前面章节我们介绍了memblock,其作用内核启动初期,常用的内存分配器还未被初始化而不能使用,在此期间memblock是一种用于内存管理区域的方法。然后调用page_init来完成系统分页机制的初始化工作,建立页表,从而内核可以完成虚拟地址到物理地址的映射关系,本章主要是分析bootmem_init的流程。
1. bootm初始化
arm架构下, 在setup_arch中通过paging_init函数初始化内核分页机制之后, 内核通过bootmem_init()开始完成内存结点和内存区域的初始化工作,其函数定义在arch/arm/mm/init.c中,如下所示
void __init bootmem_init(void)
{
unsigned long min, max_low, max_high;
memblock_allow_resize(); -------------(1)
max_low = max_high = 0;
find_limits(&min, &max_low, &max_high);
early_memtest((phys_addr_t)min << PAGE_SHIFT,
(phys_addr_t)max_low << PAGE_SHIFT);
arm_memory_present(); -------------(2)
sparse_init(); -------------(3)
zone_sizes_init(min, max_low, max_high); -------------(4)
min_low_pfn = min;
max_low_pfn = max_low;
max_pfn = max_high;
}
- 通过memblock拿到limit,DRAM的起始地址的页面号,分别为min = 0x80000, max_low = 0xa0000,内存的结束地址max_high = 0xa0000,early_memtest做内存的Memtest使用,最终会赋值给min_low_pfn(内存块的起始帧号),max_low_pfn(normal结束帧号),max_pfn(内存块的结束帧号)。
- arm_memory_present是通过CONFIG_SPARSEMEM来定义的,对于现在ARM32该宏没有定义,暂不分析,以后单独讨论。其主要是linux内核已经实现了内存热插的支持,当一个linux系统不管运行在 物理环境 或者虚拟环境 时只要宿主能提供内存热插拔机制,linux内核就能相应的增加或者减少内存。
- 启动并运行bootmem分配器,对于ARM32位系统,该功能不支持,几乎没有做什么
- zone_sizes_init()来初始化节点和管理区的一些数据项, 其中关键的是初始化了系统中各个内存域的页帧边界,保存在max_zone_pfn数组,从min_low_pfn到max_low_pfn是ZONE_NORMAL,max_low_pfn到max_pfn是ZONE_HIGHMEM。
2.zone_sizes_init初始化
static void __init zone_sizes_init(unsigned long min, unsigned long max_low,
unsigned long max_high)
{
unsigned long zone_size[MAX_NR_ZONES], zhole_size[MAX_NR_ZONES]; -------------(1)
struct memblock_region *reg;
memset(zone_size, 0, sizeof(zone_size));
zone_size[0] = max_low - min;
#ifdef CONFIG_HIGHMEM
zone_size[ZONE_HIGHMEM] = max_high - max_low;
#endif
/*
* Calculate the size of the holes.
* holes = node_size - sum(bank_sizes)
*/
memcpy(zhole_size, zone_size, sizeof(zhole_size)); -------------(2)
for_each_memblock(memory, reg) {
unsigned long start = memblock_region_memory_base_pfn(reg);
unsigned long end = memblock_region_memory_end_pfn(reg);
if (start < max_low) {
unsigned long low_end = min(end, max_low);
zhole_size[0] -= low_end - start;
}
#ifdef CONFIG_HIGHMEM
if (end > max_low) {
unsigned long high_start = max(start, max_low);
zhole_size[ZONE_HIGHMEM] -= end - high_start;
}
#endif
}
#ifdef CONFIG_ZONE_DMA -------------(3)
/*
* Adjust the sizes according to any special requirements for
* this machine type.
*/
if (arm_dma_zone_size)
arm_adjust_dma_zone(zone_size, zhole_size,
arm_dma_zone_size >> PAGE_SHIFT);
#endif
free_area_init_node(0, zone_size, min, zhole_size); -------------(4)
}
-
统计zone_size[0]和zone_size[ZONE_HIGHMEM]的大小,zone_size[0] = 0x20000,zone_size[ZONE_HIGHMEM] = 0
-
最终只是配置了zole_size[0],并且其值为0
-
如果定义了CONFIG_ZONE_DMA,通过arm_dma_zone_size来配置DMA的内存域,该区域的长度依于处理器类型。在IA-32计算机上,一般的限制为16MB,在我们现在使用的处理器上,CONFIG_ZONE_DMA没有定义,所以只有ZONE_NORMAL和ZONE_HIGHMEM两种。
-
进入到最关键的地方,free_area_init_node 用来针对特定的节点进行初始化 。
zone_size[]数据用于保持不同ZONE类型具有的页表,zhole_size数组用于保持不同的ZONE类型具有的空洞的页数,如下图所示

接下来看看free_area_init_node的实现接口
void __paginginit free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn, unsigned long *zholes_size)
{
pg_data_t *pgdat = NODE_DATA(nid); -----------------(1)
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->kswapd_classzone_idx);
pgdat->node_id = nid;
pgdat->node_start_pfn = node_start_pfn;
pgdat->per_cpu_nodestats = NULL;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
get_pfn_range_for_nid(nid, &start_pfn, &end_pfn);
pr_info("Initmem setup node %d [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
end_pfn ? ((u64)end_pfn << PAGE_SHIFT) - 1 : 0);
#else
start_pfn = node_start_pfn;
#endif
calculate_node_totalpages(pgdat, start_pfn, end_pfn, -----------------(2)
zones_size, zholes_size);
alloc_node_mem_map(pgdat); -----------------(3)
#ifdef CONFIG_FLAT_NODE_MEM_MAP
printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, node_mem_map %08lx\n",
nid, (unsigned long)pgdat,
(unsigned long)pgdat->node_mem_map);
#endif
reset_deferred_meminit(pgdat); -----------------(4)
free_area_init_core(pgdat); -----------------(5)
}
- 在NUMA有多个节点,而每个节点内,访问内存的时间是相同的,不同的节点,访问内存的时间可以不同。而对于UMA,只有一个节点,取得该node的pg_data_t数据结构变量,每个node都有一个pg_data_t变量描述,进行初始化工作。node_id=0,node_start_fn = 0x80000, start_fn = 0x80000
- 对节点长度和节点总可用页面数进行初始化。calculate_node_totalpages函数是通过调用zone_spanned_pages_in_node和zone_absent_pages_in_node函数实现的,主要是为pgdat的成员变量(包括空洞在内的总页数(node_spanned_pages))和除空洞外的页数(node_present_pages)设置值
- alloc_node_mem_map() 初始化节点的局部映射地址,即pg_data_t->node_mem_map。在NUMA中,全局mem_map指向系统第一个节点的地址,系统中每个节点的起始地址,都对应在全局mem_map的某个位置。在UMA中,全局mem_map就是节点的node_mem_map
- 由于CONFIG_DEFERRED_STRUCT_PAGE_INIT未定义,该函数为空
- 调用free_area_init_core()来真正初始化每个struct zone中的成员,填充pgdat的ZONE结构体。
2.1 calculate_node_totalpages初始化
对于该函数主要是用来计算每一个zone的总页数和实际页数(不包含空洞),以及内存节点的总页数和实际页数(不包含空洞),其代码实现如下
static void __meminit calculate_node_totalpages(struct pglist_data *pgdat,
unsigned long node_start_pfn,
unsigned long node_end_pfn,
unsigned long *zones_size,
unsigned long *zholes_size)
{
unsigned long realtotalpages = 0, totalpages = 0;
enum zone_type i;
for (i = 0; i < MAX_NR_ZONES; i++) {
struct zone *zone = pgdat->node_zones + i;
unsigned long zone_start_pfn, zone_end_pfn;
unsigned long size, real_size;
size = zone_spanned_pages_in_node(pgdat->node_id, i,
node_start_pfn,
node_end_pfn,
&zone_start_pfn,
&zone_end_pfn,
zones_size);
real_size = size - zone_absent_pages_in_node(pgdat->node_id, i,
node_start_pfn, node_end_pfn,
zholes_size);
if (size)
zone->zone_start_pfn = zone_start_pfn;
else
zone->zone_start_pfn = 0;
zone->spanned_pages = size;
zone->present_pages = real_size;
totalpages += size;
realtotalpages += real_size;
}
pgdat->node_spanned_pages = totalpages;
pgdat->node_present_pages = realtotalpages;
printk(KERN_DEBUG "On node %d totalpages: %lu\n", pgdat->node_id,
realtotalpages);
}
该函数主要计算各个ZONE区的page数目,对于ZONE区,其主要有以下3个
-
ZONE_DMA,该管理区是一些设备无法使用DMA访问所有地址的范围,因此特意划分出来的一块内存,专门用于特殊DMA访问分配使用的区域。比如x86架构此区域为0-16M。本处理器该区域不存在
-
ZONE_NORMAL:直接映射区,含有的页面数为0x20000
-
ZONE_HIGHMEM:高端内存管理区,申请的内存,需要内核进行map后才能访问
-
ZONE_MOVABLE:这个区域是一个特殊的存在,主要是为了支持memory hotplug功能,所以MOVABLE表示可移除,其实它也表示可迁移。本架构CPU不支持该功能。
简单来说,可迁移的页面不一定都在ZONE_MOVABLE中,但是ZONE_MOVABLE中的也页面必须都是可迁移的,我们通过查看/proc/pagetypeinfo来看下实例:
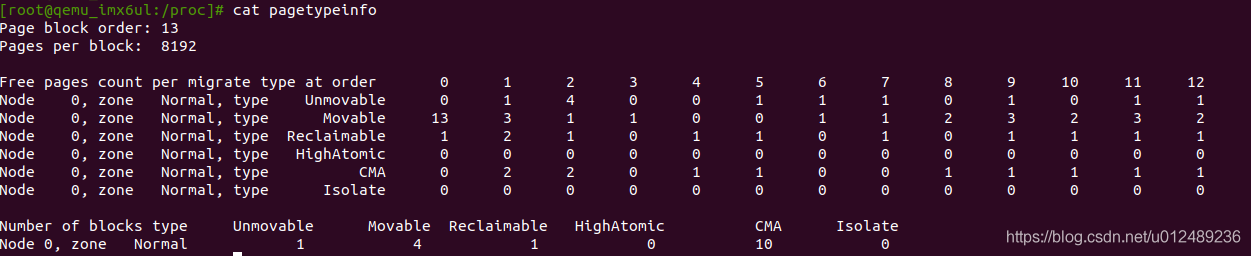
ZONE_MOVABLE这个管理区,主要是和memory hotplug功能有关,为什么要设计内存热插拔功能,主要是为了如下两点考虑:
1.逻辑内存热插拔,对于虚拟机的支持,对于虚拟机按照需求来分配可用内存
2.物理内存热插拔,对于NUMA服务器的支持,不需要的内存就设置为offline,以降低功耗
3.优化内存碎片问题
2.2 alloc_node_mem_map
在linux内核中,所有的物理内存都用struct page结构来描述,这些对象以数组形式存放,而这个数组的地址就是mem_map。内核以节点node为单位,每个node下的物理内存统一管理,也就是说在表示内存node的描述类型struct pglist_data中,有node_mem_map这个成员,其针对平坦型内存进行描述(CONFIG_FLAT_NODE_MEM_MAP)。如果系统只有一个pglist_data对象,那么此对象下的node_mem_map即为全局对象mem_map。函数alloc_remap()就是针对节点node的node_mem_map处理
static void __ref alloc_node_mem_map(struct pglist_data *pgdat)
{
unsigned long __maybe_unused start = 0;
unsigned long __maybe_unused offset = 0;
/* Skip empty nodes */
if (!pgdat->node_spanned_pages) ------------------(1)
return;
#ifdef CONFIG_FLAT_NODE_MEM_MAP
start = pgdat->node_start_pfn & ~(MAX_ORDER_NR_PAGES - 1); ------------------(2)
offset = pgdat->node_start_pfn - start;
/* ia64 gets its own node_mem_map, before this, without bootmem */
if (!pgdat->node_mem_map) {
unsigned long size, end;
struct page *map;
/*
* The zone's endpoints aren't required to be MAX_ORDER
* aligned but the node_mem_map endpoints must be in order
* for the buddy allocator to function correctly.
*/
end = pgdat_end_pfn(pgdat); ------------------(3)
end = ALIGN(end, MAX_ORDER_NR_PAGES);
size = (end - start) * sizeof(struct page); ------------------(4)
map = alloc_remap(pgdat->node_id, size);
if (!map)
map = memblock_virt_alloc_node_nopanic(size, ------------------(5)
pgdat->node_id);
pgdat->node_mem_map = map + offset;
}
#endif /* CONFIG_FLAT_NODE_MEM_MAP */
}
- pgdat->node_spanned_pages此内存节点内无有效的内存,直接略过
- 起始地址必须对其,这个一般按照MB级别对齐即可,对齐后地址与真正开始地址之间的偏移大小,start = 0x80000,offset = 0
- 获取节点内结束页帧号pfn,然后对齐,end = 0xa0000,
- 计算需要的数组大小,需要注意end-start是页帧个数(0xa0000 - 0x80000 = 0x40000),每个页需要一个struct page对象,所以,这里是乘关系,这样得到整个node内所有以page为单位描述需要占据的内存
- 如果这里分配失败,则通过memblock管理算法分配内存。
2.3 free_area_init_core
static void __paginginit free_area_init_core(struct pglist_data *pgdat)
{
enum zone_type j;
int nid = pgdat->node_id;
int ret;
pgdat_resize_init(pgdat); ------------------(1)
#ifdef CONFIG_NUMA_BALANCING
spin_lock_init(&pgdat->numabalancing_migrate_lock);
pgdat->numabalancing_migrate_nr_pages = 0;
pgdat->numabalancing_migrate_next_window = jiffies;
#endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spin_lock_init(&pgdat->split_queue_lock);
INIT_LIST_HEAD(&pgdat->split_queue);
pgdat->split_queue_len = 0;
#endif
init_waitqueue_head(&pgdat->kswapd_wait);
init_waitqueue_head(&pgdat->pfmemalloc_wait);
#ifdef CONFIG_COMPACTION
init_waitqueue_head(&pgdat->kcompactd_wait);
#endif
pgdat_page_ext_init(pgdat);
spin_lock_init(&pgdat->lru_lock);
lruvec_init(node_lruvec(pgdat));
for (j = 0; j < MAX_NR_ZONES; j++) { ------------------(2)
struct zone *zone = pgdat->node_zones + j;
unsigned long size, realsize, freesize, memmap_pages;
unsigned long zone_start_pfn = zone->zone_start_pfn;
size = zone->spanned_pages;
realsize = freesize = zone->present_pages;
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, realsize);
if (!is_highmem_idx(j)) {
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
pr_warn(" %s zone: %lu pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
}
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;
#ifdef CONFIG_NUMA
zone->node = nid;
#endif
zone->name = zone_names[j];
zone->zone_pgdat = pgdat;
spin_lock_init(&zone->lock);
zone_seqlock_init(zone);
zone_pcp_init(zone); ------------------(3)
if (!size)
continue;
set_pageblock_order();
setup_usemap(pgdat, zone, zone_start_pfn, size);
ret = init_currently_empty_zone(zone, zone_start_pfn, size); ------------------(4)
BUG_ON(ret);
memmap_init(size, nid, j, zone_start_pfn); ------------------(5)
}
}
-
主要是初始化struct pglist_data,首先初始化pgdat->node_size_lock自旋锁初始化,初始化pgdat->kswapd_wait等待队列,初始化页换出守护进程创建空闲块的大小
-
遍历各个
zone区域,进行如下初始化:- 根据spanned_pages和present_pages,调用calc_memmap_size计算管理该
zone所需的struct page结构所占的页面数memmap_pages zone中的freesize表示可用的区域,需要减去memmap_pages和dma_reserve的区域,如下开发板的Log打印所示:memmap使用1024页,DMA保留0页
- 根据spanned_pages和present_pages,调用calc_memmap_size计算管理该

- 计算
nr_kernel_pages和nr_all_pages的数量 - 初始化zone的其他变量和各种锁
- 初始化zone结构体的per_cpu_pageset结构体变量pageset,per_cpu_pageset按CPU进行管理。它不直接返回伙伴系统,为快速分配而按不同CPU持有页。
- 初始化zone结构体的free_area结构体。
- memmap_init函数在与页帧具有1:1映射关系的页数组中,向相应的页帧的page结构体的flags成员设置PG_reserved位。
最后,当我们回顾bootmem_init函数时,发现它基本上完成了linux物理内存框架的初始化,包括Node, Zone, Page Frame,以及对应的数据结构等。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
