上一章,我们学习了kswapd的内存回收的机制,其本身是一个内核线程,它和调用者的关系是异步的,那么本章就开始学习内核的内存回收的方式。因为在不同的内存分配路径中,会触发不同的内存回收方式,内存回收针对的目标有两种,一种是针对zone的,另一种是针对一个memcg的,而这里我们只讨论针对zone的内存回收,对于内存回收讨论以下三种方式
- 快速内存回收: 处于get_page_from_freelist()函数中,在遍历zonelist过程中,对每个zone都在分配前进行判断,如果分配后zone的空闲内存数量 < 阀值 + 保留页框数量,那么此zone就会进行快速内存回收,即使分配前此zone空闲页框数量都没有达到阀值,都会进行此zone的快速内存回收。注意阀值可能是min/low/high的任何一种,因为在快速内存分配,慢速内存分配和oom分配过程中如果回收的页框足够,都会调用到get_page_from_freelist()函数,所以快速内存回收不仅仅发生在快速内存分配中,在慢速内存分配过程中也会发生。
- 直接内存回收: 处于慢速分配过程中,直接内存回收只有一种情况下会使用,在慢速分配中无法从zonelist的所有zone中以min阀值分配页框,并且进行异步内存压缩后,还是无法分配到页框的时候,就对zonelist中的所有zone进行一次直接内存回收。注意,直接内存回收是针对zonelist中的所有zone的,它并不像快速内存回收和kswapd内存回收,只会对zonelist中空闲页框不达标的zone进行内存回收。并且在直接内存回收中,有可能唤醒flush内核线程。
- kswapd内存回收: 发生在kswapd内核线程中,每个node有一个swapd内核线程,也就是kswapd内核线程中的内存回收,是只针对所在node的,并且只会对 分配了order页框数量后空闲页框数量 < 此zone的high阀值 + 保留页框数量 的zone进行内存回收,并不会对此node的所有zone进行内存回收。
1 内存分配
内核的页面分配器是由伙伴系统来负责分配内存,不论是返回虚拟地址的还是返回struct page指针的,最终都会调用一个共同的接口:__alloc_pages_nodemask()
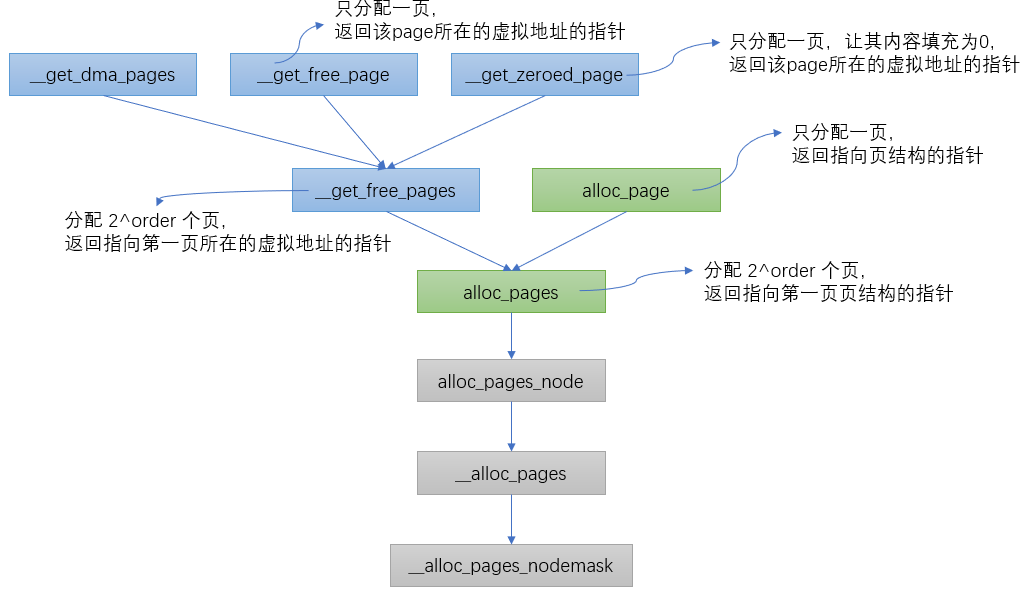
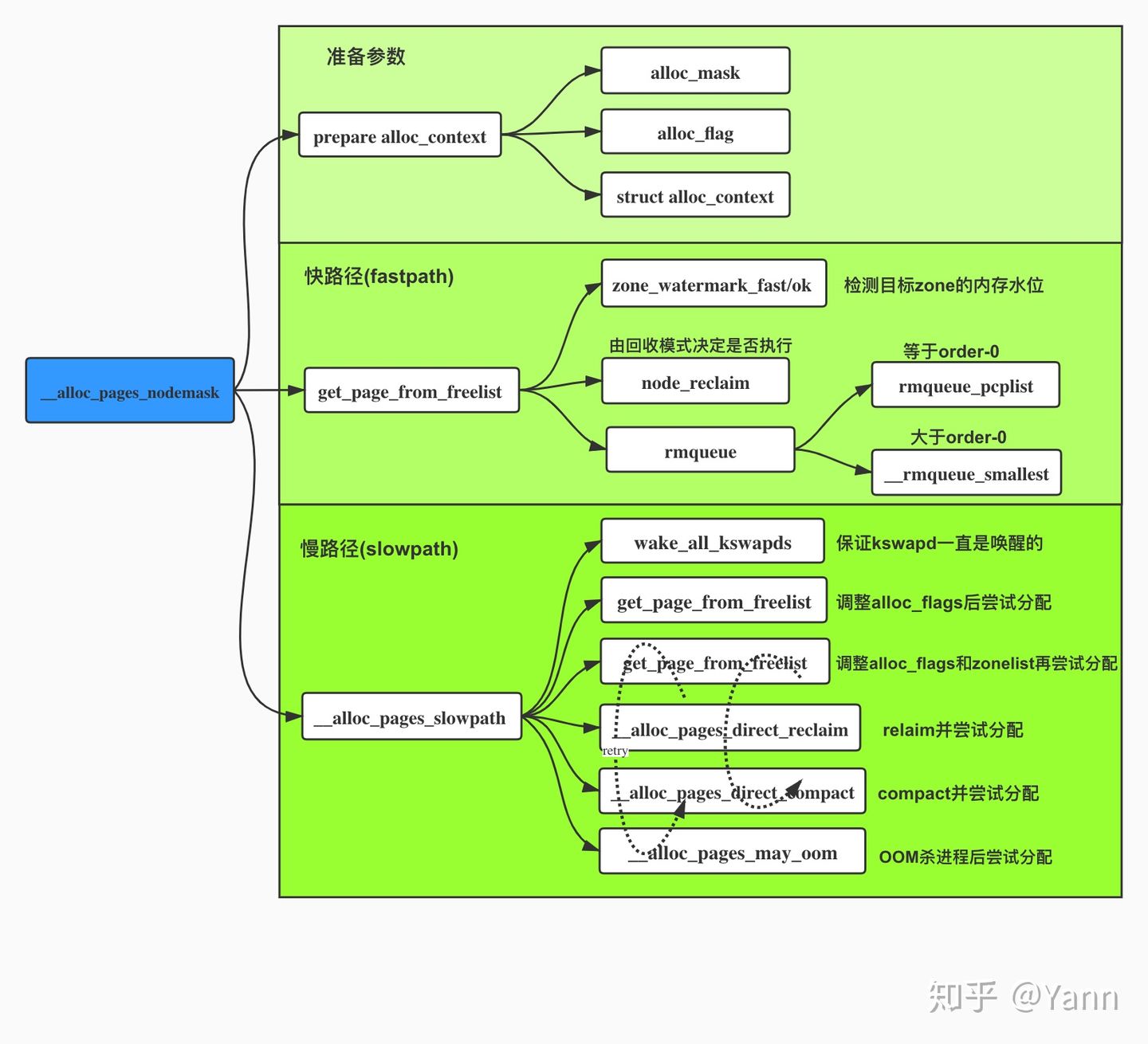
上面我们看到__alloc_pages_nodemask()即页面分配器的’心脏’了,接下来我们就梳理下这颗’心脏’中都具体做了哪些事情,该函数定义在mm/page_alloc.c文件中,该函数实现的功能主要有以下三点:
- 进行一些必要的
check,并将之后进行内存分配所要用到的一些标识进行初始化。 - 尝试快分配 -
get_page_from_freelist() - 若第2步失败,尝试慢分配 -
__alloc_pages_slowpath()
首先会判断参数order是否大于MAX_ORDER,MAX_ORDER定义为11,order表示free_list数组的下标。
if (unlikely(order >= MAX_ORDER)) {
WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN));
return NULL;
}
gfp_mask &= gfp_allowed_mask;
alloc_mask = gfp_mask;
if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags))
return NULL;
上面是做一些基本的check ,然后调用prepare_alloc_pages()函数对struct alloc_context结构体变量ac进行初始化赋值。跟进该函数:
static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order,
int preferred_nid, nodemask_t *nodemask,
struct alloc_context *ac, gfp_t *alloc_mask,
unsigned int *alloc_flags)
{
//获取内存分配时,所能分配内存的最高zone,通常的顺序是:HIGHMEN->NORMAL->DMA。high_zoneidx是_zonerefs数组的下标
ac->high_zoneidx = gfp_zone(gfp_mask);
//当perferred_zone上没有合适的页可以分配时,就要按zonelist中的顺序扫描该zonelist中备用zone列表
ac->zonelist = node_zonelist(preferred_nid, gfp_mask);
ac->nodemask = nodemask;
//根据gfp_mask标识转换成相应的migratetype
ac->migratetype = gfpflags_to_migratetype(gfp_mask);
//检查cpusets功能是否开启,这个是一个cgroup的子模块,
//如果没有设置nodemask就会用cpusets配置的cpuset_current_mems_allowed来限制在哪个node上分配,
//这个也是在NUMA结构当中才会有用的
if (cpusets_enabled()) {
*alloc_mask |= __GFP_HARDWALL;
if (!ac->nodemask)
ac->nodemask = &cpuset_current_mems_allowed;
else
*alloc_flags |= ALLOC_CPUSET;
}
fs_reclaim_acquire(gfp_mask);
fs_reclaim_release(gfp_mask);
//might_sleep_if,判断gfp_mask & __GFP_DIRECT_RECLAIM), 表示当前内存压力比较大需要直接回收内存,
//会循环睡眠同步等待页可用
might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM);
//如果当前调用进入了一个不可睡眠的上下文就会报错. should_fail_alloc_page会做一些预检查, 一些无法分配的条件会直接报错
if (should_fail_alloc_page(gfp_mask, order))
return false;
//判断是否开启了连续内存分配器,并且要求迁移类型为可移动
if (IS_ENABLED(CONFIG_CMA) && ac->migratetype == MIGRATE_MOVABLE)
*alloc_flags |= ALLOC_CMA;
return true;
}
回到__alloc_pages_nodemask函数,接着调用finalise_ac(gfp_mask, &ac)函数
static inline void finalise_ac(gfp_t gfp_mask, struct alloc_context *ac)
{
/* Dirty zone balancing only done in the fast path */
ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE);
/*
* The preferred zone is used for statistics but crucially it is
* also used as the starting point for the zonelist iterator. It
* may get reset for allocations that ignore memory policies.
*/
//对ac->preferred_zoneref 进行赋值,即可用来分配内存的zone
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
}
first_zones_zonelist函数会根据zonelist,highidx,nodemask这几个参数,最终选择一个zone最为第一个可用来内存分配的zone。内存分配的zone的寻找,是通过遍历zonelist的_zonerefs数组来做的。
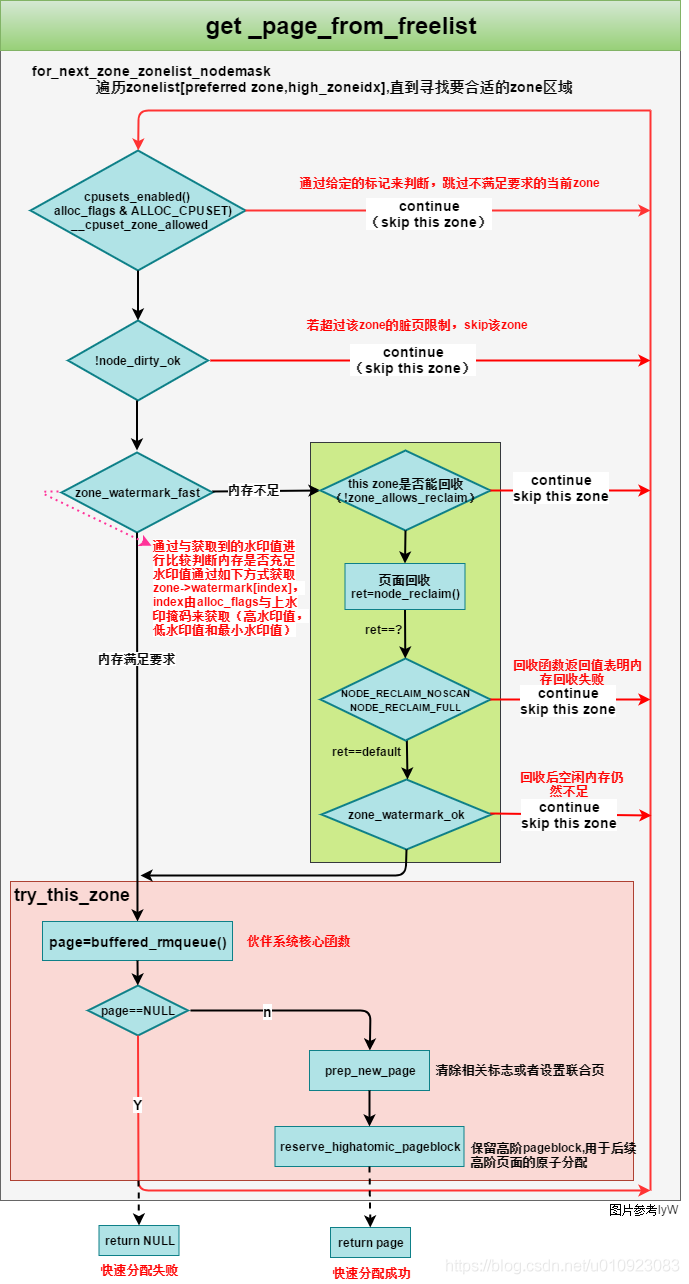
2 快分配 – get_page_from_freelist
接下来会调用关键函数get_page_from_freelist进程快速内存分配。如果分配失败,会继续尝试其他途径分配所需内存,也叫做慢分配。
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z = ac->preferred_zoneref;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
/*
* Scan zonelist, looking for a zone with enough free.
* See also __cpuset_node_allowed() comment in kernel/cpuset.c.
*/
//遍历所有的zone list,寻找有足够空间的zone
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
//参数检查,若有不满足,直接continue跳过当前zone,判断cpuset是否开启且当前CPU是否允许在内存域zone所在结点中分配内存
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
/*
* When allocating a page cache page for writing, we
* want to get it from a node that is within its dirty
* limit, such that no single node holds more than its
* proportional share of globally allowed dirty pages.
* The dirty limits take into account the node's
* lowmem reserves and high watermark so that kswapd
* should be able to balance it without having to
* write pages from its LRU list.
*
* XXX: For now, allow allocations to potentially
* exceed the per-node dirty limit in the slowpath
* (spread_dirty_pages unset) before going into reclaim,
* which is important when on a NUMA setup the allowed
* nodes are together not big enough to reach the
* global limit. The proper fix for these situations
* will require awareness of nodes in the
* dirty-throttling and the flusher threads.
*/
//不为0表示gfp_mask存在__GFP_WRITE标志位, 有可能增加脏页
if (ac->spread_dirty_pages) {
//如果当前zone所在节点被标记为脏页超标就跳过
if (last_pgdat_dirty_limit == zone->zone_pgdat)
continue;
//如果zone对应的node脏页超标则使用last_pgdat_dirty_limit标识, 并跳过该zone
if (!node_dirty_ok(zone->zone_pgdat)) {
last_pgdat_dirty_limit = zone->zone_pgdat;
continue;
}
}
//接下来检查所遍历到的内存域是否有足够的空闲页,空闲内存页中是否具有大小为2^order大小的连续内存块。
//如果没有足够的空闲页或者没有连续内存块可满足分配请求(两者出现任意一个),则将循环进行到备用列表中
//的下一个内存域,作同样的检查. 直到找到一个合适的空闲且连续的内存页块, 才会进行try_this_node进行分配
//获取分配所用水印
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
//检查zone中空闲内存是否在水印之上
if (!zone_watermark_fast(zone, order, mark,
ac_classzone_idx(ac), alloc_flags)) {
int ret;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* Watermark failed for this zone, but see if we can
* grow this zone if it contains deferred pages.
*/
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
/* Checked here to keep the fast path fast */
//如果存在ALLOC_NO_WATERMARKS标志位则忽略水位, 进入try_this_zone
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
//如果系统不允许回收内存或者preferred->zone与当前zone的node_distance大于node_reclaim_distance(默认30), 则更换zone
//程序运行到此处说明空闲页在水印之下,接下来需要做内存回收,但有两种特殊情况:
//1. 如果系统不允许内存回收
//2. 如果目标zone和当前zone的distance不小于RECLAIM_DISTANCE
if (node_reclaim_mode == 0 ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
continue;
//内存回收
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
//设置了禁止扫描的标志
case NODE_RECLAIM_NOSCAN:
/* did not scan */
continue;
//没有可回收的页
case NODE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
//内存回收后, 水位正常
if (zone_watermark_ok(zone, order, mark,
ac_classzone_idx(ac), alloc_flags))
goto try_this_zone;
continue;
}
}
//执行到此处代表选定的zone的有满足要求的空闲内存块
try_this_zone:
//伙伴算法开始分配页内存
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
//清除相关标志或者设置联合页
prep_new_page(page, order, gfp_mask, alloc_flags);
/*
* If this is a high-order atomic allocation then check
* if the pageblock should be reserved for the future
*/
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page;
} else {
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/* Try again if zone has deferred pages */
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
}
}
return NULL;
}
快路径总结:
(整体进入for循环,遍历尝试zonelist中的zone直至分配内存成功或失败,for循环中的处理如下)
- 参数检查,若有不满足,直接continue跳过当前zone;
- 检查水位zone_watermark_fast/ok。其中high low min水位线用哪根儿具体由alloc_flags中的ALLOC_WMARK_xx标志决定
- 若水位不ok,则根据回收模式zone_reclaim_mode的设置,判断是回收或是跳过当前zone,倘若最终没一个zone是ok的,则快路径失败,进入慢路径slowpath
- 若水位很ok,都符合了的话则rmqueue函数尝试分配页面,其中会区分order-0和非order-0的情况。
分配内存的时候发现物理内存不够用了,则尝试回收。如申请页面会调用get_page_from_freelist(),该函数会通过调用链get_page_from_freelist()->node_reclaim()->__node_reclaim()->shrink_node()尝试是否可以对当前的内存节点执行换出操作,从而腾出空间,这一过程属于被动页面回收。
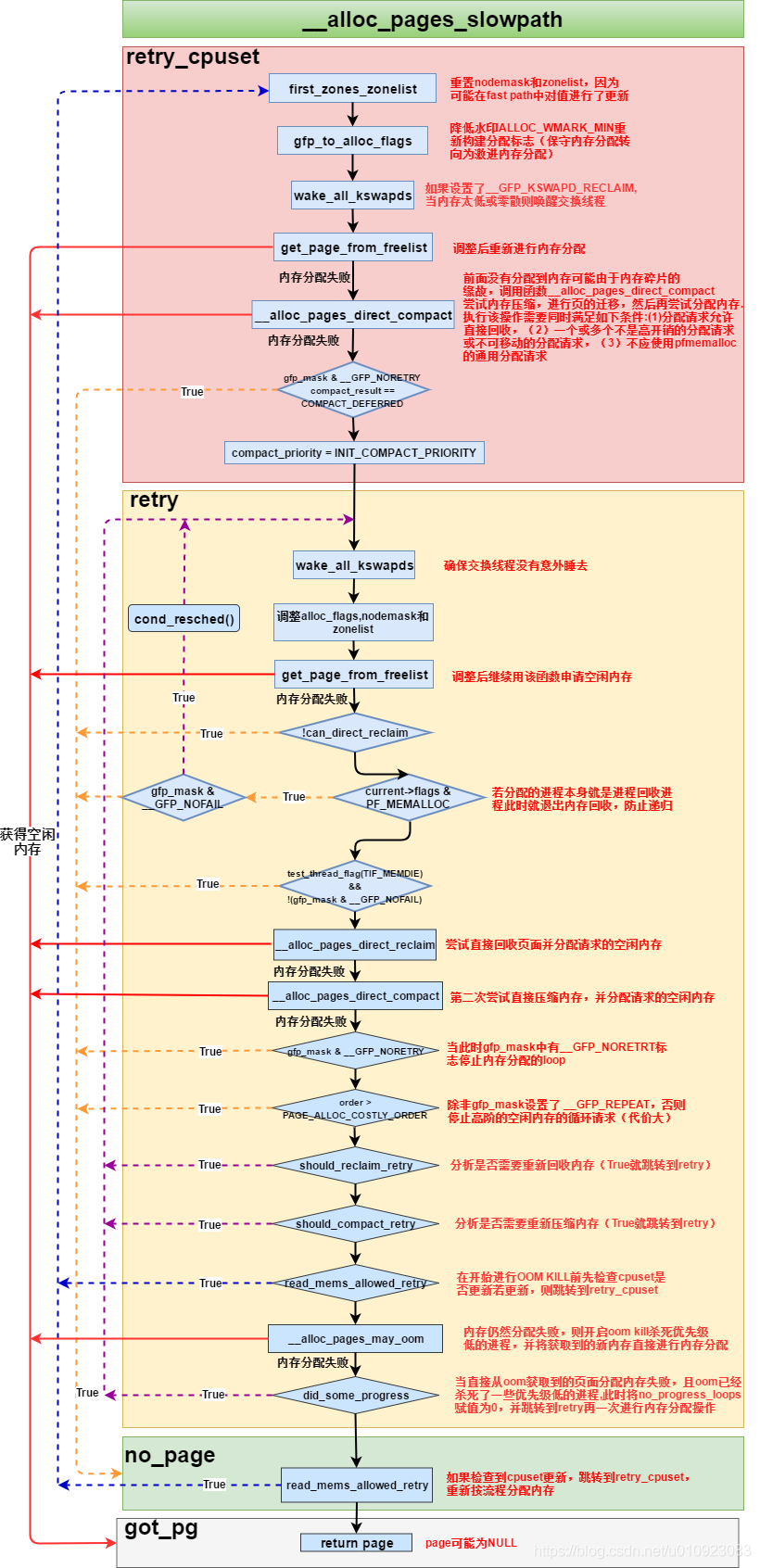
3 慢分配-__alloc_pages_slowpath
当系统内存的水位在低水位之上时,alloc_pages函数可以快速分配和获取内存,我们称之为快速路径;而当系统内存的水位在低水位之下,就要进入到慢速路径。
//gfp_mask:表示调用页面分配器时传递的分配掩码
//order:表示要分配页面的大小,大小为2的order次幂个连续物理页面
//ac:表示页面分配器内部使用的控制参数数据结构
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;
struct page *page = NULL;
unsigned int alloc_flags;
unsigned long did_some_progress;
enum compact_priority compact_priority;
enum compact_result compact_result;
int compaction_retries;
int no_progress_loops;
unsigned long alloc_start = jiffies;
unsigned int stall_timeout = 10 * HZ;
unsigned int cpuset_mems_cookie;
//检查释放大于4M的空间,因为伙伴系统最大只能分配4M空间
if (order >= MAX_ORDER) {
WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN));
return NULL;
}
//2. 检查是否在非终端上下文中滥用__GFP_ATOMIC,__GFP_ATOMIC表示调用页面分配器的进程不能直接回收页面或等待,调用者通常在中断上下文中
if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) ==
(__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)))
gfp_mask &= ~__GFP_ATOMIC;
retry_cpuset:
compaction_retries = 0;
no_progress_loops = 0;
compact_priority = DEF_COMPACT_PRIORITY;
cpuset_mems_cookie = read_mems_allowed_begin();
//是用于根据nodemask,找到合适的不大于high_zoneidx的内存管理区preferred_zone
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
if (!ac->preferred_zoneref->zone)
goto nopage;
//降低水印ALLOC_WMARK_MIN重新构建分配标志
alloc_flags = gfp_to_alloc_flags(gfp_mask);
//如果设置了__GFP_KSWAPD_RECLAIM,就唤醒kswapd线程
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
wake_all_kswapds(order, ac);
//调整后重新利用get_page_from_freelist进行内存分配
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
//前面没有分配到内存可能是因为内存碎片原因,所以就调用__alloc_pages_direct_compact尝试内存规整操作,进行页的迁移,然后再尝试分配执行
//进行该操作需要满足以下条件
//1.分配请求允许直接回收
//2. 内存分配的阶数必须要大于3,因为低阶内存块受内存碎片影响较小,内存规整不能解决问题
//3. 不能访问系统预留的内存,gfp_pfmemalloc_allowed表示是否允许访问系统预留的内存
if (can_direct_reclaim && order > PAGE_ALLOC_COSTLY_ORDER &&
!gfp_pfmemalloc_allowed(gfp_mask)) {
page = __alloc_pages_direct_compact
__alloc_pages_direct_compact尝试内存规整操作,进行页的迁移(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
/*
* Checks for costly allocations with __GFP_NORETRY, which
* includes THP page fault allocations
*/
if (gfp_mask & __GFP_NORETRY) {
/*
* If compaction is deferred for high-order allocations,
* it is because sync compaction recently failed. If
* this is the case and the caller requested a THP
* allocation, we do not want to heavily disrupt the
* system, so we fail the allocation instead of entering
* direct reclaim.
*/
if (compact_result == COMPACT_DEFERRED)
goto nopage;
/*
* Looks like reclaim/compaction is worth trying, but
* sync compaction could be very expensive, so keep
* using async compaction.
*/
compact_priority = INIT_COMPACT_PRIORITY;
}
}
retry:
/* Ensure kswapd doesn't accidentally go to sleep as long as we loop */
//注释很明白,确保交换线程没有意外的睡眠,再次重新唤醒
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
wake_all_kswapds(order, ac);
//对gfp_mask进行分析看是否可以不受水线进行内存分配
if (gfp_pfmemalloc_allowed(gfp_mask))
alloc_flags = ALLOC_NO_WATERMARKS;
//调整nodemask和zonelist
if (!(alloc_flags & ALLOC_CPUSET) || (alloc_flags & ALLOC_NO_WATERMARKS)) {
ac->zonelist = node_zonelist(numa_node_id(), gfp_mask);
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
}
//再次尝试分配内存
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
//调用者不支持直接页面回收,那么没有其他可以做的,直接跳转到nopage
if (!can_direct_reclaim) {
/*
* All existing users of the __GFP_NOFAIL are blockable, so warn
* of any new users that actually allow this type of allocation
* to fail.
*/
WARN_ON_ONCE(gfp_mask & __GFP_NOFAIL);
goto nopage;
}
//若当前进程的进程描述符为PF_MALLOC,那么会在
if (current->flags & PF_MEMALLOC) {
/*
* __GFP_NOFAIL request from this context is rather bizarre
* because we cannot reclaim anything and only can loop waiting
* for somebody to do a work for us.
*/
if (WARN_ON_ONCE(gfp_mask & __GFP_NOFAIL)) {
cond_resched();
goto retry;
}
goto nopage;
}
/* Avoid allocations with no watermarks from looping endlessly */
if (test_thread_flag(TIF_MEMDIE) && !(gfp_mask & __GFP_NOFAIL))
goto nopage;
//当调用直接页面回收机制,经过一轮直接页面回收之后,尝试分配内存
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
//调用直接内存规则机制,经过一轮的直接内存规整之后尝试分配内存
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
/* Do not loop if specifically requested */
if (gfp_mask & __GFP_NORETRY)
goto nopage;
//除非设置了__GFP_REPEAT,否则退出高阶的空闲内存的循环申请
if (order > PAGE_ALLOC_COSTLY_ORDER && !(gfp_mask & __GFP_REPEAT))
goto nopage;
//告知该空闲内存申请的时间已经过长
if (time_after(jiffies, alloc_start + stall_timeout)) {
warn_alloc(gfp_mask,
"page allocation stalls for %ums, order:%u",
jiffies_to_msecs(jiffies-alloc_start), order);
stall_timeout += 10 * HZ;
}
//检查是否有必要重新做内存回收,尝试直接页面回收机制
if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,
did_some_progress > 0, &no_progress_loops))
goto retry;
//判断是否需要重新做内存规整
if (did_some_progress > 0 &&
should_compact_retry(ac, order, alloc_flags,
compact_result, &compact_priority,
&compaction_retries))
goto retry;
/*
* It's possible we raced with cpuset update so the OOM would be
* premature (see below the nopage: label for full explanation).
*/
if (read_mems_allowed_retry(cpuset_mems_cookie))
goto retry_cpuset;
//前面一系列工作,都没有成功分配到需要的空闲内存,开启oom杀死一些进程,并重新获取页面中直接进行空闲页面分配
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
//当直接从oom获取到内存分配内存失败,且oom已经杀死了一些低优先级的进程,此时将no_progress_loop设置为0,跳转到retry再一次进行内存分配操作
if (did_some_progress) {
no_progress_loops = 0;
goto retry;
}
nopage:
/*
* When updating a task's mems_allowed or mempolicy nodemask, it is
* possible to race with parallel threads in such a way that our
* allocation can fail while the mask is being updated. If we are about
* to fail, check if the cpuset changed during allocation and if so,
* retry.
*/
if (read_mems_allowed_retry(cpuset_mems_cookie))
goto retry_cpuset;
//输出这分配内存失败的进程名字,gfp_mask,order等信息
warn_alloc(gfp_mask,
"page allocation failure: order:%u", order);
got_pg:
return page;
}
其主要大致流程如下:
-
检查是否在非终端上下文中滥用__GFP_ATOMIC,__GFP_ATOMIC表示调用页面分配器的进程不能直接回收页面或者等,调用者通常在中断上下文
-
gfp_to_alloc_flags重新设置分配掩码alloc_flags,在快速分配路径中,页面分配器使用低水位ALLOC_WMARK_LOW,这个是相对保守的策略。在这里,正因为在低水位分配失败,所以才会走到慢速路径中,所以需要改变
- 设置分配条件ALLOC_WMARK_MIN和ALLOC_CPUSET,即使最低警戒线水位来判断是否满足分配请求
- 判断gfp_mask是否设置了_GFP_HIGH,__GFP_HIGH表示页面分配器调用的进程具有很高的优先级,如实时进程,必须保证这次分配成功才能继续运行,所以在紧急情况下允许访问部分的系统预留内存
- 判断gpf_mask是否设置了__GFP_KSWAPD_RECLAIM,则调用wake_all_kswapd唤醒kswapd内核线程
-
get_page_from_freelist以最低水位为条件还不能分配成功,则调用直接内存规整机制来解决页面分配失败的问题
-
确保kswapd内核线程不会进入睡眠,因为需要重新唤醒它
-
重新调用get_page_from_freelist尝试一次页面分配,若成功,则直接返回退出
-
调用直接页面回收机制,经过一轮直接页面回收之后尝试分配内存
-
调用直接内存规整机制,经过一轮直接内存规整之后尝试分配内存
-
我们尝试了很对方法来尝试分配内存,如尝试用最低警戒水位,忽略水位,使用直接页面回收以及直接内存规整,若这些方法都不管用,那还可以重试多次
-
所以这些都尝试了,还是无法分配出所需要的内存,那么就将使用OOM killer机制,来终止占用内存比较多的进程,从而释放一些内存
4 水位管理和分配优先级
页面分配器按照zone的水位来管理,每个zone在系统初始化的时候会计算水位值:WMARK_MIN、WMARK_LOW、WMARK_HIGH。这些参数在kswapd回收页面内存的时候会用到。
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
#define min_wmark_pages(z) (z->watermark[WMARK_MIN])
#define low_wmark_pages(z) (z->watermark[WMARK_LOW])
#define high_wmark_pages(z) (z->watermark[WMARK_HIGH])
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
//zone内存区域中预留的内存
long lowmem_reserve[MAX_NR_ZONES];
...
}
除了上面的水位管理外,页面分配器在最低警戒水位预留内存,一般情况下是不能拿来使用,但是在特殊情况下是可以用来救急的。页面分配器可以通过分配掩码的不同来访问最低水位以下的内存
| 分配请求优先级 | 判断条件 | 分配行为 |
|---|---|---|
| 正常 | 如GFP_KERNEL或者GFP_USER等分配掩码 | 不能访问系统中预留的内存,只能使用最低警戒水位来判断是否完成本次分配请求 |
| 高(ALLOC_HIGH) | __GFP_HIGH | 表示这是一次优先级比较高的分配行为,可以访问最低警戒水位以下的一半内存 |
| 艰难(ALLOC_HARDER) | __GFP_ATOMIC或者实时进程 | 表示需要分配页面的进程不能睡眠并且优先级比较高,可以访问最低警戒水位以下的5/8的内存 |
| OOM进程(ALLOC_OOM) | 若进程组有线程被OOM进程终止,就适当做补偿 | 用于补偿OOM进程或线程,可以访问最低警戒水位以下的3/4的内存 |
| 紧急(ALLOC_NO_WATERMARKS) | __GFP_MEMALLOC,或者设置了__GFP_MEMALLOC标志位 | 可以访问系统中所有内存,包括预留的内存 |
在计算之前我们需要了解内核中几个全局变量值对应的意义,managed_pages,spanned_pages,present_pages三个值对应的意义
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
- spanned_pages: 代表的是这个zone中所有的页,包含空洞,计算公式是: zone_end_pfn - zone_start_pfn
- present_pages: 代表的是这个zone中可用的所有物理页,计算公式是:spanned_pages-hole_pages
- managed_pages: 代表的是通过buddy管理的所有可用的页,计算公式是:present_pages - reserved_pages
- 三者的关系是: spanned_pages > present_pages > managed_pages
系统中每个NUMA node的每个struct zone中都定义着一个_watermark[NRWMARK]数组,其中存放着该zone的min、low和high三种内存水位线。简单来说,它们是衡量当前系统剩余内存是否充足的一个标尺。当zone中的剩余内存高于high时说明剩余内存充足,低于low但高于min时说明内存短缺但是仍可分配内存,若低于min则说明剩余内存极度短缺将停止分配(GFP_ATOMIC类型的分配例外)并全力回收。下图展示了min、low、high和内存回收的关系:
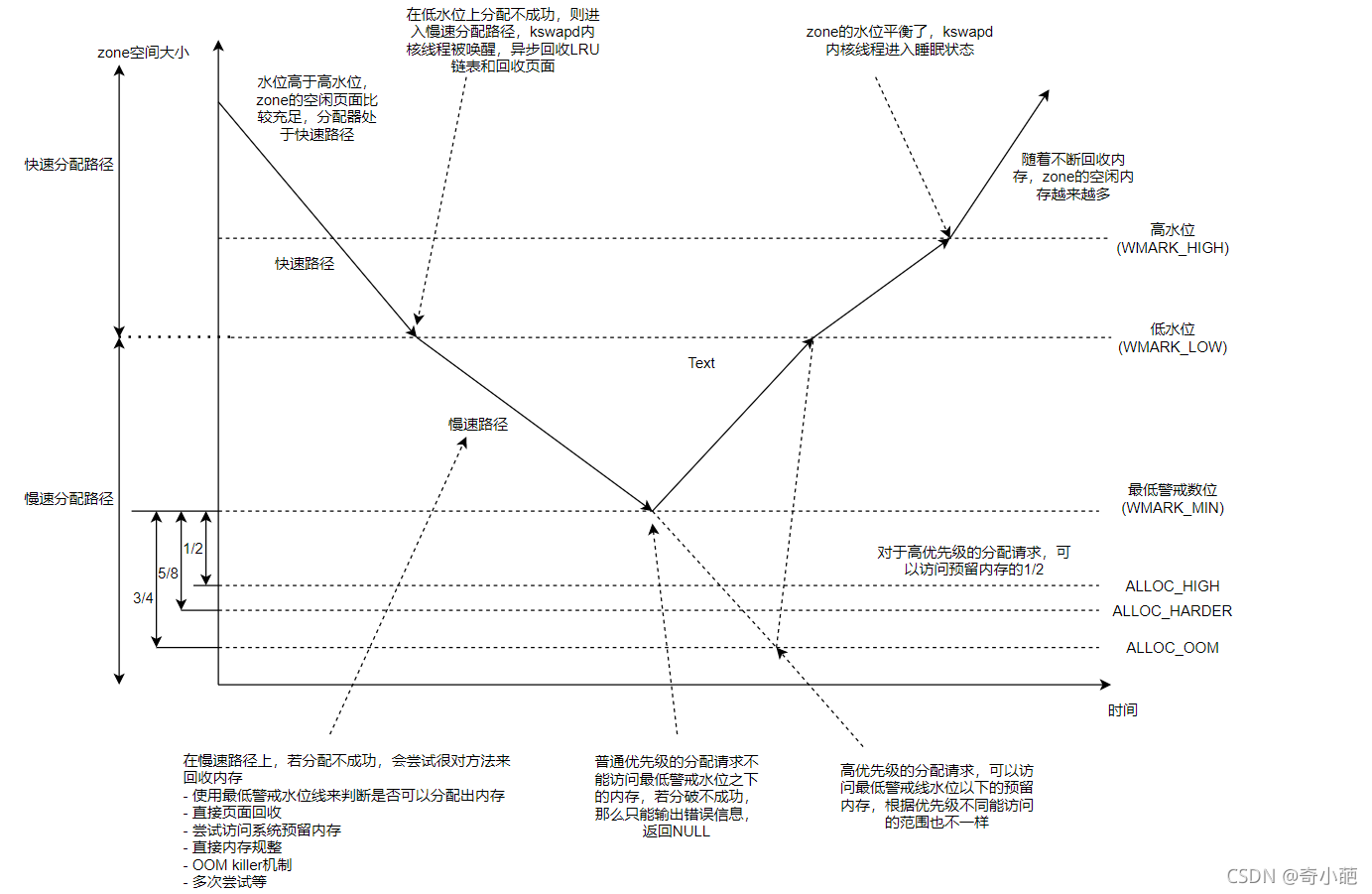
- 当total size低于low的时候,会唤醒kswapd内核线程进行异步回收(所谓异步回收,就是此时仍可以分配内存,内存回收通过kswapd内核线程在后台同时进行);
- 若回收的速度小于分配的速度,total size会降至min水位线以下,此时会触发同步回收,即在__alloc_pages_slowpath函数中阻塞分配内存并尝试直接内存回收(reclaim)、内存压缩(compact)、更甚者OOM Killer强制回收
- 直到tatol size大于high水位线,回收才会停止。整体呈现为一个"V"字形状。
计算水位的一个重要参数min_free_kbytes(代表的是系统保留空闲内存的最低限)是在init_per_zone_wmark_min中进行的
int __meminit init_per_zone_wmark_min(void)
{
unsigned long lowmem_kbytes;
int new_min_free_kbytes;
//获取free_pages根据公式 计算 new_min_free_kbytes
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
//min_free_kbytes必须在[128, 65536]之间
if (new_min_free_kbytes > user_min_free_kbytes) {
min_free_kbytes = new_min_free_kbytes;
if (min_free_kbytes < 128)
min_free_kbytes = 128;
if (min_free_kbytes > 65536)
min_free_kbytes = 65536;
} else {
pr_warn("min_free_kbytes is not updated to %d because user defined value %d is preferred\n",
new_min_free_kbytes, user_min_free_kbytes);
}
//设置每个zone的min low high水位值
setup_per_zone_wmarks();
refresh_zone_stat_thresholds();
//设置每个zone为其他zone的保留内存
setup_per_zone_lowmem_reserve();
#ifdef CONFIG_NUMA
setup_min_unmapped_ratio();
setup_min_slab_ratio();
#endif
khugepaged_min_free_kbytes_update();
return 0;
}
系统初始化里min_free_kbytes的值介于128k~65M之间,但是通过proc接口设置就没这个限制,然后就是进入setup_per_zone_wmarks计算每个zone的min、low、high水位线,因为需要考虑多个zone,因此这个min_free_kbytes需要按比例分配给各个zone。
static void __setup_per_zone_wmarks(void)
{
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
unsigned long lowmem_pages = 0;
struct zone *zone;
unsigned long flags;
/* Calculate total number of !ZONE_HIGHMEM pages */
//统计非ZONE_HIGHMEM的内存总量
for_each_zone(zone) {
if (!is_highmem(zone))
lowmem_pages += zone->managed_pages;
}
//针对每个zone设置min low high水位线
for_each_zone(zone) {
u64 tmp;
//按当前zone内存量占总的内存量的大小来分配min的水位值,所有zone的min水位相加才是真正的min_free_kbytes
spin_lock_irqsave(&zone->lock, flags);
tmp = (u64)pages_min * zone->managed_pages;
do_div(tmp, lowmem_pages);
//64位机器上不会有highmem区域,因此不考虑该情况
if (is_highmem(zone)) {
/*
* __GFP_HIGH and PF_MEMALLOC allocations usually don't
* need highmem pages, so cap pages_min to a small
* value here.
*
* The WMARK_HIGH-WMARK_LOW and (WMARK_LOW-WMARK_MIN)
* deltas control asynch page reclaim, and so should
* not be capped for highmem.
*/
unsigned long min_pages;
min_pages = zone->managed_pages / 1024;
min_pages = clamp(min_pages, SWAP_CLUSTER_MAX, 128UL);
zone->watermark[WMARK_MIN] = min_pages;
} else {
/*
* If it's a lowmem zone, reserve a number of pages
* proportionate to the zone's size.
*/
//设置min水位值
zone->watermark[WMARK_MIN] = tmp;
}
/*
* Set the kswapd watermarks distance according to the
* scale factor in proportion to available memory, but
* ensure a minimum size on small systems.
*/
tmp = max_t(u64, tmp >> 2,
mult_frac(zone->managed_pages,
watermark_scale_factor, 10000));
zone->watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp;
zone->watermark[WMARK_HIGH] = min_wmark_pages(zone) + tmp * 2;
spin_unlock_irqrestore(&zone->lock, flags);
}
/* update totalreserve_pages */
calculate_totalreserve_pages();
}
所以总的来说,
- watermark[WMARK_MIN] = min_free_kbytes/4*zone.pages/zone.allpages
- watermark[WMARK_LOW] = 5/4*watermark[WMARK_MIN]
- watermark[WMARK_HIGH] = 3/2*watermark[WMARK_MIN]
设置完内存水位线后,会更新totalreserve_pages的值,这个值用于评估系统正常运行时需要使用的内存,该值会作用于overcommit时,判断当前是否允许此次内存分配。
回到之前讨论的get_page_from_freelist,kernel中检查watermark的函数有两个:zone_watermark_fast和__zone_watermark_ok,它们会在每次rmqueue分配内存前被调用用来检查watermark。其中zone_watermark_fast()是_zone_watermark_ok()的扩展版本,增加了对order 0分配的快速检查。用于判断当前zone的空闲页是否满足ALLOC_WMARK_LOW,另外还会根据order来判断是否有足够大的空闲内存块。如果返回true,表示zone的页面高于指定水位或者满足order分配需求。
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int classzone_idx, unsigned int alloc_flags,
long free_pages)
{
long min = mark;
int o;
const bool alloc_harder = (alloc_flags & ALLOC_HARDER);
/* free_pages may go negative - that's OK */
//检查分配出去2^order个page之后的free pages是否满足mark的要求
free_pages -= (1 << order) - 1;
//ALLOC_HIGH==__GFP_HIGH,请求分配非常紧急的内存,降低水线阀值
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
/*
* If the caller does not have rights to ALLOC_HARDER then subtract
* the high-atomic reserves. This will over-estimate the size of the
* atomic reserve but it avoids a search.
*/
//只有设置了ALLOC_HARDER,才能从free_list[MIGRATE_HIGHATOMIC]的链表中进行页面分配,否则减去
if (likely(!alloc_harder))
free_pages -= z->nr_reserved_highatomic;
else
min -= min / 4; //若设置了ALLOC_HARDER,分配水线阀值进一步降低
#ifdef CONFIG_CMA
/* If allocation can't use CMA areas don't use free CMA pages */
if (!(alloc_flags & ALLOC_CMA))
free_pages -= zone_page_state(z, NR_FREE_CMA_PAGES);
#endif
/*
* Check watermarks for an order-0 allocation request. If these
* are not met, then a high-order request also cannot go ahead
* even if a suitable page happened to be free.
*/
//如果free pages已经小于等于保留内存和min之和,说明此次分配请求不满足wartmark要求
if (free_pages <= min + z->lowmem_reserve[classzone_idx])
return false;
/* If this is an order-0 request then the watermark is fine */
if (!order)
return true;
//此zone的水线检查已经通过,下面主要是检查当前zone是否具有分配order大小连续内存块的能力具体做法是:
//在当前zone中从申请order往上循环查看伙伴系统中的各个free_area链表中是否有空闲节点可以进行此次内存分配,
//有这判断通过,该zone具有此次内存分配能力。
/* For a high-order request, check at least one suitable page is free */
for (o = order; o < MAX_ORDER; o++) {
struct free_area *area = &z->free_area[o];
int mt;
if (!area->nr_free)
continue;
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!list_empty(&area->free_list[mt]))
return true;
}
#ifdef CONFIG_CMA
if ((alloc_flags & ALLOC_CMA) &&
!list_empty(&area->free_list[MIGRATE_CMA])) {
return true;
}
#endif
if (alloc_harder &&
!list_empty(&area->free_list[MIGRATE_HIGHATOMIC]))
return true;
}
//在当前zone的free_area[]中没有找到可以满足当前order分配的内存块
return false;
}
5 android对水位的调借节
为了避免direct reclaim,我们需要空余的内存大小一直保持在min值以上。但安卓这种大量用户操作网络接收的系统中,难免会遇到数据量突然增大,需要临时申请大量的内存,此时有可能kswapd回收的内存速度小于内存分配的速度,即发生direct reclaim,从而阻塞应用严重影响性能。
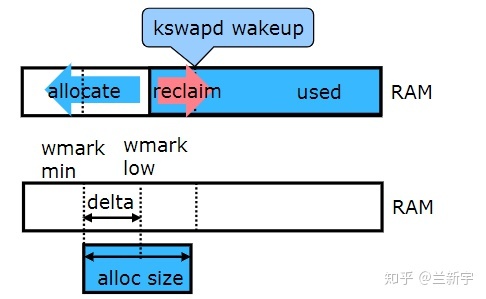
在内存分配时,只有"low"与"min"之间之间的这段区域才是kswapd的活动空间,低于了"min"会触发direct reclaim,高于了"low"又不会唤醒kswapd,而Linux中默认的"low"与"min"之间的差值确实显得小了点。
为此,Android的设计者在Linux的内存watermark的基础上,增加了一个" extra_free_kbytes "的变量,这个"extra"是额外加在"low"与"min"之间的,它在保持"min"值不变的情况下,让"low"值有所增大。假设你的"burst allocation"需要100MiB(100*1024KiB)的空间,那么你就可以把"extra_free_kbytes"的值设为102400。
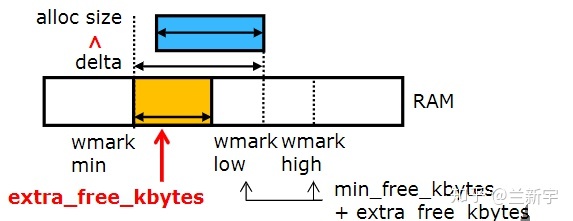
于是,设置各个zone的watermark的代码变成了这样:
void __setup_per_zone_wmarks(void)
{
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
unsigned long pages_low = extra_free_kbytes >> (PAGE_SHIFT - 10);
for_each_zone(zone) {
min = (u64)pages_min * zone->managed_pages;
do_div(min, lowmem_pages);
low = (u64)pages_low * zone->managed_pages;
do_div(low, vm_total_pages);
zone->watermark[WMARK_MIN] = min;
zone->watermark[WMARK_LOW] = min + low + (min >> 2);
zone->watermark[WMARK_HIGH] = min + low + (min >> 1)
...
}
和Linux中对应的代码相比,主要就是多了这样一个"extra_free_kbytes",该参数可通过设置"/proc/sys/vm/extra_free_kbytes"来调节。关于Andoird这个patch的详细信息,请参考这个提交记录。
在Android的机器(基于4.4的Linux内核)上用"cat /proc/zoneinfo"查看一下:
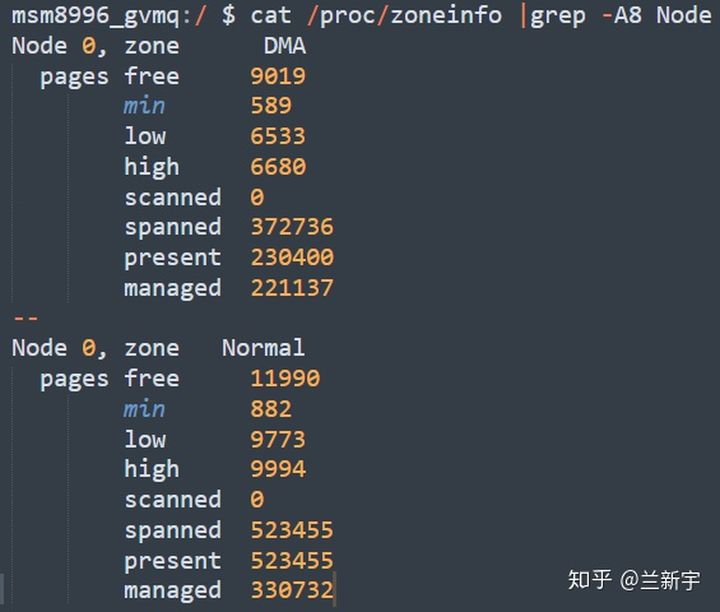
可见,这里"low"和"high"已经不再是"min"值的5/4和6/4了,而是多出了一大截。想要知道调节有没有取得预期的效果,可以通过"/proc/vmstat"中的"pageoutrun"和"allocstall"来查看,两者分别代表了kswapd和direct reclaim启动的次数。

在Linux内核4.6版本中,诞生了一种新的调节watermark的方式。具体做法是引入一个叫做" watermark_scale_factor "的系数,其默认值为10,对应内存占比0.1%(10/10000),可通过"/proc/ sys/vm/watermark_scale_factor"设置,最大为1000。当它的值被设定为1000时,意味着"low"与"min"之间的差值,以及"high"与"low"之间的差值都将是内存大小的10%(1000/10000)。
tmp = max_t(u64, tmp >> 2, mult_frac(zone_managed_pages(zone),
watermark_scale_factor, 10000));
zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp;
zone->_watermark[WMARK_HIGH] = min_wmark_pages(zone) + tmp * 2;
关于这个patch的详细信息,请参考这个提交记录。前面讲到的"extra_free_kbytes"的方式只增大了"low"与"min"之间的差值,而"watermark_scale_factor"的方式同时增大了"low"与"min"之间,以及"high"与"low"之间的差值。现在的Android代码已经合并了4.6内核的这个改动,不再单独提供通过"extra_free_kbytes"来调节watermark的方式了。
6 总结
- **快速内存分配:**是get_page_from_freelist()函数,通过low阀值从zonelist中获取合适的zone进行分配,如果zone没有达到low阀值,则会进行快速内存回收,快速内存回收后再尝试分配。
- **慢速内存分配:**当快速分配失败后,也就是zonelist中所有zone在快速分配中都没有获取到内存,则会使用min阀值进行慢速分配,在慢速分配过程中主要做三件事,异步内存压缩、直接内存回收以及轻同步内存压缩,最后视情况进行oom分配。并且在这些操作完成后,都会调用一次快速内存分配尝试获取页框。
7 参考文档:
内存回收(一):watermark与lowmem_reserve
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
