[TOC]
一、传统IO问题
传统的 IO 将一个文件通过 socket 写出
File f = new File("helloword/data.txt");
RandomAccessFile file = new RandomAccessFile(file, "r");
byte[] buf = new byte[(int)f.length()];
file.read(buf);
Socket socket = ...;
socket.getOutputStream().write(buf);
内部工作流程是这样的:
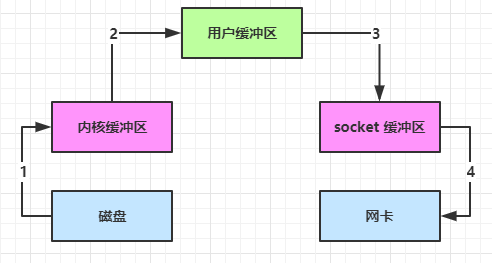
- java 本身并不具备 IO 读写能力,因此 read 方法调用后,要从 java 程序的 用户态 切换至 内核态 ,去调用操作系统(Kernel)的读能力,将数据读入 内核缓冲区 。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,其间也不会使用 cpu;
- 从 内核态 切换回 用户态 ,将数据从 内核缓冲区 读入 用户缓冲区 (即 byte[] buf),这期间 cpu 会参与拷贝,无法利用 DMA;
- 调用 write 方法,这时将数据从 用户缓冲区 (byte[] buf)写入 socket 缓冲区 ,cpu 会参与拷贝;
- 接下来要向网卡写数据,这项能力 java 又不具备,因此又得从 用户态 切换至 内核态 ,调用操作系统的写能力,使用 DMA 将 socket 缓冲区 的数据写入网卡,不会使用 cpu。
可以看到中间环节较多,java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的
- 用户态与内核态的切换发生了 3 次,这个操作比较重量级
- 数据拷贝了共 4 次
二、NIO 优化
2.1 优化一
通过 DirectByteBuf
- ByteBuffer.allocate(10) HeapByteBuffer 使用的还是 java 内存
- ByteBuffer.allocateDirect(10) DirectByteBuffer 使用的是操作系统内存
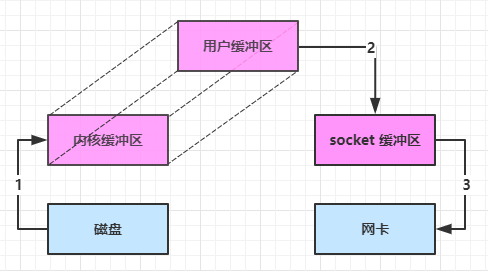
大部分步骤与优化前相同,不再赘述。唯有一点:java 可以使用 DirectByteBuf 将堆外内存映射到 jvm 内存中来直接访问使用
-
这块内存不受 jvm 垃圾回收的影响,因此内存地址固定,有助于 IO 读写
-
java 中的 DirectByteBuf 对象仅维护了此内存的虚引用,内存回收分成两步
- DirectByteBuf 对象被垃圾回收,将虚引用加入引用队列
- 通过专门线程访问引用队列,根据虚引用释放堆外内存
-
减少了一次数据拷贝,用户态与内核态的切换次数没有减少
2.2 优化二
进一步优化(底层采用了 linux 2.1 后提供的 sendFile 方法),java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据
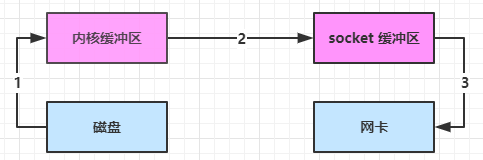
- java 调用 transferTo 方法后,要从 java 程序的 用户态 切换至 内核态 ,使用 DMA将数据读入 内核缓冲区 ,不会使用 cpu
- 数据从 内核缓冲区 传输到 socket 缓冲区 ,cpu 会参与拷贝
- 最后使用 DMA 将 socket 缓冲区 的数据写入网卡,不会使用 cpu
可以看到
- 只发生了一次用户态与内核态的切换
- 数据拷贝了 3 次
2.3 优化三
进一步优化(linux 2.4)
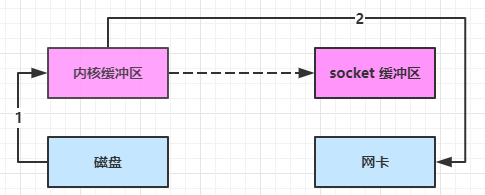
- java 调用 transferTo 方法后,要从 java 程序的 用户态 切换至 内核态 ,使用 DMA将数据读入 内核缓冲区 ,不会使用 cpu
- 只会将一些 offset 和 length 信息拷入 socket 缓冲区 ,几乎无消耗
- 使用 DMA 将 内核缓冲区 的数据写入网卡,不会使用 cpu
整个过程仅只发生了一次用户态与内核态的切换,数据拷贝了 2 次。
总结
所谓的【零拷贝】,并不是真正无拷贝,而是在不会拷贝重复数据到 jvm 内存中,零拷贝的优点有
- 更少的用户态与内核态的切换
- 不利用 cpu 计算,减少 cpu 缓存伪共享
- 零拷贝适合小文件传输
附参考原文:
《黑马程序员Netty教程》
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
