1、基本概念
重做日志记录了事务的行为,可以很好地通过其对页进行“重做”操作。但是事务有时还需要进行回滚操作,这时就需要undo。因此在对数据库进行修改时, InnoDB存储引擎不但会产生redo,还会产生一定量的undo。这样如果用户执行的事务或语句由于某种原因失败了,又或者用户用一条 ROLLBACK语句请求回滚,就可以利用这些undo信息将数据回滚到修改之前的样子。
redo存放在重做日志文件中,与redo不同,undo存放在数据库内部的一个特殊段(segment)中,这个段称为undo段(undo segment)。undo段位于共享表空间内。
用户通常对undo有这样的误解:undo用于将数据库物理地恢复到执行语句或事务之前的样子——但事实并非如此。undo是逻辑日志,因此只是将数据库逻辑地恢复到原来的样子。所有修改都被逻辑地取消了,但是数据结构和页本身在回滚之后可能大不相同。这是因为在多用户并发系统中,可能会有数十、数百甚至数千个并发事务。数据库的主要任务就是协调对数据记录的并发访问。比如,一个事务在修改当前一个页中某几条记录,同时还有别的事务在对同一个页中另几条记录进行修改。因此,不能将一个页回滚到事务开始的样子,因为这样会影响其他事务正在进行的工作。
例如,用户执行了一个INSERT10W条记录的事务,这个事务会导致分配一个新的段,即表空间会增大。在用户执行 ROLLBACK时,会将插入的事务进行回滚,但是表空间的大小并不会因此而收缩。因此,当 InnoDB存储引擎回滚时,它实际上做的是与先前相反的工作。对于每个INSERT, InnoDB存储引擎会完成一个DELETE;对于每个DELETE, InnoDB存储引擎会执行一个 INSERT:对于每个UPDATE, InnoDB存储引擎会执行一个相反的UPDATE,将修改前的行放回去。
除了回滚操作,undo的另一个作用是MVCC,即在 InnoDB存储引擎中MVCC的实现是通过undo来完成。当用户读取一行记录时,若该记录已经被其他事务占用,当前事务可以通过undo读取之前的行版本信息,以此实现非锁定读取。
最后也是最为重要的一点是, undo log会产生redo log,也就是undo log的产生会伴随着 redo log的产生,这是因为undo log也需要持久性的保护。
2、undo存储管理
InnoDB存储引擎对undo的管理同样采用段的方式。但是这个段和之前介绍的段有所不同。首先 InnoDB存储引擎有rollback segment,每个回滚段种记录了1024个undo log segment,而在每个 undo log segment段中进行undo页的申请。共享表空间偏移量为5的页(0,5)记录了所有 rollback segment header所在的页,这个页的类型为FIL_PAGE_TYPE_SYS。
在 InnoDB1.1版本之前(不包括1.1版本),只有一个 rollback segment,因此支持同时在线的事务限制为1024。虽然对绝大多数的应用来说都已经够用,但不管怎么说这是个瓶颈。从1.2版本开始 InnoDB支持最大128个rollback segment,故其支持同时在线的事务限制提高到了128*1024。
虽然InnoDB1.2版本支持了128个rollback segment,但是这些rollback segment都存储于共享表空间中。从InnoDB1.2版本开始,可通过参数对rollback segment做进一步的设置。这些参数包括:
- innodb_undo_directory
- innodb_undo_logs
- innodb_undo_tablespaces
参数innodb_undo_directory用于设置rollback segment文件所在的路径。这意味着rollback segment可以存放在共享表空间以外的位置,即可以设置为独立表空间。该参数的默认值为“.”,表示当前 InnoDB存储引擎的目录。
参数innodb_undo_logs用来设置rollback segment的个数,默认值为128。在 InnoDB1.2版本中,该参数用来替换之前版本的参数 innodb_rollback_segments。
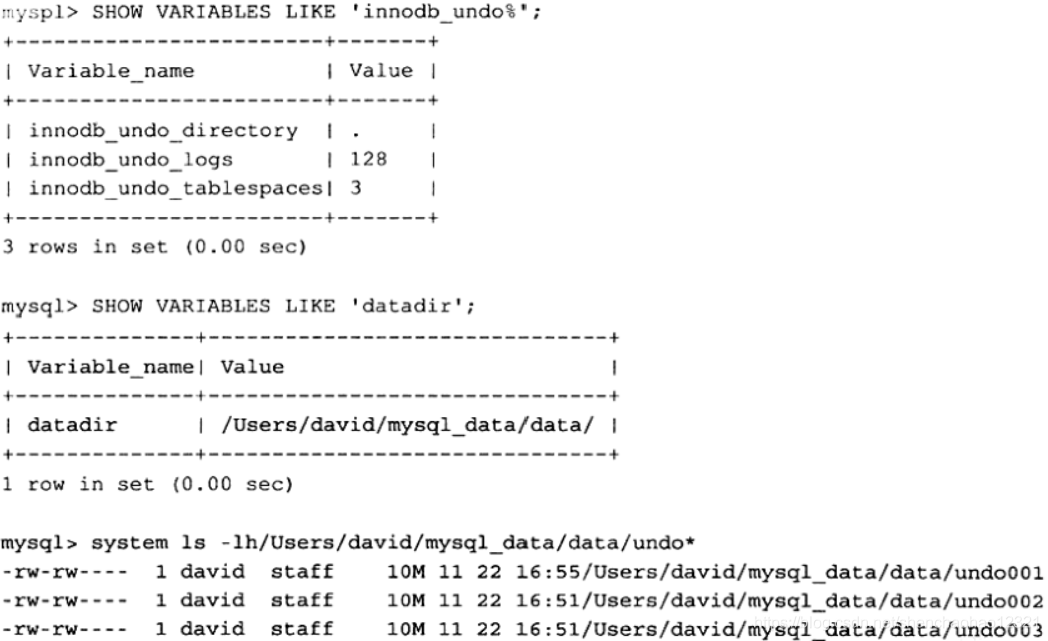
参数innodb_undo_tablespaces用来设置构成 rollback segment文件的数量,这样 rollback segment可以较为平均地分布在多个文件中。设置该参数后,会在路径innodb_undo_directory看到undo为前缀的文件,该文件就代表 rollback segment文件。下图的示例
显示了由3个文件组成的 rollback segment:
需要特别注意的是,事务在 undo log segment分配页并写入undo log的这个过程同样需要写入重做日志。当事务提交时, InnoDB存储引擎会做以下两件事情:
- 将undo log放入列表中,以供之后的 purge操作
- 判断undo log所在的页是否可以重用,若可以分配给下个事务使用
事务提交后并不能马上删除undo log及undo log所在的页。这是因为可能还有其他事务需要通过undo log来得到行记录之前的版本。故事务提交时将undo log放入一个链表中,是否可以最终删除undo log及undo log所在页由purge线程来判断。
此外,若为每一个事务分配一个单独的undo页会非常浪费存储空间,特别是对于OLTP的应用类型。因为在事务提交时,可能并不能马上释放页。假设某应用的删除和更新操作的TPS(transaction per second)为1000,为每个事务分配一个undo页,那么一分钟就需要1000*60个页,大约需要的存储空间为1GB。若每秒的 purge页的数量为20,这样的设计对磁盘空间有着相当高的要求。因此,在InnoDB存储引擎的设计中对undo页可以进行重用。
具体来说,当事务提交时,首先将 undo log放入链表中,然后判断udo页的使用空间是否小于3/4,若是则表示该undo页可以被重用,之后新的 undo log记录在当前 undo log的后面。
由于存放 undo log的列表是以记录进行组织的,而undo页可能存放着不同事务的 undo log,因此 purge操作需要涉及磁盘的离散读取操作,是一个比较缓慢的过程。
可以通过命令 SHOW ENGINE INNODB STATUS来查看链表中 undo log的数量,如
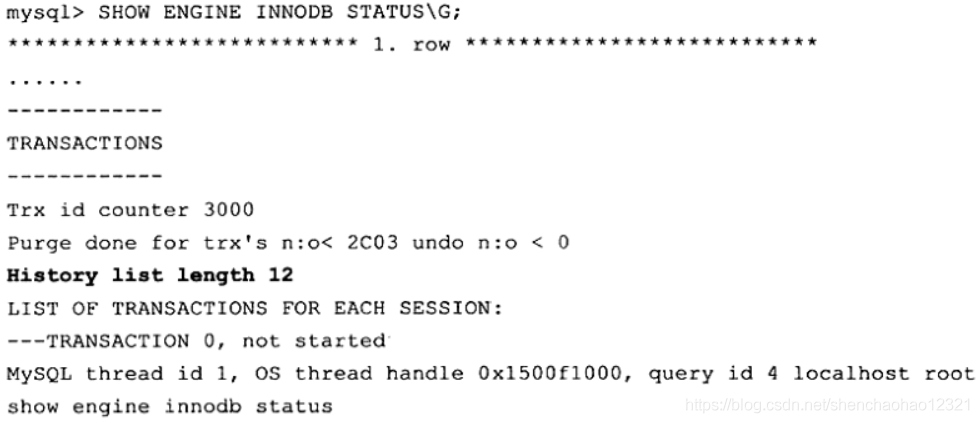
History list length就代表了 undo log的数量,这里为12。 purge操作会减少该值。然而由于 undo log所在的页可以被重用,因此即使操作发生, History list length的值也可以不为0。
3、undo log格式
在 InnoDB存储引擎中, undo log分为
- Insert undo log
- update undo log
insert undo log是指在 Insert操作中产生的 undo log。因为 Insert操作的记录,只对事务本身可见,对其他事务不可见(这是事务隔离性的要求),故该 undo log可以在事务提交后直接删除。不需要进行 purge操作。 insert undo log的格式如图7-14所示。
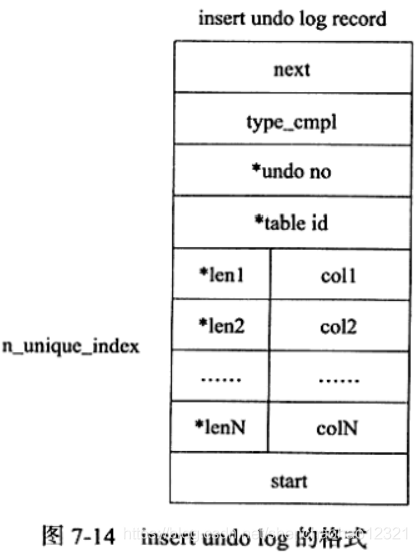
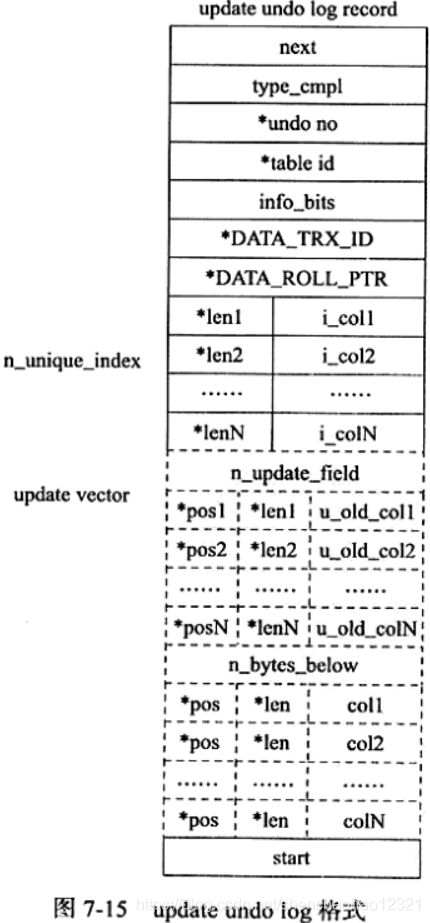
图7-14显示了 insert undo log的格式,其中为表示对存储的字段进行了压缩 insert undo log开始的前两个字节next记录的是下一个 undo log的位置,通过该next的字节可以知道一个 undo log所占的空间字节数。类似地,尾部的两个字节记录的是 undo log的开始位置。 type_cmpl占用一个字节,记录的是undo的类型,对于 insert undo log,该值总是为11。undo no记录事务的ID, table id记录undo log所对应的表对象。这两个值都是在压缩后保存的。接着的部分记录了所有主键的列和值。在进行 rollback操作时,根据这些值可以定位到具体的记录,然后进行删除即可。
update undo log记录的是对 delete和 update操作产生的 undo log。该undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,等待 purge线程进行最后的删除。 update undo log的结构如图7-15所示。
update undo log相对于之前介绍的 insert undo log,记录的内容更多,所需点用的空间也更大。next、start、undo no、table id与之前介绍的 insert undo log部分相同。这里的 type cmpl由于 update undo log本身还有分类,故其可能的值如下:
- 12 TRX_UNDO_UPD_EXIST_REC 更新non-delete-mark的记录
- 13 TRX_UNDO_UPD_DEL_REC 将 delete的记录标记为not delete
- 14 TRX_UNDO_DEL_MARK_REC 将记录标记为delete
接着的部分记录 update vector信息, update vector表示 update操作导致发生改变的列。每个修改的列信息都要记录的undo log中。对于不同的 undo log类型,可能还需要记录对索引列所做的修改。
delete操作并不直接删除记录,而只是将记录标记为已删除,也就是将记录的 delete flag设置为1。而记录最终的删除是在 purge操作中完成的。
update主键的操作其实分两步完成。首先将原主键记录标记为已删除,因此需要产生一个类型为TRX_UNDO_DEL_MARK_REC的undo log,之后插入一条新的记录,因此需要产生一个类型为TRX_UNDO_INSERT_REC的 undo log。
4、查看undo信息
Oracle和Microsoft SQL Server数据库都由内部的数据字典来观察当前undo的信息,InnoDB存储引擎在这方面做得还不够,DBA只能通过原理和经验来进行判断。 InnoSQL对 information schema进行了扩展,添加了两张数据字典表,这样用户可以非常方便和快捷地查看undo的信息。
首先增加的数据字典表为 INNODB_TRX_ROLLBACK_SEGMENT。顾名思义,这个数据字典表用来查看rollback segment,其表结构如下所示。
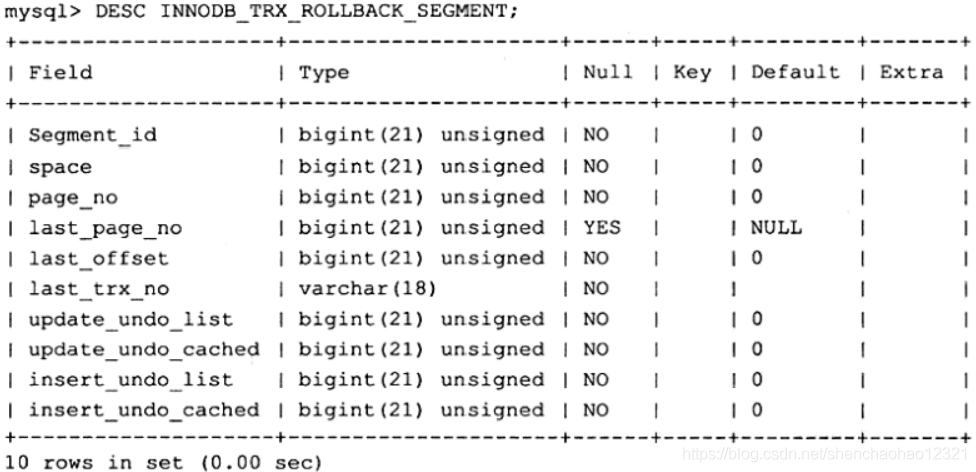
另一张数据字典表为 INNODB_TRX_UNDO,用来记录事务对应的 undo log,方便DBA和开发人员详细了解每个事务产生的undo量。
注意: mysql5.6和5.7 的 information_schema 数据库中不存在表INNODB_TRX_ROLLBACK_SEGMENT,和INNODB_TRX_UNDO。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
