
概述
Byte(字节)是计算机中数据存储的基本单位,通常用于衡量存储容量,比如移动硬盘的容量可以是1TB。
一个字节由8个比特(bit)组成。比特是最小的数据单位,它可以是0或1,用于表示二进制信息。
数据传输时通常以比特为单位进行计量,比如家里的宽带速度可能是以兆比特(Mbps)或千兆比特(Gbps)为单位。当我们说家里的宽带是100Mbps时,意味着每秒可以传输100兆比特的数据。
要将比特转换为字节,可以使用以下关系:1字节 = 8比特。因此,如果要将100Mbps转换为字节,需要将其除以8。
比特(Bit):
- 比特是信息的最小单位,代表一个二进制数字,可以是0或1。
- 它是数字数据存储和传输的基础,所有的信息都是由比特组成的。
- 比特通常用于描述计算机中的单个开关或存储单元的状态。
字节(Byte):
- 字节是由8个比特组成的集合,通常表示为8位二进制数,即2^8 = 256个可能的组合。
- 字节是计算机中最常用的数据单位,用于表示文本字符、数字和其他数据。
- 一个字节可以存储一个ASCII字符,其中ASCII(美国标准信息交换码)是一种将英文字符、数字和其他符号编码为二进制数的标准。
在实际应用中,比特和字节的关系可以这样理解:字节是比特的集合,而比特是构成字节的单个砖块。计算机处理数据时,通常以字节为单位进行读写和传输,但底层的数据传输和存储则是由单个比特组成的。
Code
获取字符串byte
public static void main(String[] args) {
String a = "a";
byte[] bytes = a.getBytes();
for (byte b : bytes) {
// 打印发现byte实际上就是ascii码
System.out.println(b);
}
}
byte转化为bit
public class ByteBit {
public static void main(String[] args) {
// 定义一个字符串变量a
String a = "a";
// 将字符串a转换为字节数组
byte[] bytes = a.getBytes();
// 遍历字节数组中的每个字节
for (byte aByte : bytes) {
// 将字节转换为整数值
int c = aByte;
// 打印出整数值
System.out.println(c);
// 将整数值转换为二进制字符串表示
String s = Integer.toBinaryString(c);
// 打印出二进制字符串表示
System.out.println(s);
}
}
}
将字符串"a"转换为字节数组,并将每个字节对应的整数值和二进制表示打印出来
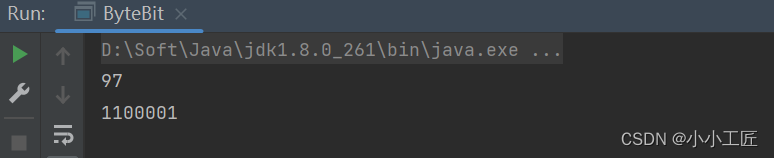
1100001 打印出来应该是8个bit,但前面是0,没有打印 ,从打印结果可以看出来,一个英文字符 ,占一个字节
中文对应的字节(UTF-8编码)–> 一个中文对应的是三个字节
这段代码演示了根据不同的编码格式(UTF-8和GBK)将字符串转换为字节数组,并打印出每个字节的整数值和二进制表示。
/**
* 根据编码的格式不一样,对应的字节也不一样
*
* 如果是UTF-8:一个中文对应的是三个字节
* 如果是GBK : 一个中文对应的是二个字节
* <p>
* 如果是英文,就无所谓编码格式
*/
public static void main(String[] args) throws Exception {
// 定义一个字符串变量a,包含一个中文字符
String a = "小";
// 根据UTF-8编码格式将字符串转换为字节数组
//byte[] bytes = a.getBytes();
// 根据GBK编码格式将字符串转换为字节数组
//byte[] bytes = a.getBytes("GBK");
// 根据UTF-8编码格式将字符串转换为字节数组
byte[] bytes = a.getBytes("UTF-8");
// 遍历字节数组中的每个字节
for (byte aByte : bytes) {
// 打印出每个字节的整数值
System.out.println(aByte);
// 将每个字节的整数值转换为二进制字符串表示,并打印出来
String s = Integer.toBinaryString(aByte);
System.out.println(s);
}
}
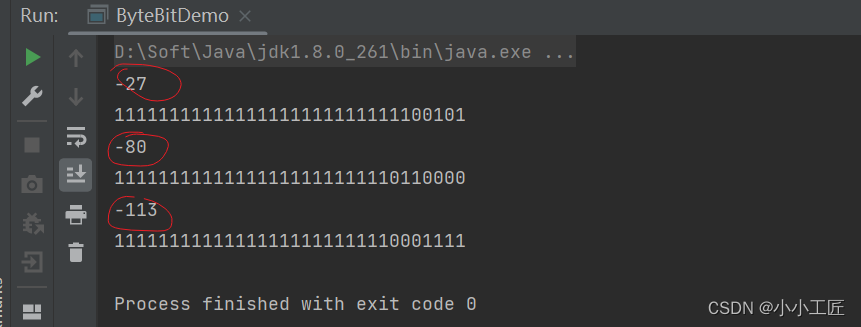
根据不同的编码格式,一个中文字符所占的字节数也不同,UTF-8编码下一个中文字符通常占三个字节,而GBK编码下通常占两个字节。
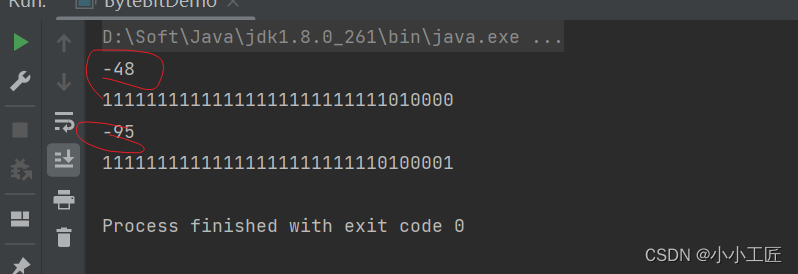
中文对应的字节(GBK编码)–> 一个中文对应的是两个字节
byte[] bytes = a.getBytes("GBK");
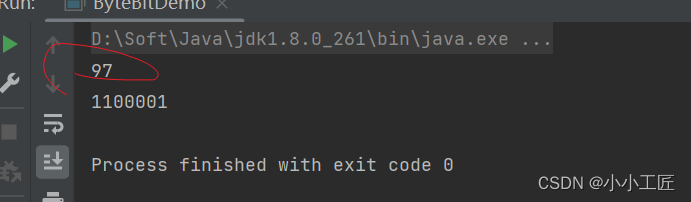
英文对应的字节 - 跟编码无关
public static void main(String[] args) throws Exception {
String a = "a";
byte[] bytes = a.getBytes();
for (byte aByte : bytes) {
System.out.println(aByte);
String s = Integer.toBinaryString(aByte);
System.out.println(s);
}
}
小结
根据编码格式的不同,字符所占的字节数也不同,这是因为不同的编码方式使用不同的规则来表示字符。这里提到了两种常见的字符编码格式:UTF-8和GBK。
- UTF-8 :UTF-8是一种变长字符编码,通常用来表示Unicode字符集中的字符。在UTF-8编码下,一个中文字符通常由三个字节表示,而一个英文字符则由一个字节表示。因为UTF-8采用了变长编码,所以不同的字符可能占据不同数量的字节,从而能够灵活地表示各种语言的字符。
- GBK :GBK是一种针对汉字的多字节编码,它主要用于中文字符的表示。在GBK编码下,一个中文字符通常由两个字节表示,而一个英文字符则仍然由一个字节表示。与UTF-8不同,GBK编码是固定长度的,每个字符所占的字节数都是相同的。
对于英文字符,由于其在各种编码格式下都是用相同的规则表示,因此无论使用何种编码格式,英文字符都只占一个字节。

Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
