1 介绍
作者是互联网一线研发负责人,所在业务也是业内核心流量来源,经常参与 业务预定、积分竞拍、商品秒杀等工作。
近期参与多场新员工的面试工作,经常就 『超高并发场景下热点数据』 可用性保障与候选人进行讨论。
本文聚焦一些关键点技术进行讨论,并总结一些热点场景的处理经验。
2 业务基础架构简图(假设)
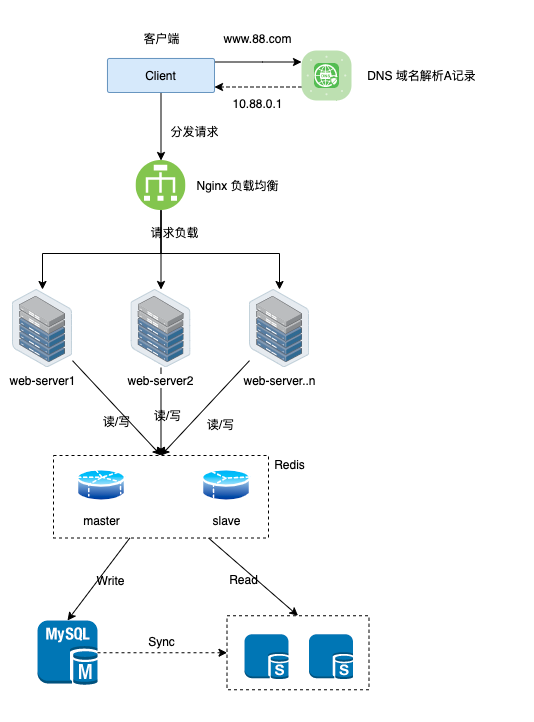
3 超高并发下热点数据的稳定性保障
3.1 命题背景
1000w+请求同时投向后端,如果缓存未建立、失效,甚至缓存服务故障,就会透过缓存层直接投向数据库。
可能会造成整体击穿/雪崩,怎么破?
3.2 各种业务场景及应对方案
3.2.1 规律性热点数据预热
无论是聚集式热key,还是散列式热key,只要是有一定规律性的,均可以做 预热。
既然是热Key,那就想办法尽可能让它不进入MySQL,就不会对数据库造成伤害,。
这种场景最常见的就是对一些字典数据做预热,因为他们不容易改变,修改频次较低,但又很容易在高峰期被群蜂请求(突发式的批量请求)。
电商领域比如: 商品种类、品牌类型、折扣规则。
办公/教学领域比如:学校、年段、班级、学科、考试科目等。
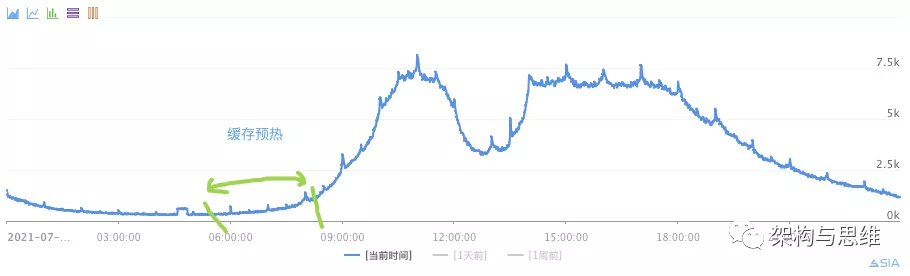
一般来说如果10点是峰值期,那么可以预先在8~10点期间,可以逐渐的把大部分缓存建立起来。如图:
3.2.2 非规律性热点数据预热
Redis + 应用层 加探测器,预判热Key,并将探测到的热Key进行预热。
1、baidu实时热搜

2. taobao商品排行
这种额外的开销就是有一个实时计算的独立组件,因为热点新闻、热点数据都有急剧突变的特性。比如weibo多次因为突发热点新闻导致网站崩溃。
3.2.3 破解过期时间一致性问题
缓存的建立过程都是散列的,但是如果长时间静待都会被逐渐释放。
比如钉钉、飞书的办公场景,遇到夜晚低峰期、周末节假日,缓存Key被逐步释放之后。很容易在第二个工作日的早高峰造成大量创建缓存,流量井喷。
解决方案除了前面我们提到的缓存预热之外,错峰过期时间也是常规操作。
可以给缓存设置过期时间时加上一个随机值时间,使得每个key的过期时间分布开来,不会集中在同一时刻失效。
随机值我们团队的做法是:n * 3/4 + n * random() 。所以,比如你原本计划对一个缓存建立的过期时间为8小时,那就是6小时 + 0~2小时的随机值。
这样保证了均匀分布在 6~8小时之间。如图:

3.2.4 过滤垃圾请求
一般情况下,我们取数先从缓存中Get Key,不存在的时候再从数据库中去获取,但这很容易给攻击者提供漏洞。
他可以疯狂模拟一些不存在的Key,让你进入数据库去取数,这样就可以拖垮你的数据库,实现击溃你系统的目的。
有效的办法是在服务层先判断这个Key的是否符合标准(比如滴滴的订单数据缓存包含时间戳+用户ID的序列化),这样可以过滤一部分无效攻击。
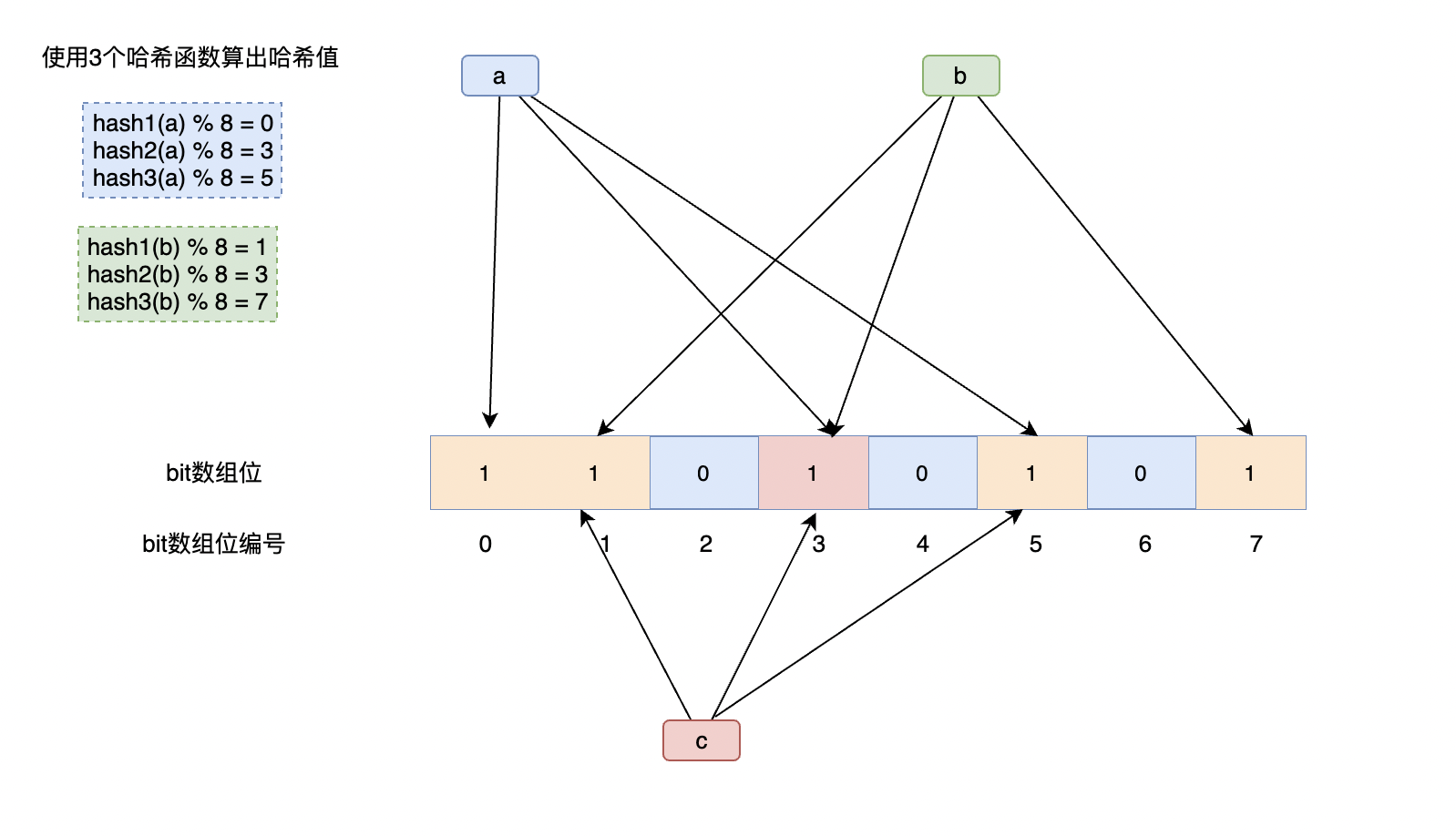
但是如果他能够破解你key的规则,依旧可以钻漏洞。你可以在缓存层上加一层过滤器,帮你Filter掉那些不合理的攻击。
详细可以参考我这篇《Redis系列16:聊聊布隆过滤器(原理篇) 》
3.2.5 消息队列和削峰
如果一个缓存不存在(不存在、过期、被误删都有可能),但是同时有千万请求投奔过来。
这时候关心是不是及时拿回正确数据已经不重要了,保住你的缓存和数据库不被击穿才是关键。
队列的目的是让并行变成串行,这一定程度上降低系统处理用户请求的吞吐能力,但是却能很好的缓解你服务的压力和风险。
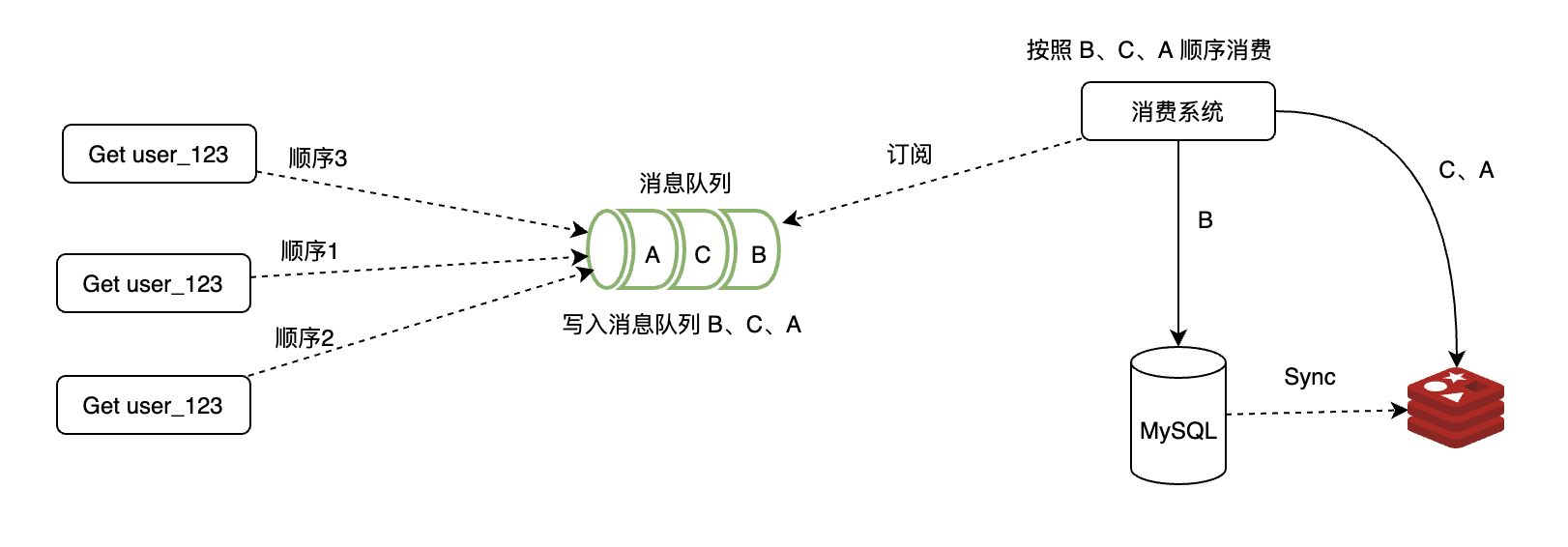
如上图:第一个请求B从数据库中取,后面的C、A就是从缓存服务中取了,压力变小很多。
3.2.6 适当加锁
分布式锁场景,在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key。
这种现象是多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
锁不好的地方就是在其他线程在拿不到锁的时候就等待,这个会造成系统整体吞吐量降低,用户体验度也不好。
这算是一种简单明了的降级策略了。
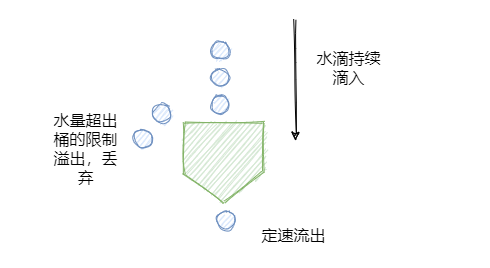
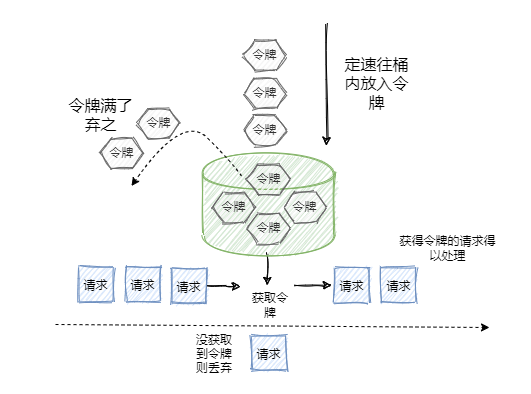
3.2.7 限流策略
一样是一种在流量井喷时保住服务不雪崩的有效方法,限流一般是从服务层去实现的。
Java服务的话可以使用 Hystrix进行限流 + 降级 ,比如一下子来了1W个请求,超过当前系统的吞吐承受能力,假设单秒TPS的能力只能是 5000个,那么剩余的 5000 请求就可以走限流逻辑。
可以设置一些默认值,然后调用我们自己降级逻辑去FallBack,保护最后的 MySQL 不会被大量的请求挂起。 除了Hystrix之外,阿里的Sentinel 和 Google的RateLimiter 都是不错的选择。
Sentinel 漏桶算法
RateLimiter 令牌桶算法
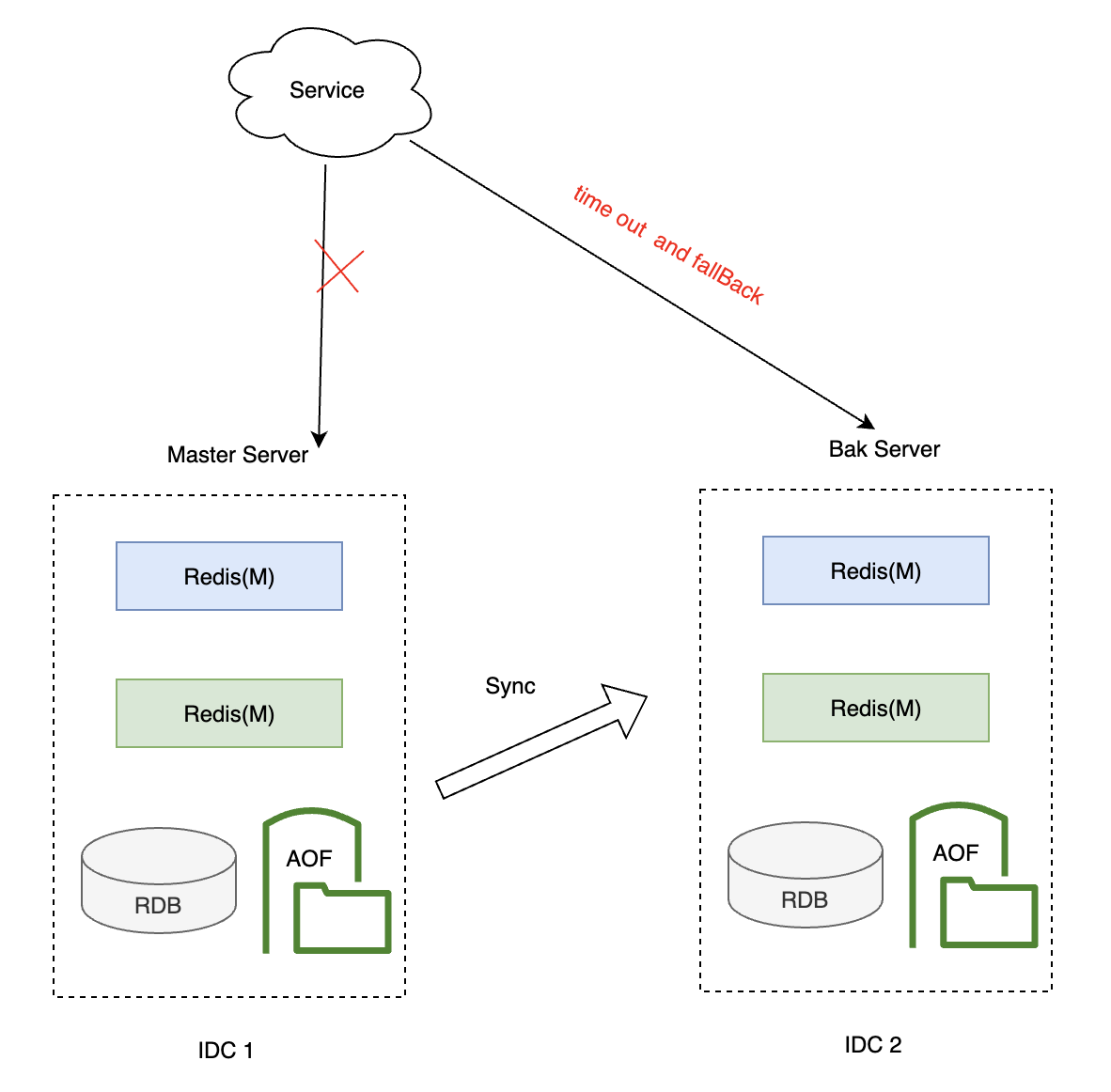
3.2.8 降级策略(备选缓存)
你的缓存层存在主备场景,他们之间定时异步同步,所以允许存在短暂数据不一致的情况。
当你的主服务挂了之后,降级去读备服务,数据时效性没那么高,但是也避免了数据库被打穿的情况发生。
3.2.9 降级策略(客户端缓存)
参考Redis 6.0的 Client Side Cache,看我这篇《追求性能极致:客户端缓存带来的革命》。
类似4.5做法,客户端缓存时效性会差一点,毕竟存在订阅跟同步的过程,数据没那么新。但是避免大量的请求直接上缓存服务,又因无效的缓存服务又把压力转移给数据库。
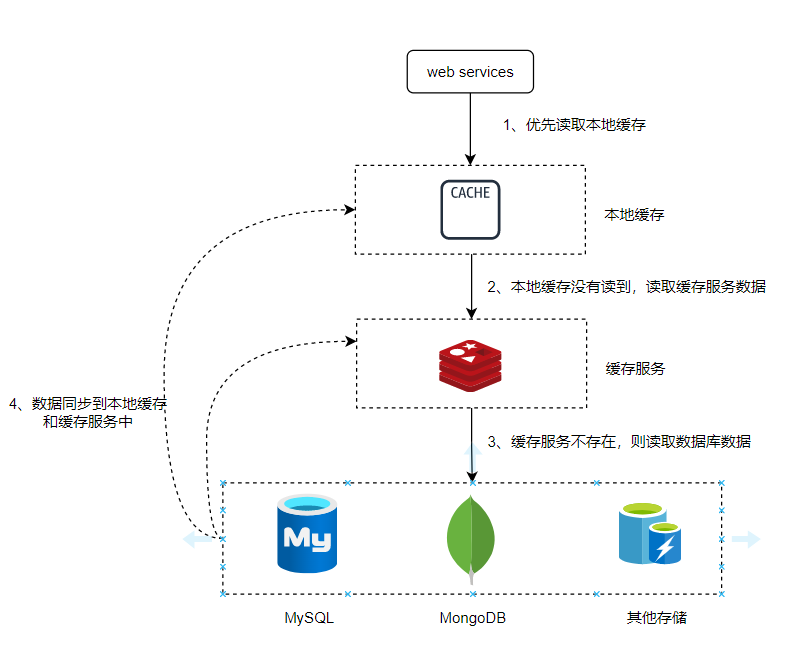
3.2.10 降级策略之空初始值
这是一种短效的降级方式:
如果一个缓存失效的时候,有无数个请求狂奔而来,而第一个请求从进入缓存池,判空,再到数据库检索,再查询出结果并返回设置缓存的这个过程里,缓存是不存在的。
这个就很危险,超高并发下这个短暂的过程足已让千千万万请求投向数据库。更别提这可能是个慢查询,整个过程可能长达2s以上,那对数据库是一种非常大的伤害。
业内有一种做法叫做空初始值,短暂的局部降级来保证整个数据库系统不被击穿。大概流程如下:
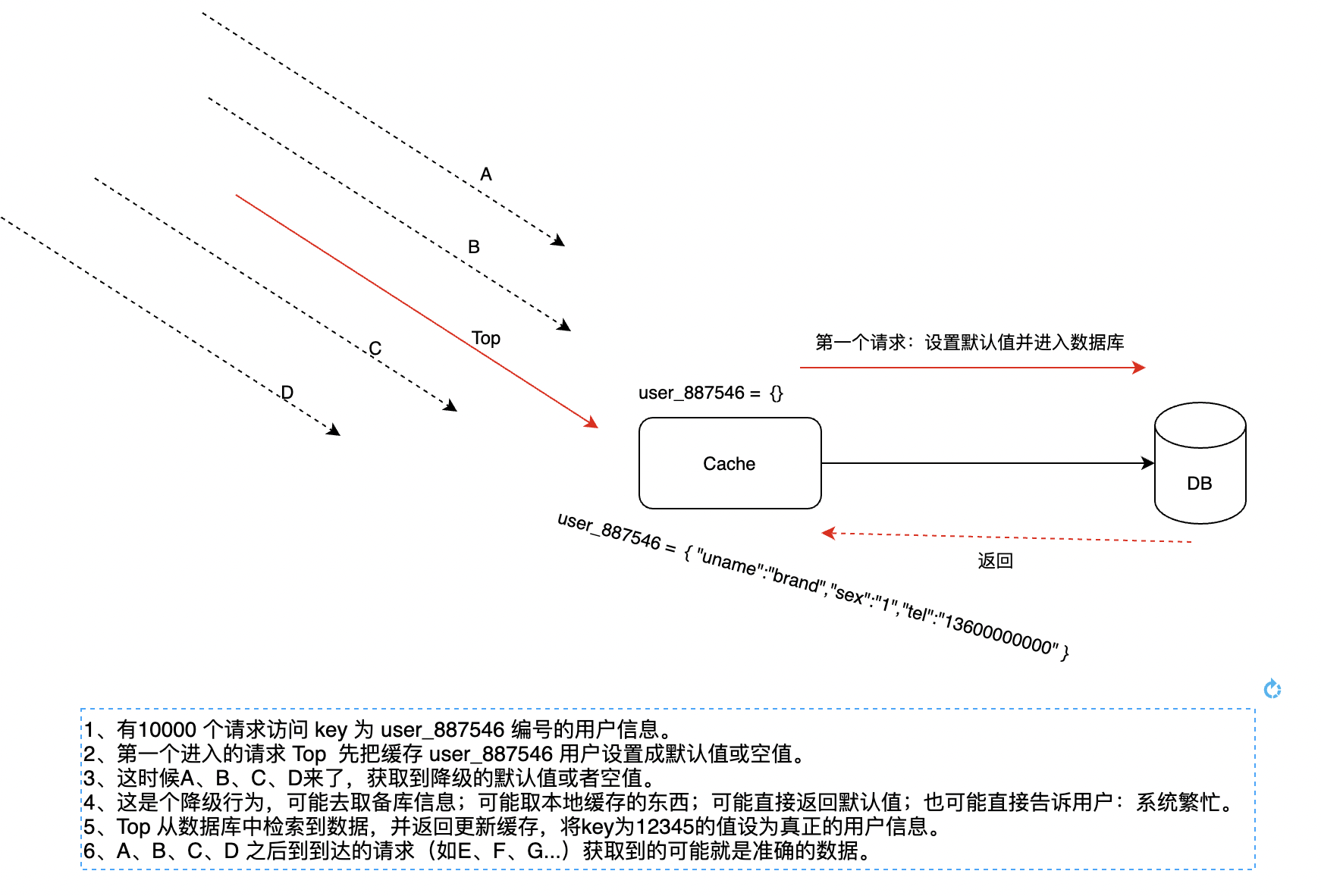
可以看出,整个过程中我们牺牲了A、B、C、D的请求,他们拿回了一个空值或者默认值,但是这局部的降级却保证整个数据库系统不被拥堵的请求击穿。
3.2.11 高可用集群和自动扩缩容
集群模式和自动扩缩容模式从服务到缓存到数据层都应该具备,否则无法根据流量来进行弹性伸缩,保持高可用。
如下图, 蓝色部件是扩容的部分,每一分层都有自己的动态扩容机制。
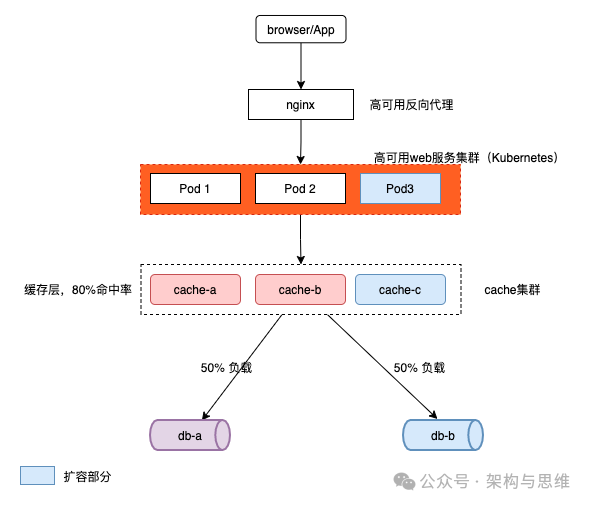
详细可以参考笔者这几篇文章。
《云原生:使用HPA和VPA实现集群扩缩容》
《数据库系列:数据库高可用及无损扩容》
3.2.12 雪崩之后的恢复
如果最终导致了缓存雪崩,那么重启后快速的数据恢复也是我们核心的目标。
刚刚恢复重启的缓存服务,这时候数据都是空的,大量的请求流量带来的缓存重建(进而拉动数据库流量)势必会带来压力甚至二次雪崩。
这时候最好的办法就是能够有工具进行缓存恢复,而不是从数据库中去获取数据来重建,这样的过程漫长而负重。
这块可以参考笔者的这两篇文章:
《Redis系列:RDB内存快照提供持久化能力》
《Redis稳定性之战:AOF日志支撑数据持久化 》
4 总结
扩展阅读:缓存雪崩、击穿、穿透
《架构与思维:一次缓存雪崩的灾难复盘 》
《架构与思维:再聊缓存击穿,面试是一场博弈》
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
