前面已经分析把物理内存添加到memblock以及给物理内存建立页表映射,这里我们分析内存模型。在Linux内核中支持3种内存模型,分别为
- flat memory model
- Discontiguous memory model
- sparse memory model
所谓memory model,其实就是从cpu的角度看,其物理内存的分布情况,在linux kernel中,使用什么的方式来管理这些物理内存。某些体系架构支持多种内存模型,但在内核编译构建时只能选择使用一种内存模型。
1. 基本概念
1.1 page frame
从虚拟地址到物理地址的映射过程,系统对于内存管理是以页为单位进行管理的。在linux操作系统中,物理内存是按照page size来管理的,具体page size是多少是和硬件以及linux系统配置相关的,4k是最经典的设定。因此,对于物理内存,我们将其分成一个个按page size排列的page,每一个物理内存中的page size的内存区域我们称之page frame。page frame是系统内存的最小单位,对内存中的每个页都会创建struct page实例。
1.2 PFN
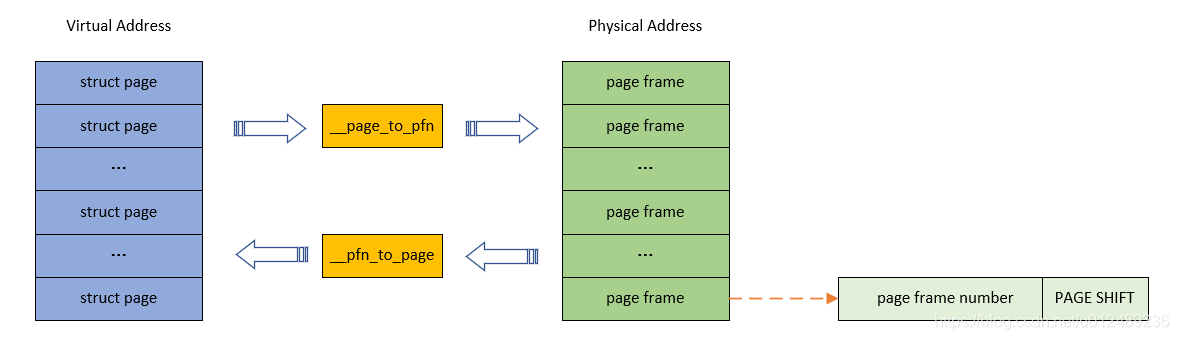
对于一个计算机系统,其整个物理地址空间应该是从0开始,到实际系统能支持的最大物理空间为止的一段地址空间。在ARM系统中,假设物理地址是32个bit,那么其物理地址空间就是4G,在ARM64系统中,如果支持的物理地址bit数目是48个,那么其物理地址空间就是256T。当然,实际上这么大的物理地址空间并不是都用于内存,有些也属于I/O空间(当然,有些cpu arch有自己独立的io address space)。因此,内存所占据的物理地址空间应该是一个有限的区间,不可能覆盖整个物理地址空间。
PFN是page frame number的缩写,所谓page frame,就是针对物理内存而言的,把物理内存分成一个个固定长度为page size的区域,并且给每一个page 编号,这个号码就是PFN。与page frame的转换关系如下图所示
1.3 NUMA
在多核的系统设计中内存的架构有两种类型计算机,分别以不同的方式管理物理内存。
-
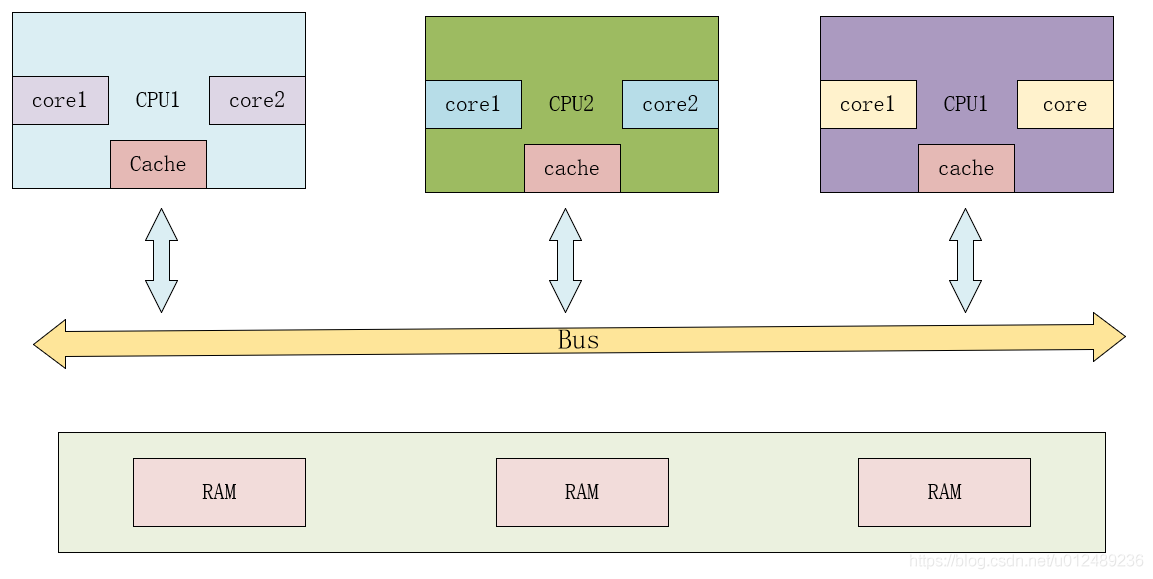
UMA计算机(一致内存访问,uniform memory access):将可用内存以连续方式组织起来,系统中所有的处理器共享一个统一的,一致的物理内存空间,无论从哪个处理器发起访问,对内存的访问时间都是一样快。其架构图如下图所示
-
NUMA计算机(非一致内存访问,non-uniform memory access):每个 CPU 都有自己的本地内存,CPU 访问本地内存不用过总线,因而速度要快很多,每个 CPU 和内存在一起,称为一个 NUMA 节点。但是,在本地内存不足的情况下,每个 CPU 都可以去另外的 NUMA 节点申请内存,这个时候访问延时就会比较长。
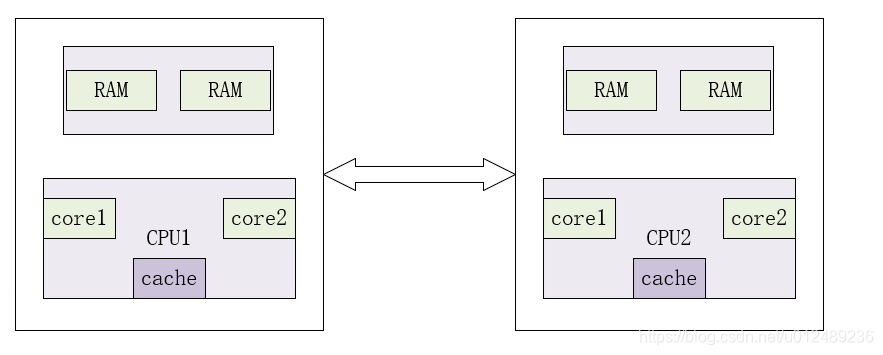
从图中可以看出,每个CPU访问local memory,速度更快,延迟更小。当然,整体的内存构成一个内存池,CPU也能访问remote memory,相对来说速度更慢,延迟更大。目前对NUMA的了解仅限于此,在内核中会遇到相关的代码,大概知道属于什么范畴就可以了。
2. linux内存模型
Linux提供了三种内存模型(include/asm-generic/memory_model.h),一般处理器架构支持一种或者多种内存模型,这个在编译阶段就已经确定,比如目前在ARM64中,使用的Sparse Memory Model。
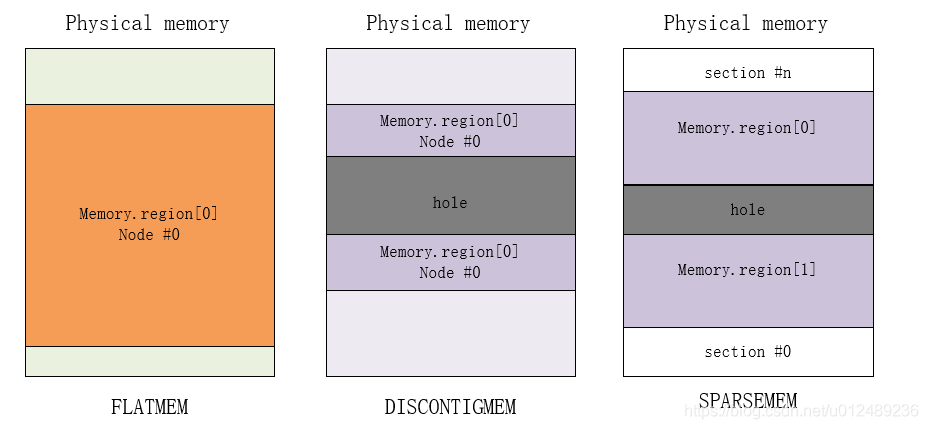
2.1 FLAT memory model(平坦内存模型)
如果从系统中任意一个CPU的角度来看,当它访问物理内存的时候,物理地址空间是一个连续的,没有空洞的地址空间,那么这种计算机系统的内存模型就是Flat memory。
早期的系统物理内存不大,那个时候Linux使用平坦内存模型(flat memory model)来管理物理内存就足够有效了。一个page frame用一个struct page结构体表示,整个物理内存可以用一个由所有struct page构成的数组mem_map表示,而经过页表查找得到的PFN,正好可以用来做这个数组的小标,__pfn_to_page()函数就是专门来完成这个功能的。
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
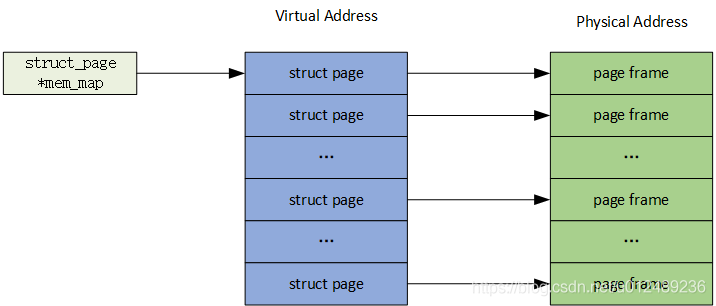
对于FLATMEM来说,物理内存本身是连续的,如果不连续的话,那么中间一部分物理地址是没有对应的物理内存,就会形成一个个洞,这就浪费了mem_map数组本身占用的内存空间。对于这种模型,其特点如下:
- 内存连续且不存在空隙
- 这种在大多数情况下,应用于UMA系统“Uniform Memory Access”。
- 通过CONFIG_FLATMEM配置
2.2 discontiguous memory model (不连续内存模型)
如果CPU在访问物理内存的时候,其地址空间是有一些空洞的,是不连续的,那么这种计算机系统的内存模型就是Discontiguous memory。在什么情况下物理内存是不连续的呢?当NUMA出现后,为了有效的管理NUMA模式的物理内存,一种被称为不连续内存模型的实现于1999年被引入linux系统中。在这中模型中,NUMA中的每个Node用一个叫做pglist_data的结构体表示。
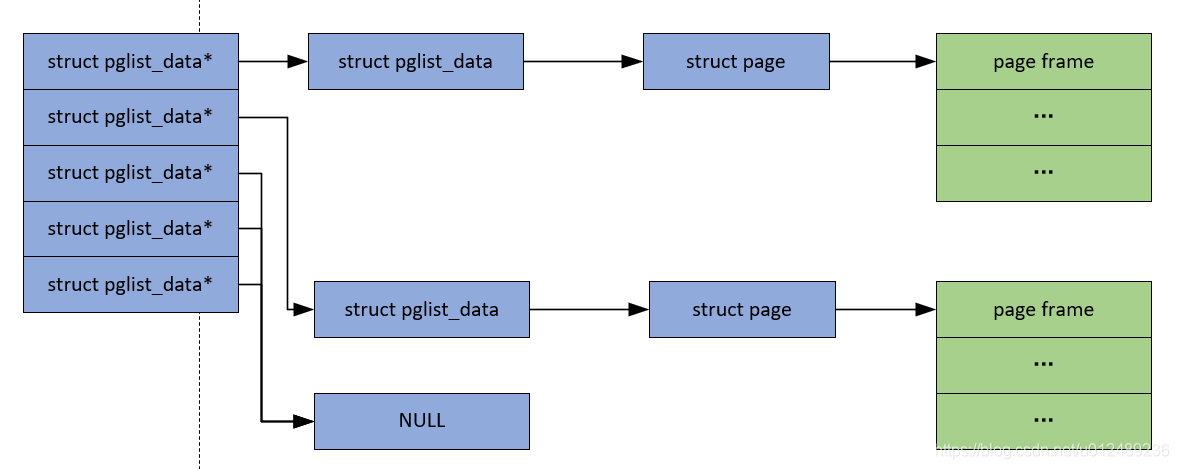
应对不连续物理内存的问题似乎是解决了,可是现在你给我一个物理page的地址,使用DISCONTIGMEM的话,我怎么知道这个page是属于哪个node的呢,PFN中可没有包含node编号啊。pfn_to_page()之前干的活多轻松啊,就是索引下数组就得到数组元素struct page了,现在PFN和page之间的对应关系不是那么直接了,pfn_to_page的任务就开始重起来了。
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
unsigned long __nid = arch_pfn_to_nid(__pfn); \
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\
})
物理内存存在空洞,随着Sparse Memory的提出,这种内存模型也逐渐被弃用了。这种内存模型有以下的特点
- 多个内存节点不连续并且存在空隙"hole"
- 适用于UMA系统和NUMA系统
- ARM在2010年已经移除了对DISCONTIGMEM的支持
- 通过CONFIG_CONTIGMEM配置
2.3 sparse memory model(稀疏内存模型)
内存模型是一个逐渐演化的过程,刚开始的时候,由于内存比较小,使用flat memory模型去抽象一个连续的内存地址空间。但是出现了NUMA架构之后,整个不连续的内存空间被分配成若干个node,每个node上是连续的内存地址空间,为了有效的管理NUMA模型下的物理内存,就开始使用discontiguous memory model。为了解决DISCONTIGMEM存在的弊端,一种新的稀疏内存模型被使用出来。
在sparse memory内存模型下,连续的地址空间按照SECTION被分成一段一段的,其中每一个section都是Hotplug的,因此sparse memory下,内存地址空间可以被切分的更细,支持更离散的Discontiguous memory。在SPARSEMEM中,被管理的物理内存由一个个任意大小的section(struct mem_section表示)构成,因此整个物理内存可被视为一个mem_section数组。每个mem_section包含了一个间接指向struct page数组的指针。
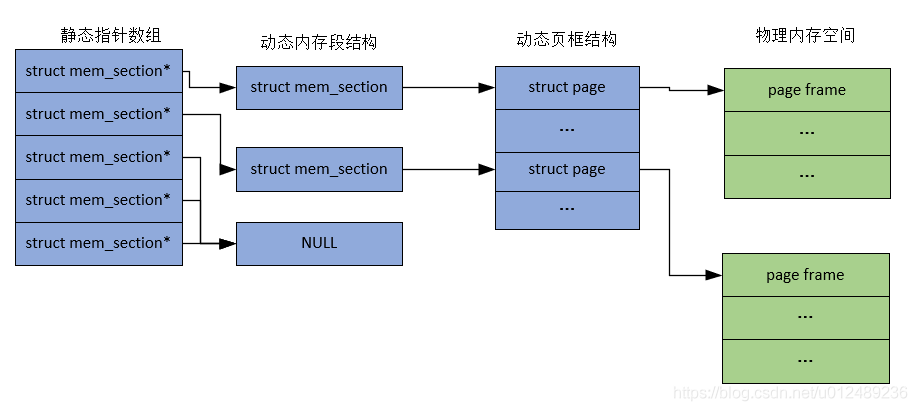
其主要的特点如下:
- 多个内存区域不连续并且存在空隙
- 支持内存热插拔(hot plug memory),但性能稍逊色于DISCONTIGMEM
- 在x86或ARM64内存采用该中模型,其性能比DISCONTIGMEM更优并且与FLATMEM相当
- 对于ARM64平台默认选择该内存模型
- 以section为单位管理online和hot-plug内存
- 通过CONFIG_SPARSEMEM配置
section大小从几十MiB到几GiB不等,取决于体系架构和内核的配置。通常在系统配置中将内存扩展单元「memory expansion unit」用作section大小。比如,如果系统内存可扩展至64GiB,并且最小内存扩展单元为1GiB,则设置section大小也为1GiB。当使用Linux系统作为hypervisor的客户操作系统「guest OS」,也是以section大小为单元在运行时向Linux系统增添内存和移除Linux系统的内存。
3. 平台内存模型支持
Linux支持的各种不同体系结构在内存管理方面差别很大,以下是主流的架构支持情况如下表所示,一个体系架构中可能有多种内存模型可用(ARM64只支持一种内存模型),通过可选的内核配置选项来决定使用哪种内存模型。
| 系统架构 | FLATMEM | DISCONTIGMEM | SPARSEMEM |
|---|---|---|---|
| ARM | 默认 | 不支持 | 某些系统可选配置 |
| ARM64 | 不支持 | 不支持 | 默认 |
| x86_32 | 默认 | 不支持 | 可配置 |
| x86_32(NUMA) | 不支持 | 默认 | 可配置 |
| x86_64 | 不支持 | 不支持 | 默认 |
| x86_64(NUMA) | 不支持 | 不支持 | 默认 |
4.小结
这章我们学习了3种内核模型的各自原理和特点,同时我们简单介绍linux kernel,对于这三种模型使用什么样的方式来管理这些物理内存,后面的章节中会针对FLAT(ARM)和SPARSE(ARM64)模型做相应的介绍。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
