1 前言
在《微服务系列》中,我们讲过很多限流,熔断相关的知识。
老生长谈的一个话题,服务的能力终归是有限的,无论是内存、CPU、线程数都是,如果遇到突如其来的峰量请求,我们怎么友好的使用限流来进行落地,避免整个服务集群的雪崩。
峰量请求主要有两种场景:
1.1 突发高峰照成的服务雪崩
如果你的服务突然遇到持续性的、高频率的、不符合预期的突发流量。你需要检查一下服务是否有被错误调用、恶意攻击,或者下游程序逻辑问题。
这种超出预期的调用经常会造成你的服务响应延迟,请求堆积,甚至服务雪崩。而雪崩会随着调用链向上传递,导致整个服务链的崩溃,对我们的系统造成很大的隐患。
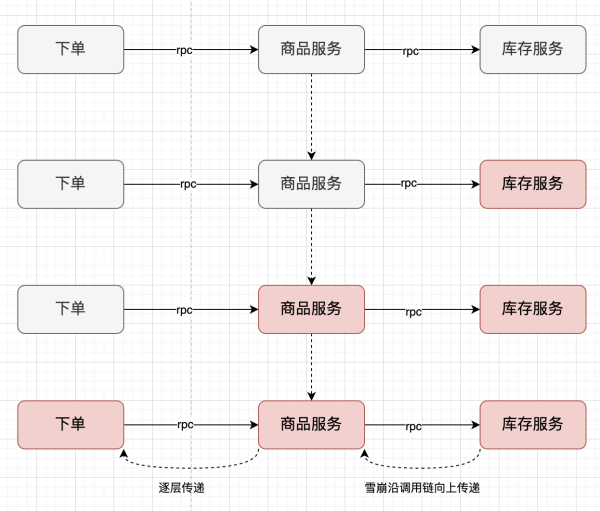
1.2 超出预期值的流量洪峰
如果你的商城或者平台搞活动(类似双11、618),但你又无法有效评估出这个峰值的具象值和持续时间,那么你的服务依然有被打垮的风险。
除非你能做到服务集群弹性伸缩(动态扩缩容)的能力,这个我在后面的云原生系列中会详细说。
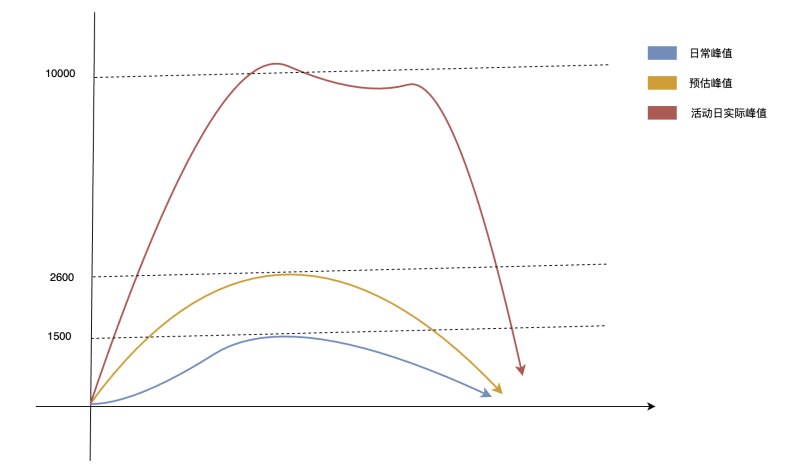
如上图,正常量值为1500 QPS,预估模型的量值是2600的QPS,后面发现,来了几波活动,量值增加到 10000,远超过我们服务器的负载。服务一过载,系统就开始出现各种问题,延迟、故障、请求堆积,甚至雪崩。
2 解决方案
2.1 云原生和弹性伸缩
如果你的服务基架构与足够强大,你的服务上云足够的彻底,那么弹性伸缩是最好的办法。类似淘宝、京东、百度APP,都是类似的做法。
kubernetes会根据流量的变化,CPU、内存的曲线过程实时计算需要的服务实例数,然后进行动态扩容,低峰期再还回去。这个要求你的服务上云足够彻底,并且有足够的资源来达成资源扩容的目标。
★关于这块内容笔者后续会有专门的系列来讲解,以及如何在大厂实现落地的过程,这边不展开。
2.2 兜底的限流、熔断
最基本的保障就是能够在服务做一层保护,避免因为过载而造成服务雪崩,导致整个系统不可用.
对超过预期或者承载能力的流量进行限流是比较好的一种办法。所以你在双11、618、抢购、竞拍 等的选择的时候会经常看到这样的词汇:
-
服务正在努力加载中,请稍候!
-
服务/网络错误,请重试!
-
哎呀,服务繁忙,请稍后再试!

2.1 应用层面解决方案
2.1.1 常见的限流算法
- 计数限流算法
计数算法是指再一定的时间间隔里,记录请求次数,当时间间隔到期之后,就把计数清零,重新计算。

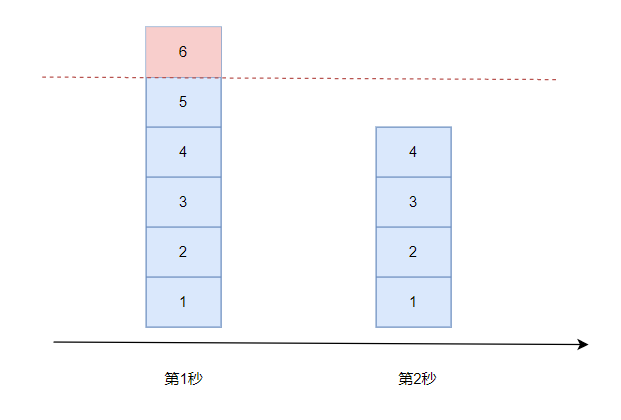
- 固定窗口限流算法(采样时间窗)
相对于上一个 计数限流,多了个时间窗口的概念,计数器每过一个时间窗口就重置,重新开始计算。
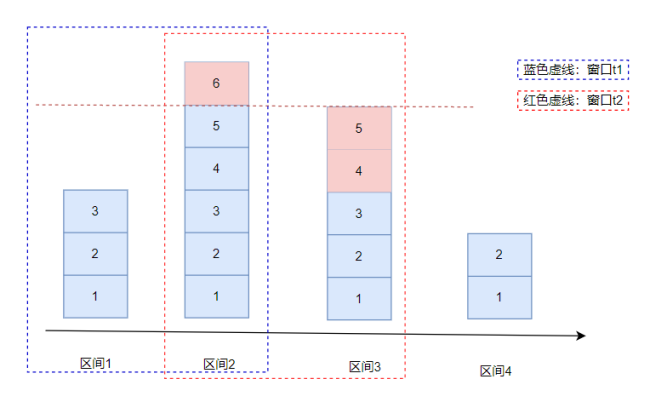
- 滑动窗口限流(记录每个请求到达的时间点)
滑动窗口限流解决固定窗口临界值的问题,可以保证在任意时间窗口内都不会超过阈值。
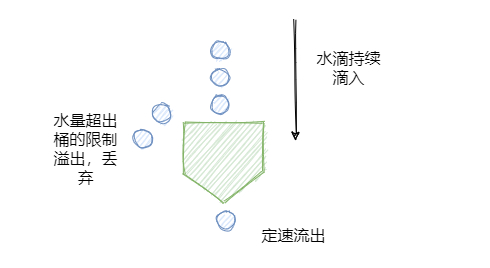
- 漏桶算法(漏斗池算法)
类似沙漏思维,大家都用过,沙子是匀速流出得。对于漏桶来说,由于它的出水口的速度是恒定的,也就是消化处理请求的速度是恒定的,所以它可以保证服务以恒定的速率来处理请求,
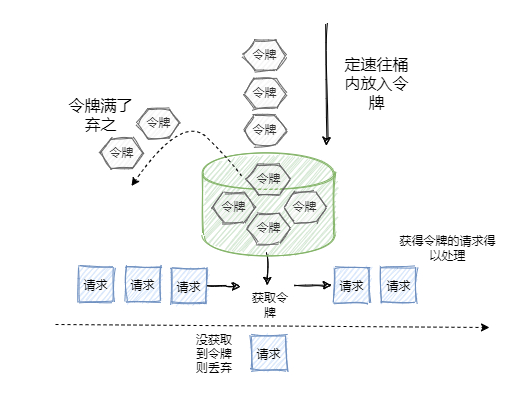
- 令牌桶算法(定速流入)
令牌桶和漏桶的原理类似,只不过漏桶是定速流出,令牌桶是定速流入(即往桶里塞入令牌),每个请求进来,分配一个令牌,只有拿到了令牌才能进入服务器处理,拿不到令牌的就被拒绝了。
因为令牌桶的大小也是有限制的,所以一旦令牌桶满,后续生成的令牌就会被丢弃,拿不到令牌的服务请求就被拒绝了,达到限流的目的。执行原理如下:
2.1.2 相关实现的框架
- Spring Cloud 的 Hystrix
- Sentinel 熔断降级能力
- Google Guava 的 Ratter Limitter
2.1.3 达到限流条件的时候的做法
fallback:返回固定的对象或者执行固定的方法
// 返回固定的对象
{
"timestamp": 1649756501928,
"status": 429,
"message": "Too Many Requests",
}
// 执行固定的处理方法
function fallBack(Context ctx) {
// Todo 默认的处理逻辑
}
2.1.4 Web/Mobile/PC/3d
接收到固定的消息结构或者固定的处理结果之后,以友好的方式提示给用户。
- 提示服务正在努力加载中,请稍候!
- 服务/网络错误,请重试!
- 哎呀,服务繁忙,请稍后再试!
2.2 存储层面解决方案
Redis热点数据同时并发请求处理,1000W+请求同时投向后端,如果缓存未建立,直接投向数据库,可能会造成击穿,怎么破?一般有如下解决方法,优劣各异:
-
分布式锁:只允许一个请求线程去访问DB,其他请求被阻塞,这样就避免了很多请求投放到DB上。但是这样吞吐量降低。
-
请求按照队列执行:按照队列顺序执行,避免全部投向数据库。这样还是吞吐量降低。
-
缓存预热:进入数据库的缓存数量会比较少,保证有一部分的数据先做出来。
-
空/默认 初始值:第一个请求进去的时候,创建空初始值或者默认初始值的缓存,并进入数据库查询。查询之后,更新缓存,保证后续的拿到正确的值。而在查询的这个过程中(可能几ms到几十ms),拿到的是默认值或空置,前端做一下友好的提示。这是一种降级的策略,保证仅有1个或者前n个进入数据库。
-
本地缓存:改造web应用服务,在获取到redis缓存后,在web服务本地把热点的数据进行缓存,因为热点的商品不会很多,所以保存在本地缓存中,是没有问题的。这样请求数据时,如果web本地有缓存数据,就直接返回了。本地缓存和服务进程缓存混用的情况。缓存更新会增加额外的负担。
这里面,空初始值和和分布式锁的结合使用是目前很多大厂的处理方式,如下: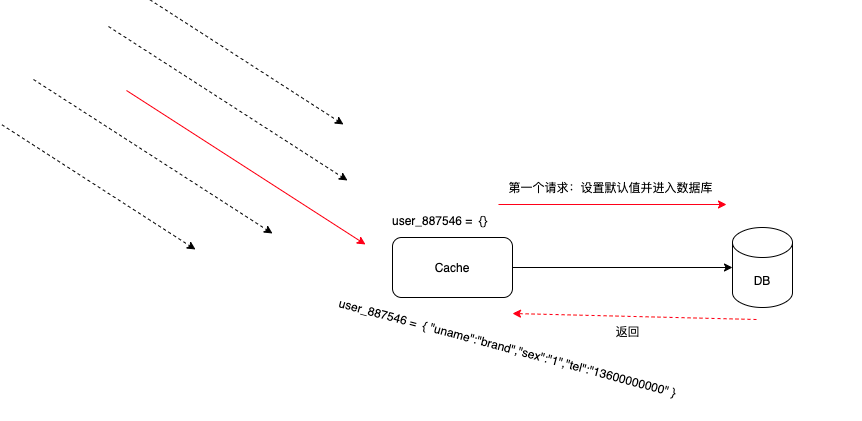
-
第一个请求进去的时候,创建空初始值或者默认初始值的缓存
-
后续进来的同类请求会短暂获取到 默认值的缓存信息
-
当第一个请求从数据库查询到结果,立即更新缓存,保证后续的同类请求拿到的是正确的值
-
而第一个请求调用数据库的过程中(可能几ms到几十ms),其他同类请求拿到的是默认值或空值,前端做一下友好的提示
-
这是一种典型的降级策略,保证仅有1个或者前n个进入数据库
3 总结
无论是应用层级还是存储层级,无非是跟前端约定一个规则,返回默认参数或者默认回到方法,让前端以用户友好体验的方式进行降级,保证服务端不至于崩溃。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
