的原因之一。对于固态硬盘的随机读和连续读取速度几乎是一致的,对它来说,文件系统碎片的多少并不会影响读取速度。
- 如果你想新增文件,那你要使用哪个block来记录呢?当然是选择
空的block来记录新文件的数据,我们如何直到哪个block是空的?这就要透过bmap的辅助。 - 如果你想删去某些文件时,那么那些文件原本占用的block号码就需要释放出来,此时在block bitmap当中相对应到该block号码的标志就要修改成未使用
虽然bmap极大的优化了扫描,但是仍然有其瓶颈:如果一个文件系统是100G?那么系统要使用128*100=12800个1KB大小的block,这就占用了12.5M的空间,试想我们需要完全扫描12800个很可能不连续的block,这也是很占用时间的,所以需要再次优化
1.4 inode表的出现
上面在inode的出现中,我们了解到inode存储了Inode号,文件属相元数据,指向文件占用的block指针,每个inode占用128字节或256字节。那么又出现了一个新问题,一个文件系统可以说有无数多文件系统,每个文件都对应一个inode,难道每一个仅128字节的inode要独占一个block进行存储吗?也会出现浪费空间的问题
所以更优化的方法是将多个inode合并存储在block中,对于128字节的inode,一个block存储8个inode,对于256字节的inode,一个block存储4个inode,这就是个每个存储的inode块不浪费。
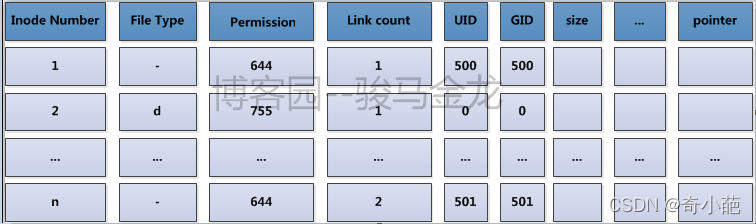
在ext文件系统上,将这些物理上存储inode的block组合起来,在逻辑上形成一张inode表(inode table)来记录所有的inode。
举个例子,每一个家庭都要向派出所登记户口信息,通过户口本可以知道家庭住址,而每个镇或街道的派出所将本镇或本街道的所有户口整合在一起,要查找某一户地址时,在派出所就能快速查找到。inode table就是这里的派出所。它的内容如下图所示。
再细细一思考,就能发现一个大的文件系统仍将占用大量的块来存储inode,想要找到其中的一个inode记录也需要不小的开销,尽管它们已经形成了一张逻辑上的表,但扛不住表太大记录太多。那么如何快速找到inode,这同样是需要优化的,优化的方法是将文件系统的block进行分组划分,每个组中都存有本组inode table范围、bmap等。
1.5 imap的出现
前面说bmap是块位图,用于标识文件系统中哪些block是空闲哪些block是占用的。而对于inode也一样,在存储文件时,也需要为其分配一个inode号,但是在格式化创建文件系统后,所有的indode号都已经被事先计算好了(创建文件系统时会为每个块组计算号该块组拥有那些inode号),因此产生了问题,要为文件分配哪一个inode号呢?又如何直到某一个inode号是否已经被分配了呢?
既然是"是否被占用"的问题,使用位图是最佳方案,像bmap记录block的占用情况一样。标识inode号是否被分配的位图称为inode map简称为imap。这时要为一个文件分配inode号只需扫描imap即可知道哪一个inode号是空闲的。
imap存在着和bmap和inode table一样需要解决的问题:如果文件系统比较大,imap本身就会很大,每次存储文件都要进行扫描,会导致效率不够高。同样,优化的方式是将文件系统占用的block划分成块组,每个块组有自己的imap范围。
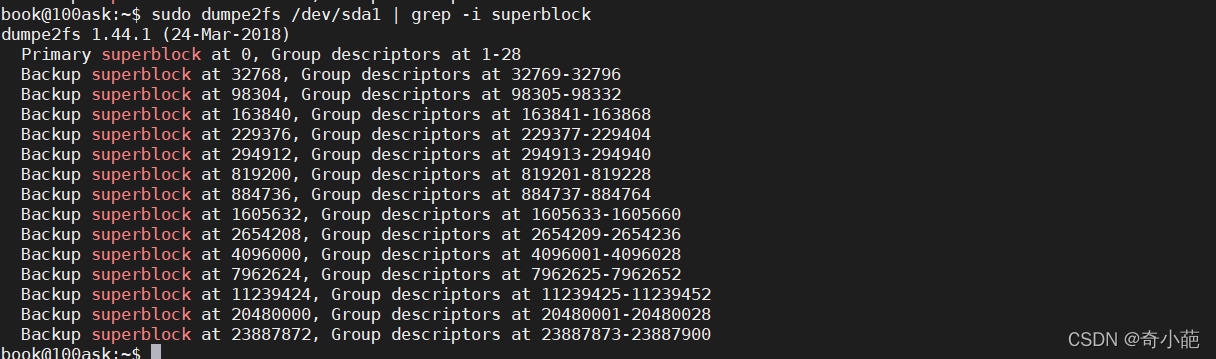
了解了文件系统的概念之后,再来当然是观察这个文件系统啰!刚刚谈到的各部分数据都与 block 号码有关! 每个区段与 superblock 的信息都可以使用 dumpe2fs 这个命令来查询的!查询的方法与实际的观察如下:
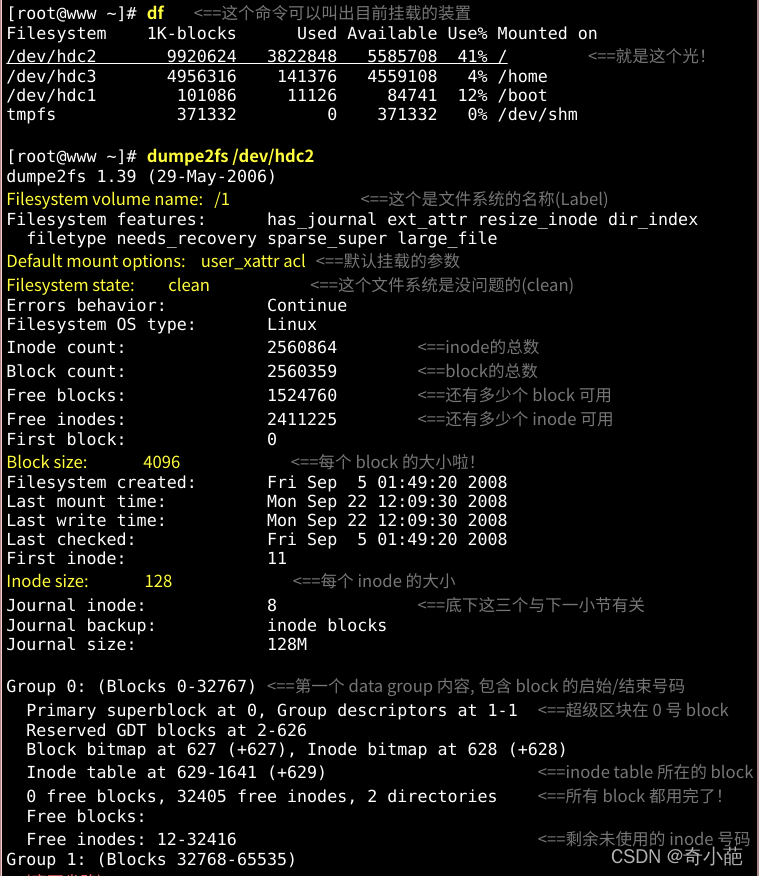
如上所示,利用 dumpe2fs 可以查询到非常多的信息,不过依内容主要可以区分为上半部是 superblock 内容, 下半部则是每个 block group 的信息了。从上面的表格中我们可以观察到这个 /dev/hdc2 规划的 block 为 4K, 第一个 block 号码为 0 号,且 block group 内的所有信息都以 block 的号码来表示的。 然后在 superblock 中还有谈到目前这个文件系统的可用 block 与 inode 数量。至于 block group 的内容我们单纯看 Group0 信息好了。从上表中我们可以发现:
- Group0 所占用的 block 号码由 0 到 32767 号,superblock 则在第 0 号的 block 区块内
- 文件系统描述说明在第 1 号 block 中
- block bitmap 与 inode bitmap 则在 627 及 628 的 block 号码上
- 至于 inode table 分布于 629-1641 的 block 号码中
- 由于 (1)一个 inode 占用 128 bytes ,(2)总共有 1641 - 629 + 1(629本身) = 1013 个 block 花在 inode table 上, (3)每个 block 的大小为 4096 bytes(4K)。由这些数据可以算出 inode 的数量共有 1013 * 4096 / 128 = 32416 个 inode 啦!
- 这个 Group0 目前没有可用的 block 了,但是有剩余 32405 个 inode 未被使用
- 剩余的 inode 号码为 12 号到 32416 号
1.6 块组的出现
前面一直提高的优化方法是将文件系统占用的block划分成块组(block group),解决bmap、inode table和imap 太大的问题。在物理层面划分是将磁盘按照柱面划分为多个分区,即多个文件系统;在逻辑层面上的划分是将文件系统划分成块组,每个文件系统包含有多个块组,每个块组包含了多个元数据区和数据区
- 元数据区: 就是存储bmap、inode、inode table的数据
- 数据区: 就是存储文件数据的区域
块组在文件系统创建完成后就已经划分完成了,也就是说元数据区bmap、inode table和imap等信息占用的block以及数据区占用的block都已经划分好了。那么文件系统如何知道一个块组元数据区包含多少个block,数据区又包含多少block呢?
它只需确定一个数据——每个block的大小,再根据bmap至多只能占用一个完整的block的标准就能计算出块组如何划分。如果文件系统非常小,所有的bmap总共都不能占用完一个block,那么也只能空闲bmap的block了。
假设限制的block的大小是1KB,一个bmap完整占用一个block能表示1024*8=8192个block。每个block是1KB,每个块组是8192K即8M,创建1G的文件系统需要划分1024/8=128个块组,如果是1.1G的文件系统呢?128+12.8=128+13=141个块组
每个组的block数目是划分好的,但是每个组设定多少个inode号?inode table占用多少block?这需要由系统决定,因为描述"每多少个数据区的block就为其分配一个inode号”,这个是创建文件系统时指定,也可以认为指定这个指标。
下图是一个ext4文件系统的部分信息,在这些信息的后面还有每个块组的信息,其实这里面的很多信息都可以通过几个比较基本的元数据推导出来
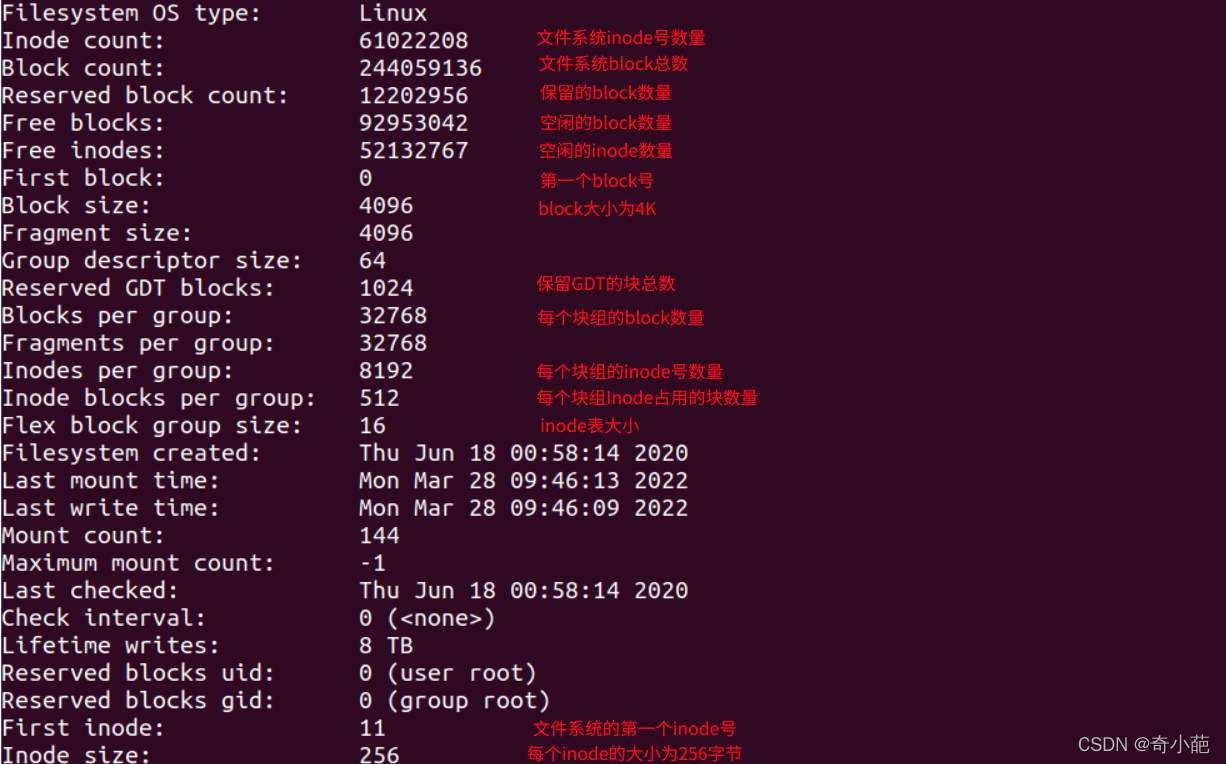
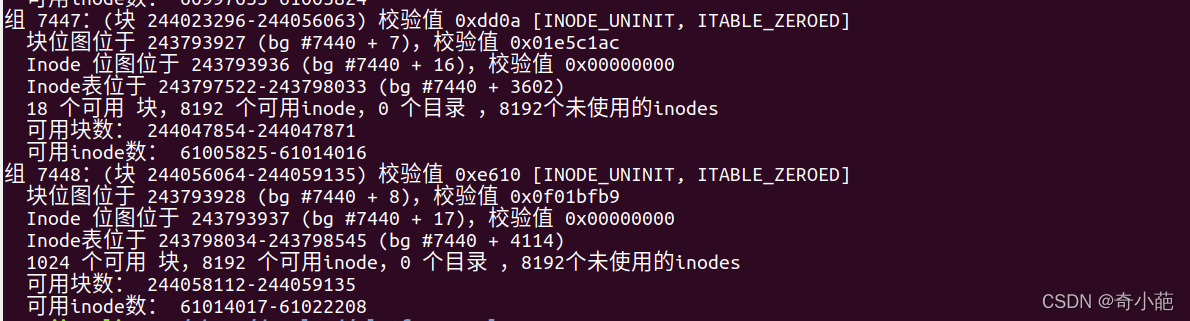
从这张表能计算出文件系统的大小,该文件系统共有244059136个blocks,每个blocks大小为4K,所以文件系统的大小为 244059136*4/1024/1024 = 931GB
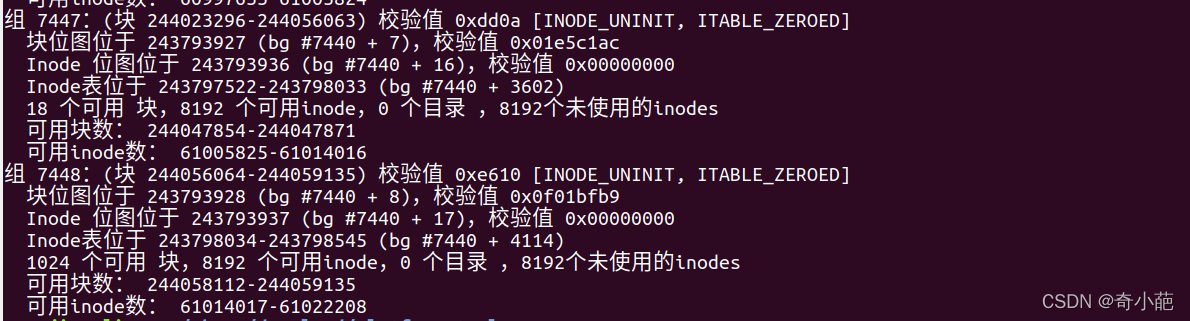
也能计算出分了多少个块组,因为每个块组的block数量为32768,所以块组的数量为244059136/32768=7448.09,由于块组从0开始编号,所以最后一个块组编号为7448,如下图
1.7目录的出现
我们知道了一个普通文件是如何存储的,但还有一个特殊的文件,经常用到的目录,它是如何保存的呢?目录系统的最简单形式是在一个目录中包含所有的文件,这个称为根目录,这种设计的优点在于简单,并且能够快速定位文件,这种目录系统经常用于简单的嵌入式装置中,如电话、数码相机以及一些便携式音乐播放器等。
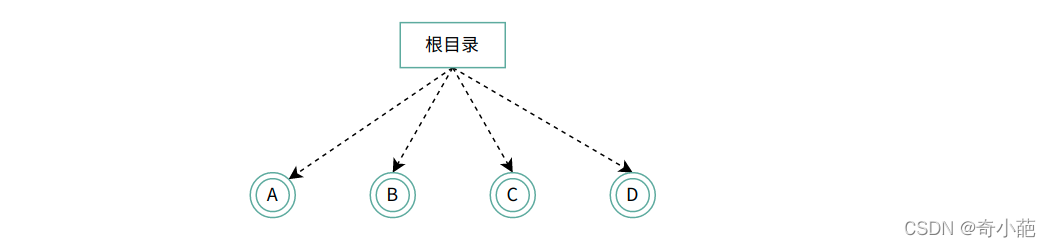
对于简单的应用场景而言,单层目录是合适的,但是随着多用户的发展,同时每个用户有着数以千计的文件,如果所有的文件都在一个目录中,寻找文件就变得越来越困难了,这里就需要的是层次结构(即一个目录树)。通过这种方式,可以用很多目录把文件以自然的方式分组,集中划分,分而治之。
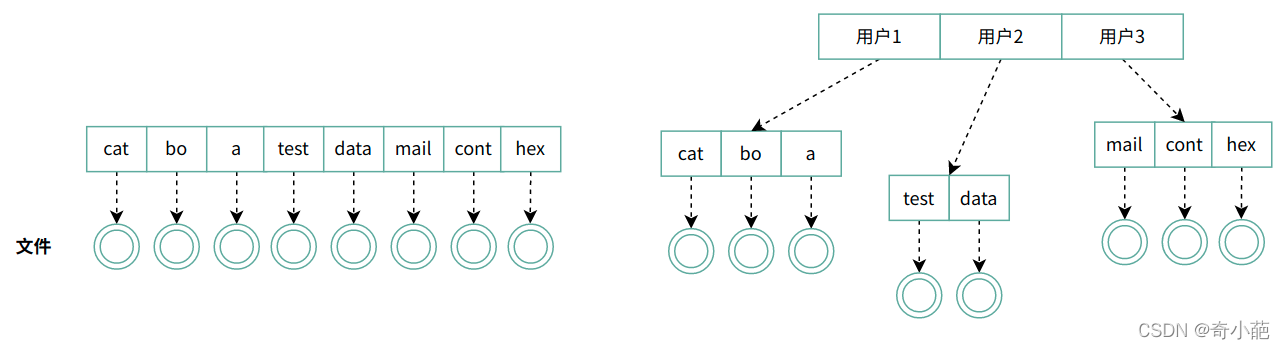
引入目录树后,将划分后的集合在进行划分,K次划分后,每个集合中的文件数为O(logkN)
- 这一树状结构扩展性好、表示清晰、最常用
- 引入了一个新的东西,目录,表示一个文件的集合
我们来想想如何设计,实现目录称为关键问题,例如我们想访问/my/data/a的文件,该解决那些问题呢?
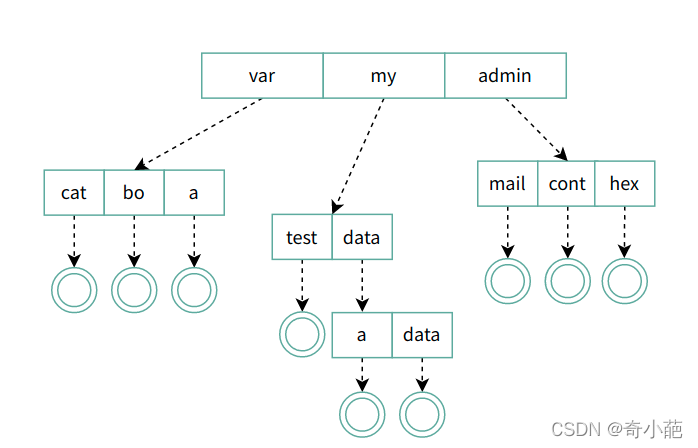
- 根据/my/data/a,如何得到文件a的FCB?
- 存放目录下的所有文件的FCB吗?如果是,解析my要做些什么?有什么办法(目录存写什么)可以使系统效率更高?
那么首先想到,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件,那么我们是不是可以跟文件一样,形成一系列的目录项列表,每个目录项,由两部分组成:所包含文件的文件名和inode号码呢?但是我们要区分文件的Inode节点,对于这个专门生成了一个目录项的节点
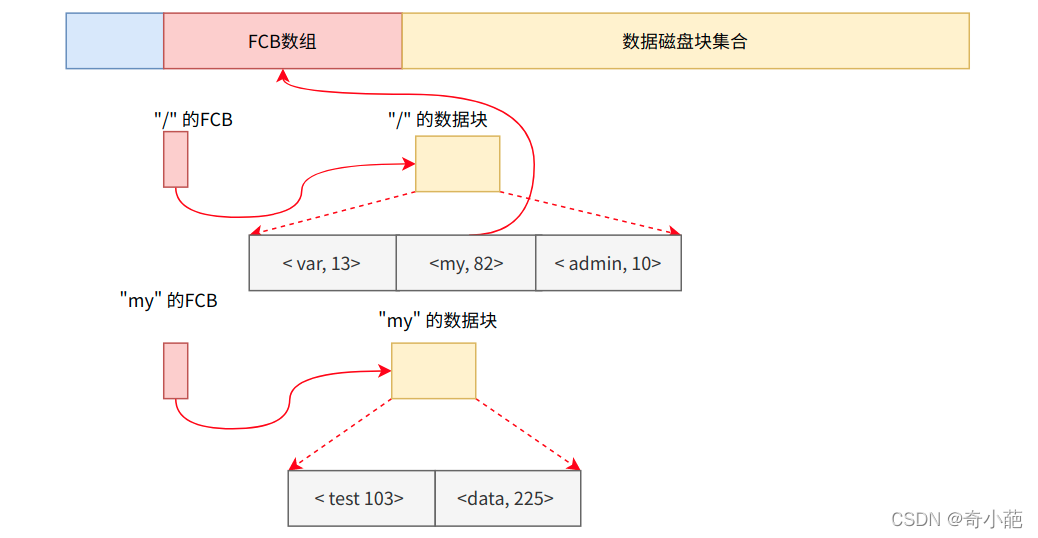
当系统的存储空间比较少的时候,对于目录项可以与Inode节点公用,但是当系统的存储空间越来越大的时候,为了提高系统的Inode节点的利用率,就需要将目录项独立出去,对于这个方案ext4,采用一个单独的分区,用于存放根节点,然后将根节点下的目录项,随着文件的目录的创建放到数据磁盘块中,也就是说对于上面的FCB数组,值需要存放var,my,data对应的数据节点即可。ls -i命令列出整个目录文件,即文件名和inode号码:
ls -i /
14155777 bin 11796481 etc 1048577 lib 11 lost+found 1 proc 52166657 sbin 1 sys 1157 vmlinuz
3932161 boot 49807361 home 47972353 lib32 17039361 media 48758785 ramdisk 52428801 snap 55050241 tmp 12491 vmlinuz.old
21233665 cdrom 1155 initrd.img 47448065 lib64 27262977 mnt 22282241 root 11927553 srv 1835009 usr
2 dev 16 initrd.img.old 24117249 libx32 43778049 opt 2 run 15 swap 45088769 var
1.8 块组描述符表(GDT)
既然文件系统划分了块组,那么每个块组的信息和属性元数据又保存在哪里呢?对于ext文件系统每个块组使用32字节描述,这32字节称为块组描述符,所有的块组的块组描述符组成块组描述符表GDT(group descriptor table)。
深入每个块组需要块组描述符来记录块组的信息和属性元数据,但是不是每个块组都存放块组描述符呢?对于ext4的文件系统,将它们组成一个GDT,并将该GDT存放于某些块组中。
假设block的大小为4KB的文件系统划分了143个块组,每个块组描述符为32字节,那么GDT就需要143*32=4576字节,即两个block来存放,这两个GDT block中记录了所有块组的块信息,且存放GDT的块组中的GDT都是完全相同的。下面是一个块组描述符的信息(dumpe2fs获取)
1.9 保留GDT(Reserved GDT)
保留GDT用于以后扩容文件系统使用,防止扩容后块组太多,使得块组描述符超出当前存储GDT的blocks。例如前面143个块组使用了2个block来存放GDT,但是此时第二个block还空余了很多空间,当扩容到一定程度时,2个block已经无法再记录块组描述符,这个时候就需要分配一个或者多个Reserved GDT的block来存放超出的块组描述符。
1.10 超级块
既然一个文件系统会分多个块组,那么文件系统怎么知道分了多少个块组呢?每个块组又有多少block多少inode号等等信息呢?还有,文件系统本身的属性信息如各种时间戳、block总数量和空闲数量、inode总数量和空闲数量、当前文件系统是否正常、什么时候需要自检等等,它们又存储在哪里呢?
毫无疑问,这些信息必须要存储在block中。存储这些信息占用1024字节,所以也要一个block,这个block称为超级块(superblock),它的block号可能为0也可能为1。如果block大小为1K,则引导块正好占用一个block,这个block号为0,所以superblock的号为1;如果block大小大于1K,则引导块和超级块同置在一个block中,这个block号为0。总之superblock的起止位置是第二个1024(1024-2047)字节。
使用df命令读取的就是每个文件系统的superblock,所以它的统计速度非常快。相反,用du命令查看一个较大目录的已用空间就非常慢,因为不可避免地要遍历整个目录的所有文件。
[root ]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda3 ext4 18G 1.7G 15G 11% /
tmpfs tmpfs 491M 0 491M 0% /dev/shm
/dev/sda1 ext4 190M 32M 149M 18% /boot
Superblock 是记录整个 filesystem 相关信息的地方, 没有 Superblock ,就没有这个 filesystem 了。他记录的信息主要有:
- block与inode的总量
- 未使用和已使用inode/block数量
- block 与 inode 的大小 (block 为 1, 2, 4K,inode 为 128 bytes)
- filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘 (fsck) 的时间等文件系统的相关信息
- 一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0 ,若未被挂载,则 valid bit 为 1
superblock对于文件系统而言是至关重要的,超级块丢失或损坏必将导致文件系统的损坏。所以旧式的文件系统将超级块备份到每一个块组中,但是这又有所空间浪费,所以ext2文件系统只在块组0、1和3、5、7幂次方的块组中保存超级块的信息,如Group9、Group25等。尽管保存了这么多的superblock,但是文件系统只使用第一个块组即Group0中超级块信息来获取文件系统属性,只有当Group0上的superblock损坏或丢失才会找下一个备份超级块复制到Group0中来恢复文件系统。
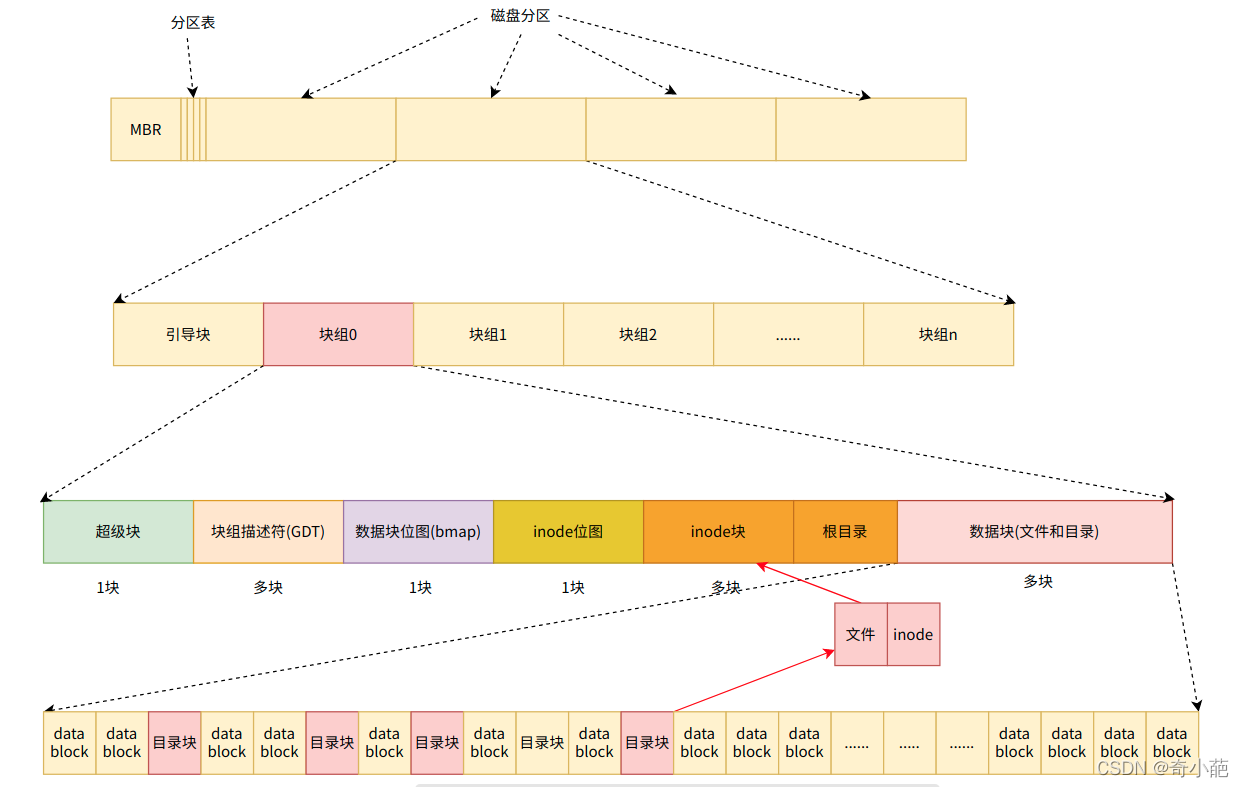
2. 文件系统的架构
我们来看看我们文件系统的架构
-
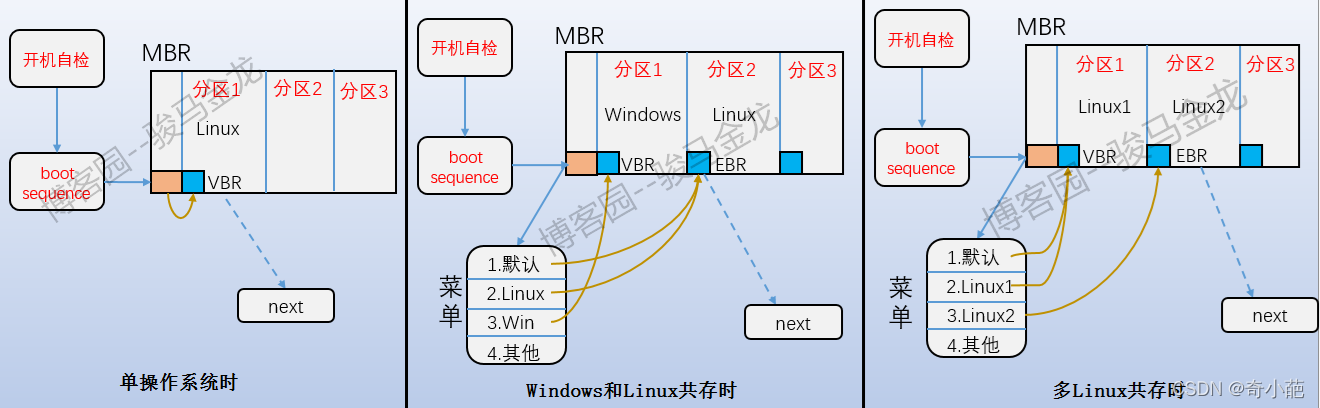
引导分区: 即上图中的MBR部分,它位于分区上的第一个块,占用1024个字节,并非所有分区都有这个,只有装了操作系统的主分区和装了操作系统的逻辑分区才有,里面放了bootloader。开机启动的时候,首先加载MBR中的bootloader,然后定位到操作系统所在分区的boot serctor加载到此处的bootloader。如果是多系统,加载MBR中的bootloader后会列出操作系统菜单,如下
-
超级块: 既然一个文件系统会分多个块组,那么文件系统怎么知道分了多少个块组呢?每个块组又有多少block多少inode号等等信息呢?还有,文件系统本身的属性信息如各种时间戳、block总数量和空闲数量、inode总数量和空闲数量、当前文件系统是否正常、什么时候需要自检等等,它们又存储在哪里呢?毫无疑问,这些信息必须要存储在block中,这个Block成为超级块,它的block号可能是0也可能是1。
-
如果block大小为1K,则引导块正好占用一个block,这个block号为0,所以superblock的号为1;如果block大小大于1K,则引导块和超级块同置在一个block中,这个block号为0。总之superblock的起止位置是第二个1024(1024-2047)字节。
-
块组描述符: 包含文件系统中各个块组的状态,比如块组中空闲块和 inode 的数目等,每个块组都包含了文件系统中「所有块组的组描述符信息」。
-
data block: 主要是完成从应用程序的逻辑块到磁盘访问的物理块的转变,一旦决定文件按固定大小的块来存储,就会出现data block的大小问题,数据所占用的block由文件对应的inode记录中的block指针找到,不同的文件类型,数据block中存储的内容是不一样的,以下是Linux中不同类型文件的存储方式
- 对于常规文件,文件的数据正常存储在数据块中
- 对于目录,该目录下的所有文件和一级子目录的目录名存储在数据块中,文件名和inode号不是存储在文件自身的inode中,而是存储在其所在目录的data block中
- 对于符号链接,如果目标路径名较短,则直接保存在inode中以便更快的查找;如果目标名较长,则分配一个数据块来保存
- 设备文件、FIFO和Socket等特殊文件没有数据块,设备文件的主设备号和次设备号保存在inode中
-
bmap: 一旦选定了块和块大小的概念,下一个问题就是怎么跟踪空闲块。在向硬盘存储数据时,文件系统需要直到哪些块是空闲的,哪些块是已经被占用的?对于磁盘空间管理的方法是采用位图法,n个块的磁盘需要n位位图,在位图中,空闲块用1表示,已分配块用0表示。
-
imap: 与bmap的功能类似,inode 是空闲的,还是被使用中
-
inode节点: 包含了块组中所有的 inode,inode 用于保存文件系统中与各个文件和目录相关的所有元数据,一个文件可以分成几个数据块存储,就像是分散在各地的龙珠一样,为了顺利地收集齐龙珠,我们需要一个雷达的指引。该文件对应的inode,每个文件对应一个inode,这个inode包含多个指针,指向属于该文件的各个数据块,当操作系统需要读取文件时,只需要对应的inode的mapping,收集起分散的数据块,就可以获取到我们的文件了。
你可以会发现每个块组里有很多重复的信息,比如 超级块和块组描述符表,这两个都是全局信息,而且非常的重要 ,这么做是有两个原因:
- 如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
- 通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能。
3. 文件系统实现原理
当我们读写文件时底层的工作原理是什么?

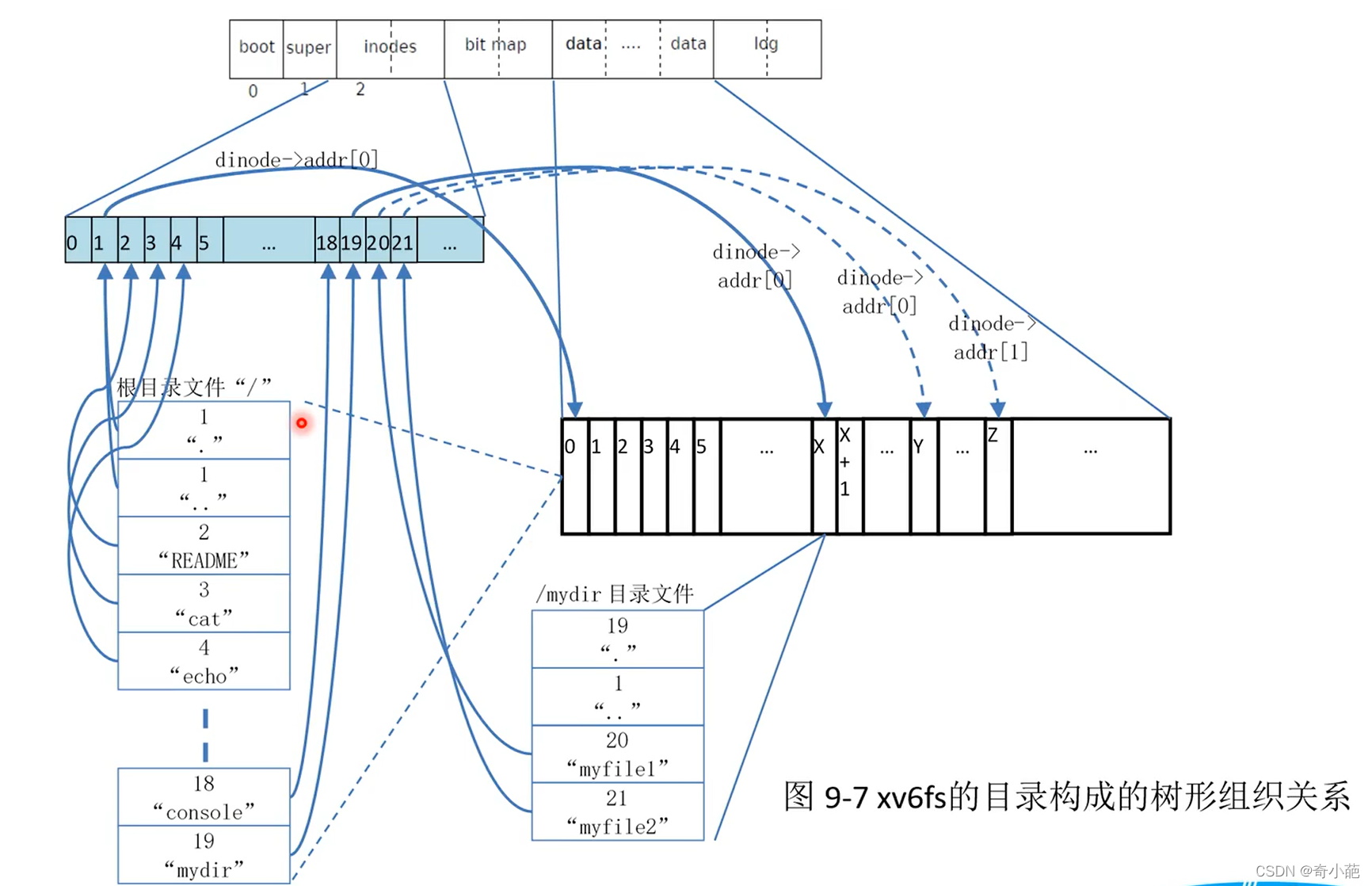
- 当访问一个文件的时候,先进入目录,目录中有相应的目录项,目录项中有对应的文件名和inode号,也就是根据文件名,通过目录项例的对应关系,找到文件对应的inode number
- 再根据inode number读取文件的inode table
- 通过inode里面的指针指向相应的数据块,这样就能访问文件的内容
下面是一个完整的文件系统的访问过程
下面我们来看看,我们如何来查看一个文件内容
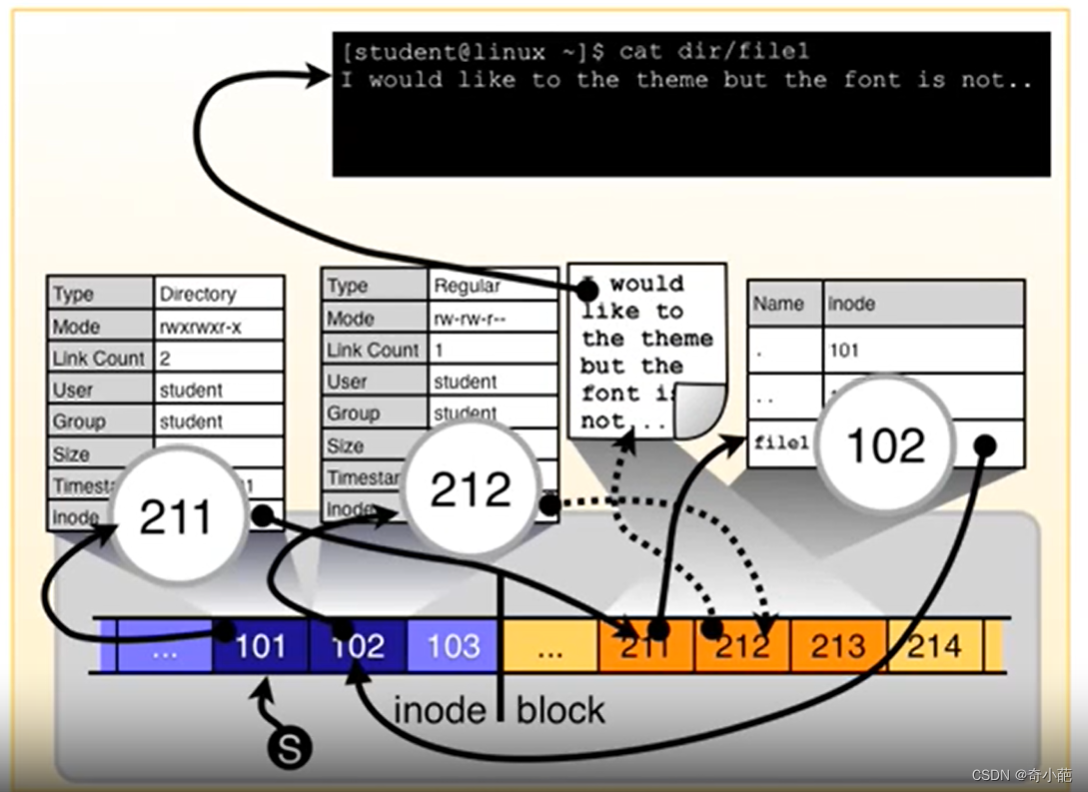
- 首先,我们查找当前目录下的dir,发现其inode是101,就会通过该inode信息中的查找到对应的inode指向的目录项在数据区的211
- 其次,去数据区的211目录项,其中存放了该目录下的所有的数据,包括当前目录.,上级目录…和要查找的file1的inode节点102
- 接着,file1指向的102的inode节点查找对应的数据的Inode,这个是一个文件,直接指向了数据区的212,所以可以直接获得该文件内容
视频请参考
https://www.youtube.com/watch?v=oHrlU3b1ZAw
4 参考文档
鸟哥的 Linux 私房菜 – Linux 磁盘与文件系统管理
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
