文件系统(三)—老祖宗长的什么样
文件系统已经发展的如此完善,同时文件系统的代码也越来越复杂,我们通过前面两章大致知道了可以如何去设计一个文件系统,所以我们有必要去了解一下linux文件系统的老祖宗长的什么样。一方面,我们可以通过这个可以了解文件系统最初的样子,更加加深的理解文件系统的理念和基础概念;另外一方面是现代的文件系统都比较庞大,不容易理解,而老的文件系统才几千行代码,理解起来比较容易。
1 minix文件系统
当编写原始Linux内核,Linus Torvalds需要一个文件系统,但是不想开发它。因此他简单的使用了Minix文件系统,这是 Andrew S. Tanenbaum开发的,而且是Tanenbaum 的Minix操作系统的一部分。Minix是类Unix操作系统,为教育使用而开发。它的代码开放使用,而且合理的授权给Torvalds,允许他将它用于Linux的初代版本。首先我们可能想知道Ext4的老祖宗到底是谁,我们知道Linux操作系统是参考MINIX操作系统写的。
minix文件系统与标准的UNIX文件系统基本相同,它由6个部分组成,对于一个360K的软盘,其各部分的分布如下图所示
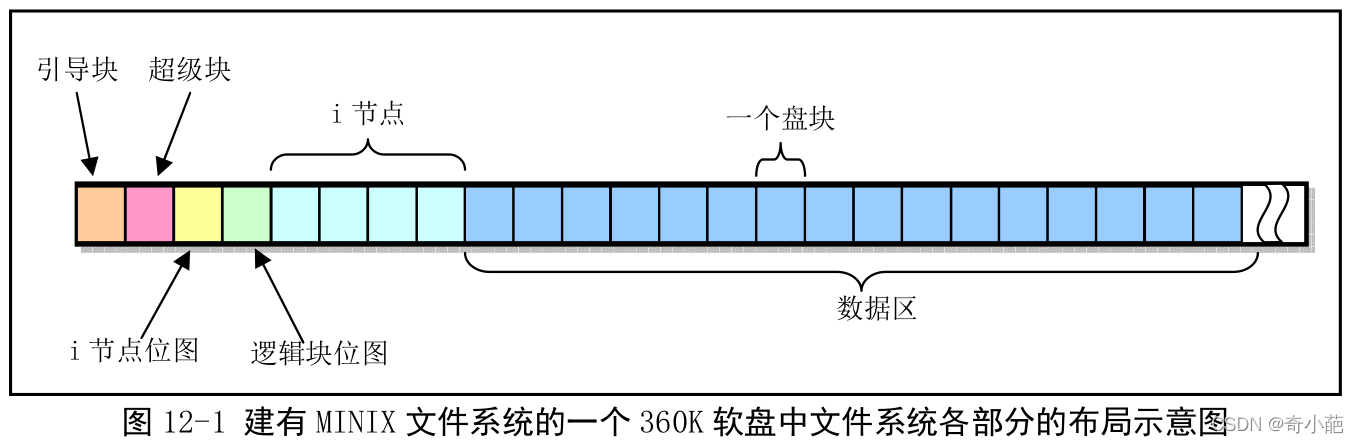
图中,整个磁盘块被划分为以1KB为单位的磁盘块,因此上图中共有360个磁盘块,每个方格表示一个磁盘块。
-
引导块: 是计算机加电启动时可由ROM BOIS自动读入的执行代码和数据,但并非所有盘都用于引导设备,所以对于不用于引导的盘片,这一盘块中可以不含代码。但是任何盘片必须含有引导空间,以保持MINIX文件系统的格式统一。
-
超级块: 用于存放盘设备省文件系统结构的信息,并说明各部分的大小,其数据结构如下

为什么要分内存段和磁盘段呢?
对于文件系统,本应该磁盘中存储这些数据结构就够了,但是操作系统为了更快更好的管理文件系统,便用 以空间换时间的 思想来操作数据。
从超级块的数据结构中,我们可以看出,逻辑块位图最多使用8块缓冲区(s_zmap[8]),而每块缓冲区大小是1024字节,每比特表示一个盘块的占用状态,因此一个缓冲区可代表8192个盘块。8个缓冲区块总共可表示65536个盘块,因此MINIX文件系统1.0所能支持的最大块设备容量64M。
- 逻辑块位图: 用于描述盘上每个数据盘块的使用情况,除了第一个比特位(位0)以外,逻辑块位图中每个比特位依次代表盘上数据区中的一个逻辑块。
逻辑块位图的比特位1代表盘上数据区中的第一个数据盘块,而非盘上的第一个磁盘块(引导块)。当一个数据盘块被占用时,则逻辑块位图中相应的比特位被置位。由于当所有磁盘数据盘块都被占用时查找空闲盘块的函数会返回0值,所以逻辑块位图最低比特位(位0)闲置不用,并且在创建文件系统时,会预先将其设置为1 - inode节点位图: 用于说明i节点是否被使用,同样是每个比特位代表一个i节点,对于1K大小的盘片来说,一个盘片可表示8192个i节点的使用状况。
与逻辑块位图情况类似,由于当所有的i节点都被使用时查找空闲的i节点的函数会返回0值,因此i节点位图的第1个字节的最低比特位(位0)和对应的i节点都闲置不用,并且在创建文件系统时,会预先将i节点0对应比特位图中的比特位置为1,因此第一个i节点位图块中只能表示8191个i节点的状况 - i节点: 存放着文件系统中文件或目录名的索引节点,每个文件或目录名都有一个i节点,每个i节点结构中存放着对应文件的相关信息。
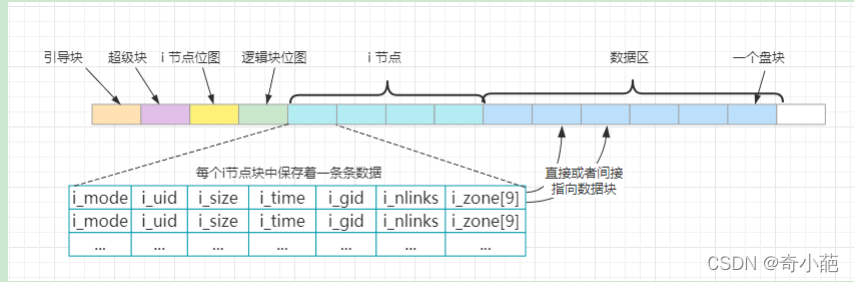

文件中的数据是放在磁盘块的数据区中,而一个文件名则通过对应的i节点与这些数据磁盘块相联系,这些盘块的号码就存放在i节点的逻辑块组i_zone[],这个数组用于存放i节点对应文件的盘块号。
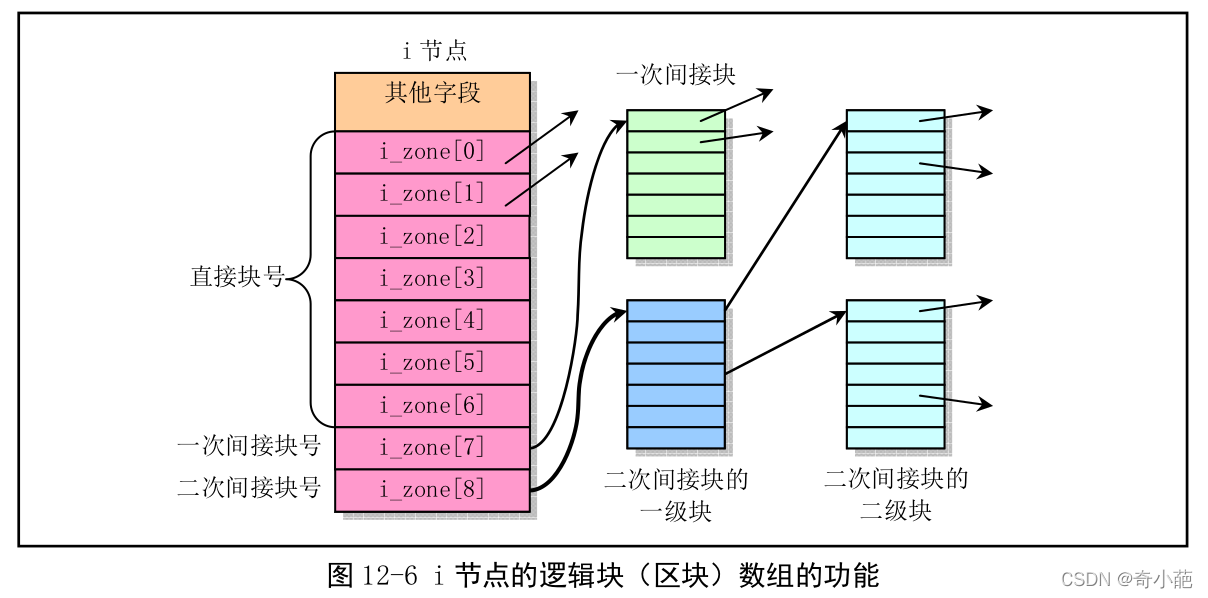
- i_zone[0]到i_zone[6]用于存放文件开始的7个磁盘块号,称为直接块。如果文件长度小于等于7K字节,则根据其i节点可以很快就找到它所使用的盘块。
- 如果文件大一些,则需要用到一级间接块(i_zone[7]),这个盘块中存放着附加的盘块号,对于MINIX文件系统它可以存放512个盘块号,因此可以寻址512个盘块。
- 如果文件还要大一些,则需要使用到二级间接块(i_zone[8]),二级间接块的作用类似一级间接盘块,因此使用可以寻址512*512个盘块
所以对于MINIX文件系统来说,一个文件的最大长度为(7+512+512*512) = 262,663KB
对于/dev目录下的设备文件来说,它们并不用占用磁盘数据中的数据盘块,即它们文件的长度为0,设备文件名的i节点用于保存其所定义的设备属性和设备号。
下面以具体的例子来说明一个minix文件系统的细节:
- 首先我们在ubuntu系统里面构建一个minix文件系统的镜像
dd if=/dev/zero of=minix.img bs=1K count=360
记录了360+0 的读入
记录了360+0 的写出
368640 bytes (369 kB, 360 KiB) copied, 0.00125697 s, 293 MB/s
mkfs.minix minix.img
128 个 inode
360 个块
首个数据区=8 (8)
区大小=1024
最大尺寸=268966912
我们构建了一个minix.img镜像文件,这个镜像文件格式化成minix文件系统。大小为360k,从输出信息可以知道,有些数据在格式化之后,就确定下来,比如:
(1)总共128个i节点
(2)总共360个块
(3)第一个数据区编号为8
(4)zone的大小是1024字节
(5)文件最大尺寸是268966912
- 挂载这个镜像文件,然后人为生成一些文件和目录
mkdir mnt
sudo mount minix.img -o loop mnt
tree
.
├── bb.txt
└── mydir
└── aaa.txt
1 directory, 2 files
mnt$ cat bb.txt
bbb
mnt$ cat mydir/aaa.txt
aaa
- 查看minix.img镜像里面的数据,输出如下:
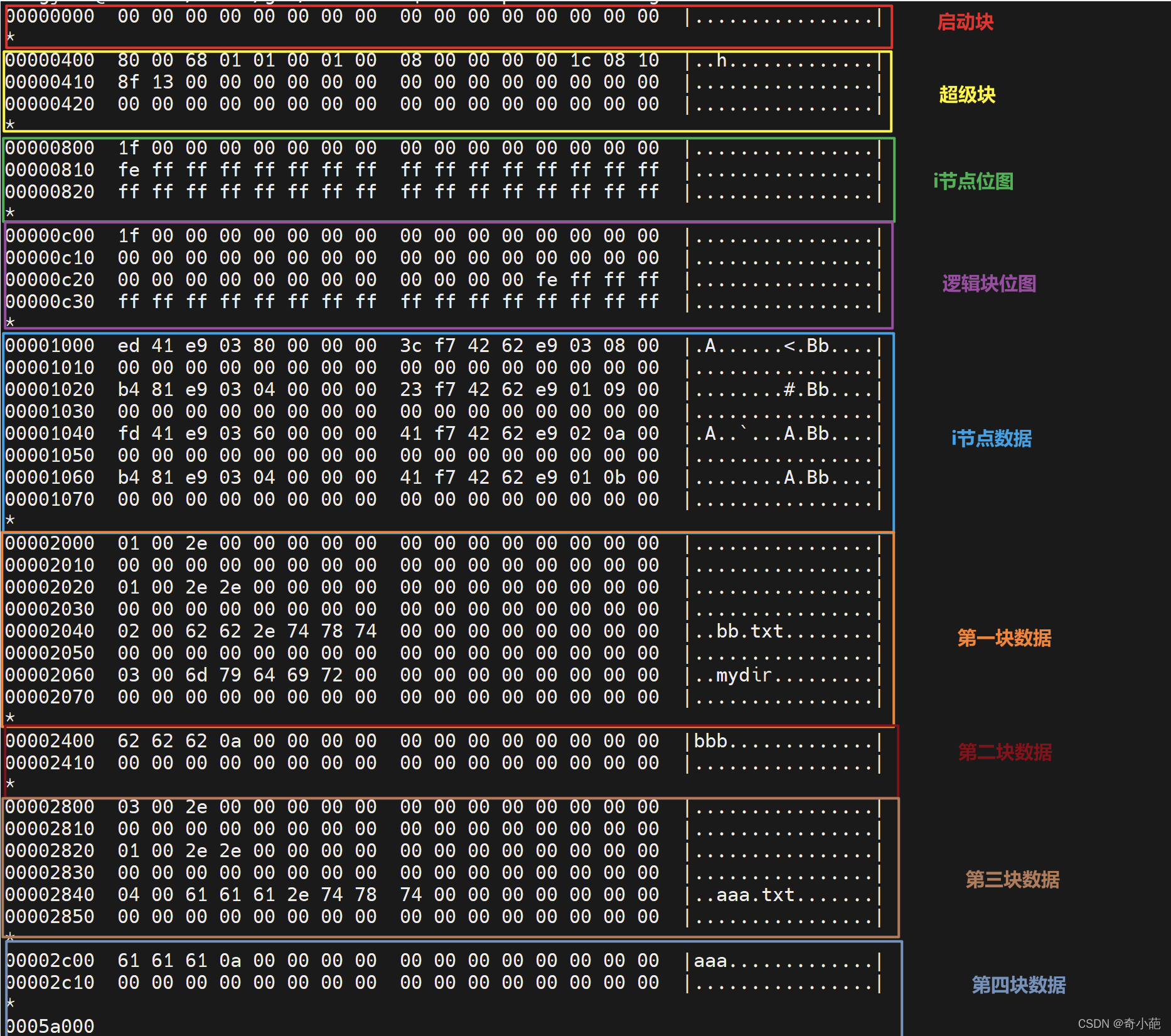
- 对比引导块,我们发现这个1K的数据区都是0,所以没有使用引导块,保留
- 对比超级块,对应超级块的结构体和字段数据如下,超级块是整个文件系统的入口,里面包含inode数量、数据块数量、zone大小和第一个zone的位置等。
struct d_super_block {
unsigned short s_ninodes; //0x0080,十进制128,inode总共128个
unsigned short s_nzones; //0x0168,十进制360,总共360个zone
unsigned short s_imap_blocks; //0x0001,十进制1,inode位图占1个块
unsigned short s_zmap_blocks; //0x0001,十进制1,zone位图占1个块
unsigned short s_firstdatazone;//0x0008,十进制8,第一个数据区编号是8
unsigned short s_log_zone_size;//0x0000,log表示的一块数据大小,1kb
unsigned long s_max_size; //0x10081c00,十进制268966912,最大文件长度
unsigned short s_magic; //0x138f,minix魔数
};
以上才多少字节,肯定不能完全占用1k啊,但是规定就是这样,就算不能占用所有1k空间,也给你留着,以备不时之需。可以看到,没有用到数据区全部为0。
- 对比i节点位图, 一个比特位0/1表示一个i节点是否被使用。
00000800 1f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000810 fe ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
00000820 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
我们看到前面16个字节,第一个字节是0x1f=0b00011111,后面15个字节都是0。16个字节刚好等于128位,由超级块可知,总共有128个i节点。第一个位图不用,但是置为1,这样一算,是不是少了一位了,只有127位。我们看到后面有一个0xfe,这里还有一位是0,加上之前16字节里面的127位,刚好是128个位。
- 对比数据区块位图
00000c00 1f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000c10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000c20 00 00 00 00 00 00 00 00 00 00 00 00 fe ff ff ff |................|
00000c30 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
以上从0x1f到0xfe,出去第一位不用,刚好352个位图。这个应该是数据区块的位图占用记录,而第一个数据区从8开始。
- 对比i节点数据
minix使用32字节的结构表示一个i节点的数据,其结构体如下:
struct m_inode {
unsigned short i_mode; //0x41ed,040755, 目录文件, rwxr-xr-x
unsigned short i_uid; //0x03e8, 1000
unsigned long i_size; //0x00000080, 128
unsigned long i_mtime; //0x5cb93ad2
unsigned char i_gid; //0xe8
unsigned char i_nlinks; //0x03
unsigned short i_zone[9]; //0x08,i_zone[0]=8,数据块在第8号区块
};
- 对比数据区: 第一块数据区,实际上是根目录的数据区,根目录的数据区里面存放的是目录项,每个目录项,minix2.0是32位,minix1.0是16位。一个目录项表示一个目录或者文件,其中2字节表示这个目录或者文件的inode节点序号,剩下的字节用于存放文件名字符串。其中第一个目录项表示’.‘,第二个表示’…',第三个表示mydir目录项也。如果是普通文件的数据区,则直接存放文件内容,具体在什么数据区由i节点数据表示
2 文件系统目录项结构
linux 0.11系统采用的是MINIX文件系统1.0版,它的目录结构和目录项结构与传统的UNIX文件目录项结构相同,定义在include/linux/fs.h中
#define NAME_LEN 14 // 名字长度值。
#define ROOT_INO 1 // 根i 节点。
// 文件目录项结构。
struct dir_entry
{
unsigned short inode; // i 节点。
char name[NAME_LEN]; // 文件名。
};
每个目录项只包括一个长度为14字节的文件名字符串和该文件名对应的2字节的i节点号,因此一个逻辑磁盘块可以存放1024/16=64个目录项。有关文件的其他信息则被保存在该i节点指定的i节点结构中,主要包括文件访问属性、宿主、长度、访问保存时间以及所在的磁盘块等信息。每个i节点号的i节点都位于磁盘上的固定位置处。
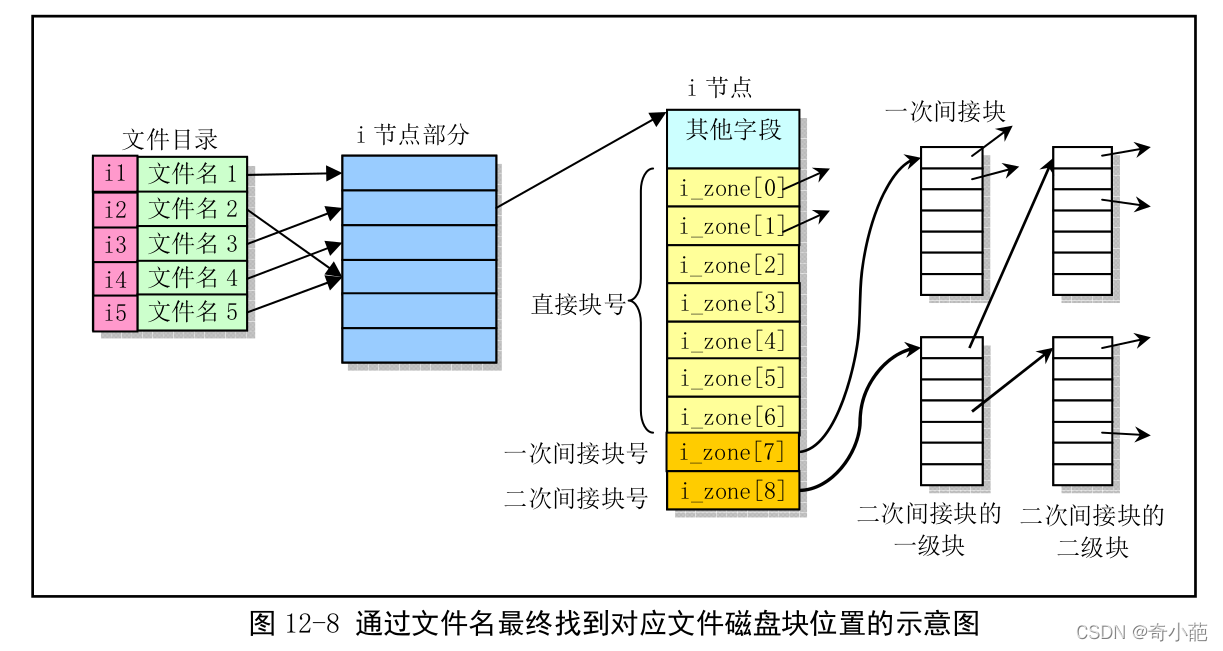
- 在打开一个文件时,文件系统会根据给定的文件名找到i节点号,从而通过其对应的i节点信息找到文件系统所在的磁盘块位置
- 对于要查找文件名/usr/bin/vi的i节点号,文件系统首先会从具有固定i节点号(1)的根目录开始操作,即从i节点号1的数据块中查找到对应的usr目录项,从而得到文件/usr的i节点号;根据该i节点号文件系统可以顺利取得目录/usr,并在其中找到文件名bin的目录项,这样也就知道了/usr/bin的i节点,因而我们可以直到目录/usr/bin的目录所在的位置,并在该目录中找到vi文件的目录项,最终获取文件路径名为/usr/bin/vi的i节点号,从而可以从磁盘上得到该i节点号的i节点结构信息。
如果从一个文件在磁盘上的分布来看,对于某个文件数据块信息的寻找过程可用下图表示(其中 未画出引导块、超级块、i 节点和逻辑块位图)。
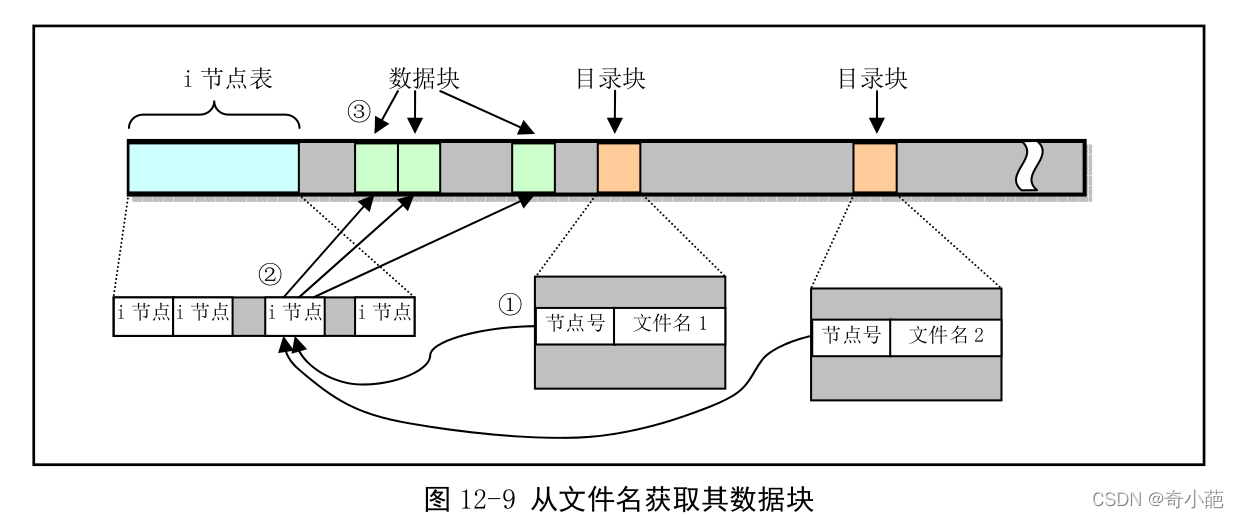
例如我们想在当前目录中创建一个名为mydir的子目录,那么在当前目录和该子目录中的链接示意图为
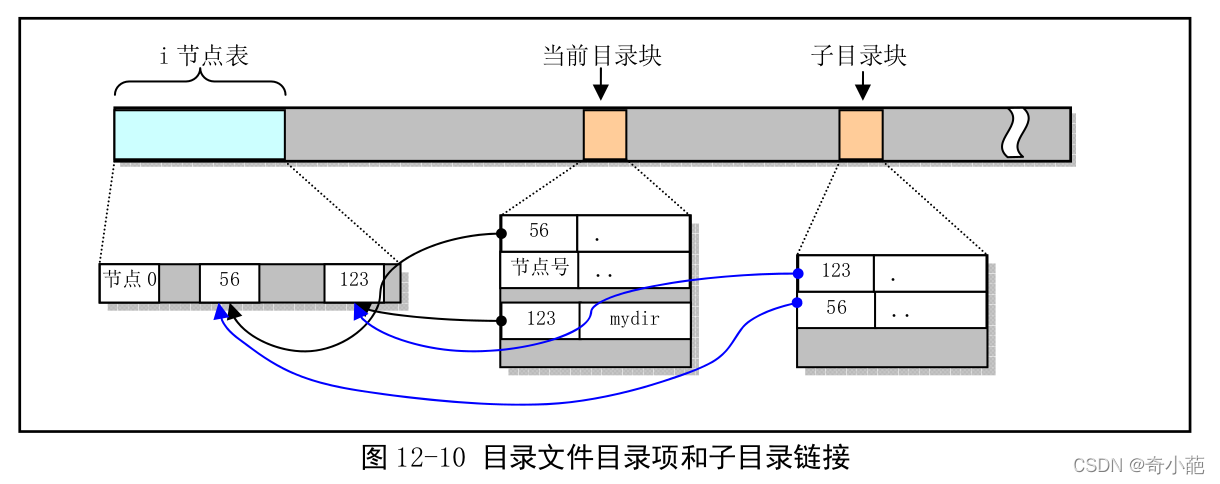
我们在 i 节点号为 56 的目录中建立了一个 mydir 子目录,该子目录的 i 节点号是 123。
在 mydir 子目录中的’.‘目录项指向自己的 i 节点 123,而其’…'目录项则指向其父目录的 i 节点 56。可见,由于一个目录的目录项本身总是会有两个链接,若其中再包含子目录,那么父目录的 i 节点链接数就等于 2+子目录数。
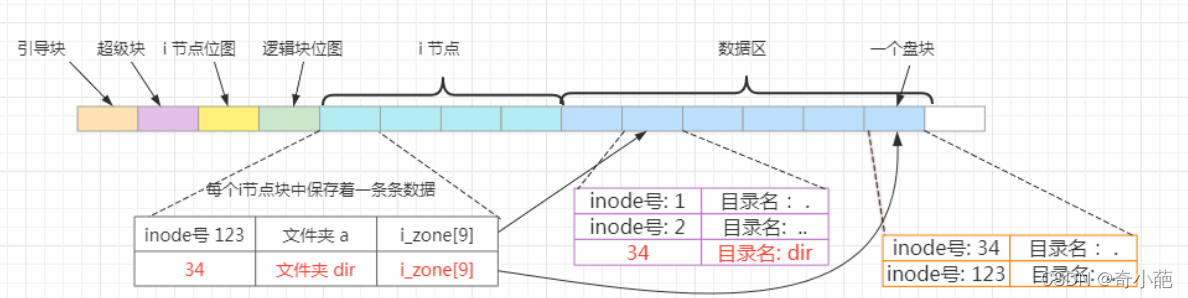
比如,在文件夹a下创建一个文件夹dir,其流程如下:
- 首先在a的i_zone[]所有的数据块中遍历,查找有没有存在名字为dir的目录项,如果存在,则返回文件已存在,结束;如果不存在则进行下一步
- 在i节点位图中查找一个bit位为0的空闲位,在对应的i节点中创建一条i节点记录,也即下图i节点的中的dir的i节点记录
- 为文件夹dir的i节点创建一个数据块,数据块中保存2个目录项,也就是.和…目录项,所以.的目录项中inode节点是指向自己的Inode节点,…的目录项中inode节点指向的时a的节点号
- 由于在a的目录下新增了一个文件夹dir,因此在a的目录数据块增加一条dir的目录项,当然dir的目录项中Inode号也就是自己的inode号
3 高速缓冲管理
为了访问块设备上文件系统中的,内核需要每次都访问块设备,进行读写操作。但是每次I/O操作的时间与内存和CPU处理速度相比是非常慢的,为了提高系统的性能,内核就在内存中开辟了一个高速数据缓存区(buffer Cache),将其划分成一个个与磁盘数据块大小相等的缓存块来使用和管理,以减小访问块设备的次数。
在linux内核中,高速缓冲区位于内核代码和主内存之间,如下图所示,高速缓冲区在块设备与内核其他程序之间起着一个桥梁作用。除了块设备驱动程序以外,内核程序如果需要访问块设备中的数据,就都需要经过高速缓冲区来间接地操作。
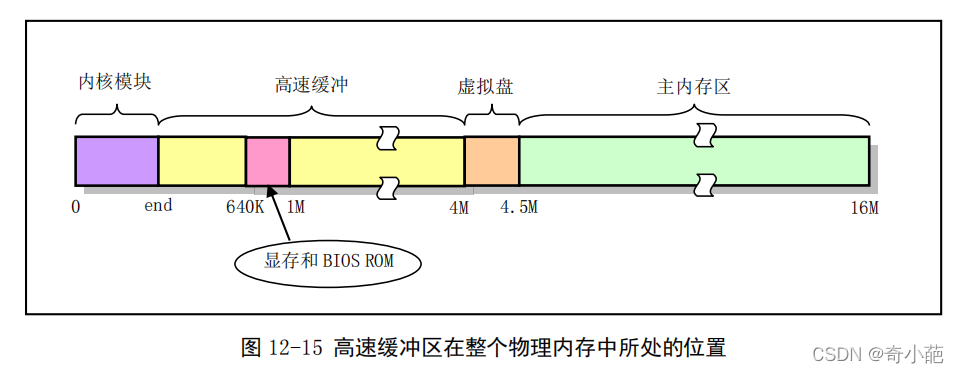
高速缓冲中存放着最近被使用过 的各个块设备中的数据块
- 当需要从块设备中读取数据时,缓存区管理程序首先会在高速缓冲区中寻找,如果响应数据已经在高速缓冲区,就无需再从块设备上读,如果数据不在高速缓冲区中,就发出读块设备的命令,将数据读到高速缓冲区中
- 当需要把数据写到块设备时,系统就会在高速缓冲区中申请一块空闲的缓冲块来临时存放这些数据,至于什么时候把数据真正写到设备上去,则是通过设备数据同步实现
3.1 初始化
整个高速缓冲区被划分成1024字节大小的缓存块,这正好与块设备上的磁盘逻辑块大小相同。高速缓冲采用hash表和包含所有缓冲块的链表进行操作管理。初始化程序从整个缓冲区的两端开始,分别同时设置缓冲块头结构和划分出对应的缓存块,如图所示
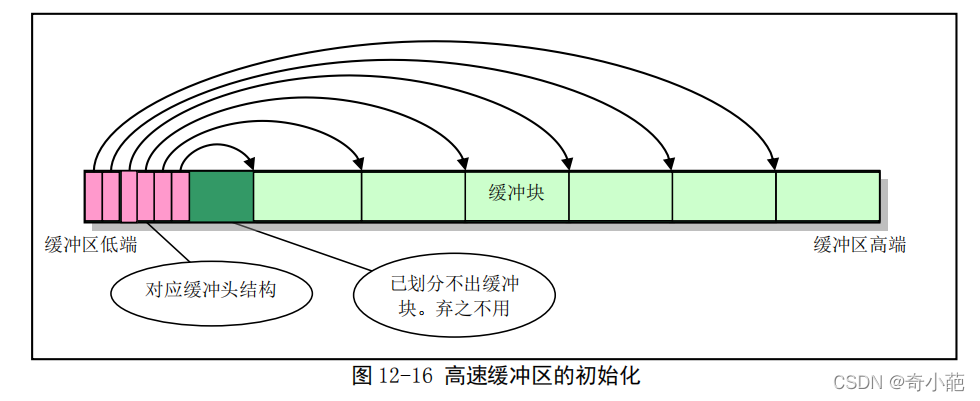
缓冲区的高端被划分成一个个1024字节的缓存块,低端则分别建立起对应各缓冲块的缓冲头结构buffer_head,该结构用于描述对应缓存块的属性,并用于把所有缓冲头连接成链表,划分操作一直持续到缓冲区中没有足够的内存再划分出缓存块为止。
3.2 高速缓冲区结构和链表
所有的缓冲块的buffer_head被链成一个双向链表结构,称为空闲链表
// 在程序中常用bh 来表示buffer_head 类型的缩写。
struct buffer_head
{
char *b_data; //指向缓存块中数据区(1024字节)的指针
unsigned long b_blocknr; // 块号/block number
unsigned short b_dev; // 数据源的设备号(0 = free)
unsigned char b_uptodate; // 更新标志:表示数据是否已更新。
unsigned char b_dirt; //修改标志:0 未修改,1 已修改.
unsigned char b_count; // 使用该块的用户数
unsigned char b_lock; // 缓冲区是否被锁定
struct task_struct *b_wait; // 指向等待该缓冲区解锁的任务。
struct buffer_head *b_prev; // hash 队列上前一块(这四个指针用于缓冲区的管理)。
struct buffer_head *b_next; // hash 队列上下一块。
struct buffer_head *b_prev_free; // 空闲表上前一块。
struct buffer_head *b_next_free; // 空闲表上下一块。
};
- 字段b_lock是锁定标志,用于驱动程序正在对该缓冲块内容进行修改,因此该缓冲块正处于忙状态而被锁定。该标志与缓冲块的其他标志无关,主要用于 blk_drv/ll_rw_block.c 程序中在更新缓冲块中数据信息时锁定缓冲块。因为在更新缓冲块中数据时,当前进程会自愿去睡眠等待,从而别的进程就有机会访问该缓冲块。因此,此时为了不让其他进程使用其中的数据就一定要在睡眠之前锁定缓冲块
- 字段b_count是缓存管理程序buffer使用的计数值,表示相应缓冲块正被各个进程使用(引用)的次数。当引用计数不为0时,缓存管理程序不能释放想用的缓存块。
- 字段b_dirt是脏标志位,说明缓存块内容是否已被修改而与块设备上的对应数据块内容不同。
- 字段b_uptodate是数据更新(有效)标志,说明缓存块中数据是否有效,初始化或释放块时,这两个标志位均设置为0,表明缓存块此时无效。当数据写入缓存块但还没有被写入设备时,则b_dirt = 1,b_uptodate = 0;当数据被写入缓存块或刚从块设备中读入缓存块则数据标称有效,即b_uptodate=1;当新申请一个设备缓存块时,b_dirt与b_uptodate都为1,表示缓存块中数据虽然与块设备上的不同,但是数据仍然是有效的(更新的)
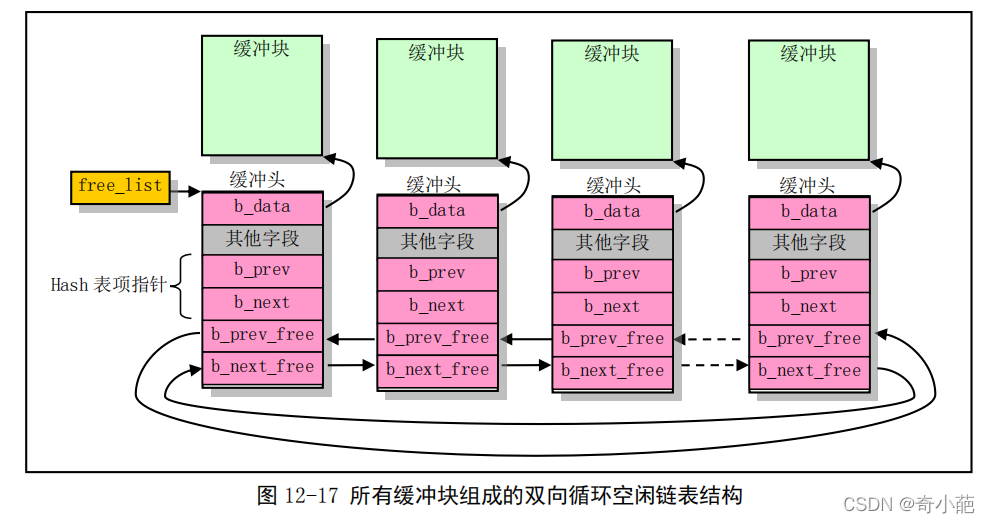
- 图中free_list指针释该链表的头指针,指向空闲块链表中第一个最为空闲的缓冲块,即近期最少使用的缓存块,而该缓冲块的反向指针b_prev_free则指向缓存块中的最后一个缓存块,即最近使用的缓存块。
- 图中缓存头结构“其他字段”包括块设备、缓冲数据逻辑块号,这两个字段唯一确定缓冲块中数据对应的块设备和数据块,另外还有几个标志位:数据有效标志、修改标志、数据被使用的进程数和被本缓存块是否上锁
内核程序使用高速缓冲区的缓存块,是制定设备号(dev)和所要访问设备数据的逻辑块(block),通过调用缓存块读取函数bread()、bread_page()或breada()进行操作。这几个函数都使用缓存区搜索管理函数getblk()用于在所有缓存块中寻找匹配或最为空闲的缓存块。所有这些缓冲块数据存取和管理函数的调用层次关系为

3.3 高速缓冲区的 Hash 表
为了能够快速而有效地在缓冲区中寻找判断出请求的数据块是否已经被读入到缓冲区中,内核使用了具有304个buffer_head指针项的hash数组表结构。hash表使用的散列函数由设备号和逻辑块号组成
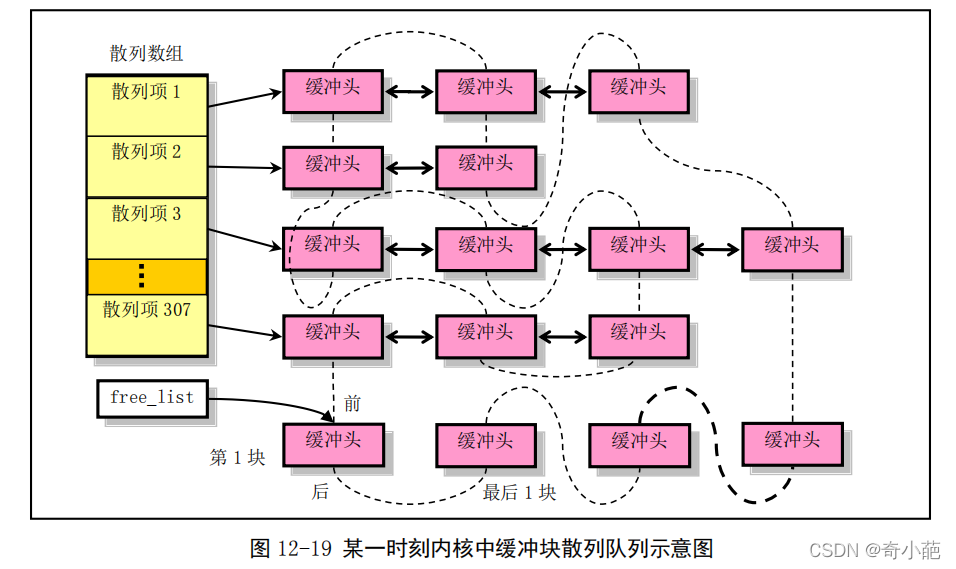
对于free_list指针指向的缓存头的链表中指针b_prev/b_next就是用于hash表中散列在同一个项上多个缓存块的双向链表,即把hash函数计算出具有相同散列值的缓存块链接在散列数组同一项链表上。
- 双向横线表示散列在同一hash表项中缓存块头结构之间的双向链表指针
- 虚线表示缓冲区中所有缓存块组成了一个双向链表,而free_list是该链表最为空闲的缓存块出的头指针,实际上这个双向链表是一个最近最少使用的LRU链表
对于高速缓冲区,最重要的是getblk()处理过程,函数在每次获取新的空闲缓冲块时,就会把它移到free_list头指针所指链表的最后面,即越靠近链表末端的缓冲块被使用的时间就越近,因此如果Hash表中没有找到对应缓存块,就会在搜索新的空闲缓存块时从free_list链表头开始,内核取得缓存块算法使用以下的策略
- 如果指定的缓存块在hash表中,则说明已经取得可用缓存块,于是直接返回
- 否则就需要从链表的free_list头指针开始搜索,即最近最少使用的缓存块开始,因此最理想的找到一个完全空闲的缓存块,即b_dirt和b_lock标志位均为0的缓存块;如果不能满足这两个条件,那么就需要根据b_dirt和b_lock的标志位计算出一个值,因为设备操作通常很耗时,所以在计算时需加大b_dirt的权重,然后我们在计算结果值最小的缓冲块等待,最后当标志位b_lock为0时,表示所等待的缓存块原内容已经写到设备上,就可以获得一个缓存块,如下所示
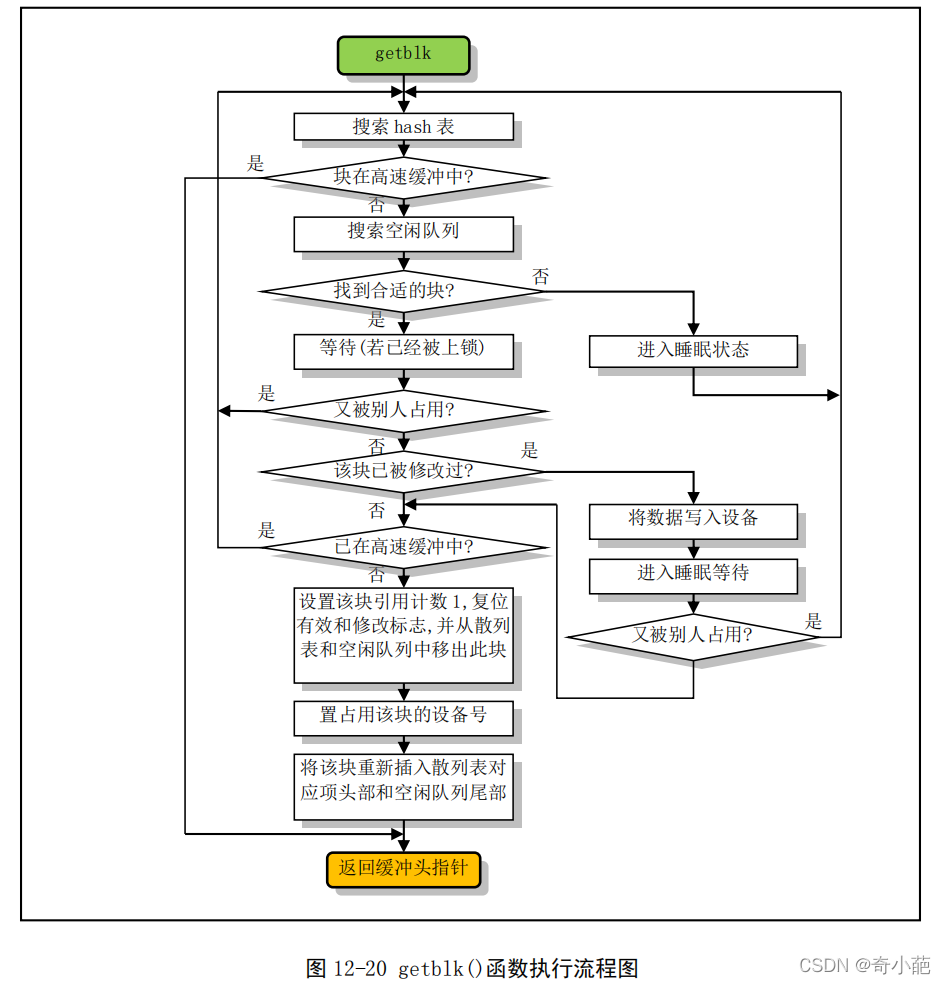
对于高速缓冲块读取函数,首先getblk()返回的缓存块可能是一个新的空闲块,也可能正好是含有我们需要数据的缓存块,它已经存在高速缓冲区中。因此对于读取数据块,此时要判断该缓冲块的更新标志,看看所含数据是否有效,如果有效就可以直接将该数据块返回给申请的程序。否则就需要调用设备的底层块读写函数(ll_rw_block),并同时让自己进入睡眠状态,等待数据被读入缓存块。
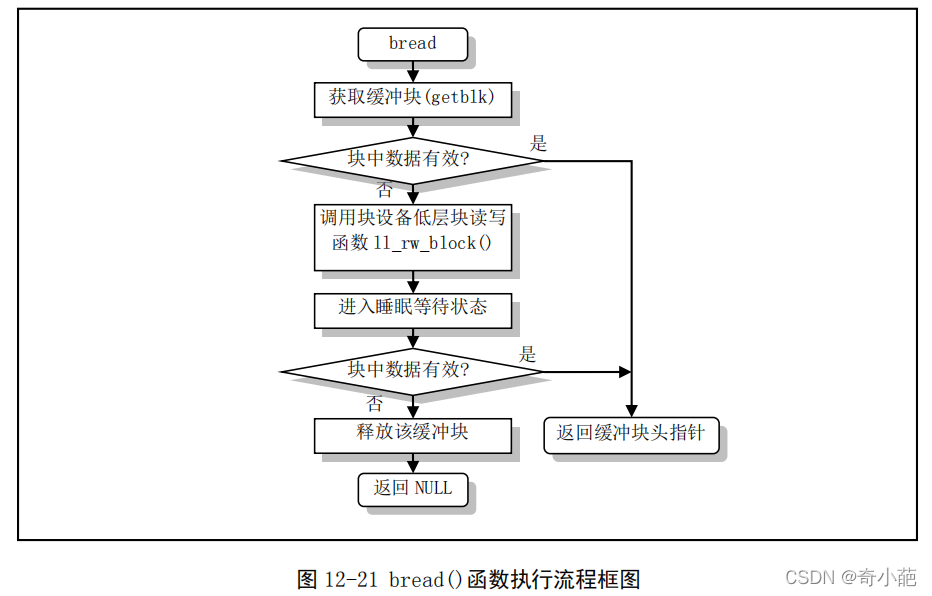
3.4 高速缓冲区访问过程和同步操作
除驱动程序外,内核其他的上层程序对块设备的读写操作都需要经过高速缓冲区管理程序来间接实现。对于上层要访问块设备数据,通过bread()向缓冲区管理程序申请,如果所需的数据已经在高速缓冲区中,管理程序就会将数据直接返回给程序;如果所需的数据暂时不在缓冲区,则管理程序通过ll_rw_block向块设备驱动程序申请,同时让程序对应的进程睡眠等待,等待块设备驱动程序把指定的数据放入高速缓存区,返回给上层应用
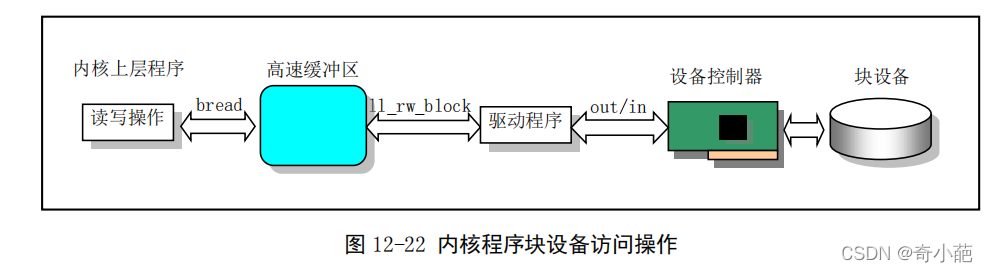
对于更新和同步的操作,其主要作用是让内存中的一些缓存块内容与磁盘等块设备上的信息一致。
sync_inodes主要是把i节点表的inode_table中的i节点信息与磁盘上的一致起来。
4 底层操作函数
这部分主要包括5个文件,分别是super.c、bitmap.c、truncate.c、inode.c和namei.c程序
4.1 bitmap.c
bitmap程序主要是用于根据文件系统中逻辑块和i节点结构的使用情况,对逻辑块位图和i节点位图分别进行比特位的占用和释放设置操作。
free_block用于释放指定设备dev上的数据区的逻辑块Block,具体操作是复位指定逻辑块block对应逻辑块位图的比特位,其实现比较简单
释放设备dev 上数据区中的逻辑块block。
// 复位指定逻辑块block 的逻辑块位图比特位。
// 参数:dev 是设备号,block 是逻辑块号(盘块号)。
void free_block(int dev, int block)
{
struct super_block * sb;
struct buffer_head * bh;
// 取指定设备dev 的超级块,如果指定设备不存在,则出错死机。
if (!(sb = get_super(dev)))
panic("trying to free block on nonexistent device");
// 若逻辑块号小于首个逻辑块号或者大于设备上总逻辑块数,则出错,死机。
if (block < sb->s_firstdatazone || block >= sb->s_nzones)
panic("trying to free block not in datazone");
// 从hash 表中寻找该块数据。若找到了则判断其有效性,并清已修改和更新标志,释放该数据块。
// 该段代码的主要用途是如果该逻辑块当前存在于高速缓冲中,就释放对应的缓冲块。
bh = get_hash_table(dev,block);
if (bh) {
if (bh->b_count != 1) {
printk("trying to free block (%04x:%d), count=%d\n",
dev,block,bh->b_count);
return;
}
bh->b_dirt=0; // 复位脏(已修改)标志位。
bh->b_uptodate=0; // 复位更新标志。
brelse(bh);
}
// 计算block 在数据区开始算起的数据逻辑块号(从1 开始计数)。然后对逻辑块(区块)位图进行操作,
// 复位对应的比特位。若对应比特位原来即是0,则出错,死机。
block -= sb->s_firstdatazone - 1 ;
if (clear_bit(block&8191,sb->s_zmap[block/8192]->b_data)) {
printk("block (%04x:%d) ",dev,block+sb->s_firstdatazone-1);
panic("free_block: bit already cleared");
}
// 置相应逻辑块位图所在缓冲区已修改标志。
sb->s_zmap[block/8192]->b_dirt = 1;
}
- 首先,取出指定设备dev的超级块,并根据超级块给出设备逻辑块的范围,判断逻辑块号block的有效性
- 然后再高速缓冲区中进行查找,看看指定的逻辑块此时是否正在高速缓冲区中。如果是,则将对应的缓冲块释放掉
- 接着计算Block从数据区开始算出数据块号(从1开始计算),并对逻辑块位图进行操作,并复位对应的Bit位,最后在包含相应逻辑块位图的缓存块中,根据逻辑块号设置已修改比特位标志
new_block用于向设备申请一个逻辑块,返回逻辑块号,并置位指定逻辑块block对应的逻辑块位图bit位。
向设备dev 申请一个逻辑块(盘块,区块)。返回逻辑块号(盘块号)。
// 置位指定逻辑块block 的逻辑块位图比特位。
int new_block(int dev)
{
struct buffer_head * bh;
struct super_block * sb;
int i,j;
// 从设备dev 取超级块,如果指定设备不存在,则出错死机。
if (!(sb = get_super(dev)))
panic("trying to get new block from nonexistant device");
// 扫描逻辑块位图,寻找首个0 比特位,寻找空闲逻辑块,获取放置该逻辑块的块号。
j = 8192;
for (i=0 ; i<8 ; i++)
if (bh=sb->s_zmap[i])
if ((j=find_first_zero(bh->b_data))<8192)
break;
// 如果全部扫描完还没找到(i>=8 或j>=8192)或者位图所在的缓冲块无效(bh=NULL)则返回0,
// 退出(没有空闲逻辑块)。
if (i>=8 || !bh || j>=8192)
return 0;
// 设置新逻辑块对应逻辑块位图中的比特位,若对应比特位已经置位,则出错,死机。
if (set_bit(j,bh->b_data))
panic("new_block: bit already set");
// 置对应缓冲区块的已修改标志。如果新逻辑块大于该设备上的总逻辑块数,则说明指定逻辑块在
// 对应设备上不存在。申请失败,返回0,退出。
bh->b_dirt = 1;
j += i*8192 + sb->s_firstdatazone-1;
if (j >= sb->s_nzones)
return 0;
// 读取设备上的该新逻辑块数据(验证)。如果失败则死机。
if (!(bh=getblk(dev,j)))
panic("new_block: cannot get block");
// 新块的引用计数应为1。否则死机。
if (bh->b_count != 1)
panic("new block: count is != 1");
// 将该新逻辑块清零,并置位更新标志和已修改标志。然后释放对应缓冲区,返回逻辑块号。
clear_block(bh->b_data);
bh->b_uptodate = 1;
bh->b_dirt = 1;
brelse(bh);
return j;
}
- 首先取指定设备dev的超级块,然后对整个逻辑块位图进行搜索,寻找首个是0的bit位,如果没有找到,则说明盘设备空间已经用完,返回0;否则将找到的第1个0值对应Bit位置1,表示占用对应的数据逻辑块,并将包含该比特位的逻辑位图所在缓冲区的已修改标志位置位
- 计算出数据逻辑块的盘块号,并在高速缓冲区中申请相应的缓存块,并把该缓冲块清0,然后设置该缓冲块已更新和已修改,最后释放该缓冲块,以便其他程序使用,并返回盘块号
函数free_inode()用于释放指定的i 节点,并复位对应的i 节点位图比特位;new_inode()
用于为设备dev建立一个新i 节点。返回该新i 节点的指针。主要操作过程是在内存i 节点表
中获取一个空闲i 节点表项,并从i 节点位图中找一个空闲i 节点。这两个函数的处理过程
与上述两个函数类似,因此这里就不用再赘述。
4.2 truncate.c
本程序主要用于释放指定i节点在设备上占用的所有逻辑块,包括直接块、一次间接块和二次间接块,从而将文件节点对应的文件长度截为0,并释放占用的设备空间。
将节点对应的文件长度截为0,并释放占用的设备空间。
void
truncate (struct m_inode *inode)
{
int i;
// 如果不是常规文件或者是目录文件,则返回。
if (!(S_ISREG (inode->i_mode) || S_ISDIR (inode->i_mode)))
return;
// 释放i 节点的7 个直接逻辑块,并将这7 个逻辑块项全置零。
for (i = 0; i < 7; i++)
if (inode->i_zone[i])
{ // 如果块号不为0,则释放之。
free_block (inode->i_dev, inode->i_zone[i]);
inode->i_zone[i] = 0;
}
free_ind (inode->i_dev, inode->i_zone[7]); // 释放一次间接块。
free_dind (inode->i_dev, inode->i_zone[8]); // 释放二次间接块。
inode->i_zone[7] = inode->i_zone[8] = 0; // 逻辑块项7、8 置零。
inode->i_size = 0; // 文件大小置零。
inode->i_dirt = 1; // 置节点已修改标志。
inode->i_mtime = inode->i_ctime = CURRENT_TIME; // 重置文件和节点修改时间为当前时间。
}
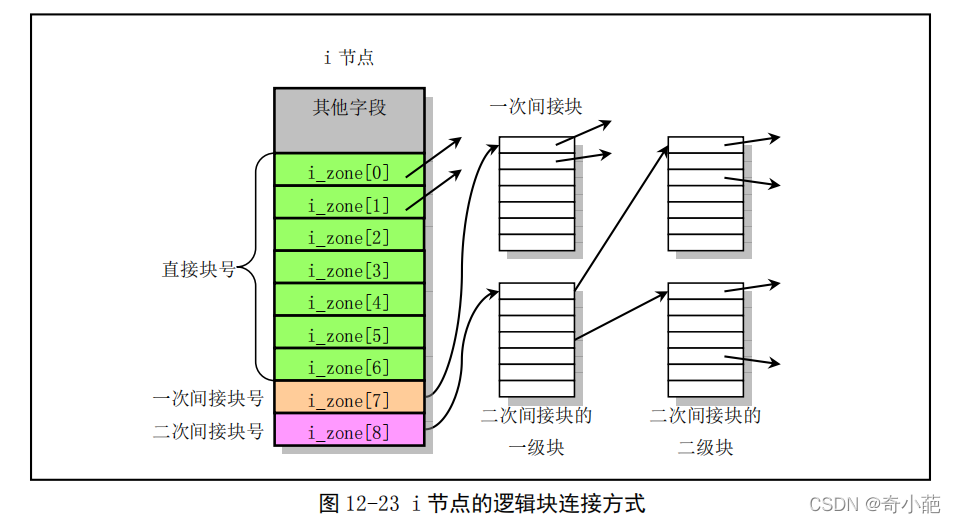
i 节点中 i_zone[]数组中存放着设备上逻辑块的盘块号码。该数组的前 7 项(i_zone[0]–i_zone[6])可
以直接存放着相关文件中前 7 个数据块盘块的号码。i_zone[7]存放一次间接块的盘块号。因为这里盘块大小为 1024 字节,因此每个盘块中可以存放(1024 / 2)= 512 个盘块号,也即一次间接块号最多可以寻址 512 个设备盘块。相应地,二次间接块号 i_zone[8]可以寻址(512 *512)= 261,144 个盘块号。
4.3 inode.c
该程序主要包括处理 i 节点的函数 iget()、iput()和块映射函数 bmap(),以及其他一些辅助函数。iget()、iput()和 bmap()函数主要用于 namei.c 程序的映射函数 namei()中,用于由文件路径名查找对应 i 节点。
-
iget(): 该函数用于从设备 dev 上读取指定节点号 nr 的 i 节点,并且把节点的引用计数字段值 i_count 增 1
-
iput(): 所完成的功能正好与 iget()相反。它主要用于把 i 节点引用计数值递减 1,并且若是管道 i
节点,则唤醒等待的进程。 -
bmap(): 用于把一个文件数据块映射到对应的盘块上,其主要是对i节点的逻辑块数组i_zone[]进行处理,并根据i_zone中所设置的逻辑块号来设置逻辑块位图的占用情况。
- i_zone[0]至 i_zone[6]用于存放对应文件的直接逻辑块号
- i_zone[7]用于存放一次间接逻辑块号;
- i_zone[8]用于存放二次间接逻辑块号
- 当文件较小时(小于 7K),就可以将文件所使用的盘块号直接存放在 i 节点的 7 个直接块项中;当文件稍大一些时(不超过 7K+512K),需要用到一次间接块项 i_zone[7];当文件更大时,就需要用到二次间接块项i_zone[8]了。因此,文件比较小时,linux 寻址盘块的速度就比较快一些。
4.4 super.c
该文件描述了对文件系统中超级块操作的函数,这些函数属于文件系统低层函数,供上层的文件名和目录操作函数使用,主要有 get_super()、put_super()和 read_super()函数。另外还有有关文件系统加载/卸载的系统调用 sys_umount()和 sys_mount(),以及根文件系统加载函数 mount_root()。其他一些辅助函数与 buffer.c 中的辅助函数的作用类似。
- get_super()函数用于在指定设备的条件下,在内存超级块数组中搜索对应的超级块,并返回相应超级块的指针。因此,在调用该函数时,该相应的文件系统必须已经被加(mount),或者起码该超级块已经占用了超级块数组中的一项,否则返回 NULL。
- put_super()用于释放指定设备的超级块。它把该超级块对应的文件系统的 i 节点位图和逻辑块位图所占用的缓冲块都释放掉,并释放超级块表(数组)super_block[]中对应的操作块项。在调用 umount()卸载一个文件系统或者更换磁盘时将会调用该函数。
- read_super()用于把指定设备的文件系统的超级块读入到缓冲区中,并登记到超级块表中,同时也把文件系统的 i 节点位图和逻辑块位图读入内存超级块结构的相应数组中。最后返回该超级块结构的指针。
- sys_umount()系统调用用于卸载一个指定设备文件名的文件系统,而 sys_mount()则用于往一个目录名上加载一个文件系统。程序中最后一个函数 mount_root()用于安装系统的根文件系统,并将在系统初始化时被调用
- mount_root()函数是在系统执行初始化程序 main.c 中,在进程 0 创建了第一个子进程(进程 1)后被调用的,而且系统仅在这里调用它一次。具体的调用位置是在初始化函数 init()的 setup()函数中
5 文件数据的访问操作
我们学习了底层的接口函数和原理,主要是为了提供上层应用的接口,由于linux0.11还没有虚拟文件系统的概念,其主要是通过如下框架
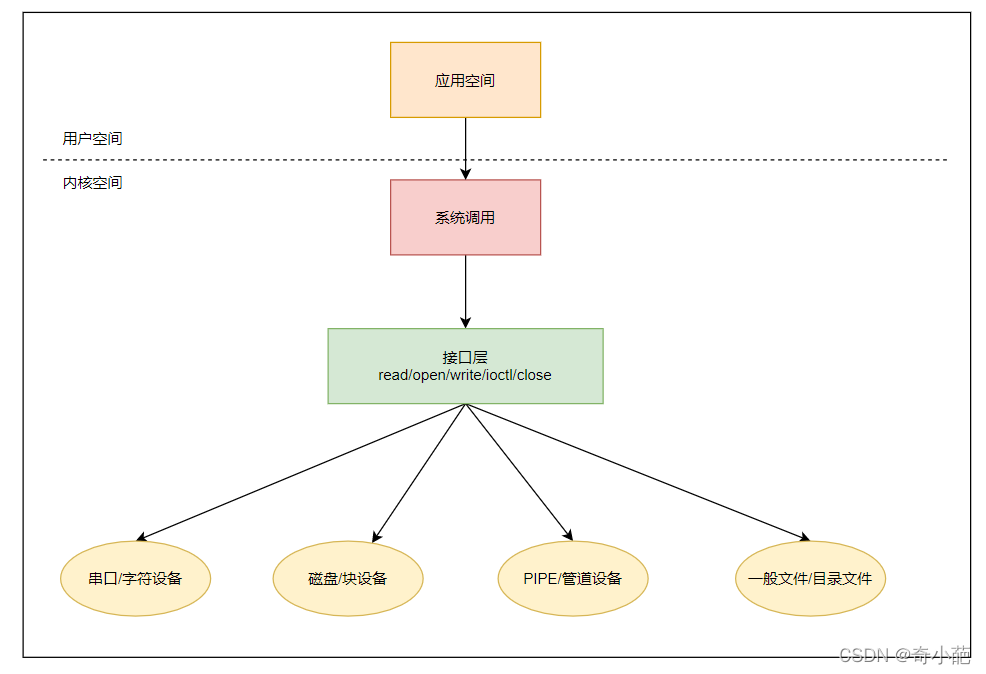
关于文件中数据的访问操作,主要涉及5个文件:blk_dev.c,file_dev.c,char_dev.c,pipe.c和read_write.c。前四个可以认为是块设备、普通文件、字符设备、管道设备与文件读写系统调用的接口程序, 它们共同实现了read_write.c 中的read()和write()系统调用。 通过对被操作文件属性的判断,这两个系统调用会分别调用这些文件中的相关处理函数进行操作。
- block_dev.c 中的函数 block_read()和block_write()是用于读写块设备特殊文件中的数据,使用的参数指定了 要访问的设备号、读写的起始位置和长度。
- file_dev.c 中的file_read()和file_write()函数是用来访问一般的正规文件,通过文件名获取对应的i节点号和文件信息,从而进行读写操作。
- pipe.c 管道主要用于在进程之间按照先进先出的方式传送数据,也可以用于使进程同步执行。
- 有名管道,是使用文件系统的open调用建立的
- 无名管道,使用系统调用 pipe()创建的
- char_dev.c 字符设备包括控制台终端(tty),串口终端(ttyx)和内存字符设备,对于字符设备文件,系统调用read()与write()会调用char_dev.c中的 rw_char() 函数来操作
我们以sys_write为例,就能很快 就明白了,这个是如何处理
int sys_write (unsigned int fd, char *buf, int count)
{
struct file *file;
struct m_inode *inode;
// 如果文件句柄值大于程序最多打开文件数NR_OPEN,或者需要写入的字节计数小于0,或者该句柄
// 的文件结构指针为空,则返回出错码并退出。
if (fd >= NR_OPEN || count < 0 || !(file = current->filp[fd]))
return -EINVAL;
// 若需读取的字节数count 等于0,则返回0,退出
if (!count)
return 0;
// 取文件对应的i 节点。若是管道文件,并且是写管道文件模式,则进行写管道操作,若成功则返回
// 写入的字节数,否则返回出错码,退出。
inode = file->f_inode;
if (inode->i_pipe)
return (file->f_mode & 2) ? write_pipe (inode, buf, count) : -EIO;
// 如果是字符型文件,则进行写字符设备操作,返回写入的字符数,退出。
if (S_ISCHR (inode->i_mode))
return rw_char (WRITE, inode->i_zone[0], buf, count, &file->f_pos);
// 如果是块设备文件,则进行块设备写操作,并返回写入的字节数,退出。
if (S_ISBLK (inode->i_mode))
return block_write (inode->i_zone[0], &file->f_pos, buf, count);
// 若是常规文件,则执行文件写操作,并返回写入的字节数,退出。
if (S_ISREG (inode->i_mode))
return file_write (inode, file, buf, count);
// 否则,显示对应节点的文件模式,返回出错码,退出。
printk ("(Write)inode->i_mode=%06o\n\r", inode->i_mode);
return -EINVAL;
}
5 总结
通过linux0.11的代码和原理,我们进一步熟悉了怎么去自己实现一个文件系统,如何提供给上层接口。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
