1 为什么熔断限流
分布式系统环境下,服务间类似依赖非常常见,一个业务调用通常依赖多个基础服务。
如下图,对于同步调用,当库存服务不可用时,商品服务请求线程被阻塞,当有大批量请求调用库存服务时,最终可能导致整个商品服务资源耗尽,
无法继续对外提供服务。并且这种不可用可能沿请求调用链向上传递,这种现象被称为雪崩效应。
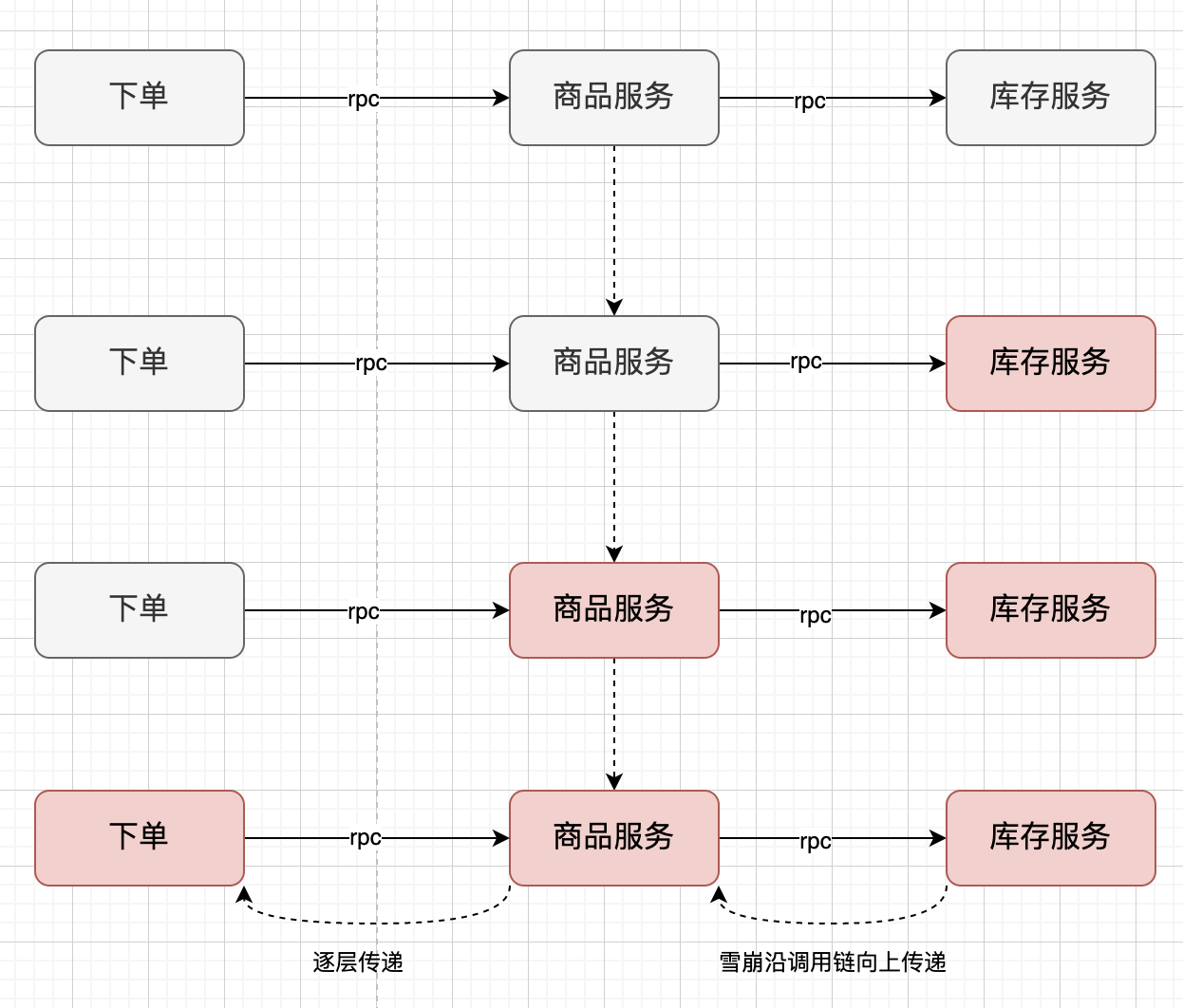
1.2 雪崩效应常见场景
- 硬件故障:如服务器宕机,机房断电,光纤甚至专线被破坏等。
- 流量激增:如异常流量,线上活动导致的流量激增,重试导致流量放大等。
- 缓存穿透:缓存服务重启,导致大量缓存同时失效时。重建缓存或者大量的请求无法命中缓存,会直接投向数据库,导致服务和数据层压力骤增甚至雪崩。
- 程序漏洞:如程序逻辑(如死循环)导致内存泄漏,或者死锁操作导致互相等待,或者JVM长时间FullGC等。
- 同步等待:服务间采用同步调用模式,同步等待造成的资源耗尽。
1.3 雪崩效应应对策略
针对上述的常见场景,需要给出不同的策略来应对,主要有如下几个方面,参考如下:
- 硬件故障:分服甚至分机房容灾、异地多活等。
- 流量激增:服务动态扩缩容,流量控制(熔断,限流,超时重试)等。
- 缓存穿透:缓存预加载、异步加载,设置不定的过期时间等。详细参考这篇《一次缓存雪崩的灾难复盘》
- 程序的健壮性:修复程序漏洞、避免内存泄漏、及时释放资源 等等。
- 同步等待:资源隔离、MQ解耦、不可用服务调用快速失败(超时能力)等。
综合上述的内容可知,如果一个服务不能对自己依赖以及产生的故障进行隔离,那么它自己本身就会处在雪崩风险中。要想构建稳定健壮的分布式系统,我们的服务应当具有自我保护能力和容错的能力。
避免造成更大的故障设置服务雪崩。而这种自我保护的模式就是熔断、限流、异常驱逐等能力。
2 常见的限流的算法
2.1 计数限流算法
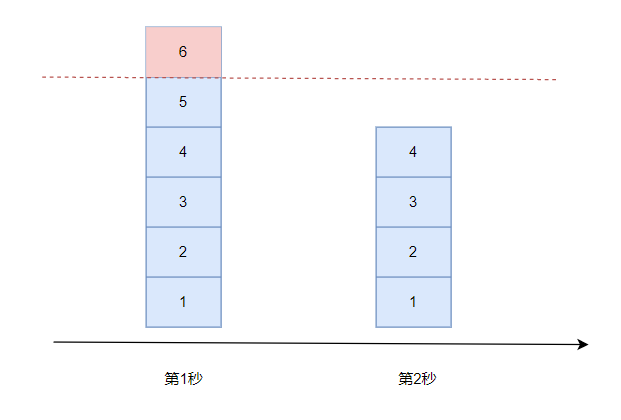
计数算法是指再一定的时间间隔里,记录请求次数,当时间间隔到期之后,就把计数清零,重新计算。如果请求次数超过统计周期内额定的最大次数时,直接拒绝访问,简单粗暴。
计数器的值要是存在内存中就算单机限流算法,类似 Atomic 等原子类。如果存放在类似Redis的第三方缓存服务服务中就是分布式限流了,类似 Redis incr、Redis decr。
如下图所示:

可能存在的问题是:请求分布的不均衡,比如在时间周期1分钟的第1秒,就把100次请求用完了,那么最后59秒都是空白的。也可能直到最后1秒才有大批量的流量
涌入,造成系统的不稳定。
2.2 固定窗口限流算法(采样时间窗)
相对于上一个 计数限流,多了个时间窗口的概念,计数器每过一个时间窗口就重置,重新开始计算
固定窗口计数算法的步骤是:
- 将时间划分为固定的时间窗口,比如1s。
- 在窗口时间段内,每来一个请求,对计数器加1。
- 当计数器达到设定限制后(比如上图,限制了5s),该窗口时间内的之后的请求都被直接拒绝了。
- 时间窗结束后,计数器重置,重新开始计数。
2.3 滑动窗口限流(记录每个请求到达的时间点)
滑动窗口限流解决固定窗口临界值的问题,可以保证在任意时间窗口内都不会超过阈值。
相对于固定窗口,滑动窗口除了需要引入计数器之外还需要记录时间窗口内每个请求到达的时间点,因此对内存的占用会比较多。
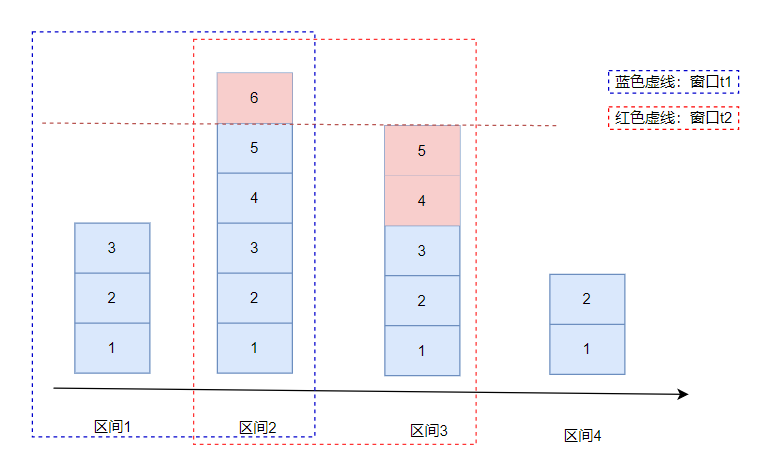
上图中每个时间窗口限流8个req,滑动窗口计数算法的步骤如下:
- 将一个时间窗口划分为细粒度的区间,每个区间配置一个计数器,每incr一个请求则将计数+1。
- 因为一个时间窗口是由多个时间区间组成,每走完一个区间时间后,则抛弃最老的一个区间,纳入新区间。如上图抛弃区间1,纳入新区间3
- 窗口由t1 过渡为 窗口t2。
- 若当前窗口的区间计数器总和超过额定的限制数量8,别区间2使用了5,则区间3最多只能使用剩下3个,后续请求都被丢弃。
2.4 漏桶算法(漏斗池算法)
类似沙漏思维,大家都用过,沙子是匀速流出得。对于漏桶来说,由于它的出水口的速度是恒定的,也就是消化处理请求的速度是恒定的,所以它可以保证组件以恒定的速率来处理请求,
这对一些对处理速度或者资源有严格要求的系统是非常实用的。原理如下:
- req到来则放入桶中
- 桶内请求量满了,则拒绝后续的请求
- 服务定速地从桶内拿出请求并处理
宽进严出是它最大的特点,无论请求多少,请求的速率有多大,都按照固定的速率流出(定速输出),而服务也只能按照固定速率处理,有点像固定延时的消息队列。
如果有处理不过来的请求,那就按照队列进行排队,避免巨大输出把服务搞挂掉,队列满了就refuse。

2.5 令牌桶算法(定速流入)
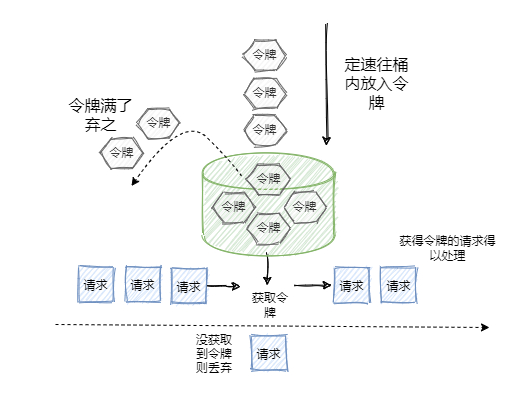
令牌桶和漏桶的原理类似,只不过漏桶是定速流出,令牌桶是定速流入(即往桶里塞入令牌),每个请求进来,分配一个令牌,只有拿到了令牌才能进入服务器处理,拿不到令牌的就被拒绝了。
因为令牌桶的大小也是有限制的,所以一旦令牌桶满,后续生成的令牌就会被丢弃,拿不到令牌的服务请求就被拒绝了,达到限流的目的。执行原理如下:
- 定速将令牌放如令牌桶
- 当桶里面的令牌数量超过桶的额度,直接丢弃
- 当req进来,令牌桶会分配一个令牌给请求,如果令牌桶空了,则请求会被直接拒绝
相对于漏洞的定速流程那种的匀速消费模式,令牌桶可以将积压的令牌一下子花掉,所以在应对流量洪峰的时候,他的表现比露铜算法更优异。
2.6 应用场景
Google Guava 提供的限流工具类 RateLimiter,是基于令牌桶实现的,并且扩展了算法,支持预热功能。
阿里开源的限流框架Sentinel 中的匀速排队限流策略,就采用了漏桶算法。
3 主流熔断限流技术介绍
3.1 Sentinel熔断降级
3.1.1 介绍
Sentinel 被称为高可用流量管理框架,分布式系统流量卫兵。假如对一个接口QPS(每秒请求数)最大限制为10000,在QPS超过10000之后的请求我们就要限制其访问,并给出友好的提示。
不限制QPS无限的次数就会造成服务器超量访问而宕机。在服务调用的过程中,如果调用链路中的某个资源出现了不稳定,比如错误数增加,请求平响升高,则大概率会导致请求堆积,进而诱发整个链路的雪崩,解决办法就是熔断、限流、降级。熔断限流就是当检测到调用链路中某个服务出现不稳定时,对服务的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联故障。
3.1.2 功能特性
Sentinel是分布式系统的流量防卫兵,他有如下优秀特质:
丰富的应用场景:
Sentinel承接了阿里近十年的双11、618等重大活动的流量核心场景,经典如秒杀、竞拍 (即突发流量控制在系统容量可以承受的范围),消息削峰填谷,集群流量控制,实时熔断下游等应用场景
完美的实时监控:
Sentinel同时提供实时、丰富的监控功能,可以在控制台看到接入应用的单台机器秒级流量数据,甚至几百台规模的集群的汇总运行情况
广泛的开源生态:
Sentinel提供开箱即用的,可与其他框架/库的快速整合的模块,例如与SpringCloud,Dubbo,gRPC的整合,引入相应的maven依赖即可快速接入Sentinel。
完美的SPI扩展点:
Sentinel提供简单易用的,完美的SPI扩展接口,可以通过实现扩展接口来快速定制逻辑,例如定制规则管理,适配动态数据源等.。
3.2 Spring Cloud 的Hystrix
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
3.2.1 使用方式
- 构建HystrixCommand,执行命令,execute()、queue()、observe()、toObservable()
- 添加 @WafHystrixFallback 注解
- 判断熔断器是否打开;判断线程池/队列/信号量是否已满;执行HystrixObservableCommand.construct()或HystrixCommand.run() 失败或者超时,走Fallback备用逻辑。
4 总结
- 熔断限流的目的是避免超出预期的调用、或者你自身服务的故障 造成服务响应延迟,请求堆积,甚至服务雪崩。而雪崩会随着调用链向上传递,可能导致整个服务链的崩溃。
- 常见的限流算法有:计数限流、固定窗口限流、滑动窗口限流、漏桶算法、令牌同算法等。
- 主流的熔断限流技术有 Hystrix 、Rate Limiter、Seninel 等
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
