1、简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
2、流式数据平台
作为一个流式数据平台,最重要的是要具备下面3个特点。
- 类似消息系统,提供事件流的发布和订阅,即具备数据注入功能。
- 存储事件流数据的节点具有故障容错的特点,即具备数据存储功能。
- 能够对实时的事件流进行流式地处理和分析,即具备流处理功能。
下面我们分析作为一个流式数据平台,Kafka是如何实现并组合上面的3个功能特点的。
-
消息系统:如图所示,消息系统(也叫作消息队列)主要有两种消息模型:队列和发布订
阅。Kafka使用消费组(consumer group)统一了上面两种消息模型。Kafka使用队列模型时,它可以将处理工作平均分配给消费组中的消费者成员;使用发布订阅模式时,它可以将消息广播给多个消费组。采用多个消费组结合多个消费者,既可以线性扩展消息的处理能力,也允许消息被多个消费组订阅。 -
队列模式(也叫作点对点模式):多个消费者读取消息队列,每条消息只发送给一个消费者。 -
发布-订阅模式(pub/sub):多个消费者订阅主题,主题的每条记录会发布给所有的消费者。
-
存储系统:任何消息队列要做到“发布消息”和“消费消息”的解耦合,实际上都要扮演一个存储系统的角色,负责保存还没有被消费的消息。否则,如果消息只是在内存中,一旦机器宕机或进程重启,内存中的消息就会全部丢失。Kafka也不例外,数据写入到Kafka集群的服务器节点时,还会复制多份来保证出现故障时仍能可用。为了保证消息的可靠存储,Kafka还允许生产者的生产请求在收到应答结果之前,阻塞式地等待一条消息,直到它完全地复制
到多个节点上,才认为这条消息写入成功。 -
流处理系统:流式数据平台仅仅有消息的读取和写入、存储消息流是不够的,还需要有实时的流式数据处理能力。对于简单的处理,可以直接使用Kafkal的生产者和消费者API来完成;但对于复杂的业务逻辑处理,直接操作原始的API需要做的工作非常多。Kafka流处理(Kafka Streams)为开发者提供了完整的流处理API,比如流的聚合、连接、各种转换操作。同时,Kafka流处理框架内部解决很多流处理应用程序都会面临的问题:处理乱序或迟来的数据、重新处理输入数据、窗口和状态操作等。 -
将消息系统、存储存储、流处理系统组合在一起:传统消息系统的流处理通常只会处理订阅
动作发生之后才到达的新消息,无法处理订阅之前的历史数据。分布式文件存储系统一般存储静态的历史数据,对历史数据的处理一般采用批处理的方式。现有的开源系统很难将这些系统无缝地整合起来,Kafka则将消息系统、存储系统、流处理系统都组合在一起,构成了以Kafka为中心的流式数据处理平台。它既能处理最新的实时数据,也能处理过去的历史数据。
Kafka作为流式数据平台的核心组件,主要包括下面4种核心的API,如图所示。
- 生产者(producer)应用程序发布事件流到Kafka的一个或多个主题。
- 消费者(consumer)应用程序订阅Kafka的一个或多个主题,并处理事件流。
- 连接器(connector)将Kafka主题和已有数据源进行连接,数据可以互相导入和导出。
- 流处理(processor)从Kafka主题消费输入流,经过处理后,产生输出流到输出主题。

建立以Kafa为核心的流式数据管道,不仅要保证低延迟的消息处理,还需要保证数据存储的可靠性。另外,在和离线系统集成时,将Kafka的数据加载到批处理系统时,要保证数据不遗漏;Kafka集群的某些节点在停机维护时,要保证集群可用。
3、Kafka的基本概念
3.1、分区模型
Kafka集群由多个消息代理服务器(broker server)组成,发布到Kafka集群的每条消息都有一个类别,用主题(topC)来表示。通常,不同应用产生不同类型的数据,可以设置不同的主题。一个主题一般会有多个消息的订阅者,当生产者发布消息到某个主题时,订阅了这个主题的消费者都可以接收到生产者写入的新消息。
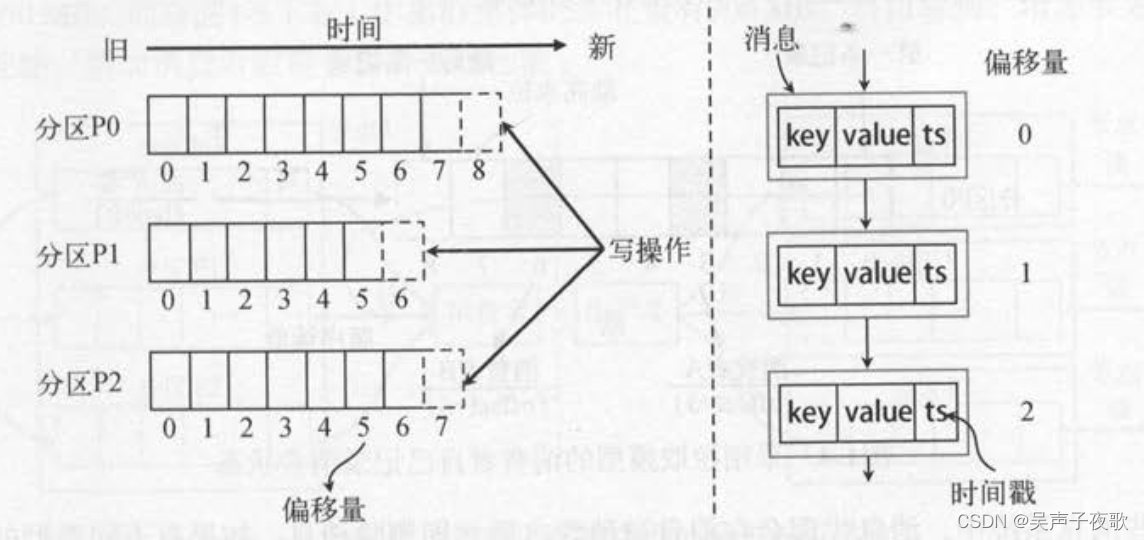
Kafka集群为每个主题维护了分布式的分区(partition)日志文件,物理意义上可以把主题看作分区的日志文件(partitioned log)。每个分区都是一个有序的、不可变的记录序列,新的消息会不断追加到提交日志(commit log)。分区中的每条消息都会按照时间顺序分配到一个单调递增的顺序编号,叫作偏移量(offset),这个偏移量能够唯一地定位当前分区中的每一条消息。
如图所示,主题有3个分区,每个分区的偏移量都从0开始,不同分区之间的偏移量都是独立的,不会互相影响。右图中,发布到Kafka主题的每条消息包括键值和时间戳。消息到达服务端的指定分区后,都会分配到一个自增的偏移量。原始的消息内容和分配的偏移量以及其他一些元数据信息最后都会存储到分区日志文件中。消息的键也可以不用设置,这种情况下消息会均衡地分布到不同的分区。
传统消息系统在服务端保持消息的顺序,如果有多个消费者消费同一个消息队列,服务端会以消息存储的顺序依次发送给消费者。但由于消息是异步发送给消费者的,消息到达消费者的顺序可能是无序的,这就意味着在并行消费时,传统消息系统无法很好地保证消息被顺序处理。虽然我们可以设置一个专用的消费者只消费一个队列,以此来解决消息顺序的问题,但是这就使得消费处理无法真正
执行。
Kafka比传统消息系统有更强的顺序性保证,它使用主题的分区作为消息处理的并行单元。Kafka以分区作为最小的粒度,将每个分区分配给消费组中不同的而且是唯一的消费者,并确保一个分区只属于一个消费者,即这个消费者就是这个分区的唯一读取线程。那么,只要分区的消息是有序的,消费者处理的消息顺序就有保证。每个主题有多个分区,不同的消费者处理不同的分区,所以Kafka不
仅保证了消息的有序性,也做到了消费者的负载均衡。
3.2、消费模型
消息由生产者发布到Kafka集群后,会被消费者消费。消息的消费模型有两种:推送模型(push)和拉取模型(pull)。基于推送模型的消息系统,由消息代理记录消费者的消费状态。消息代理在将消息推送到消费者后,标记这条消息为已消费,但这种方式无法很好地保证消息的处理语义。比如,消息代理把消息发送出去后,当消费进程挂掉或者由于网络原因没有收到这条消息时,就有可能造成消息丢失(因为消息代理已经把这条消息标记为已消费了,但实际上这条消息并没有被实际处理)。如果要保证消息的处理语义,消息代理发送完消息后,要设置状态为“已发送”,只有收到消费者的确认请求后才更新为“已消费”,这就需要在消息代理中记录所有消息的消费状态,这种做法也是不可取的。
Kafka采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序读取每个分区的消息。如图所示,有两个消费者(不同消费组)拉取同一个主题的消息,消费者A的消费进度是3,消费者B的消费者进度是6。消费者拉取的最大上限通过最高水位(watermark)控制,生产者最新写入的消息如果还没有达到备份数量,对消费者是不可见的。这种由消费者控制偏移量的优点是:消费者可以按照任意的顺序消费消息。比如,消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前时刻开始消费。

在一些消息系统中,消息代理会在消息被消费之后立即删除消息。如果有不同类型的消费者订阅同一个主题,消息代理可能需要冗余地存储同一条消息;或者等所有消费者都消费完才删除,这就需要消息代理跟踪每个消费者的消费状态,这种设计很大程度上限制了消息系统的整体吞吐量和处理延迟。Kafka的做法是生产者发布的所有消息会一直保存在Kafka集群中,不管消息有没有被消费。用户可以通过设置保留时间来清理过期的数据,比如,设置保留策略为两天。那么,在消息发布之后,它可以被不同的消费者消费,在两天之后,过期的消息就会自动清理掉。
3.3、分布式模型
Kafka每个主题的多个分区日志分布式地存储在Kafka集群上,同时为了故障容错,每个分区都会以副本的方式复制到多个消息代理节点上。其中一个节点会作为主副本(Leader),其他节点作为备份副本(Follower,也叫作从副本)。主副本会负责所有的客户端读写操作,备份副本仅仅从主副本同步数据。当主副本出现故障时,备份副本中的一个副本会被选择为新的主副本。因为每个分区的副本中只有主副本接受读写,所以每个服务端都会作为某些分区的主副本,以及另外一些分区的备份副本,这样Kafka集群的所有服务端整体上对客户端是负载均衡的。
Kafka的生产者和消费者相对于服务端而言都是客户端,生产者客户端发布消息到服务端的指定主题,会指定消息所属的分区。生产者发布消息时根据消息是否有键,采用不同的分区策略。消息没有键时,通过轮询方式进行客户端负载均衡;消息有键时,根据分区语义确保相同键的消息总是发送到同一个分区。
Kafka的消费者通过订阅主题来消费消息,并且每个消费者都会设置一个消费组名称。因为生产者发布到主题的每一条消息都只会发送给消费组的一个消费者。所以,如果要实现传统消息系统的“队列”模型,可以让每个消费者都拥有相同的消费组名称,这样消息就会负载均衡到所有的消费者;如果要实现“发布-订阅”模型,则每个消费者的消费组名称都不相同,这样每条消息就会广播给所有的消费者。
分区是消费者线程模型的最小并行单位。如图所示,生产者发布消息到一台服务器的3个分区时,只有一个消费者消费所有的3个分区。在图中,3个分区分布在3台服务器上,同时有3个消费者分别消费不同的分区。假设每个服务器的吞吐量是300MB,在图中分摊到每个分区只有100MB,而在图中集群整体的吞吐量有900MB。可以看到,增加服务器节点会提升集群的性能,增加消费者数量会提升处理性能。

同一个消费组下多个消费者互相协调消费工作,Kafka会将所有的分区平均地分配给所有的消费者实例,这样每个消费者都可以分配到数量均等的分区。Kafka的消费组管理协议会动态地维护消费组的成员列表,当一个新消费者加入消费组,或者有消费者离开消费组,都会触发再平衡操作。
Kafka的消费者消费消息时,只保证在一个分区内消息的完全有序性,并不保证同一个主题中多个分区的消息顺序。而且,消费者读取一个分区消息的顺序和生产者写入到这个分区的顺序是一致的。比如,生产者写入“hello”和“kafka”两条消息到分区P1,则消费者读取到的顺序也一定是“hello”和“kafka”。如果业务上需要保证所有消息完全一致,只能通过设置一个分区完成,但这种做法的缺点是最多只能有一个消费者进行消费。一般来说,只需要保证每个分区的有序性,再对消息加上键来保证相同键的所有消息落入同一个分区,就可以满足绝大多数的应用。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
